Rotary Positional Embedding
当embedding维度为2时,position的位置每往后一个,就把embedding对应维度旋转θ角度,这就是RoPE的核心思想。问题:理论上讲,位置1,2对应的PE应该在距离上比位置1,500的PE更接近,但APE做不到这一点。的操作是完全一样的(如果去掉Attention Is All You Need中的PE的话)。解决了APE中的问题,但也带来了计算效率低下等问题。而矩阵的第一项,就是
先介绍几个之前的PE:
1. Absolute Positional Embedding
比如 Transformer原论文中的PE。
问题:理论上讲,位置1,2对应的PE应该在距离上比位置1,500的PE更接近,但APE做不到这一点。
2.Relative Positional Embedding
解决了APE中的问题,但也带来了计算效率低下等问题。此处不对RPE做详细介绍
3.Learned Positional Embedding
每个位置的PE通过学习得到。
问题:如果训练集中的Sequence Length都是512以内,那么当推理时遇到长度长于512得到sequence时,就会出问题了。
4.Rotary Positional Embedding
不太懂旋转矩阵的可以参考这个链接
RoPE怎么做的?请看: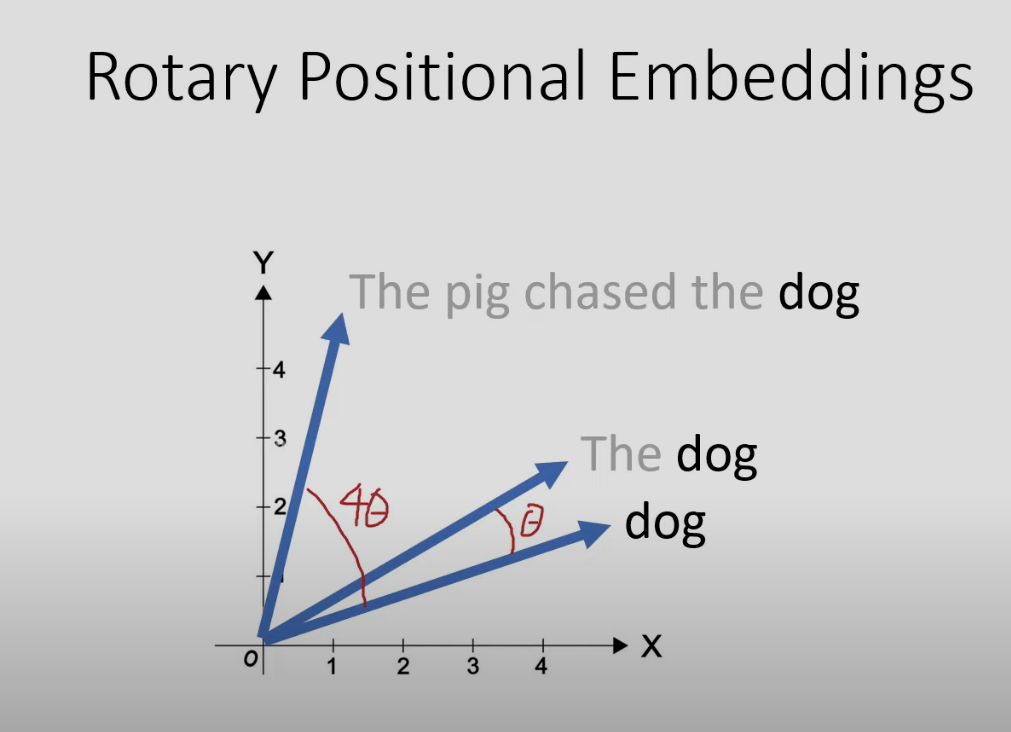
当embedding维度为2时,position的位置每往后一个,就把embedding对应维度旋转θ角度,这就是RoPE的核心思想。
再看论文的公式13: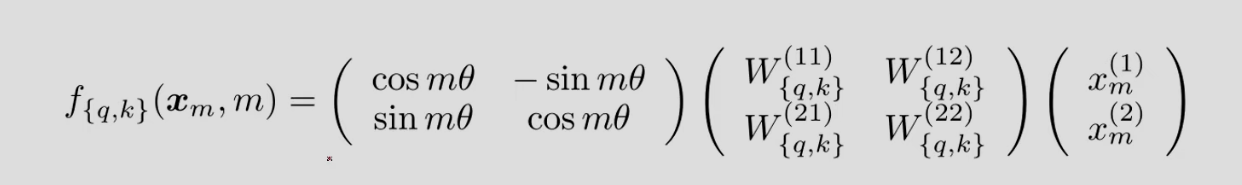
其中 x m x_m xm表示位置 m m m处的embedding(由embedding层得到,还不含PE信息); { q , k } \{q,k\} {q,k}表示得到的是 q q q或者 k k k的表示(不含 v v v)。
矩阵乘法的后两项,就是把二维的embedding映射到 q q q和 k k k的简单映射(四个W都是标量)。这里的操作和Attention Is All You Need中得到 q q q或者 k k k的操作是完全一样的(如果去掉Attention Is All You Need中的PE的话)。
而矩阵的第一项,就是把矩阵做一个简单的旋转,这一点我们已经提到过了。
当embedding维度大于2的时候怎么办呢?我们只需要将维度2个2个地进行旋转就行了: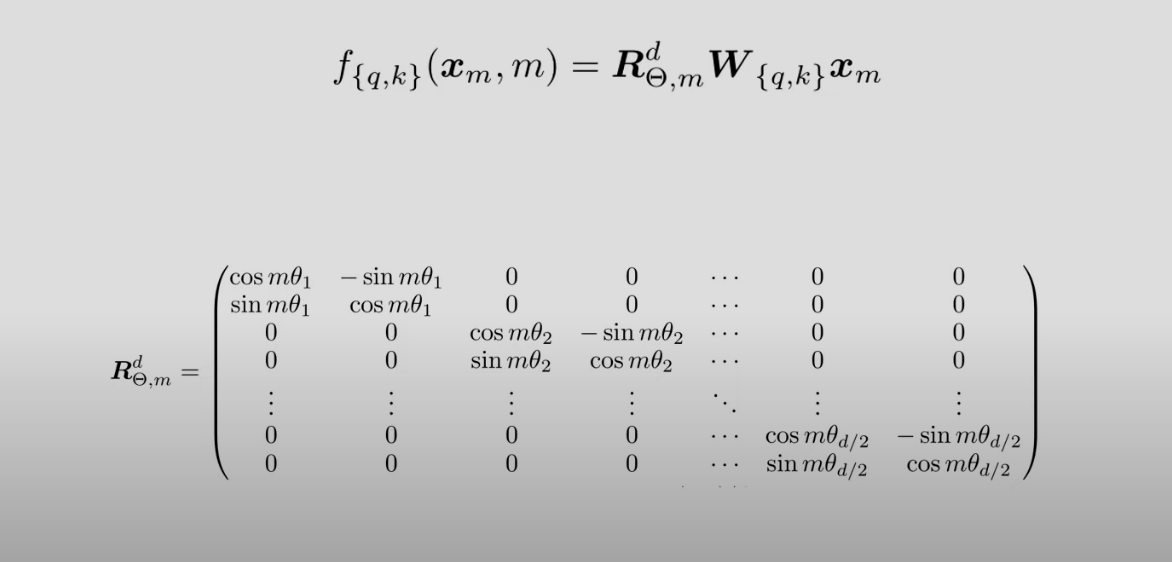
原始论文也对这一过程进行了图解说明: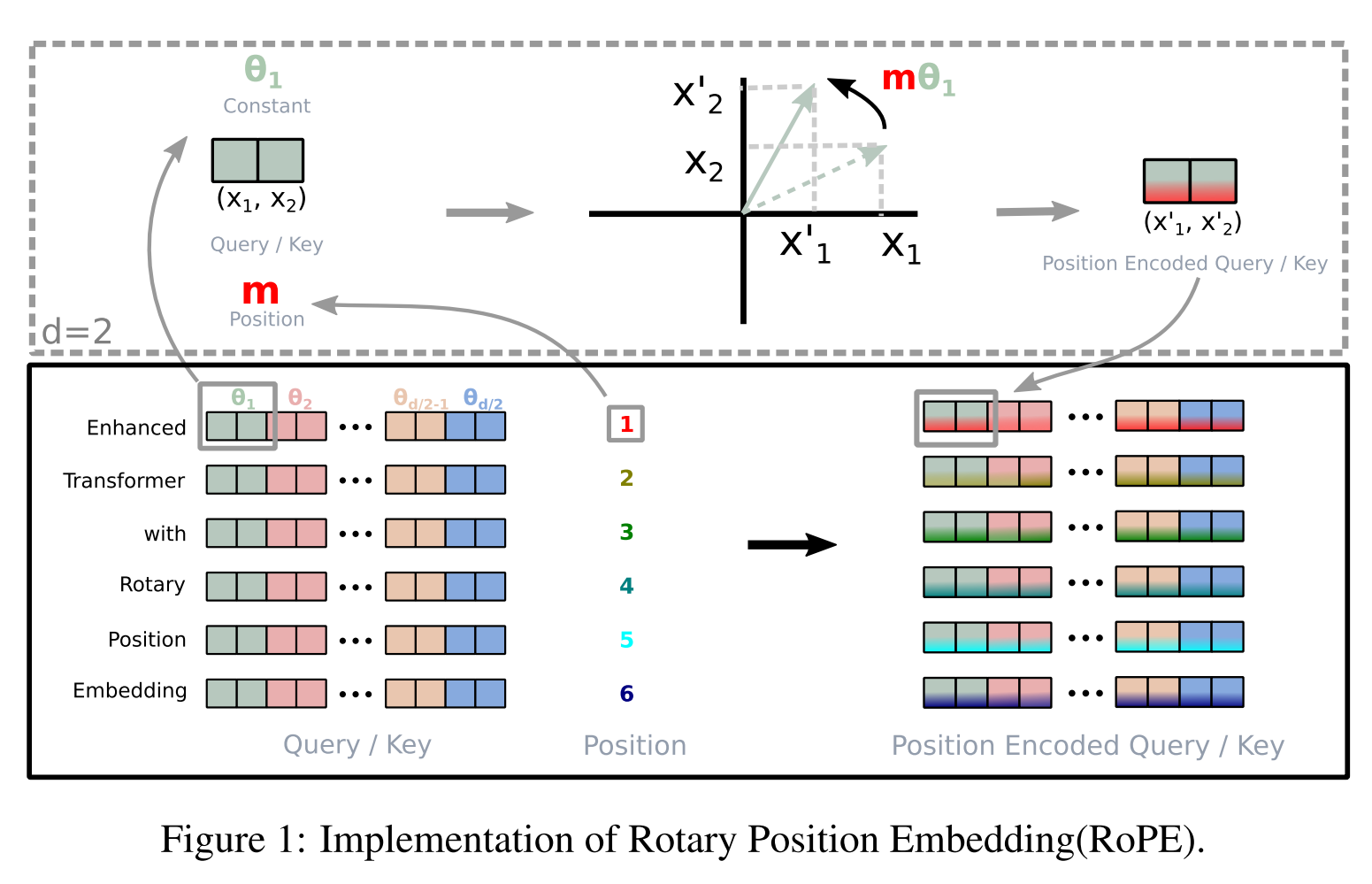
参考链接

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)