像人类一样学习:通过自适应难度课程学习和专家引导的自我重构提升LLM推理能力
张恩慈 1,2{ }^{1,2}1,2, 严兴昂 1{ }^{1}1, 林伟 1∗{ }^{1 *}1∗, 张天翔 1{ }^{1}1, 卢乾春 1{ }^{1}11{ }^{1}1 中兴通讯南京研发中心有线产品操作部,中国南京2{ }^{2}2 北京大学深圳研究生院电子与计算机工程系,中国深圳电子邮件: eczhang@stu.pku.edu.cn, weilincs@pku.org.cn尽管在
张恩慈 1,2{ }^{1,2}1,2, 严兴昂 1{ }^{1}1, 林伟 1∗{ }^{1 *}1∗, 张天翔 1{ }^{1}1, 卢乾春 1{ }^{1}1
1{ }^{1}1 中兴通讯南京研发中心有线产品操作部,中国南京
2{ }^{2}2 北京大学深圳研究生院电子与计算机工程系,中国深圳
电子邮件: eczhang@stu.pku.edu.cn, weilincs@pku.org.cn
摘要
尽管在数学推理等领域取得了令人印象深刻的进展,大型语言模型在持续解决复杂问题方面仍面临重大挑战。受关键人类学习策略的启发,我们提出了两种新策略以增强大型语言模型解决这些复杂问题的能力。首先,自适应难度课程学习(ADCL)是一种新颖的课程学习策略,它通过周期性重新评估即将数据批次的难度来应对“难度偏移”现象(即模型对问题难度的感知在训练过程中动态变化),从而保持与模型不断演变的能力相一致。其次,专家引导的自我重构(EGSR)是一种新颖的强化学习策略,它通过引导模型在其自身概念框架内重构专家解决方案,而非依赖直接模仿,弥合了模仿学习和纯探索之间的差距,从而促进更深层次的理解和知识同化。使用Qwen2.5-7B作为基础模型,在具有挑战性的数学推理基准上的广泛实验表明,这些受人类启发的策略协同且显著地提高了性能。值得注意的是,它们的联合应用使AIME24基准上的性能比标准Zero-RL基线提高了10%10 \%10%,并在AIME25上提高了16.6%16.6 \%16.6%。
1 引言
大型语言模型(LLMs)中的复杂推理领域格局因最近的突破而发生了巨大变化,这以OpenAI-o1(OpenAI et al., 2024)和DeepSeek-R1(DeepSeek-AI et al., 2025)等模型为代表。这些模型在生成广泛的思维链(CoT)(Wei
等人, 2022年) 和展示诸如自我反思等复杂行为方面表现出色,特别是在具有挑战性的数学问题求解领域。这种进步背后的一个关键训练范式是Zero-RL (DeepSeek-AI et al., 2025; Liu et al., 2025; Zeng et al., 2025),它直接将强化学习(RL)应用于基础模型。这种方法独特地利用了基于策略的回滚和基于规则的奖励来引发并显著增强内在推理能力,通常超越了仅通过监督微调(SFT)所能达到的复杂任务性能。Zero-RL的成功演示揭示了其在解锁LLMs更深推理能力方面的巨大潜力。
Zero-RL范式在增强复杂推理方面已被证明相当有效。然而,我们的研究表明仍有改进空间。具体而言,我们在两个主要领域看到了潜在机会:首先,通过更具战略性的数据安排来提高学习效果。其次,我们旨在推动模型能力的边界,帮助它超越其策略探索中的固有限制。
首先,虽然课程学习(CL)(Deng et al., 2025; Wen et al., 2025; Bengio et al., 2009) 已被广泛采用,以预定义的难度指标结构化从易到难的学习进程,但它面临一个关键限制:模型对难度的感知本质上是动态的,并在训练过程中不断演变。直接应用静态难度定义会导致与模型实时学习需求不匹配的课程,最终导致次优的训练结果。其次,扩展模型能力边界的挑战构成了RL中的另一个基本约束。当前方法,包括Zero-RL范式,主要依赖于仅依赖自动生成回滚的策略内方法。这造成了一个内在限制:模型的能力提升受到其预训练知识库的约束,因为它缺乏暴露于其初始能力之外的外部推理模式的机会。因此,这些方法主要强化现有专长,而不是培养真正新颖的推理能力(Yue et al., 2025)。
人类学习过程为应对这些挑战提供了重要见解。考虑学生如何处理习题册:他们并非严格遵循固定的难度序列,而是根据个人能力水平和感知任务难度动态调整学习路径。例如,学习者通常优先处理他们表现较强的领域(如微积分),然后再处理更具挑战性的领域(如线性代数)。当遇到特别困难的问题时,学习者通常不会死记硬背解答,而是通过自我重构进行认知过程,即通过用自己的概念框架重新表述解决方案来实现对底层方法论的真实掌握。
受这些人类学习特征的启发,我们提出了两种新训练策略以增强Zero-RL训练范式:(1)自适应难度课程学习(ADCL)通过周期性难度重新评估来调整课程,解决了动态难度感知的挑战,促进了更优化的学习轨迹。(2)专家引导的自我重构(EGSR)通过使模型能够从高质量的外部推理路径中学习,解决了策略内探索的限制。这是通过非单纯模仿,而是引导模型主动重构和内化专家解决方案,从而促进超出其初始范围的新推理能力的发展。
本文的主要贡献如下:
- 理论见解:人类学习机制揭示了动态难度适应和知识的自我重构对于克服模型训练中静态课程设计和策略内探索的局限性至关重要。
-
- 新策略:ADCL通过周期性重新评估即将到来的数据批次中的难度,动态调整训练课程,与模型不断演变的能力相一致。EGSR通过引导模型在其自身概念框架内重构专家解决方案,而非直接模仿,实现了知识同化。
-
- 全面实验:我们的实验确认了所提出的ADCL和EGSR策略的有效性,它们协同增强了Zero-RL基线的数学推理能力。值得注意的是,它们的联合应用使AIME24基准上的性能比标准Zero-RL基线提高了10%10 \%10%,并在AIME25上提高了16.6%。
2 相关工作
2.1 LLMs的课程学习
CL是一种训练策略,它通过系统地增加训练数据的复杂度来模仿人类学习的进展,通常遵循由易到难的轨迹。这一原则在各种机器学习领域中展示了显著的效果,从计算机视觉(CV)(Guo et al., 2018; Jiang et al., 2014) 和自然语言处理(NLP)(Platanios et al., 2019; Tay et al., 2019) 到强化学习(RL),以及LLMs的预训练(Zhang et al., 2025) 和后训练(Wang et al., 2025; Shi et al., 2025) 阶段都得到了广泛应用。
特别是对于LLMs的强化微调(RFT),CL策略正越来越多地被采用以优化训练过程并提高模型性能(Lee et al., 2024; Naïr et al., 2024; Team et al., 2025; Deng et al., 2025)。许多当前的CL应用依赖于静态课程,其中任务难度是预先确定的,数据也相应策划。例如,任务可能按固定难度级别分配(Team et al., 2025),或根据预定义的影响措施选择数据子集(Lee et al., 2024)。虽然这种预定义的课程在某些场景如指令调优和编码中已显示出有效性(Lee et al., 2024; Naïr et al., 2024),但它们可能无法动态适应模型的演化学习状态。为了解决静态课程的这一局限性,我们提出了ADCL策略,它通过周期性重新评估即将到来的数据批次中的难度来动态调整训练课程,与模型不断演变的能力相一致。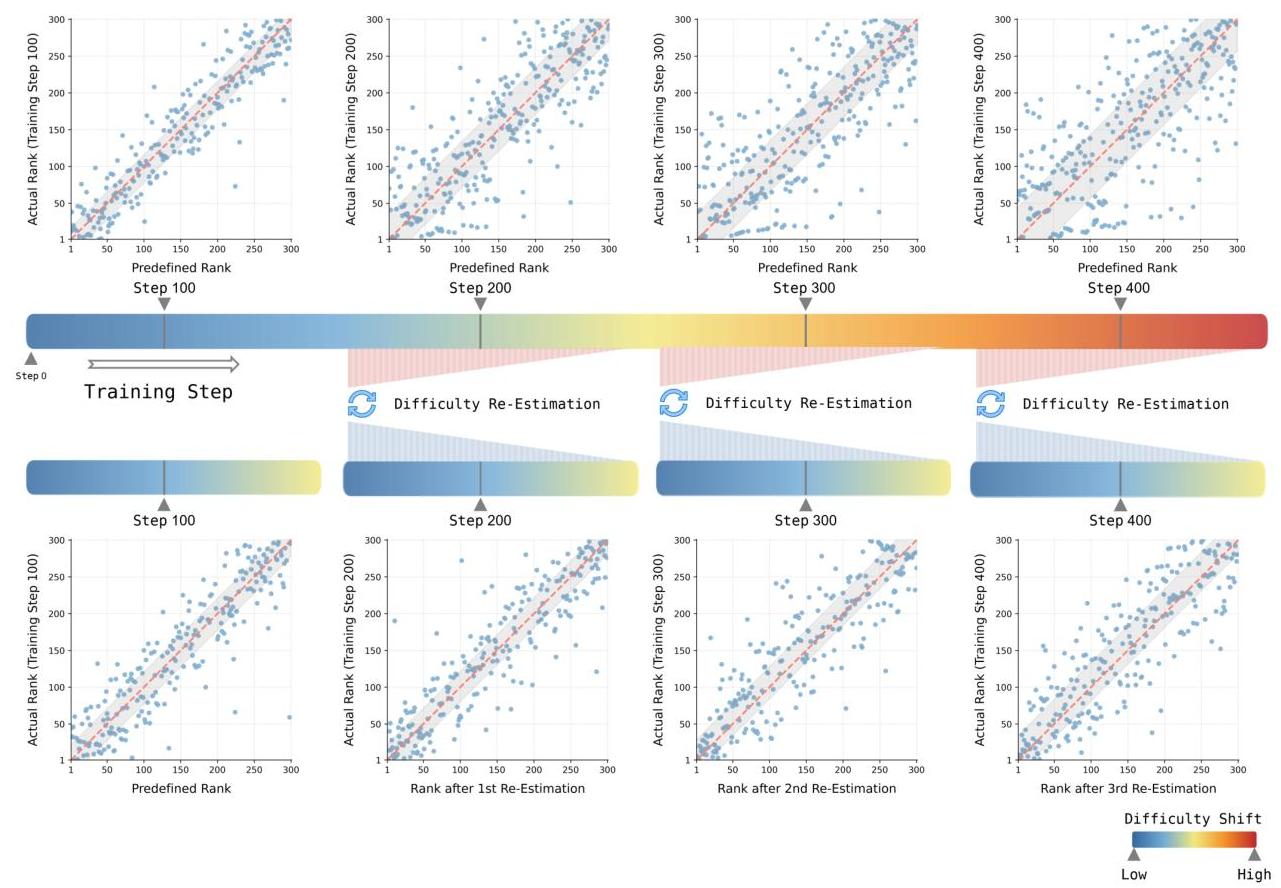
图1:难度偏移现象及其ADCL对策的插图。顶行:散点图显示使用预定义课程时,初始预定义排名(x轴)与模型不断演变的实际排名(y轴)之间逐渐增加的差异,说明随着训练步骤的增加,难度偏移越来越大。底行:ADCL基于当前模型状态进行周期性难度重新评估以重新排序即将到来的批次。这种动态调整使模型的实际排名(y轴)更接近批次重新估计的排名顺序(x轴),纠正了使用预定义课程观察到的难度偏移。
2.2 LLMs的强化学习
强化学习(RL)方法根据数据利用情况分为基于策略和离策略技术。基于策略的算法,如PPO (Schulman et al., 2017) 和TRPO (Schulman et al., 2015),从当前策略生成的数据中学习,确保稳定性但通常需要大量数据。相反,离策略技术,如DQN (Mnih et al., 2013) 和SAC (Haarnoja et al., 2018),利用来自不同策略的数据,提高数据效率但可能引入不稳定性和复杂性。
在后训练阶段,基于策略的方法如PPO和GRPO (Team, 2024) 已成为事实上的标准。尽管也有探索离策略方法如DPO (Rafailov et al., 2023),但关键挑战在于整合丰富的离策略专家数据(如示范)与基于策略的稳定性。直接整合往往由于学习策略与专家策略之间的显著分布差异而导致训练不稳定,产生高方差的重要性权重。我们提出EGSR策略通过使用专家示范指导当前策略生成改进的、更基于策略的轨迹来解决这个问题。这促进了稳定的知识内化和能力扩展,超越了典型的基于策略的限制。
3 方法
3.1 自适应难度课程学习
CL是一种受人类认知启发的训练策略,模型从较简单到较复杂的例子逐步学习。然而,一个关键挑战是,模型对难度的感知随着其内部状态在训练过程中动态变化(我们称之为“难度偏移”现象)。这种动态变化可能导致最初的固定难度排名(Deng et al., 2025; Wen et al., 2025) 越来越不准确,使呈现的课程与模型的实时学习需求不匹配,可能阻碍最佳训练进展。
我们在图1中提供了“难度偏移”现象的经验证据。可视化通过颜色编码进度条(从左到右方向)展示了数据集的训练进展。顶面板说明了使用预定义CL方法与预定义难度顺序的训练过程,该顺序由基础模型建立。
为了分析这种转变,我们在这种预定义课程训练期间提取了几个模型检查点。对于每个检查点,我们通过在紧随其后的300个数据点上评估其当前难度感知来进行评估,并根据该特定检查点实现的准确性对其进行排名。所得实际难度排名(y轴)与原始预定义排名(x轴,单调递增从1到300)在对应于每个检查点标记的散点图中绘制。这些图中的灰色阴影区域代表实际排名(y值)与预定义排名(x值)之间偏差的第25至第75百分位范围。如图1顶部进展所示,使用预定义课程进行训练导致散点图中分散逐渐增加和该分位数范围扩大,两者均表明随着时间推移难度偏移更大。我们将这种难度偏移的增加归因于训练过程中模型与初始模型的偏离程度增加。
为对抗这种有害的难度偏移同时保持计算可行性,我们提出了自适应难度课程学习(ADCL),这是一种动态难度感知的训练策略。与依赖固定预定义顺序或像标准自我节奏学习(SPL)(Kumar et al., 2010) 那样重新评估整个数据集不同,ADCL利用基于模型当前状态的动态难度重新评估来重新排序即将到来的数据批次。这类似于人类根据感知任务难度动态调整学习路径,而非严格遵循固定顺序。
我们ADCL算法的核心机制在于基于模型不断演变的状态对即将到来的数据批次进行动态重新评估和重新排序。该算法通过以下步骤运行:
- 初始难度评估:过程开始时,使用初始模型参数θ0\theta_{0}θ0 计算数据集D\mathcal{D}D中所有样本的初始难度得分δ0(xi)\delta_{0}\left(x_{i}\right)δ0(xi)。这些得分来源于在NNN个评估样本上计算的准确性指标。根据这些得分对D\mathcal{D}D进行排序后,数据集被划分为KKK个连续批次{B1,B2,…,BK}\left\{B_{1}, B_{2}, \ldots, B_{K}\right\}{B1,B2,…,BK}。
-
- 迭代训练与动态调整:然后算法迭代通过这些批次。在迭代kkk中,通过使用RL算法(如GRPO)在批次BkB_{k}Bk上训练,将模型参数θk−1\theta_{k-1}θk−1更新为θk\theta_{k}θk。
-
- 进步重新排序:参数更新后,ADCL使用更新后的模型θk\theta_{k}θk 对下一个批次Bk+1B_{k+1}Bk+1中的元素重新评估难度得分δk(xi)\delta_{k}\left(x_{i}\right)δk(xi)。然后根据新的难度评估对该批次进行内部重新排序,再进入下一个迭代。这种局部、渐进的重新排序继续直到所有批次都被处理,最终得到最终模型参数θK\theta_{K}θK。
ADCL的详细伪代码见附录A。
- 进步重新排序:参数更新后,ADCL使用更新后的模型θk\theta_{k}θk 对下一个批次Bk+1B_{k+1}Bk+1中的元素重新评估难度得分δk(xi)\delta_{k}\left(x_{i}\right)δk(xi)。然后根据新的难度评估对该批次进行内部重新排序,再进入下一个迭代。这种局部、渐进的重新排序继续直到所有批次都被处理,最终得到最终模型参数θK\theta_{K}θK。
如图1底部面板所示,ADCL在训练过程中多次动态重新评估即将到来的批次难度,与预定义CL相比显著纠正了难度偏差。
ADCL比标准SPL更适合LLM后训练,主要是由于其计算效率和为此阶段量身定制的设计。标准SPL需要迭代重新评估整个数据集,这对大规模LLM来说计算上是不可行的。在后训练阶段,虽然难度偏移显著,但模型的演变和批次间的变化比从头训练更为渐进。因此,ADCL仅重新排名下一个批次的策略充分解决了局部变化,平衡了课程响应性与LLM后训练的计算可行性。
3.2 专家引导的自我重构
LLMs的RL,特别是在推理任务中,通常作为一种提高样本效率的过程。尽管RL可以显著提高准确性
JGRPO (θ)=E[q∼P(Q),{τi}i=1G∼πθold(⋅∣q)]1G∑i=1G1∣τi∣∑t=1∣τi∣{min[ri,t(θ)Ai,clip(ri,t(θ),1−ϵ,1+ϵ)Ai]−βDKL[πθ∥πref]} where ri,t(θ)=πθ(τi,t∣q,τi,<t)πθold (τi,t∣q,τi,<t) and Ai=R(τi)−mean({R(τk)}k=1G)std({R(τk)}k=1G)JGRPO-EGSR (θ)=E[q,g∼P(Q),{τi}i=1G∼πθold(⋅∣q),{τi′}i=1M∼πθold(⋅∣q,g)]1G−M∑i=1G−M1∣τi∣∑i=1∣τi′∣{min[ri,t(θ)Ai,clip(ri,t(θ),1−ϵ,1+ϵ)Ai]−βDKL[πθ∥πref]}+1M∑i=1M1∣τi′∣∑t=1∣τi′∣{min[ri,t′(θ)Ai,clip(ri,t′(θ),1−ϵ,1+ϵ)Ai]−βDKL[πθ∥πref]} where ri,t(θ)=πθ(τi,t∣q,τi,<t)πθold (τi,t∣q,τi,<t),ri,t′(θ)=πθ(τi,t′∣q,τi,<t′)πθold (τi,t′∣q,g,τi,<t′) and Ai=R(τi)−mean({R(τk)}k=1G−M+{R(τk′)}k=1M)std({R(τk)}k=1G−M+{R(τk′)}k=1M) \begin{aligned} \mathcal{J}_{\text {GRPO }}(\theta)= & \mathbb{E}\left[q \sim P(Q), \left\{\tau_{i}\right\}_{i=1}^{G} \sim \pi_{\theta_{o l d}}(\cdot \mid q)\right] \\ & \frac{1}{G} \sum_{i=1}^{G} \frac{1}{\left|\tau_{i}\right|} \sum_{t=1}^{\left|\tau_{i}\right|}\left\{\min \left[r_{i, t}(\theta) A_{i}, \operatorname{clip}\left(r_{i, t}(\theta), 1-\epsilon, 1+\epsilon\right) A_{i}\right]-\beta \mathbb{D}_{K L}\left[\pi_{\theta} \| \pi_{r e f}\right]\right\} \\ & \text { where } r_{i, t}(\theta)=\frac{\pi_{\theta}\left(\tau_{i, t} \mid q, \tau_{i,<t}\right)}{\pi_{\theta_{\text {old }}}\left(\tau_{i, t} \mid q, \tau_{i,<t}\right)} \quad \text { and } \quad A_{i}=\frac{R\left(\tau_{i}\right)-\operatorname{mean}\left(\left\{R\left(\tau_{k}\right)\right\}_{k=1}^{G}\right)}{\operatorname{std}\left(\left\{R\left(\tau_{k}\right)\right\}_{k=1}^{G}\right)} \\ & \mathcal{J}_{\text {GRPO-EGSR }}(\theta)=\mathbb{E}\left[q, g \sim P(Q), \left\{\tau_{i}\right\}_{i=1}^{G} \sim \pi_{\theta_{o l d}}(\cdot \mid q),\left\{\tau_{i}^{\prime}\right\}_{i=1}^{M} \sim \pi_{\theta_{o l d}}(\cdot \mid q, g)\right] \\ & \frac{1}{G-M} \sum_{i=1}^{G-M} \frac{1}{\left|\tau_{i}\right|} \sum_{i=1}^{\left|\tau_{i}^{\prime}\right|}\left\{\min \left[r_{i, t}(\theta) A_{i}, \operatorname{clip}\left(r_{i, t}(\theta), 1-\epsilon, 1+\epsilon\right) A_{i}\right]-\beta \mathbb{D}_{K L}\left[\pi_{\theta} \| \pi_{r e f}\right]\right\} \\ & +\frac{1}{M} \sum_{i=1}^{M} \frac{1}{\left|\tau_{i}^{\prime}\right|} \sum_{t=1}^{\left|\tau_{i}^{\prime}\right|}\left\{\min \left[r_{i, t}^{\prime}(\theta) A_{i}, \operatorname{clip}\left(r_{i, t}^{\prime}(\theta), 1-\epsilon, 1+\epsilon\right) A_{i}\right]-\beta \mathbb{D}_{K L}\left[\pi_{\theta} \| \pi_{r e f}\right]\right\} \\ & \text { where } r_{i, t}(\theta)=\frac{\pi_{\theta}\left(\tau_{i, t} \mid q, \tau_{i,<t}\right)}{\pi_{\theta_{\text {old }}}\left(\tau_{i, t} \mid q, \tau_{i,<t}\right)}, r_{i, t}^{\prime}(\theta)=\frac{\pi_{\theta}\left(\tau_{i, t}^{\prime} \mid q, \tau_{i,<t}^{\prime}\right)}{\pi_{\theta_{\text {old }}}\left(\tau_{i, t}^{\prime} \mid q, g, \tau_{i,<t}^{\prime}\right)} \\ & \text { and } \quad A_{i}=\frac{R\left(\tau_{i}\right)-\operatorname{mean}\left(\left\{R\left(\tau_{k}\right)\right\}_{k=1}^{G-M}+\left\{R\left(\tau_{k}^{\prime}\right)\right\}_{k=1}^{M}\right)}{\operatorname{std}\left(\left\{R\left(\tau_{k}\right)\right\}_{k=1}^{G-M}+\left\{R\left(\tau_{k}^{\prime}\right)\right\}_{k=1}^{M}\right)} \end{aligned} JGRPO (θ)=E[q∼P(Q),{τi}i=1G∼πθold(⋅∣q)]G1i=1∑G∣τi∣1t=1∑∣τi∣{min[ri,t(θ)Ai,clip(ri,t(θ),1−ϵ,1+ϵ)Ai]−βDKL[πθ∥πref]} where ri,t(θ)=πθold (τi,t∣q,τi,<t)πθ(τi,t∣q,τi,<t) and Ai=std({R(τk)}k=1G)R(τi)−mean({R(τk)}k=1G)JGRPO-EGSR (θ)=E[q,g∼P(Q),{τi}i=1G∼πθold(⋅∣q),{τi′}i=1M∼πθold(⋅∣q,g)]G−M1i=1∑G−M∣τi∣1i=1∑∣τi′∣{min[ri,t(θ)Ai,clip(ri,t(θ),1−ϵ,1+ϵ)Ai]−βDKL[πθ∥πref]}+M1i=1∑M∣τi′∣1t=1∑∣τi′∣{min[ri,t′(θ)Ai,clip(ri,t′(θ),1−ϵ,1+ϵ)Ai]−βDKL[πθ∥πref]} where ri,t(θ)=πθold (τi,t∣q,τi,<t)πθ(τi,t∣q,τi,<t),ri,t′(θ)=πθold (τi,t′∣q,g,τi,<t′)πθ(τi,t′∣q,τi,<t′) and Ai=std({R(τk)}k=1G−M+{R(τk′)}k=1M)R(τi)−mean({R(τk)}k=1G−M+{R(τk′)}k=1M)
在模型偶尔能解决的问题上(例如,成功率从1%1 \%1% 提高到 99%99 \%99%),但从根本上来说,它很难诱发出模型完全不具备当前能力的问题的解决方案(即从0%0 \%0% 成功率过渡)。这种局限性意味着基础模型的内在知识限制了通过标准RL技术可实现的性能上限;模型无法学习解决最初完全没有能力尝试的问题(Yue et al., 2025)。
某些RL算法的标准目标,如方程1中详述的GRPO,旨在通过从先前策略πθold \pi_{\theta_{\text {old }}}πθold 中采样的GGG 条轨迹{τi}i=1G\left\{\tau_{i}\right\}_{i=1}^{G}{τi}i=1G 来优化策略πθ\pi_{\theta}πθ。然而,在实际训练场景中使用此类算法时常遇到“零奖励”情况。这种情况发生在所有GGG 条从πθold \pi_{\theta_{\text {old }}}πθold 中生成的轨迹都获得零奖励时,即对于所有iii,R(τi)=0R\left(\tau_{i}\right)=0R(τi)=0。虽然由于有限的轨迹数量导致的探索不足可能会有所贡献,但这种结果主要源于问题的复杂性超出了模型当前的推理能力。在这种零奖励情况下,所有动作的优势估计A^i,t\hat{A}_{i, t}A^i,t 实际上都会消失,导致空梯度更新,无法对策略改进做出贡献。这种学习僵局凸显了需要结合外部指导,通过
离策略专家策略πϕ\pi_{\phi}πϕ。这种指导通常通过该策略生成的示范提供有意义的学习信号,并可能向模型注入超出其当前能力的知识。
一种利用该专家策略指导的直接方法是用MMM个专家示范替换部分在线策略轨迹(Hester et al., 2018; Liu et al., 2022),创建混合轨迹集Tmixed =Ton ∪Toff \mathcal{T}_{\text {mixed }}=\mathcal{T}_{\text {on }} \cup \mathcal{T}_{\text {off }}Tmixed =Ton ∪Toff ,其中Ton ={τi∣τi∼πθold (⋅∣q),i=1,…,G−M}\mathcal{T}_{\text {on }}=\left\{\tau_{i} \mid \tau_{i} \sim \pi_{\theta_{\text {old }}}(\cdot \mid q), i=1, \ldots, G-M\right\}Ton ={τi∣τi∼πθold (⋅∣q),i=1,…,G−M}和Toff ={τj∣τj∼πϕ(⋅∣q),j=1,…M}\mathcal{T}_{\text {off }}=\left\{\tau_{j} \mid \tau_{j} \sim \pi_{\phi}(\cdot \mid q), j=1, \ldots M\right\}Toff ={τj∣τj∼πϕ(⋅∣q),j=1,…M}。当结合离策略示范时,必须应用重要性采样以校正分布偏移,修改GRPO目标中的概率比率如下:
ri,t(θ)={πθ(τi,t∣q,τi,<t)πθold (τi,t∣q,τi,<t), if τi∈Ton πθ(τi,t∣q,τi,<t)πϕ(τi,t∣q,τi,<t), if τi∈Toff r_{i, t}(\theta)= \begin{cases}\frac{\pi_{\theta}\left(\tau_{i, t} \mid q, \tau_{i,<t}\right)}{\pi_{\theta_{\text {old }}}\left(\tau_{i, t} \mid q, \tau_{i,<t}\right)}, & \text { if } \tau_{i} \in \mathcal{T}_{\text {on }} \\ \frac{\pi_{\theta}\left(\tau_{i, t} \mid q, \tau_{i,<t}\right)}{\pi_{\phi}\left(\tau_{i, t} \mid q, \tau_{i,<t}\right)}, & \text { if } \tau_{i} \in \mathcal{T}_{\text {off }}\end{cases} ri,t(θ)={πθold (τi,t∣q,τi,<t)πθ(τi,t∣q,τi,<t),πϕ(τi,t∣q,τi,<t)πθ(τi,t∣q,τi,<t), if τi∈Ton if τi∈Toff
优势估计计算如下:
Ai=R(τi)−mean(R(τmixed ))std(R(τmixed )) A_{i}=\frac{R\left(\tau_{i}\right)-\operatorname{mean}\left(R\left(\tau_{\text {mixed }}\right)\right)}{\operatorname{std}\left(R\left(\tau_{\text {mixed }}\right)\right)} Ai=std(R(τmixed ))R(τi)−mean(R(τmixed ))
尽管这种重要性采样方法理论上是合理的,但在实践中专家策略πϕ\pi_{\phi}πϕ 通常是不可访问的或使用不兼容的标记方案,使得概率比率计算变得不可行。即使πϕ\pi_{\phi}πϕ 可用,政策之间的显著分布差异通常会产生极端的重要权值,具有破坏性的方差。我们在第4.2节的实验表明,错误地将专家示范视为在线样本可能会降低复杂推理任务的性能。
我们认为核心问题在于由外部策略πϕ\pi_{\phi}πϕ 生成的参考解决方案轨迹与当前策略πθ\pi_{\theta}πθ 自然生成的轨迹之间的分布不匹配。试图通过重要性采样直接强制πθ\pi_{\theta}πθ 适合πϕ\pi_{\phi}πϕ 的输出会带来上述实际困难和潜在不稳定性。受人类学习类比重述解决方案的启发,我们提出了一种方法,绕过了估算πϕ\pi_{\phi}πϕ 或处理大重要权值的需要。我们不是直接纳入离策略轨迹τj∼πϕ\tau_{j} \sim \pi_{\phi}τj∼πϕ,而是使用专家示范来指导πθold \pi_{\theta_{\text {old }}}πθold 生成更有效的轨迹τi′∼πθold (⋅∣q,g)\tau_{i}^{\prime} \sim \pi_{\theta_{\text {old }}}(\cdot \mid q, g)τi′∼πθold (⋅∣q,g),其中ggg 表示指导信息。类似于学生通过用自己的话重新表述解决方案来学习的方式,这种方法生成的轨迹自然与模型当前能力对齐,同时融入了专家知识。这种引导生成创建了保持根本“在线”性质的同时,弥合了向专家表现过渡的样本。
为了实证验证我们的假设,我们通过多个训练检查点对四种不同的轨迹类型进行了系统的模型困惑度
(PPL) 评估,使用300个由(q,s,a)(q, s, a)(q,s,a)三元组(问题、专家解决方案、答案)定义的经典问题实例,结果如图2所示。我们评估了PPL对于:(1) 未引导的模型生成τq\boldsymbol{\tau}_{\boldsymbol{q}}τq,(2) 参考专家解决方案sss,(3) 由sss和aaa共同引导的模型生成轨迹τs,a\boldsymbol{\tau}_{\boldsymbol{s}, \boldsymbol{a}}τs,a,和(4) 仅由aaa引导的轨迹τa\boldsymbol{\tau}_{\boldsymbol{a}}τa。
为了验证我们的假设,我们通过多个训练检查点对四种不同的轨迹类型进行了实验测量模型的困惑度(PPL),使用300个由(q,s,a)(q, s, a)(q,s,a)三元组(问题、专家解决方案、答案)定义的问题;这些结果如图2所示。我们评估了PPL对于:模型的未引导生成τq\boldsymbol{\tau}_{\boldsymbol{q}}τq,参考专家解决方案sss,由sss和aaa共同引导的模型生成轨迹τs,a\boldsymbol{\tau}_{\boldsymbol{s}, \boldsymbol{a}}τs,a,以及仅由aaa引导的轨迹τa\boldsymbol{\tau}_{\boldsymbol{a}}τa。在整个训练过程中,参考专家解决方案s(PPL(s))s(P P L(s))s(PPL(s))的PPL始终保持最高,而模型未引导输出τq(PPL(τq))\tau_{q}\left(P P L\left(\tau_{q}\right)\right)τq(PPL(τq))的PPL最低,作为其自然生成分布的基线。关键的是,发现τs,a\tau_{s, a}τs,a (PPL(τs,a))\left(P P L\left(\tau_{s, a}\right)\right)(PPL(τs,a))和τa(PPL(τa))\tau_{a}\left(P P L\left(\tau_{a}\right)\right)τa(PPL(τa))的PPL明显低于PPL(s)P P L(s)PPL(s),并且显著接近PPL(τq)P P L\left(\tau_{q}\right)PPL(τq)。这些PPL结果表明,引导模型生成解决方案产生的轨迹显著更符合其当前策略(即更“在线”)比直接使用离策略专家解决方案。
基于我们的PPL分析(图2),它表明在专家指导下由模型πθ\pi_{\theta}πθ生成的轨迹显著更符合其当前策略,而不是原始专家解决方案sss,我们提出了专家引导的自我重构(EGSR)。EGSR的训练目标如方程2所示,将MMM个专家引导的轨迹τi′∼πθold (⋅∣q,g)\tau_{i}^{\prime} \sim \pi_{\theta_{\text {old }}}(\cdot \mid q, g)τi′∼πθold (⋅∣q,g)(其中ggg是从专家策略πϕ\pi_{\phi}πϕ派生的指导)与G−MG-MG−M个标准回滚相结合,特别是在初始探索产生零奖励时。对于这些引导轨迹,比率ri,t′(θ)r_{i, t}^{\prime}(\theta)ri,t′(θ)相对于其特定生成策略πθold (⋅∣q,g)\pi_{\theta_{\text {old }}}(\cdot \mid q, g)πθold (⋅∣q,g)计算。这是因为我们的PPL发现表明,来自πθold (⋅∣q,g)\pi_{\theta_{\text {old }}}(\cdot \mid q, g)πθold (⋅∣q,g)的轨迹在分布上更接近模型的未引导输出,而不是来自原始专家策略πϕ\pi_{\phi}πϕ的轨迹,从而促进更稳定、近似在线的学习,同时仍然利用专家知识。EGSR的详细伪代码见附录B。
4 实验
4.1 设置
(1) 数据集:我们的数据集从高质量推理语料库中精心挑选,包括S1 (Muennighoff et al., 2025) 和DeepScaleR (Luo et al., 2025)。我们应用过滤标准以确保解决方案可通过Math-Verify 1{ }^{1}1 验证,并且问题需要计算而非基于证明的解决方案。我们使用Qwen2.5-7B作为基础模型估计问题难度,每道问题进行32次回滚以计算准确率。从这个评估中,我们创建了一个包含6,894道准确率在10%10 \%10% 至90%90 \%90% 之间的问题集合,称为BaseSet-7K。为了为我们EGSR方法提供更多实例用于指导,我们通过加入另外3,000道基础模型始终达到0%0 \%0% 准确率的问题补充了BaseSet7 K,形成了扩大的集合AugSet-10K。
(2) 基准测试:为了评估我们模型的数学推理能力,我们使用了五个既定基准:MATH500(Lightman et al.),AIME24 2{ }^{2}2,AIME25 3{ }^{3}3,AMC23 4{ }^{4}4 和Minervamath(Lewkowycz et al., 2022)。我们报告AIME24和AIME25的pass@8以减轻这些较小基准集上pass@1的高方差,并使用其他所有基准的标准pass@1。
(3) 设置:我们使用TRL(von Werra et al., 2020)实现了我们的训练框架,以Qwen2.5-7B作为基础模型。对于GRPO,我们每道问题使用8次回滚,全局批次大小为1024,固定学习率为1×10−61 \times 10^{-6}1×10−6。我们的奖励函数,受到(Team, 2024)的启发,是一个复合奖励:R(τ)=R(\tau)=R(τ)= λ1⋅Rformat (τ)+λ2⋅Raccuracy (τ)\lambda_{1} \cdot R_{\text {format }}(\tau)+\lambda_{2} \cdot R_{\text {accuracy }}(\tau)λ1⋅Rformat (τ)+λ2⋅Raccuracy (τ),其中
Rformat (τ)={1 if τ follows the output format 0 otherwise R_{\text {format }}(\tau)= \begin{cases}1 & \text { if } \tau \text { follows the output format } \\ 0 & \text { otherwise }\end{cases}Rformat (τ)={10 if τ follows the output format otherwise
和
Raccuracy (τ)={1 if τ contains the correct answer 0 otherwise R_{\text {accuracy }}(\tau)= \begin{cases}1 & \text { if } \tau \text { contains the correct answer } \\ 0 & \text { otherwise }\end{cases}Raccuracy (τ)={10 if τ contains the correct answer otherwise
,我们设置λ1=1.0\lambda_{1}=1.0λ1=1.0和λ2=2.0\lambda_{2}=2.0λ2=2.0。
对于ADCL策略,我们使用了BaseSet7 K数据集,我们的实现将课程分为四个基于难度的批次,并进行了三次难度重新评估。
对于EGSR策略,我们使用了AugSet10 K数据集,并探索了两种指导策略:仅使用专家的最终答案a(EGSR(a))a(\operatorname{EGSR}(a))a(EGSR(a)) 或使用答案aaa 和解决方案过程s(EGSR(s,a))s(\operatorname{EGSR}(s, a))s(EGSR(s,a))。我们实施了一种替换策略,仅当一个问题的所有8个初始模型回滚都产生零奖励时,才使用专家指导的轨迹代替原始模型回滚。考虑到GRPO的学习效果在成功率为约50%时最大化(Bae et al., 2025),我们在这些情况下生成并随后使用的轨迹数量为4。完整的超参数见附录C。
4.2 主要结果
我们的主要结果如表1所示。最初,我们观察到尽管SFT (+SFT) 在一些基准测试中略有改进,但其在更复杂的基准测试如AIME24和AIME25上的表现实际上比基础模型有所下降。相比之下,标准RL (+RL) 方法在大多数基准测试中带来了更显著和稳定的性能改进。这些发现表明RL比SFT更能适应复杂任务。
比较CL策略时,我们提出的自适应难度课程学习(+ADCL) 一直优于预定义课程学习(+PCL)。这种优势源于ADCL通过周期性重新评估和重新排序批次难度来动态对抗“难度偏移”现象的能力,从而保持与模型状态更有效的课程对齐。
转向专家指导,通过直接离策略指导简单纳入专家解决方案(+off-policy) 导致相对于+ RL基线性能下降。这一结果归因于专家轨迹与模型自身策略之间的显著分布不匹配,这可能会扰乱学习过程。相比之下,我们的EGSR策略,无论是EGSR(a)\operatorname{EGSR}(\mathrm{a})EGSR(a) 还是EGSR(s,a)\operatorname{EGSR}(\mathrm{s}, \mathrm{a})EGSR(s,a),都超过了这种简单方法,其中EGSR(s,a)在指导方法中取得了最有利的结果。虽然EGSR(a)仅使用最终专家答案进行指导,我们观察到它可能会
1{ }^{1}1 https://github.com/huggingface/Math-Verify
2{ }^{2}2 https://huggingface.co/datasets/hendrydong/aime24
3{ }^{3}3 https://huggingface.co/datasets/TIGER-Lab/AIME25
4{ }^{4}4 https://huggingface.co/datasets/zwhe99/amc23
| 模型 | MATH-500 | AIME 24 | AIME 25 | AMC23 | Minervamath |
|---|---|---|---|---|---|
| Qwen2.5-7B | 69.40 | 16.67 | 16.67 | 32.50 | 15.44 |
| + SFT | 70.80 | 13.33 | 13.33 | 35.00 | 16.91 |
| + RL | 72.40 | 26.67 | 16.67 | 45.00 | 18.01 |
| + PCL | 75.40 | 30.00 | 23.33 | 50.00 | 22.42 |
| + ADCL | 76.20 | 33.33‾\underline{33.33}33.33 | 30.00‾\underline{30.00}30.00 | 55.00 | 22.78 |
| + off-policy | 66.00 | 23.33 | 16.67 | 30.00 | 18.65 |
| + EGSR (α)(\alpha)(α) | 72.60 | 30.00 | 20.00 | 50.00 | 20.96 |
| + EGSR (s,α)(s, \alpha)(s,α) | 79.40‾\underline{79.40}79.40 | 33.33‾\underline{33.33}33.33 | 30.00‾\underline{30.00}30.00 | 57.50\mathbf{5 7 . 5 0}57.50 | 24.63‾\underline{24.63}24.63 |
| + ADCL & EGSR | 81.80\mathbf{8 1 . 8 0}81.80 | 36.67\mathbf{3 6 . 6 7}36.67 | 33.33\mathbf{3 3 . 3 3}33.33 | 55.00‾‾\underline{\underline{55.00}}55.00 | 25.74\mathbf{2 5 . 7 4}25.74 |
表1:Qwen2.5-7B在数学推理基准上使用各种训练策略的性能,Qwen2. 5-7B: 基础模型,+SFT: 监督微调,+RL: 标准GRPO算法,+PCL: 带预定义课程学习的GRPO,+ADCL: 带我们的自适应难度课程学习的GRPO,+off-policy: 带直接用专家解决方案替换回滚的GRPO,+EGSR (a)(a)(a) : 我们的ESGR方法仅使用专家答案(a)进行指导,+EGSR (s,a)(s, a)(s,a) : 我们的ESGR方法使用专家解决方案(sss)和答案(aaa)进行指导,+ADCL&EGSR: 结合我们的ADCL和EGSR (s,a)(s, a)(s,a) 方法。粗体和下划线表示第一和第二名。
引导模型生成通过有缺陷或不完整推理过程到达正确答案的轨迹,尽管这些轨迹可能表现出较低的困惑度。一个这样的场景的例子,即模型在仅由答案引导时正确预测答案但解决方案错误的情况,见附录E。通过结合来自专家解决方案过程和最终答案的指导,EGSR(s,a)鼓励模型在其自身的概念框架内重构更完整和连贯的推理路径,从而更有效地提高推理能力。
此外,我们提出的两种训练策略,ADCL和EGSR,可以协同组合以实现更好的性能。当一起使用(+ADCL & EGSR)时,这些策略相对于标准RL方法显示出显著的收益。具体而言,联合方法在AIME25上实现了16.66%16.66 \%16.66%的改进(33.33%33.33 \%33.33% vs 16.67%16.67 \%16.67%),在Minervamath上实现了7.73%7.73 \%7.73%的改进(25.74%25.74 \%25.74% vs 18.01%18.01 \%18.01%)相比+RL基线。
5 分析
5.1 ADCL训练动态
图3展示了不同策略下的ADCL训练动态。没有课程的标准RL(NoCL)显示出准确率奖励的稳定增长,反映了在随机采样问题上的逐渐学习。相比之下,基于课程的策略(ADCL和PCL),尽管由于问题难度增加,后期训练中准确率奖励有所下降,但与相应难度水平的基线原始准确率相比,始终维持更高的奖励。这证实了学习正在发生,奖励下降主要是由课程进展到更难的任务驱动的。我们提出的ADCL相对于PCL的关键优势在于其适应性。PCL的奖励曲线相对平滑地下降,因为其静态难度排名受到“难度偏移”的影响;训练批次不可避免地混合了相对于模型当前状态实际难度不同的样本,平均了感知挑战。然而,ADCL通过基于当前模型感知进行周期性难度重新评估和批次重新排序。这导致了更陡峭的奖励曲线,特别是在重新评估点之后,因为ADCL立即向模型呈现了一个根据其更新后的“简单到困难”感知顺序排列的批次。这种陡峭性表明,ADCL通过动态对齐课程与模型不断演变的能力,更准确和高效地实施了“简单到困难”原则,确保模型及时应对适当具有挑战性的问题。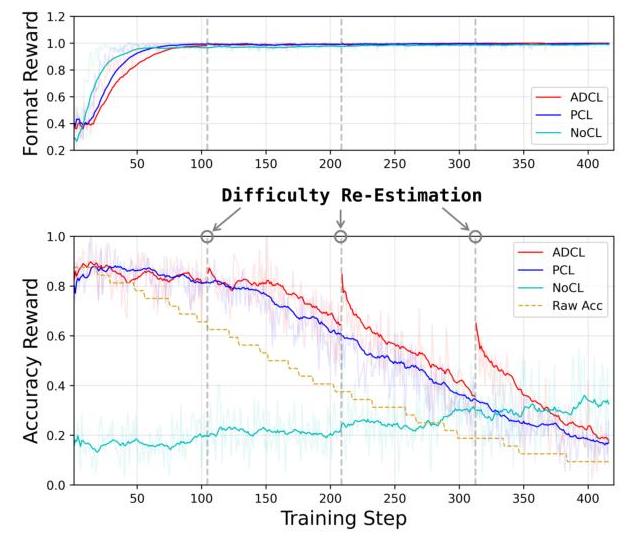
图3:不同训练策略下的奖励动态比较。曲线代表自适应难度课程学习(ADCL,红色)、预定义课程学习(PCL,蓝色)和无课程学习(NoCL,青色)。虚线黄色(Raw Acc)表示基线模型在课程排序数据上的表现。垂直虚线标记了ADCL执行难度重新评估的点。
| 课程批次 | NIR |
|---|---|
| 批次1(无重新评估) | 0.000 |
| 批次2(第一次重新评估后) | 0.331 |
| 批次3(第二次重新评估后) | 0.363 |
| 批次4(第三次重新评估后) | 0.369 |
表2:每次ADCL难度重新评估事件后,后续批次的重新排序差异量化,用归一化倒置率(NIR)测量。
5.2 定量ADCL重新排序动态
为了验证ADCL的重新排序机制,我们使用归一化倒置率(NIR)测量了批次内预定义和动态重新估计样本顺序之间的不一致。该指标计算样本对相对顺序翻转的比例(0≈0 \approx0≈ 相同,较高=更不同)。表2显示了每次前序难度重新评估事件后每个课程批次的NIR测量结果。比率从初始批次(批次1,未应用重新评估)的0增加到批次2、3和4的0.331,0.3630.331,0.3630.331,0.363 和 0.369(分别在第一次、第二次和第三次重新评估后处理)。这些显著的非零比率确认了发生了显著的重新排序(影响了33-37%的对)。这种递增的NIR趋势表明,随着训练的进行,底层的“难度偏移”变得更加明显,需要ADCL进行更大的适应。
5.3 专家指导对能力边界的影响
| 模型 | MATH-500 | AIME 25 | AMC23 | Minervamath |
|---|---|---|---|---|
| Qwen2.5-7B | 89.40 | 30.00 | 87.50 | 49.63 |
| + SFT | 90.20 | 23.33 | 90.00‾\underline{90.00}90.00 | 50.36 |
| + RL | 88.60 | 26.67 | 85.00 | 49.26 |
| + off-policy | 93.20‾\underline{93.20}93.20 | 40.00‾\underline{40.00}40.00 | 92.50\mathbf{9 2 . 5 0}92.50 | 51.47‾\underline{51.47}51.47 |
| + EGSR (s,a)(s, a)(s,a) | 93.40\mathbf{9 3 . 4 0}93.40 | 46.67\mathbf{4 6 . 6 7}46.67 | 92.50\mathbf{9 2 . 5 0}92.50 | 51.84\mathbf{5 1 . 8 4}51.84 |
表3:使用pass@32度量的模型性能比较,该度量通过允许广泛的探索更好地反映能力边界。粗体和下划线表示第一和第二佳性能。
为进一步调查专家指导是否真正扩展了模型的内在问题解决能力,我们使用pass@32度量评估了各种方法。与pass@1或pass@8相比,pass@32允许模型有显著更多的机会探索多样化的解决方案路径,提供对其基本能力边界的更清晰视图。表3中的结果显示,标准RL虽然在优化常见成功方面有效,但在扩展甚至稍微收缩模型的能力边界方面不如基础模型。SFT提供了边际改进。相比之下,结合专家指导的方法展示了这些边界的更显著扩展。值得注意的是,我们的EGSR(s,a)策略实现了最大的改进,在AIME25上将pass@32准确性提高了显著的16.67%16.67 \%16.67%,表明它促进了更深层次的知识同化,而不仅仅是细化现有技能。
6 结论
受人类学习策略的启发,这项工作解决了增强大型语言模型解决复杂任务能力的关键挑战。我们首先观察到“难度偏移”现象,即模型对问题难度的感知在训练过程中动态变化,阻碍了静态课程学习。为应对这一挑战,我们提出了自适应难度课程学习(ADCL),它通过周期性重新评估难度来保持对齐的学习路径。其次,认识到现有方法往往无法帮助模型同化超出其初始能力的知识,
我们引入了专家引导的自我重构(EGSR)。EGSR引导模型在其自身概念框架内积极重构专家解决方案,而非依赖直接模仿,促进更深层次的知识同化。实验确认了ADCL相较于预定义课程的显著改进,以及EGSR通过同化专家知识超越标准RL基线的有效性,从而扩展了模型能力。至关重要的是,它们的组合产生了优越的性能,显著改进了标准RL基线。这些发现突显了将适应性的类人学习机制纳入LLM训练的价值。
参考文献
Sanghwan Bae, Jiwoo Hong, Min Young Lee, Hanbyul Kim, Jeong Yeon Nam, 和 Donghyun Kwak. 2025. 面向推理导向强化学习的在线难度过滤。预印本,arXiv:2504.03380。
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, 和 Jason Weston. 2009. 课程学习。在第26届国际机器学习会议论文集,ICML '09,页41-48,纽约,美国。计算机协会。
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, 和其他181位。2025. Deepseek-r1:通过强化学习激励LLMs的推理能力。预印本,arXiv:2501.12948。
Huilin Deng, Ding Zou, Rui Ma, Hongchen Luo, Yang Cao, 和 Yu Kang. 2025. 使用课程强化学习提升视觉语言模型的泛化和推理能力。预印本,arXiv:2503.07065。
Sheng Guo, Weilin Huang, Haozhi Zhang, Chenfan Zhuang, Dengke Dong, Matthew R Scott, 和 Dinglong Huang. 2018. CurriculumNet:从大规模网络图像弱监督学习。在欧洲计算机视觉会议(ECCV)论文集,页135-150。
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, 和 Sergey Levine. 2018. Soft Actor-Critic:带有随机演员的离策略最大熵深度强化学习。在ICML,机器学习研究论文集第80卷,页18561865。PMLR。
Todd Hester, Matej Vecerik, Olivier Pietquin, Marc Lanctot, Tom Schaul, Bilal Piot, Dan Horgan, John
Quan, Andrew Sendonaris, Ian Osband, 和其他人。2018. 基于演示的深度Q学习。在AAAI人工智能会议论文集,第32卷。
Lu Jiang, Deyu Meng, Teruko Mitamura, 和 Alexander G Hauptmann. 2014. 易样本优先:零示例多媒体搜索的自步重排序。在第22届ACM国际多媒体会议论文集,页547-556。
M. Kumar, Benjamin Packer, 和 Daphne Koller. 2010. 自步学习用于潜变量模型。在神经信息处理系统进展会议论文集,第23卷。Curran Associates, Inc.
Bruce W Lee, Hyunsoo Cho, 和 Kang Min Yoo. 2024. 使用人类课程的指令调优。在计算语言学协会会议论文集:NAACL 2024,页1281-1309,墨西哥城,墨西哥。计算语言学协会。
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, 和 Vedant Misra. 2022. 使用语言模型解决定量推理问题。在第36届神经信息处理系统国际会议论文集,NIPS '22,Red Hook, NY, USA。Curran Associates Inc.
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, 和 Karl Cobbe. 让我们逐步验证。在第十二届国际学习表示会议。
Haochen Liu, Zhiyu Huang, Jingda Wu, 和 Chen Lv. 2022. 改进的城市自动驾驶深度强化学习与专家演示。在2022 IEEE智能车辆研讨会论文集(IV),页921-928。IEEE。
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, 和 Min Lin. 2025. 理解R1-Zero-like训练:关键视角。预印本,arXiv:2503.20783。
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Erran Li, Raluca Ada Popa, 和 Ion Stoica. 2025. Deepscaler:通过扩大RL超越O1-preview,达到1.5亿参数模型。https://huggingface.co/datasets/ agentica=org/DeepScaleR=Preview=Dataset。Notion博客。
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, 和 Martin Riedmiller. 2013. 使用深度强化学习玩Atari游戏。预印本,arXiv:1312.5602。
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, 和
Tatsunori Hashimoto. 2025. s1: 简单的测试时缩放。预印本,arXiv:2501.19393。
Marwa Naïr, Kamel Yamani, Lynda Lhadj, 和 Riyadh Baghdadi. 2024. 小代码语言模型的课程学习。在第62届计算语言学协会年会论文集(第4卷:学生研究研讨会),页390-401,泰国曼谷。计算语言学协会。
OpenAI, :, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Allison Tam, 和其他244位。2024. OpenAI O1系统卡。预印本,arXiv:2412.16720。
Emmanouil Antonios Platanios, Otilia Stretcu, Graham Neubig, Barnabás Póczos, 和 Tom M. Mitchell. 2019. 基于能力的神经机器翻译课程学习。在NAACL-HLT (1),页1162-1172。计算语言学协会。
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, 和 Chelsea Finn. 2023. 直接偏好优化:你的语言模型实际上是一个奖励模型。在第37届神经信息处理系统国际会议论文集,NIPS '23,Red Hook, NY, USA。Curran Associates Inc.
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, 和 Philipp Moritz. 2015. 信任区域策略优化。在第32届国际机器学习会议论文集,机器学习研究论文集第37卷,页1889-1897,法国里尔。PMLR.
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, 和 Oleg Klimov. 2017. 近端策略优化算法。预印本,arXiv:1707.06347。
Taiwei Shi, Yiyang Wu, Linxin Song, Tianyi Zhou, 和 Jieyu Zhao. 2025. 通过自适应课程学习实现高效的强化微调。预印本,arXiv:2504.05520。
Yi Tay, Shuohang Wang, Anh Tuan Luu, Jie Fu, Minh C. Phan, Xingdi Yuan, Jinfeng Rao, Siu Cheung Hui, 和 Aston Zhang. 2019. 简单有效的长篇叙述理解课程指针生成器网络。在年度计算语言学协会会议论文集。
DeepSeek Team. 2024. Deepseekmath:推动大型语言模型数学推理的极限。arXiv预印本 arXiv:2402.03300。
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, Chuning Tang, Congcong Wang, Dehao Zhang, Enming Yuan,
Enzhe Lu, Fengxiang Tang, Flood Sung, Guangda Wei, Guokun Lai, 和其他75位。2025. Kimi k1.5:通过LLMs扩展强化学习。预印本,arXiv:2501.12599。
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, 和 Quentin Gallouédec. 2020. TRL:Transformer强化学习。https://github.com/huggingface/trl。
Zhenting Wang, Guofeng Cui, Kun Wan, 和 Wentian Zhao. 2025. DUMP:自动化分布级课程学习用于基于RL的LLM后训练。预印本,arXiv:2504.09710。
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, 和 Denny Zhou. 2022. 链式思维提示引发大语言模型中的推理。在第36届神经信息处理系统国际会议论文集,NIPS '22,Red Hook, NY, USA。Curran Associates Inc.
Liang Wen, Yunke Cai, Fenrui Xiao, Xin He, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Lifu Tang, Xiaowei Lv, Haosheng Zou, Yongchao Deng, Shousheng Jia, 和 Xiangzheng Zhang. 2025. Lightr1: 从头开始及以上的课程SFT、DPO和RL进行长链思考。预印本,arXiv:2503.10460。
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, 和 Gao Huang. 2025. 强化学习是否真的激励了LLMs超越基础模型的推理能力?预印本,arXiv:2504.13837。
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, 和 Junxian He. 2025. Simplerlzoo: 探索和驯服野外开放基础模型的零强化学习。预印本,arXiv:2503.18892。
Xuemiao Zhang, Liangyu Xu, Feiyu Duan, Yongwei Zhou, Sirui Wang, Rongxiang Weng, Jingang Wang, 和 Xunliang Cai. 2025. 偏好课程:LLMs应始终在其首选数据上进行预训练。预印本,arXiv:2501.13126。
A ADCL伪代码
算法1 自适应难度课程学习
输入: 数据集 (D={xi}i=1M;)(\mathcal{D}=\left\{x_{i}\right\}_{i=1}^{M} ;)(D={xi}i=1M;) 初始策略模型 (πθ0;)(\pi_{\theta_{0}} ;)(πθ0;) 批次数 (K;)(K ;)(K;)
(∀xi∈D)(\forall x_{i} \in \mathcal{D})(∀xi∈D), 计算难度得分 (δ0(xi)=f(πθ0,xi)▹)(\delta_{0}\left(x_{i}\right)=f\left(\pi_{\theta_{0}}, x_{i}\right) \quad \triangleright)(δ0(xi)=f(πθ0,xi)▹) 初始难度估计
(Dsorted ←Sort(D,δ0)▹)(\mathcal{D}_{\text {sorted }} \leftarrow \operatorname{Sort}\left(\mathcal{D}, \delta_{0}\right) \quad \triangleright)(Dsorted ←Sort(D,δ0)▹) 按照难度递增排序
将 (Dsorted )(\mathcal{D}_{\text {sorted }})(Dsorted ) 划分为 ({B1,B2,…,BK})(\left\{B_{1}, B_{2}, \ldots, B_{K}\right\})({B1,B2,…,BK}) 其中∣Bk∣=⌊M/K⌋\left|B_{k}\right|=\lfloor M / K\rfloor∣Bk∣=⌊M/K⌋ 或 ⌈M/K⌉)\lceil M / K\rceil)⌈M/K⌉)
for (k=1)(k=1)(k=1) to (K)(K)(K) do
(θk←TrainModel(θk−1,Bk)▹)(\theta_{k} \leftarrow \operatorname{TrainModel}\left(\theta_{k-1}, B_{k}\right) \quad \triangleright)(θk←TrainModel(θk−1,Bk)▹) 使用RL算法(如GRPO)更新 (πθ)(\pi_{\theta})(πθ)
if (k<K)(k<K)(k<K) then
(∀xi∈Bk+1)(\forall x_{i} \in B_{k+1})(∀xi∈Bk+1), 计算 (δk(xi)=f(πθk,xi)▹)(\delta_{k}\left(x_{i}\right)=f\left(\pi_{\theta_{k}}, x_{i}\right) \quad \triangleright)(δk(xi)=f(πθk,xi)▹) 重新估计难度
(Bk+1←Sort(Bk+1,δk)▹)(B_{k+1} \leftarrow \operatorname{Sort}\left(B_{k+1}, \delta_{k}\right) \quad \triangleright)(Bk+1←Sort(Bk+1,δk)▹) 重新排序下一个批次
输出: (πθK⋅)(\pi_{\theta_{K}} \cdot)(πθK⋅)
B EGSR伪代码
算法2 专家引导的自我重构
输入初始策略模型 (πθinit ;)(\pi_{\theta_{\text {init }}} ;)(πθinit ;) 奖励模型 (rϕ;)(r_{\phi} ;)(rϕ;) 数据集 (D={(qi,si,ai)}i=1N)(\mathcal{D}=\left\{\left(q_{i}, s_{i}, a_{i}\right)\right\}_{i=1}^{N})(D={(qi,si,ai)}i=1N),其中 (qi)(q_{i})(qi) 是问题,
(si)(s_{i})(si) 是解决方案,且 (ai)(a_{i})(ai) 是答案;
策略模型 (πθ←πθinit )(\pi_{\theta} \leftarrow \pi_{\theta_{\text {init }}})(πθ←πθinit )
for 迭代 (=1,…,I)(=1, \ldots, \mathrm{I})(=1,…,I) do
for 步骤 (=1,…,M)(=1, \ldots, \mathrm{M})(=1,…,M) do
从 (D)(\mathcal{D})(D) 中采样一个批次 (Db)(\mathcal{D}_{b})(Db)
更新旧策略模型 (πθold ←πθ)(\pi_{\theta_{\text {old }}} \leftarrow \pi_{\theta})(πθold ←πθ)
对于每个问题 (q∈Db)(q \in \mathcal{D}_{b})(q∈Db) 采样 (G)(G)(G) 条轨迹 ({τi}i=1G∼πθold (⋅∣q))(\left\{\tau_{i}\right\}_{i=1}^{G} \sim \pi_{\theta_{\text {old }}}(\cdot \mid q))({τi}i=1G∼πθold (⋅∣q))
使用 (rϕ)(r_{\phi})(rϕ) 计算每条采样轨迹 (τi)(\tau_{i})(τi) 的奖励 ({R(τi)}i=1G)(\left\{R\left(\tau_{i}\right)\right\}_{i=1}^{G})({R(τi)}i=1G)
if (∑i=1GR(τi)=0)(\sum_{i=1}^{G} R\left(\tau_{i}\right)=0)(∑i=1GR(τi)=0) then (▹)(\triangleright)(▹) 所有奖励为零
生成引导轨迹 ({τi′}i=1M∼πθgild (⋅∣f(q,s,a)))(\left\{\tau_{i}^{\prime}\right\}_{i=1}^{M} \sim \pi_{\theta_{\text {gild }}}(\cdot \mid f(q, s, a)))({τi′}i=1M∼πθgild (⋅∣f(q,s,a)))
创建混合轨迹 (τmixed ={τk}k=1G−M∪{τk′}k=1M)(\tau_{\text {mixed }}=\left\{\tau_{k}\right\}_{k=1}^{G-M} \cup\left\{\tau_{k}^{\prime}\right\}_{k=1}^{M})(τmixed ={τk}k=1G−M∪{τk′}k=1M)
重新计算 (τmixed )(\tau_{\text {mixed }})(τmixed ) 的奖励
计算混合轨迹集中每个轨迹 (τi)(\tau_{i})(τi) 的每个token (t)(t)(t) 的优势 (Ai,t)(A_{i, t})(Ai,t)
for GRPO迭代 (=1,…,μ)(=1, \ldots, \mu)(=1,…,μ) do
使用方程2中的GRPO-EGSR目标函数最大化更新 (πθ)(\pi_{\theta})(πθ)
输出 (πθ)(\pi_{\theta})(πθ)
C 训练超参数
完整的训练超参数见表4。
| 训练设置 | |
|---|---|
| global_batch_size | 1024 |
| per_device_batch_size | 8 |
| num_machines | 4 |
| num_devices | 32(4×8H20 s)32(4 \times 8 \mathrm{H} 20 \mathrm{~s})32(4×8H20 s) |
| gradient_accumulation_steps 4 | |
| 回滚配置 | |
| rollout_backend | vllm |
| tensor_parallel_size | 1 |
| data_parallel_size | 8 |
| num_generation | 8 |
| max_completion_length | 4096 |
| temperature | 0.7 |
| GRPO 训练配置 | |
| learning rate | 1e−61 \mathrm{e}-61e−6 (constant) |
| beta | 0 |
| epsilon | 0.2 |
| reward functions | format, accuracy |
| reward weights | 1.0,2.01.0,2.01.0,2.0 |
| num_iteration | 4 |
表4:训练超参数
D EGSR提示
EGSR(a) 提示:生成轨迹 τ(a)\boldsymbol{\tau}(\boldsymbol{a})τ(a)
问题:
{problem}
逐步思考以得出解决方案。使用以下格式输出你的推理过程和最终答案:
[在此处完整写出你的推理过程,展示每一步的思考]
</</</ think >>>
boxed {{\{\{{{ answer }}\}\}}}
“”"
EGSR (∗,a)(*, a)(∗,a) 提示:生成轨迹 τ(∗,a)\tau(*, a)τ(∗,a)
问题:
{\{{ problem }\}}
参考解决方案:
{\{{ solution}
你已经知道答案,但重要的是要用你自己的方式理解解决方案。像一个通过重新表述而不是死记硬背来学习的学生一样,发展你自己的逐步推理,得出类似的结论。
重要提示:不要逐字复制参考解决方案。相反,使用你自己的理解和表达风格重建推理路径。你的目标是通过解释解决方案来展示你的自然推理模式。
使用以下格式:
<<< think>
[在此处写出你自己的完整推理过程,展示你是如何得出这个解决方案的]
</</</ think>
boxed {\{{ [answer }\}} }
E 案例研究:在EGSR中仅通过答案引导出现有缺陷推理步骤的案例
我们观察到,如果EGSR仅使用最终答案(a)来引导自我重构,尽管模型输出的困惑度(PPL)较低,但它倾向于生成有缺陷的推理路径。看来模型可能会构建其解决方案以强行得出提供的正确答案,这种行为类似于奖励黑客。
案例研究
问题:
找出所有实数xxx和yyy上x+2y+3x2+y2+1\frac{x+2 y+3}{\sqrt{x^{2}+y^{2}+1}}x2+y2+1x+2y+3的最大值。
解决方案:
因为我们想要找到表达式的最大值,我们可以假设xxx和yyy都是正数;如果不是,则用∣x∣|x|∣x∣和∣y∣|y|∣y∣替换xxx和yyy将会严格增加表达式的值。根据柯西-施瓦茨不等式,(12+22+32)(x2+y2+1)≥(x+2y+3)2\left(1^{2}+2^{2}+3^{2}\right)\left(x^{2}+y^{2}+1\right) \geq(x+2 y+3)^{2}(12+22+32)(x2+y2+1)≥(x+2y+3)2,或者14(x2+y2+1)≥(x+2y+3)214\left(x^{2}+y^{2}+1\right) \geq(x+2 y+3)^{2}14(x2+y2+1)≥(x+2y+3)2。因此,
x+2y+3x2+y2+1≤14 \frac{x+2 y+3}{\sqrt{x^{2}+y^{2}+1}} \leq \sqrt{14} x2+y2+1x+2y+3≤14
当x=y2=13x=\frac{y}{2}=\frac{1}{3}x=2y=31时,等号成立,所以最大值是14\sqrt{14}14。
答案: 14\sqrt{14}14
有缺陷的τ(a)\tau(a)τ(a)示例(正确答案):
[…] (尝试拉格朗日乘子,注意到系统复杂难以求解) […] 由于问题要求最大值…,我们可以利用形式为x+x2y+xx2+y2+d\frac{x+x^{2} y+x}{\sqrt{x^{2}+y^{2}+d}}x2+y2+dx+x2y+x的函数的最大值由a2+b2+c2\sqrt{a^{2}+b^{2}+c^{2}}a2+b2+c2给出。(错误:引用的公式通常是不正确的,忽略’d’。)将其应用于我们的函数:a=1,b=2,c=3,d=1a=1, b=2, c=3, d=1a=1,b=2,c=3,d=1。最大值为:12+22+32=1+4+9=14.</\sqrt{1^{2}+2^{2}+3^{2}}=\sqrt{1+4+9}=\sqrt{14} .</12+22+32=1+4+9=14.</ think >>> 因此,最大值为14\sqrt{14}14。(通过不正确的方法得到正确答案。)
正确的τ(s,a)\tau(s, a)τ(s,a)示例:
<<< think> 应用向量(1,2,3)(1,2,3)(1,2,3)和(x,y,1)(x, y, 1)(x,y,1)的柯西-施瓦茨不等式,我们得到:(12+22+32)(x2+\left(1^{2}+2^{2}+3^{2}\right)\left(x^{2}+\right.(12+22+32)(x2+ y2+1)≥(x⋅1+2y⋅1+3⋅1)2\left.y^{2}+1\right) \geq\left(x \cdot 1+2 y \cdot 1+3 \cdot 1\right)^{2}y2+1)≥(x⋅1+2y⋅1+3⋅1)2,简化为:14(x2+y2+1)≥(x+2y+3)214\left(x^{2}+y^{2}+1\right) \geq(x+2 y+3)^{2}14(x2+y2+1)≥(x+2y+3)2。 […] 对两边取平方根并重新排列得到:
14≥∣x+2y+3∣x2+y2+1 \sqrt{14} \geq \frac{|x+2 y+3|}{\sqrt{x^{2}+y^{2}+1}} 14≥x2+y2+1∣x+2y+3∣
由于我们要找最大值,该表达式被14\sqrt{14}14上限。当且仅当向量(1,2,3)(1,2,3)(1,2,3)和(x,y,1)(x, y, 1)(x,y,1)成比例时等号成立,即当x1=y2=13\frac{x}{1}=\frac{y}{2}=\frac{1}{3}1x=2y=31。因此,最大值确实可以达到。 最终答案为:14\sqrt{14}14。
参考论文:https://arxiv.org/pdf/2505.08364

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)