大模型学习(一)通义千问1.8B大模型微调
本人双非硕,硕士课题研究机械臂抓取相关的工作,秋招两个半月,投递简历500+,笔试测评若干,面试10+,到手小厂视觉算法岗offer一个。奈何算法太吃bg了,准备转大模型开发,这个专栏用于记录我的大模型学习记录。,老师讲的很不错!
感谢B站UP的教程大模型系列,老师讲的很不错!
环境配置
当前使用的环境为:Python3.10 torch2.4.2 modelscope1.13.0 transformers4.57.1 vllm0.6.0 CUDA12.1
显卡使用RTX 3090
下载模型
我是使用国内的魔搭社区下载Qwen1.8B的量化模型,下载速度比较快:
from modelscope import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer
model_dir = snapshot_download('qwen/Qwen-1_8B-Chat-Int4', cache_dir="./Models")
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto",
trust_remote_code=True
).eval()
这段代码中,指定下载的模型是“qwen/Qwen-1_8B-Chat-Int4”,下载到指定目录“./Models”中。
tips:模型量化是一种模型压缩和加速技术,通过将模型中的高精度数值(通常是32位浮点数,FP32)转换为低精度表示(如8位整数,INT8,或更低的位数),来减少模型的存储需求、计算量和推理延迟,同时尽量保持模型的精度。例如本实验使用的就是Int 4量化模型。量化具体介绍可以看博客。挖个坑,后面补一下量化的实验。
下载好的文件内容如下: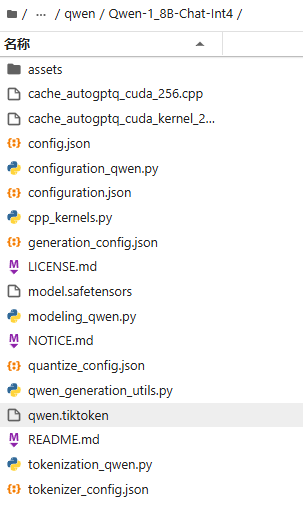
assets/:存放模型运行所需的资源文件,如 CUDA 自定义算子等二进制依赖。
cache_autogpt_cuda_256.cpp 和 cache_autogpt_cuda_kernel_2…:用于 GPU 加速的 C++/CUDA 内核源码,优化 INT4 量化模型在显卡上的推理性能。
configuration_qwen.py:定义 Qwen 模型的 Python 配置类,包含模型结构参数。
config.json:以 JSON 格式存储模型的核心配置信息,如层数、隐藏维度等。
cpp_kernels.py:Python 接口文件,用于加载和调用上述 CUDA 内核。
generation_config.json:指定文本生成时的默认参数,如最大长度、温度、top_p 等。
LICENSE.md:模型的开源许可证文件,说明使用条款。
model.safetensors:模型权重文件,采用安全高效的 safetensors 格式存储(替代传统的 .bin)。
modeling_qwen.py:Qwen 模型的主实现代码,包含前向传播逻辑和网络结构。
NOTICE.md:法律或技术声明文件,通常包含版权、第三方依赖等信息。
qwen_generation_utils.py:提供文本生成相关的工具函数,如采样、停止条件判断等。
qwen.tokenized:分词器使用的词汇表或缓存文件,辅助快速分词。
quantize_config.json:记录模型的量化配置,如量化位宽(INT4)、算法类型(如 GPTQ)等。
README.md:模型的使用说明文档,包含简介、安装、示例等信息。
tokenization_qwen.py:Qwen 分词器的实现代码,负责文本与 token ID 之间的转换。
tokenizer_config.json:分词器的配置文件,定义特殊 token、填充策略等参数。
挖个坑,后面逐一解读这些文件
提示词工程
# 城市数据
with open('city.txt','r',encoding='utf-8') as fp:
city_list=fp.readlines()
city_list=[line.strip().split(' ')[1] for line in city_list]
首先读取city.txt文件,文件内容如下:
strip()是一个字符串方法,会跳过字符串前后的空格、\tab、\n等,例如" Hello, World! \n"经过处理后成为"Hello, World!"。最终得到的city_list格式如下:
接下来进行提示词生成,首先定义一个提示词模版:
prompt_template='''
给定一句话:“%s”,请你按步骤要求工作。
步骤1:识别这句话中的城市和日期共2个信息
步骤2:根据城市和日期信息,生成JSON字符串,格式为{"city":城市,"date":日期}
请问,这个JSON字符串是:
'''
接下来我们可以往提示词模板里面的%s填充内容:
Q='青岛4月6日下雨么?'
prompt_template%(Q,)
得到的结果如下:
接下来我们需要调用大模型生成微调数据,在此之前需要先了解通义千问数据集的格式:
Qwen的SFT数据格式要求:
[
{
"id": "identity_0",
"conversations": [
{
"from": "user",
"value": "你好"
},
{
"from": "assistant",
"value": "我是一个语言模型,我叫通义千问。"
}
]
}
]
tips:
必须交替出现:对话必须严格按 user → assistant → user → assistant → … 的顺序。
必须以 user 开头:每段对话应由用户发起。
不能连续两个 user 或两个 assistant:这会被视为格式错误。
每轮对话是一个独立对象:包含 “from” 和 “value” 两个字段。
接下来生成微调数据集:
import random
import json
import time
train_data=[]
Q_list=[
('{city}{year}年{month}月{day}日的天气','%Y-%m-%d'),
('{city}{year}年{month}月{day}号的天气','%Y-%m-%d'),
('{city}{month}月{day}日的天气','%m-%d'),
('{city}{month}月{day}号的天气','%m-%d'),
('{year}年{month}月{day}日{city}的天气','%Y-%m-%d'),
('{year}年{month}月{day}号{city}的天气','%Y-%m-%d'),
('{month}月{day}日{city}的天气','%m-%d'),
('{month}月{day}号{city}的天气','%m-%d'),
('你们{year}年{month}月{day}日去{city}玩吗?','%Y-%m-%d'),
('你们{year}年{month}月{day}号去{city}玩么?','%Y-%m-%d'),
('你们{month}月{day}日去{city}玩吗?','%m-%d'),
('你们{month}月{day}号去{city}玩吗?','%m-%d'),
]
# 生成一批"1月2号"、"1月2日"、"2023年1月2号", "2023年1月2日", "2023-02-02", "03-02"之类的话术, 教会它做日期转换
for i in range(1000):
Q=Q_list[random.randint(0,len(Q_list)-1)]
city=city_list[random.randint(0,len(city_list)-1)]
year=random.randint(1990,2025)
month=random.randint(1,12)
day=random.randint(1,28)
time_str='{}-{}-{}'.format(year,month,day)
date_field=time.strftime(Q[1],time.strptime(time_str,'%Y-%m-%d'))
Q=Q[0].format(city=city,year=year,month=month,day=day) # 问题
A=json.dumps({'city':city,'date':date_field},ensure_ascii=False) # 回答
example={
'id': 'identity_{}'.format(i),
'conversations':[
{
'from': 'user',
'value': prompt_template%(Q,),
},
{
'from': 'assistant',
'value': A,
}
]
}
train_data.append(example)
with open('train.txt','w',encoding='utf-8') as fp:
fp.write(json.dumps(train_data))
print("样本数量:",len(train_data))
解析json格式的数据集格式如下:
微调模型
接下来微调模型,生成到output_qwen。Qwen1.8B提供了多种微调方法: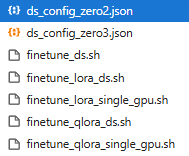
ds_config_zero3.json:DeepSpeed ZeRO-3 分布式训练的配置文件,用于多卡高效训练。finetune_ds.sh:使用 DeepSpeed 启动全参数分布式微调的训练脚本。finetune_lora_single_gpu.sh:在单张 GPU 上使用 LoRA 进行参数高效微调的脚本。finetune_qlora_single_gpu.sh:在单张 GPU 上结合 4-bit 量化与 LoRA(即 QLoRA)进行超低显存微调的脚本。finetune_lora_multi_gpu.sh:在多张 GPU 上使用 LoRA 进行并行微调的脚本。finetune_qlora_multi_gpu.sh:在多张 GPU 上使用 QLoRA(量化 + LoRA)进行并行微调的脚本。
这里我们使用量化的微调脚本finetune_qlora_single_gpu.sh,代码如下:
python finetune.py \
--model_name_or_path $MODEL \
--data_path $DATA \
--fp16 True \
--output_dir output_qwen \
--num_train_epochs 10 \
--per_device_train_batch_size 5 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 1000 \
--save_total_limit 10 \
--learning_rate 3e-4 \
--weight_decay 0.1 \
--adam_beta2 0.95 \
--warmup_ratio 0.01 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--report_to "none" \
--model_max_length 512 \
--lazy_preprocess True \
--gradient_checkpointing \
--use_lora \
--q_lora \
# --deepspeed finetune/ds_config_zero2.json 不使用分布式训练,所以注释
以下是每个参数的解释:
-
--model_name_or_path $MODEL:指定预训练模型的路径或 Hugging Face 模型 ID,用于加载基础模型权重。 -
--data_path $DATA:指定训练数据文件或目录的路径,通常为 JSON 或 JSONL 格式的指令微调数据集。 -
--fp16 True:启用半精度浮点数(FP16)训练,减少显存占用并加速计算(需 GPU 支持)。 -
--output_dir output_qwen:设置模型训练过程中检查点和最终结果的保存目录。 -
--num_train_epochs 10:指定整个训练数据集将被遍历训练 10 轮。 -
--per_device_train_batch_size 5:每个 GPU 设备在训练时每次处理 5 个样本。 -
--per_device_eval_batch_size 1:每个 GPU 设备在评估时每次处理 1 个样本(通常因显存限制设得较小)。 -
--gradient_accumulation_steps 8:每 8 个 mini-batch 累积一次梯度再更新,等效于增大 batch size。 -
--evaluation_strategy "no":训练过程中不进行验证评估。 -
--save_strategy "steps":按训练步数(而非 epoch)保存模型检查点。 -
--save_steps 1000:每训练 1000 步保存一次模型。 -
--save_total_limit 10:最多保留最近的 10 个检查点,避免磁盘爆满。 -
--learning_rate 3e-4:优化器的学习率设为 0.0003,控制参数更新幅度。 -
--weight_decay 0.1:L2 正则化系数为 0.1,用于防止过拟合。 -
--adam_beta2 0.95:Adam 优化器的 β2 参数,控制梯度平方的指数衰减率。 -
--warmup_ratio 0.01:学习率预热比例,前 1% 的训练步数中线性增加学习率。 -
--lr_scheduler_type "cosine":使用余弦退火学习率调度策略,平滑降低学习率。 -
--logging_steps 1:每 1 步就在日志中记录训练指标(如 loss)。 -
--report_to "none":不将训练日志上报到任何外部平台(如 TensorBoard、W&B)。 -
--model_max_length 512:设定模型输入序列的最大长度为 512 个 token,超长部分会被截断。 -
--lazy_preprocess True:启用懒加载预处理,仅在需要时对数据进行 tokenize,节省内存。 -
--gradient_checkpointing:启用梯度检查点技术,用时间换空间,显著降低显存占用。 -
--use_lora:启用 LoRA(低秩适配)微调,只训练少量新增参数,冻结原始模型权重。 -
--q_lora:启用 QLoRA,在 4-bit 量化模型基础上应用 LoRA,实现极低显存微调。 -
# --deepspeed ...:注释掉的 DeepSpeed 配置,表示当前不使用分布式训练框架。
接下来指定模型和数据集进行微调:
bash finetune/finetune_qlora_single_gpu.sh -m /root/shared-nvme/LLM-Learning/Qwen-SFT/Models/qwen/Qwen-1_8B-Chat-Int4 -d ../train.txt
该命令使用 QLoRA(量化低秩适应)方法对 Qwen-1.8B-Chat-Int4 模型进行微调,训练数据来自指定的文本文件,微调结果将保存到 output_qwen 目录。
训练结束过程如下: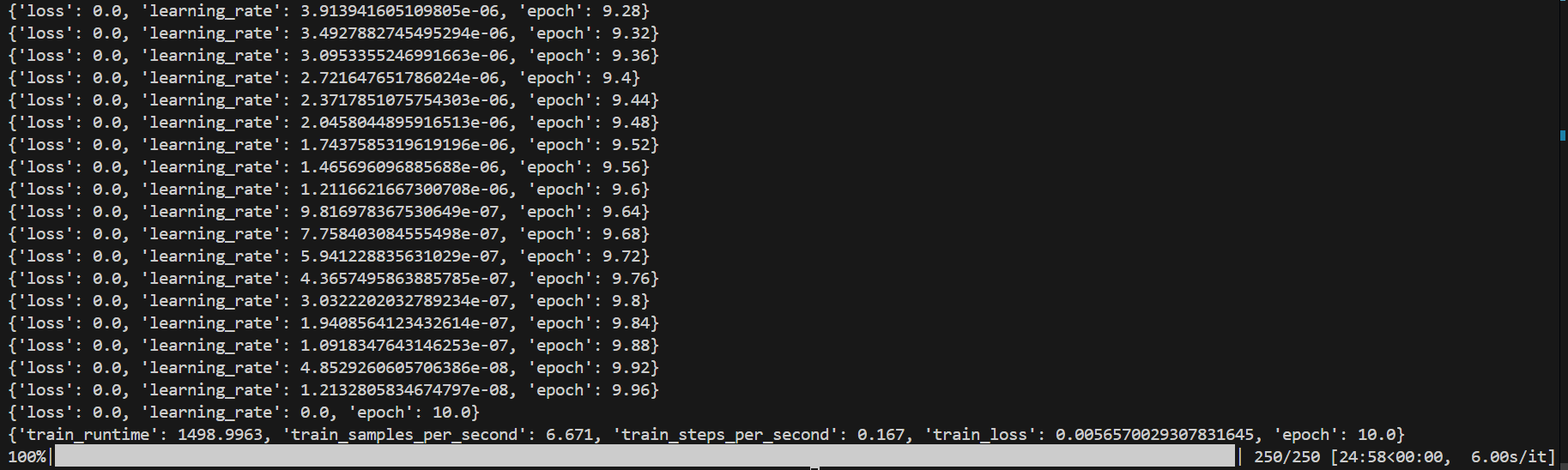
保存后的模型结构如下: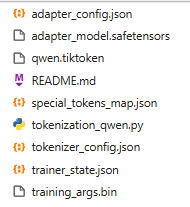
微调结束后保存的模型目录中各个文件的详细解释:
-
adapter_config.json:记录 LoRA 微调的配置信息,包括 LoRA 的秩(rank)、alpha、dropout 等参数,用于在推理时正确加载和应用适配器权重。 -
qwen_model.safetensors:存储原始 Qwen 模型的主权重文件,采用 safetensors 格式,安全高效,包含冻结的原始模型参数,通常不被修改。 -
qwen.tokenized:分词器使用的词汇表或 token 映射文件,用于将文本转换为 token ID,是分词过程的基础数据。 -
README.md:模型说明文档,包含模型简介、微调方法、使用说明、依赖项等信息,方便他人理解和复现。 -
special_tokens_map.json:定义特殊 token(如[PAD],[CLS],[SEP]等)的映射关系,确保分词器能正确处理这些标记。 -
tokenization_qwen.py:Qwen 分词器的 Python 实现代码,负责文本与 token ID 之间的转换逻辑。 -
tokenizer_config.json:分词器的配置文件,包含分词器类型、最大长度、特殊 token 设置等参数。 -
trainer_state.json:训练器状态文件,记录训练过程中的步数、学习率、epoch 进度等元信息,可用于恢复训练。 -
training_args.bin: 训练参数的二进制文件,保存了训练时的所有超参数(如 batch size、learning rate 等),由 Hugging Face Trainer 自动生成。
加载SFT后的模型
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained(
'./Qwen/output_qwen', # path to the output directory
device_map="auto",
trust_remote_code=True
).eval()
tips:这里加载模型使用 AutoPeftModelForCausalLM(而不是普通的 AutoModelForCausalLM)来加载模型,是因为你微调时使用了 PEFT(Parameter-Efficient Fine-Tuning)技术,比如 LoRA 或 QLoRA。
经过10个epoch后的训练,效果非常可以了:
同样的,模型也不会只回答这种格式的内容: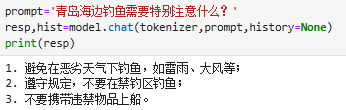

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)