5 分钟上手!一文掌握 LangGraph 核心技巧,创建能自主研究、管理 TODO 列表的 AI 智能体
LangGraph 是一个专门为创建能够处理复杂任务的智能体而设计的库。让我们了解下深度智能体,理解它们的核心能力,然后使用该库来构建我们自己的 AI Agents。
AI 智能体(Agents)已经将大型语言模型(LLMs)的能力提升了一个台阶,而深度智能体(Deep Agents)又承诺,它不仅仅可以回答你的问题,而且还能够预先思考、分解任务、创建自己的待办事项(TODOs),甚至可以生成子智能体来完成工作,让 AI Agents的能力有提升了一个档次。
深度智能体是基于 LangGraph 构建的,LangGraph 是一个专门为创建能够处理复杂任务的智能体而设计的库。让我们了解下深度智能体,理解它们的核心能力,然后使用该库来构建我们自己的 AI Agents。
Deep Agents
LangGraph 为有状态的工作流提供了基于图(graph-based)的运行时,但你仍然需要从零开始构建自己的规划、上下文管理或任务分解逻辑。DeepAgents(基于 LangGraph 构建)则将规划工具、基于虚拟文件系统的内存和子智能体编排等功能开箱即用地打包在一起。
可以通过独立的 deepagents 库来使用深度智能体(Deep Agents)。它不仅包含了规划能力、还可以生成子智能体,同时利用文件系统进行上下文管理。它还能与 LangSmith 结合使用,用于部署和监控。本文中构建的智能体默认使用 “claude-sonnet-4-5-20250929” 模型,但可以根据需要进行自定义。在我们开始创建智能体之前,先来了解一下它的核心组件。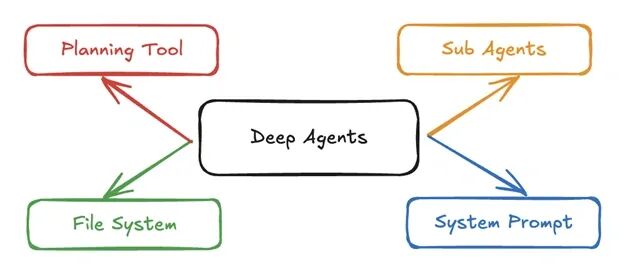
核心组件
- 详细的系统提示词(Detailed System Prompts): 深度智能体使用带有详细说明和示例的系统提示词。
- 规划工具(Planning Tools): 深度智能体内置了用于规划的工具,智能体使用 TODO 列表管理工具来实现规划。这有助于它们即使在执行复杂任务时也能保持专注。
- 子智能体(Sub-Agents): 子智能体被用于处理委派的任务,它们在上下文隔离的环境中执行。
- 文件系统(File System): 虚拟文件系统用于上下文管理和内存管理。这里的 AI 智能体将文件作为工具,在上下文窗口满时将上下文卸载到内存中。
Deep Agents 示例
让我们使用 deepagents 库来构建一个Research Agent,它将使用 Tavily 进行网络搜索,并具备深度智能体的所有组件。
环境准备
需要一个 OpenAI API 密钥来创建这个智能体,你也可以选择使用 Gemini/Claude 等其他模型提供商。请从以下平台获取你的 OpenAI 密钥:https://platform.openai.com/api-keys
同时,还要从这里获取用于网络搜索的 Tavily API 密钥:https://app.tavily.com/home
在 Google Colab 中打开一个新的 Notebook 并添加密文:
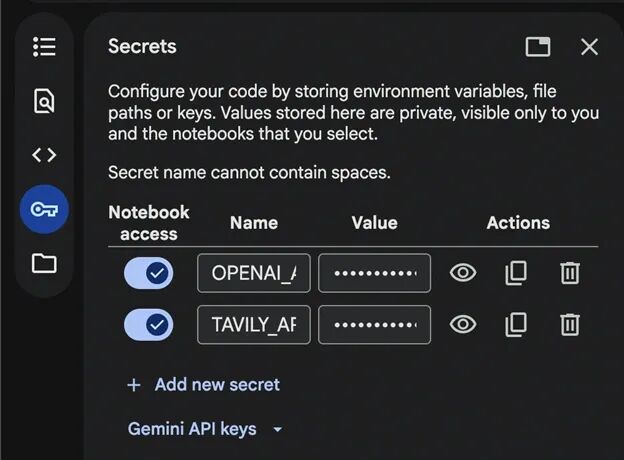
将密钥保存为 OPENAI_API_KEY 和 TAVILY_API_KEY 用于演示,并且不要忘记开启 Notebook 对这些密文的访问权限。
安装依赖库
!pip install deepagents tavily-python langchain-openai
我们将安装运行代码所需的这些库。
导入和 API 设置
import osfrom deepagents import create_deep_agentfrom tavily import TavilyClientfrom langchain.chat_models import init_chat_modelfrom google.colab import userdata# Set API keys TAVILY_API_KEY = userdata.get("TAVILY_API_KEY")os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")
我们将 Tavily API 密钥存储在一个变量中,并将 OpenAI API 密钥设置到环境变量中。
定义工具、子智能体和主智能体
# Initialize Tavily client tavily_client = TavilyClient(api_key=TAVILY_API_KEY)# Define web search tool def internet_search(query: str, max_results: int = 5) -> str:"""Run a web search to find current information""" results = tavily_client.search(query, max_results=max_results)return results# Define a specialized research sub-agent research_subagent = {"name": "data-analyzer","description": "Specialized agent for analyzing data and creating detailed reports","system_prompt": """You are an expert data analyst and report writer. Analyze information thoroughly and create well-structured, detailed reports.""","tools": [internet_search],"model": "openai:gpt-4o",}# Initialize GPT-4o-mini model model = init_chat_model("openai:gpt-4o-mini")# Create the deep agent# The agent automatically has access to: write_todos, read_todos, ls, read_file, # write_file, edit_file, glob, grep, and task (for subagents) agent = create_deep_agent( model=model, tools=[internet_search], # Passing the tool system_prompt="""You are a thorough research assistant. For this task: 1. Use write_todos to create a task list breaking down the research 2. Use internet_search to gather current information 3. Use write_file to save your findings to /research_findings.md 4. You can delegate detailed analysis to the data-analyzer subagent using the task tool 5. Create a final comprehensive report and save it to /final_report.md 6. Use read_todos to check your progress Be systematic and thorough in your research.""", subagents=[research_subagent],)
我们定义了一个用于网络搜索的工具,并将其传递给了我们的智能体。我们在这个演示中使用了 OpenAI 的 gpt-4o-mini 模型,你可以将其更改为任何其他模型。
另请注意,我们没有创建任何文件,也没有为上下文卸载所需的文件系统或 TODO 列表定义任何内容。这些功能都已在 create_deep_agent() 中预构建,并默认可供智能体访问。
运行
# Research query research_topic = "What are the latest developments in AI agents and LangGraph in 2025?"print(f"Starting research on: {research_topic}\n")print("=" * 70)# Execute the agent result = agent.invoke({ "messages": [{"role": "user", "content": research_topic}]})print("\n" + "=" * 70)print("Research completed.\n")
注意: 智能体的执行可能需要一些时间。
输出结果
# Agent execution trace print("AGENT EXECUTION TRACE:")print("-" * 70)for i, msg in enumerate(result["messages"]):if hasattr(msg, 'type'): print(f"\n[{i}] Type: {msg.type}") if msg.type == "human": print(f"Human: {msg.content}") elif msg.type == "ai": if hasattr(msg, 'tool_calls') and msg.tool_calls: print(f"AI tool calls: {[tc['name'] for tc in msg.tool_calls]}") if msg.content: print(f"AI: {msg.content[:200]}...") elif msg.type == "tool": print(f"Tool '{msg.name}' result: {str(msg.content)[:200]}...")
# Final AI response print("\n" + "=" * 70)final_message = result["messages"][-1]print("FINAL RESPONSE:")print("-" * 70)print(final_message.content)
# Files created print("\n" + "=" * 70)print("FILES CREATED:")print("-" * 70)if"files"in result and result["files"]:for filepath in sorted(result["files"].keys()): content = result["files"][filepath] print(f"\n{'=' * 70}") print(f"{filepath}") print(f"{'=' * 70}") print(content)else: print("No files found.")print("\n" + "=" * 70)print("Analysis complete.")
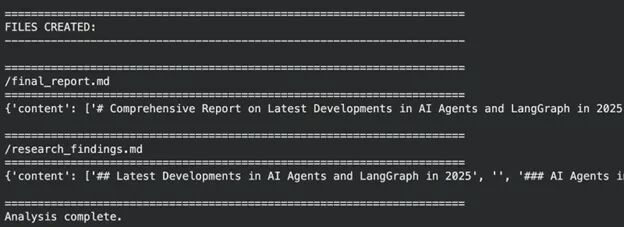
正如我们所看到一样,这个智能体做得很好。它维护了一个虚拟文件系统,经过多次迭代后给出了响应,并认为自己应该是一个“深度智能体”。但我们的系统仍有改进的空间,让我们看看下一节中可以进行哪些改进。
我们构建了一个简单的深度智能体,如果你感兴趣的话,可以基于此并构建出更好的东西。以下是可以改进这个智能体的一些方法:
- 使用长期记忆(Long-term Memory): 深度智能体可以将用户偏好和反馈保存在文件(
/memories/)中。这将帮助智能体给出更好的答案,并从对话中建立知识库。 - 控制文件系统(Control File-system): 默认情况下,文件存储在虚拟状态中,你可以使用
deepagents.backends中的FilesystemBackend将其更改为不同的后端或本地磁盘。 - 优化系统提示词(Refining the System Prompts): 你可以测试多个提示词,看看哪个最适合你的需求。
成功构建了我们的深度智能体,现在可以看到 AI 智能体如何能够利用 LangGraph 来处理任务,将 LLM 的能力提升一个台阶。凭借内置的规划、子智能体和虚拟文件系统,它们能够顺畅地管理 TODO 列表、上下文和研究工作流。深度智能体功能强大,但也要记住,如果一个任务更简单,可以通过一个简单的智能体或 LLM 来完成,那么就不建议使用深度智能体。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献481条内容
已为社区贡献481条内容

所有评论(0)