EMNLP 2024|Infrared-LLaVA: Enhancing Understanding of Infrared Images in Multi-Modal Large Language
在多模态大语言模型(MLLMs)席卷通用视觉领域的当下,红外图像这一具有“全天候感知”能力的特殊模态,却因数据稀缺、模态特性差异大等问题,成为多模态理解的“盲区”。哈尔滨工业大学与鹏城实验室联合团队提出的Infrared-LLaVA,通过辩论式多智能体数据生成、专属基准构建与精细化模型训练,构建了一套完整的红外图像理解解决方案。本文将从技术原理、核心公式、实验细节到文章关键图片解读,全面拆解这一创
这里写目录标题
一.论文信息
题目:Infrared-LLaVA: Enhancing Understanding of Infrared Images in
Multi-Modal Large Language Models
作者:Shixin Jiang1, Zerui Chen1, Jiafeng Liang1, Yanyan Zhao1, Ming Liu1,2*, Bing Qin1,2
单位:Harbin Institute of Technology, Harbin.China,Peng Cheng Laboratory, Shenzhen, China
期刊:Findings of the Association for Computational Linguistics: EMNLP 2024
二.摘要
在多模态大语言模型(MLLMs)席卷通用视觉领域的当下,红外图像这一具有“全天候感知”能力的特殊模态,却因数据稀缺、模态特性差异大等问题,成为多模态理解的“盲区”。哈尔滨工业大学与鹏城实验室联合团队提出的Infrared-LLaVA,通过辩论式多智能体数据生成、专属基准构建与精细化模型训练,构建了一套完整的红外图像理解解决方案。本文将从技术原理、核心公式、实验细节到文章关键图片解读,全面拆解这一创新成果。
三、技术背景:红外图像理解的核心挑战与底层矛盾
红外图像通过捕捉物体热辐射成像,在低光、雾雪、沙尘等恶劣环境下仍能稳定保留目标信息,但其与可见光图像的本质差异,导致现有多模态模型难以直接适配,核心矛盾集中在两点:
1. 模态特性差异导致的对齐偏差
可见光图像依赖颜色、纹理等外观特征,而红外图像仅反映热辐射强度分布,颜色、透明度、材质等可见光关键特征在红外图像中完全不可见。现有方法(如ImageBind-LLM、Pandagpt)通过ImageBind构建的统一嵌入空间,用可见光图文对间接对齐红外特征,完全跳过红外编码器的监督信号,导致模型对红外图像的理解存在“认知偏差”——例如模型可能错误认为“红外图像中能识别飞机材质”,而实际红外图像仅能反映飞机轮廓与热分布。
2. 数据稀缺与评估缺失的双重制约
- 数据层面:公开红外数据集多为单任务(如行人检测、目标跟踪),缺乏多模态所需的“图像-文本-指令”联动数据,人工标注红外图文对成本极高;
- 评估层面:无专门针对红外图像的问答基准,无法量化模型对红外特有任务(如热目标计数、恶劣环境下目标定位)的理解能力。
四、核心创新1:辩论式多智能体系统——红外数据生成的技术原理与图像解读
为低成本解决红外数据稀缺问题,团队设计了全自动辩论式多智能体系统,通过“生成-评估-优化”闭环,将COCO可见光数据集的知识迁移为红外模态数据。系统包含三大智能体,各模块原理、协作流程及对应图像解读如下:
1. 系统整体架构:三大智能体的协作逻辑(图1解读)
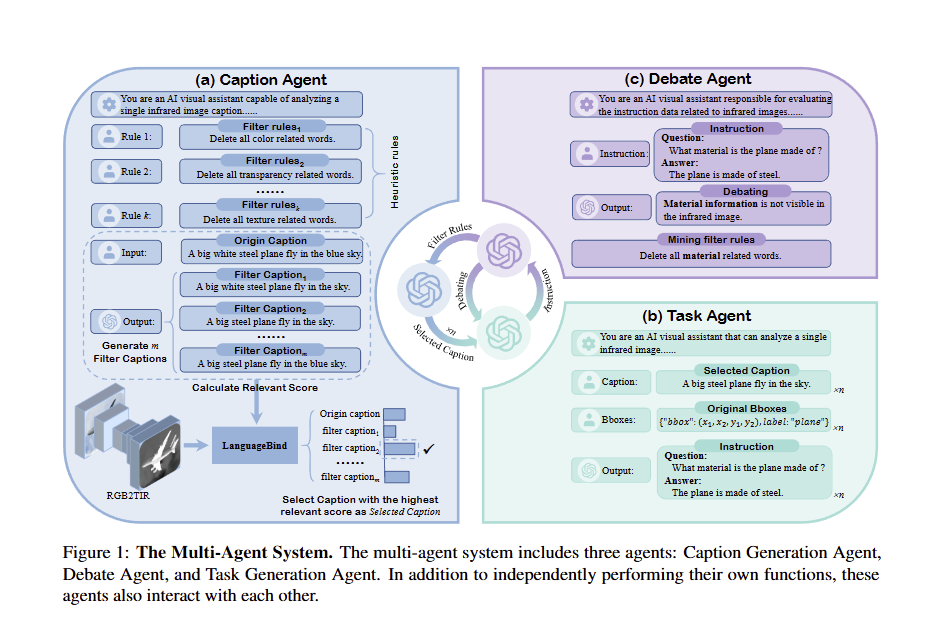
文章中图1(The Multi-Agent System) 清晰展示了多智能体系统的组成与交互关系,分为三个核心模块:
- (a) 字幕智能体(Caption Agent):左侧流程为“可见光图像→sRGB-TIR模型→红外图像”的转换,中间通过GPT-3.5基于过滤规则生成多个候选字幕,右侧利用LanguageBind计算“红外图像-候选字幕”的相似度,最终筛选出最优字幕。例如,输入可见光字幕“A big white steel plane fly in the blue sky”,经规则过滤(删除颜色、材质词)和相似度计算后,输出“A big steel plane fly in the sky”。
- (b) 任务智能体(Task Agent):接收字幕智能体的“红外图像+最优字幕”与原始边界框标注(如飞机的x、y坐标),通过GPT-3.5生成三类指令(复杂推理、多轮对话、详细描述),并将指令传递给辩论智能体。
- © 辩论智能体(Debate Agent):左侧接收任务智能体的指令,基于红外特性评估其有效性(如拒绝“判断飞机材质”的指令),右侧从评估结果中挖掘新过滤规则(如“Delete all material related words”),反馈给字幕智能体更新规则库。
整体流程形成“生成→评估→优化”的闭环,确保生成数据符合红外模态特性,且无需人工干预。
2. 各智能体核心原理与关键公式
(1)字幕智能体(Caption Agent):生成高质量红外图文对
分为三步:
- 红外图像转换:采用sRGB-TIR图像转换模型(Lee et al., 2023),将COCO可见光图像转换为红外图像,确保场景结构(如目标位置、物体轮廓)和语义关联性一致(Gao et al., 2023)。
- 字幕过滤:人工预设基础规则(删除颜色、透明度等),结合辩论智能体动态规则,由GPT-3.5(温度=0.8)生成5个候选字幕。
- 图文匹配筛选:利用LanguageBind的红外编码器与文本编码器计算相似度,选择匹配度最高的字幕
(2)任务智能体(Task Agent):生成红外指令数据
基于“红外图文对+边界框标注”,调用GPT-3.5生成三类指令,若未通过辩论智能体评估,则根据反馈重新生成(最大重试次数设为3次)。
(3)辩论智能体(Debate Agent):保障数据质量与规则迭代
- 指令评估:判断指令是否符合红外特性,例如拒绝“询问材质”的指令,接受“询问目标位置”的指令;
- 过滤规则挖掘:从无效指令中提炼新规则(如“材质信息不可见→删除材质相关词”),反馈给字幕智能体。
3. 系统输出:规模化红外数据集
通过上述流程,系统最终生成三大核心数据:
- 118k张合成红外图像(基于COCO转换);
- 500k条红外图文对(经相似度筛选);
- 12k条红外指令数据(含三类任务),命名为“Infrared Instruction Dataset”。
五、核心创新2:Infrared Template Benchmark——红外问答基准的构建原理与图像解读
为客观评估模型对红外图像的理解能力,团队构建了首个红外专属问答基准,从数据筛选、任务定义到模板构建均围绕红外特性设计,对应图2(Template-Based Construction) 的解读与原理如下:
1. 基准构建流程(图2解读)
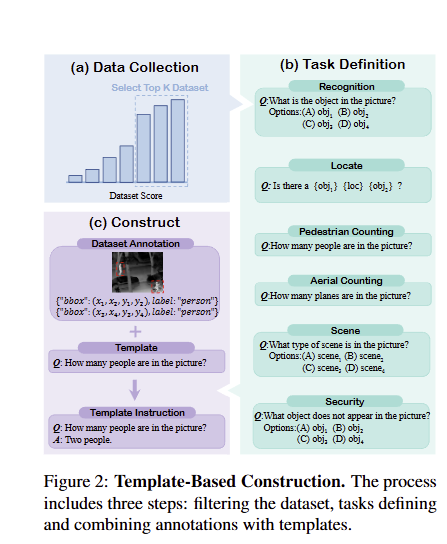
文章中图2展示了基准构建的三步核心流程,直观呈现从数据到问答对的转化过程:
- (a) 数据筛选(Data Collection):左侧为“62个原始红外数据集→基于Q-score和N-score筛选→6个核心数据集”的流程,右侧标注了筛选后数据集的任务类型(行人识别、目标跟踪等),确保数据质量与多样性;
- (b) 任务定义(Task Definition):中间列出6类核心任务,每个任务配有典型示例,例如“Counting”任务包含“Pedestrian Counting(统计行人数量)”和“Aerial Counting(统计航拍目标数量)”,“Locate”任务需判断目标相对位置;
- © 模板构建(Construct):右侧为“数据集标注+任务模板→生成问答对”的过程,例如“Pedestrian Counting”任务的模板为“Q: How many people are in the picture? A: [具体数字]”,结合真实标注生成22655条问答对,确保基准的准确性与一致性。
2. 数据集筛选:基于质量与多样性评分
从62个公开红外数据集(如LLVIP、FLIR、Vedai)中,通过Q-score(质量评分) 与N-score(多样性评分) 筛选出6个核心数据集,筛选公式如下:
Score ( D ) = α × Q score ( D ) + ( 1 − α ) × N score ( D ) \text{Score}(D) = \alpha \times Q_{\text{score}}(D) + (1-\alpha) \times N_{\text{score}}(D) Score(D)=α×Qscore(D)+(1−α)×Nscore(D)
其中:
- Q score ( D ) Q_{\text{score}}(D) Qscore(D):采用IQA模型Q-Alion(Wu et al., 2023)对每个数据集的100张随机图像打分,取平均值;
- N score ( D ) N_{\text{score}}(D) Nscore(D):等于数据集中标注的目标类别数量(如FLIR含8类目标,N-score=8);
- α \alpha α:权重系数(实验中设为0.6),优先保证成像质量。
3. 任务定义与基准构成
设计6类贴合红外应用场景的任务,生成22655条问答对,各任务数量与占比如下:
| 任务类型 | 数据来源 | 数量 | 占比(%) |
|---|---|---|---|
| 定位(Locate) | FLIR | 4387 | 14.48 |
| 航空计数 | Vedai、Visdrone | 3721 | 16.42 |
| 行人计数 | LLVIP | 2388 | 10.54 |
| 识别(Recognition) | LSOTB | 7463 | 32.94 |
| 场景(Scene) | RGBNIR | 477 | 2.10 |
| 安全(Security) | FLIR | 4219 | 18.62 |
| 总计 | - | 22655 | 100.00 |
六、核心创新3:Infrared-LLaVA-7B模型——红外多模态理解的实现原理与图像解读
基于生成的红外数据与基准,团队构建了首款专为红外优化的多模态模型Infrared-LLaVA-7B,从架构设计到训练流程均针对红外模态优化,对应图3(模型框架) 与图4(对齐方式) 的解读如下:
1. 模型架构:三层结构实现红外-文本对齐(图3解读)
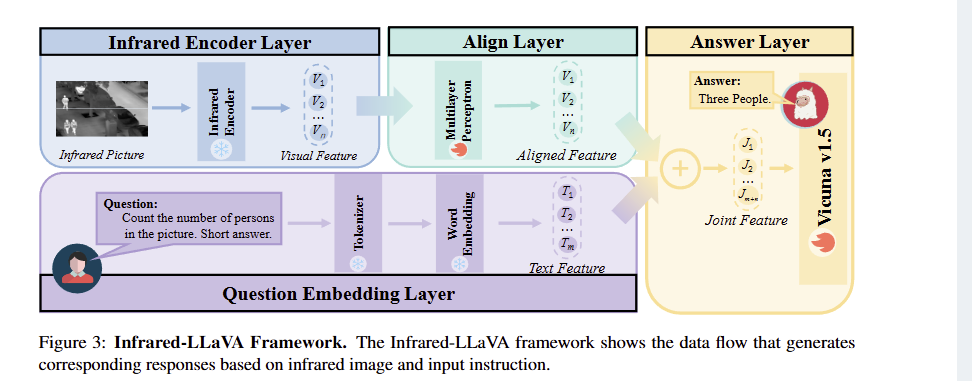
文章中图3(Infrared-LLaVA Framework) 展示了模型的完整数据流向,清晰呈现“红外图像→特征提取→对齐→文本生成”的过程:
- 左侧:红外特征提取与对齐:红外图像输入LanguageBind红外编码器,输出视觉特征(V1、V2…Vn),经多层感知机(MLP)对齐层转换为“对齐特征(Aligned Feature)”,确保维度与文本特征一致;
- 右侧:文本特征与联合生成:文本指令(如“Count the number of persons in the picture”)经Tokenizer转换为文本嵌入(T1、T2…Tm),与对齐特征拼接为“联合特征(Joint Feature)”;
- 底部:回答生成:联合特征输入Vicuna v1.5基座模型,最终输出回答(如“Three People”)。
该架构的核心是MLP对齐层,解决了红外特征与文本特征的模态鸿沟,确保模型能基于红外图像准确响应指令。
2. 双阶段训练:对齐与微调的精细化优化(图4解读)
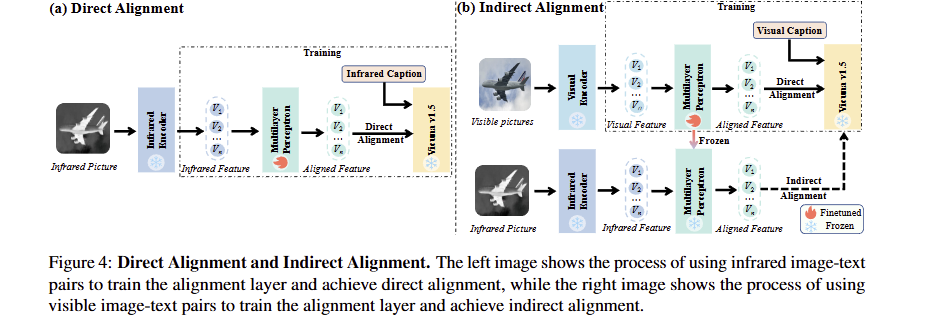
文章中图4(Direct Alignment and Indirect Alignment) 对比了两种对齐方式的差异,是理解模型训练逻辑的关键:
- (a) 直接对齐(Direct Alignment):左侧流程为“红外图像→红外编码器→红外特征→MLP对齐层→对齐特征”,训练数据为500k条红外图文对,固定红外编码器与Vicuna模型,仅训练MLP层,直接实现红外特征与文本特征的对齐;
- (b) 间接对齐(Indirect Alignment):右侧流程为“可见光图像→可见光编码器→可见光特征→MLP对齐层→对齐特征”,训练数据为500k条可见光图文对,依赖LanguageBind的统一嵌入空间,间接实现红外特征与文本特征的对齐(因LanguageBind已实现多模态特征的统一映射)。
3. 训练细节:参数与效率优化
- 硬件配置:4×NVIDIA A800 GPU;
- 对齐阶段: batch size=128,学习率=1e-3,训练1轮,耗时3.5小时;
- SFT阶段:batch size=64,学习率=2e-5,训练3轮,耗时1.5小时;
- 优化器:Adam优化器(无权重衰减),余弦学习率调度(预热比例3%);
- 内存优化:采用Full Shared Data Parallel(FSDP)与梯度检查点技术,降低显存占用。
七、实验验证:Infrared-LLaVA-7B的性能突破与图像解读
团队通过三类实验验证方案有效性,所有实验均基于Infrared Template Benchmark(训练集:测试集=2:1),评估指标为任务准确率与平均准确率(ITB Avg),关键实验结果对应图5(数据集有效性) 与表格数据。
1. 数据集有效性验证:红外指令提升现有模型性能(图5解读)
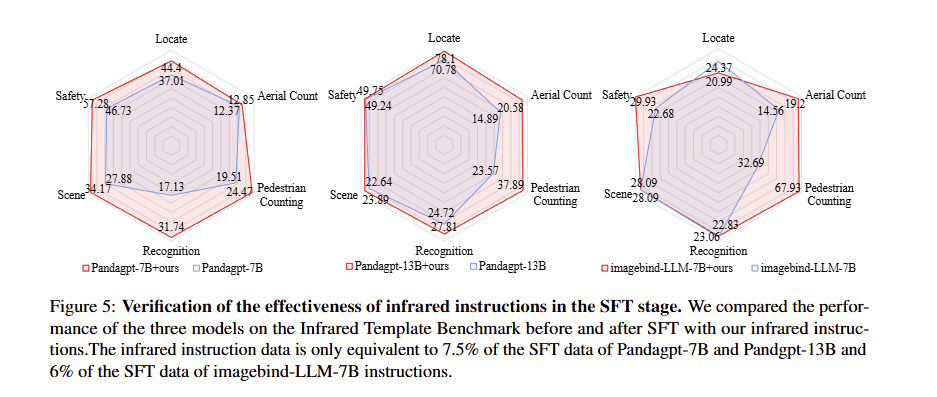
文章中图5(Verification of the effectiveness of infrared instructions) 为柱状图对比,展示了3个现有模型(Pandagpt-13B、Pandagpt-7B、imagebind-LLM-7B)在“使用红外指令微调前”与“微调后”的性能差异:
- 横坐标为6类任务(Locate、Aerial Count、Pedestrian Counting等),纵坐标为准确率;
- 每个任务对应两组柱状图:浅色为“微调前”,深色为“微调后”,所有任务的深色柱状图均高于浅色,证明红外指令能有效提升模型的红外理解能力;
- 例如,Pandagpt-13B的“Pedestrian Counting”准确率从23.57%提升至68.90%,“Recognition”准确率从24.72%提升至64.71%,且红外指令数据量仅为原有SFT数据的7.5%~6%,凸显生成数据的高质量。
2. 模型对比实验:Infrared-LLaVA-7B性能领先
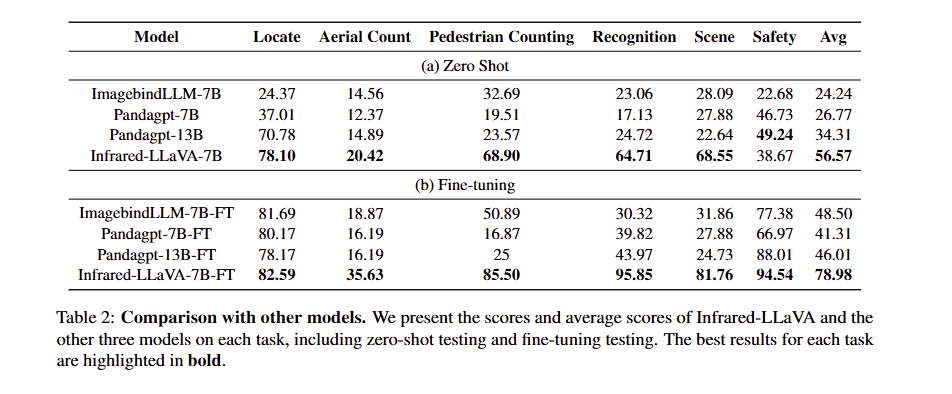
(1)零样本测试(未用基准数据训练)
Infrared-LLaVA-7B在5个任务上取得最优成绩,平均准确率达56.57%,远超ImageBind-LLM-7B(26.77%)、Pandagpt-7B(24.24%)与Pandagpt-13B(34.31%):
- 行人计数准确率:68.90%(比Pandagpt-13B高45.33个百分点);
- 识别准确率:64.71%(比Pandagpt-13B高40个百分点)。
(2)基准微调测试(用基准训练集微调)
Infrared-LLaVA-7B微调后平均准确率达78.98%,所有任务均最优:
- 识别准确率:95.85%(接近完美识别);
- 安全任务准确率:94.54%(高效检测异常目标)。
3. 消融实验:关键组件的作用验证
(1)对齐方式与SFT数据的影响
| 对齐方式 | SFT数据类型 | ITB Avg |
|---|---|---|
| 直接对齐 | 可见光指令 | 47.11 |
| 间接对齐 | 可见光指令 | 52.57 |
| 间接对齐 | 红外指令 | 55.23 |
| 直接对齐 | 红外指令 | 56.57 |
结论:红外指令比可见光指令提升2.7~9.4个百分点,证明红外专属数据能降低理解偏差;直接与间接对齐效果相近,为数据稀缺场景提供灵活选择。
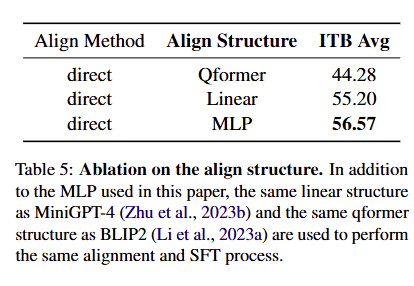
(2)SFT结构与对齐层类型的影响
-
同时训练MLP与LLM的效果最优(ITB Avg=56.57),比单独训练MLP高12.29个百分点;
-
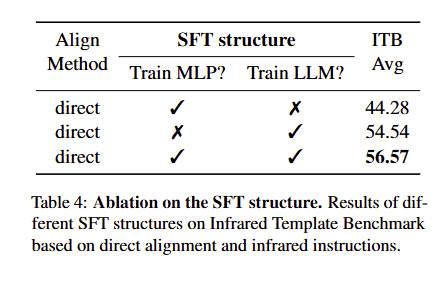
-
MLP对齐层效果优于Qformer(44.28)与Linear(55.20),证明MLP是红外-文本对齐的最优选择。
八、局限性与未来方向
尽管Infrared-LLaVA取得显著突破,仍存在可优化空间:
- 数据噪声与幻觉:GPT-3.5缺乏红外专业知识,生成的指令存在少量幻觉(如图8中“Multi Conversations Example”对“防护装备”的模糊回答),未来需用红外领域文本微调GPT-3.5;
- 基准任务单一:现有基准仅覆盖通用红外任务,未纳入工业测温、医疗病灶检测等专业场景,需扩充任务类型;
- 多模态扩展不足:仅验证可见光与红外的对齐,未来可拓展到X射线、深度图像等其他稀缺模态;
- 智能体必要性验证:未单独评估每个智能体的作用,需通过消融实验验证辩论机制的核心价值。
九、总结:红外多模态理解的里程碑
Infrared-LLaVA通过“辩论式多智能体数据生成(图1)-专属基准构建(图2)-精细化模型训练(图3、图4)”的三位一体方案,首次系统性解决了红外图像理解的核心难题:
- 数据层面:全自动生成高质量红外数据,大幅降低稀缺模态数据构建成本;
- 评估层面:构建首个红外问答基准,为模型性能衡量提供客观标准;
- 模型层面:Infrared-LLaVA-7B展现出领先的红外理解能力(图5、表格数据),为红外应用(如夜间安防、自动驾驶、医疗诊断)提供多模态技术支撑。
这一成果不仅填补了红外多模态理解的空白,更为其他稀缺模态的多模态研究提供了可复用的技术范式——通过智能体生成数据、专属基准评估、模态适配模型,让多模态大模型突破“通用视觉”的局限,走向更细分的专业领域。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)