CrateDB单库、集群安装
CreateDB表可以有主键,但是无法创建索引。CreateDB不支持外键约束。
CrateDB单节点&&集群安装
一、cratedb单节点安装
背景介绍
- 1、产品架构:Shared-Nothing
- 2、开发语言:Java
- 3、Crate 4.5并转向开源
性能,分片规则
- 1、分配不足:CrateDB中的表分片数可以指定,集群中的分片数少于 CPU 数,CrateDB没有获得最佳性能。
- 2、过度分配:每个表的分片数多于 CPU 数,一个 很少的超额分配是可取的,如果您明显超额分配 每个表的分片数,您将看到性能下降。
- 3、
refresh_interval参数,设置刷新间隔,可以设置毫秒级时间单位,非空闲情况下,默认1秒刷新一次,写入操作可能只是在本地节点或者部分节点的某个缓冲区域完成,刷新操作确保数据在各个节点上的一致性。
知识补充
- 1、传统关系型数据库在数据量大到一定量级后(一般是单表超过500W行或者2G左右)
执行计划
cr> explain (analyze,verbose) select count(*) from time_series_table;
SQLParseException[The ANALYZE and VERBOSE options are not allowed together]
数据以copy的方式导出
## 以栈跟踪的模式显示
[root@PostgreSQL crash]# ./crash -v
+-----------------------+-----------+---------+-----------+---------+
| server_url | node_name | version | connected | message |
+-----------------------+-----------+---------+-----------+---------+
| http://localhost:4200 | Piz Medel | 5.9.5 | TRUE | OK |
+-----------------------+-----------+---------+-----------+---------+
CONNECT OK
CLUSTER CHECK OK
TYPES OF NODE CHECK OK
cr> copy sensor_data to directory '/root/soft/crash/';
安装环境要求:
CrateDB 需要 Java 虚拟机才能运行。
- 从 CrateDB 4.2 开始,Java 与 CrateDB 捆绑在一起,没有额外的 安装是必要的。
- 4.2 之前的 CrateDB 版本需要单独的 Java 安装。为 CrateDB 3.0 到 4.1,Java 11 是最低要求。CrateDB 版本 3.0 之前的版本需要 Java 8。我们建议在 Linux 系统上使用 OpenJDK。
1.1、使用yum源安装
# 新建用户
useradd cratedb
echo 'linux123!@#' | passwd --stdin cratedb
# 添加cratedb库
cat > /etc/yum.repos.d/cratedb.repo << EOF
[cratedb-ce-stable]
name=CrateDB RPM package repository - $basearch - Stable
baseurl=https://cdn.crate.io/downloads/yum/7/$basearch
enabled=1
gpgcheck=0
gpgkey=https://cdn.crate.io/downloads/yum/RPM-GPG-KEY-crate
autorefresh=1
type=rpm-md
[cratedb-ce-testing]
name=CrateDB RPM package repository - $basearch - Testing
baseurl=https://cdn.crate.io/downloads/yum/testing/7/$basearch
enabled=0
gpgcheck=1
gpgkey=https://cdn.crate.io/downloads/yum/RPM-GPG-KEY-crate
autorefresh=1
type=rpm-md
EOF
## 更新yum仓库包
yum update
## 列出可用版本
yum --showduplicates list crate
## 只下载不安装
yumdownloader --destdir=/root/soft/ crate-5.7.4-1.x86_64 --resolve
## 安装命令
yum localinstall *.rpm -y
# 执行安装命令
sudo yum install --enablerepo=cratedb-ce-stable crate
sudo systemctl start crate
查看端口
其中4200端口,是CrateDB接受http协议连接的端口,5432端口是CrateDB接受PostgreSQL协议连接的端口
[root@PostgreSQL ~]# netstat -ntpl
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1349/sshd: /usr/sbi
tcp6 0 0 :::4200 :::* LISTEN 4610/java
tcp6 0 0 :::4300 :::* LISTEN 4610/java
tcp6 0 0 :::22 :::* LISTEN 1349/sshd: /usr/sbi
tcp6 0 0 :::5432 :::* LISTEN 4610/java
环境变量
根据实际情况修改CrateDB的环境变量参数
[root@PostgreSQL crash]# cat /usr/lib/systemd/system/crate.service
[Unit]
Description=CrateDB Server
Documentation=https://crate.io/docs/
Wants=network.target
After=network.target
[Service]
Type=simple
User=crate
Group=crate
WorkingDirectory=/usr/share/crate
Environment="CRATE_HEAP_SIZE=2G" #根据主机环境,约为内存的30%
# default environment variables
Environment="CRATE_HOME=/usr/share/crate"
Environment="CRATE_PATH_CONF=/etc/crate"
Environment="CRATE_PATH_LOG=/var/log/crate"
Environment="CRATE_GC_LOG_DIR=/var/log/crate"
Environment="CRATE_HEAP_DUMP_PATH=/var/lib/crate"
# load environment
EnvironmentFile=-/etc/default/crate
配置远程访问
编辑配置文件 vim /etc/crate/crate.yml
network.bind_host: 0.0.0.0
使用crash登录
# 安装crash
curl -o crash https://cdn.crate.io/downloads/releases/crash_standalone_latest
chmod +x crash
crash --host 127.0.0.1
登录数据库
crash --host 127.0.0.1
[root@PostgreSQL crash]# ./crash --host 127.0.0.1
CONNECT OK
cr> \dt
+------+
| name |
+------+
+------+
SELECT 0 rows in set (0.002 sec)
cr>
USER: crate | SCHEMA: doc | CLUSTER: crate | HOSTS: 127.0.0.1:4200 [ctrl+d] Exit
使用控制台登录
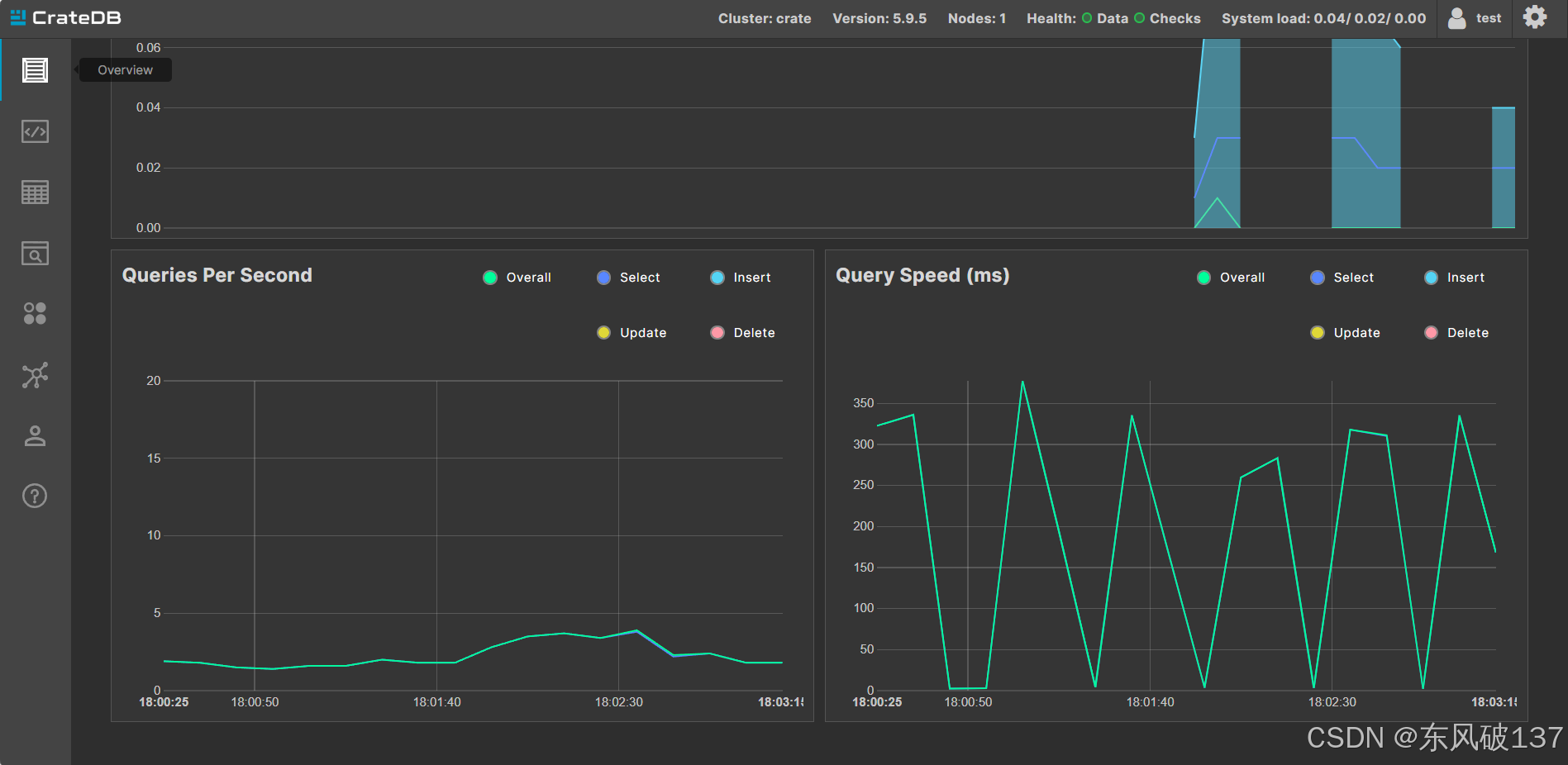
使用psql登录
如果使用psql登录,必须指定-d (在cratedb中为一个模式),且不完全兼容psql
[root@PostgreSQL ~]# psql -p 5432 -U crate -h 127.0.0.1 -d doc
psql (16.4, 服务器 14.0)
输入 "help" 来获取帮助信息.
doc=> \l
数据库列表
名称 | 拥有者 | 字元编码 | Locale Provider | 校对规则 | Ctype | ICU Locale | ICU Rules | 存取权限
-------+-----------------+----------+-----------------+-------------+-------------+------------+-----------+----------
crate | unknown (OID=1) | UTF8 | libc | en_US.UTF-8 | en_US.UTF-8 | | |
(1 行记录)
doc=> \d
关联列表
架构模式 | 名称 | 类型 | 拥有者
----------+-------------+--------+-----------------
doc | sensor_data | 数据表 | unknown (OID=0)
(1 行记录)
doc=> \dn
架构模式列表
名称 | 拥有者
------------+-----------------
benchmark | unknown (OID=0)
blob | unknown (OID=0)
crate | unknown (OID=0)
doc | unknown (OID=0)
my_schema | unknown (OID=0)
pg_catalog | unknown (OID=0)
sys | unknown (OID=0)
(7 行记录)
doc=>
创建表格
-- 建表
cr> CREATE TABLE sensor_data (
id INTEGER PRIMARY KEY,
timestamp TIMESTAMP,
sensor_id STRING,
value DOUBLE
);
CREATE OK, 1 row affected (30.027 sec)
-- 插入数据
cr> INSERT INTO doc.sensor_data (id, timestamp, sensor_id, value)
SELECT
rowid,
date_trunc('second', '2024-01-01T00:00:00'::timestamp + (rowid * 60)::integer),
'sensor' || (random() * 100)::integer,
random() * 100
FROM
generate_series(1, 1000) AS rowid;
INSERT OK, 1000 rows affected (0.091 sec)
cr> select * from doc.sensor_data limit 10;
+----+---------------+-----------+---------------------+
| id | timestamp | sensor_id | value |
+----+---------------+-----------+---------------------+
| 5 | 1704067200000 | sensor5 | 1.0331609962403343 |
| 7 | 1704067200000 | sensor83 | 21.62251189745248 |
| 19 | 1704067201000 | sensor22 | 32.54692551576568 |
| 21 | 1704067201000 | sensor94 | 51.548747604375514 |
| 31 | 1704067201000 | sensor60 | 20.082309794939967 |
| 36 | 1704067202000 | sensor35 | 61.95814885205305 |
| 41 | 1704067202000 | sensor54 | 44.36488076346821 |
| 42 | 1704067202000 | sensor71 | 71.75778073855368 |
| 45 | 1704067202000 | sensor9 | 87.40520040744948 |
| 46 | 1704067202000 | sensor54 | 55.14748545405072 |
+----+---------------+-----------+---------------------+
SELECT 10 rows in set (0.006 sec)
-- 查看表格
cr> \dt
+--------------------+
| name |
+--------------------+
| doc.sensor_data |
| my_schema.my_table |
+--------------------+
SELECT 2 rows in set (0.004 sec)
-- 查看表结构
cr> SHOW CREATE TABLE doc.sensor_data;
+-----------------------------------------------------+
| SHOW CREATE TABLE doc.sensor_data |
+-----------------------------------------------------+
| CREATE TABLE IF NOT EXISTS "doc"."sensor_data" ( |
| "id" INTEGER NOT NULL, |
| "timestamp" TIMESTAMP WITHOUT TIME ZONE, |
| "sensor_id" TEXT, |
| "value" DOUBLE PRECISION, |
| PRIMARY KEY ("id") |
| ) |
| CLUSTERED BY ("id") INTO 4 SHARDS |
| WITH ( |
| "allocation.max_retries" = 5, |
| "blocks.metadata" = false, |
| "blocks.read" = false, |
| "blocks.read_only" = false, |
| "blocks.read_only_allow_delete" = false, |
| "blocks.write" = false, |
| codec = 'default', |
| column_policy = 'strict', |
| "mapping.total_fields.limit" = 1000, |
| max_ngram_diff = 1, |
| max_shingle_diff = 3, |
| number_of_replicas = '0-1', |
| "routing.allocation.enable" = 'all', |
| "routing.allocation.total_shards_per_node" = -1, |
| "store.type" = 'fs', |
| "translog.durability" = 'REQUEST', |
| "translog.flush_threshold_size" = 536870912, |
| "translog.sync_interval" = 5000, |
| "unassigned.node_left.delayed_timeout" = 60000, |
| "write.wait_for_active_shards" = '1' |
| ) |
+-----------------------------------------------------+
-- 删表语句
cr> drop TABLE sensor_data;
DROP OK, 1 row affected (0.021 sec)
查看某个模式下的表
cr> show schemas;
+--------------------+
| schema_name |
+--------------------+
| benchmark |
| blob |
| crate |
| doc |
| information_schema |
| my_schema |
| pg_catalog |
| sys |
+--------------------+
SHOW 8 rows in set (0.001 sec)
cr> show tables from sys like '%jo%';
+--------------+
| table_name |
+--------------+
| jobs |
| jobs_log |
| jobs_metrics |
+--------------+
SHOW 3 rows in set (0.002 sec)
查看元数据表
也可以查看
pg_catalog.pg_tables表
select * from pg_catalog.pg_tables
cr> SELECT table_name, table_type
FROM information_schema.tables
WHERE table_schema = 'information_schema';
+-------------------------+------------+
| table_name | table_type |
+-------------------------+------------+
| character_sets | BASE TABLE |
| columns | BASE TABLE |
| foreign_server_options | BASE TABLE |
| foreign_servers | BASE TABLE |
| foreign_table_options | BASE TABLE |
| foreign_tables | BASE TABLE |
| key_column_usage | BASE TABLE |
| referential_constraints | BASE TABLE |
| routines | BASE TABLE |
| schemata | BASE TABLE |
| sql_features | BASE TABLE |
| table_constraints | BASE TABLE |
| table_partitions | BASE TABLE |
| tables | BASE TABLE |
| user_mapping_options | BASE TABLE |
| user_mappings | BASE TABLE |
| views | BASE TABLE |
+-------------------------+------------+
SELECT 17 rows in set (0.001 sec)
cr>
模式
-- 创建模式
cr> create table my_schema.my_table (
pk int primary key,
label text,
position geo_point
);
CREATE OK, 1 row affected (30.052 sec)
-- 查看模式
cr> select * from information_schema.schemata;
+--------------------+
| schema_name |
+--------------------+
| blob |
| information_schema |
| my_schema |
| pg_catalog |
| doc |
| sys |
+--------------------+
SELECT 6 rows in set (0.001 sec)
-- 切换模式
[root@PostgreSQL crash]# ./crash -U crate --schema my_schema --hosts 127.0.0.1
CONNECT OK
cr>
USER: crate | SCHEMA: my_schema | CLUSTER: crate | HOSTS: 127.0.0.1:4200
用户
-- 列出用户
cr> SELECT name, granted_roles, password, session_settings, superuser FROM sys.u
sers order by name;
+-------+---------------+----------+------------------+-----------+
| name | granted_roles | password | session_settings | superuser |
+-------+---------------+----------+------------------+-----------+
| crate | [] | NULL | {} | TRUE |
+-------+---------------+----------+------------------+-----------+
SELECT 1 row in set (0.004 sec)
自定义分片数,连表查询
CreateDB表可以有主键,但是无法创建索引。
CreateDB不支持外键约束。
数据存储方式
官网给出的案例
drop table timeseries_table;
-- 分片分区,可以选择month,不支持选择1 hour、2hour、3hour...
CREATE TABLE timeseries_table (
ts TIMESTAMP,
val DOUBLE PRECISION,
part GENERATED ALWAYS AS date_trunc('hour',ts) -- 这个函数将 ts 列的时间戳截断到小时级别,生成一个表示小时的 TIMESTAMP 值。这个列用于分区。
) CLUSTERED INTO 6 SHARDS
PARTITIONED BY(part);
-- 插入数据,插入1天范围内的随机数据
INSERT INTO timeseries_table (ts, val)
SELECT
current_timestamp + floor(random() * 100000000),
floor(random() * 100000) -- 确保插入的是数字
FROM generate_series(1, 1000);
-- 查询插入的数据
cr> SELECT
date_format('%Y-%m-%d %H:%i:%S.%f', ts) AS ts_formatted,
val,
date_format('%Y-%m-%d %H:%i:%S.%f', part) AS part_formatted
FROM timeseries_table
LIMIT 3;
+----------------------------+---------+----------------------------+
| ts_formatted | val | part_formatted |
+----------------------------+---------+----------------------------+
| 2025-01-09 16:56:29.960000 | 44305.0 | 2025-01-09 16:00:00.000000 |
| 2025-01-09 17:56:31.879000 | 21880.0 | 2025-01-09 17:00:00.000000 |
| 2025-01-09 18:06:18.342000 | 61144.0 | 2025-01-09 18:00:00.000000 |
+----------------------------+---------+----------------------------+
SELECT 3 rows in set (0.007 sec)
-- 查询时间范围
cr> SELECT
date_format('%Y-%m-%d %H:%i:%S.%f', MIN(ts)) AS min_ts_formatted,
date_format('%Y-%m-%d %H:%i:%S.%f', MAX(ts)) AS max_ts_formatted
FROM timeseries_table;
+----------------------------+----------------------------+
| min_ts_formatted | max_ts_formatted |
+----------------------------+----------------------------+
| 2025-01-09 16:46:43.892000 | 2025-01-10 20:21:38.609000 |
+----------------------------+----------------------------+
-- 查询分区
cr> SELECT DISTINCT date_format('%Y-%m-%d %H:%i:%S.%f', part) AS part_formatted
FROM timeseries_table;
+----------------------------+
| part_formatted |
+----------------------------+
| 2025-01-09 21:00:00.000000 |
| 2025-01-09 23:00:00.000000 |
| 2025-01-09 20:00:00.000000 |
| 2025-01-10 08:00:00.000000 |
| 2025-01-10 07:00:00.000000 |
| 2025-01-10 09:00:00.000000 |
| 2025-01-09 22:00:00.000000 |
| 2025-01-10 01:00:00.000000 |
| 2025-01-10 02:00:00.000000 |
| 2025-01-10 03:00:00.000000 |
| 2025-01-10 00:00:00.000000 |
| 2025-01-10 06:00:00.000000 |
| 2025-01-10 20:00:00.000000 |
| 2025-01-10 05:00:00.000000 |
| 2025-01-10 04:00:00.000000 |
| 2025-01-09 17:00:00.000000 |
| 2025-01-09 16:00:00.000000 |
| 2025-01-09 19:00:00.000000 |
| 2025-01-10 19:00:00.000000 |
| 2025-01-10 16:00:00.000000 |
| 2025-01-10 15:00:00.000000 |
| 2025-01-10 17:00:00.000000 |
| 2025-01-10 18:00:00.000000 |
| 2025-01-10 10:00:00.000000 |
| 2025-01-10 13:00:00.000000 |
| 2025-01-10 12:00:00.000000 |
| 2025-01-10 11:00:00.000000 |
| 2025-01-10 14:00:00.000000 |
| 2025-01-09 18:00:00.000000 |
+----------------------------+
SELECT 29 rows in set (0.006 sec)
-- 查看分区正好是3x29 = 97
cr> select count(*) from sys.shards where table_name = 'timeseries_table';
+----------+
| count(*) |
+----------+
| 87 |
+----------+
SELECT 1 row in set (0.002 sec)
分片方式
SELECT sha.node, sha.table_name,sha.id,seg.segment_name,seg.num_docs, seg.size,sha.path
FROM sys.shards sha
JOIN sys.segments seg ON seg.shard_id = sha.id
WHERE sha.table_name = 'timeseries_table'
order by id,segment_name;
使用TSBS工具测试
## 生成在cratedb中专用的数据
nohup tsbs_generate_data --use-case="cpu-only" --seed=123 --scale=10 --timestamp-start="2023-08-01T00:00:00Z" --timestamp-end="2023-08-02T00:00:00Z" --log-interval="1s" --format="cratedb" > Cratedb.data &
## 插入数据
[fbase@PostgreSQL bin]$ cat Cratedb.data | tsbs_load_cratedb --batch-size 100 --shards 4
time,per. metric/s,metric total,overall metric/s,per. row/s,row total,overall row/s
1736347484,126696.83,1.267000E+06,126696.83,12669.68,1.267000E+05,12669.68
1736347494,142198.06,2.689000E+06,134447.40,14219.81,2.689000E+05,13444.74
1736347504,159099.17,4.280000E+06,142664.58,15909.92,4.280000E+05,14266.46
1736347514,163306.16,5.913000E+06,147824.77,16330.62,5.913000E+05,14782.48
1736347524,164197.91,7.555000E+06,151099.43,16419.79,7.555000E+05,15109.94
Summary:
loaded 8640000 metrics in 56.482sec with 1 workers (mean rate 152968.34 metrics/sec)
loaded 864000 rows in 56.482sec with 1 workers (mean rate 15296.83 rows/sec)
表结构
cr> SELECT
column_name,
data_type,
is_nullable
FROM
information_schema.columns
WHERE
table_name = 'cpu';
+-----------------------------+-----------------------------+-------------+
| column_name | data_type | is_nullable |
+-----------------------------+-----------------------------+-------------+
| tags | object | TRUE |
| tags['hostname'] | text | TRUE |
| tags['region'] | text | TRUE |
| tags['datacenter'] | text | TRUE |
| tags['rack'] | text | TRUE |
| tags['os'] | text | TRUE |
| tags['arch'] | text | TRUE |
| tags['team'] | text | TRUE |
| tags['service'] | text | TRUE |
| tags['service_version'] | text | TRUE |
| tags['service_environment'] | text | TRUE |
| ts | timestamp without time zone | TRUE |
| usage_user | double precision | TRUE |
| usage_system | double precision | TRUE |
| usage_idle | double precision | TRUE |
| usage_nice | double precision | TRUE |
| usage_iowait | double precision | TRUE |
| usage_irq | double precision | TRUE |
| usage_softirq | double precision | TRUE |
| usage_steal | double precision | TRUE |
| usage_guest | double precision | TRUE |
| usage_guest_nice | double precision | TRUE |
+-----------------------------+-----------------------------+-------------+
cr> show create table cpu;
+-----------------------------------------------------+
| SHOW CREATE TABLE benchmark.cpu |
+-----------------------------------------------------+
| CREATE TABLE IF NOT EXISTS "benchmark"."cpu" ( |
| "tags" OBJECT(DYNAMIC) AS ( |
| "hostname" TEXT, |
| "region" TEXT, |
| "datacenter" TEXT, |
| "rack" TEXT, |
| "os" TEXT, |
| "arch" TEXT, |
| "team" TEXT, |
| "service" TEXT, |
| "service_version" TEXT, |
| "service_environment" TEXT |
| ), |
| "ts" TIMESTAMP WITHOUT TIME ZONE, |
| "usage_user" DOUBLE PRECISION, |
| "usage_system" DOUBLE PRECISION, |
| "usage_idle" DOUBLE PRECISION, |
| "usage_nice" DOUBLE PRECISION, |
| "usage_iowait" DOUBLE PRECISION, |
| "usage_irq" DOUBLE PRECISION, |
| "usage_softirq" DOUBLE PRECISION, |
| "usage_steal" DOUBLE PRECISION, |
| "usage_guest" DOUBLE PRECISION, |
| "usage_guest_nice" DOUBLE PRECISION |
| ) |
| CLUSTERED INTO 5 SHARDS |
| WITH ( |
| "allocation.max_retries" = 5, |
| "blocks.metadata" = false, |
| "blocks.read" = false, |
| "blocks.read_only" = false, |
| "blocks.read_only_allow_delete" = false, |
| "blocks.write" = false, |
| codec = 'default', |
| column_policy = 'strict', |
| "mapping.total_fields.limit" = 1000, |
| max_ngram_diff = 1, |
| max_shingle_diff = 3, |
| number_of_replicas = '0', |
| "routing.allocation.enable" = 'all', |
| "routing.allocation.total_shards_per_node" = -1, |
| "store.type" = 'fs', |
| "translog.durability" = 'REQUEST', |
| "translog.flush_threshold_size" = 536870912, |
| "translog.sync_interval" = 5000, |
| "unassigned.node_left.delayed_timeout" = 60000, |
| "write.wait_for_active_shards" = '1' |
| ) |
+-----------------------------------------------------+
SHOW 1 row in set (0.002 sec)
表连接的支持
它不支持外键约束
支持复合主键
-- 创建学生信息表
CREATE TABLE students (
student_id INT PRIMARY KEY,
name TEXT,
age INT,
gender TEXT
);
-- 创建成绩表并设置复合主键
CREATE TABLE grades (
grade_id INT,
student_id INT,
course TEXT,
score INT,
PRIMARY KEY (grade_id, student_id)
);
-- 向学生信息表中插入数据
INSERT INTO students (student_id, name, age, gender) VALUES
(1, '张三', 20, '男'),
(2, '李四', 21, '男'),
(3, '王五', 19, '女'),
(4, '赵六', 22, '男');
-- 向成绩表中插入数据
INSERT INTO grades (grade_id, student_id, course, score) VALUES
(1, 1, '数学', 85),
(2, 1, '英语', 90),
(3, 2, '数学', 78),
(4, 2, '英语', 88),
(5, 3, '数学', 92),
(6, 3, '英语', 85),
(7, 4, '数学', 70),
(8, 4, '英语', 80);
-- 查询每个学生的姓名、年龄和数学成绩
SELECT s.name, s.age, g.score AS math_score
FROM students s
INNER JOIN grades g ON s.student_id = g.student_id
WHERE g.course = '数学';
-- 查询每个学生的姓名、所有课程及对应成绩
SELECT s.name, g.course, g.score
FROM students s
LEFT JOIN grades g ON s.student_id = g.student_id;
执行计划
1.2、使用二进制启动
添加用户
# 新建用户
useradd cratedb
echo 'linux123!@#' | passwd --stdin cratedb
获取安装包
su - cratedb
wget https://cdn2.crate.io/downloads/releases/crate-5.7.4.tar.gz
修改配置文件
vim /home/cratedb/crate/config/crate.yml
## 修改java启动参数堆大小(一般为主机内存的1/3)
vim /home/cratedb/crate/bin/crate
## 添加
CRATE_HEAP_SIZE=2G
二、cratedb集群安装
2.2、手动引导
要跨多个主机运行 CrateDB 集群,您必须手动配置 引导过程,告诉节点如何:
2.2.1、手动设定种子
您可以通过在配置文件中设置 discovery.seed_hosts 来指定一个节点列表,以启动发现过程。此设置应包含每个主节点候选节点的一个标识符。
您必须使用种子节点列表配置每个节点。每个节点 通过种子节点发现集群的其余部分。
discovery.seed_hosts: ["192.168.1.128:4350","192.168.1.129:4350","192.168.1.130:4350"]
2.2.2、主节点选举
主节点负责对全局集群状态进行更改。在集群首次启动时,会从配置的主节点候选节点列表中选举出主节点。
如果未设置初始主节点,则新节点将期望能够发现一个已存在的集群。如果节点无法找到要加入的集群,它将定期记录一条警告消息,表明主节点尚未被发现或选举。
您可以通过在配置文件中设置 cluster.initial_master_nodes 来定义初始的主节点候选节点集合
您不需要在每个节点上配置 ,cluster.initial_master_nodes。然而,如果您确实进行了配置,则必须在所有配置的地方保持 cluster.initial_master_nodes 的一致性,否则 CrateDB 可能会形成多个独立的集群(这可能导致数据丢失)。
cluster.initial_master_nodes: ["192.168.1.128:4350","192.168.1.129:4350","192.168.1.130:4350"]
2.2.3、元数据网关
您可以配置元数据网关(metadata gateway),以便 CrateDB 在一定数量的节点可用之前延迟恢复操作。
因为如果在某些节点不可用时启动恢复,CrateDB 会基于这些节点可能不会重新上线的假设来操作,并会根据需要创建新的副本并重新平衡分片。这是一个代价高昂的操作,根据具体情况,如果节点只是短时间不可用,那么最好避免这种操作。
gateway:
recover_after_data_nodes: 3
expected_data_nodes: 3
2.2.4、配置文件
尽量不要动他的顺序,尽量在原来的位置上修改(因为不同的cratedb版本参数配置格式不都相同)
主要修改如下项:
################################### Cluster ##################################
cluster.name: crate
#//////////////////////// Database Administration ////////////////////////////
auth:
host_based:
config:
0:
user: crate
address: 192.168.6.118
method: trust
99:
method: password
这里的ip根据节点ip进行修改
#################################### Node ####################################
node.name: "node118"
另外两个节点根据ip进行修改
#################################### Paths ###################################
path.data: /opt/crate-4.2.1/data
path.logs: /opt/crate-4.2.1/logs
############################## Network And HTTP ###############################
network.bind_host: 192.168.6.118
network.publish_host: 192.168.6.118
network.host: 192.168.6.118
另外两个节点根据机器ip进行修改
################################# Discovery ##################################
discovery.seed_hosts:
- 192.168.6.118:4300
- 192.168.6.119:4300
- 192.168.6.120:4300
cluster.initial_master_nodes: ["192.168.6.118", "192.168.6.119","192.168.6.120"]
################################### Gateway ##################################
gateway.recover_after_nodes: 2
gateway.expected_nodes: 3
2.3、集群的使用
## 登录主节点
[cratedb@PostgreSQL ~]$ ./crash --host 192.168.6.118
CONNECT OK
-- 集群检测
cr> \check
CLUSTER CHECK OK
NODE CHECK OK
cr> SELECT master_node from sys.cluster; -- 查看主节点
+------------------------+
| master_node |
+------------------------+
| yeSEEKieSZWMwh5Z7f2oIQ |
+------------------------+
SELECT 1 row in set (0.003 sec)
cr> SELECT id,name from sys.nodes; -- 查看集群节点
+------------------------+---------+
| id | name |
+------------------------+---------+
| jphg8PVAQ_O5yCJo9cpFUg | node120 |
| 4ITU0nMGT3CKHElcETGJpw | node119 |
| yeSEEKieSZWMwh5Z7f2oIQ | node118 |
+------------------------+---------+
SELECT 3 rows in set (0.015 sec)
2.3.1、创建表格
CREATE TABLE cpu (
time TIMESTAMPTZ NOT NULL, -- 时间戳,带时区
tags_id INTEGER, -- 标签ID,整数类型
hostname TEXT, -- 主机名,文本类型
usage_user DOUBLE PRECISION, -- 用户CPU使用率,双精度浮点数
usage_system DOUBLE PRECISION, -- 系统CPU使用率,双精度浮点数
usage_idle DOUBLE PRECISION, -- 空闲CPU使用率,双精度浮点数
usage_nice DOUBLE PRECISION, -- Nice CPU使用率,双精度浮点数
usage_iowait DOUBLE PRECISION, -- I/O等待CPU使用率,双精度浮点数
usage_irq DOUBLE PRECISION, -- 硬中断CPU使用率,双精度浮点数
usage_softirq DOUBLE PRECISION, -- 软件中断CPU使用率,双精度浮点数
usage_steal DOUBLE PRECISION, -- 偷取CPU使用率,双精度浮点数
usage_guest DOUBLE PRECISION, -- Guest CPU使用率,双精度浮点数
usage_guest_nice DOUBLE PRECISION -- Guest Nice CPU使用率,双精度浮点数
);
INSERT INTO cpu (time, tags_id, hostname, usage_user, usage_system, usage_idle, usage_nice,
usage_iowait, usage_irq, usage_softirq, usage_steal,
usage_guest, usage_guest_nice)
SELECT
-- 以当前时间为基准,添加一个 0 到 1 天的随机时间间隔
current_timestamp + (random() * interval '1 day'),
1 + floor(random() * 10),
'host_' || floor(random() * 100),
random() * 100,
random() * 100,
random() * 100,
random() * 100,
random() * 100,
random() * 100,
random() * 100,
random() * 100,
random() * 100,
random() * 100
FROM generate_series(1, 10000);
2.3.2、查看表格分片在个个节点上的分布情况
cr> show create table doc.cpu;
+-----------------------------------------------------+
| SHOW CREATE TABLE doc.cpu |
+-----------------------------------------------------+
| CREATE TABLE IF NOT EXISTS "doc"."cpu" ( |
| "time" TIMESTAMP WITH TIME ZONE NOT NULL, |
| "tags_id" INTEGER, |
| "hostname" TEXT, |
| "usage_user" DOUBLE PRECISION, |
| "usage_system" DOUBLE PRECISION, |
| "usage_idle" DOUBLE PRECISION, |
| "usage_nice" DOUBLE PRECISION, |
| "usage_iowait" DOUBLE PRECISION, |
| "usage_irq" DOUBLE PRECISION, |
| "usage_softirq" DOUBLE PRECISION, |
| "usage_steal" DOUBLE PRECISION, |
| "usage_guest" DOUBLE PRECISION, |
| "usage_guest_nice" DOUBLE PRECISION |
| ) |
| CLUSTERED INTO 6 SHARDS |
| WITH ( |
| "allocation.max_retries" = 5, |
| "blocks.metadata" = false, |
| "blocks.read" = false, |
| "blocks.read_only" = false, |
| "blocks.read_only_allow_delete" = false, |
| "blocks.write" = false, |
| codec = 'default', |
| column_policy = 'strict', |
| "mapping.total_fields.limit" = 1000, |
| max_ngram_diff = 1, |
| max_shingle_diff = 3, |
| number_of_replicas = '0-1', |
| "routing.allocation.enable" = 'all', |
| "routing.allocation.total_shards_per_node" = -1, |
| "store.type" = 'fs', |
| "translog.durability" = 'REQUEST', |
| "translog.flush_threshold_size" = 536870912, |
| "translog.sync_interval" = 5000, |
| "unassigned.node_left.delayed_timeout" = 60000, |
| "write.wait_for_active_shards" = '1' |
| ) |
+-----------------------------------------------------+
SHOW 1 row in set (0.008 sec)
cr>
cr> select node from sys.shards where table_name = 'cpu';
+-----------------------------------------------------+
| node |
+-----------------------------------------------------+
| {"id": "4ITU0nMGT3CKHElcETGJpw", "name": "node119"} |
| {"id": "4ITU0nMGT3CKHElcETGJpw", "name": "node119"} |
| {"id": "4ITU0nMGT3CKHElcETGJpw", "name": "node119"} |
| {"id": "4ITU0nMGT3CKHElcETGJpw", "name": "node119"} |
| {"id": "jphg8PVAQ_O5yCJo9cpFUg", "name": "node120"} |
| {"id": "jphg8PVAQ_O5yCJo9cpFUg", "name": "node120"} |
| {"id": "jphg8PVAQ_O5yCJo9cpFUg", "name": "node120"} |
| {"id": "jphg8PVAQ_O5yCJo9cpFUg", "name": "node120"} |
| {"id": "yeSEEKieSZWMwh5Z7f2oIQ", "name": "node118"} |
| {"id": "yeSEEKieSZWMwh5Z7f2oIQ", "name": "node118"} |
| {"id": "yeSEEKieSZWMwh5Z7f2oIQ", "name": "node118"} |
| {"id": "yeSEEKieSZWMwh5Z7f2oIQ", "name": "node118"} |
+-----------------------------------------------------+
SELECT 12 rows in set (0.006 sec)
## 表的大小
cr> SELECT
table_name,
CAST(SUM(size) / (1024.0 * 1024) AS FLOAT) AS total_size_mb
FROM
sys.shards
WHERE
table_name = 'cpu'
GROUP BY
table_name;
+------------+---------------+
| table_name | total_size_mb |
+------------+---------------+
| cpu | 723.8309 |
+------------+---------------+
SELECT 1 row in set (0.061 sec)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)