FLUX.1模型代码解析
24年8月,stable diffusion前核心团队成员组建的黑森林实验室公布了一款文生图模型——FLUX.1, 效果惊艳四座,不仅克服了stable diffusion, SDXL等一众模型画手错乱的问题,在图片质量、精细程度以及图片细节、风格多样性上碾压了一众模型,达到了当时的SOTA水平。因此本文将带领大家,从源码上来学习该模型的思想。
1. 简介
24年8月,stable diffusion前核心团队成员组建的黑森林实验室公布了一款文生图模型——FLUX.1, 效果惊艳四座,不仅克服了stable diffusion, SDXL等一众模型画手错乱的问题,在图片质量、精细程度以及图片细节、风格多样性上碾压了一众模型,达到了当时的SOTA水平。 因此本文将带领大家,从源码上来学习该模型的思想。
项目地址: https://link.zhihu.com/?target=https%3A//blackforestlabs.io/flux-1/
代码地址:https://link.zhihu.com/?target=https%3A//github.com/black-forest-labs/flux
huggingface地址: https://link.zhihu.com/?target=https%3A//huggingface.co/black-forest-labs

2. 模型架构
下面这张图是本人参照diffusync-studio手绘的FLUX.1的模型架构图。
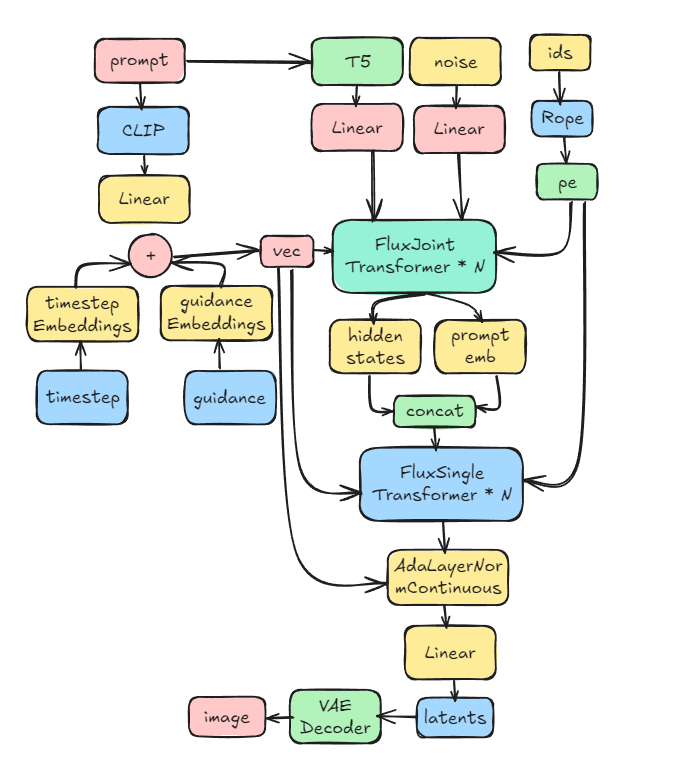
可以从这张模型架构图中可以看出,对于FLUX.1来说,核心的模型架构有如下部分:
- FluxJointTransformer
输入: 该模块对应着原始代码中DoduleStreamBlock模块,其输入有4个,分别是随机的noise,prompt经过T5特征提取器,而后再经过Linear投射层的特征, prompt经过CLIP提取的特征,以及图片和文本的位置编码pe。
输出: 该模块的输出有两个,分别是hidden states和prompt emb
- FluxSingleTransformer
输入: 该模块对应原始代码中的SingleStreamBlock模块,其输入有3个,分别是代表位置编码的pe, prompt经过CLIP提取的特征vec, 以及hidden state和prompt emb进行concat后的特征。
输出: 输出有一个,为hidden states
- Rope位置编码
为了标识不同的词和表示不同的图片位置,FLUX.1模型使用了RoPE位置编码。
接下来我们参照代码实现,来讲解FLUX.1模型。
2.1. FluxJointTransformer
在Diffusync-studio项目中, FluxJointTransformer的源代码如下:
class FluxJointTransformerBlock(torch.nn.Module):
def __init__(self, dim, num_attention_heads):
super().__init__()
# DIT的结构,将hidden_state chunk成6块,然后进行变换
self.norm1_a = AdaLayerNorm(dim)
self.norm1_b = AdaLayerNorm(dim)
# 计算attention
self.attn = FluxJointAttention(dim, dim, num_attention_heads, dim // num_attention_heads)
self.norm2_a = torch.nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
self.ff_a = torch.nn.Sequential(
torch.nn.Linear(dim, dim*4),
torch.nn.GELU(approximate="tanh"),
torch.nn.Linear(dim*4, dim)
)
self.norm2_b = torch.nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
self.ff_b = torch.nn.Sequential(
torch.nn.Linear(dim, dim*4),
torch.nn.GELU(approximate="tanh"),
torch.nn.Linear(dim*4, dim)
)
def forward(self, hidden_states_a, hidden_states_b, temb, image_rotary_emb, attn_mask=None, ipadapter_kwargs_list=None):
# 将hidden_states_a和hidden_states_b 进行变换一下
norm_hidden_states_a, gate_msa_a, shift_mlp_a, scale_mlp_a, gate_mlp_a = self.norm1_a(hidden_states_a, emb=temb)
norm_hidden_states_b, gate_msa_b, shift_mlp_b, scale_mlp_b, gate_mlp_b = self.norm1_b(hidden_states_b, emb=temb)
# Attention计算
attn_output_a, attn_output_b = self.attn(norm_hidden_states_a, norm_hidden_states_b, image_rotary_emb, attn_mask, ipadapter_kwargs_list)
# Part A
hidden_states_a = hidden_states_a + gate_msa_a * attn_output_a
norm_hidden_states_a = self.norm2_a(hidden_states_a) * (1 + scale_mlp_a) + shift_mlp_a
hidden_states_a = hidden_states_a + gate_mlp_a * self.ff_a(norm_hidden_states_a)
# Part B
hidden_states_b = hidden_states_b + gate_msa_b * attn_output_b
norm_hidden_states_b = self.norm2_b(hidden_states_b) * (1 + scale_mlp_b) + shift_mlp_b
hidden_states_b = hidden_states_b + gate_mlp_b * self.ff_b(norm_hidden_states_b)
return hidden_states_a, hidden_states_b2.2. FluxSingleTransformer
FluxSingleTransformer的代码如下:
class FluxSingleTransformerBlock(torch.nn.Module):
def __init__(self, dim, num_attention_heads):
super().__init__()
self.num_heads = num_attention_heads
self.head_dim = dim // num_attention_heads
self.dim = dim
self.norm = AdaLayerNormSingle(dim)
self.to_qkv_mlp = torch.nn.Linear(dim, dim * (3 + 4))
self.norm_q_a = RMSNorm(self.head_dim, eps=1e-6)
self.norm_k_a = RMSNorm(self.head_dim, eps=1e-6)
self.proj_out = torch.nn.Linear(dim * 5, dim)
def apply_rope(self, xq, xk, freqs_cis):
xq_ = xq.float().reshape(*xq.shape[:-1], -1, 1, 2)
xk_ = xk.float().reshape(*xk.shape[:-1], -1, 1, 2)
xq_out = freqs_cis[..., 0] * xq_[..., 0] + freqs_cis[..., 1] * xq_[..., 1]
xk_out = freqs_cis[..., 0] * xk_[..., 0] + freqs_cis[..., 1] * xk_[..., 1]
return xq_out.reshape(*xq.shape).type_as(xq), xk_out.reshape(*xk.shape).type_as(xk)
def process_attention(self, hidden_states, image_rotary_emb, attn_mask=None, ipadapter_kwargs_list=None):
batch_size = hidden_states.shape[0]
qkv = hidden_states.view(batch_size, -1, 3 * self.num_heads, self.head_dim).transpose(1, 2)
q, k, v = qkv.chunk(3, dim=1)
q, k = self.norm_q_a(q), self.norm_k_a(k)
q, k = self.apply_rope(q, k, image_rotary_emb)
hidden_states = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=attn_mask)
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, self.num_heads * self.head_dim)
hidden_states = hidden_states.to(q.dtype)
if ipadapter_kwargs_list is not None:
hidden_states = interact_with_ipadapter(hidden_states, q, **ipadapter_kwargs_list)
return hidden_states
def forward(self, hidden_states_a, hidden_states_b, temb, image_rotary_emb, attn_mask=None, ipadapter_kwargs_list=None):
# 残差边
residual = hidden_states_a
# norm 归一化
norm_hidden_states, gate = self.norm(hidden_states_a, emb=temb)
hidden_states_a = self.to_qkv_mlp(norm_hidden_states)
# 将hidden_states_a分割成两个部分
attn_output, mlp_hidden_states = hidden_states_a[:, :, :self.dim * 3], hidden_states_a[:, :, self.dim * 3:]
# 将rope pos应用于attn_output
attn_output = self.process_attention(attn_output, image_rotary_emb, attn_mask, ipadapter_kwargs_list)
mlp_hidden_states = torch.nn.functional.gelu(mlp_hidden_states, approximate="tanh")
hidden_states_a = torch.cat([attn_output, mlp_hidden_states], dim=2)
hidden_states_a = gate.unsqueeze(1) * self.proj_out(hidden_states_a)
hidden_states_a = residual + hidden_states_a
return hidden_states_a, hidden_states_b2.3. RoPE旋转位置编码
先看代码如下(得到image_rotary_emb)
class RoPEEmbedding(torch.nn.Module):
def __init__(self, dim, theta, axes_dim):
super().__init__()
self.dim = dim
self.theta = theta
self.axes_dim = axes_dim
def rope(self, pos: torch.Tensor, dim: int, theta: int) -> torch.Tensor:
assert dim % 2 == 0, "The dimension must be even."
# scale = (0, 2, 4, ..., dim-2 ) / dim
scale = torch.arange(0, dim, 2, dtype=torch.float64, device=pos.device) / dim
omega = 1.0 / (theta**scale) #omega = 1 / 10000^scale
batch_size, seq_length = pos.shape
out = torch.einsum("...n,d->...nd", pos, omega) # = pos * omega
cos_out = torch.cos(out)
sin_out = torch.sin(out)
stacked_out = torch.stack([cos_out, -sin_out, sin_out, cos_out], dim=-1)
out = stacked_out.view(batch_size, -1, dim // 2, 2, 2)
return out.float()
def forward(self, ids):
n_axes = ids.shape[-1]
emb = torch.cat([self.rope(ids[..., i], self.axes_dim[i], self.theta) for i in range(n_axes)], dim=-3)
return emb.unsqueeze(1)从上方的代码我们可以看出,它的计算过程如下:
- ids为txt_id和 image_id concat在一起的向量
- 对于ids最后一个维度进行遍历, 然后分别计算旋转矩阵
- 之后进行concat,再unsqueeze
而后我们来看添加旋转矩阵的代码。
def apply_rope(self, xq, xk, freqs_cis):
# 将最后一维分解成复数的形式
xq_ = xq.float().reshape(*xq.shape[:-1], -1, 1, 2)
xk_ = xk.float().reshape(*xk.shape[:-1], -1, 1, 2)
# 对应 [[cos, -sin], [sin, cos]] * [a, b]
xq_out = freqs_cis[..., 0] * xq_[..., 0] + freqs_cis[..., 1] * xq_[..., 1]
xk_out = freqs_cis[..., 0] * xk_[..., 0] + freqs_cis[..., 1] * xk_[..., 1]
return xq_out.reshape(*xq.shape).type_as(xq), xk_out.reshape(*xk.shape).type_as(xk)3. 参考文献

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)