漫游Embedding高维向量空间
无论是bge-m3基于transformer网络结构的“小”模型,还是RQ-VAE基于transformer网络结构的定制模型,同LLM大模型一样,这些模型的tokenizer,其实就是些比较大的embedding向量表,无数难以言明的语义embedding在神经网络中加减、插值、投影等大量繁复而递归地操作,最终行成了不同语义之间的深刻关联,乃至于让机器吐出“人话”,通过图灵测试,走向AGI智能时
引言
初看embedding,一组由简单的正数或负数组成的数组,它们是某个高维向量空间的坐标,映射了语义空间的方向,同时它们也是LLM矩阵运算的组成单元,是attention注意力机制的基础。embedding是我们努力对自然语言或真实世界的一种客观描述,饱含了人类的思维认知和独特表达。
看embedding主要有两个层面,一个是embedding怎么来的,二是embedding怎么用的。
embedding怎么来的,大体上经历了Word2Vec-BERT(embedding)-语言模型LLM(embedding)-多模态模型MLLM(embedding)过程,embedding模型的训练语料越来越大,embedding模型的规模也越来越大,从文字到图片语音,从语义层面的token表示到包含实际物理意义的item表示,可探索的embedding向量空间的广度和深度也越来越大了。
本文主要介绍文本embedding怎么用的,除了常见的cosine计算两个embedding向量夹角以表示语义相似度外,embedding这颗大树上还有一些低垂的果实可以采摘品尝,向上伸伸手,看看还能够到什么。
本文主要实验了embedding的加减法与插值、正交投影和残差量化方法,采用bge-m3模型的embedding向量,ollama部署,向量长度1024维。涉及的函数计算,见附录函数python代码。
Embedding加减法与插值
一般的,如果两个向量的cosine运算值达到0.7以上,可以认为两个向量的语义高度相似。当然,一对反义词的cosine值也很高,这是我们要避坑的地方。
Embedding加减法
两个embedding相加,可以认为是两个语义概念的合成。
但两个embedding加和的向量模不再是1,需要对加和embedding进行归一化norm操作。
这里我们看两个例子,分别计算两个语义概念的合成结果与真实结果。
cosine(norm(vec("中国国体")+vec("国旗")) , vec("五星红旗")) = 0.8331
cosine(norm(vec("美国国体")+vec("国旗")) , vec("星条旗)")) = 0.7442可以看到,合成结果与真实结果存在高度相似。
不过,这里要强调的一点是,当我们要进行两个概念的合成时,这两个概念的含义指向需要尽量精准,不要发散,例如vec("中国")同时对vec("中国文化")、vec("中国人口")和vec("中国历史")也具有较高的相似度,用"中国国体"叠加"国旗",相比用"中国"叠加"国旗",合成向量的语义会更贴近"五星红旗"。
两个向量的减法,是加法的一种变形形式,可以认为是用两个显式概念推导出一个隐式概念。
这里用城市和国家,来推导隐式的"首都"概念。
cosine(norm(vec("巴黎城市行政区") - vec("法国国家体制")), norm(vec("伦敦城市行政区") - vec("英国国家体制"))) = 0.9258
cosine(norm(vec("巴黎城市行政区") - vec("法国国家体制")), norm(vec("北京城市行政区") - vec("中国国家体制"))) = 0.8197
cosine(norm(vec("北京城市行政区") - vec("中国国家体制")), norm(vec("伦敦城市行政区") - vec("英国国家体制"))) = 0.8265可以看到,法国的"首都"、英国的"首都"和中国的"首都",三者概念都很接近。
Embedding插值运算
从embedding的加法,自然想到能否对多个embedding进行插值运算,从而“按需”定义一个语义概念。
首先看一下线性插值,这里我们以传统“火药”的配方“一硝二硫三木炭”来试试。
cosine(norm(vec(硝石材料)*(1/6) + vec(硫磺材料) *(2/6) + vec(木炭材料)*(3/6)), vec(火药材料)) = 0.7328可以看到按“配方”比例合成“火药”,也是“可行的”。
最常见的做法,还是LLM领域中的注意力机制attention,毕竟“配方”不可常得,唯有自力更生计算而来。
当然,在高维向量空间进行线性插值,尽管norm插值embedding的模是1,但从语义的加权方向来说并非严格等价,为了更好的对embedding进行插值,Slerp 球面插值方法有如下优点:
-
始终在超球面上移动
-
保持原始向量的"纯度"
-
均匀融合两个概念的本质特征
比较线性插值lerp+归一化与球面插值Slerp的结果,我们看一个特例:norm(vec(word1)*0.5 + vec(word2) *0.5)与slerp(vec(word1), vec(word2), 0.5)有哪些区别。
| 特性 | 球面插值Slerp | 线性插值Lerp+归一化 |
| 空间位置 | 在向量空间中准确位于两个向量的平分点 | 在向量空间位置不确定(取决于原向量分布) |
| 计算方式 | 基于三角函数的测地线插值 | 加权平均后缩放 |
| 角度均匀性 | 角度变化恒定 | 角度非线性变化 |
| 向量模长 | 结果直接是单位向量 | 需要额外归一化 |
| t=0.5对称性 | 严格对称 | 权重对称但几何不对称 |
Embedding与正交投影
下面我们从embedding的向量特性出发,讨论构建一对正交基,在实际应用时,可以构建事实-情感的二元评估维度,以此来衡量文本在事实方向和情感方向的强度。
首先构建事实-情感的基础向量,可以看到事实与情感基础向量的相似性为0.5654,这两个基础向量不正交。
import torch
import numpy as np
fact_query = ['事实标准', '数学单位', '物理定律']
emo_query = ['欢天喜地', '表情夸张', '令人惊讶']
fact_emb = torch.tensor(norm(np.mean([vec(w) for w in fact_query], axis=0)))
emo_emb = torch.tensor(norm(np.mean([vec(w) for w in emo_query], axis=0)))
print('事实与情感基础向量的相似性:', cosine(fact_emb, emo_emb))
# 事实与情感基础向量的相似性: tensor(0.5654)下面对事实-情感的基础向量进行正交处理
fact_axis = fact_emb
emo_axis = norm(emo_emb - project(fact_axis, emo_emb))看下不同文本在事实-情感正交轴上的强度,这两个句子一个偏向事实,一个偏向情感,总体上符合预期。
content = "今年销售额增加20%"
# content = "今年销售额大幅增长,我们都很高兴"
content_vec = vec(content)
fact_score = torch.dot(content_vec, fact_axis)
emo_score = torch.dot(content_vec, emo_axis)
print(f"事实强度: {fact_score:.2f}, 情感强度: {emo_score:.2f}")
# 今年销售额增加20% -- 事实强度: 0.36, 情感强度: 0.32
# 今年销售额大幅增长,我们都很高兴 -- 事实强度: 0.37, 情感强度: 0.48同时,我们也看下计算出的事实轴与情感轴是否真的正交,cosine结果非常接近0,达到正交的条件。
cosine(fact_axis, emo_axis)
# 结果:-6.5193e-08这里有一个要避坑的地方,一对正交基,首先需要从概念上就互不相关,例如“积极”和“消极”不能算作正交的维度,类似的还有“肯定”和“否定”、“差评”和“好评”等,这些属于一元连续谱系而非二元正交概念。
Embedding的残差量化
上面对embedding的简单运算可以算做前菜,接下来分层剖析embedding向量空间,看看能发现什么。
所谓embedding残差量化(Residual Quantization),即用固定大小的码本codebook,通过递归量化生成每个码本的ID码,简而言之,就是找到一组有限的数字ID(例如[2,5,6])来表示高维度的embedding向量,在推荐系统中可以理解为推荐物料item的简化表示,在LLM/MLLM领域中可以理解为大模型的tokenizer。
这个过程反过来说,就是一个embedding通过逐级残差量化的方法表示为一组数字ID,当两个embedding在相同码本上的值也相同,可以理解为两个embedding在某个隐式维度具有一致性,这个隐式维度既可以是一种让人一目了然的分类标签,也可以是某种特殊的语义结构,或者我们暂时不能理解的语义形式。如果两个embedding的码本ID值都相同,可以理解为这两个embedding向量十分接近,这十分利于相似embedding的筛选控制及其可解释性。
Embedding残差量化代表性工作是RQ-VAE[1],这也是推荐系统OneRec[2]进行统一item编码和自回归预测Next-Item的基础。本文参考RQ-VAE-recommender[3]开源代码,在中文金融资讯推荐系统数据集上进行了初步实验,这里码本ID叫做语义SemanticID,码本codebook数量为3,每个codebook大小为512,若存在有前三个语义SemanticID均相同的情况,设置额外的区分码来对应不同embedding代表的物品,实验表明:
-
当第一个语义SemanticID=48,对应embedding代表的资讯标题具有特定的组织结构,如“股票名称:公司业务”

-
当第一个语义SemanticID=49,对应embedding代表的资讯标题主要涉及“A股”涨跌相关内容

-
当前两个语义SemanticID=49-384,对应embedding代表的资讯标题主要是A股下跌的内容

-
当前两个语义SemanticID=49-284,对应embedding代表的资讯标题主要是A股上涨的内容

从SemanticID=49、SemanticID=49-384和SemanticID=49-284的案例看出,语义呈现逐级分化趋势。
RQ-VAE原理
下面介绍RQ-VAE(Residual-Quantized Variational AutoEncoder)的基本原理。VAE的做法由来已久,我们看看RQ-VAE是如何在基础VAE上创新的。
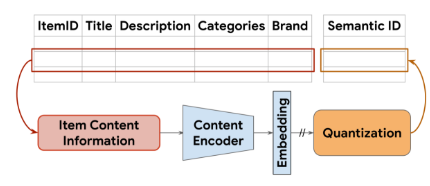
将物品的文本内容x通过Embedding模型编码到高维向量空间
对于每个codebook码本d,有K个码本ID/SemanticID
残差量化过程可以表示为:
具体我们看下面的残差量化流程图
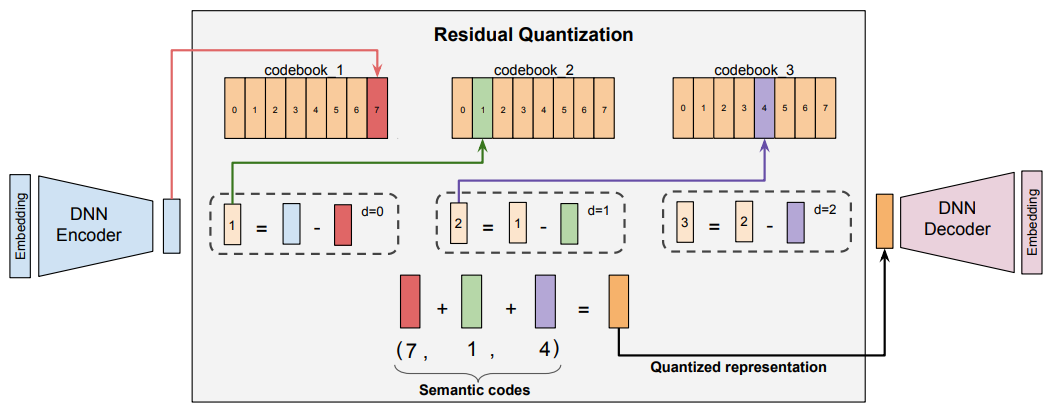
1. 初始化
物品的文本内容经过Embedding向量模型后获得(蓝色块),作为初始向量。
为了防止训练后的codebook过分集中,即码本使用率很低,使用基于kmenas算法的聚类中心来初始化codebook。
2. 第1层量化
第一层码本codebook 1包含了K个向量(这里K=8),从中选出与距离最近的向量作为
(红色块),对应的码本索引
,第一层残差的误差为
3. 第2层量化
在第二层码本codebook 2,选出与最接近的
(绿色块),对应的码本索引
,第二层残差的误差为
4. 第3层量化
最后在第三层码本codebook 3,选出与最接近的
(紫色块),对应的码本索引
,第三层残差的误差为
最终由三个码本codebook组成的最为物品的SemanticID,例如[12, 90, 45]。
在实际训练过程中,会出现多个物品对应一组SemanticID,这里会增加额外的区分码,相同SemanticID的物品在区分码上逐个增加索引,以示区分,例如[12, 90, 45, 0]和[12, 90, 45, 1]表示有两个embedding代表的物品极为类似,它们在文本语义上非常接近。
5. 损失函数
RQ-VAE的最终损失函数包含重建损失和RQ-VAE量化损失,将所有量化时选择的向量相加得到近似向量
重建损失:
RQ-VAE量化损失,其中sg表示 stop-gradient 操作,避免梯度直接更新codebook表达
最终损失函数:
RQ-VAE实战
开源代码RQ-VAE-recommender,整体上是一种基于推荐系统+大模型自回归迭代训练预测Next-Item的模式,分为两个阶段,第一个阶段为训练RQ-VAE tokenizer,第二阶段利用推荐系统的用户点击序列训练decoder来预测Next-Item。
代码中的训练数据集为Amazon的beauty、sports和toys(电商推荐系统数据),或MovieLens(电影推荐系统数据),笔者在跑通Amazon-beauty两阶段训练流程后,即在中文金融资讯上进行RQ-VAE tokenizer的训练,本文也仅展示RQ-VAE tokenizer训练的过程。
RQ-VAE tokenizer的训练仅需相关的embedding向量数据集即可,本文选取中文金融资讯23622篇,每个资讯使用bge-m3模型的输出向量
= vec('Title\n$资讯标题$\nAbstract\n$资讯摘要$\nContent\n$资讯正文$')
设计码本codebook数量为3,每个codebook大小512且维度32,增加额外的区分码(同样大小也为512)。
看一下训练loss趋势,loss快速下降后比较稳定,unique_ids即不重复的SemanticID后续有小幅下滑,我们可以考虑选择step靠前的checkpoints作为最终的RQ-VAE模型。
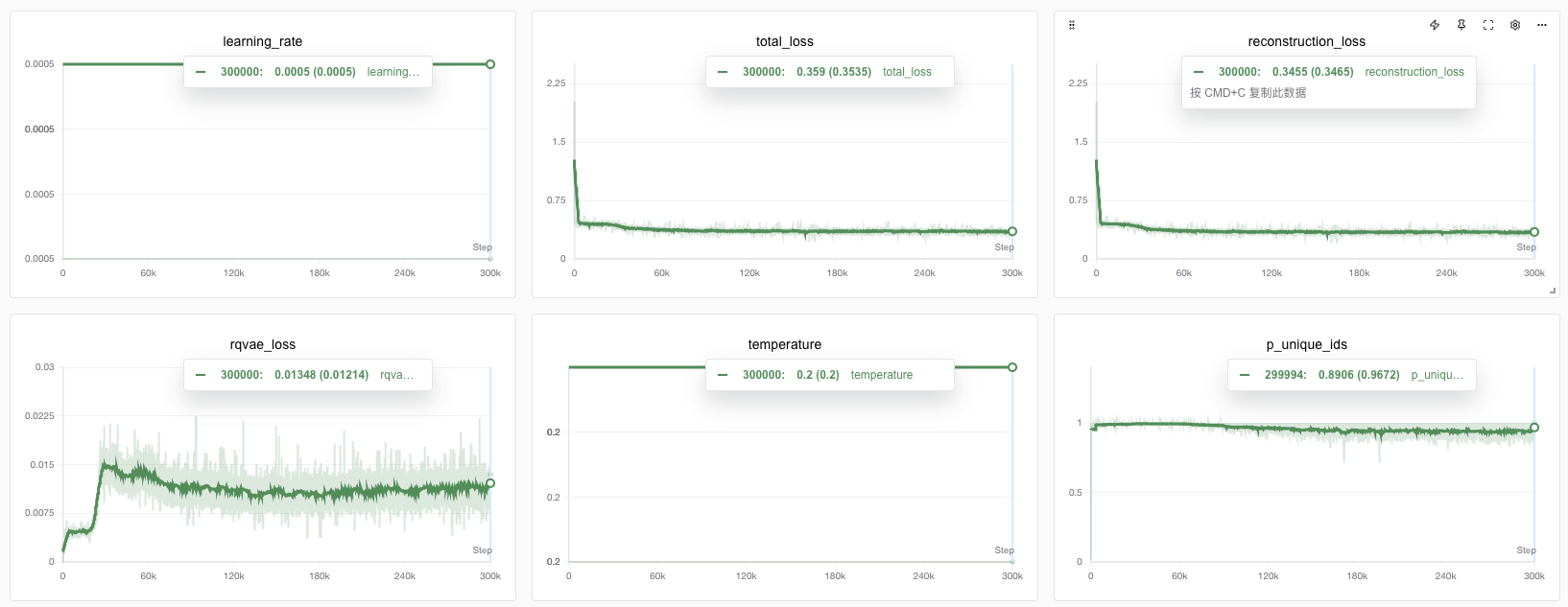
这里也要重点看一下码本利用率,均在95%以上,这个数字越接近100%越好。

当然,这里码本利用率没有达到100%,说明RQ-VAE的做法还存在一些深层缺陷,在OneRec论文中提到了升级版的RQ-Kmeans,据说能做到更高的码本利用率。
总结回顾
对Embedding高维向量空间的极致探索和利用,还得是LLM大模型领域,具体来说,是transformer网络结构及其变种,是注意力机制attention及其变种。
本文选用的bge-m3是基于transformer网络结构的“小”模型,RQ-VAE也是基于transformer网络结构的定制模型,同LLM大模型一样,这些模型的tokenizer,其实就是些比较大的embedding向量表,无数难以言明的语义embedding在神经网络中加减、插值、投影等大量繁复而递归地操作,最终行成了不同语义之间的深刻关联,乃至于让机器吐出“人话”,通过图灵测试,走向AGI智能时代。
本文同步在《机智流》公众号发布。
附录函数
vec函数,获取query的embedding向量
import torch, requests
def vec(query, model="bge-m3:latest"):
url = "YOUR-API/v1/embeddings"
headers = {"Content-Type": "application/json"}
data = {
"input": [query],
"model": model,
"encoding_type": "dense",
"return_dense": True,
}
try:
response = requests.post(url, json=data, headers=headers)
result = response.json()
dense_vectors = result["data"][0]["embedding"]
return torch.tensor(dense_vectors)
except:
return 'ERR'cosine函数,获取两个向量的相似度
import torch.nn.functional as F
def cosine(emb1, emb2):
return F.cosine_similarity(emb1, emb2, dim = -1, eps = 1e-8)norm函数,获取归一化后的向量
import numpy as np
def norm(emb):
return emb / np.linalg.norm(emb)slerp函数,获取球面插值后的向量
import numpy as np
def slerp(v0, v1, t):
"""
球面线性插值
:param v0, v1: 单位向量
:param t: 插值参数 (0.0-1.0)
"""
# 计算角度
dot = np.dot(v0, v1)
dot = np.clip(dot, -1.0, 1.0) # 确保数值稳定性
theta = np.arccos(dot) * t
# 插值计算
v2 = v1 - v0 * dot
if np.linalg.norm(v2) < 1e-10: # 处理共线情况
return v0 * (1 - t) + v1 * t
v2 = v2 / np.linalg.norm(v2)
return v0 * np.cos(theta) + v2 * np.sin(theta)project函数,获取v在u上的正交投影分量
import numpy as np
def project(u, v):
"""计算v在u方向上的投影"""
scale = np.dot(u, v) / np.dot(u, u) # 投影缩放系数
return scale * u # 投影向量参考资料
[1]RQ-VAE: https://arxiv.org/pdf/2305.05065
[2]OneRec: https://arxiv.org/pdf/2506.13695
[3]RQ-VAE-recommender: https://github.com/EdoardoBotta/RQ-VAE-Recommender

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)