微软:LLM推理一致性评估
大语言模型(LLM)在推理任务中如何评估其推理一致性?论文提出了一种新的度量标准“推理一致性”,用于评估AI系统在推理过程中依据其中间步骤的有效性。

📖标题:DeduCE: Deductive Consistency as a Framework to Evaluate LLM Reasoning
🌐来源:arXiv, 2504.07080
🌟摘要
🔸尽管在奥林匹克水平的推理问题上表现出色,但当遇到标准基准之外的新问题时,前沿的大型语言模型在高中数学上仍然很困难。
🔸超越最终准确性,我们提出了一种演绎一致性度量来分析语言模型(LM)的思维输出链。从形式上讲,演绎推理涉及两个子任务:理解一组输入前提并推断出从中得出的结论。所提出的度量研究了LM在这些子任务上的表现,目的是解释LM在新问题上的推理错误:随着上下文长度的增加,LM对输入前提的理解程度如何,以及它们在多个推理跳中推断结论的能力如何?由于现有的基准可以被记忆,我们开发了一个管道来评估LM在新的、受干扰的基准问题版本上的演绎一致性。
🔸在新的小学数学问题(GSM-8k)上,我们发现线性矩阵对输入前提数量的增加具有相当的鲁棒性,但随着推理跳数的增加,精度会显著下降。有趣的是,这些错误在原始基准测试中被掩盖了,因为所有模型都达到了接近100%的准确率。随着我们使用合成数据集增加解决方案步骤的数量,与理解输入前提相比,对多跳的预测仍然是主要的误差来源。其他因素,如语言风格的转变或早期错误的自然传播,并不能解释这种趋势。我们的分析提供了一种新的视角来描述LM推理——作为在输入前提和推理跳跃窗口上的计算——可以在问题域之间提供统一的评估。
🛎️文章简介
🔸研究问题:大语言模型(LLM)在推理任务中如何评估其推理一致性?
🔸主要贡献:论文提出了一种新的度量标准“推理一致性”,用于评估AI系统在推理过程中依据其中间步骤的有效性。
📝重点思路
🔸通过构建一个包含初始前提和目标谓词的推理问题,利用推理链条追踪来评估LLM的推理一致性。
🔸引入了一个名为DeduCE的框架,利用对原始基准问题的扰动生成新问题,并通过与理想推理者的比较来评估推理一致性。
🔸采用“生成-验证”方法,先生成候选解决方案,再进行一致性检查,确保其正确性。
🔸设计新颖的问题,通过改变基准问题中的变量值来减少记忆影响,评估模型在新问题上的推理能力。
🔸通过合成数据集控制问题的生成,系统地评估模型在不同推理深度和前提长度下的表现。
🔎分析总结
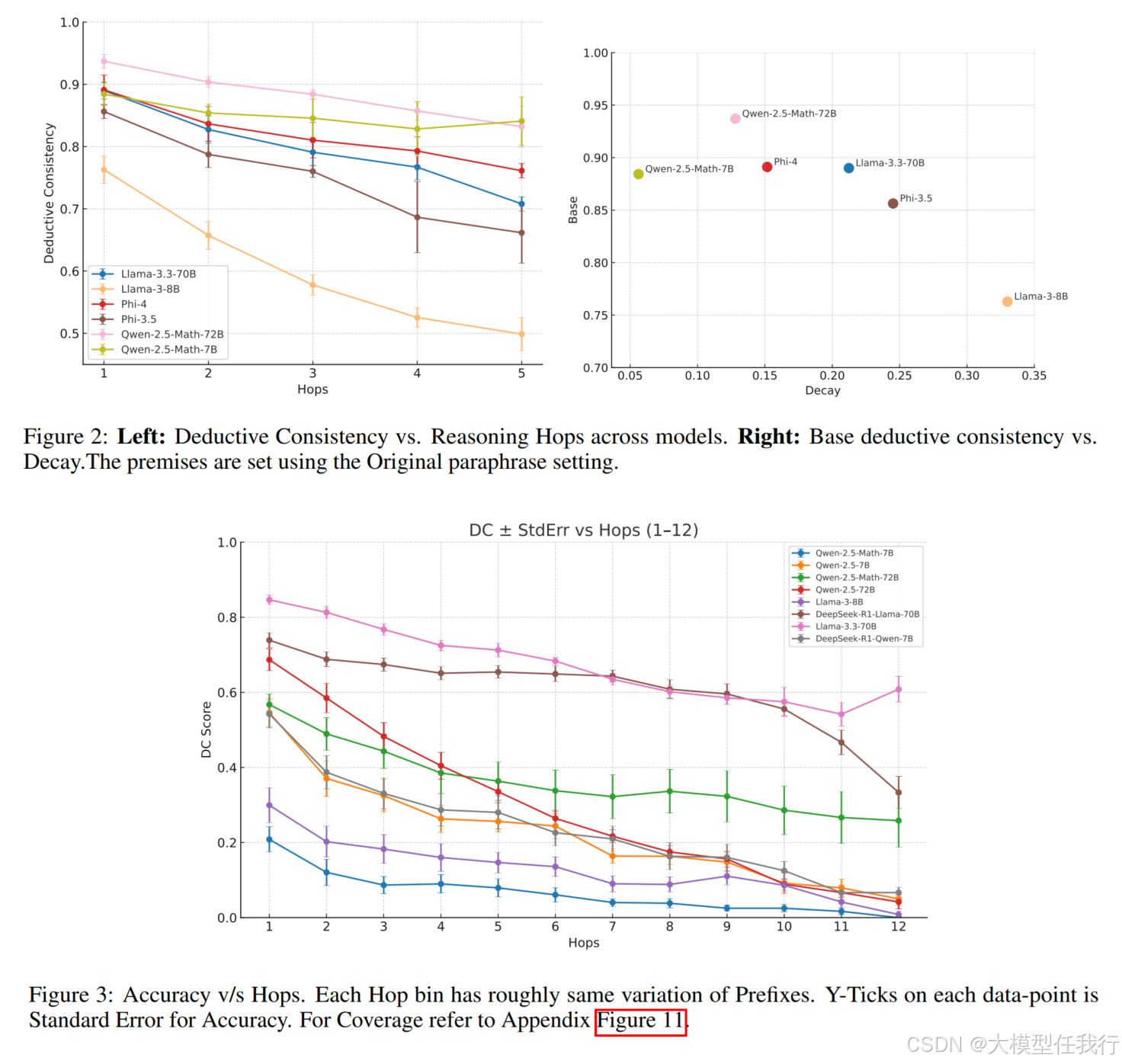
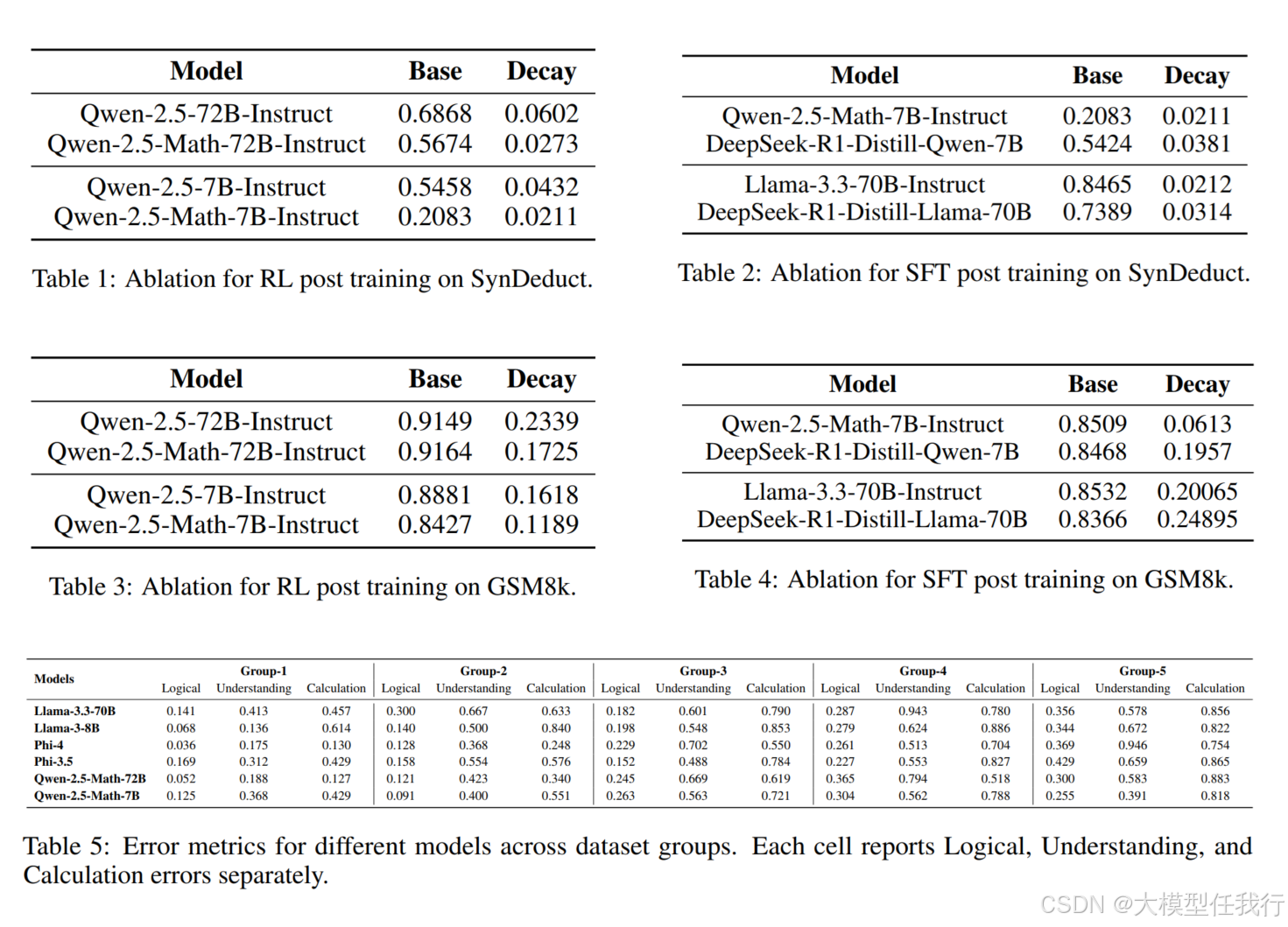
🔸实验结果表明,LLM在面对新问题时的推理一致性显著下降,尤其是推理步骤(hops)增加时,一致性下降幅度更大。
🔸更大的模型在面对推理步骤增加时表现出更高的鲁棒性,而较小的模型则表现出显著的性能下降。
🔸发现模型的推理一致性与输入前提的长度关系不大,但与推理步骤的数量密切相关。
🔸通过对合成数据集的评估,验证了在真实场景下的发现,支持了关于推理一致性随推理复杂度变化的理论。
💡个人观点
论文的核心在于构建问题变种来比较推理一致性,能够更全面地反映LLM在复杂推理任务中的表现,超越了传统的仅基于最终答案准确性的评估方式。
🧩附录

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 46
46 0
0- 0



 已为社区贡献305条内容
已为社区贡献305条内容

所有评论(0)