从0构建大模型知识体系(5):大模型BERT
Transformer的大儿子,NLP通用模型

更好的阅读体验可以直接点击这里
按照惯例,结论先行
这篇文章要讨论啥?
讨论由 Transformer 编码器部分发展而来的大模型 BERT。这是一个里程碑式的大模型,它凭借深远的技术影响力早已成为众多互联网应用(如搜索、推荐)的核心,因此学习 BERT 有助于我们洞悉当前大模型强大能力的技术奠基与实际价值。
文章讨论的核心问题和结论是啥?
① BERT 是什么,它与 Transformer 有什么关系?
BERT 是一个基于 Transformer 的编码器部分发展而来的模型,旨在通过预训练成为一个“通用”的语言理解模型。BERT 与 GPT(基于 Transformer 解码器发展而来)并列为 Transformer 架构的两个最负盛名的分支。
② BERT 如何实现其“通用性”并解决多种自然语言处理任务?
BERT 的“通用性”是通过预训练实现的。之后进行简单的微调就能解决多种 NLP 任务。 这种“预训练 + 微调”的范式是 BERT 成功的关键。
③ BERT 是如何预训练的?
通过“完形填空”和“判断下一句”两个无监督的预训练任务。完形填空指在输入句子中随机遮盖一部分词再让模型预测这些被遮盖的词是什么。这迫使模型理解上下文信息来推断词义。判断下一句是指给模型输入两个句子A 和 B,让模型判断句子 B 是否是句子 A 在原文中的下一句,以此让模型学习句子间的关系和连贯性。
④ BERT 的实际应用价值和影响如何?
学术上 BERT 的引用量为13万,远高于GPT 的1.3万。行业应用上 BERT “一次训练、多次复用”的特性非常契合互联网行业快速迭代的需求,已广泛应用于各互联网业务中。美团在其业务中应用 BERT 提升了用户评论情感分析的准确性、搜索词意图识别准确率以及搜索词改写准确率,并估算能带来显著的年营收增长。
“BERT 饱览了世间所有情话,只为在你每一次轻唤时都能恰如其分地温柔”
——题记
在上一篇文章《从0构建大模型知识体系(4):大模型的爸爸Transformer》中我们聊到,Transformer 以注意力机制为核心搭建了编码器-解码器(Encoder-Decoder)架构,编码器负责将输入转化成机器可理解的代码,解码器负责将代码转化成人类可理解的输出。这种完全以注意力机制构建起的编码器-解码器架构彻底解决了 RNN 健忘和训练慢的老大难问题,且在多项语言翻译任务上取得了最佳成绩。
在此之后,大量基于 Transformer 的模型被提出,其中最负盛名的两个模型便是 BERT 和 GPT。前者基于 Transformer 的编码器发展而来,后者则基于 Transformer 的解码器部分发展而来。本文将详细讨论 BERT。
诶~我好像听到屏幕前有人说“GPT 我知道,但从来没听说过 BERT ?没觉得它很有名啊?”确实,BERT 并不能像 GPT 那样可以做个非技术人群也能轻松使用的聊天机器人,所以在技术圈外名气没有 GPT 大。但在技术圈内 BERT 的名气可是 GPT 的 10 倍。截止到2025年5月,BERT 的原始论文引用量为13万,十倍于 GPT 的1.3万

BERT 在技术圈内之所以能这么火热的一个重要原因是它只需要经过简单的调整便可处理一堆自然语言任务。这一特性使得研究者们纷纷基于 BERT 进行优化改造,在解决实际问题的同时,也为学术成果的产出提供了便利。换句话说,BERT 真正实现了 NLP 学者们长期以来的理想 —— 打造一个 “通用” 的语言模型。
从通用语言模型说起
BERT 出现前,解决一类任务需要专门设计一种模型。 比如在之前的文章中我们用 RNN 解决文本生成类任务,用 Transformer 解决翻译类任务。可一旦遇到新任务还得重新设计一个模型,这未免也太麻烦了。
BERT 出现后,解决一类任务只需要在 BERT 的基础上简单改改即可。 有了 BERT 之后,我们只需要在 BERT 的基础上外装一些“配件”就能解决问题。比如一个马达,给它外装四个轮子可以当车用,外装个搅拌棒可以当搅拌机用,外装个圆盘刀片可以当切割机用。类似地,通过外装一些简单的结构,BERT 就能同时胜任阅读理解、文本分类、语义匹配等多种任务,所以被称为 “通用”。
BERT 能做到“通用”主要得益于基于 Transformer 编码器的设计。 回顾一下,Transformer 是一个采用编码器-解码器架构的翻译模型,其中编码器负责理解原文的语义,解码器负责将语义翻译成目标语言。所以 Transformer 的编码器本就是一个强大的语义理解器,要是把它单独拿出来再增强一下,那这语义理解能力岂不是能飞天?诶,没错,BERT 就是这么做的,而且成功了。所以下面我们来看下 BERT 的具体设计
这,就是 BERT
BERT的基本组成单元:Transformer 的编码器块(Transformer Encoder Block)。 在上一篇文章《从0构建大模型知识体系(4):大模型的爸爸Transformer》中我们的 Transformer 架构图是这样的
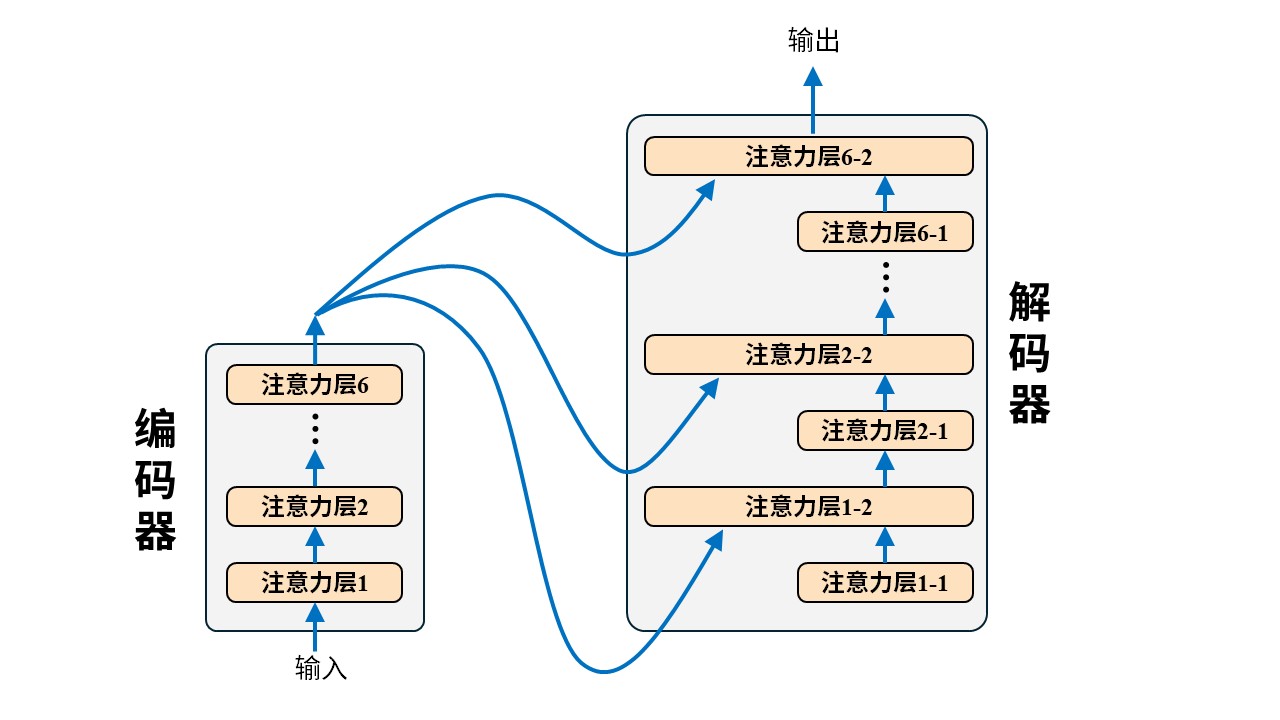
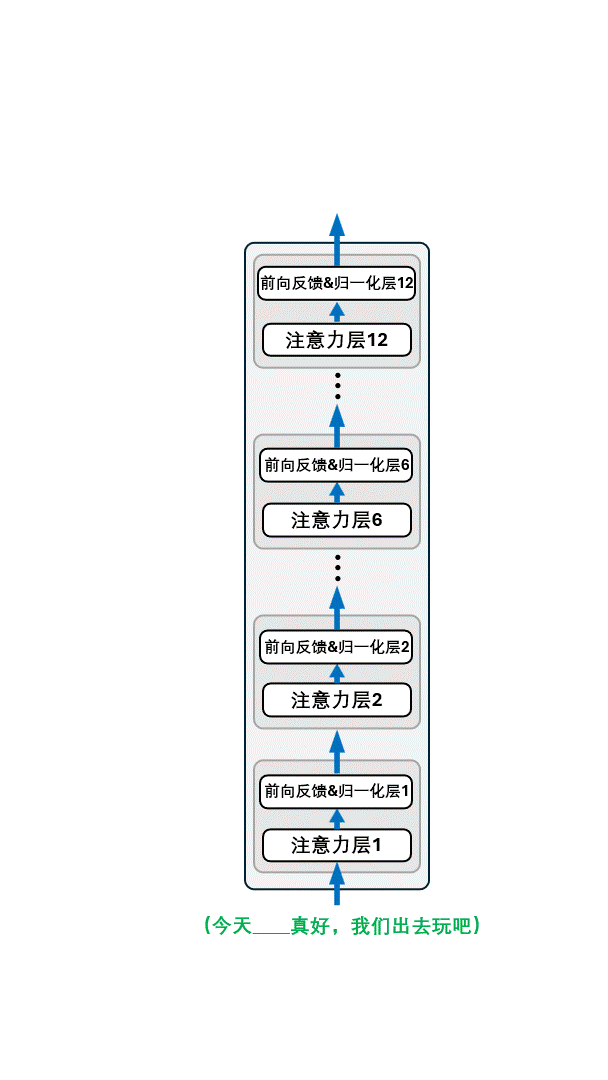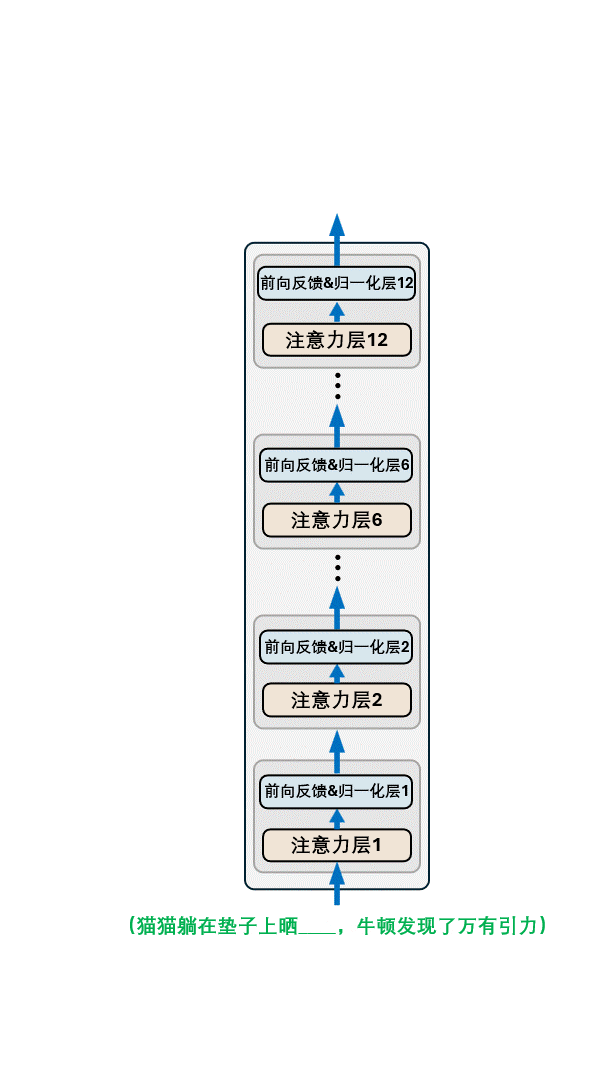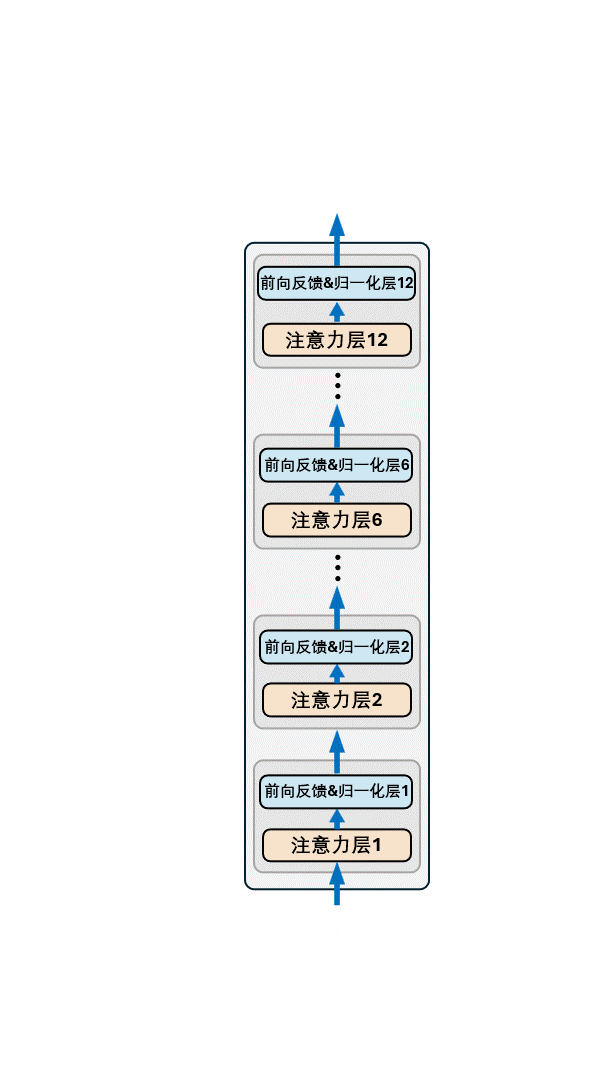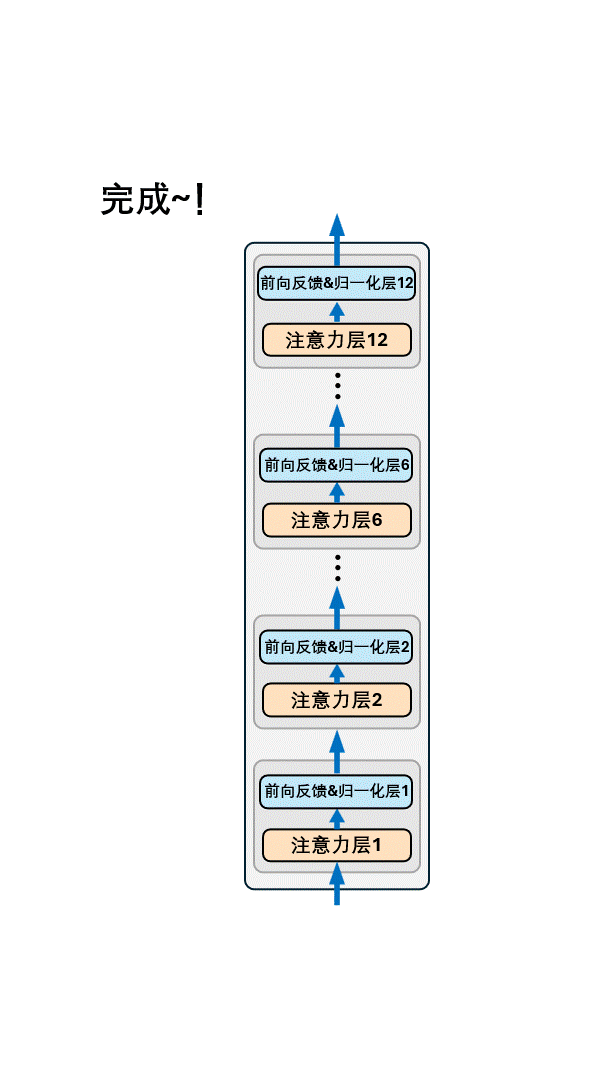
其中为便于理解,编码器部分只画出了注意力层,而实际上真正的 Transformer 编码器中每个注意力层还会搭配一个前向反馈和归一化层,也就是下图这样
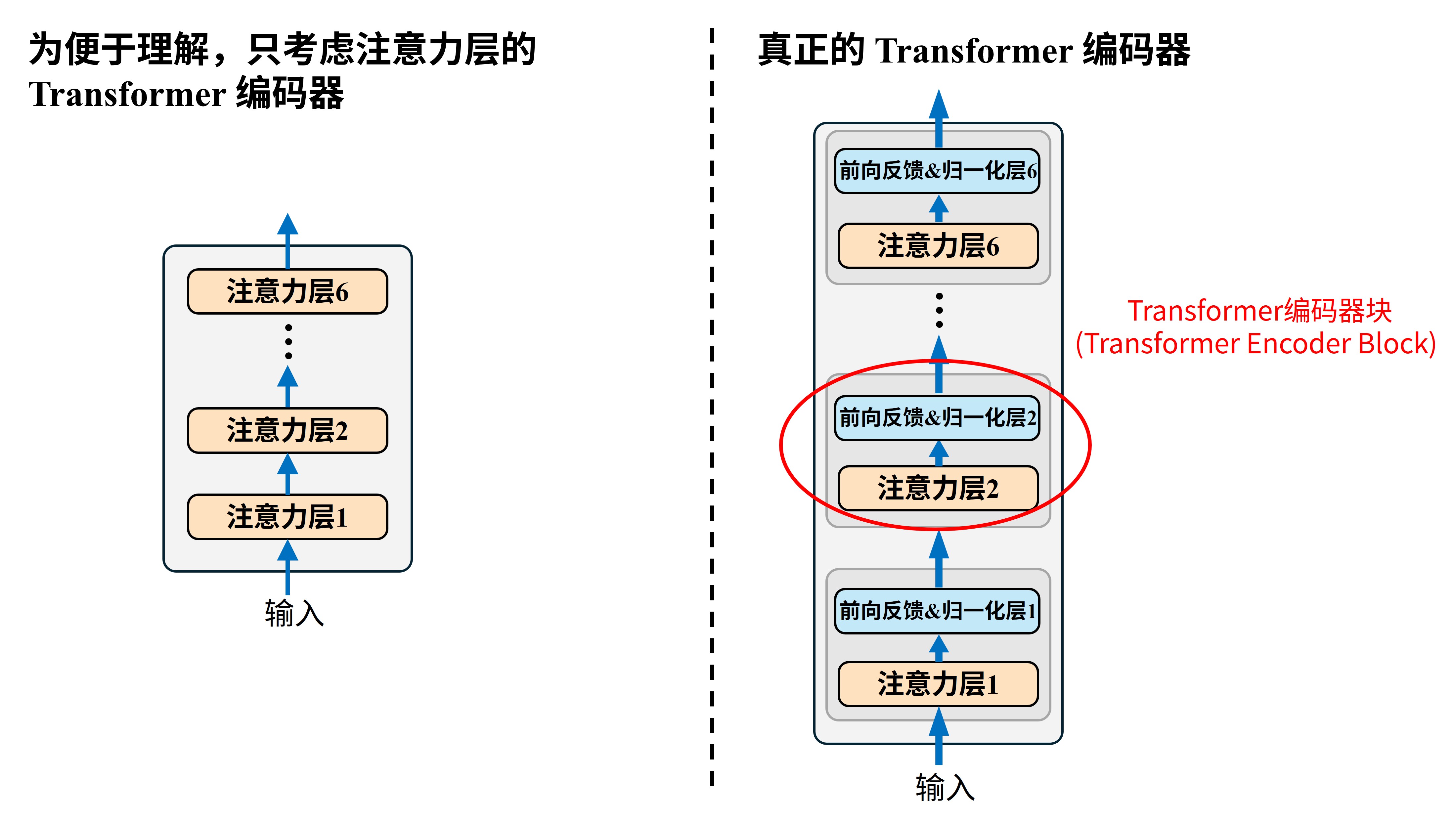
这个层的作用简单来说是对注意力层输出的整合,对非技术同学来说无需过多关注。一个【注意力层】外加一个【前向反馈&归一化层】就被称作一个Transformer 编码器块(Transformer Encoder Block)。
BERT 就是12个 Transformer 编码器块的叠加。 Transformer 的编码器一共有6个这样的模块,而 BERT 则有12个,二者的核心差别就在模块数量上,也就是下面这样
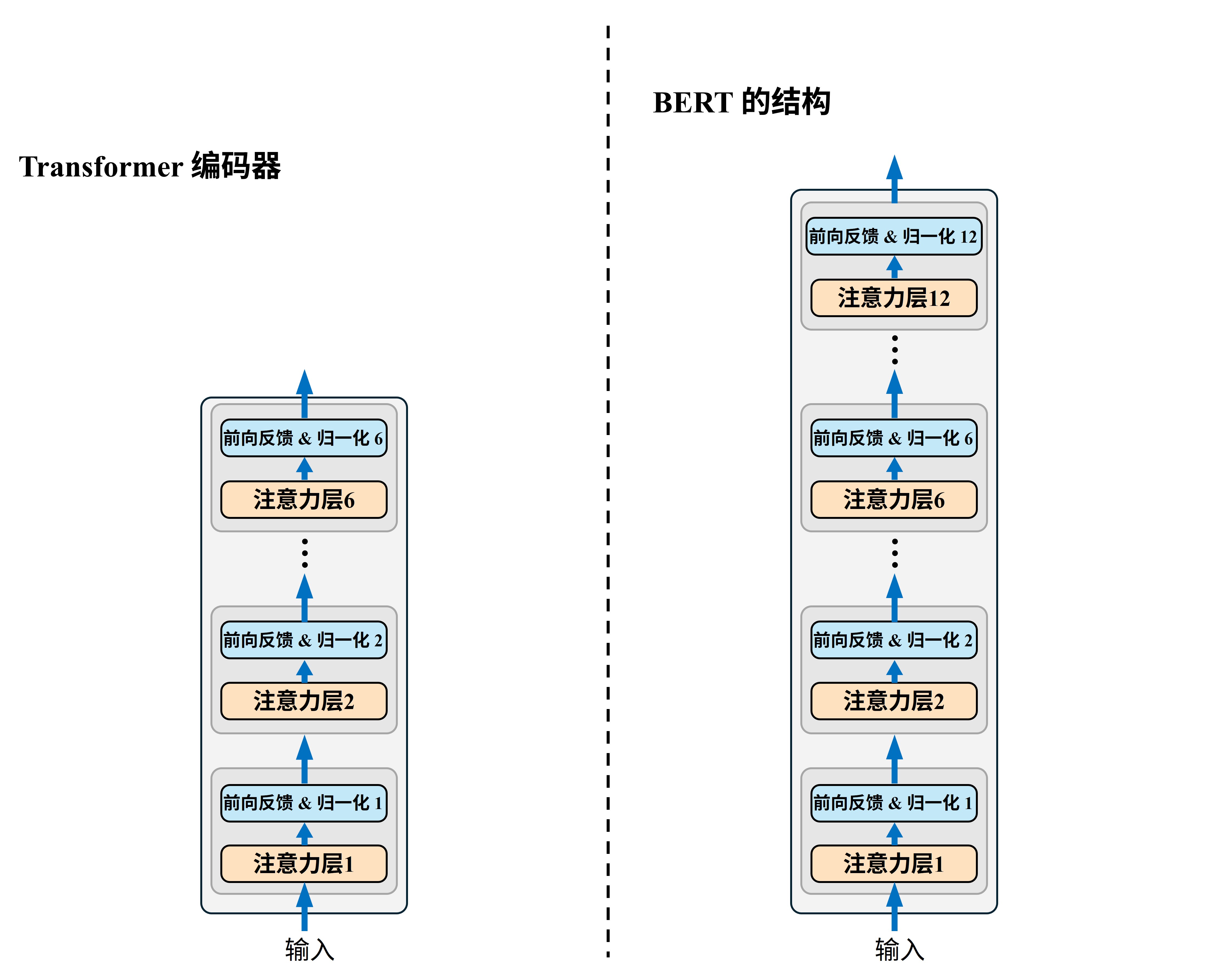
然后,BERT 就搭建好了…没错,真就这么简单。但其实在原论文中除了用12个这样的模块搭建BERT外,作者还测试了用24个来搭会得到什么效果,最后结论是越大越好。
到此,我们已经完成了 BERT 的搭建。但完成搭建仅仅是开始,更关键的是要让它具备理解自然语言的能力,成为一个通用语言模型。而让 BERT 具备这种能力所进行的训练任务有两个:“完形填空”和“判断下一句”。
BERT 的两大训练任务:“完形填空”和“判断下一句”
完形填空:从一句话中随机遮住一个词,让模型预测被遮住的词是什么。 举个例子:
- 原句:这老板真水
- 遮住“老板”:这____真水
- 任务:让 BERT 预测被被遮住的词是什么,我们期望模型能输出“老板”这个词
判断下一句:给模型两个句子A和B,让它判断句子B是否是原文中句子A的下一句。 举俩例子:
例子一:
- 句子A:今天天气真好
- 句子B:我们去公园玩吧
- 任务:让 BERT 判断句子B会不会是原文中句子A的下一句话,我们期望 BERT 能输出“是”
例子二:
- 句子A:今天天气真好
- 句子B:这老板真水
- 任务:让 BERT 判断句子B会不会是原文中句子A的下一句话,我们期望 BERT 能输出“否”
如此一来,我们让 BERT 在“完形填空”中学会通过上下文信息来推断词义,以及在“判断下一句”中学习句子间的关系和连贯性。这样 BERT 就能逐渐学会深刻理解词语含义和句子之间的逻辑关系。
模型结构有了,训练方式也清楚了,接下来就是准备训练数据并开始实际训练了。
训练前:准备训练数据
文档级语料:BooksCorpus 与英文维基百科。 BERT 的训练数据来源于 BooksCorpus(收录了约7000本书,共计约8亿英文单词)和英文维基百科(约25亿英文单词)。需要特别注意的是这两个数据集中的语料都是文档级的,好处在于文档级语料保留了原文结构与上下文,利于提取长连续文本序列,从而能让模型学习复杂语义。
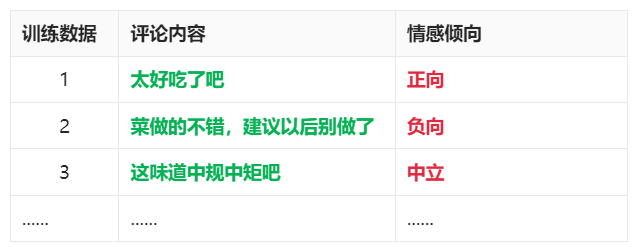
无需人工标注便可构造训练数据。 显然,对于“完形填空”任务来说我们只要随机从已有的句子中遮挡住几个单词就行,这事儿完全可以自动化快速搞定。对于“判断下一句”任务来说哪些句子在原文中是挨在一起的我们也知道,所以也无需人工标注。因此我们可以快速构造如下的训练数据:
- 完形填空训练数据:
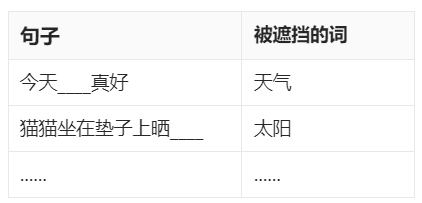
- 判断下一句训练数据
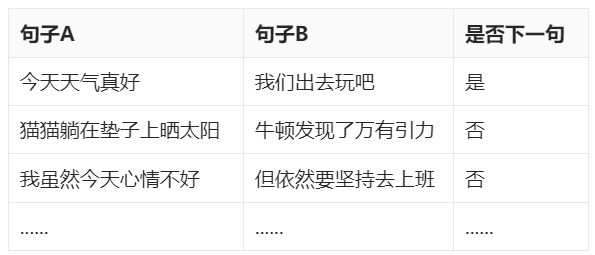
将二者结合一下得到最终的训练数据

训练中:这,就是预训练
以第一条数据:(今天____真好,我们出去玩吧),(天气,是) 为例:
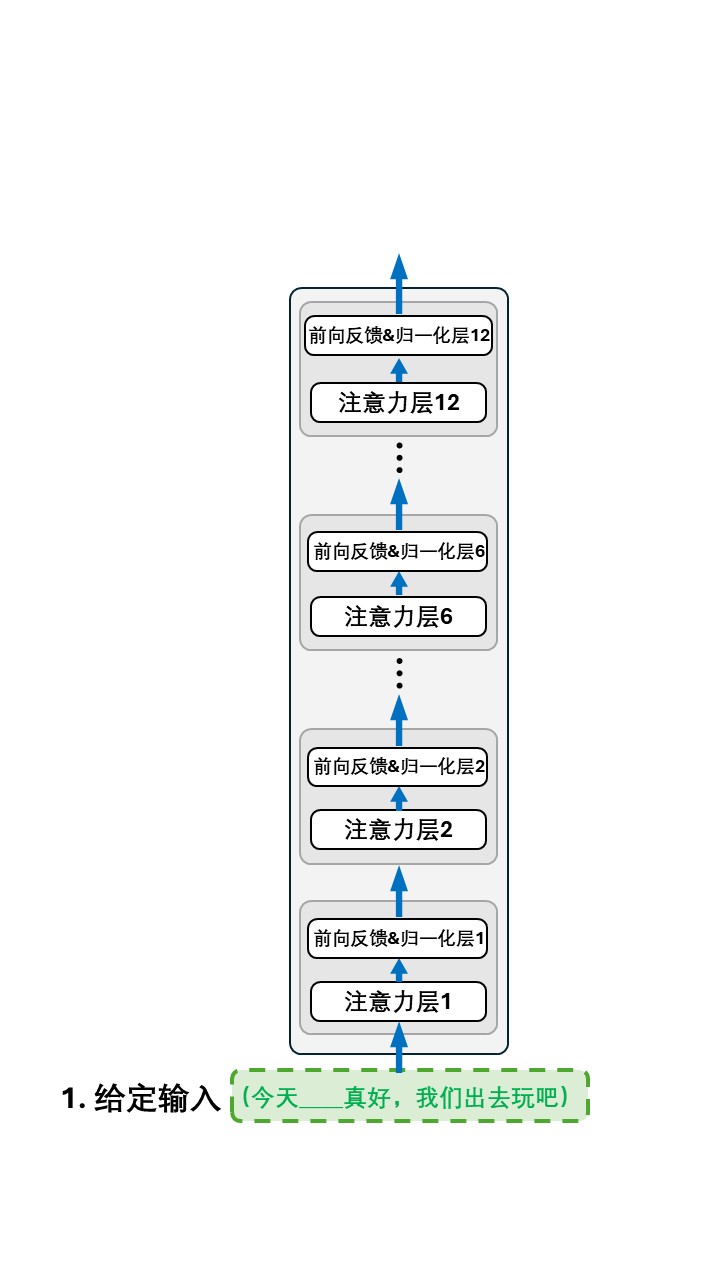
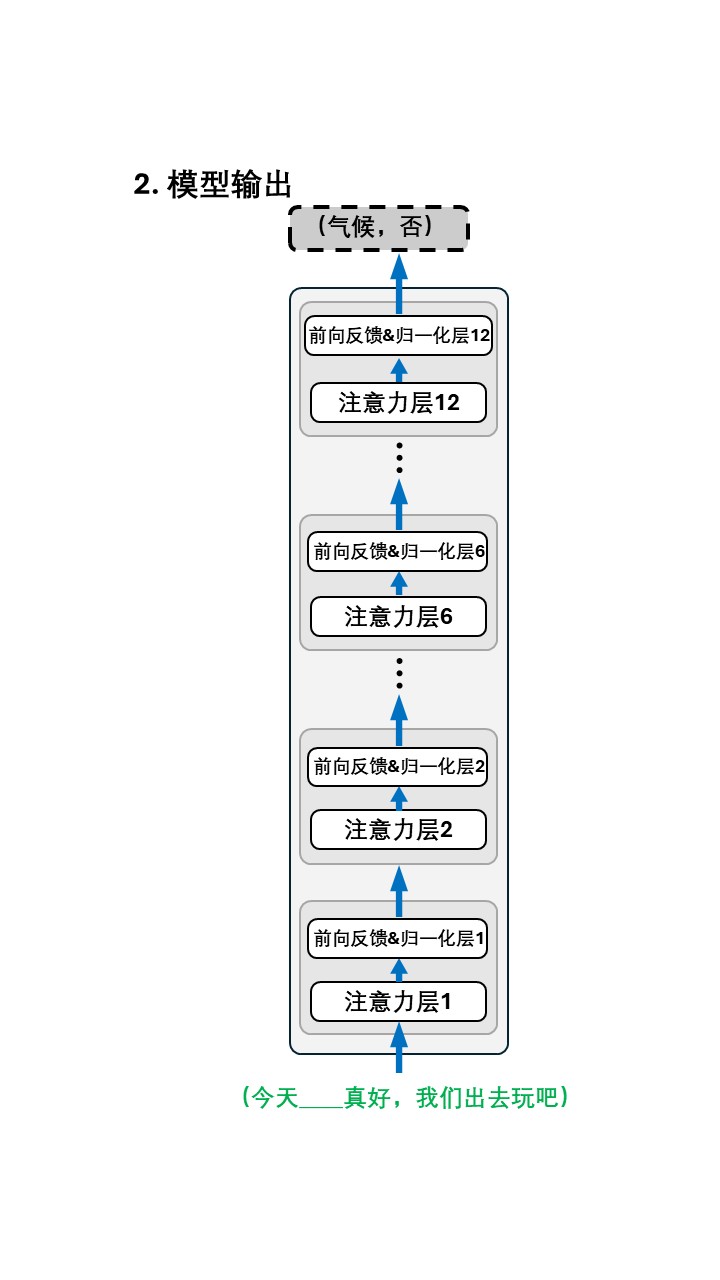
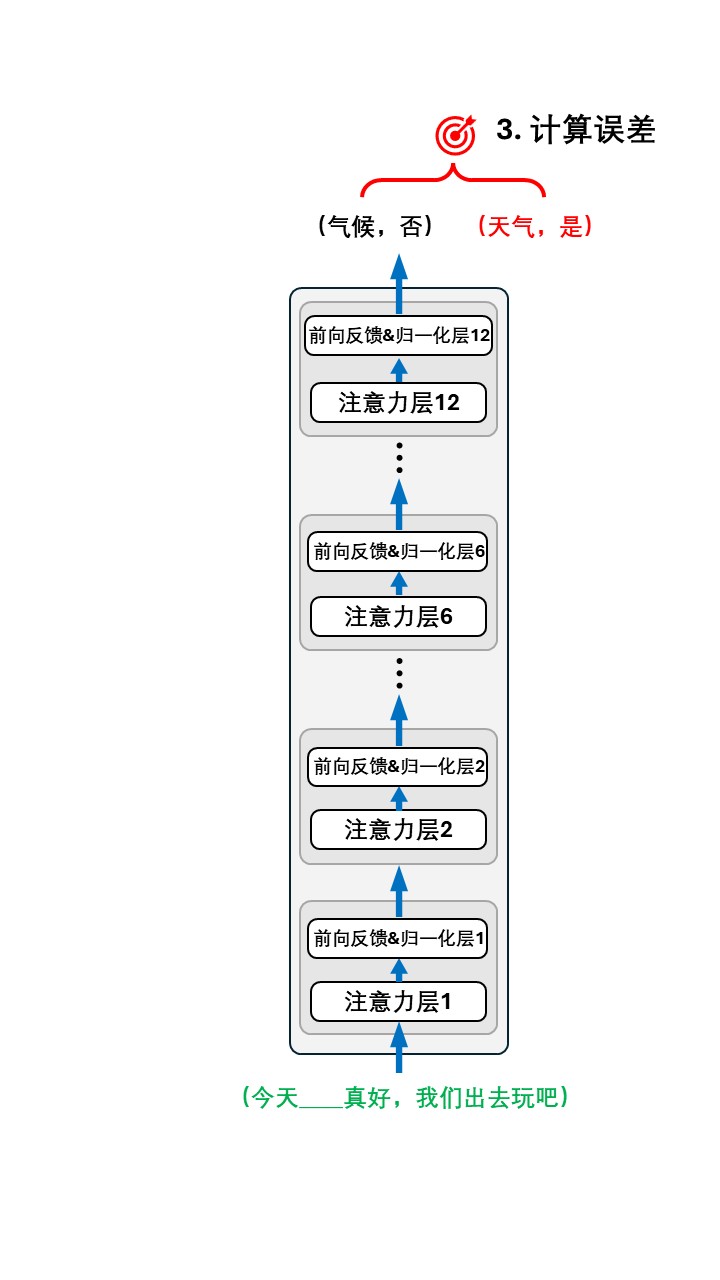
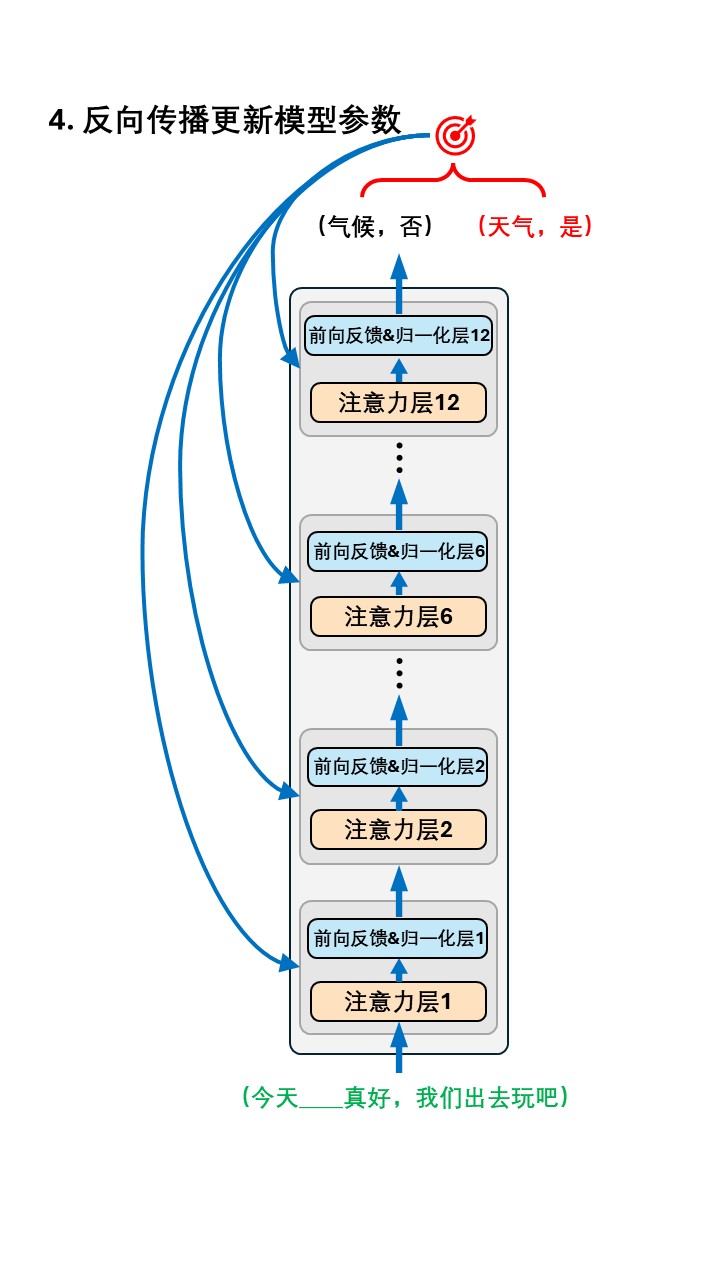
所以整个训练过程可以这样表示:
单论训练过程,预训练和之前我们介绍的模型训练并没有什么不同。 二者都是给定输入数据,让模型输出,计算模型输出的误差然后用来反向传播更新参数。那二者的核心差别在哪呢?
预训练和正常训练的核心差别在于训练目标是否直接指向某个具体任务。 比如对于“判断用户评论的情感倾向是正向还是负向”这个具体任务而言,目前我们所做的“完形填空”和“判断下一句”训练并不能让模型直接完成这个任务,但我们知道这俩任务是在帮模型先建立起基本的语义理解能力,对最终完成这个任务肯定是有帮助的,因此这里的训练被称作“预训练”。
训练后:微调即可完成众多 NLP 任务
微调 = 添加配件 + 少量数据训练。 对BERT进行微调一般包含两项具体的工作:
- 根据目标任务为 BERT 添加合适的输入转换器、输出转换器,或两者同时添加。
- 使用相对少量的数据调整模型的参数(“相对少” 指此时所需的数据规模远小于预训练 BERT 本身所需的数据规模)
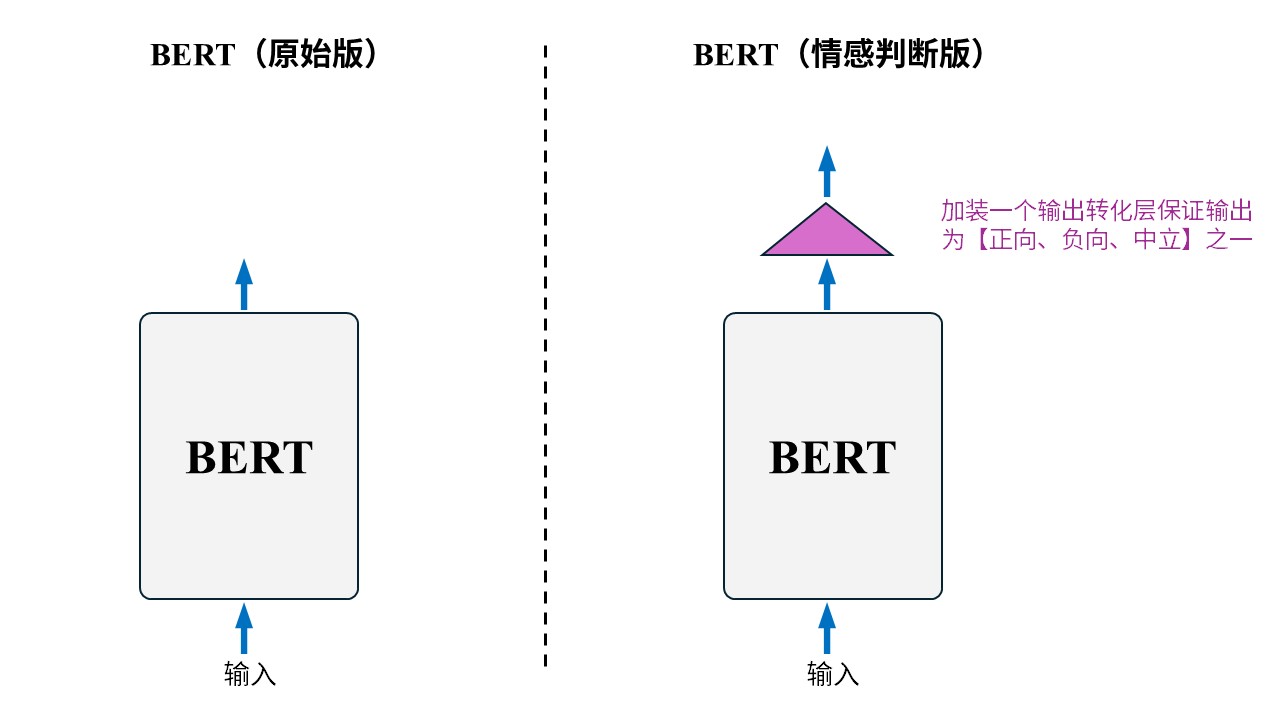
举个例子,让 BERT 来判断用户评论的情感倾向。 也就是给定一条用户评论,让 BERT 来判断到底是在夸还是在骂。由于 BERT 本身就能读取句子,所以在输入方面不需要做修改,但在输出上需要加一层控制保证 BERT 的输出是“正向”、“负向”、“中立”三者之一,也就是下图这样:
然后准备下图所示的训练数据:
最后再整体训练一下就可以了
所以你看,BERT 诞生之初并不是为了解决某个具体的问题,而是通过大量语料来“通用地”学习如何理解人类语言。当我们要用它来解决具体问题时,只需进行简单的修改和少量训练就行,这个过程就是微调。
在 BERT 原论文中,作者通过上述方式微调 BERT 解决了4大类,共计11个具体的 NLP 任务,这4个类别分别是:句子对分类任务、单句子分类任务、问答任务、单句子标注任务,分别举例说明一下:
- 句子对分类任务:比如给定一对句子,判断后一句表达的观点和前一句是矛盾、支持还是中立
- 单句子分类任务:比如我们刚举的例子,给定一句话,判断这句话的感情是正向、负向还是中立
- 问答任务:比如给定一个问题以及一篇包含此问题答案的文章,让模型回答这篇文章具体是从哪到哪回答了这个问题
- 单句子标注任务:识别文本中具有特定意义的实体,主要包括人名、地名、时间等。比如给定“张三今天上午吃了苹果”,则需要能够标注出【张三:人名】、【今天上午:时间】、【吃了:动作】、【苹果:名词】
所以总结一下,BERT 凭借预训练 + 微调的技术范式展现出对众多 NLP 任务的强大适配能力。
这种 “一次训练、多次复用”的特性就特别满足互联网行业“快速迭代”的模式。所以虽然技术圈外的用户没怎么听说过和使用过 BERT ,但 BERT 早已在各种互联网 app 中遍地开花,比如美团。
BERT 在美团业务中的应用
注:内容参考自《美团BERT的探索和实践》
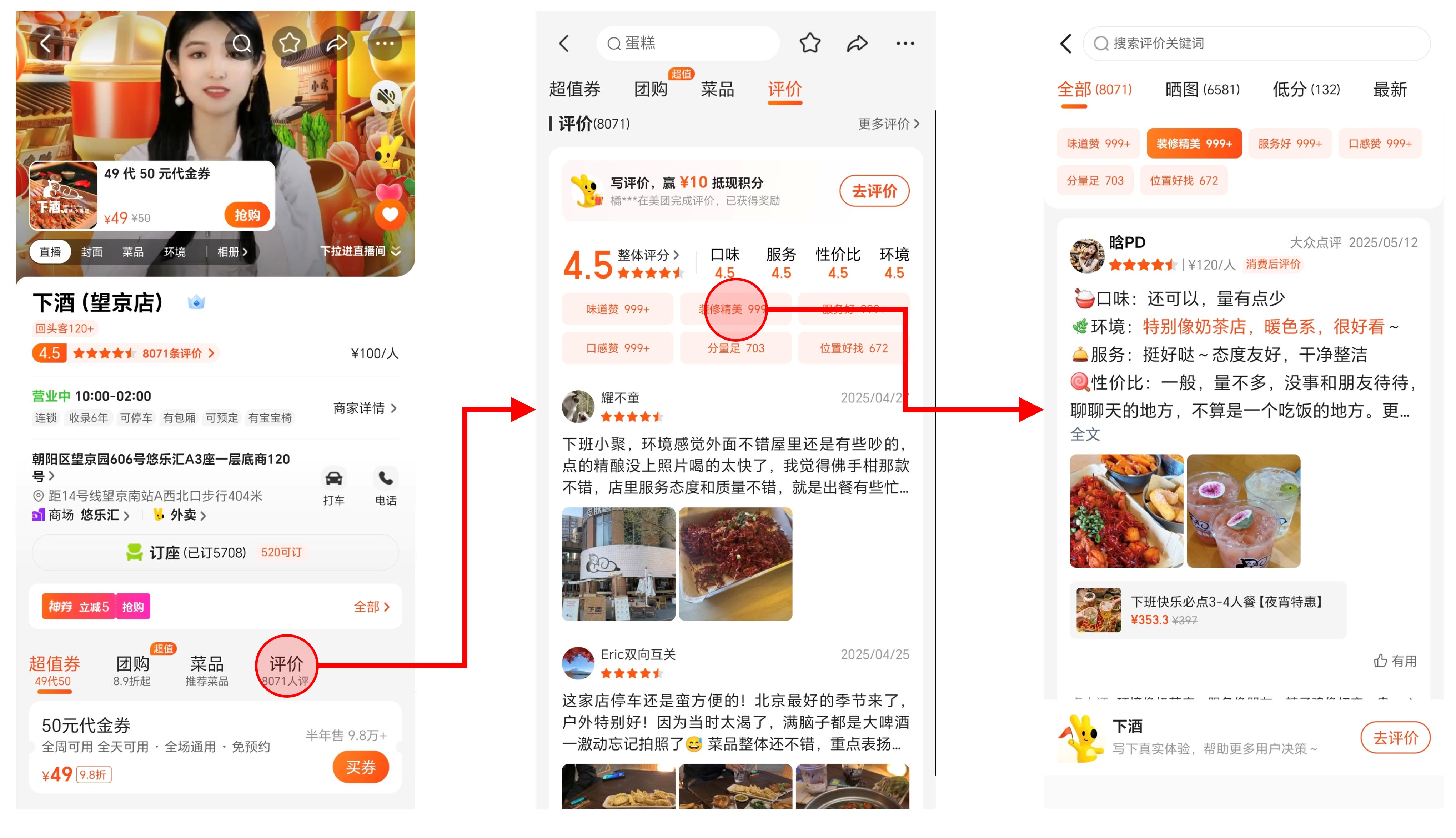
应用1:通过 BERT 提升用户评论情感分析准确性,让商家评价标签为用户提供更精准的消费指引。 所谓细粒度情感分析是指机器能够识别一段文本中不同对象的情感倾向。比如能够识别出“这家店味道很棒,但是服务不太好”中“味道”是正面的,“服务”是负面的。美团积累了海量的用户评论,引入 BERT 后对这些评论的细粒度情感倾向分析准确率达到了 72.04%(引入 BERT 之前是多少没找到公开数据,但行业经验是65%-70%)。
落实到产品设计中,细粒度情感分析让美团能够对商家的多条评论进行精准的情感聚合,从而可以直接呈现下图中【装修精美 999+】 这样的评价标签及相关评价数量,甚至还能高亮是哪部分文本体现了这种情感倾向,从而让用户高效的从评论中获取商家信息。
应用2:通过 BERT 提升搜索词意图识别准确率,让用户更快搜到想搜的东西。 所谓搜索词意图识别是指判断用户输入的搜索词属于什么需求类型。比如用户搜“霸王别姬”和“霸王茶姬”虽然只有一字之差,但前者是电影意图,那么应该向用户展示电影列表,后者是商家意图,则应该向用户展示商家列表。显然,意图识别不准确会导致展示内容完全不符合用户预期,轻则让用户搜索体验不畅,重则让用户失去耐心转而用别的 app 下单。美团引入 BERT 后搜索词意图识别准确率达到了 93.24%(引入BERT之前是多少没找到公开数据,但行业经验是85%-90%)。
在业务收益上,BERT 上线预计能让年营收增加5个亿。 据美团技术团队2019年发布的数据,美团美食频道在使用 BERT 后搜索QV-CTR从约57.60%提升至约58.80%。我们来计算下收益,按照“用户触发搜索→用户点击搜索结果→用户下单”的业务链路来算,假设当时的日均搜索QV是500万,并且点击某个搜索结果后下单的概率是10%,再考虑到美团美食频道以正餐为主,所以假设一单的营收是100元,那么:
- BERT上线前的营收 = 500万 x 57.60% x 10% x 100 = 2800万
- BERT上线后的营收 = 500万 x 58.80% x 10% x 100 = 2940万
WoW~这样一天的营收就多了140万,一年就多5.11亿,搜索技术团队的年终奖应该可以拿满了哈哈哈
应用3:提升搜索词改写准确率,让搜索结果更相关。 我们平时在搜索框输入一个搜索词后,系统并不会原封不动的用这个词进行搜索,而是有可能对它做改写。比如原始搜索词是“附近的kfc”,系统会自动改写为 “附近的肯德基”后再进行搜索,因为肯德基真正的商店名称是“肯德基”三个字而不是“kfc”。这种在不改变用户意图的情况下,对原始搜索词进行优化调整,使其能够匹配到更相关信息的环节就叫搜索词改写。显然,在美团的业务体量下需要改写的搜索词数量非常多,不可能人工核验所有的改写是否准确,因此美团引入 BERT 来判断原搜索词和改写后的搜索词是否语义一致。实验证明,基于 BERT 的改写方案在准确率和召回率都超过原先的 XGBoost(一个于2015年提出的分类模型) ,但具体是多少没说。
复盘一下,我们学到了什么
BERT 是个通用的语言模型。 所谓“通用”是指它并不是为了解决某个具体问题而生,而是具备理解自然语言的底层能力,当我们需要用它解决某个具体问题时只要进行简单修改就行。
BERT 是Transformer Encoder Block的叠加。 将12个 Transformer Encoder Block 叠加就得到了 BERT。
BERT 通过“完形填空”和“判断下一句”两个任务来学会理解自然语言。 所谓“完形填空”是指挖掉句子中的某个词后给 BERT 看,让它预测这个被挖掉的词是什么。“判断下一句”是指给 BERT 两个句子A和B,让他判断B在原文中是不是A的下一句话。
BERT 的训练数据无需人工标注。 无论是完形填空还是判断下一句,其训练数据都可以通过自动化的方式高效构建,这使得 BERT 可以在大规模的语料上进行充分训练,不会让数据标注成本成为阻碍。
预训练是指训练目的不直接指向目标任务的训练。 比如我们用“完形填空”和“判断下一句”两个任务让 BERT 先学会理解自然语言,之后会再训练它去完成别的任务。这俩训练就是预训练。
微调 BERT 即可完成众多具体任务。 微调 BERT 具体指给它外加一些配件,让它能够接受目标任务的输入并给出符合预期的输出,再用少量的相关数据训练整个模型即可让 BERT 胜任目标任务。
BERT “一次训练,多次复用”的特性特别满足互联网行业快速迭代的发展模式。 比如美团就用 BERT 来提升用户评论情感分析的准确性、搜索词意图识别准确率以及搜索词改写准确率。
欢迎来到2018
BERT 的提出源自2018年谷歌发表的论文_BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding _
到此,恭喜你对大模型知识的理解来到了2018年,此时距离DeepSeek-R1发布还有7年。
AI Heroes

Jacob Devlin, BERT的第一作者
因BERT而闻名的杰出科学家。 BERT 彻底改变了NLP领域,使得机器理解和处理人类语言的方式取得了重大进展,截止2025年5月BERT的引用量已达13万,据我所知在NLP领域应该仅次于 Transformer 的18万。
在顶尖科技研究机构的职业生涯。 Jacob是谷歌的高级研究科学家,其许多包括 BERT 在内的有影响力的工作都在此完成。他曾在微软研究院担任首席研究科学家,期间领导了微软翻译向神经网络的过渡,并为移动端神经网络翻译开发了先进的设备端模型。2023 年的报道曾指出他短暂加入 OpenAI 后又重返谷歌。
致力于开发快速、强大且可扩展的深度学习模型以用于语言理解。 他目前的工作涵盖信息检索、问答和机器翻译等领域,持续推动着自然语言处理及其应用的边界。
“他在语言的荒原上辟筑丝路,一次夯土成基,便可让千万商队沿着预训练的砖石走向不同的城邦。”
——后记

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)