评估者-优化者 (Evaluator-Optimizer) 【智能体开发模式】
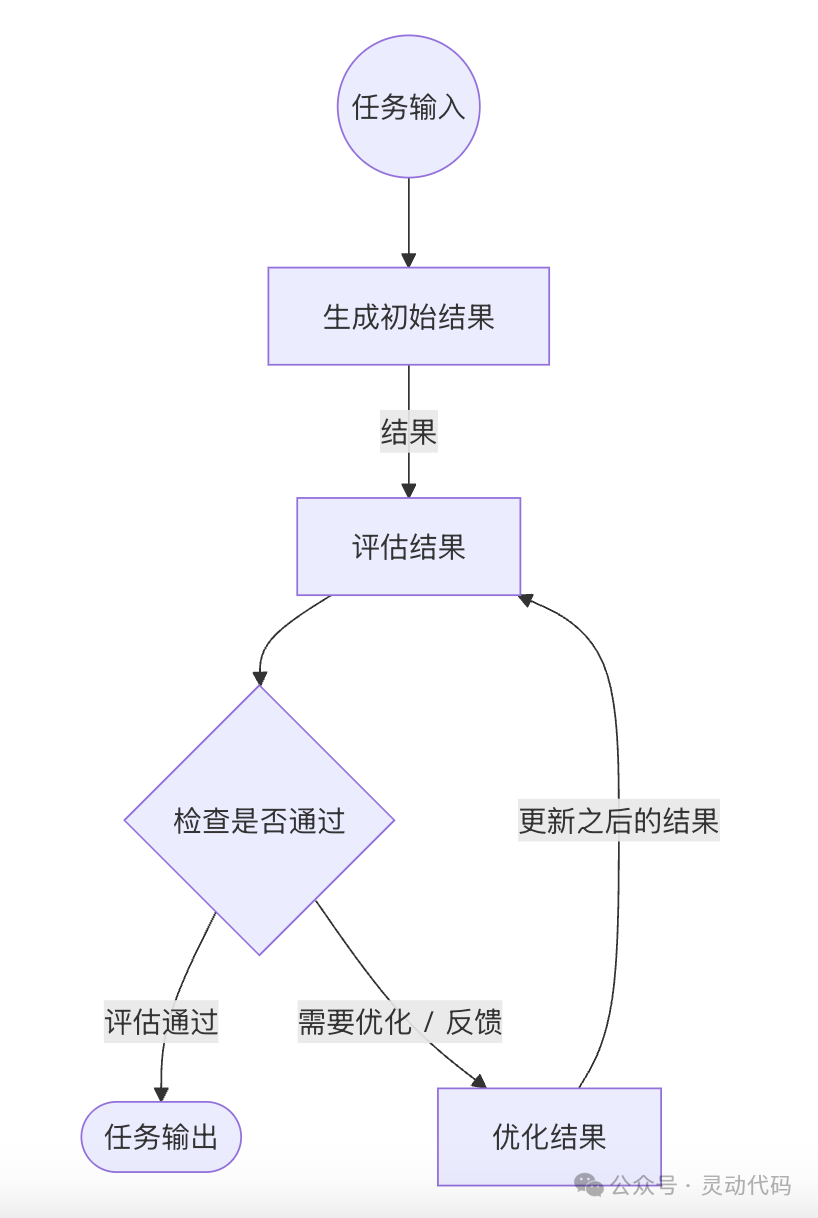
与并行工作流模式共同使用时,可以执行多个并行的评估,取这些评估值的平均值,作为最终的评估结果。当达到了最大的执行次数之后,即便评估的结果是不通过,最后一次生成的结果仍然会被返回。如果评估的结果是不通过,代码可以基于评估的反馈进行优化。评估者-优化者模式通过评估者的反馈来优化前一次生成的结果,从而提高最终生成结果的质量。如果评估不通过,feedback 中包含的是评估者的反馈。生成了初始的结果之后,
评估者-优化者模式通过评估者的反馈来优化前一次生成的结果,从而提高最终生成结果的质量。这种“评估-优化”的循环可以执行多次。
实现
该模式的实现包含了 3 个子任务。每个子任务使用任务执行模式。
-
一个任务生成初始的结果。
-
一个任务对结果进行评估,并给出反馈。
-
一个任务根据反馈来优化之前的结果。
下图给出了评估者-优化者模式的基本流程。
指南
下面是实现该模式的一些参考。
使用不同的模型
推荐使用不同的模型来进行生成和评估,以获得更好的结果。举例来说,我们可以使用 GPT-4o 进行生成,使用 DeepSeek V3 来进行评估。反过来也可以。
最大的评估次数
推荐设置“评估-优化”流程的最大执行次数。当达到了最大的执行次数之后,即便评估的结果是不通过,最后一次生成的结果仍然会被返回。这会减少响应时间,并降低成本。
评估的结果
对于评估的结果,可以是 boolean 类型,仅包含是否通过两个值;也可以是 0 到 100 的数值类型。数值类型更灵活,因为我们可以设置不同的阈值,来把结果标记为是否通过。与并行工作流模式共同使用时,可以执行多个并行的评估,取这些评估值的平均值,作为最终的评估结果。
示例
该示例是使用多轮评估进行代码生成。
生成初始的结果
在生成初始的结果时,提示模板中仅包含任务的输入。模板的变量 input 表示任务的输入。生成的是 Java 代码。
Goal: Generate Java code to complete the task based on the input.
{input}该任务的输出是生成的代码。
评估
生成了初始的结果之后,可以对生成的代码进行评估。模板变量 code 表示要评估的代码。模板中列出了评估代码的标准。
Goal: Evaluate this code implementation for correctness, time complexity, and best practices.
Requirements:- Ensure the code have proper javadoc documentation.- Ensure the code follows good naming conventions.- The code is passed if all criteria are met with no improvements needed.
{code}下面是评估结果的类型。这里使用的是 boolean 类型。如果评估不通过,feedback 中包含的是评估者的反馈。
import org.jspecify.annotations.Nullable;
/** * Evaluation result * * @param passed Passed or not passed * @param feedback Feedback if not passed */public record Evaluation(boolean passed, @Nullable String feedback) {
}优化
如果评估的结果是不通过,代码可以基于评估的反馈进行优化。模板变量 code 表示需要优化的代码,feedback 表示评估者给出的反馈。
Goal: Improve existing code based on feedback.
Requirements:- Address all concerns in the feedback.
Code:{code}
Feedback:{feedback}输出的结果是优化之后的代码。优化之后的代码会被再次评估,直到通过评估,或者达到了最大的评估次数。
运行示例
下面是该示例智能体执行时的 trace。agent.execute 表示智能体的执行。最外层的 trace 代表整个代码生成过程。之下的另外 4 个 agent.execute 表示 4 个子任务,依次是:
-
生成初始的结果
-
第一次结果评估,不通过
-
第一次结果优化
-
第二次结果评估,通过

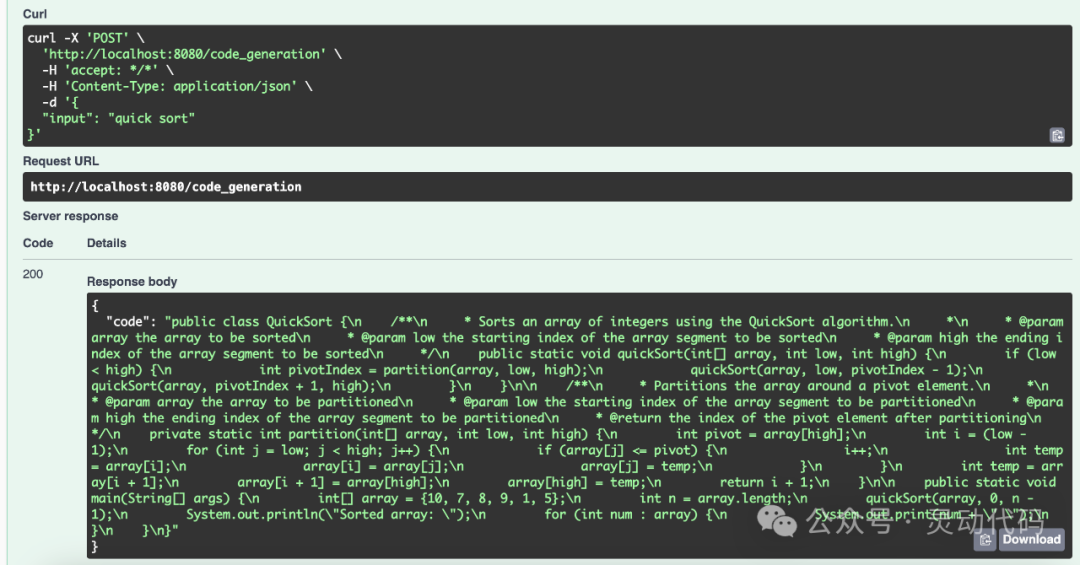
评估通过之后的结果,就是最终的返回结果。下图是使用 Swagger UI 测试的结果。输入是 “quick sort”。输出是通过了评估的 Java 代码实现。
完整的视频在我的 B 站,搜索【成富_Alex】。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)