ACL’25 Oral | 突破模糊瓶颈—LLM主动式不确定性识别与生成优化
本文主要考虑由于不确定性,模型无法直接回答问题,但存在某些方法可以帮助消除这种不确定性并生成更好的回答的场景,消除不确定性提升生成质量的方案主要有三种:Retrieval,CoT以及Clarification,分别对应三种不确定性的来源,文档稀缺,能力受限以及问题模糊,这三种提升生成质量的方法最为常见,因此我们选择对应的三种不确定性以涵盖大多数场景。为进一步证明我们的推断合理性,我们对于所面临的问
本文分享阿里妈妈智能创作与AI应用团队在LLM方向上提出的不确定性感知与分析问题,使模型主动感知不确定性类型,并采取针对性策略识别不确定性以获取更优的答案。基于该项工作总结的论文已被 ACL 2025 录用为 Oral Representation,并在阿里妈妈面向商家与广告主的对话式营销助手-AI小万的规划任务中应用,欢迎阅读或 ACL Oral 现场交流。
论文:Do not Abstain! Identify and Solve the Uncertainty
作者:Jingyu Liu*, JingquanPeng*, Xiaopeng Wu, Xubin Li, Tiezheng Ge, Bo Zheng, Yong Liu
论文地址:https://arxiv.org/abs/2506.00780
一、背景
近年来,大语言模型(LLMs)在文本生成、问答、代码编写、信息检索以及工具调用等多个领域展现出了强大的能力。然而,这些模型在面对超出其知识范围的问题时,常常表现出“过度自信”的倾向,即在并不确定答案的情况下仍给出看似合理的回答[1]。
为了解决这一问题,当前的研究主要采用一种保守策略:当模型意识到不确定性时,直接回复“我不知道”[2,3]。虽然这种方式在某些“不可知”问题(例如“2050年的天气如何?”)上是合理且必要的,但在许多可以解决的不确定问题中,这种简单回应却显得过于被动,错失了通过其他方式获取更优答案的机会。
如下表所示,对于不可知(unanswerable)的问题(例如“2050年的天气如何?”),无论模型的不确定性是高是低,都应当回复“I do not know”。但是对于可知的问题,如果模型的不确定性较低,可以使其直接给出答案,然而如果模型不确定性较高,则应当主动解决该不确定性,而非直接放弃回答。
过去的研究者也注意到了该问题,尝试通过模型向用户提问以获取clarification [4],或者通过检索的方法获取更多的文档信息[5]。然而他们仅仅考虑了固定的一种不确定性,未考虑到模型遇到的不确定性是多种多样的,模型需要首先理解该不确定性是由什么引起,而后采取针对性的解决策略,通过与用户或环境的交互解决该不确定性以获取更优的答案。

为此,我们构造了ConfuseBench,该benchmark中主要包含三类的不确定性——文档缺失、推理能力不足或问题本身模糊——模型在面对这些query时,应当判别出其不确定性的来源,并采取针对性的策略以解决其不确定性。比如,通过检索补充信息(RAG)、深度思考(Chain-of-Thought)或者向用户请求澄清以明确问题意图。
-
文档稀缺型:模型缺少关键事实信息;
-
能力受限型:问题复杂度超出现有模型处理能力;
-
问题模糊型:问题表述不清,存在多种解释或无法作答。
本文主要考虑由于不确定性,模型无法直接回答问题,但存在某些方法可以帮助消除这种不确定性并生成更好的回答的场景,消除不确定性提升生成质量的方案主要有三种:Retrieval,CoT以及Clarification,分别对应三种不确定性的来源,文档稀缺,能力受限以及问题模糊,这三种提升生成质量的方法最为常见,因此我们选择对应的三种不确定性以涵盖大多数场景。
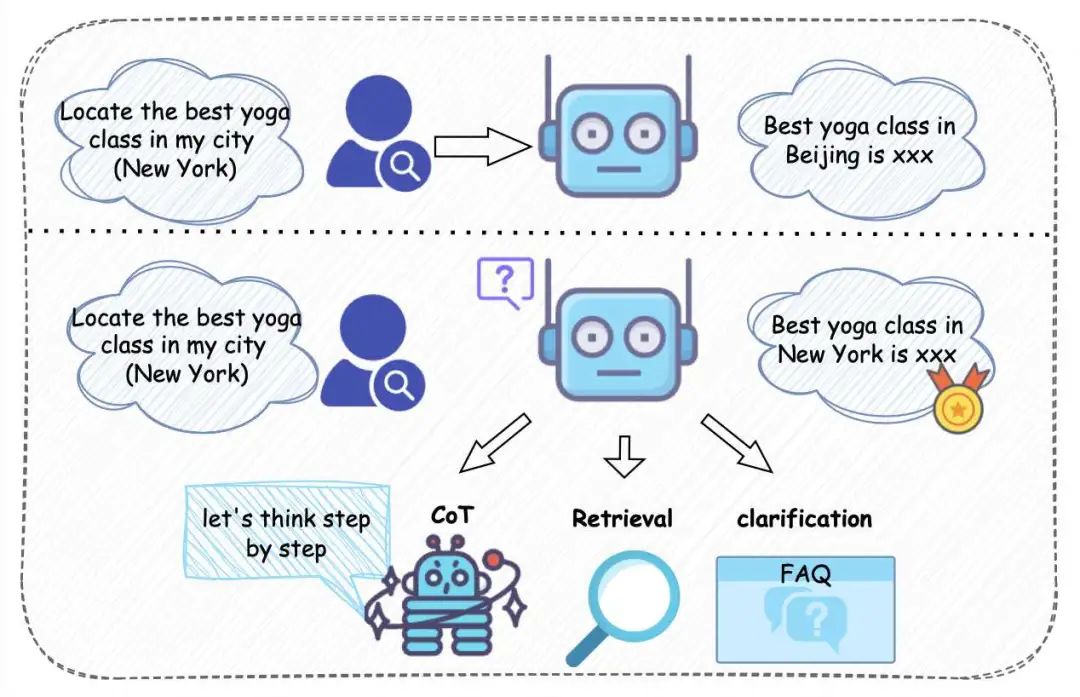
与以往仅关注准确率或基础不确定性判断的评测不同,ConfuseBench 更加强调模型是否具备诊断不确定性来源的能力。本文将围绕这三类不确定性展开分析,并探讨如何助大模型更好地应对不确定信息,从而生成更具质量保障的回答。
二、数据集构建
2.1 构建方法
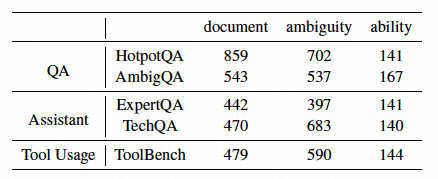
对于如何衡量LLM不确定性分析上,已有的benchmark和数据集上,单纯面向未知领域拒答,或仅仅考虑到单一检索澄清方法,这些工作没有覆盖系统性的对不确定性分析与解决,因为我们构建了ConfuseBench来更系统的评估和识别LLM中的Uncertainty。基于前文中提到的不确定性分类体系(文档稀缺型、能力受限型、问题模糊型),我们在三个典型应用场景中构建了不确定性案例:
-
基础问答(Basic QA) 包括 HotpotQA 和 AmbigQA 数据集,用于测试模型在知识密集型任务中的表现。
-
助手任务(Assistant) 使用 ExpertQA 和 TechQA,模拟真实场景中用户与AI助手之间的对话交互。
-
工具调用(Tool Usage) 基于 ToolBench 数据集,评估模型在需要调用外部工具时的推理与决策能力。
对于能力受限型的不确定性数据集构造,要求大语言模型(LLM)基于查询语句及完整标准文档集生成答案。若模型未能输出正确答案(该答案已明确包含在文档中),则判定其不确定性源于模型自身能力不足。
若模型成功生成正确答案,则通过:1)文档级的噪音注入:随机剔除部分标准文档内容;2)检索级的噪音注入:新增干扰项并引入无关新文档。若模型无法保持正确应答,则判定该不确定性由文档缺失引发。值得注意的是,不同大语言模型的知识边界与能力阈值存在差异,因此需要对与Benchmark的数据集进行难易度判断,若模型基于原始查询和文档能生成正确答案,此类案例将被标记为"无不确定性",并自动排除在评估范围之外。
而问题模糊型的数据构建相对复杂,对于AmbigQA 数据集,我们直接进行复用,对于其他几个数据集我们参考了传统NLP方法中的Parsing思想,基于AMR构建相关语义解析图,并基于此进行增强。具体步骤如下:
-
数据解析图构建:将原始查询转换为抽象语义表示(AMR)并通过实体节点及其关系网络构建图结构
-
噪音注入增强:引导GPT-4o对AMR图进行修改以引入模糊性,如成分删减(删除修饰词与描述性语素),关键信息遮蔽(选择性省略核心信息),关系扰动(调整节点间逻辑关系),并基于上述增强后的结果重构AMR拓扑。
-
模糊查询生成:最终基于上一步产出的语义解析图逆向转换为自然语言查询,同步生成对应的澄清说明文本。
基于上述的方法,若模型无法正确响应模糊查询,以及在获得澄清说明后可以正确回答,则说明该query存在模糊性,注入到数据集中。
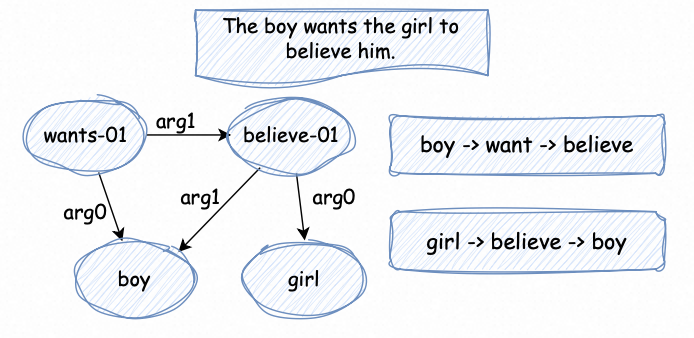
AMR for "The boy wants the girl to believe him."
最终基于上述的合成方法构建的数据量级如下,最终为确保数据问题分布的多样性以及质量,我们通过人工筛选最后构建出650条数据。
2.2 数据验证
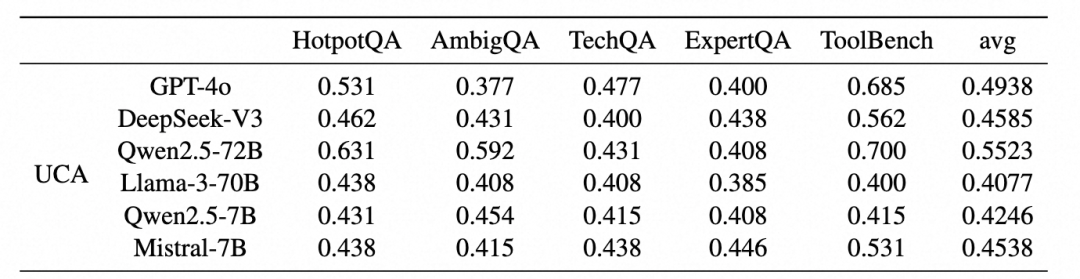
为了验证数据集质量,我们对当前主流的大语言模型进行了初步测试,包括 GPT-4o、DeepSeek-V3、Llama3、Qwen2.5 等多个代表性模型。评估模型是否能识别问题的不确定性来源。其中UCA代表Uncertainty Classification Accuracy,
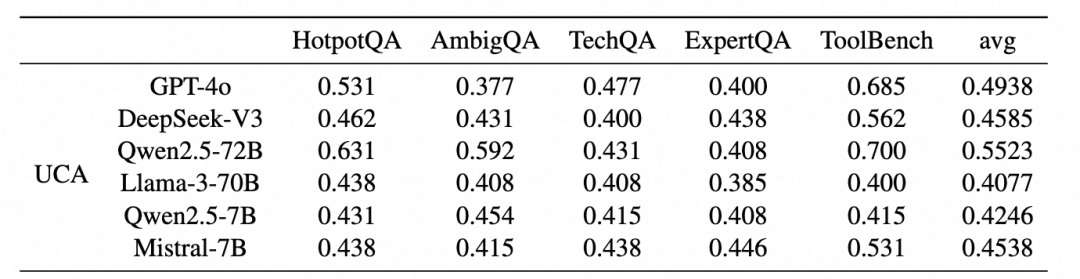
可以看到,即使是哪些比较强的模型,在识别不确定性的源头方面也仅能达到约 50% 的准确率。而一些较小的模型,表现更差,几乎无法有效识别不确定性的原因。
并且,我们发现多数模型在遇到不确定问题时,更容易判断为“问题模糊”,而不是“文档缺失”或“能力不足”。这导致它们频繁地向用户提出澄清请求,而不是尝试通过检索或推理解决问题。
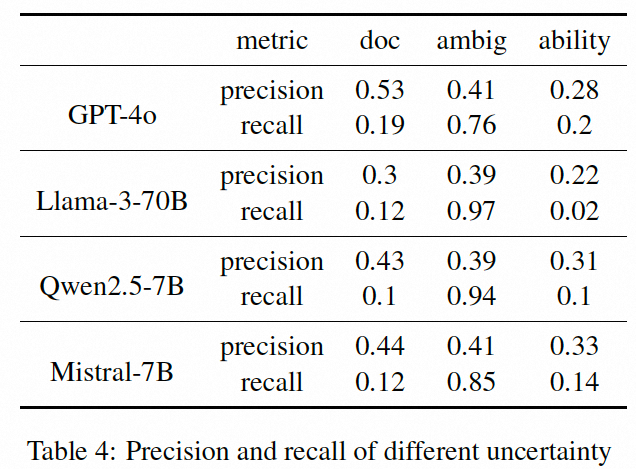
如上左图所示,在一个原本清晰但伴随干扰文档的问题中,模型反而要求用户重新表述问题,似乎更愿意相信文档的有效性而非问题本身的明确性。同时大多数模型很少承认自己是因为“能力不足”而无法作答。这种现象类似于人类的“过度自信”心理 —— 宁愿给出错误答案,也不愿承认“我不知道”。下表中对于不确定来源的准确和召回,也定量的证实了上述的观点。较弱的模型倾向于进行反问澄清而解决类似的问题而不是深入给出不确定性来源。而所有的模型在“能力不足”上的准召上都在一个较低的水位。
三、方法
3.1 不确定性判断
在当前的主流方法中,如何先验的识别模型对于一个问题的不确定性类别与来源,是个极具挑战的问题。但在实际测试中我们发现,很多模型虽然不能准确识别不确定性的根源(比如是文档缺失、能力不足还是问题模糊),但它们仍然能够生成合理的Inquiry及澄清性提问。因此我们通过评估后验的Inquiry类型,来指导模型对于LLM不确定性的来源判断。以下是一些例子:
-
如果模型问:“你是说北京还是上海?”——可能是由于问题模糊;
-
如果模型问:“有没有相关的资料可以参考?”——可能是由于文档缺失;
-
如果模型只是重复原问题或语焉不详——可能是由于自身能力不足。
我们可以发现,模型生成的inquiry似乎本身就可以代表着原始query的不确定性类型。因此我们先让模型对问题进行澄清,并观察其提问的内容如果提问指向多个可能的答案 则为问题模糊,如果提问要求提供更多背景信息则归类为文档缺失,如果提问只是重复原问题或含糊不清则其表现为能力不足。
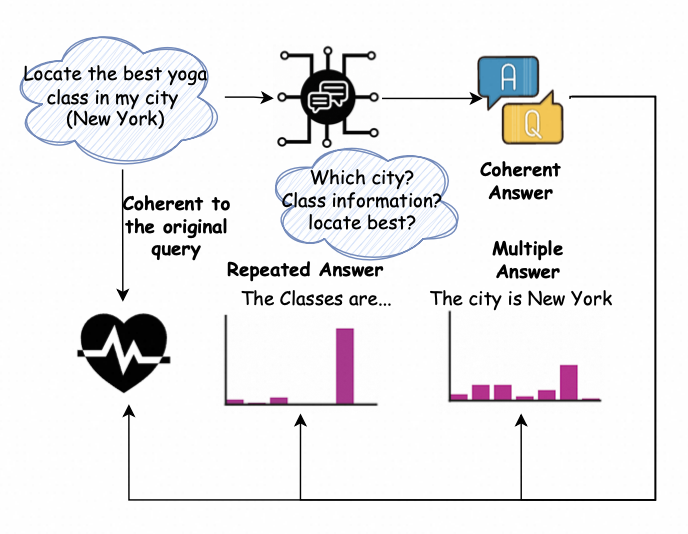
同时受到[6]的启发,也为了对Inquiry进行进一步的评估,我们模拟Inquiry与环境交互的结果,让模型对inquiry进行回答,根据Inquiry可能的环境模拟反馈结果,进一步辅助判断不确定性类型:
-
如果是文档缺失型问题:模型不具备回复该问题的能力,则模型会倾向于接受并复述这个答案。
-
如果是问题模糊型问题:有很多答案可以很好的回答该问题,模型可以生成不同的合理回应。
一种类似“信念测试”的方法。先给模型一个假设答案,再让它尝试生成另一个不同的答案。
3.2 理论证明
为进一步证明我们的推断合理性,我们对于所面临的问题进行形式化并给出初步的理论证明,给定查询词x,以及对应的回复 y,相关的知识文档d,澄清查询c。θ为模型参数,则Uc为模型能力不确定性、Uk为知识文档缺失造成的不确定性、Ua为模糊不确定性。

该定理认为,如果模型有能力生成高质量的inquiry,那么该inquiry所包含的不确定性与原始查询相似。反之,如果inquiry是无意义的,则表明模型未能很好地理解该查询,同时也表明其能力不足。具体理论证明可以见论文中附录。
3.3 实验结果
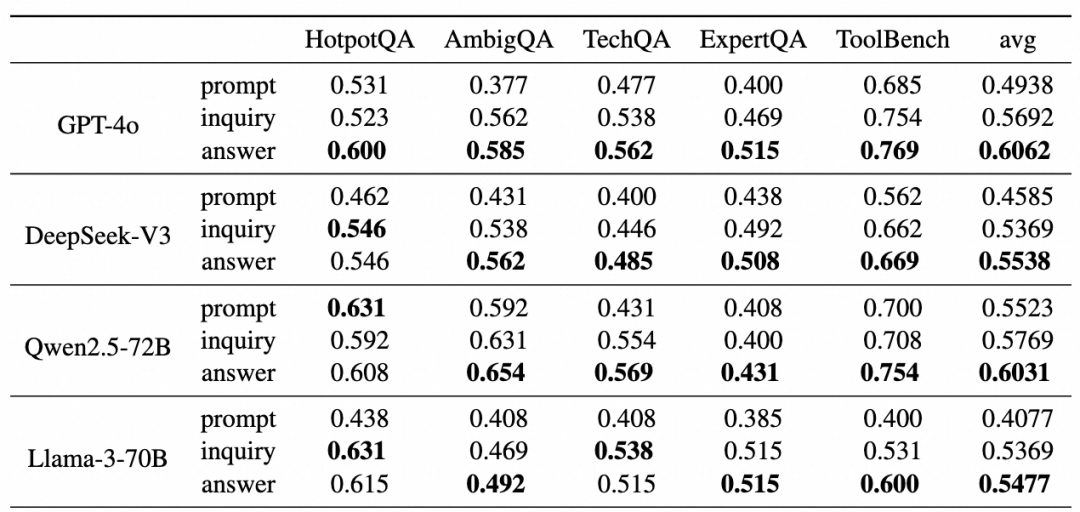
基于上述的Motivation,我们基于ConfuseBench的数据构建方法进行数据构建与方法实践,并在ConfuseBench上进行Evaluation,发现通过inquiry以及inquiry answer判断不确定性的类型取得了一定的提升,模型可以识别不确定性的来源。
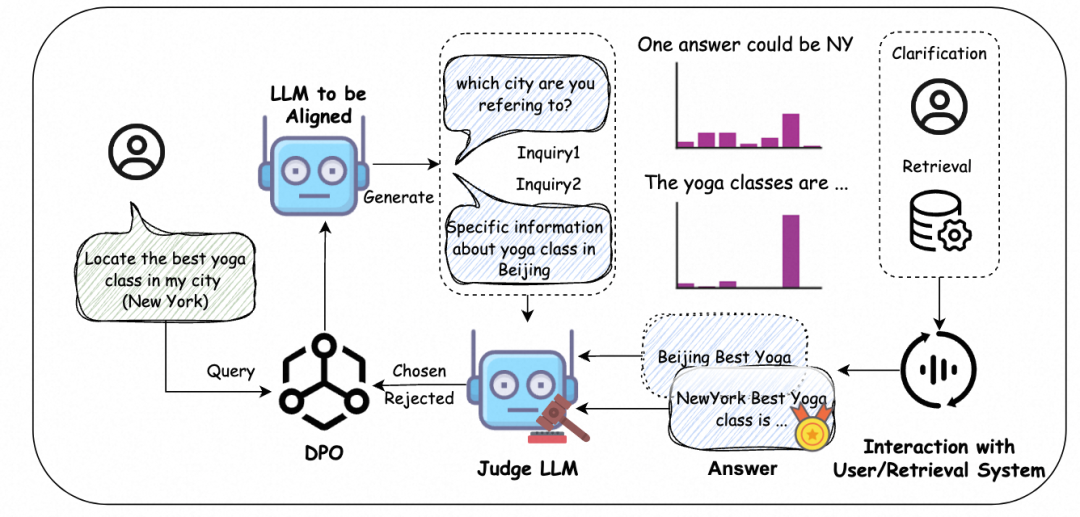
为进一步提升其性能,我们通过一种on-policy的DPO方法提升模型生成的inquiry质量,具体来说,在训练过程中,针对一个query,我们使用模型在线生成一个对应的inquiry,并尝试通过该inquiry判断不确定性来源解决该query,如果当前的inquiry可以成功解决该query,将其设为chosen,否则设为rejected,通过on-policy的训练方法进一步提升其性能。
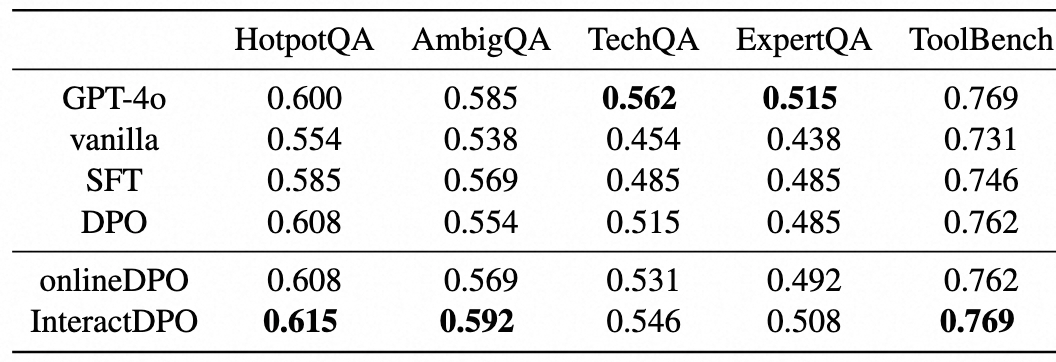
该方法的设计与实验在2024年底,与当前较为流行的GRPO叠加Verified Reward方法有异曲同工之妙。更多基于RL的方法来解决LLM不确定性的问题也在探索中。
四、应用
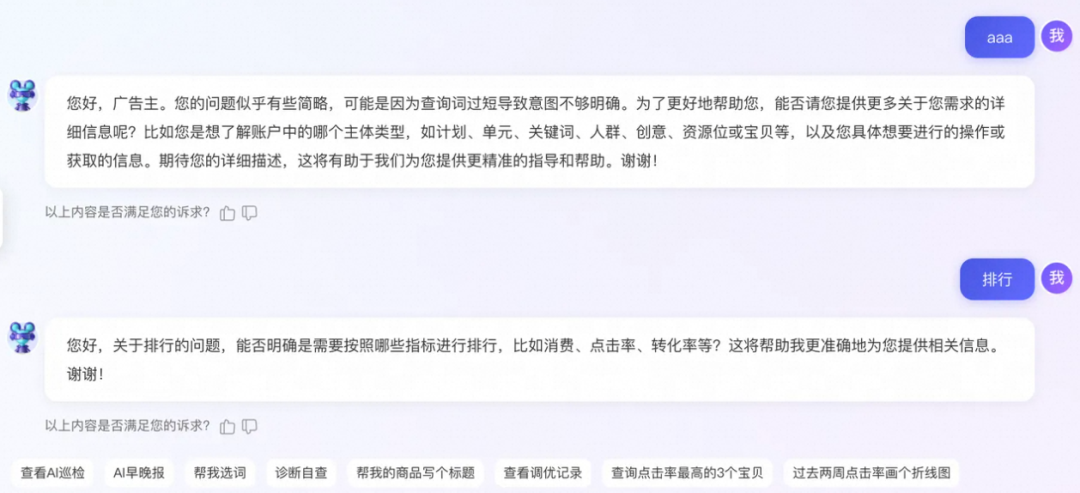
文中的数据构造方法与不确定性识别方法当前应用于阿里妈妈广告主Copilot工具(618现货倒计时1天,赶紧用AI小万秒级批量调优!以及 揭秘阿里妈妈『AI小万』背后的AI Native工程能力 )的规划模型中模糊意图澄清、澄清Inquiry生成等场景中。为进一步提升面向业务提升数据质量,参考了体育联赛中的并行小组赛打分策略[7]。将生成的模糊query两两匹配,使用LLM as judge方法挑选出优胜者,而后再对优胜者两两匹配,如此不断进行两两比较,挑选出较优的模糊query进行模型训练以增强其性能。
五、总结
在本研究中,旨在系统评估大语言模型(LLMs)在面对不确定性时的来源分析,我们提出了新的评测基准 ConfuseBench,同时基于此评测基准,我们提出了一种On-Policy DPO的方法提升对于不确定性时的识别与应对能力。不同于传统评测仅关注答案准确性或是否拒绝回答,我们的方法更强调模型能否“诊断问题来源”并“主动求解”。
我们的初步测试表明,当前主流模型在识别不确定性的根源方面仍存在明显不足,倾向于将问题归为“模糊性”并频繁请求澄清,而忽视文档缺失或推理能力不足的问题。为此,我们提出一种基于“提问与回答”的新方法,利用模型生成的澄清inquiry及其回答来辅助判断不确定性的类型,从而引导更有效的解决策略。
参考文献
[1]Xiong M, Hu Z, Lu X, et al. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms[J]. arXiv preprint arXiv:2306.13063, 2023.
[2]Li J, Tang Y, Yang Y. Know the unknown: An uncertainty-sensitive method for llm instruction tuning[J]. arXiv preprint arXiv:2406.10099, 2024.
[3]Feng S, Shi W, Wang Y, et al. Don't Hallucinate, Abstain: Identifying LLM Knowledge Gaps via Multi-LLM Collaboration[J]. arXiv preprint arXiv:2402.00367, 2024.
[4]Qian C, He B, Zhuang Z, et al. Tell me more! towards implicit user intention understanding of language model driven agents[J]. arXiv preprint arXiv:2402.09205, 2024.
[5]Wang R, Zha D, Yu S, et al. Retriever-and-Memory: Towards Adaptive Note-Enhanced Retrieval-Augmented Generation[J]. arXiv preprint arXiv:2410.08821, 2024.
[6]Abbasi Yadkori Y, Kuzborskij I, György A, et al. To believe or not to believe your llm: Iterative prompting for estimating epistemic uncertainty[J]. Advances in Neural Information Processing Systems, 2024, 37: 58077-58117.
[7] Chen Y, Liu Q, Zhang Y, et al. Tourrank: Utilizing large language models for documents ranking with a tournament-inspired strategy[C]//Proceedings of the ACM on Web Conference 2025. 2025: 1638-1652.
🏷 关于我们
我们是阿里妈妈智能创作与AI应用,专注于智能创意创作与投放、AIGC、LLM应用等方向,欢迎各业务方关注与业务合作。同时,真诚欢迎具备CV、NLP和推荐系统相关背景同学加入!
📮 投递简历邮箱:alimama_chuangyi@service.alibaba.com
END

也许你还想看
更真、更像、更美:阿里妈妈重磅升级淘宝星辰视频生成大模型 2.0
懂你,更懂电商:阿里妈妈推出淘宝星辰视频生成大模型及图生视频应用
NeurIPS'24 | FlowDCN:基于可变形卷积的任意分辨率图像生成模型
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)