大模型推理并行
目前大模型的参数以及计算量越来越大,如果放在多卡上处理成为关键,这里简单记录一下每种并行策略的概念。目前大模型核心就是gemm、FFN(MLP)、attention, 所以下面的说明也以这三个算子作为说明。每个gpu上储存一份模型参数,通过切分batch来实现并行推理。
·
参考
https://zhuanlan.zhihu.com/p/622212228
背景
目前大模型的参数以及计算量越来越大,如果放在多卡上处理成为关键,这里简单记录一下每种并行策略的概念。目前大模型核心就是gemm、FFN(MLP)、attention, 所以下面的说明也以这三个算子作为说明。
流水线并行
就是把一个模型每个op放在一个gpu上执行,其中每一行是一个gpu,这样gpu的利用率就会比较高。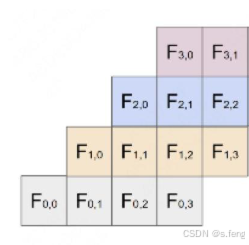
数据并行
每个gpu上储存一份模型参数,通过切分batch来实现并行推理
张量并行
gemm乘法
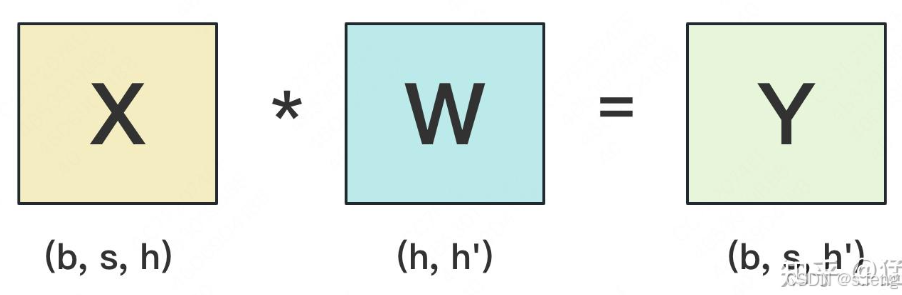
如果分到不同的gpu上的时候有两种方式:
第一种: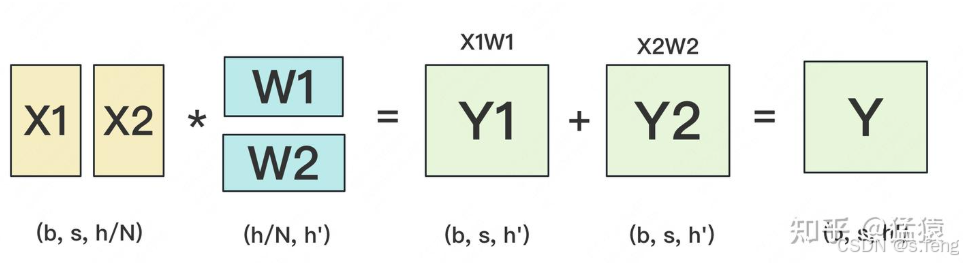
第二种: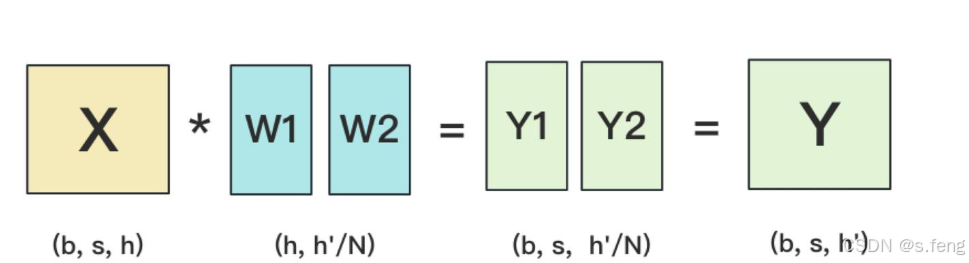
FFN
原始算法: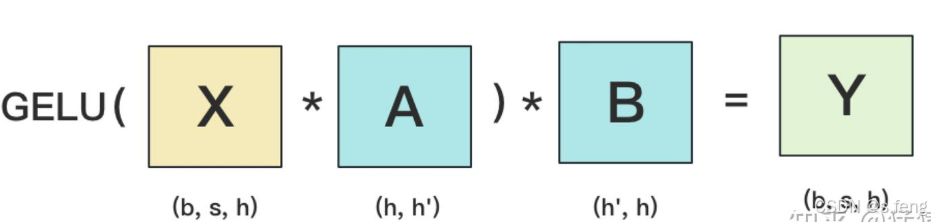
并行方式:
其实就是上面两个gemm的综合:
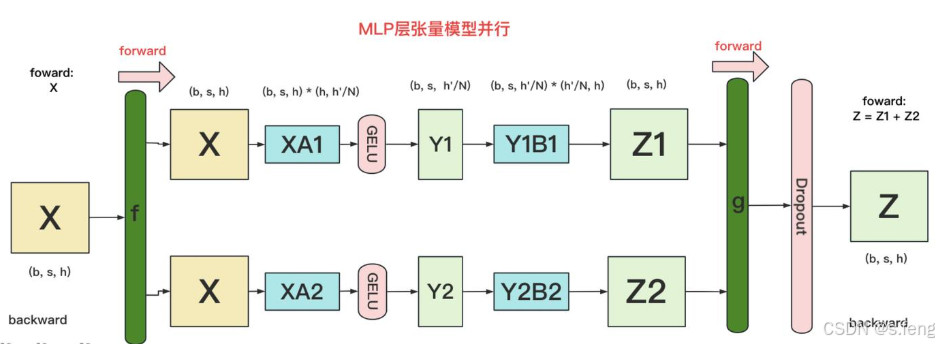
attention
核心还是上面那个gemm切分方式,由于multi-head天生就有一个并行的算法优势,所以这里可以直接按照头去切分。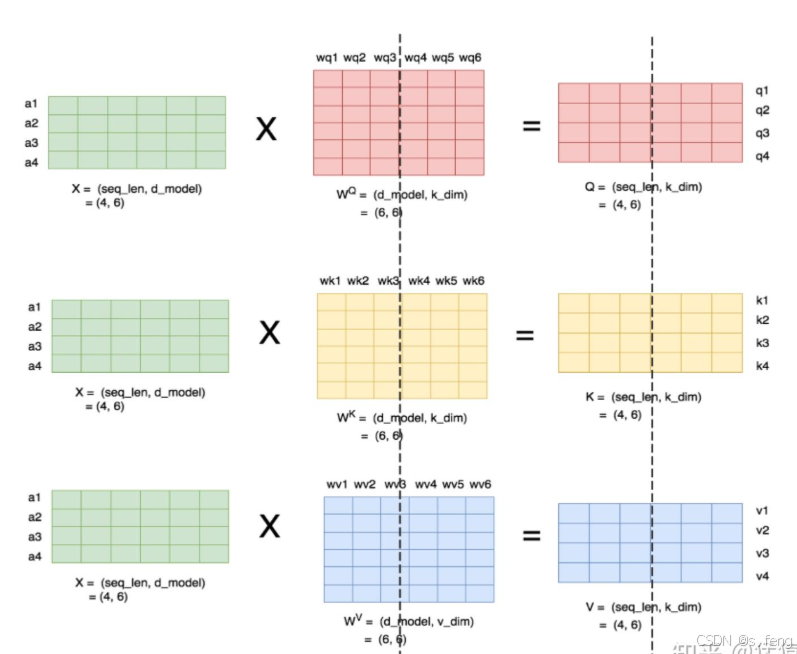
一般情况下,self-attention在结尾还有一个gemm,所以后面可以采用gemm的切分方式: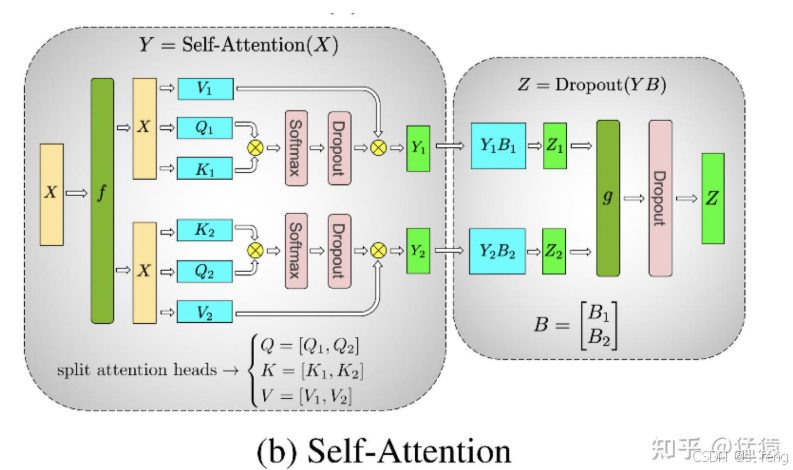
可以看到通讯部分就是最后的all-reduce,为啥要all-reduce呢,因为后面的ffn需要一个整块的输入。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)