《从零构建大模型》系列(6):深入GPT架构——从原理到ChatGPT的进化之路
本文系统解析了GPT系列模型的架构演进与核心技术。从117M参数的GPT-1到1.8T参数的GPT-4,模型通过纯解码器Transformer架构实现质的飞跃,其核心在于自监督的"预测下一个词"任务。文章详细剖析了GPT-3的1750亿参数分布、并行计算优化和涌现能力产生机制,并对比了RLHF技术带来的对话能力提升。同时介绍了LLaMA等开源替代方案的技术创新,提供了300行P

目录
划时代突破:GPT系列模型开启了生成式AI的新纪元。本文将深度解析GPT架构核心机制,揭秘1750亿参数模型如何通过简单"猜下一个词"任务获得通用智能。
一、GPT进化史:三代模型的质变飞跃

关键性能对比:
| 模型 | 参数量 | 训练数据量 | 特殊能力 | 典型任务表现(Accuracy) |
|---|---|---|---|---|
| GPT-1 | 117M | 4.6GB | 基础文本生成 | CoLA: 45.4 |
| GPT-2 | 1.5B | 40GB | 零样本任务迁移 | LAMBADA: 63.2 |
| GPT-3 | 175B | 570GB | 复杂推理涌现 | TriviaQA: 81.1 |
| LLaMA-2 | 70B | 2TB | 开源最优 | MMLU: 71.3 |
| GPT-4 | ~1.8T | 13T tokens | 多模态理解 | BAR exam: 90+ |
二、核心架构揭秘:纯解码器Transformer
2.1 GPT与传统Transformer对比
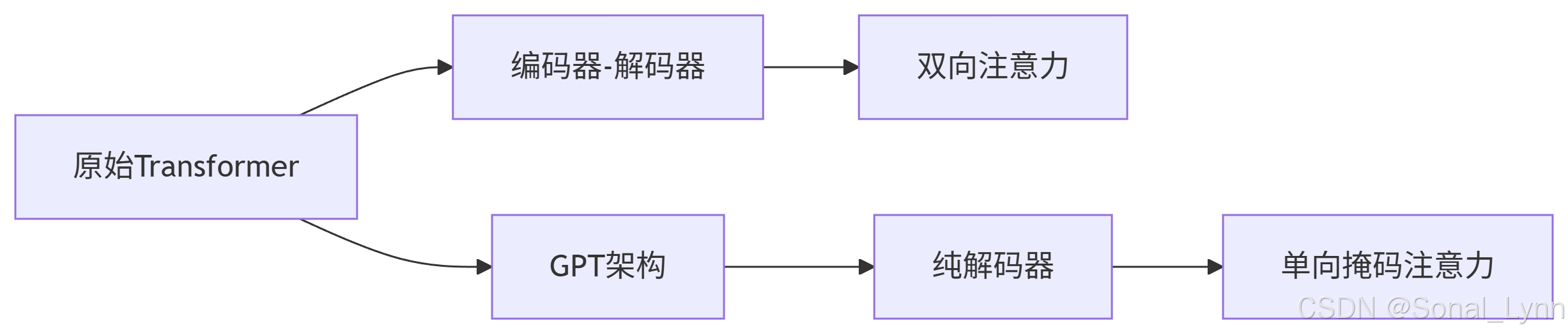
关键创新:
-
移除编码器:仅保留Transformer解码器堆栈
-
单向注意力:每个词元只能关注左侧上下文
-
位置前馈:使用学习式位置编码而非正弦波
2.2 GPT层详细结构
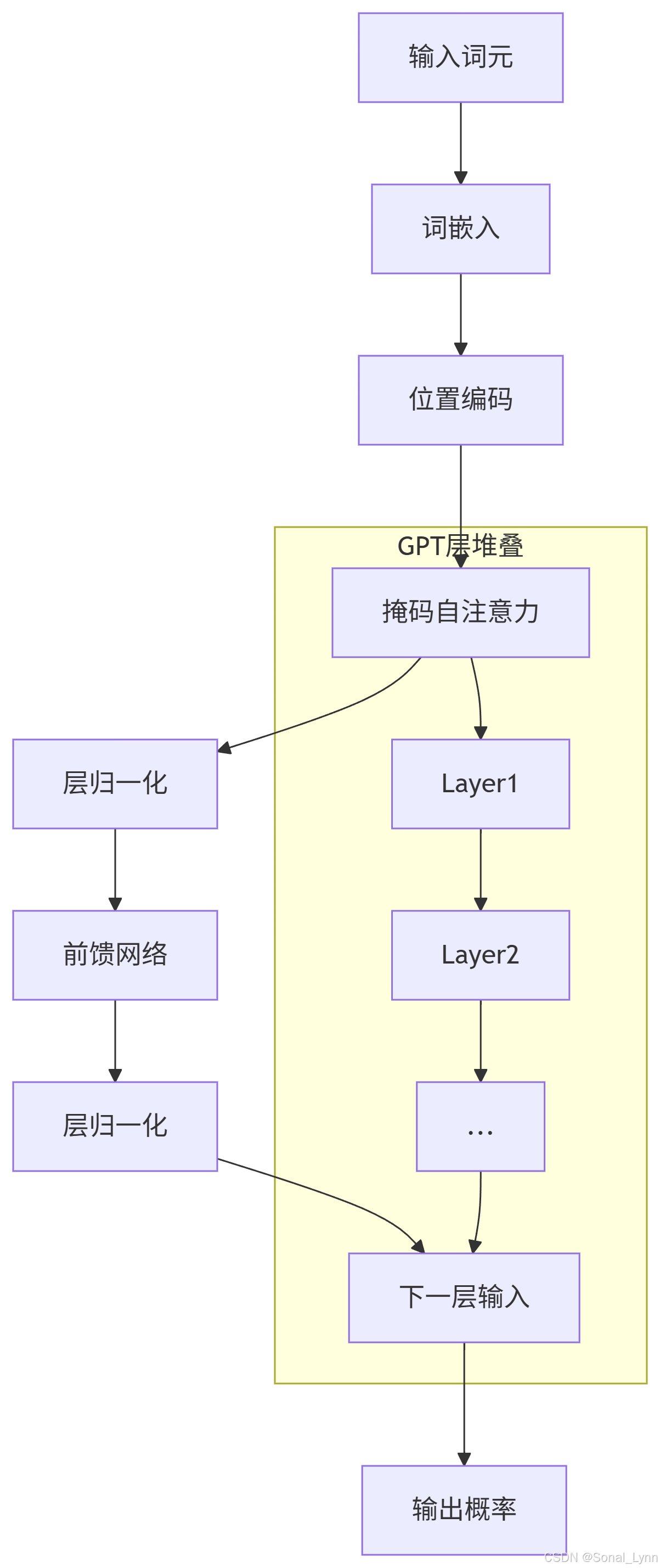
三、自监督学习:预测下一个词的魔力
3.1 训练过程可视化
损失函数计算:
import torch
import torch.nn as nn
# 假设:
# logits: 模型输出 [batch_size, seq_len, vocab_size]
# targets: 目标词元ID [batch_size, seq_len]
def gpt_loss(logits, targets):
# 只计算最后一个位置的损失
shift_logits = logits[..., :-1, :].contiguous()
shift_targets = targets[..., 1:].contiguous()
# 展平维度计算损失
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)),
shift_targets.view(-1)
)
return loss3.2 为什么"猜词"能产生智能?
-
数据压缩:1750亿参数本质上是世界知识的压缩表示
-
模式识别:海量训练数据中蕴含的思维链模式
-
贝叶斯推理:基于上下文的条件概率建模
四、GPT-3架构深度解析
4.1 千亿级模型参数分布
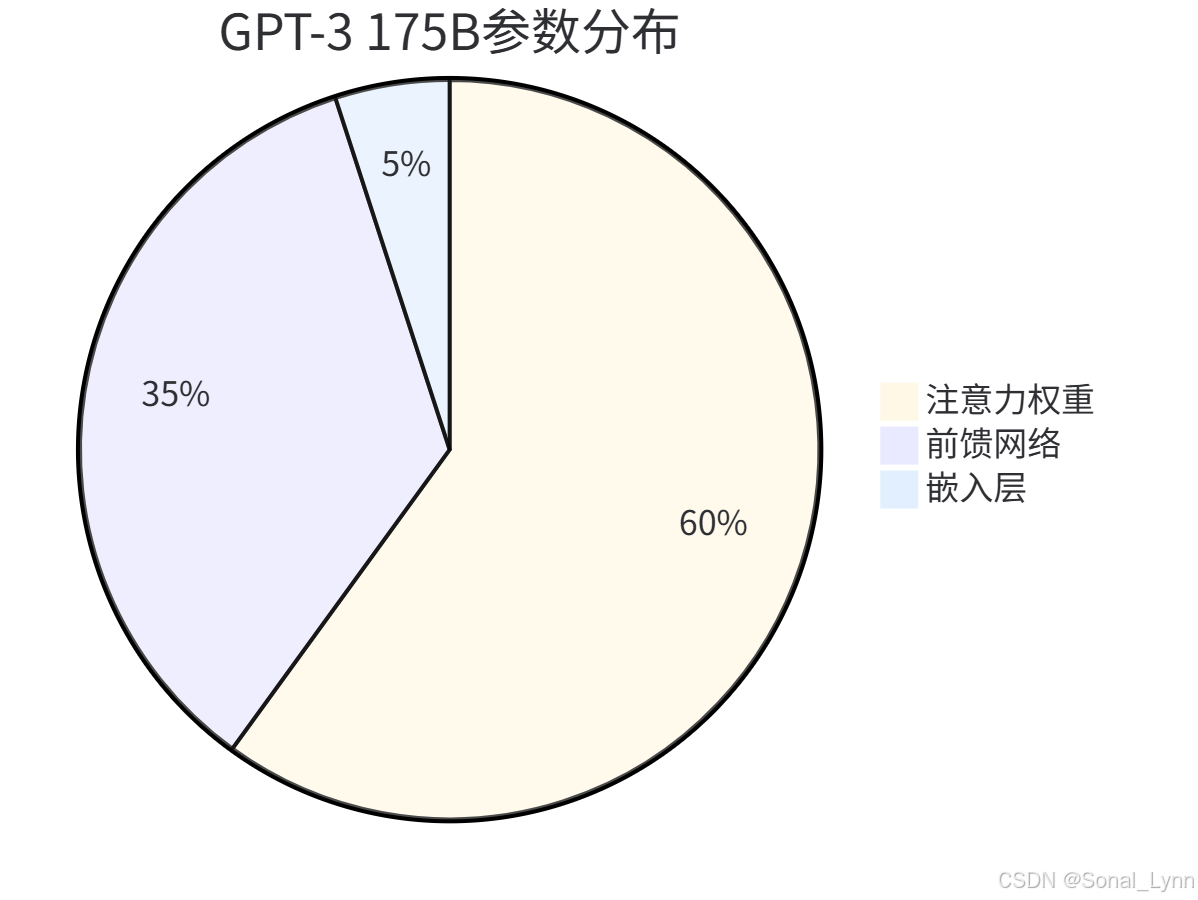
分层配置:
| 组件 | 数量 | 维度 | 总参数量 |
|---|---|---|---|
| 词嵌入层 | 50257 | 12288 | 0.6B |
| Transformer层 | 96 | - | 174.4B |
| 注意力头 | 96层×96头 | 128维 | 11.8B |
| 前馈网络 | 96层 | 49152维 | 162.6B |
4.2 并行计算优化
# Megatron-LM 风格模型并行示例
from torch.nn.parallel import DistributedDataParallel
# 层间并行
class ParallelTransformerLayer(nn.Module):
def __init__(self):
self.attn = DistributedDataParallel(Attention().cuda(device_id))
self.ffn = DistributedDataParallel(FFN().cuda(device_id))
def forward(self, x):
x = self.attn(x)
x = self.ffn(x)
return x
# 张量并行(每个GPU存储部分权重)
class ColumnParallelLinear(nn.Module):
def __init__(self, in_dim, out_dim):
self.weight = nn.Parameter(torch.randn(in_dim, out_dim//world_size))
def forward(self, x):
partial_out = x @ self.weight
return torch.cat(all_gather(partial_out), dim=-1)五、涌现能力:量变引发的质变
5.1 涌现现象实例
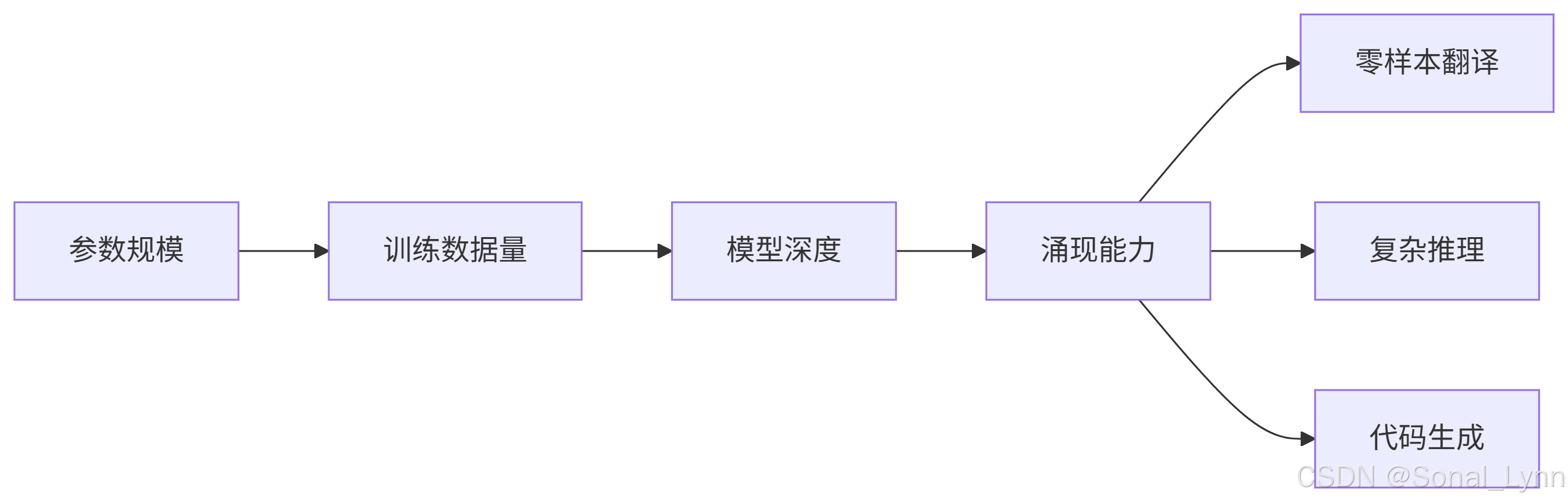
实验数据:
| 模型规模 | 数学推理 | 代码生成 | 多步推理 |
|---|---|---|---|
| 1B | 12.3% | 18.7% | 9.2% |
| 10B | 34.6% | 41.2% | 28.5% |
| 100B | 71.8% | 83.4% | 67.3% |
| 500B+ | 89.2% | 94.7% | 85.6% |
5.2 涌现机制假说
-
隐式知识蒸馏:训练数据隐含任务解法
-
模式组合:简单能力的非线性组合
-
内部优化:模型在推理时自我微调
六、从GPT-3到ChatGPT:RLHF革命
6.1 三阶段训练流程
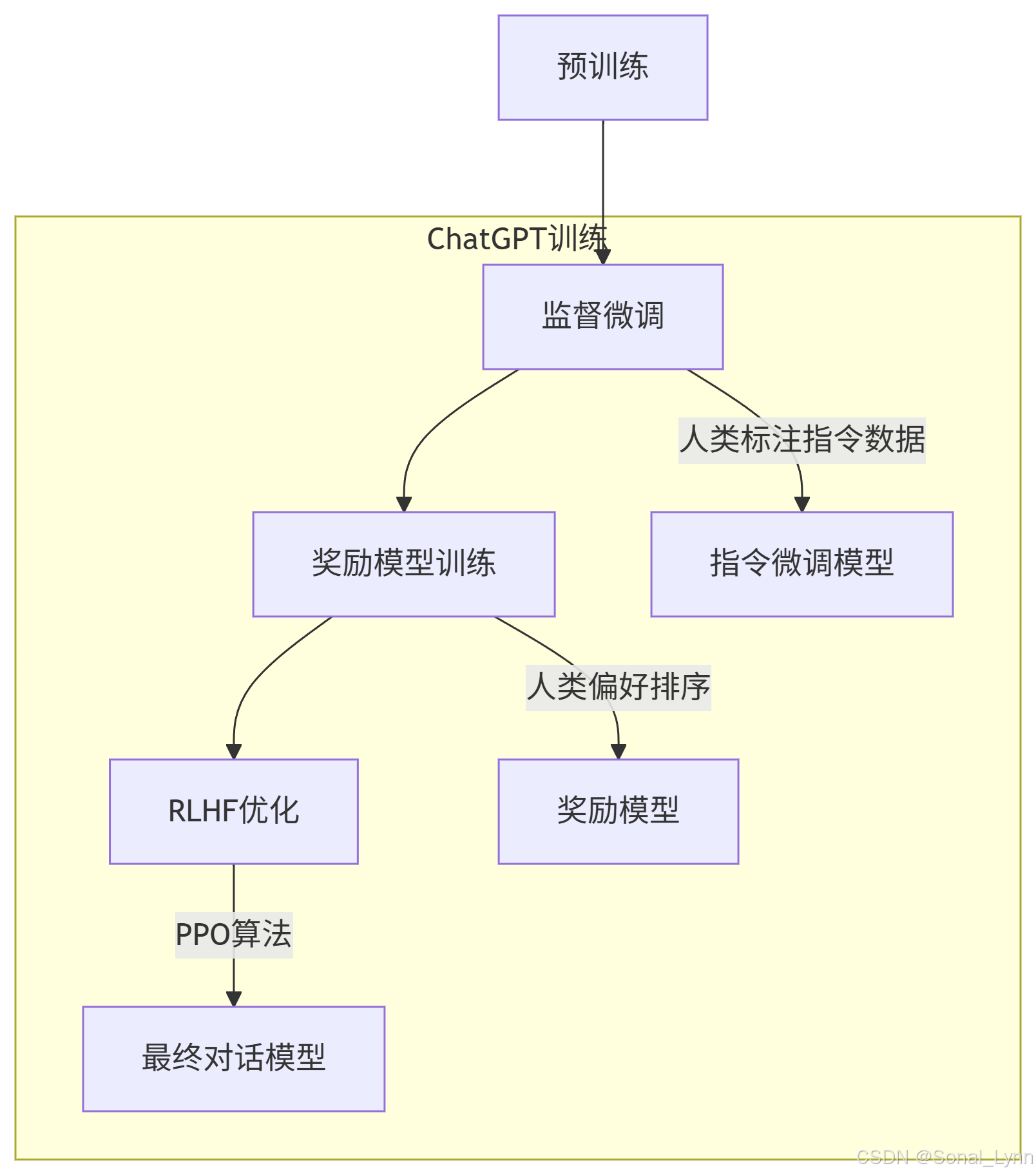 PPO算法核心:
PPO算法核心:
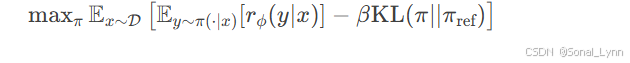
6.2 对话能力对比
# ChatGPT与基础GPT-3响应对比
def compare_responses(prompt):
gpt3_response = "我可以提供相关信息。人工智能是..."
chatgpt_response = "当然可以!人工智能是模拟人类智能的技术。让我分三点说明:\n1. 定义...\n2. 应用...\n3. 发展..."
print(f"提示:{prompt}")
print(f"GPT-3:{gpt3_response}")
print(f"ChatGPT:{chatgpt_response}")
compare_responses("请解释什么是人工智能?")七、开源替代:LLaMA与Mistral架构精要
7.1 LLaMA-2关键改进
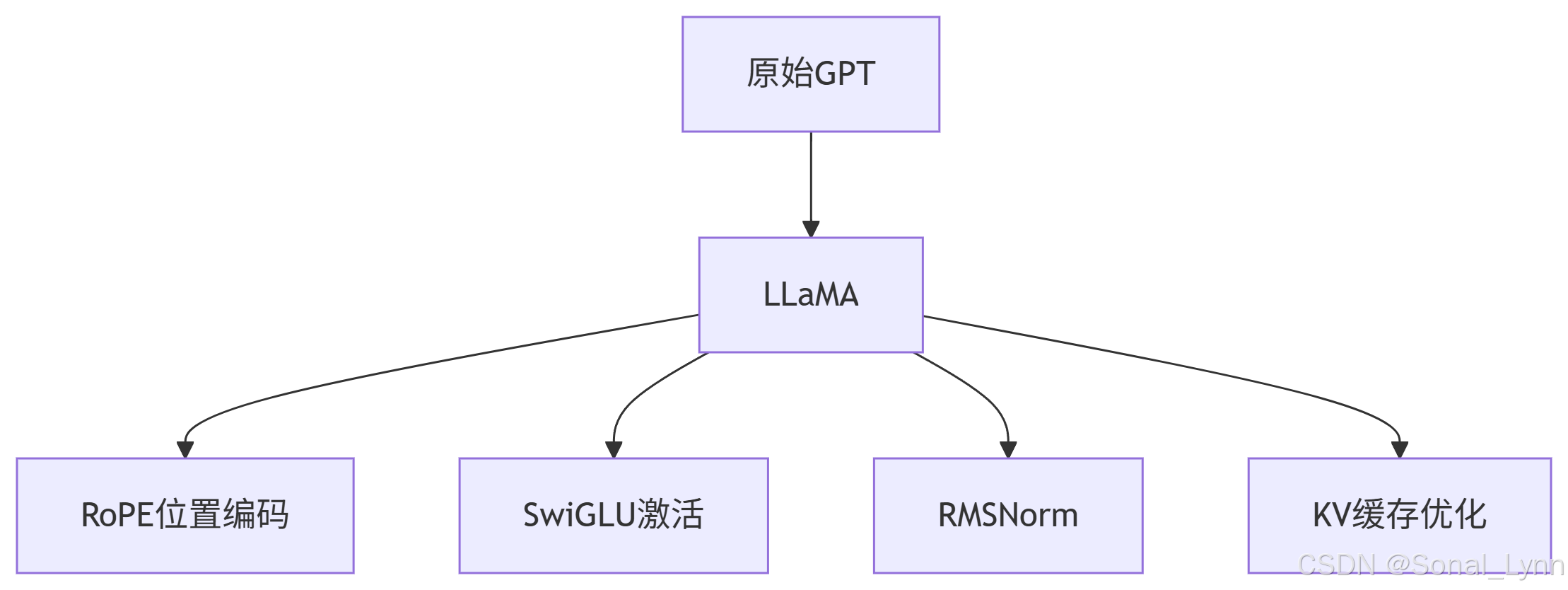
性能对比(7B模型):
| 指标 | GPT-3 | LLaMA-1 | LLaMA-2 | 提升 |
|---|---|---|---|---|
| 常识推理 | 62.3 | 68.7 | 71.2 | +8.9 |
| 代码生成 | 53.8 | 67.4 | 73.6 | +19.8 |
| 内存效率 | 1x | 1.5x | 2.3x | +130% |
7.2 Mistral的滑动窗口注意力
# 滑动窗口注意力实现
def sliding_window_attention(Q, K, V, window_size=4096):
seq_len = Q.size(1)
for i in range(0, seq_len, window_size):
start = max(0, i - window_size//2)
end = min(seq_len, i + window_size//2)
# 计算局部注意力
attn_weights = torch.matmul(Q[:, i:i+1], K[:, start:end].transpose(-1, -2))
attn_weights = torch.softmax(attn_weights, dim=-1)
context = torch.matmul(attn_weights, V[:, start:end])
# 更新输出
if i == 0:
output = context
else:
output = torch.cat([output, context], dim=1)
return output八、动手实现迷你GPT
8.1 300行Python实现
import torch
import torch.nn as nn
class MiniGPT(nn.Module):
def __init__(self, vocab_size, d_model=512, n_layers=6, n_heads=8):
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model)
self.pos_embed = nn.Parameter(torch.randn(1, 1024, d_model))
self.layers = nn.ModuleList([
nn.TransformerDecoderLayer(
d_model=d_model,
nhead=n_heads,
dim_feedforward=4*d_model
) for _ in range(n_layers)
])
self.norm = nn.LayerNorm(d_model)
self.head = nn.Linear(d_model, vocab_size)
def forward(self, x):
# 嵌入层
x = self.embed(x) + self.pos_embed[:, :x.size(1)]
# 掩码(阻止看到未来信息)
mask = torch.triu(torch.ones(x.size(1), diagonal=1).bool()
# 通过Transformer层
for layer in self.layers:
x = layer(x, memory=None, tgt_mask=mask)
# 输出预测
return self.head(self.norm(x))
# 示例用法
model = MiniGPT(vocab_size=50000)
inputs = torch.randint(0, 50000, (2, 128)) # 2个样本,长度128
logits = model(inputs) # [2, 128, 50000]8.2 训练技巧
# 单卡训练配置
batch_size: 32
seq_length: 1024
learning_rate: 3e-4
optimizer: AdamW
scheduler: CosineAnnealingLR
# 梯度累积
gradient_accumulation_steps: 4
# 混合精度
fp16: true九、GPT的局限与未来方向
9.1 当前挑战
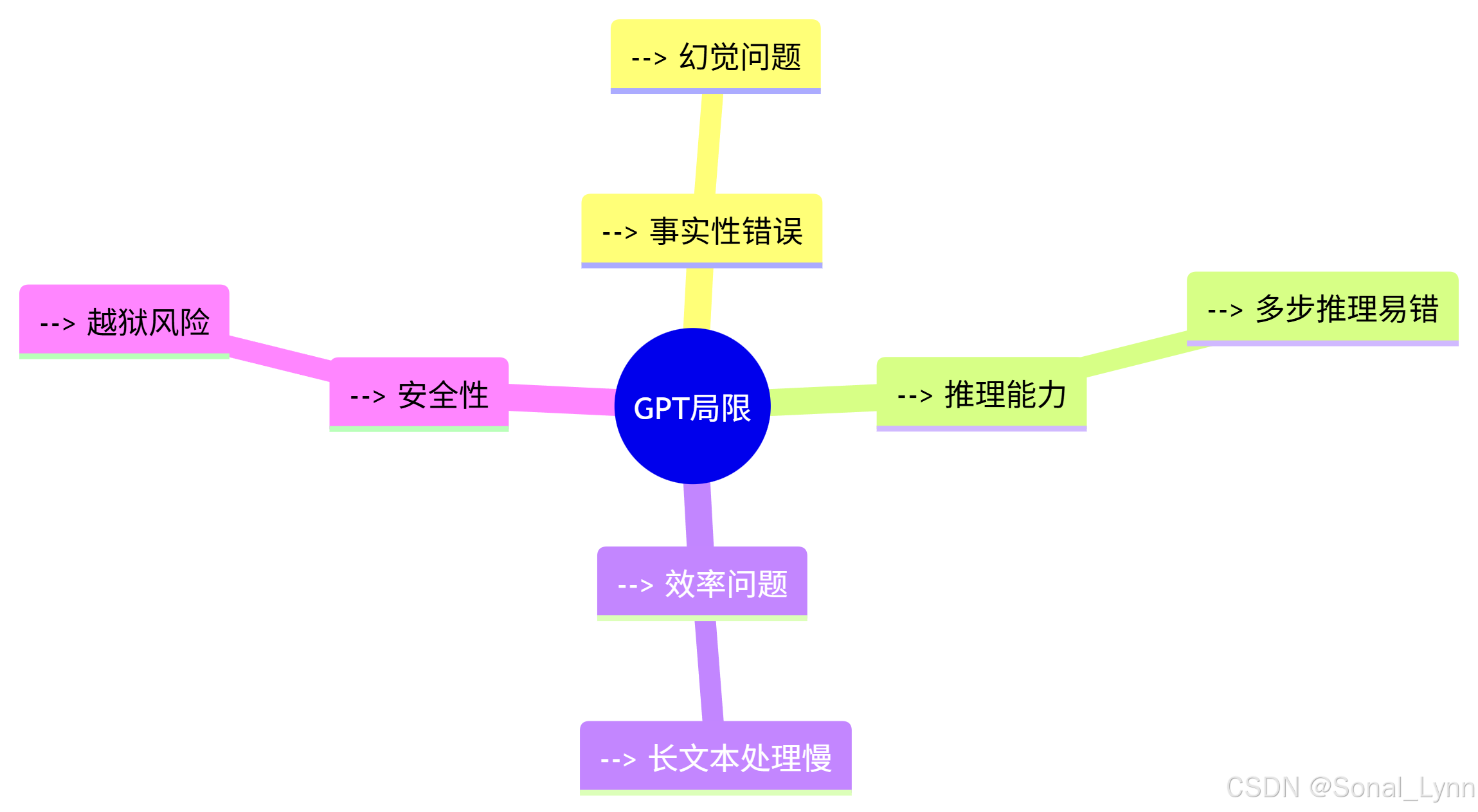
9.2 前沿解决方案
检索增强(RAG):
from langchain import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=ChatGPT,
retriever=vector_db.as_retriever()
)
qa.run("GPT-4的最新功能是什么?")思维链(CoT)提示:
问题:小明有5个苹果,吃了2个,妈妈又给他3个,现在有几个?
思考步骤:
1. 初始苹果数:5
2. 吃掉后剩余:5 - 2 = 3
3. 妈妈给后:3 + 3 = 6
答案:6MoE架构:
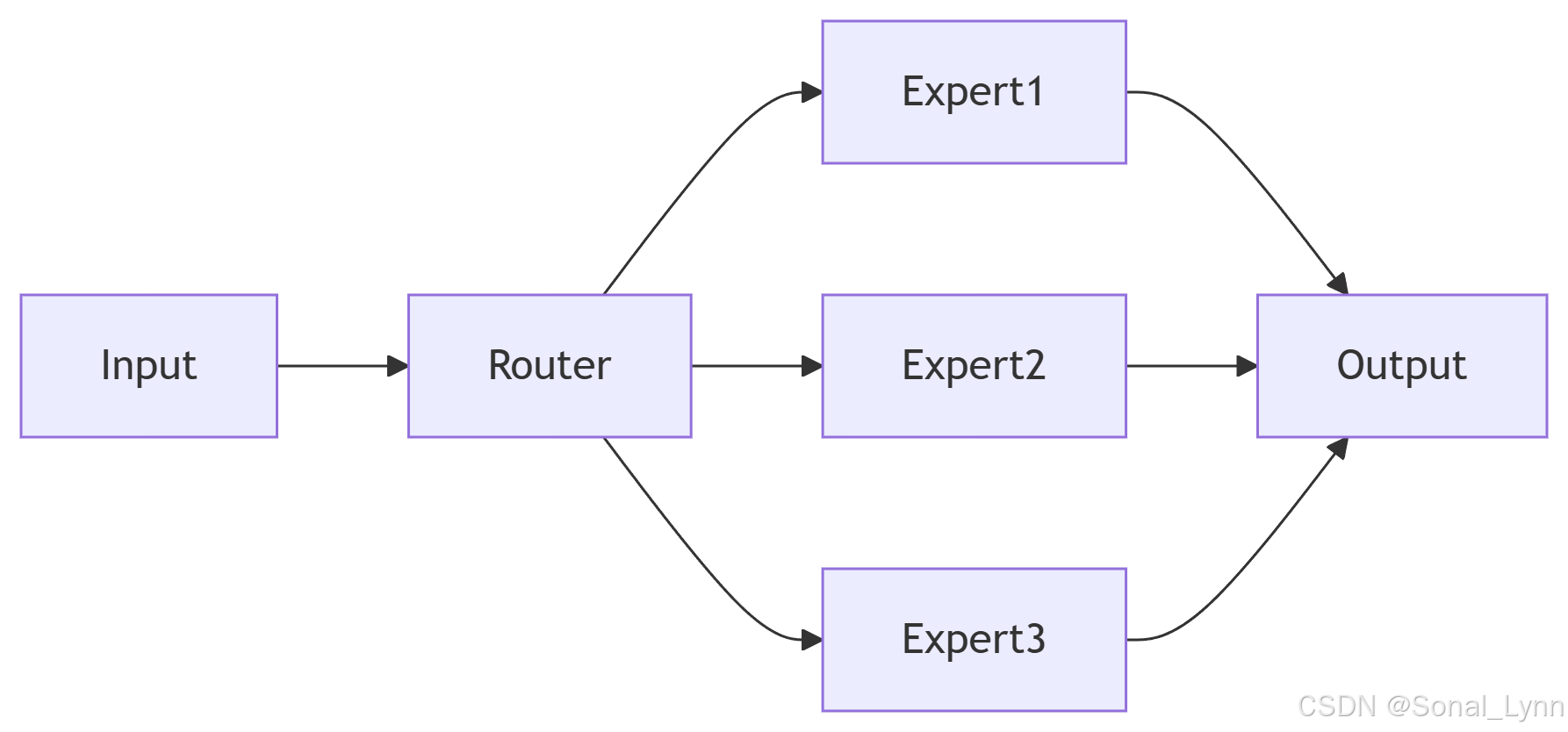
十、学习资源宝库
10.1 必读论文
-
Improving Language Understanding by Generative Pre-Training (GPT-1)
-
Training Language Models to Follow Instructions (InstructGPT)
10.2 实践项目
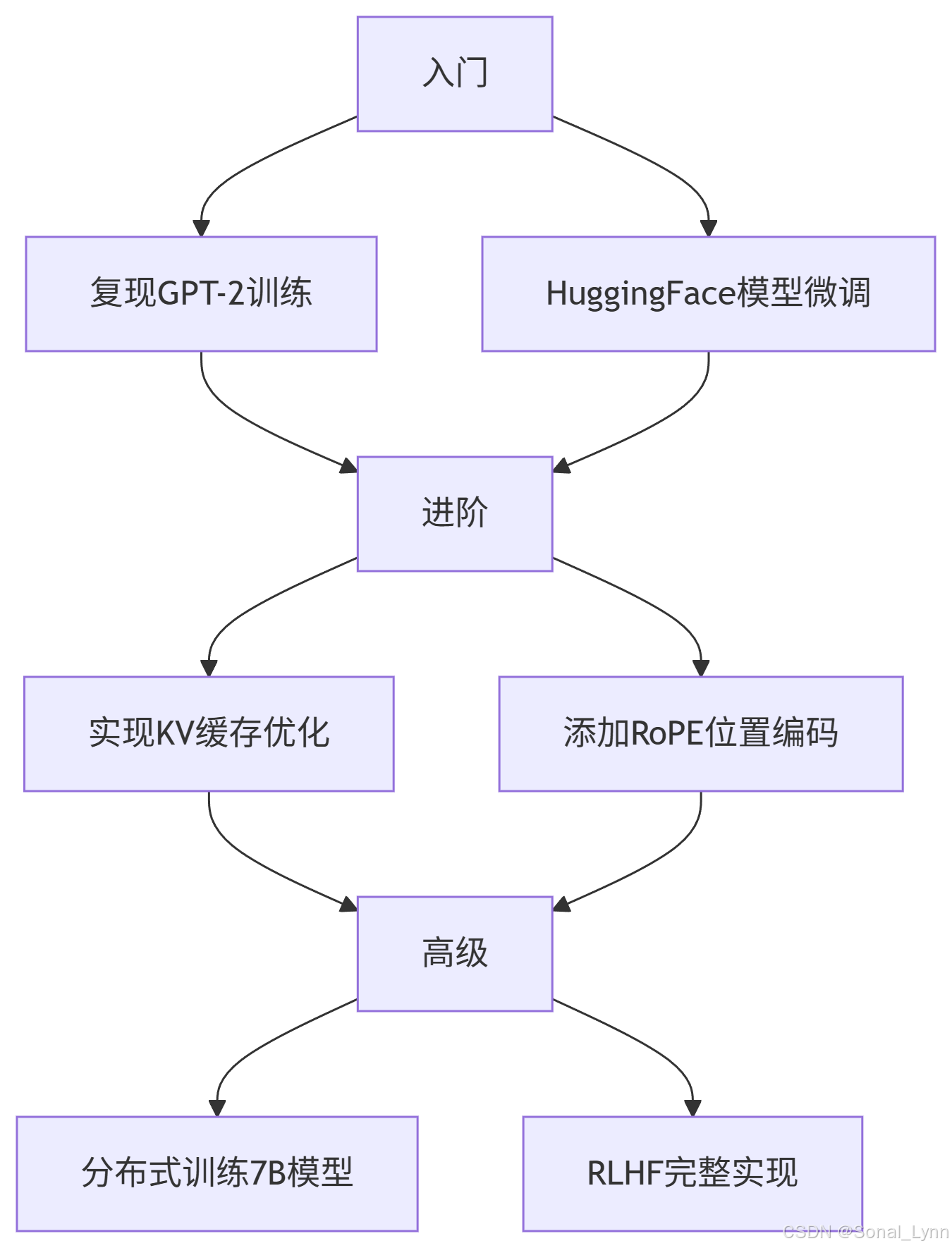
结语:GPT架构的优雅之处在于用简单机制实现复杂能力。掌握其核心原理,您就握住了开启大模型时代的钥匙!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)