书生大模型实战营——2. Browser-USE使用/InternLM微调/GraphGen训练数据合成框架
SFT(Supervised Fine-Tuning,监督微调), 一般指的就是指令微调,使用指令跟随数据集(QA pair)就从:生成/筛选高质量数据 → 寻找模型“实际”需要的数据。增量预训练——Continue PreTraining。上面的描述,好像之前基于GAN生成ocr图片的感觉,在GraphGen中,
1. Browser-USE使用
评价:
- 整体还是比较有意思的一个项目,就是通过解析自然语言的输入,然后调用Browser-USE这个工具,去浏览器里执行相应的操作。
- Browser-USE会识别页面中的按键以及相应位置,并在此基础上执行自然语言代表的命令
- 功能很简单,给一个人发一封只有一句话的邮件,但是用了1min30s大概,如果快点的话,就真的太好了,从这里看到了以后操作系统的入口是LLM的感觉~
2. InternLM 微调论文分类实践
- B站视频: 玩转书生大模型 API 之 Browse Use实践
- 文档:

视觉定位(Visual Grounding): 人工智能的视觉语言桥梁:视觉定位(Visual Grounding)技术全览
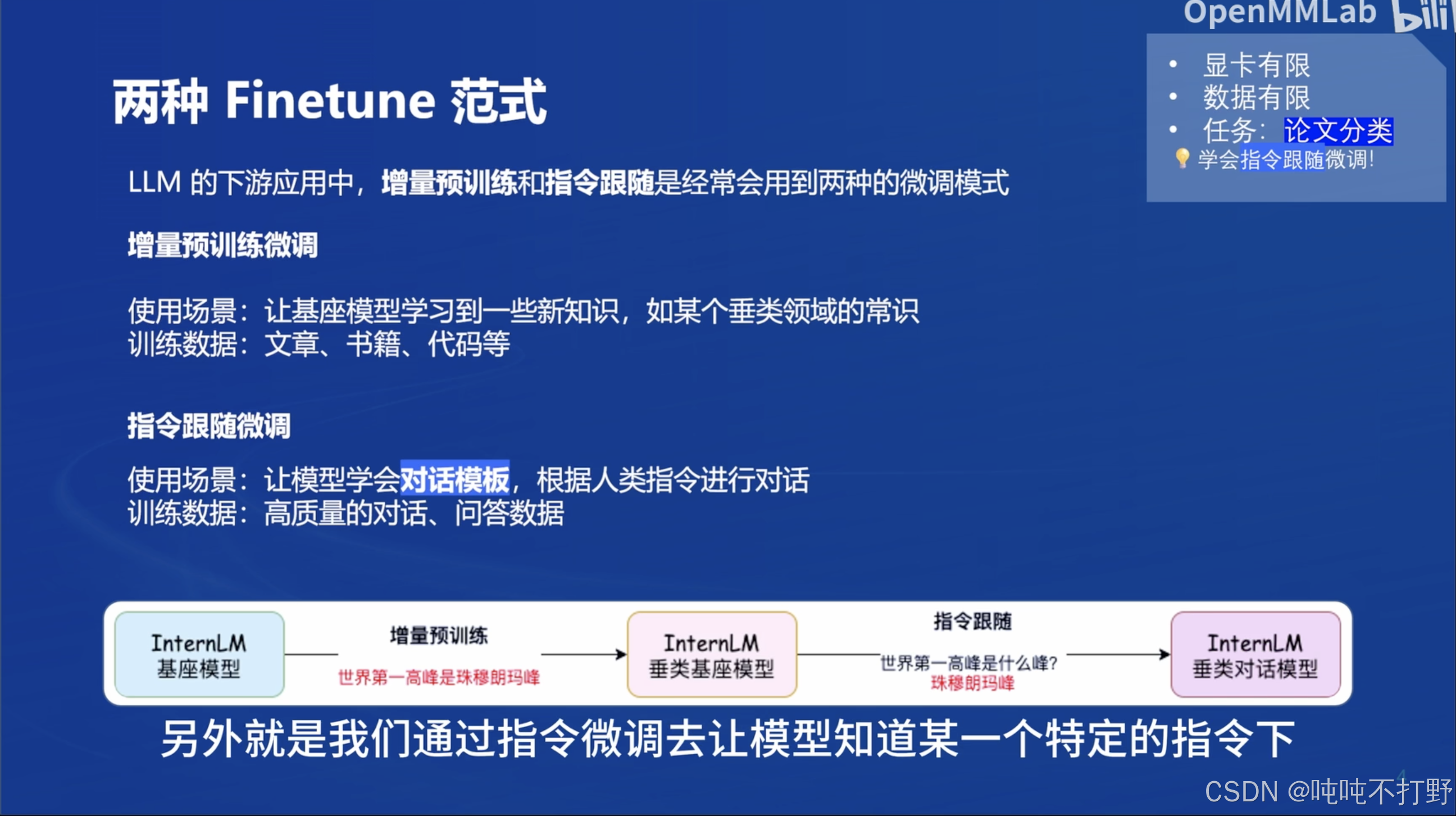
增量预训练——Continue PreTraining
SFT(Supervised Fine-Tuning,监督微调), 一般指的就是指令微调,使用指令跟随数据集(QA pair)
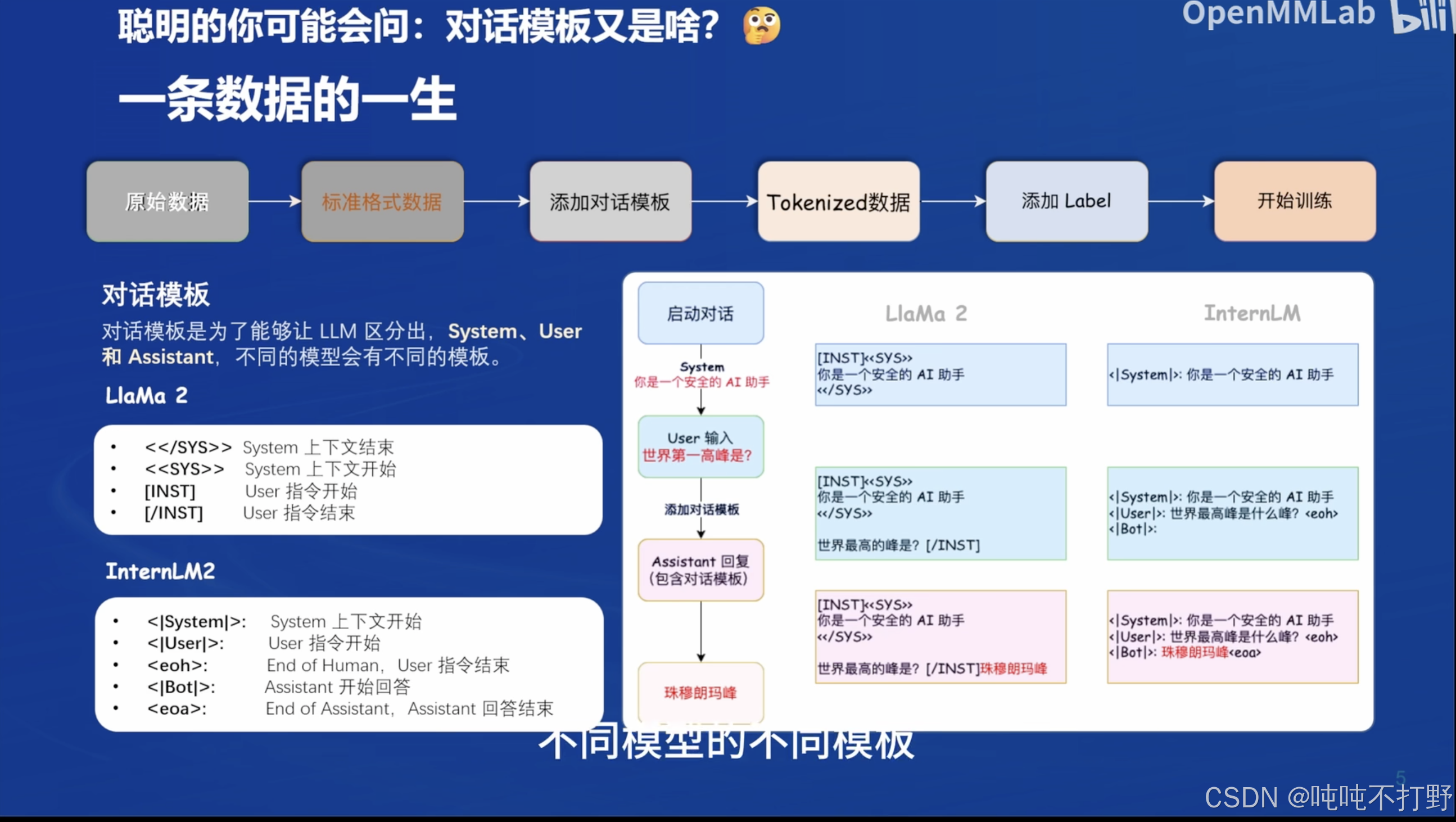
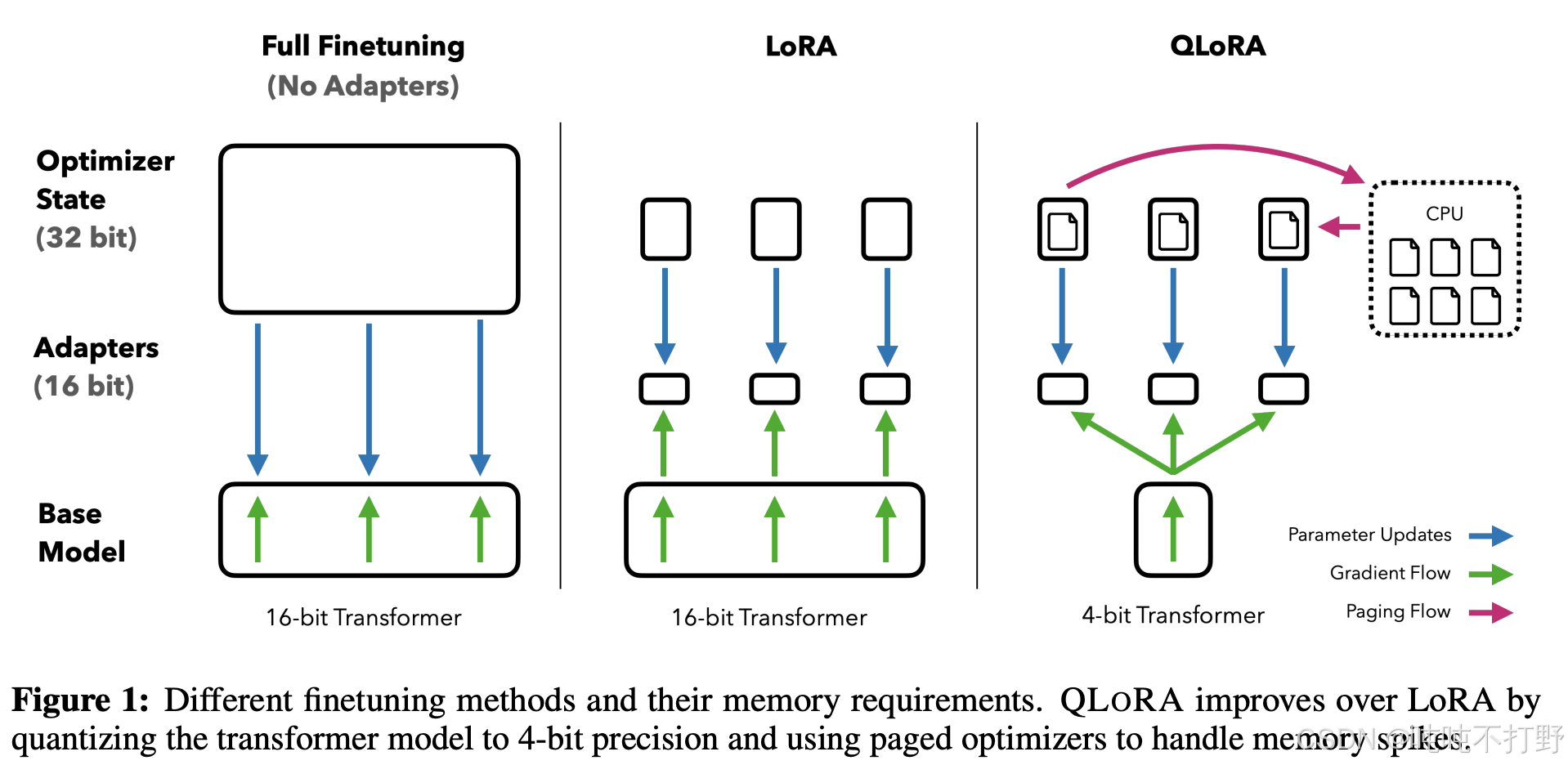
图自: QLoRA: Efficient Finetuning of Quantized LLMs
3. GraphGen
论文链接:GraphGen: Enhancing Supervised Fine-Tuning for LLMs with Knowledge-Driven Synthetic Data Generation
Github链接: open-sciencelab/GraphGen
飞书文档链接: L2G2-GraphGen:训练数据合成实践
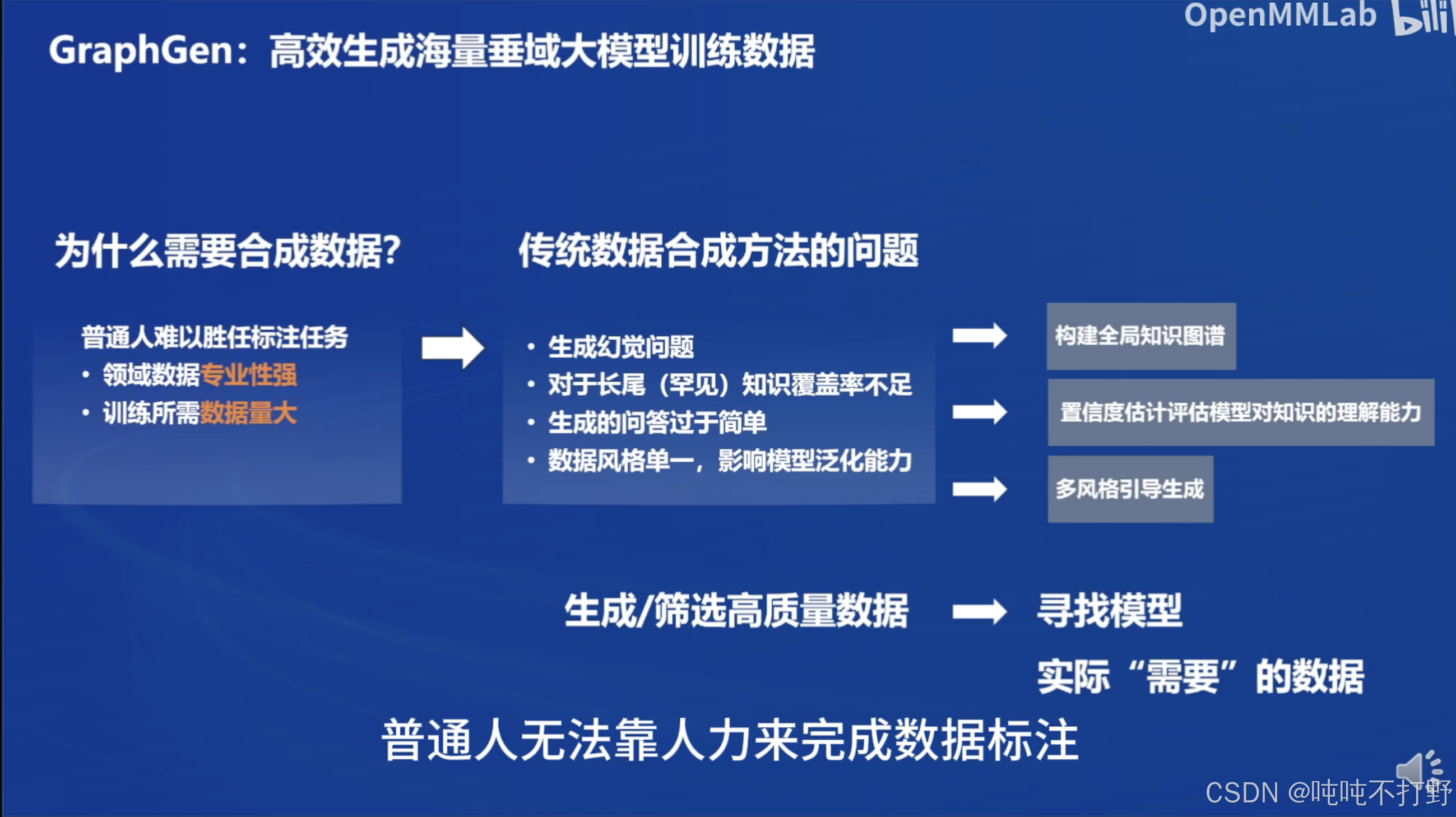
为什么需要合成数据:
- 专业领域训练数据通常需要10w条以上,因此需要考虑合成数据
传统数据合成方法的问题:
- 幻觉问题
- 长尾知识覆盖率不足,即: 大模型更容易生成高频知识,而忽略罕见知识
- 生成数据风格单一,容易导致模型自我重复问题,甚至崩溃
采取的方案:
- 构建全局知识图谱
- 通过置信度估计,评估模型对知识图谱中知识的理解能力
- 生成多种风格的数据
此时合成数据的目标就从:生成/筛选高质量数据 → 寻找模型“实际”需要的数据
上面的描述,好像之前基于GAN生成ocr图片的感觉, PaddleOCR二次全流程——2.使用StyleText合成图片
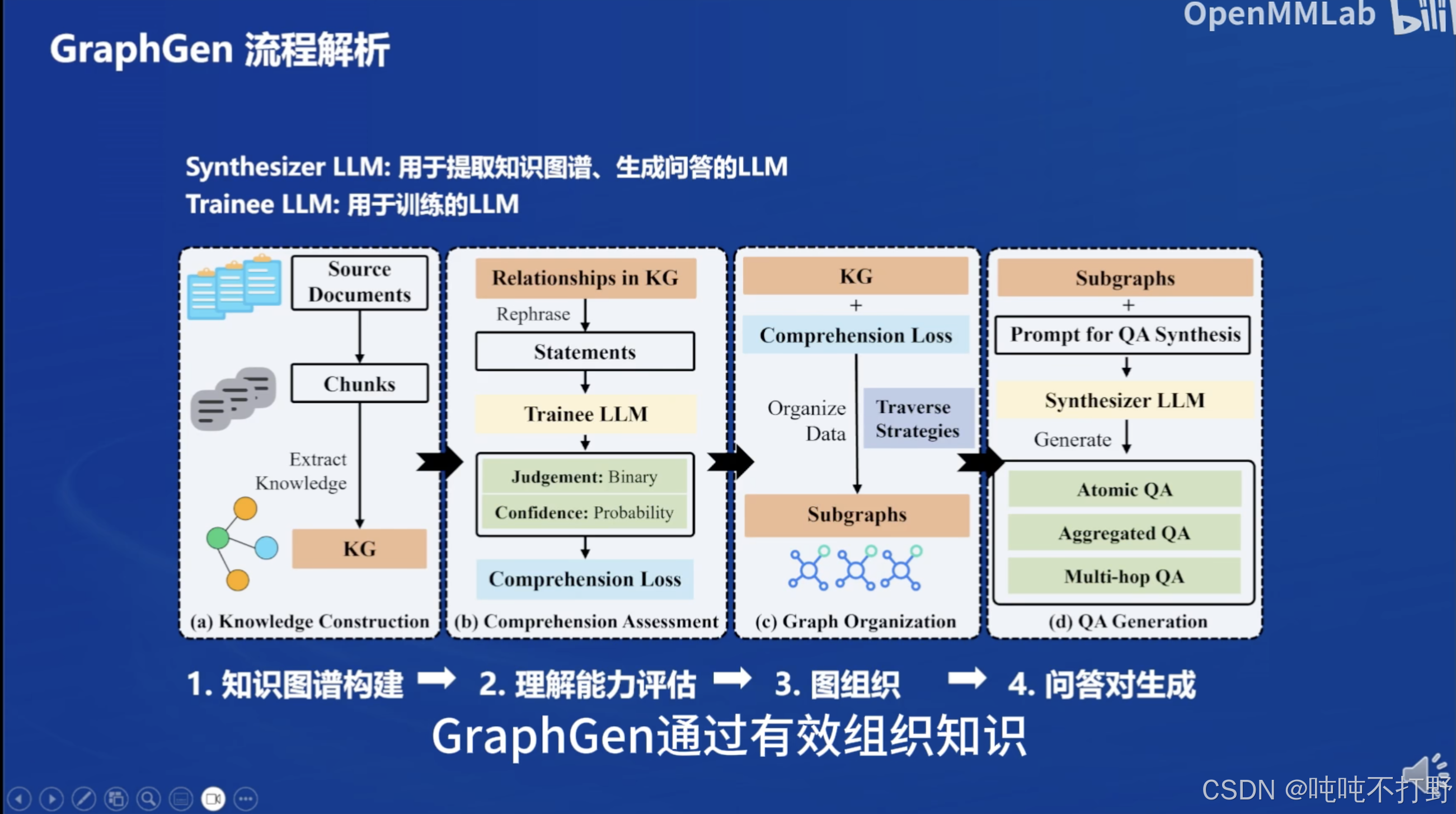
四个核心步骤:
- 从知识中提取实体和关系,来构建知识图谱
- 评估学生模型对知识点的理解能力
- 构建多种策略抽取子图以实现高效训练
- 将子图转换为问答对

ECE是一种衡量模型预测置信度与实际准确性之间关系的指标,其核心思想是:
- 一个模型是校准良好的,当且仅当其预测的置信度与实际的正确概率相匹配
- 即: 模型给出的概率与数据的真实分布概率,越接近越好
在GraphGen中,
- ECE被用于识别大语言模型对知识图谱中知识的理解偏差
- 具体来说:
- 把边看做一个恒正确的论断,通过改写的方式获得多次采样,让模型判断这些论断的正确性,并计算模型对于每个论断的置信度
- 通过大语言模型对论断的判断的token概率来实现评估
- 最后计算理解偏差,理解偏差越大,代表模型越需要这样的数据

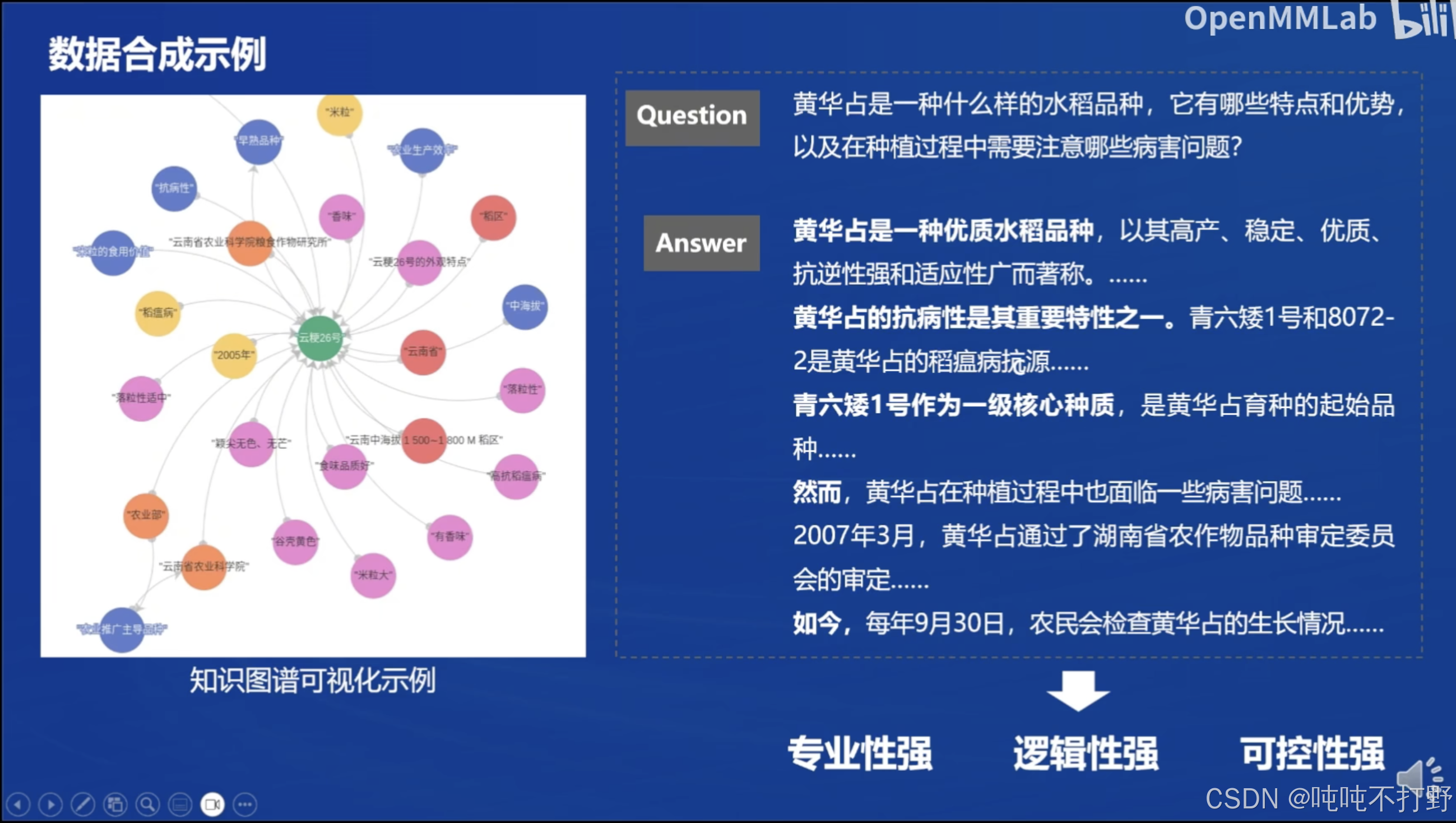
QA:
- 原子问答对
- 聚合问答对
- 多跳问答对

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)