【课程笔记】华为 HCIE-AI Solution Architect 人工智能05:AI Agent发展趋势
(1) 大模型与小模型优劣势大模型:①多任务处理②很好理解人类的意图③生成相关信息④隐私泄露问题⑤设备、能耗要求高⑥运行成本高昂小模型:①参数量小,能耗小,可以使用在端侧设备上,实现端到端运行②在一些领域中,小模型的处理效果比大模型效果好③训练数据相对单一,好处理④不同任务需要多次处理,相对复杂(2) AI Agent理解将LLM添加上工具插件,实现复杂的功能,有可能对软件进行革命。
AI Agent发展趋势
目录
一、AI发展之路
(1) 何为AGI
通用人工智能(AGl,Artificial General Intelligence)是一个人工智能理论研究领域,研究如何开发具有类人智能和自学能力的软件。其目标是让软件能够执行训练或开发目的之外的任务
当前的人工智能技术均依靠一组预先确定的参数运行,例如图像识别和语音识别;而近两年大火的LLM(大语言模型)本质上也只是在做文字接龙,依靠海量的权重参数输出结果。作为一项理论研究,AGI旨在开发具有自主自我控制、合理的自我理解以及新技能学习能力的人工智能系统。它可以在创建时未进行教导的环境和情境中解决复杂的问题。具有人类能力的AGI仍然只是理论概念和研究目标
(2) 大模型的突破性在哪?
在ChatGPT出现之前其实很多AI模型在特定领域已经做的很好了,基本可以取代人类,比如图像识别、语音识别等,可大大降低人工成本,而类似ChatGPT的对话机器人也有很多应用,虽然达不到人类的智力水平,但也可以解决部分问题
ChatGPT出现后展现出了强大的语言理解能力,这是以前的所有模型所不具备的,很多任务,只有听懂了才能做得好、做的对,ChatGPT的出现让大家看到了AGI的曙光
Sora出现后,大模型又在新的领域产生了突破,Sora生成的视频似乎包含了物理世界的规则,如浪花的溅射、光影的反射等
可以说,以前的AI就像个普通的工具,可以做一些简单且具体的任务,而大模型出现后AI具备了一定“思考”能力,可以做更加复杂且不太明确的任务
(3) 小模型的价值
大模型出现后小模型的研究并没有完全停止,小模型的优势如下:
①简单场景小模型效果足够好,没必要上大模型,如图像分类
②小模型现在的研究在改进推理速度上,降低部署成本,大范围使用,而大模型部署成本高
③通过压缩,小模型可以在端侧设备上运行且对续航影响较小
④小模型使用成本低,适合用于学校教学、个人学习等,降低了AI学习门槛
二、大模型的局限性
(1) 大模型设备需求
与小模型相比,大模型的训练和推理对硬件提出了更高的要求
高算力:
①由于大模型的参数量非常庞大,对应的就是计算量非常大,如果使用单个节点训练需要数年时间,因此需要并行训练,而互联带宽的需求也就出来了
大带宽:
①互联带宽:由于大模型需要并行训练,又涉及到了大量权重参数,因此对互联带宽提出了要求,现有的PCle无法满足,因此各个厂商都推出了专有协议用于计算节点互联,如HCCS、NVLink
②内存带宽:对于自回归形式的大语言模型,模型在Decoder阶段需要频繁读取模型和KV Cache的参数,而这个过程计算量并不高,瓶颈在内存带宽,因此高端的计算卡都会采用HBM内存,而HBM内存的成本比DDR要高很多
③集群间通信:单机内互联可以使用HCCS,而多机互联则需要通过网络,如果带宽无法保证,并行训练的速度将会受到影响,因此无损通信协议、高吞吐交换机、高性能通信算子等需求也随之而来
因此,从设备需求来看,大模型的大不止体现在参数规模,更体现在设备的需求和成本上
(2) 大模型能力局限
虽然大模型表现出了惊艳的能力,但是在某些简单场景却做的比较差,以下为一些示例及解释:
①姓名按笔画排序:让大语言模型按照姓名笔画进行排序,很多大语言模型会答得比较差,因为模型实际做的是next token的预测,它本身不知道或只知道部分汉字的笔画数
②数学计算:这个问题与上面的类似,大语言模型本身不具备计算能力,完全靠next token来预测出来准确的数值结果,难度太通大了
③文档检索:大语言模型的回答取决于模型本身的参数,假如咨询一些书籍或文献中的小范围问答,模型回答的效果也会较差
(3) 隐私保护问题
隐私泄露风险:
①由于大模型对硬件设备要求高,不是人人都能部署私有化模型,甚至不是所有企业都能部署大模型,而使用服务商提供的大模型服务,就存在信息泄露的风险
②在ChatGPT刚出现的时候,有新闻报到某企业全面禁用ChatGPT,原因是有员工拿公司机密信息与ChatGPT对话,可能导致商业机密泄露
私有化部署弊端:
①目前Intel和AMD都推出了集成专用AI模块的CPU,计划打造AIPC,受制于功耗、成本等因素,PC上只能运行一些较小的大模型(7B或者13B),而这些模型的能力与服务商提供的大模型服务相比,效果还是差了很多的
②除此之外,现在的手机芯片也都集成NPU,但可运行的模型规模有限,一般是运行小模型,难以达到理想的效果
综上来看,隐私保护与性能之间似乎难以取得平衡
(4) 小模型与现存API工具
目前互联网上存在各种各样的API工具,提供了天气查询、数学计算等各种功能,而各个云服务商也通过API对外提供各种服务,这些工具可以解决前面提到的姓名笔画排序、数学问题计算、文档检索等各种问题,如果在本地完成数据脱敏等操作,隐私保护的问题似乎也可以得到解决
假如大模型充当“大脑”,小模型充当“眼睛、嘴巴等”,各种API充当“计算器”等各种工具,那么前面提到的问题基本上都可以得到解决,离AGI也就更近了一步
三、AI Agent的优势与发展
(1) AI Agent介绍
AI Agent(智能体)领域演进极快,定义没有学术、工业统一,主流定义为能自主完成任务的AI智能体。Agent需要拥有记忆、工具、计划能力、执行能力等。主要用于自主完成任务。该定义较为广泛
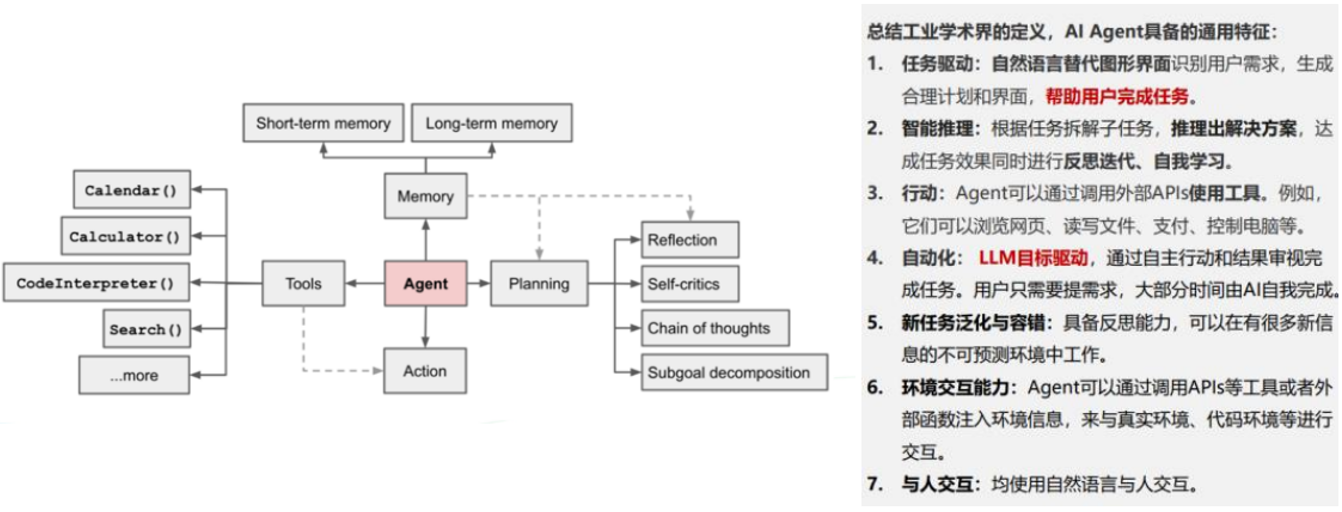
(2) AI软件演进趋势
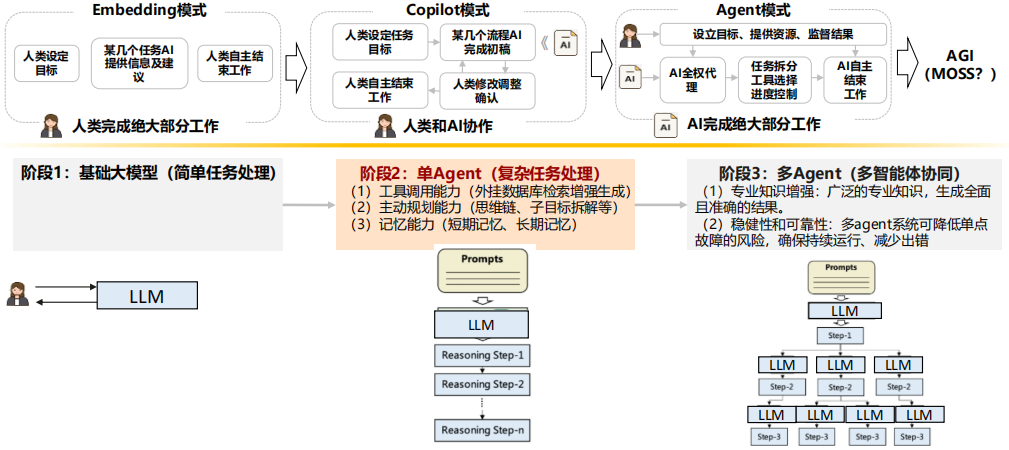
(3) AI Agent分析总结

四、模型协同技术与案例
(1) Function Call
Function Call可以让LLM支持工具调用,基本流程分为两部分:
①定义(并不是真的写程序去定义一个函数,而仅仅是用文字来描述一个函数)一些Function(需要指定函数名,函数用途的描述,参数名,参数描述),传给LLM
②当用户输入一个问题时,LLM通过文本分析是否需要调用某一个Function,如果需要调用,那么LLM返回一个json,json包括需要调用的Function名,需要输入到Function的参数名,以及参数值
③通过Function Call,LLM就可以实现查询天气、数学计算等功能
(2) 一些大小模型协同案例
在ChatGPT中,如果使用了GPT4,可以调用DALL-E来帮忙画图,同时也可调用OCR工具(基于AI小模型)来识别文字
ChatGLM提供了AI搜索功能,在模型感觉无法直接给出准确答案的情况下会联网搜索,然后给出更准确的答案,对于查询一些较新的知识很有用,右侧图片是在Meta论文发表3天后的查询结果,引用的网页很多都是查询当天刚发表的
可以发现,工具调用大大扩展了大模型的使用场景并提升了用户使用体验
(3) 多模态原生
各个厂商对于多模态模型的研究从未停止,传统的多模态基础模型通常为每种模态采用特定的编码器或解码器,这限制了模型有效融合跨模态信息的能力,而GPT-4o是首个端到端训练的模型,跨越文本、视觉和音频模态,所有的输入和输出都由单个神经网络处理,也就是原生支持多模态
Meta的研究团队推出了“混合模态基座模型”--Chameleon,与GPT-4o类似,变色龙也采用了统一的Transformer架构,使用文本、图像和代码的混合模态进行训练,通过将图像离散“分词化”(tokenization),变色龙实现了文本和图像序列的交替生成和推理
这两种模型的出现,相对于工具调用,可以提供更好的体验,不过工具调用覆盖的场景更多,扩展方便,两者都是未来研究发展的方向
总结
(1) 大模型与小模型优劣势
大模型:
①多任务处理
②很好理解人类的意图
③生成相关信息
④隐私泄露问题
⑤设备、能耗要求高
⑥运行成本高昂
小模型:
①参数量小,能耗小,可以使用在端侧设备上,实现端到端运行
②在一些领域中,小模型的处理效果比大模型效果好
③训练数据相对单一,好处理
④不同任务需要多次处理,相对复杂
(2) AI Agent理解
将LLM添加上工具插件,实现复杂的功能,有可能对软件进行革命

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)