NLP自然语言处理初始以及基于Word2Vec的静态训练词向量方法和词向量的应用
NLP初识
一、分词
1、英文分词
按照分词粒度大小:
词级就是按单词分,但是实际应用中容易出现OOV问题out of vocabulary,包括网络热词、专有名
词、复合词比如chatgpt,模型无法识别这些词,通常会把这些替换为特殊标记如<UNK>,从而导
致语义丢失,影响模型预测。
字符级就是按字母分,覆盖率极高,词表小,很难出现OOV问题,但是单个字符信息极弱,模型
必须依赖上下文推断语义,增加建模难度和训练成本。
子词级是一种介于前两者之间的一种分词方法,把词语切分成更小的单元,例如词根、前后缀或常
见词片段等,常见的子词级分词算法包括BPE,WorldPiece和Unigram Language Model,其中
BPE最广泛,原理是先做一个字符级分词,再合并,统计字符对的频率,添加到词表里。
2、中文分词
字符级分词就是按汉字分,中文的字符级更加友好,语义友好
词级分词,切分结果贴近阅读习惯
子词级分词,先切成单字,再看字符对的频率
3、分词工具
基于词典或模型,以词为单位切分,jieba,HanLP,
基于子词建模算法如BPE,自动学习高频字组合,构建词表,hugging face tokenizer,
sentencepiece,tiktoken等
jieba分词器
pip install jieba精确模式(fault) .cut<generator> .lcut<list>
<generator>要遍历输出
import jieba
text = '小明毕业于北京大学计算机系'
words_generator = jieba.lcut(text)
print(words_generator)
#result:['小明', '毕业', '于', '北京大学', '计算机系']全模式cut_all = True,输出如下:
['小', '明', '毕业', '于', '北京', '北京大学', '大学', '计算', '计算机', '计算机系', '算机', '系']
搜索引擎模式.cut_for_search
自定义词典 load_userdict(' dict.txt '),add_word(word,freq = None, tag = None),del_word(word)
二、词向量
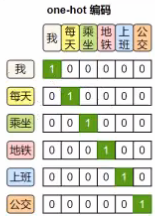
one-hot独热简单但是无法表示语义
CBOW(Continuous Bag-of-Words)连续词袋模型,知道前后文预测中间词
Skip-gram模型,知道中间预测前后词 ,输入层是词语的独热编码,输出层是词表每个词的概率
SGNS(Skip-gram with Negative Sampling)可以理解成:SGNS 是 Skip-gram 的加速版 + 负样
本训练策略
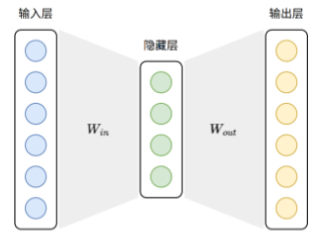
Word2Vec原理:利用大规模原始文本作为数据源,从中自动构造训练样本,由于两种模型的输入
输出都是词语,因此首先需要对原始文本进行分词,将连续文本转换为token序列,此外,模型无
法直接处理文本符号,训练时仍需将词语转换为 one-hot 编码,以便作为模型的输入和输出进行计
算。
1、获取Word2Vec词向量
注意了W2V这个方式获得的词向量是static的,不会根据上下文的变化来改变词向量的内容,所以
这个只是一个经典的方式
pip install gensim1)使用公开的中文词向量,可从 https://github.com/Embedding/Chinese-Word-Vectors 下载,其提
供了基于多个数据集训练得到的词向量。

我们这里用sgns的词向量库来演示
from gensim.models import KeyedVectors
model_path = 'data/sgns.weibo.word(1)/sgns.weibo.word(1)'
model = KeyedVectors.load_word2vec_format(model_path)
print(model.key_to_index)vector = model['地铁']
print(vector)
print(vector.shape)这里可以直接通过输入词语来查找词向量
2、计算向量的相似度
1)比对两个词similarity
model.similarity 计算的是两个词向量的余弦相似度
print(model.similarity('地铁','公交'))
#result:0.654582142)找出与目标词相似/不相似的词most_similar(),positive是相似negative是不相似,topn是要输出的个数,我们传相似不相似的时候要上传列表,后面这些数字是相似度
similar_words = model.most_similar(negative = ['地铁'], topn = 5)
print(similar_words)
#result:[('穆', 0.07467251271009445), ('长青', 0.06398050487041473), ('干白', 0.061115290969610214), ('挚', 0.06012710556387901), ('功劳', 0.05630827695131302)]案例:对比填词,
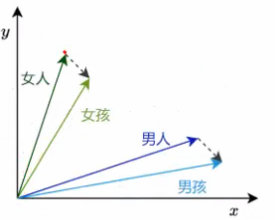
result = model.most_similar(positive = ('男人','女孩'),negative = ('女人'),topn = 1)
print(result)
#result:[('男孩', 0.5668050050735474)]3、自行训练词向量
Word2Vec 是训练词向量的模型
KeyedVectors 是存储和操作已训练词向量的工具类
这个前面的token是新加的,目的是为了去掉空的字符
import pandas as pd
import jieba
from gensim.models import Word2Vec, KeyedVectors
df = pd.read_csv('data/online_shopping_10_cats.csv').dropna()
sentences = [ [token for token in jieba.lcut(sentence) if token.strip() != ''] for sentence in df['review']]
model = Word2Vec(
sentences = sentences, #已分词的句子序列
window = 5,#上下文窗口大小
sg = 1, #1表示skip-gram,0表示cbow
vector_size = 100, #词向量维度
min_count = 5, #最小词频
workers = 5, #并行训练线程数
)
model_path = 'data/review.txt'
model.wv.save_word2vec_format(model_path)
kv_model = KeyedVectors.load_word2vec_format(model_path)
print(kv_model)
#result:KeyedVectors<vector_size=100, 17018 keys>print(kv_model.similarity('地铁','公交'))
0.852923print(kv_model['地铁'])
[ 0.19500694 -0.03965044 0.1324852 0.10620299 -0.4235677 -0.7651219
0.35803005 -0.03432196 -0.3441585 0.01472531 -0.02551124 -0.1966812
0.50005436 0.11777816 0.26972964 -0.39212835 0.1059521 -0.8275402
0.09232639 -0.17036419 0.23938079 -0.6067029 0.16755275 0.18860516
-0.22056982 0.09086072 0.12811464 -0.08946093 0.23552182 -0.35849762
0.5508271 0.44139338 -0.01307059 -0.40379706 0.23712929 -0.32623547
0.11192365 -0.02663203 0.17870496 -0.6673017 -0.584636 0.43865106
-0.37505236 0.01376642 0.37338766 -0.5476329 -0.11379293 0.48873746
0.2114909 0.19136614 0.3628646 0.15822539 -0.12155686 0.09103846
0.09672575 -0.18193625 0.37623656 -0.05954948 -0.37473536 0.05388224
0.33835897 0.92868674 0.02416807 -0.23636033 0.06309167 0.09657489
0.07441811 0.30667982 -0.2695101 0.54302526 0.1245986 -0.15983255
0.40304184 0.24169847 0.40091097 -0.07505183 -0.12165613 0.20424005
-0.2171529 -0.5317836 0.43617678 0.02835425 0.07248473 0.10208542
-0.21886182 -0.35131636 -0.22335248 0.48000592 0.35729057 0.03773176
0.34011748 0.22837088 -0.03961422 0.20944718 0.34765387 0.20317239
0.08094657 -0.02142851 0.84808177 -0.46067324]4、词向量应用
在现代深度学习NLP模型中,大多数任务的输入第一层都是嵌入层。本质上嵌入层是一个查找表
(lookup table),这个嵌入层是要给他训好的词向量的,但是不给也可以,就是要用自己的模型
先做一个初始化然后再训。
随机初始化:略
使用预训练词向量初始化:这个意思就是我们传入已经训练好的词向量,比如上面用w2v训练好的
词向量作为初始值,这样我们用当前模型训练的时候,就不用从0开始训练了,他就已经有一些懂
词的基础了,降低了训练难度,这种方法在低资源任务中优势明显。
embedding = nn.Embedding(vocab_size, vector_dim)这个代码的意思是:embedding变量是一个词嵌入矩阵,这个矩阵的shape是(vocab_size,
vector_dim),这个是基于随机生成的。
import torch
import torch.nn as nn
from gensim.models import KeyedVectors
wv_model = KeyedVectors.load_word2vec_format('data/review.txt')
vector_dim = wv_model.vector_size # 词表维度
word2id = wv_model.key_to_index
vocab_size = len(word2id) # 词表大小
embedding_matrix = torch.zeros(vocab_size, vector_dim)
for word, id in word2id.items():
embedding_matrix[id] = torch.tensor(wv_model[word])
print(embedding_matrix.shape)完整代码如下,并解决了OOV问题
这里是加了oov词汇的<unk>,其实word2id就是一个字典,id2word就是一个列表,我们unkword
默认加到列表的首位,word2id跟着枚举一下
import torch
import torch.nn as nn
import jieba
from gensim.models import KeyedVectors
wv_model = KeyedVectors.load_word2vec_format('data/word2vec.kv')
vector_dim = wv_model.vector_size
print(vector_dim)
unk_token = '<unk>'
id2word = [unk_token] + wv_model.index_to_key
word2id = {word : id for id, word in enumerate(id2word)}
vocab_size = len(word2id)
print(vocab_size)
embedding_matrix = torch.zeros(vocab_size, vector_dim)
for word,id in word2id.items():
if word in wv_model:
embedding_matrix[id] = torch.tensor(wv_model[word])
print(embedding_matrix.shape)
embedding = nn.Embedding.from_pretrained(embedding_matrix, freeze=False)
text = "我喜欢乘坐宇宙飞船"
tokens = jieba.lcut(text)
print(tokens)
ids = [word2id.get(word,word2id[unk_token]) for word in tokens]
print(ids)
input = torch.tensor([ids])
output = embedding(input)
print(output)
print(output.size())wv_model是keyedvectors的一个实例对象,并加载了预训练好的“data/word2vec.kv”词向量,后面
我们添加了unk为了解决oov问题,构建了词表,对于embedding层,如果要加载预训练的嵌入矩
阵的话需要一个tensor的matrix词嵌入矩阵,所以我们用最原始的方法先构建了一个全0空矩阵,然
后利用词表填入内容并转换成tensor以便后续训练。后面是测试环节,创建一个text用结巴分词,
然后把词的列表转换成序号的列表并转换成tensor形式,把这个input丢进词嵌入层,获得的是各个
词语对应的词向量。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)