企业级RAG架构全解:从零构建企业知识中枢
本文详细介绍了企业级检索增强生成(RAG)系统的架构设计与实践方案,涵盖典型场景应用、进阶架构策略、安全合规考量及差异化落地建议。文章分析了大规模文档管理、智能客服等场景,提出分层索引、实时同步和多模态支持等技术,针对不同规模企业提供私有化与云端部署方案,为企业构建可靠知识注入系统提供全面指导。
本文详细介绍了企业级检索增强生成(RAG)系统的架构设计与实践方案,涵盖典型场景应用、进阶架构策略、安全合规考量及差异化落地建议。文章分析了大规模文档管理、智能客服等场景,提出分层索引、实时同步和多模态支持等技术,针对不同规模企业提供私有化与云端部署方案,为企业构建可靠知识注入系统提供全面指导。
前言
随着大语言模型(LLM)在对话与生成任务上的快速普及,Retrieval-Augmented Generation(RAG)成为解决大模型“幻觉”等短板的重要方案。通过将外部检索到的真实文档嵌入对话上下文,RAG确保了输出的准确性与可控性,在企业内的知识库问答、技术支持、报告生成等应用中备受关注。
然而,从系统架构设计师的角度看,RAG的企业级落地仍需应对多种挑战与需求:
- 大规模文档管理与搜索
- 实时数据同步与多语言支持
- 隐私合规、权限管理
- 高并发与负载扩展

AI
典型场景的架构解构与挑战应对
在大模型落地应用中,架构设计往往需要结合业务需求进行针对性优化,以提升智能化水平、响应速度和系统可靠性;面对不同的应用场景,如大规模文档管理、智能客服、垂直领域知识中枢,需要构建高效的数据处理管道、优化推理架构,并增强模型的可解释性与合规性。
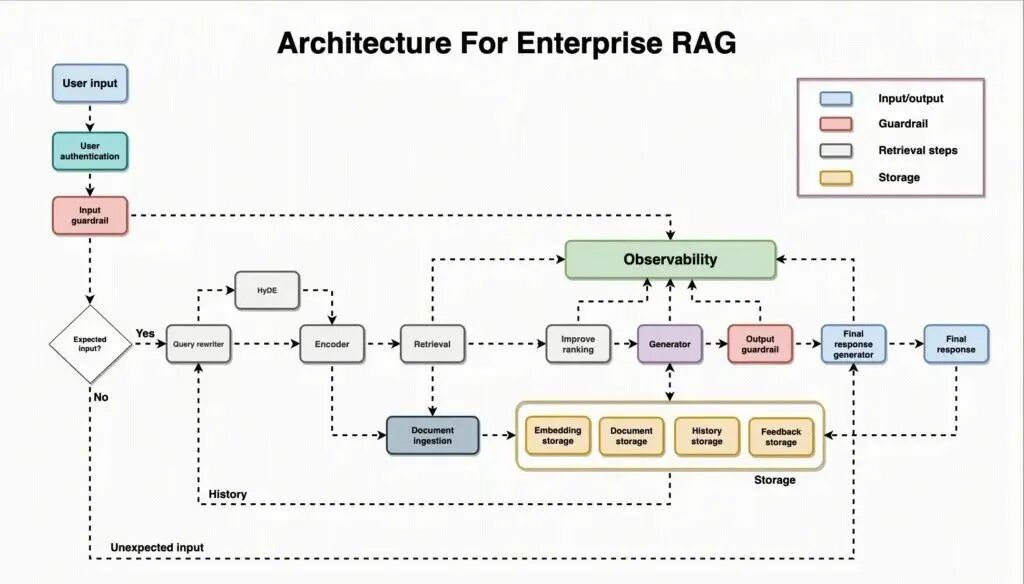
大规模文档管理系统的智能化重构
0****1
核心需求:
- 实现非结构化文档(合同、报告、邮件等)的语义检索与知识沉淀。
- 结合全文索引与向量搜索,提供高效的检索能力。
架构设计要点:
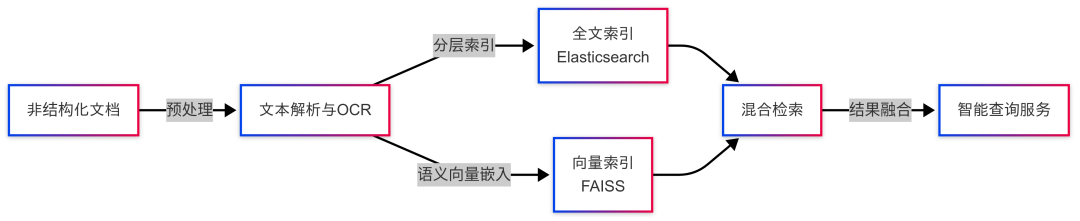
- **分层索引策略:**基于Elasticsearch(全文索引)+ FAISS(向量检索)结合,实现高效搜索。
- **增量更新管道:**使用Kafka + CDC(变更数据捕获)机制,实现近实时索引更新,提升数据时效性。
- **冷热数据分层:**将长期未访问的历史数据迁移至低成本存储,提高查询响应速度。
智能客服场景的端到端优化
0****2
核心需求:
- 大型企业内部的技术文档、项目档案、Wiki规模庞大,员工难以快速检索;
- RAG让员工可用自然语言问答形式来获取精确片段,提高生产力。
架构设计要点:
- **RAG增强方案:**结合检索增强生成(RAG)方案,优化智能客服的回答。
- **三级应答机制:**举例如下
if 置信度 > 0.9: 直接返回生成结果
elif 0.7 < 置信度 ≤ 0.9: 提供推荐答案选项
else
- **会话上下文感知:**使用向量缓存池存储多轮对话的语义信息,提高模型的连续性理解能力。
- **低置信度补偿策略:**当AI置信度较低时,引导用户选择推荐答案,减少误答的影响。
垂直领域知识中枢构建
0****3
核心需求:
- 诸如金融、法律、医疗等行业有大量专业文档、报表,员工或客户想通过问答式交互来获取分析和结论;
- 需要模型在回答时可引用具体条文、数据指标。
架构设计要点:
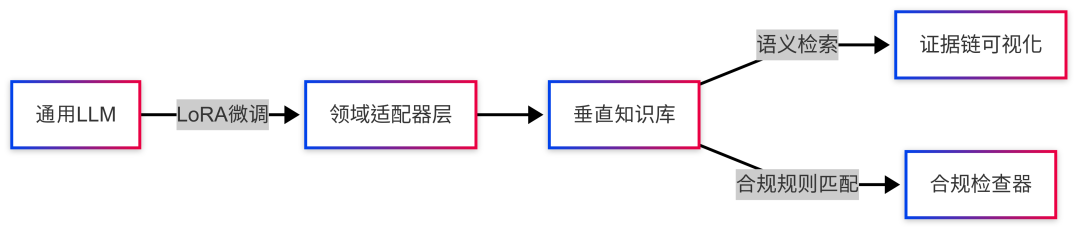
- **领域适配器层:**基于LoRA(Low-Rank Adaptation)技术,对通用LLM进行小规模高效微调,使其适配法律、医疗、金融等领域。
- **证据链可视化:**检索结果支持溯源标注与可信度评分,确保答案来源可验证,提高可靠性。
- **合规检查器:**内置行业法规词库,实现自动合规校验,辅助企业合规决策。
AI
企业级RAG的进阶架构策略
在实际应用中,RAG不仅仅局限于文本检索增强,而是在多个方面持续进化,以适应更复杂的业务需求,包括多模态支持、实时数据同步、以及更高效的Prompt处理策略。
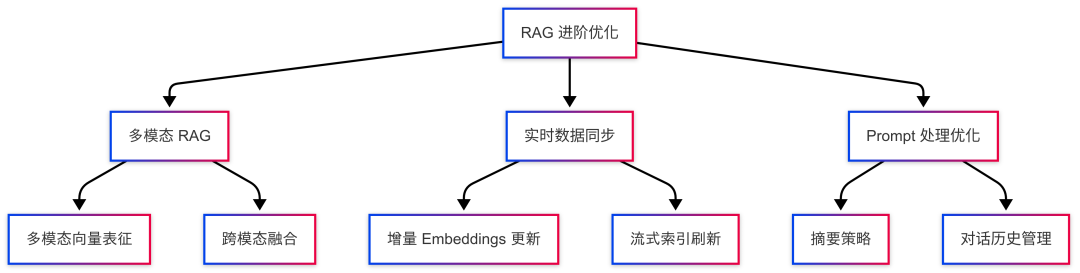
多模态RAG
0****1
传统RAG主要围绕文本进行检索增强,而在某些场景下,仅靠文本无法提供足够的信息支持,因此RAG需要支持图像、音频、视频等多模态数据,以提高信息的丰富度和准确性。
多模态向量表征:
- 需要使用CLIP、BLIP-2、ALIGN等模型将图像、音频等数据转换为向量,存入向量数据库。
- 结合 跨模态检索(Cross-modal Retrieval),允许模型根据文本查询出相关的图像、视频片段等。
跨模态融合:
- 在回答问题时,大模型不仅能读取文本信息,还能结合视觉、音频等输入进行多模态信息融合,增强回答质量。
实时数据同步
0****2
在新闻、金融、客服等场景中,离线构建的向量索引往往滞后,无法满足低延迟、高时效的需求,为此需要支持实时数据更新。
增量Embeddings更新:
- 监测数据变更后,增量更新而非重新构建整个向量索引,提升更新效率。
- 采用局部替换机制(如基于IDFA/唯一索引ID替换旧内容)。
流式索引刷新:
- 结合消息队列(Kafka/Pulsar)+ 实时计算(Flink/Spark Streaming),在新数据进入时触发Embeddings计算与索引更新,确保检索结果时刻保持最新。
Prompt处理与上下文溢出对策
0****3
当检索到的内容超过大模型的Token窗口(如GPT-4 Turbo的128K Token上限),需要高效管理上下文,避免信息丢失,即上下文溢出(Semantic Overflow)。
摘要策略(Multi-step Retrieval + Summarization):
- 在输入LLM之前,先对超长检索内容进行摘要,减少Token占用。
- 结合Sliding Window + Rank-based Retrieval方法,确保检索的内容片段最相关的信息优先保留。
对话历史管理(Conversation Buffer + Retrieval):
- 采用分层记忆机制,将较远的对话历史归档,并仅保留最近的关键上下文信息。
- 结合记忆缓冲池(Memory Buffer),动态调整对话的保留范围,提高模型的上下文连贯性。
AI
企业安全与合规
在企业应用大模型时,安全性和合规性是必须考虑的核心要素,不同企业对数据保护的要求不同,如何在私有化部署与云端服务之间找到平衡?如何确保企业数据的访问控制、合规审计以及信息安全?这些问题决定了RAG等大模型应用的落地策略。
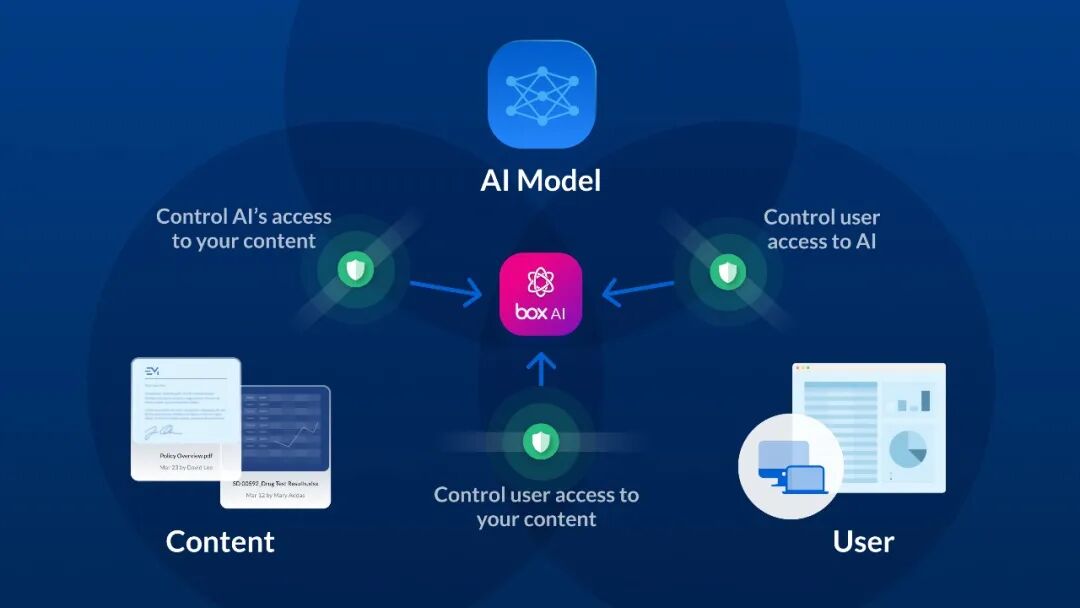
私有化部署vs.公有云RAG服务
0****1
企业在选择部署方式时,通常需要在私有化和公有云之间做出权衡。
私有化部署:
- 适用于金融、医疗、政府等高安全性、强监管行业,企业可完全控制数据流向和处理流程。
- 优点是数据安全性高,无需担心数据被云端存储或处理,符合数据主权要求。
- 缺点是成本较高,需自行管理GPU计算、存储、索引,并维护本地RAG系统。
公有云RAG服务:
- 适合对数据安全要求较低、希望快速上线 AI 功能的企业。
- 优点是无需维护基础设施,直接使用云厂商提供的Embeddings、向量数据库、大模型API。
- 缺点是需关注数据对外传输的安全性,避免敏感信息泄露。
- 可通过数据匿名化、加密传输(TLS)、访问策略等方式降低风险。
合规与数据主权
0****2
在金融、医疗、政府等强监管行业,企业需要严格控制数据流向,并保证符合行业法规(如GDPR、HIPAA、ISO 27001等)。
细粒度权限控制:
- 仅允许特定用户、特定角色访问特定文档或特定段落,避免敏感信息泄露。
- 例如:金融行业的交易数据,医疗行业的患者记录,政府内部文档等。
审计日志:
- 记录每次查询日志、命中结果、输出文本,确保所有数据访问可溯源。
- 在合规检查时,可以回溯AI生成的内容,验证其是否符合业务要求。
数据主权要求:
- 一些行业或政府机构要求数据存储和计算必须位于特定地理区域,如欧盟的GDPR规定。
- 若公有云不符合数据主权要求,企业可能需要采用私有化或混合云架构,以确保数据合规。
其他安全策略
0****3
除了数据存储和访问控制外,还需要考虑企业级AI解决方案的其他安全机制。
身份认证与SSO(单点登录):
- 限制AI访问范围,防止内部员工或外部攻击者未经授权访问企业数据。
- 例如使用OAuth、LDAP、Active Directory(AD)等身份验证系统,实现基于角色的访问控制(RBAC)。
日志脱敏(Log Redaction):
- 隐藏敏感信息(如个人隐私、财务数据、医疗记录等),防止数据在日志、调试、监控过程中暴露。
- 例如在企业客服AI处理用户对话时,可屏蔽身份证号、银行卡号、地址等敏感字段。
监控与安全告警:
- 设定异常访问检测机制,防止AI被大规模恶意查询、暴力抓取公司机密信息。
- 结合SIEM(安全信息与事件管理)、防火墙、DLP(数据防泄露)等安全方案,确保企业AI系统的稳健性。
AI
企业规模与数据类型的落地建议
在企业应用大模型时,不同规模的组织面临不同的资源、成本和合规要求,因此选择合适的数据处理方式、存储方案和计算架构至关重要;小型企业往往更关注易用性和成本,而大型企业和政府部门则需要数据合规、可控性和安全策略;此外数据类型的多样性(文本、语音、图像等)也对Embeddings和检索机制提出了更高要求。
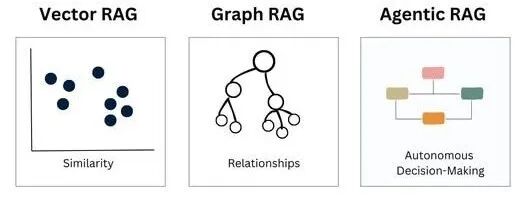
中小企业
0****1
-
**易用性与低成本优先:**中小企业通常没有足够的资源和技术能力来搭建完整的RAG(Retrieval-Augmented Generation)系统,因此建议优先在公有云上进行RAG POC(Proof of Concept)。
-
**云厂商 Embeddings + 大模型API组合:**使用云厂商提供的Embeddings服务(如OpenAI、Azure AI、阿里云 PAI Embedding)和大模型API进行初步试验。
-
**公共向量数据库SaaS:**当数据不算特别敏感时,可以使用云上的向量数据库服务(如Pinecone、Weaviate)进行检索增强。
-
**私有化的考虑:**如果业务扩张或数据合规要求提高,可以考虑迁移至本地或私有云解决方案。
大型企业/政府部门
0****2
-
**数据合规需求高:**大型企业和政府机构通常要求数据存储在本地数据中心或合规云,避免泄露敏感信息。
-
**搭建企业级检索系统:**建议采用Elasticsearch、Milvus、Faiss等向量数据库,结合企业内部的RAG方案,提高数据检索的精度和效率。
-
**与内部大模型集成:**对接企业自研或合作的大模型(如智谱AI、文心一言、DeepSeek等),实现端到端的智能问答、搜索增强等功能。
-
**上下文管理:**控制RAG过程中注入的信息,避免prompt窃取攻击(Prompt Injection)。
-
**权限与审计系统:**建立访问控制,确保不同部门、不同级别的用户只能访问对应权限的数据。
不同数据类型
0****3
- **文本档案:**常见的企业数据存储格式(PDF、HTML、Word、Excel)需要解析(Parsing)和分段(Segmentation),以适应向量化存储和高效检索。
- **多语种场景:**企业在跨国业务中,需要考虑Embeddings方案是否支持多语言向量化,如Mistral、LaBSE 这种多语种Embeddings。
- **多模态数据:**在涉及图像、语音、视频等内容时,可以使用跨模态Embeddings(如CLIP)将不同类型的数据转换为可检索的格式,并纳入RAG流程。
AI
结语
RAG不应被视为孤立的技术组件,而应作为企业认知中枢的核心引擎,为大模型在企业中的应用提供了有效的知识注入路径,改善了幻觉与可解释性;从客服问答、内部知识库到行业数据分析等场景,我们见证了RAG在落地价值和用户体验上的显著提升。
然而RAG并非一劳永逸,合规、安全、扩展等问题在企业中仍需综合考量,而且在架构设计的过程中需在三个维度保持平衡:知识新鲜度(实时更新能力)、推理可靠性(可解释机制)、系统扩展性(异构数据兼容);系统架构设计师可通过:
- **进阶策略:**支持多模态、实时更新、Prompt优化;
- **私有化和云端:**结合数据安全与成本,部署合适的索引与大模型;
- **安全合规:**完善权限、审计与监控机制;
- **规模化落地:**根据企业规模与数据特点做差异化实现;
让RAG真正为企业带来知识效率与业务洞察的提升,并为未来结合多模态、大模型私有化 等更深度创新预留空间。
//
大模型未来如何发展?普通人如何抓住AI大模型的风口?
※领取方式在文末
为什么要学习大模型?——时代浪潮已至
随着AI技术飞速发展,大模型的应用已从理论走向大规模落地,渗透到社会经济的方方面面。
- 技术能力上:其强大的数据处理与模式识别能力,正在重塑自然语言处理、计算机视觉等领域。
- 行业应用上:开源人工智能大模型已走出实验室,广泛落地于医疗、金融、制造等众多行业。尤其在金融、企业服务、制造和法律领域,应用占比已超过30%,正在创造实实在在的价值。
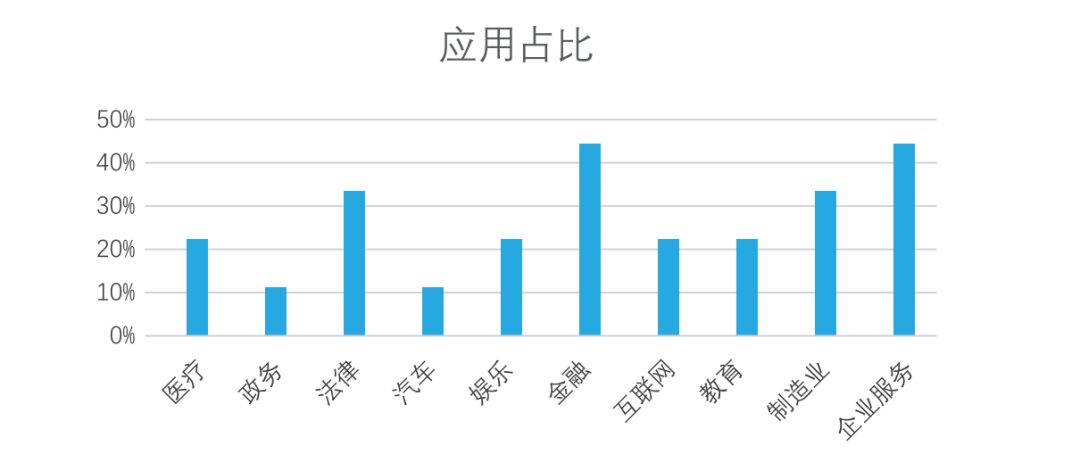
未来大模型行业竞争格局以及市场规模分析预测: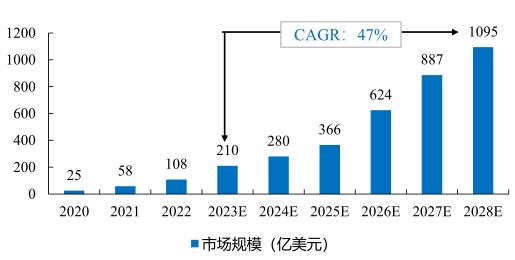
同时,AI大模型技术的爆发,直接催生了产业链上一批高薪新职业,相关岗位需求井喷:
AI浪潮已至,对技术人而言,学习大模型不再是选择,而是避免被淘汰的必然。这关乎你的未来,刻不容缓!
那么,我们如何学习AI大模型呢?
这份精心整理的AI大模型学习资料,我整理好了,免费分享!只希望它能用在正道上,帮助真正想提升自己的朋友。让我们一起用技术做点酷事!
ps:微信扫描即可获取
加上后我将逐一发送资料
与志同道合者共勉
真诚无偿分享!!!

适学人群
我们的课程体系专为以下三类人群精心设计:
-
AI领域起航的应届毕业生:提供系统化的学习路径与丰富的实战项目,助你从零开始,牢牢掌握大模型核心技术,为职业生涯奠定坚实基础。
-
跨界转型的零基础人群:聚焦于AI应用场景,通过低代码工具让你轻松实现“AI+行业”的融合创新,无需深奥的编程基础也能拥抱AI时代。
-
寻求突破瓶颈的传统开发者(如Java/前端等):将带你深入Transformer架构与LangChain框架,助你成功转型为备受市场青睐的AI全栈工程师,实现职业价值的跃升。

※大模型全套学习资料展示
通过与MoPaaS魔泊云的强强联合,我们的课程实现了质的飞跃。我们持续优化课程架构,并新增了多项贴合产业需求的前沿技术实践,确保你能获得更系统、更实战、更落地的大模型工程化能力,从容应对真实业务挑战。 资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
01 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。希望这份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
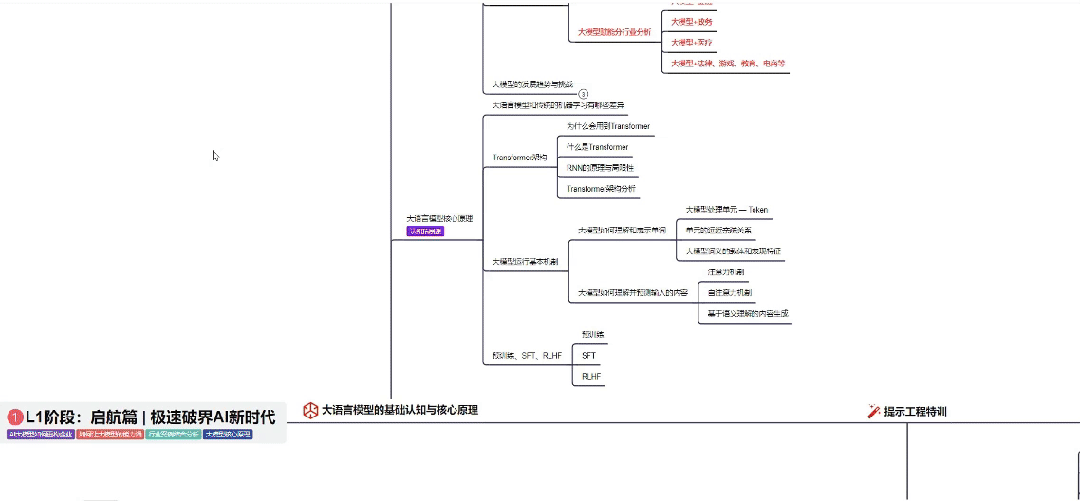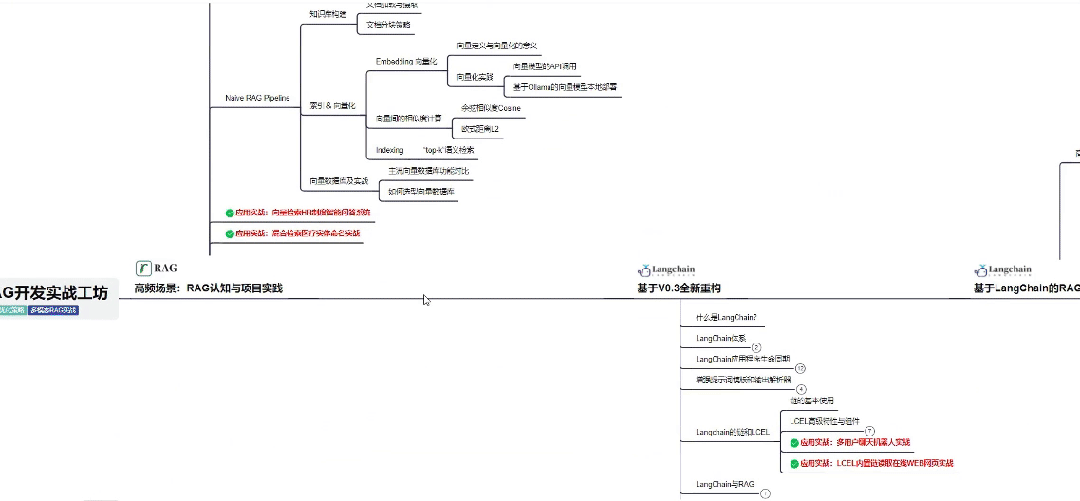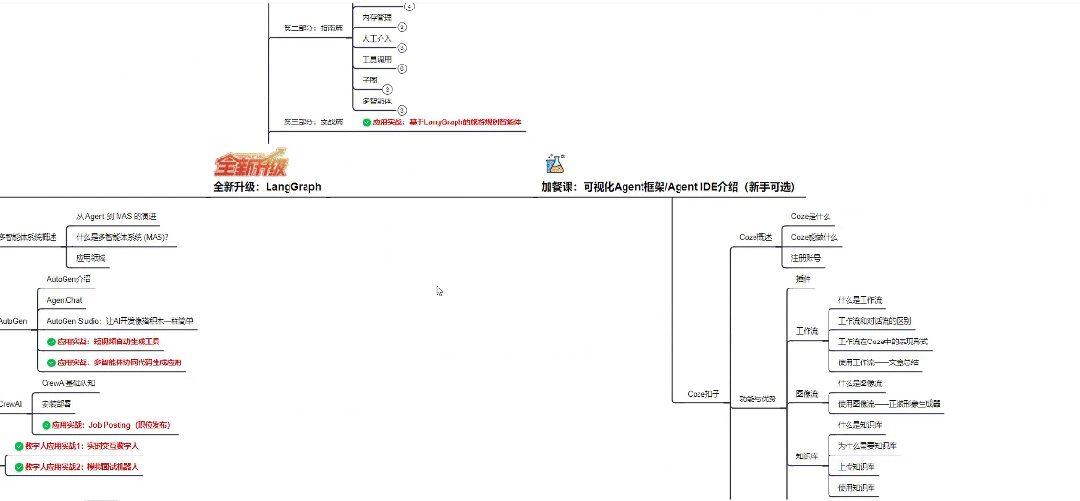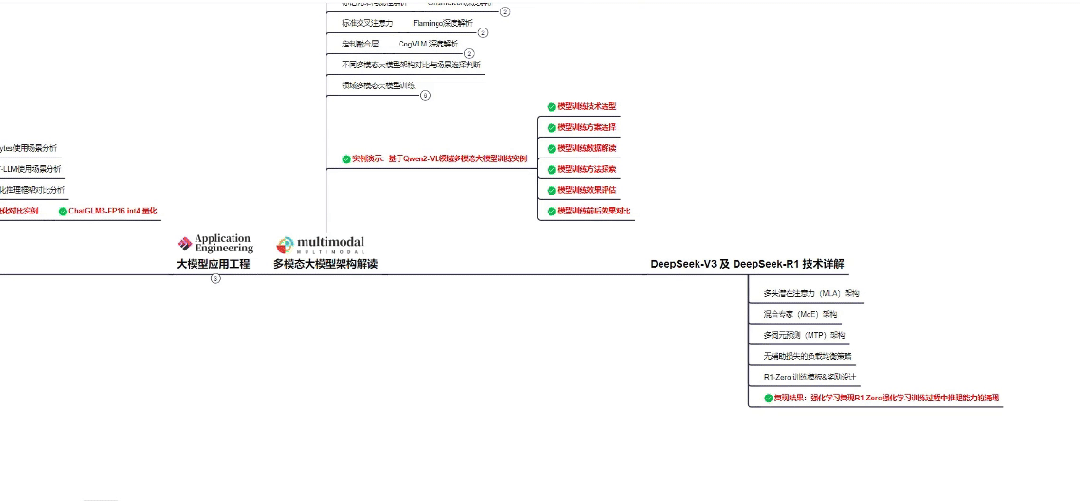
👇微信扫描下方二维码即可~

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
02 大模型学习书籍&文档
新手必备的权威大模型学习PDF书单来了!全是一系列由领域内的顶尖专家撰写的大模型技术的书籍和学习文档(电子版),从基础理论到实战应用,硬核到不行!
※(真免费,真有用,错过这次拍大腿!)

03 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
04 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
05 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

06 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
由于篇幅有限
只展示部分资料
并且还在持续更新中…
ps:微信扫描即可获取
加上后我将逐一发送资料
与志同道合者共勉
真诚无偿分享!!!
最后,祝大家学习顺利,抓住机遇,共创美好未来!


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献342条内容
已为社区贡献342条内容

所有评论(0)