EnerVerse:展望机器人操控的具身未来空间
25年1月来自智元机器人、上海AI实验室、香港中文大学、上海交大、复旦大学、香港科技大学和哈工大的论文“EnerVerse: Envisioning Embodied Future Space for Robotics Manipulation”。EnerVerse,是一个专为机器人操控任务而设计、具身未来空间生成的综合框架。EnerVerse 无缝集成卷积和双向注意机制,用于内部块空间建模,从而
25年1月来自智元机器人、上海AI实验室、香港中文大学、上海交大、复旦大学、香港科技大学和哈工大的论文“EnerVerse: Envisioning Embodied Future Space for Robotics Manipulation”。
EnerVerse,是一个专为机器人操控任务而设计、具身未来空间生成的综合框架。EnerVerse 无缝集成卷积和双向注意机制,用于内部块空间建模,从而确保低层一致性和连续性。认识到视频数据中固有的冗余性,故提出一种稀疏内存上下文(sparse memory context)与逐块单向生成范式(chunkwise unidirectional generative paradigm)相结合的方法,以促进无限长序列的生成。为了进一步增强机器人能力,引入自由锚点视图 (FAV) 空间,它提供灵活的视角,可增强观察和分析能力。FAV 空间减轻运动建模的模糊性,消除密闭环境中的物理限制,并显著提高机器人在各种任务和设置中的泛化和适应性。为了解决获取多摄像头观测值所带来的高昂成本和劳动强度,提出一个数据引擎流水线,将生成模型与 4D Gaussian Splatting (4DGS) 相结合。该流程利用生成模型强大的泛化能力和 4DGS 提供的空间约束,能够迭代增强数据质量和多样性,从而产生数据飞轮效应,有效缩小模拟与现实之间的差距。最后,实验表明,具身未来空间(embodied future space)生成先验,显著增强策略预测能力,从而提高了整体性能,尤其是在远程机器人操控任务中。
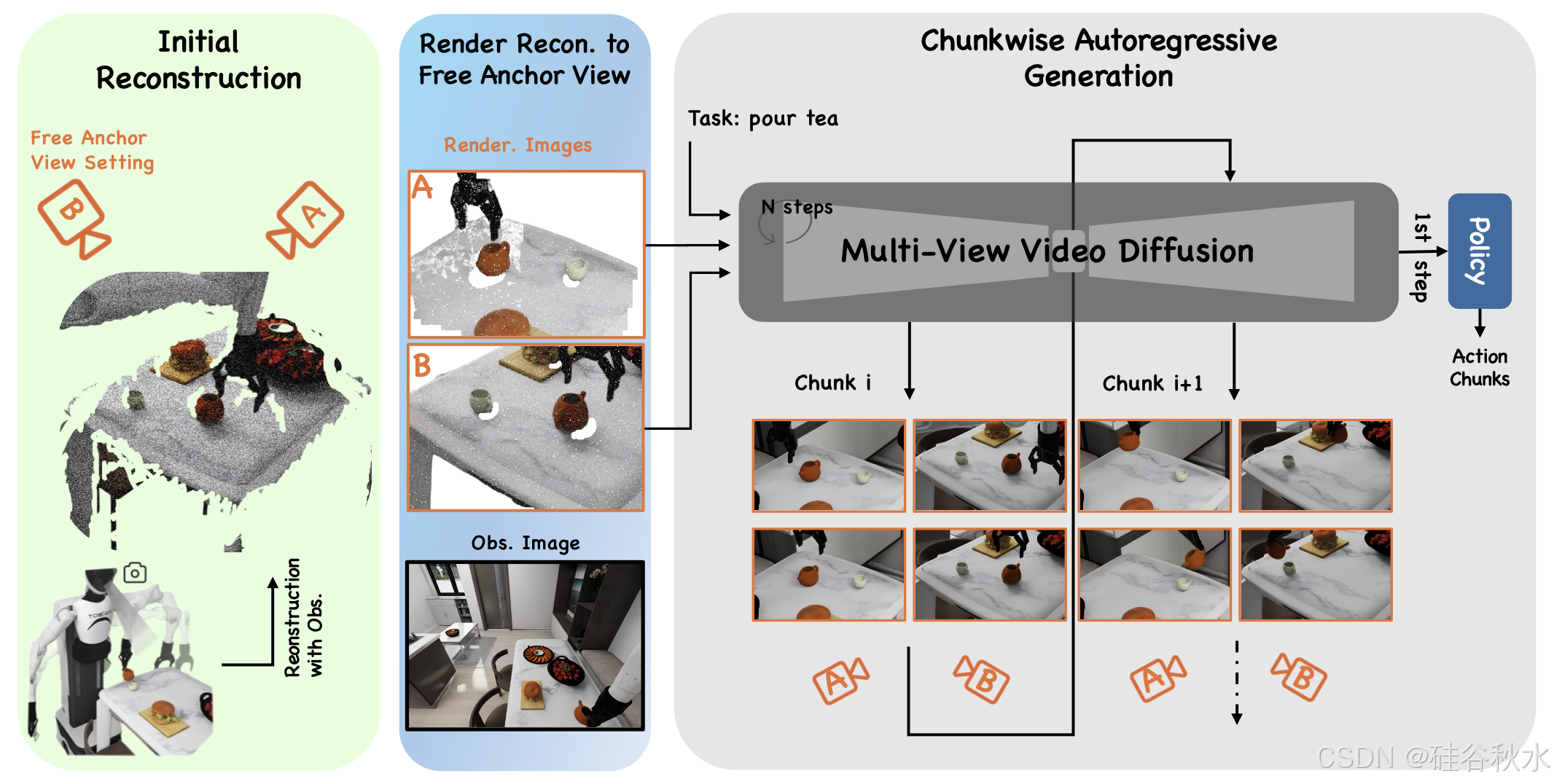
如图所示EnerVerse 模型概述:由三个关键部分组成。首先,初始重建使用安装在机器人上的摄像头的观察图像来构建初始 3D 点云,并将锚点视图设置为适应环境并满足特定于任务的要求。其次,自由锚点视图(FAV)渲染器,从这些锚点视角生成渲染图像,以提供全面的场景表示。最后,逐块自回归生成采用多视图视频扩散,根据任务指令分块生成图像序列。当与策略头集成时,此模块可以生成机器人动作来执行给定的任务。
高容量基础模型在各种模态中都取得显著的成功,包括语言 (Wang 2024b)、图像 (Rombach 2022) 和视频 (Blattmann 2023)。这些模型在大型数据集上进行广泛的预训练,可以针对特定的下游任务进行微调。在机器人技术中,这些基础模型通过利用其预训练功能并适应特定于任务的应用程序,为解决复杂任务提供一个有前途的框架。
这种范式允许机器人根据不同的输入数据处理不同的任务。然而,基于实时观察规划未来行动仍然是机器人技术的一个核心挑战。与语言或视觉领域不同,机器人系统必须实时与物理世界交互,需要精确的动作规划和执行。
这种复杂性来自两个主要挑战:(1) 跨模态的显式对齐:对齐任务指令、观察和动作空间本质上是复杂的。早期的工作(Goyal 2024); (Shridhar 2022) 使用预训练模型进行语言-视觉对齐,并使用复杂算法将其映射到动作。最近,基于 LLM 的方法 (Liang 2023);(Huang 2023, 2024) 已被引入,以使用预训练的视觉模型生成代码策略。尽管简化对齐,但这些方法受到普通语言的表示能力的限制,使其不适合复杂的任务。 (2) 数据稀缺:缺乏大规模的任务-观察-动作数据集,阻碍映射关系的隐性学习。虽然已经引入大规模数据集 (O’Neill 2023);(Khazatsky 2024),但它们的多样性和质量仍然低于语言和视觉领域的数据集。一种方法 (Kim 2024) 试图通过将这些数据集与预训练的 LLM 知识相结合来解决这一限制,但它们需要大量数据,因此是资源密集型。
最近的研究 (Wen 2024); (Rigter 2024); (Cheang 2024); (Guo 2024) ,通过将视频生成与策略规划相结合,利用没有动作标签的大规模视频数据集,取得有希望的结果。然而,(Rigter 2024) 的许多方法只是将通用视频生成模型应用于具身任务,而忽略了机器人固有的独特要求。必须强调的是,视频生成并不等同于生成具身未来空间。机器人任务的特点是具有特定的需求,包括描述任务启动和完成的因果逻辑、实现精确结果的能力以及上下文记忆能力。此外,机器人在现实世界的三维环境中运行,而视频生成仅限于 2D 投影序列,无法充分捕捉具身未来空间的复杂性。因此,视频表示与三维空间动作之间的关系仍然不明确。
对于高信息密度的语言任务,利用单向注意的因果建模范式 (Vaswani 2017);(Achiam 2023) 表现出色。然而,对于以显著信息冗余为特征的视觉任务,确定最佳建模范式仍然是一个尚未解决的研究挑战。与语言任务相比,视觉生成任务通常受益于双向计算机制,例如双向注意和卷积,这些机制已被证明在各个领域都非常有效,包括图像生成 (Chi 2023);(Li 2024b);(Chang 2022)、一般视频生成 (Xing 2025);Ho(2022) 和 3D 生成 (Gao 2024b);(Wu 2024b)。
视频生成模型。基于扩散的视频生成模型近年来取得重大进展 (Blattmann 2023);(Ho 2020);(Song 2020),特别是在文本到视频 (T2V) 生成领域。早期的 T2V 模型(Zhang 2023);(Chen 2023);(Ren 2024);(Zhang 2024) 利用文本到图像 (T2I) 模型建立的强先验,结合在视频数据上训练的时间模块来实现视频生成。例如,AnimateDiff (Guo 2023) 引入一个即插即用的运动模块,可以无缝集成到现有的个性化 T2I 扩散模型中,有效地为静态图像制作动画。同样,DynamicCrafter (Xing 2025) 将文本到视频扩散模型的运动先验调整到图像到视频 (I2V) 设置,通过调节输入静止图像上的噪声来生成动画剪辑。最近的进展 (Kong 2024); (Zheng 2024); (Bao 2024) 探索在去噪过程中用扩散Transformer架构取代传统的 U-Net,这一尝试受到扩散Transformer在图像生成中取得的最新成功的启发 (Peebles & Xie 2023a); (Liu 2024b); (Zhuo 2024)。此外,一些研究 (Gao 2024a) 通过结合因果机制扩展原始视频扩散范式,从而能够生成长序列视频。此外,其他研究 (Hu 2023); (Wang 2023); (Zhao 2024) 将视频生成模型扩展到世界建模领域,可以预测未来状态。
机器人视频预训练。同时开展的工作 GR-2 (Cheang 2024) 引入一种多功能且可推广的机器人操作框架,该框架依赖于使用来自互联网的大量视频进行预训练。GR-2 针对使用机器人轨迹的视频生成和动作预测进行微调。LAPA (Ye 2024) 还利用互联网规模的视频从非机器人动作视频中学习预训练表示。它首先使用 VQ-VAE 学习图像帧之间的离散潜动作,然后预训练潜视觉-语言-动作 (VLA) 模型,以根据观察和任务描述预测这些潜动作。最后,在小规模机器人操作数据集上对 VLA 进行微调,以将潜动作映射到机器人动作。SEER (Tian 2024) 通过加入额外的逆动力学预训练来扩展 LAPA,以进一步提高性能。AVID (Rigter 2024) 利用 DynamicCrafter (Xing 2025) 作为其基础视频生成模型,并使用适配器将原始模型传输到机器人领域。VidMan (Wen 2024) 以 OpenSora(Zheng 2024) 为基础,利用视频扩散模型在动作生成之前的环境预测能力,但仍然局限于 2D 图像空间。
4D 重建和生成。(Chen & Wang 2024) 使用 3D GS (Kerbl 2023) 和 NeRF(Mildenhall 2021) 等技术,从 2D 视频重建动态场景方面取得重大进展。先前的研究通过使用一组 4D 高斯 (Yang 2023) 来近似场景的底层时空 4D 体积来制定这项任务。(Wu 2024a) 提出通过联合优化正则空间中的高斯和变形场来对场景的几何和动态进行建模。 4D 生成领域的最新进展,主要集中在为生成多视角视频的扩散模型设计采样方案 (Li 2024a),主要针对单个动态目标的建模。DimensionX (Sun 2024) 使用多个 LoRA (Hu 2021),每个 LoRA 都是为特定的相机运动设计的,用于生成多视角视频,随后用于 4D 场景重建。同时,Cat4D (Wu 2024b) 使用单个多视角视频扩散模型生成多视角视频,然后将其用于将动态 3D 场景重建为变形的 3D 高斯。
EnerVerse 模型设计有多个专为未来空间生成量身定制的组件,并结合高斯 Splatting (GS) 数据工厂流水线。首先,采用与视频扩散模型集成的逐块自回归策略,通过分析可管理块中的前一个序列并利用视频扩散模型的功能来预测未来帧。其次,提出一种基于自由锚点视图(FAV)的 4D 生成方法,其中每个锚点的射线方向图作为先验知识提供,以促进目标新视图视频的有效生成。最后,实现一个由生成模型和 4DGS 组成的数据引擎流水线,它可以生成具有指定相机姿势的多样化新视图视频序列。然后利用这些生成的视频序列来驱使 Sim2Real 的自适应迁移。
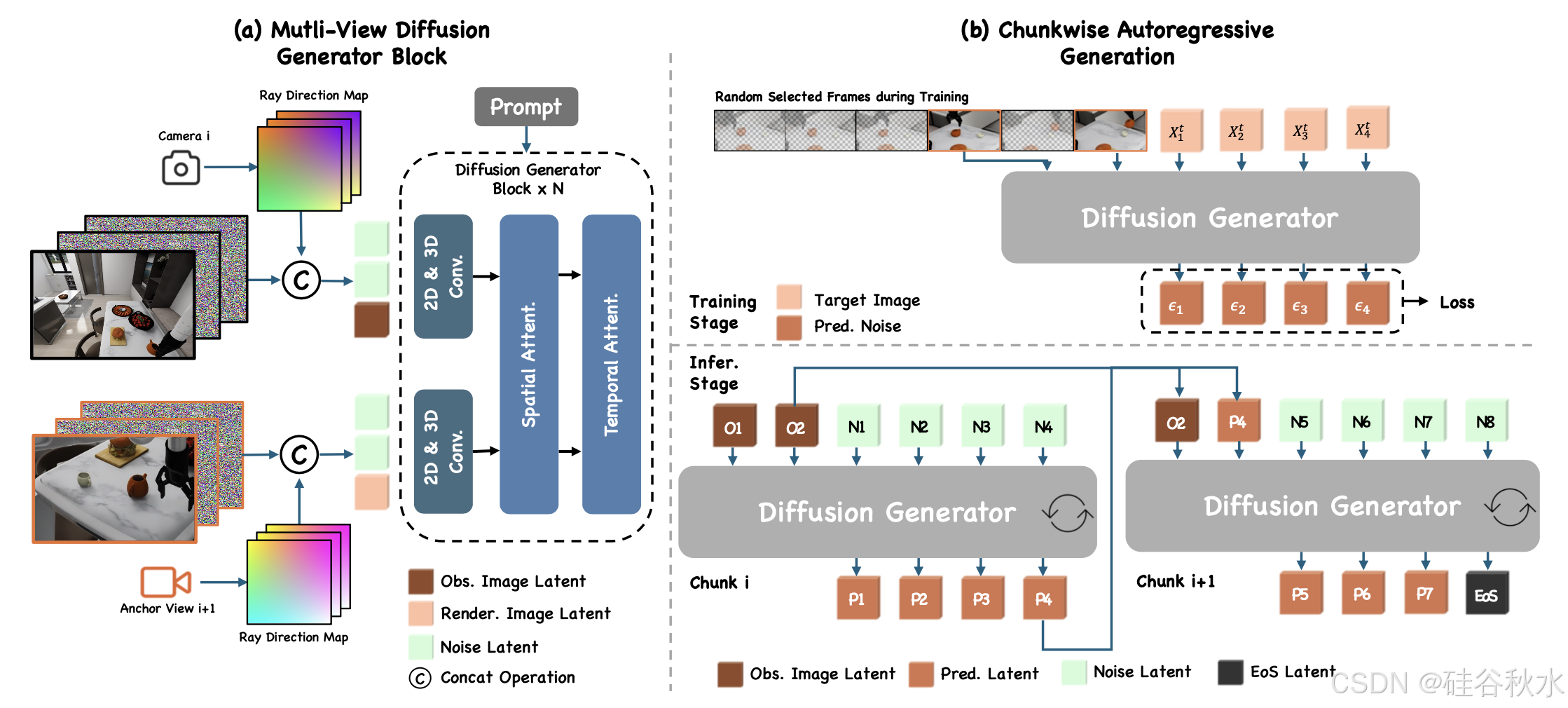
下一个块扩散
如图所示,观察的潜序列表示为 o^1:K = [o^1/0, . . . , o^K/0 ],使用预训练的变分自动编码器 (VAE) 进行编码。其中,K 表示观察的帧数,H × W 表示下采样的空间分辨率,C 表示颜色通道数。类似地,渲染图像的潜表示为 r/0。预测的潜序列表示为 z^1:N/0 = [z1/0,…,zN/0]。目标是开发一个视频扩散模型,该模型根据条件概率分布 pθ(z^1:N/0 | c, o^1:K/0, r/0),根据观察的潜序列、渲染的潜序列和文本输入生成预测的潜序列。这里,c 表示文本条件,θ 是去噪网络的参数,表示为 εθ(z^1:N/t, c, o^1:K/0, r/0, t)。为了保持一致性,将观察的帧和渲染的帧都称为干净帧上下文。去噪网络经过训练,可以从含噪帧目标中预测真值噪声 ε,并以以下目标进行优化:
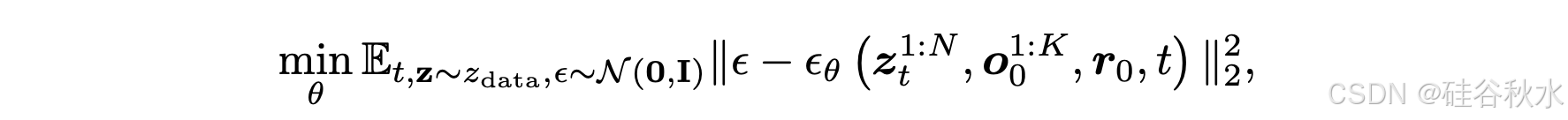
在实践中,根据 (Salimans & Ho 2022) 之前的工作,预测 v 。完成模型训练后,可以通过迭代去噪从随机噪声 z/T 中得出去噪数据 z/0。
在推理过程中,干净帧与含噪帧相结合,输入到扩散生成器中以产生 N 个含噪帧。然后将最近生成的帧用作下一次推理迭代的新干净帧。此迭代过程持续到检测预定义的序列结束 (EOS) 帧。由于扩散生成是在连续的潜表示帧上运行的,因此在推理过程中计算每个帧的生成结果及其与 EOS 的 L1 距离。应用预定义阈值来确定何时终止该过程。在实践中,这种基于阈值的检测 EOS 的方法已被证明是高度准确的。
上下文帧机制。提出一种替代方法,即使用稀疏采样帧作为干净帧,而不是在训练期间使用连续帧作为块预测(chunk prediction)的干净帧上下文传统方法。对于通常包含大量冗余信息的视频数据,该方法可以丢弃大约 80% 的帧,同时仍保留足够的信息进行有效训练。此外,以高比率丢弃帧可以提高模型的鲁棒性,使其能够更好地处理分布不均 (OOD) 场景,特别是机器人学习领域中常见的协变漂移(covariant shift)问题。总体而言,从表示学习的角度来看,这种随机选择策略鼓励更全面地理解块预测,与依赖连续帧的方法相比,可能会带来更好的结果。
在推理过程中,从观察的或渲染的帧中获得干净帧,并使用滑动窗方法进行去噪。此方法可确保从观察帧到生成帧的无缝过渡,同时提高推理效率并减少 GPU 内存使用量。
4D 生成
单视图视频生成方法在解决遮挡方面面临巨大挑战,遮挡是机器人操作任务中常见且不可避免的问题 (Huang 2024)。以前的方法通常采用单一的自上而下视角,例如鸟瞰图 (BEV)。然而,由于 3D 环境中遮挡关系的复杂性,这种设置不足以完成操作任务。同样,固定的多锚点视图表示也受到环境的过度限制。例如,在厨房等狭窄而密闭的空间中,固定的摄像机位置可能在物理上不可行,预装的高架摄像机可能会与墙壁或其他障碍物相交。
相比之下,自由多视图视频生成提供了一种更实用、更灵活的替代方案。通过使生成模型能够专注于目标的物理属性(例如它们的形状和位置),这种方法增强目标级推理,这对于需要精确建模物理交互的操作任务尤其重要。另一种常见的观察设置涉及相对运动,例如安装在机器人手腕上的摄像机。然而,这种设置将环境动态与机器人自身的运动相结合,从而引入缺点,使策略学习变得复杂。
自由锚点视图视频生成流水线。如上图所示,该方法的目标是直接生成多视图潜在值,表示为 z^1:N/0,V 表示视图数。在多摄像机或多视图设置中,每个摄像机固有地捕捉同一场景的不同视角。如果不明确考虑这些不同的视角,模型可能难以产生一致的输出。为了解决这个问题,通过沿通道维度附加射线方向图来增强初始图像 E/init 的嵌入。射线方向图对观察视图信息进行编码,包括内外摄像机参数。通过射线投射,生成过程变得具有视图-觉察能力,依赖摄像机参数调节模型。这使模型能够反映每个锚点视图的独特视角,同时捕获 3D 空间关系和遮挡属性——这对于操作任务至关重要。此外,将原有的二维空间注意机制扩展为三维跨视图注意机制,进一步增强模型的三维空间感知能力。此方法可确保不同视图之间的一致性和连贯性,同时保留场景中目标之间的几何关系。通过利用自由锚点视图表示,该流程可有效解决遮挡问题,增强空间推理能力,并无缝适应复杂的三维环境。
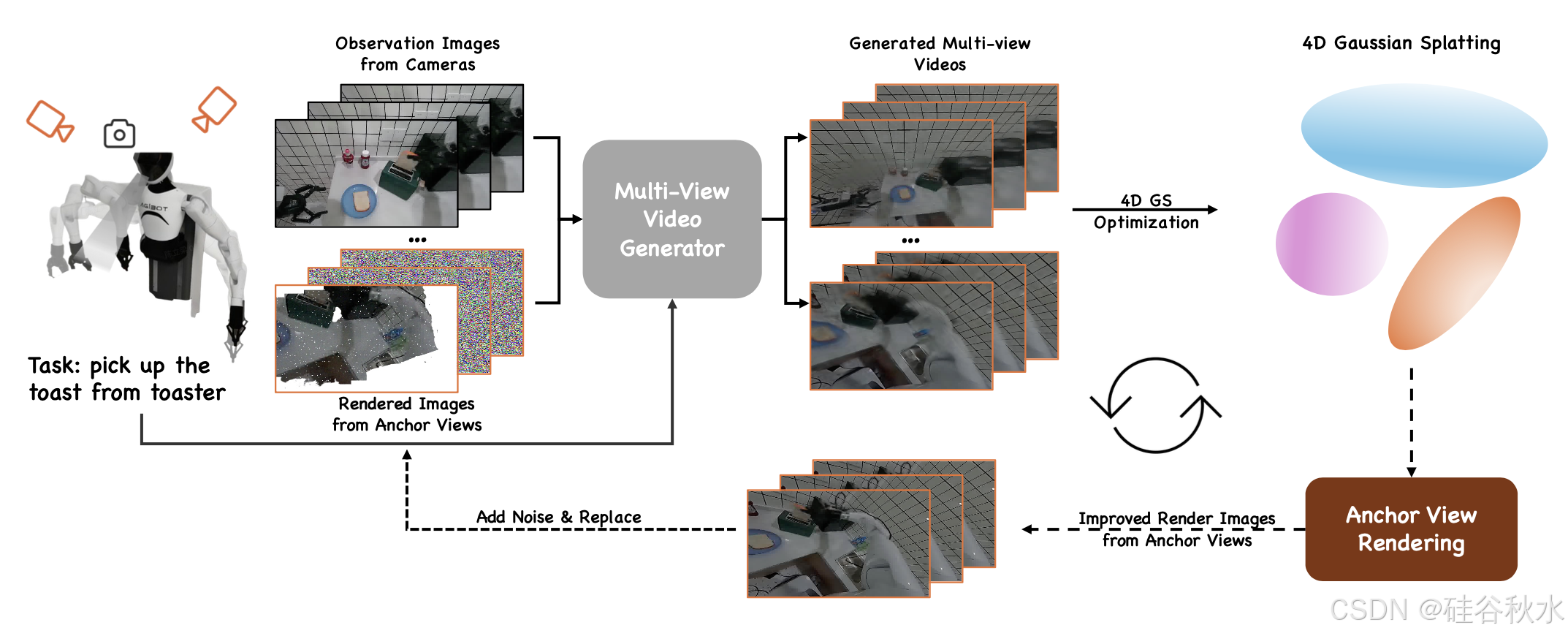
带 EnerVerse 和 4DGS 的现实世界数据飞轮。在现实世界中获取经过精心标定的多摄像机观测数据既昂贵又耗费人力。因此,主要依赖来自模拟器的数据。然而,来自模拟环境或学术基准的视频数据,在应用于现实世界场景时往往会出现域差距。这些差距通常表现为视觉外观、尺度感知和度量精度方面的差异,从而阻碍了直接应用。为了应对这些挑战,提出一种数据生成引擎流水线,利用稀疏或孤立的观测来生成给定场景的多视角视图。通过利用高斯 Splatting 从这些多视角观测中进行 4D 重建,确保几何和光学一致性,从而提高不同视点之间的对齐和连贯性。
EnerVerse 模型是一种数据引擎,采用多阶段流程来增强视频生成和重建,如图所示。最初,用来自模拟器的数据训练一个基础模型 EnerVerse。然后,该模型被微调为 EnerVerse-D,以完整的离线观察序列为条件,其中从多个安装的摄像头捕获清晰、无噪音的视频。这些视频包括机械臂运动和场景动态,确保各个视图之间的运动一致性。随后,这些多视图视频用于通过高斯 splatting 构建 4D 高斯表示。完成 3D 场景重建后,从锚视图渲染内容以获得更高精度的观测值。渲染后的观测值经过去噪和几何一致性处理,使用 EnerVerse-D 进行迭代细化以生成伪真值。在使用数据引擎收集足够的现实世界多视图视频数据后,用这些数据进一步微调多视图视频生成器。这个迭代过程降低噪声,提高重建质量,并促进 Sim2Real 域自适应迁移,最终产生训练 4D 生成模型所必需的大规模高质量视频数据集。
应用
策略头。除了视频生成之外,还将策略头集成到扩散生成器网络中,从而能够在经过大量未来空间生成预训练后同时生成视频和相应的动作。具体来说,按照 (Chi 2023) 中的架构设计策略头,采用多个Transformer块的堆栈。作为条件的策略头输入潜向量,是从扩散生成器的中间层提取的。与视频生成过程不同,视频生成过程中采用多个去噪步骤来提高生成质量,仅使用噪声最大的步骤,即第一个去噪步后的特征向量。这种设计显著提高动作输出的速度,满足机器人控制的频率要求。值得注意的是,在策略预测过程中,稀疏内存,存储在多视图设置下观察的或重建的 FAV 的视觉图像,而不是依赖于生成的信息(如图所示)。

此外,在第一步动作预测过程中,尽管策略模型明确地仅依赖于历史观察数据,但对未来空间生成的大量预训练可确保隐式嵌入有关未来空间动态的信息。这使模型能够以前瞻性的视角规划动作,与设想未来空间的总体目标保持一致。此外,动作以块的形式进行预测,允许模型同时生成多个未来动作步骤。这种基于块的预测方法进一步提高了效率,使其非常适合实时机器人控制任务。
训练数据。选择几个具有明确任务逻辑的公开数据集,包括 RT-1 (Brohan 2022)、Taco-Play (Rosete-Beas 2022)、ManiSkill (Gu 2023)、BridgeV1 (Walke 2023)、LanguageTable (Lynch 2023)和 RoboTurk (Mandlekar 2019),用于预训练。在此预训练阶段,仅使用视频帧进行视频生成训练。此外,用 Isaac Sim 模拟器 (Mittal 2023)构建一个包含多锚点视图视频基本事实的数据集。FAV 生成模型是通过利用从单视图视频生成模型中得出的权重进行训练的。对于策略规划任务,使用来自特定场景有限数量的演示数据进行微调足以获得最先进的性能。为了缓解使用异构数据进行训练时遇到的域差距,采用受 (Wang 2024a) 启发的域嵌入。具体来说,为每个子数据集分配不同的域嵌入。在后续的空间生成和策略规划中,这些嵌入在输入到扩散模型之前与扩散时间步嵌入集成。这种方法有效地缓解因实体、任务类型和视觉风格差异而引起的冲突。
训练细节。模型是基于基于 UNet 的 VDM (Xing 2025) 进行的,并且可以轻松适应 DiT (Peebles & Xie 2023b) 架构。在生成具身未来空间的实验中,块大小会显著影响模型性能。使用块大小 1、4、8 和 16 的比较分析表明,当使用块大小 8 时,该模型表现出最佳的鲁棒性。按照 (Bruce 2024) 中概述的方法,在记忆上下文中的帧中引入破坏性噪声。为了减轻自回归生成的退化,这种噪声的强度以余弦相关的方式相对于与当前时刻的距离进行调节。在策略预测实验中,动作头采用扩散策略 DP 架构 (Chi 2023),总共有 190M 个参数。对于 DP 头的情况,在第一个去噪步骤中利用 UNet 中间块之前的特征,并计算空间维度上的平均值,最终形状为 T × C,其中 T 是视频长度,C 是中间块之前的通道数。渲染的 FAV 图像具有 512 × 320 的图像大小,动作头预测增量姿势。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献215条内容
已为社区贡献215条内容

所有评论(0)