从零实现 vLLM (1.1):并行词嵌入 VocabParallelEmbedding
在自然语言处理(NLP)和机器学习中,Embedding 是一种将离散的类别变量(例如词汇表中的单词)转换为连续的、低维度的向量表示的技术。计算机无法直接理解“猫”或“狗”这样的文本,它们需要数字化的输入。
前言
我一直都喜欢通过代码学习各种技术,特别是各种从零开始实现 XX 的。为了学习大模型推理引擎的技术,我找到了 DeepSeek 研究员俞星凯仅用不到1200行代码实现的 nano-vllm。我会把我的学习过程记录下来,方便大家参考。
要学习这么大一个技术的课题,需要从什么地方下手呢?下面是我学习计划:
-
构建 Transformer 模型: 我们首先要有一个“能运行”的模型。这部分将专注于用 Python 和 PyTorch 实现构成大语言模型(以 Qwen3 为例)的核心模块。
-
实现朴素推理: 有了模型,我们将实现一个最基础的推理流程,支持单个请求的文本生成,并深入理解其中最重要的 KV Cache 机制。
-
构建高性能推理引擎: 这是 vLLM 的精髓。我们将引入 vLLM 的核心思想,如 PagedAttention、请求调度、内存管理等,将我们的朴素实现改造成一个支持高吞吐、低延迟的现代化推理引擎。
本文作为开篇,先从第一部分网络结构开始,用 Qwen3 作为例子,对每个组件进行深入的学习。
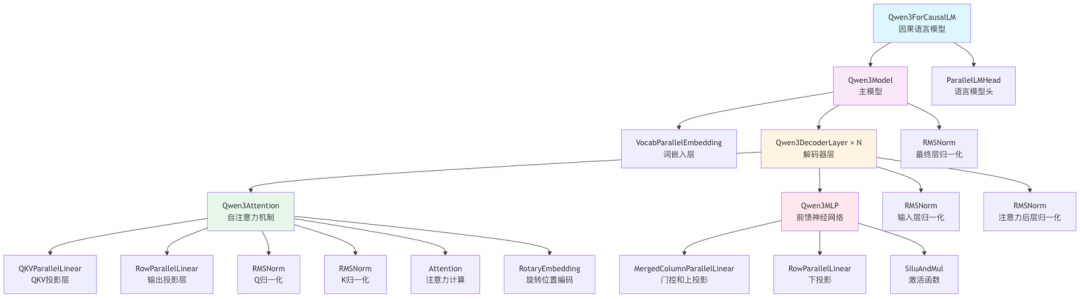
Qwen3 网络结构分析
Qwen3ForCausalLM 是一个因果语言模型,其主要组成部分包括:
-
Qwen3Model: 主要的模型结构
-
ParallelLMHead: 语言模型头,用于生成最终的输出logits
Qwen3Model 进一步包含:
-
VocabParallelEmbedding: 词嵌入层
-
多个Qwen3DecoderLayer: 解码器层
-
RMSNorm: 最终的层归一化
每个 Qwen3DecoderLayer 包含:
-
Qwen3Attention: 自注意力机制
-
Qwen3MLP: 前馈神经网络
-
两个RMSNorm: 分别用于注意力前后的层归一化
我们从 Qwen3Model 模型中第一个组件:VocabParallelEmbedding 开始。
什么是 Embedding?
在自然语言处理(NLP)和机器学习中,Embedding 是一种将离散的类别变量(例如词汇表中的单词)转换为连续的、低维度的向量表示的技术。计算机无法直接理解“猫”或“狗”这样的文本,它们需要数字化的输入。Embedding 就是将每个单词映射到一个由实数组成的向量。
它的核心作用是捕捉词与词之间的语义关系。 在一个训练良好的模型中,意思相近的词,其对应的 Embedding 向量在向量空间中的距离也更近。
举个例子:
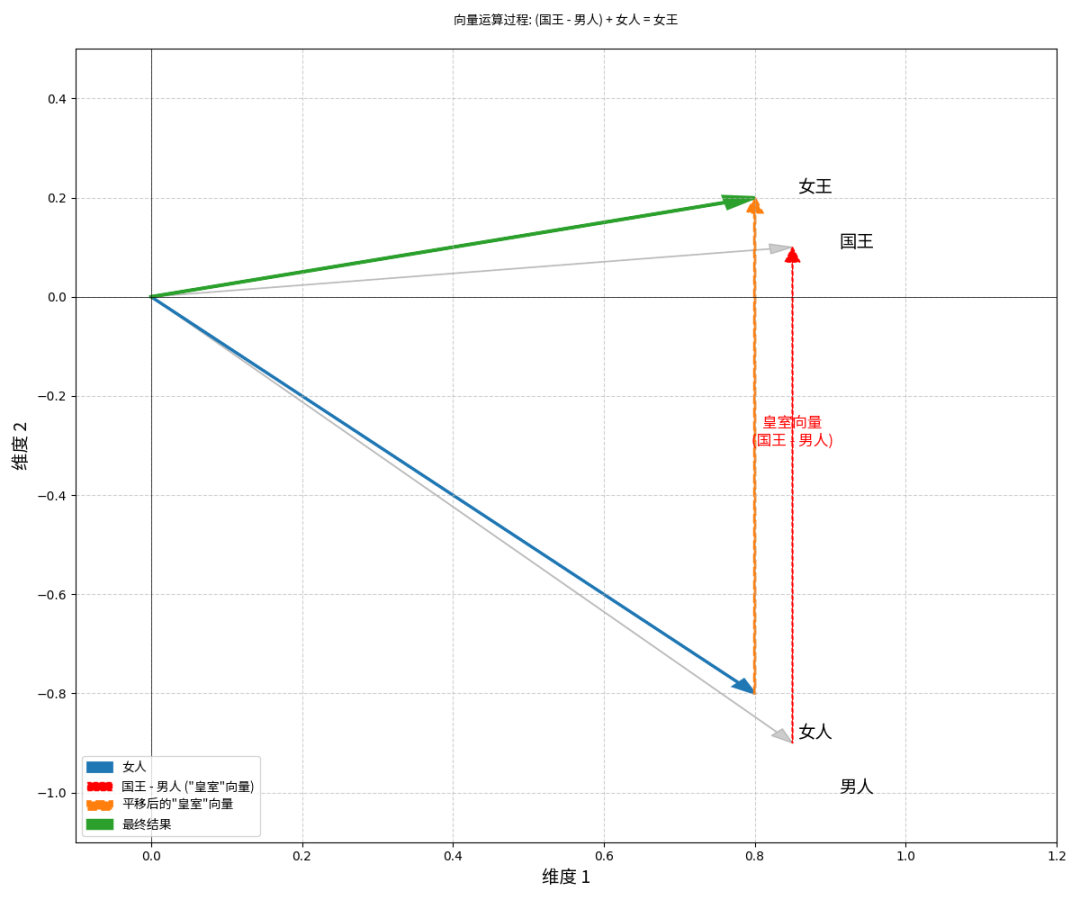
假设我们有一个小词汇表:{“国王”, “女王”, “男人”, “女人”}。
一个简单的 Embedding 层可能会学习到如下的二维向量表示:
-
国王 (King):
[0.85, 0.1] -
女王 (Queen):
[0.8, 0.2] -
男人 (Man):
[0.85, -0.9] -
女人 (Woman):
[0.8, -0.8]
在这个向量空间中,我们可以发现一些有趣的关系:
-
“国王”和“女王”的向量很相似,因为它们都代表皇室成员。
-
“男人”和“女人”的向量也很相似。
-
我们甚至可以进行向量运算,比如
(国王 - 男人) + 女人的结果会非常接近女王的向量。这表明 Embedding 捕捉到了“性别”和“皇室”这两个维度的语义信息。
通过这种方式,Embedding 让模型能够理解和利用单词之间的复杂关系,而不仅仅是把它们当作独立的符号。
VocabParallelEmbedding 运行机制详解
72B 以上的模型一般都需要在多卡的机器上面才能运行,有点像以前大数据框架一样,需要类似 MapReduce 的机制来分布式进行一次神经网络的前向推理。
VocabParallelEmbedding 相比单机版本的 nn.Embedding,核心思想是将整个词汇表(Vocabulary)切分成若干部分,每个设备只负责其中的一部分。当需要查找词嵌入时,每个设备独立计算自己负责的词,然后通过一个集合通信操作(All-Reduce)将所有设备的结果聚合起来,得到最终的完整嵌入。
下面,我们将通过一个具体的模拟示例,来逐步拆解其内部的运行过程。
import torch
import torch.nn as nn
import torch.nn.functional as F
# 词汇表定义
VOCAB = [
"a", "big", "cat", "sits", "on", "the", # 这 6 个词属于 Rank 0
"mat", "and", "a", "small", "dog", "plays"# 这 6 个词属于 Rank 1
]
# 注意:为了演示方便,"a" 在词汇表里出现了两次,分别在两个分片中。
# 在真实场景中,词汇表中的词是唯一的。
word_to_id = {word: i for i, word in enumerate(VOCAB)}
id_to_word = {i: word for i, word in enumerate(VOCAB)}
# VocabParallelEmbedding 类保持不变,它只处理数字ID
class VocabParallelEmbedding(nn.Module):
def __init__(
self,
num_embeddings: int,
embedding_dim: int,
tp_rank: int,
tp_size: int,
):
super().__init__()
self.tp_rank = tp_rank
self.tp_size = tp_size
assert num_embeddings % self.tp_size == 0
self.num_embeddings = num_embeddings
self.num_embeddings_per_partition = self.num_embeddings // self.tp_size
self.vocab_start_idx = self.num_embeddings_per_partition * self.tp_rank
self.vocab_end_idx = self.vocab_start_idx + self.num_embeddings_per_partition
self.weight = nn.Parameter(torch.empty(self.num_embeddings_per_partition, embedding_dim))
def forward(self, x: torch.Tensor):
mask = (x >= self.vocab_start_idx) & (x < self.vocab_end_idx)
print(f"\n[步骤 1: 生成的掩码 (Mask)]")
print(mask)
local_x = (x - self.vocab_start_idx) * mask
print(f"\n[步骤 2: 转换后的本地索引]")
print(local_x)
y = F.embedding(local_x, self.weight)
print(f"\n[步骤 3: 本地 Embedding 查找结果]")
print(y)
y = y * mask.unsqueeze(-1)
print(f"\n[步骤 4: 清零后的输出 (准备 All-Reduce)]")
print(y)
return y
# --- 模拟环境设置 ---
VOCAB_SIZE = len(VOCAB)
EMBEDDING_DIM = 4
TP_SIZE = 2
# 输入从ID改为文字
text_input = ["cat", "dog"]
input_ids = torch.tensor([[word_to_id[word] for word in text_input]], dtype=torch.long)
print("="*60)
print(f"模拟开始: TP_SIZE={TP_SIZE}, VOCAB_SIZE={VOCAB_SIZE}")
print(f"词汇表: {VOCAB}")
print(f"输入文字: {text_input}")
print(f"转换后的输入 Token IDs: {input_ids.flatten().tolist()}")
print("="*60)
# --- 手动模拟每个 Rank 的执行过程 ---
partial_outputs = []
all_embeddings_for_verification = []
for tp_rank in range(TP_SIZE):
print(f"\n{'#'*20} 模拟 Rank {tp_rank} 的计算过程 {'#'*20}")
embedding_layer = VocabParallelEmbedding(VOCAB_SIZE, EMBEDDING_DIM, tp_rank, TP_SIZE)
partition_size = VOCAB_SIZE // TP_SIZE
# 打印当前GPU负责的词汇
start_idx = embedding_layer.vocab_start_idx
end_idx = embedding_layer.vocab_end_idx
vocab_slice = [f"'{id_to_word[i]}':{i}"for i in range(start_idx, end_idx)]
print(f"\nRank {tp_rank} 负责的词汇 (及其全局ID): \n{vocab_slice}")
# 设置权重
weights_data = torch.arange(
start_idx, end_idx, dtype=torch.float32
).unsqueeze(1) * 10.0 + torch.arange(EMBEDDING_DIM, dtype=torch.float32)
with torch.no_grad():
embedding_layer.weight.copy_(weights_data)
all_embeddings_for_verification.append(weights_data)
print(f"\nRank {tp_rank} 的权重分片:")
print(embedding_layer.weight)
partial_y = embedding_layer(input_ids)
partial_outputs.append(partial_y)
# --- 模拟 All-Reduce 操作 ---
print(f"\n\n{'='*25} 模拟 All-Reduce 聚合 {'='*25}")
for i, p_out in enumerate(partial_outputs):
print(f"\n来自 Rank {i} 的贡献:")
print(p_out)
final_output = torch.stack(partial_outputs).sum(dim=0)
print(f"\n聚合后的最终结果:")
print(final_output)
# --- 验证结果 ---
print(f"\n\n{'='*28} 验证结果 {'='*28}")
full_weight_matrix = torch.cat(all_embeddings_for_verification, dim=0)
print(f"\n完整权重矩阵 (每一行代表一个单词的向量):")
print(full_weight_matrix)
standard_embedding_layer = nn.Embedding(VOCAB_SIZE, EMBEDDING_DIM)
with torch.no_grad():
standard_embedding_layer.weight.copy_(full_weight_matrix)
standard_output = standard_embedding_layer(input_ids)
print(f"\n标准 nn.Embedding 计算结果:")
print(standard_output)
# 更加直观地对比单个词的结果
word_to_check = "cat"
word_id = word_to_id[word_to_check]
word_index_in_batch = text_input.index(word_to_check)
print(f"\n--- 单独验证单词 '{word_to_check}' (ID: {word_id}) 的向量 ---")
print(f"并行计算得到的向量:\n{final_output[0, word_index_in_batch]}")
print(f"标准计算得到的向量:\n{standard_output[0, word_index_in_batch]}")
are_equal = torch.allclose(final_output, standard_output)
print(f"\n并行计算结果与标准计算结果是否一致: {are_equal}")
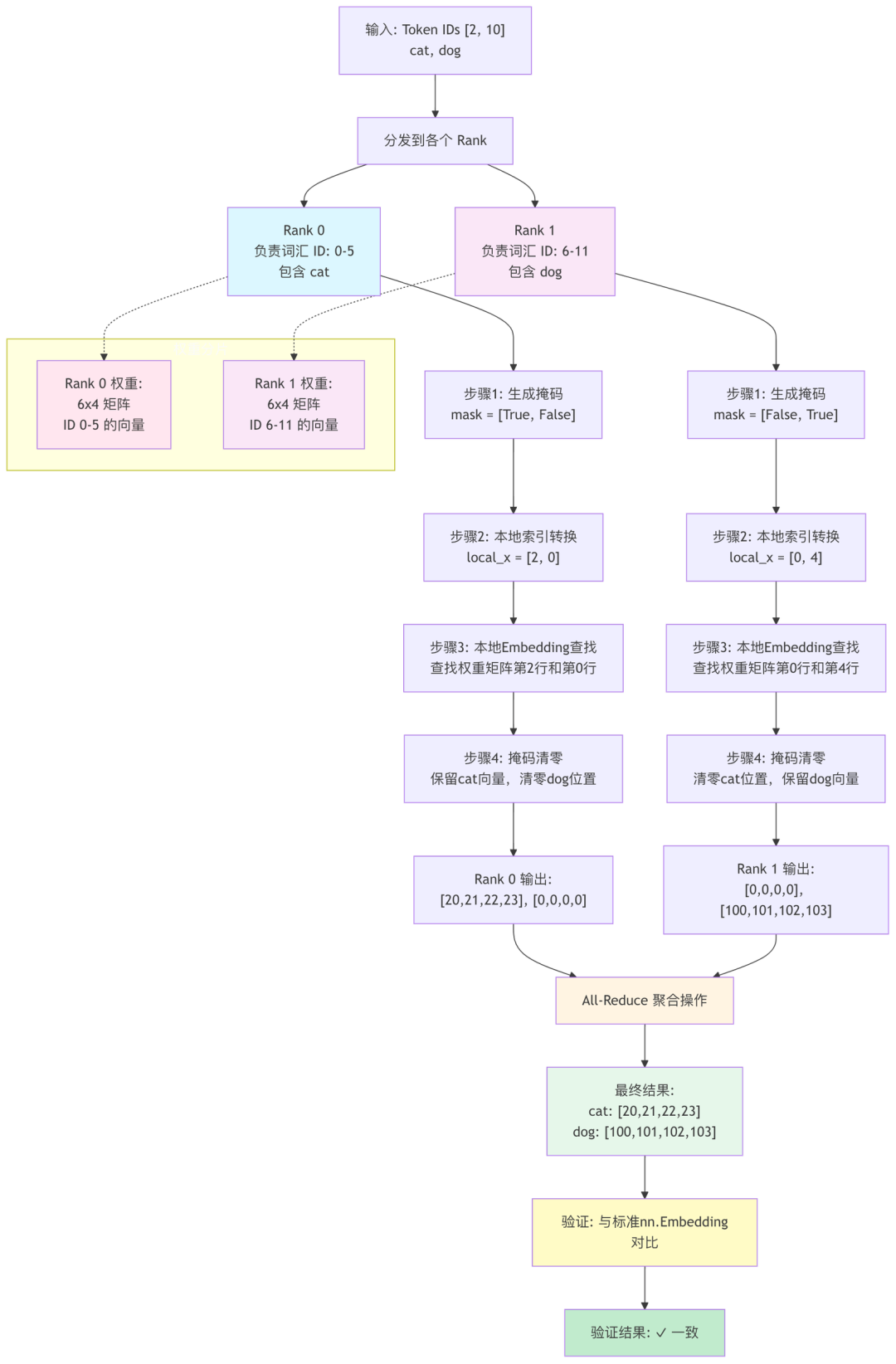
执行结果的图示如下:
模拟环境设置
首先,我们定义一个拥有 12 个单词的词汇表,并设置一个由两个词("cat", "dog")组成的输入句子。我们将模拟一个双卡并行的环境(TP_SIZE=2),其中 Rank 0(GPU 0) 和 Rank 1 (GPU 1)各负责词汇表的一半。
-
输入:
["cat", "dog"] -
转换后的 Token IDs:
[2, 10] -
Rank 0 负责的词汇 ID:
[0, 1, 2, 3, 4, 5] -
Rank 1 负责的词汇 ID:
[6, 7, 8, 9, 10, 11]
Rank 0 计算过程详解
Rank 0 负责词汇表的前半部分。对于输入 [2, 10],它将进行如下计算:
步骤 1: 生成掩码 (Mask)
此步骤判断输入 Token 中,哪些是属于当前 Rank 的。
代码:
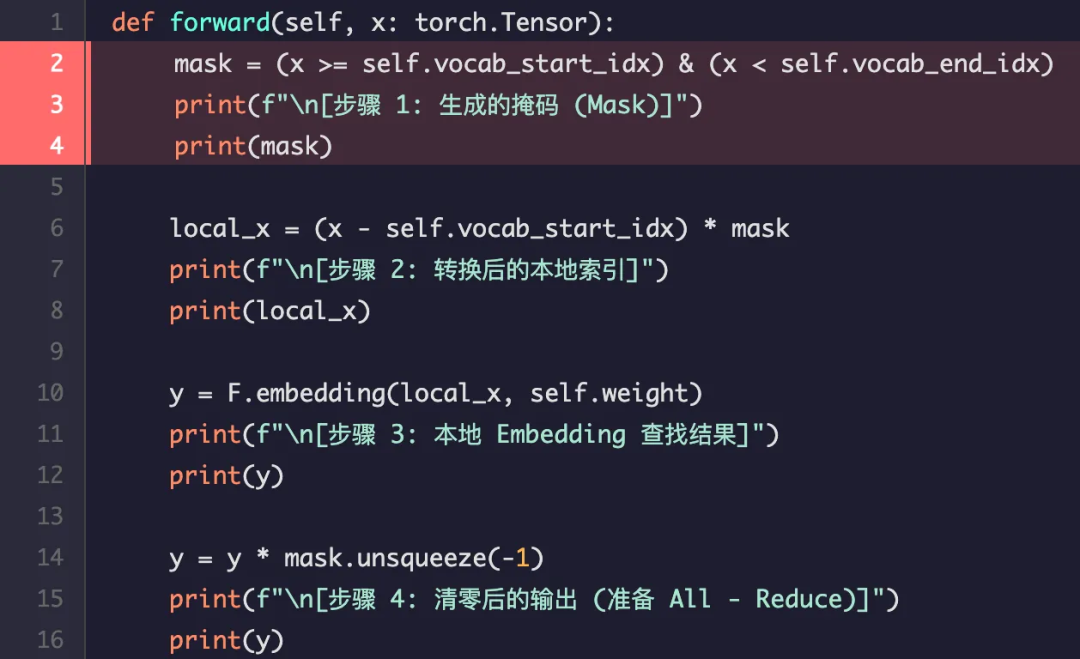
解释:
输入 x 是 [2, 10]。Rank 0 负责的 ID 范围是 [0, 6)。因此,2 在范围内(True),而 10 不在范围内(False)。
输出结果:
[步骤 1: 生成的掩码 (Mask)]
tensor([[ True, False]])
步骤 2: 转换后的本地索引
将全局 Token ID 转换为当前设备权重矩阵的本地索引。
代码:
解释:
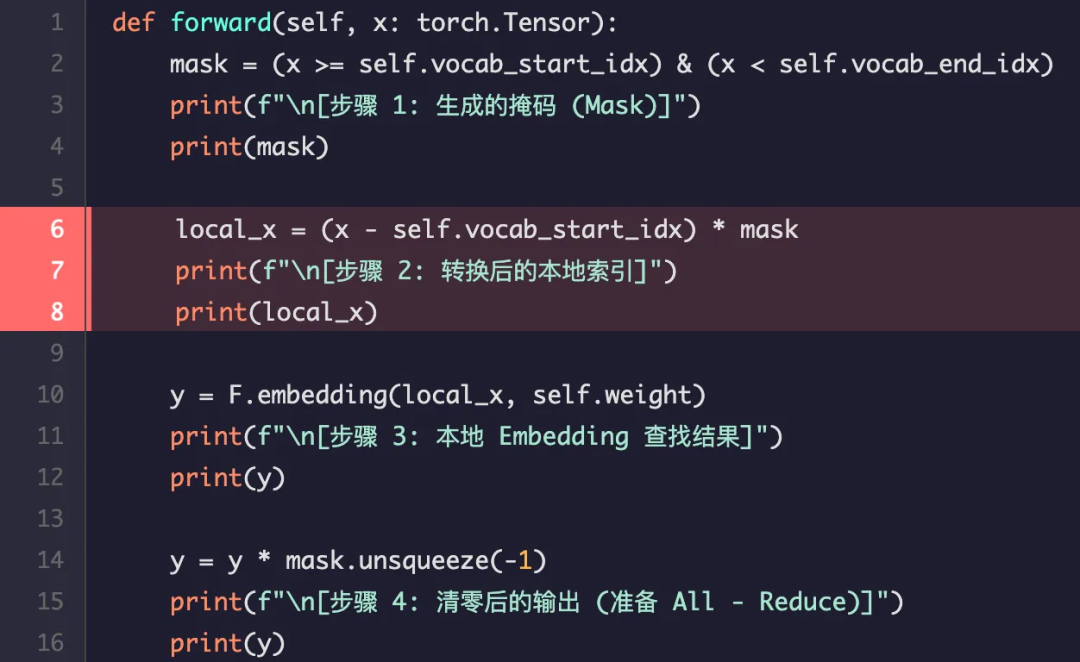
对于在范围内的 Token 2,本地索引为 2 - 0 = 2。对于不在范围内的 Token 10,掩码为 False,因此其本地索引被置为 0,以避免访问越界。
输出结果:
[步骤 2: 转换后的本地索引]
tensor([[2, 0]])
步骤 3: 本地 Embedding 查找
使用本地索引在当前 Rank 的权重分片中查找嵌入向量。
代码:
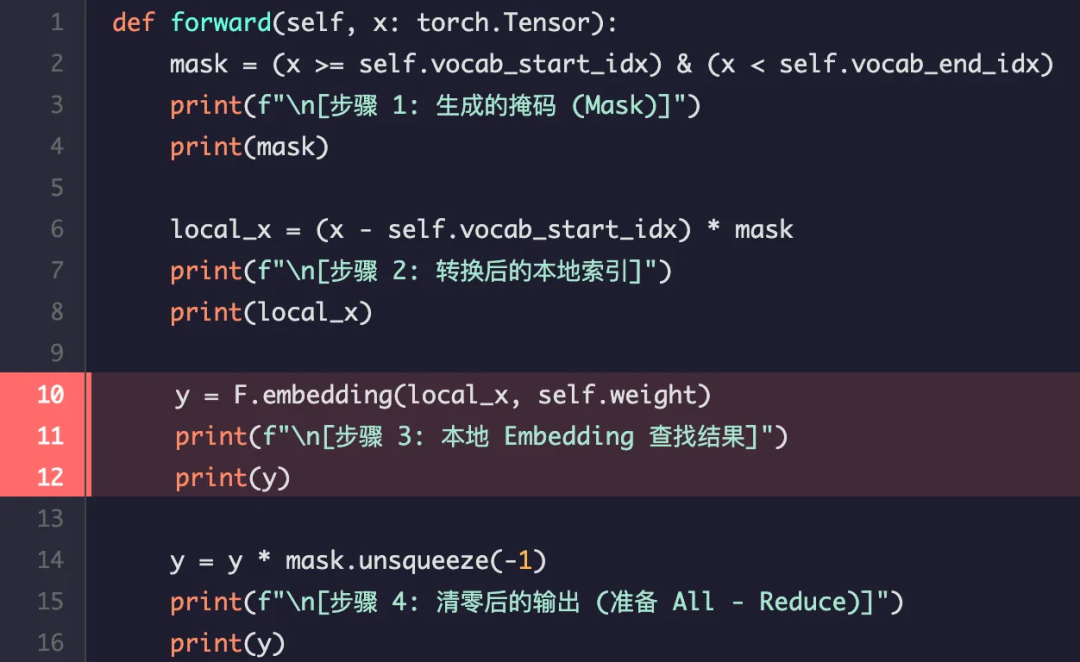
解释:
根据本地索引 [2, 0],在 Rank 0 的权重矩阵中查找第 2 行和第 0 行的向量。此时,我们得到了 "cat" 的正确向量和 "a" (ID 为 0)的向量(因为 "dog" 的 ID 被临时置为了 0)。这一步很重要,如果不置 0 将“dog”映射到 0 的位置,访问 10 这个索引对应的向量就会出现越界访问报错,因为 10 对应的向量并不在 Rank 0 上面。
输出结果:
[步骤 3: 本地 Embedding 查找结果]
tensor([[[20., 21., 22., 23.],
[ 0., 1., 2., 3.]]], grad_fn=)
步骤 4: 清零无关输出
利用步骤 1 的掩码,将不属于当前 Rank 的 Token 的输出向量清零。
代码:
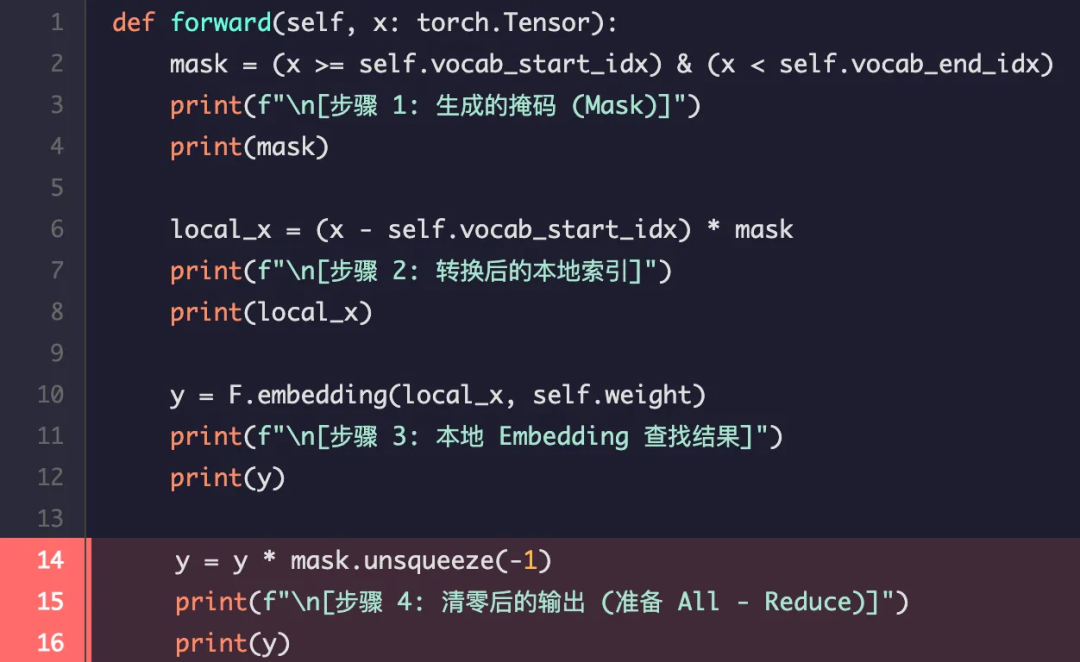
解释:
这是关键一步。我们将上一步的结果与掩码 [[True], [False]] 相乘。这使得 "cat" 的向量被保留,而 "dog"(被错误地查找为 "a")的向量被清零。这样就确保了 Rank 0 只贡献它所负责的 "cat" 的嵌入。
输出结果:
[步骤 4: 清零后的输出 (准备 All-Reduce)]
tensor([[[20., 21., 22., 23.],
[ 0., 0., 0., 0.]]], grad_fn=)
Rank 1 计算过程详解
Rank 1 的计算流程与 Rank 0 完全相同,但它负责词汇表的后半部分(ID 范围 [6, 12))。
-
步骤 1 (Mask): 对于输入
[2, 10],Token2不在范围(False),Token10在范围(True)。输出为tensor([[False, True]])。 -
步骤 2 (Local Index): Token
2的本地索引被置为0。Token10的本地索引为10 - 6 = 4。输出为tensor([[0, 4]])。 -
步骤 3 (Local Embedding): 在 Rank 1 的权重中查找本地索引
[0, 4]对应的向量。 -
步骤 4 (Zeroing): 将属于 Token
2的向量清零,只保留属于 Token10("dog")的向量。
Rank 1 最终准备 All-Reduce 的输出:
tensor([[[ 0., 0., 0., 0.],
[100., 101., 102., 103.]]], grad_fn=)
模拟 All-Reduce 聚合
在所有 Rank 完成本地计算后,需要将它们的结果聚合起来。All-Reduce 操作会将所有 Rank 的输出张量按元素相加。
代码:
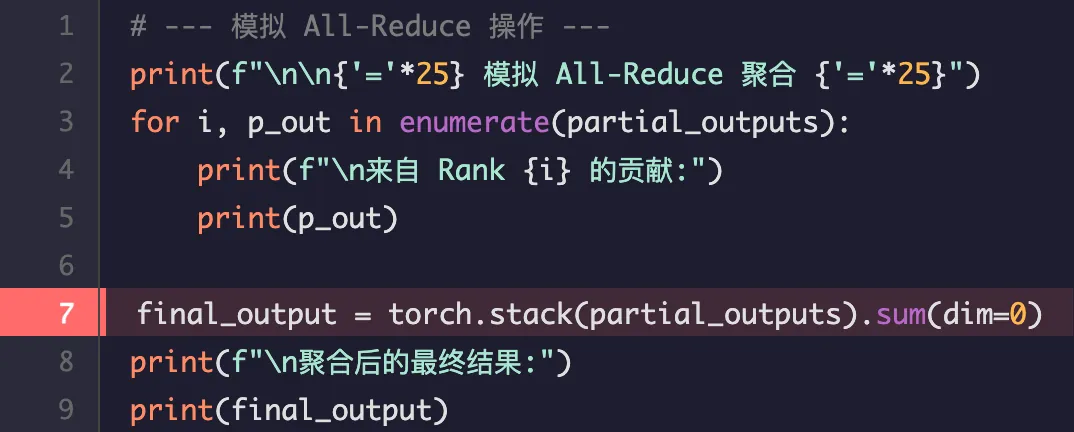
解释:
我们将 Rank 0 和 Rank 1 的输出相加:Rank 0 的贡献: [[[20., 21., 22., 23.], [0., 0., 0., 0.]]]Rank 1 的贡献: [[[0., 0., 0., 0.], [100., 101., 102., 103.]]]
相加后,"cat" 和 "dog" 的向量被正确地放置在了最终结果中。
输出结果:
聚合后的最终结果:
tensor([[[ 20., 21., 22., 23.],
[100., 101., 102., 103.]]], grad_fn=)
结果验证
最后,我们将并行计算的结果与标准的、非并行的 nn.Embedding 层计算的结果进行比较。结果完全一致,证明了 VocabParallelEmbedding 实现的正确性。
标准nn.Embedding计算结果:
tensor([[[ 20., 21., 22., 23.],
[100., 101., 102., 103.]]], grad_fn=)

最终验证:
并行计算结果与标准计算结果是否一致: True
通过这个分步解析,我们可以清晰地看到 VocabParallelEmbedding 如何通过“分而治之”与“合作汇总”的思想,高效地完成了分布式词嵌入的计算。
nano-vllm 源码分析
在看完前面的演示代码之后,我们回到 nano-vllm 的代码加深理解。
class VocabParallelEmbedding(nn.Module):
def __init__(
self,
num_embeddings: int,
embedding_dim: int,
):
super().__init__()
self.tp_rank = dist.get_rank()
self.tp_size = dist.get_world_size()
assert num_embeddings % self.tp_size == 0
self.num_embeddings = num_embeddings
self.num_embeddings_per_partition = self.num_embeddings // self.tp_size
self.vocab_start_idx = self.num_embeddings_per_partition * self.tp_rank
self.vocab_end_idx = self.vocab_start_idx + self.num_embeddings_per_partition
self.weight = nn.Parameter(torch.empty(self.num_embeddings_per_partition, embedding_dim))
self.weight.weight_loader = self.weight_loader
def weight_loader(self, param: nn.Parameter, loaded_weight: torch.Tensor):
param_data = param.data
shard_size = param_data.size(0)
start_idx = self.tp_rank * shard_size
loaded_weight = loaded_weight.narrow(0, start_idx, shard_size)
assert param_data.size() == loaded_weight.size()
param_data.copy_(loaded_weight)
def forward(self, x: torch.Tensor):
if self.tp_size > 1:
mask = (x >= self.vocab_start_idx) & (x < self.vocab_end_idx)
x = mask * (x - self.vocab_start_idx)
y = F.embedding(x, self.weight)
if self.tp_size > 1:
y = mask.unsqueeze(1) * y
dist.all_reduce(y)
return y
下面我们分步解析:
1. __init__ (初始化):分区的准备工作
这部分代码负责“分而治之”的准备工作,即确定每个 GPU(或进程,由 rank 标识)负责词汇表的哪一部分。
# 获取当前进程的排名(rank)和总进程数(world_size)
self.tp_rank = dist.get_rank()
self.tp_size = dist.get_world_size()
# 计算每个分区的大小,以及当前进程负责的词汇表的起始和结束索引
self.num_embeddings_per_partition = self.num_embeddings // self.tp_size
self.vocab_start_idx = self.num_embeddings_per_partition * self.tp_rank
self.vocab_end_idx = self.vocab_start_idx + self.num_embeddings_per_partition
# 只为当前分区创建权重参数,而不是整个词汇表
self.weight = nn.Parameter(torch.empty(self.num_embeddings_per_partition, embedding_dim))
这完全对应了演示代码中的“模拟环境设置”部分。前面是手动为 Rank 0 和 Rank 1 分配词汇范围,而这段代码通过 torch.distributed 的 get_rank() 和 get_world_size() 自动完成了这个过程,使其能适应任意数量的 GPU。
2. weight_loader (权重加载)
这是一个辅助函数,用于从一个完整的权重文件中加载属于自己这个分区的数据。在实际应用中,模型权重通常是作为一个大文件保存的,加载时每个 GPU 需要从中“切”出自己负责的那一块。
# 计算在完整权重张量中的起始位置
start_idx = self.tp_rank * shard_size
# 使用 narrow 方法精确地切出所需的分片
loaded_weight = loaded_weight.narrow(0, start_idx, shard_size)
# 将切片后的权重拷贝到参数中
param_data.copy_(loaded_weight)
在前面的模拟中没有直接体现,但属于工程实践中的必要环节。前面是为每个 Rank 单独生成了权重,而这里展示了如何从一个统一的来源加载权重。
3. forward (前向传播):执行“MapReduce”
这是并行计算的核心,完美地执行了文章中分步详解的整个流程。
# 1. 生成掩码 (Mask),判断输入Token是否属于当前分区
mask = (x >= self.vocab_start_idx) & (x < self.vocab_end_idx)
# 2. 转换本地索引,并用掩码清零无关Token
# 这一步合并了演示代码中的步骤2和3的一部分
x = mask * (x - self.vocab_start_idx)
# 3. 本地 Embedding 查找
y = F.embedding(x, self.weight)
# 4. 清零无关输出,确保只保留当前分区贡献的向量
y = mask.unsqueeze(1) * y
# 5. 聚合 (All-Reduce),将所有GPU的结果相加
dist.all_reduce(y)
总结
VocabParallelEmbedding 本质上是将词表分布到不同 GPU 上面实现的 MapReduce 操作,主要目的是为了将输入的词通过查表的方式映射到指定的向量上面。
VocabParallelEmbedding 的核心思想就是“分而治之”与“合作汇总”:
-
分而治之 (Map): 每个 GPU 只负责词汇表的一部分,并独立查找自己那部分词的向量。
-
合作汇总 (Reduce): 通过
All-Reduce通信操作,将所有 GPU 的计算结果相加,最终在每个 GPU 上都得到完整的、正确的词嵌入向量。
最后附带一个表格进行总结
|
特性 |
VocabParallelEmbedding |
|---|---|
| 角色 |
输入层 (Input Embedding) |
| 输入 |
Token IDs (整数) |
| 输出 |
Embeddings (浮点数) |
| 核心操作 | F.embedding
(查表) |
| 通信方式 | dist.all_reduce
(求和) |
| 最终结果 |
所有 GPU 上都有完整结果 |
关于我们
看到这里,相信你对本文核心主题已经有了更深入的理解。但 AI 和大模型领域更新迭代极快,单篇文章的内容很难覆盖所有细节,只能算是入门铺垫。
我平时会在【小灰熊大模型】这个公・Z・号里,系统整理 AI 大模型相关的实用资料,比如最新模型技术白皮书、实战调参手册、行业落地案例合集,还会每周更新 AI 前沿动态速递。
里面沉淀的干货具体包括:
- 大模型入门学习路线图,帮新手少走弯路
- 大模型方向必读书籍 PDF 版,方便随时查阅
- 大模型面试题库,覆盖常见考点和高频问题
- 大模型项目源码,可直接参考实操
- 超详细海量大模型 LLM 实战项目,从 0 到 1 带练
- Langchain/RAG/Agent 学习教程,聚焦热门技术方向
- LLM 大模型系统 0 到 1 入门学习教程,适合零基础
- 吴恩达最新大模型视频 + 课件,同步前沿课程内容
一直以来,我都在专注分享 AI 与大模型领域的干货 —— 从基础原理拆解到进阶实战教程,从开源工具测评到商业落地思考,每一篇内容都尽量打磨得细致实用,希望能帮大家快速跟上技术浪潮。
如果需要上述资料,关注后在GZH后台回复关键词【大模型福利】就能获取,后续也会持续更新更多针对性资源,一起在 AI 领域慢慢深耕成长~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)