LLM学习笔记--3.3 Decoder-Only PLM
Decoder-Only,即只使⽤ Decoder 堆叠⽽成的模型。Decoder-Only 就是⽬前⼤⽕的 LLM 的基础架构,⽬前所有的 LLM 基本都是 Decoder-Only 模型((RWKV、Mamba 等)。
Decoder-Only,即只使⽤ Decoder 堆叠⽽成的模型。Decoder-Only 就是⽬前⼤⽕的 LLM 的基础架构,⽬前所有的 LLM 基本都是 Decoder-Only 模型((RWKV、Mamba 等)。
一、GPT
GPT,即 Generative Pre-Training Language Model,是由 OpenAI 团队于 2018年发布的预训练语⾔模型。
1. 模型架构-Decoder-Only
GPT整体结构选择使用Decoder来进行模型结构的堆叠,这种结构更契合于NLG任务和Seq2Seq任务。
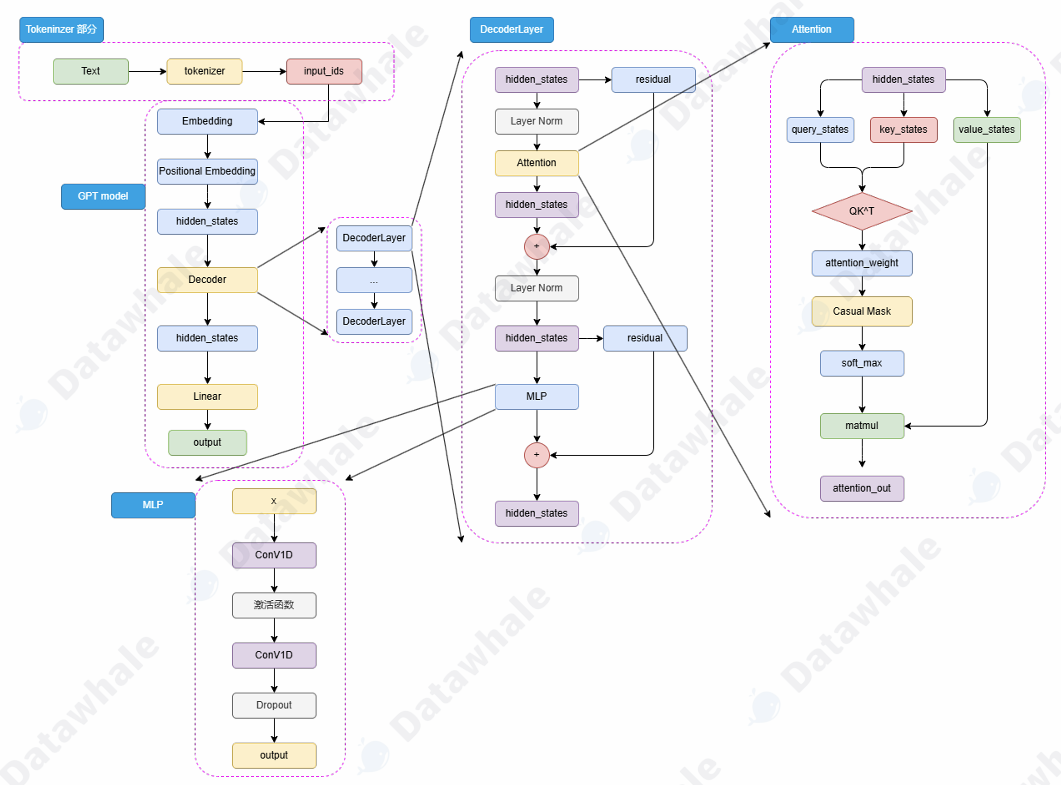
由于不再有Encoder的输入,Decoder层仅保留了一个带掩码的注意力层,并且将LayerNorm层从Transformer的注意力层之后提到了注意力层之前。hidden_states 输⼊ Decoder 层之后,会先进⾏ LayerNorm,再进⾏掩码注意⼒计算,然后经过残差连接和再⼀次 LayerNorm 进⼊到 MLP 中并得到最后输出。
2. 预训练任务-CLM
因果语言模型,Casual Language Model,简称CLM。这个模型可以视为N-gram的一个扩展,N-gram的工作方式是根据前N个token来预测下一个token,CLM的工作方式是根据前面所有token来预测下一个token。举例,对于一个目标文本长度为256,期待文本长度为256的任务,要进行256次计算,最后生成一个长度为512的输出文本,其中前256个是输入,后256个是模型实际输出。
3.GPT系列模型发展
OpenAI一直致力于“体量即正义”的道路,通过不断扩充预训练数据集、模型体量等扩充操作来发展GPT模型,ChatGPT的成功也证明了这种思路的正确性和有效性。
GPT1是第⼀个使⽤ Decoder-Only 的预训练模型,其预训练体量和模型体量都较小,沿袭了Transformer模型结构。其表现并没有比BERT模型的效果更好,没有成为同时代模型里的代表。
GPT2在GPT1的基础上进一步探究预训练语言模型多任务学习能力,其主要改动在于扩大模型参数规模、将Post-Norm改为Pre-Norm(先进行LayerNorm再进行注意力计算)。这些改动是为了降低模型出现梯度消失/爆炸的风险。还有一项重大突破是提出以zero-shot(零样本学习)为主要目标,不对模型进行微调,而是直接要求模型解决任务。由于模型能力欠缺,Zero-shot并未完全展示出其效果,而是在其延伸发展出的few-shot中扩充了应用。
GPT3继续增大数据集和参数规模,整体参数量达到175B,大体量模型。few-shot 是在 zero-shot 上的改进,研究者发现即使是 175B ⼤⼩的 GPT-3,想要在 zero-shot 上取得较好的表现仍然是⼀件较为困难的事情。⽽ few-shot 是对 zero-shot 的⼀个折中,旨在提供给模型少样的示例来教会它完成任务。同时,few-shot也被称为上下文学习(Incontext Learning),让模型通过上下文理解语义。
二、LLaMA
LLaMA模型是由Meta(前Facebook)开发的⼀系列⼤型预训练语⾔模型。
1. 模型架构-Decoder-Only
LLaMA模型的整体结构于GPT结构类似,只是在模型规模和预训练数据集上有所不同。
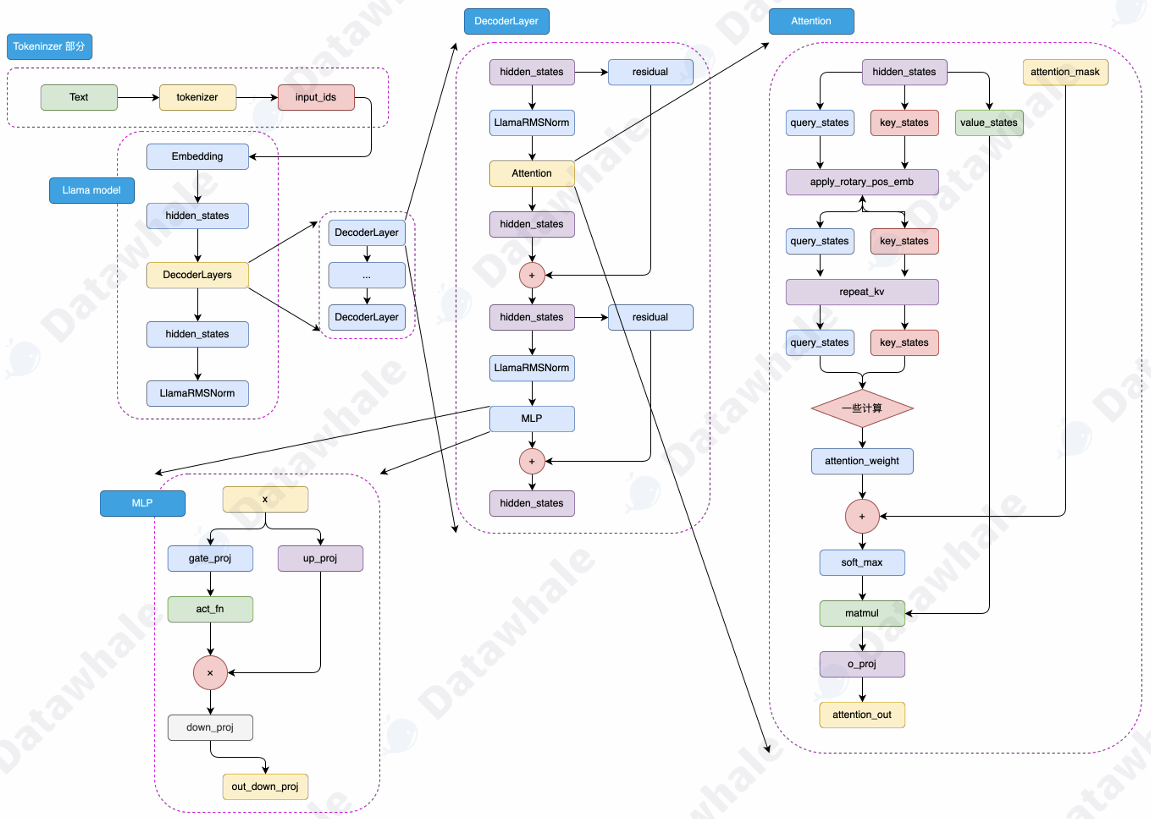
2. LLaMA模型发展历程
2023年1月发布LLaMA-1,这些模型在1T token的语料上进行预训练,因其开源和优异性能成为开源社区最受欢迎的大模型之一。2023年7月发布LLaMA-2,预训练规模扩大到2T,模型上下文长度由2048增大到4096,并且引入了分组查询注意力机制(Grouped-Query Attention,GQA)。2024年4月发布了LLaMA-3,支持8k长文本,并采用了编码效率更高的tokenizer,词表大小高达128k,且使用了超过15T token的预训练预料,规模大增。
三、GLM
GLM 系列模型是由智谱开发的主流中⽂ LLM 之⼀。相比于其他大模型,GLM有三个特点:
- 自编码,随机 MASK 输入中连续跨度的 token
- 自回归,基于自回归空白填充的方法重新构建跨度中的内容
- 2维的编码技术,来表示跨间和跨内信息
GLM 通过添加二维位置编码和允许任意顺序预测空白区域,改进了空白填充预训练,在自然语言理解任务上超越了 BERT 和 T5。GLM 从输入文本中随机挖掉一些连续的词语,然后训练模型按照一定的顺序逐个恢复这些词语。这种方法结合了自编码和自回归两种预训练方式的优点。
实验表明,GLM 在参数量和计算成本相同的情况下,能够在 SuperGLUE 基准测试中显著超越BERT,并且在使用相似规模的语料(158GB)预训练时,能够超越 RoBERTa 和 BART。GLM 还能够在自然语言理解和生成任务上显著超越 T5,而且使用的参数和数据更少。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 43
43 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)