[大模型微调]1.一文全面了解大模型微调
本系列将详细介绍常用的大模型微调方法。作为本系列的第一篇文章,将概括性的介绍各种微调方法,每一种方法将在后续文章中详细介绍。
本专栏其他文章:
一、微调的基础理论
1.大模型的训练过程
要理解微调,首先要理解大型语言模型(LLM)的训练过程,该过程通常分为两大阶段:
预训练阶段 Pre-training
这一阶段,模型在海量的无标签数据(比如网页、百科、小说、对话等等)上训练,目标是使模型掌握语言的统计特征和基础知识。此期间,模型将掌握词汇的含义、句子的构造规则、世界常识以及文本的基本信息和上下文。
预训练实质上是一种无监督学习过程。完成预训练的模型,被称为基座模型(Base Model),拥有了普遍适用的预测能力,就像一个“通才”,能理解语言和生成语言,但还没特别擅长某个具体任务。例如,GLM-130B模型、OpenAI的四个主要模型均属于基座模型。
微调阶段 Fine-tuning
预训练完成的模型接下来会在针对性的任务数据集上接受更进一步的训练。这一阶段主要涉及对模型权重的细微调整,使其更好地适配具体任务,专精于某一领域。如gpt code系列、gpt text系列、ChatGLM-6B等。
这属于有监督学习(因为数据通常带有标签或标准答案),有时还结合人类反馈强化学习(RLHF) 来让模型更“听话”。常见的ChatGLM-6B → 偏向中文对话;GPT-Code → 偏向代码生成;GPT-Text → 偏向写作、文本任务。
2.微调的基础知识
从上文中我们可以知道,微调是在一个已经预训练好的大模型上,继续用更“窄、更贴近你目标”的数据再训练一小会儿。目的不是让模型“重新学会语言”,而是让它把已有的一般能力,对齐到你的任务、风格和约束上。可以理解为:底座脑子很大,但个性中立、技能泛化;微调是在这个脑子上“塑形”。
专业性解释:利用特定领域的数据集对已预训练的大模型进行进一步训练的过程。它旨在优化模型在特定任务上的性能,使模型能够更好地适应和完成特定领域的任务。
微调时需要注意的一个关键问题是保持模型的泛化能力。过度的微调可能会导致模型对特定训练数据过拟合,而忽略了其在实际应用中的泛化能力。
微调的意义
- 微调可以强化预训练模型在特定任务上的能力
- 微调可以提高模型性能
- 微调自有模型可避免数据泄漏
- 使用微调模型,可降低成本
微调的分类
微调的本质是,在已经训练好的模型参数基础上,再去调整一部分参数,让模型更贴近任务。
微调任务的分类方式有很多种,以下图片是一种分类方式参考,本文主要聚焦于从“训练范围”和“训练目标‘这两大类来分。
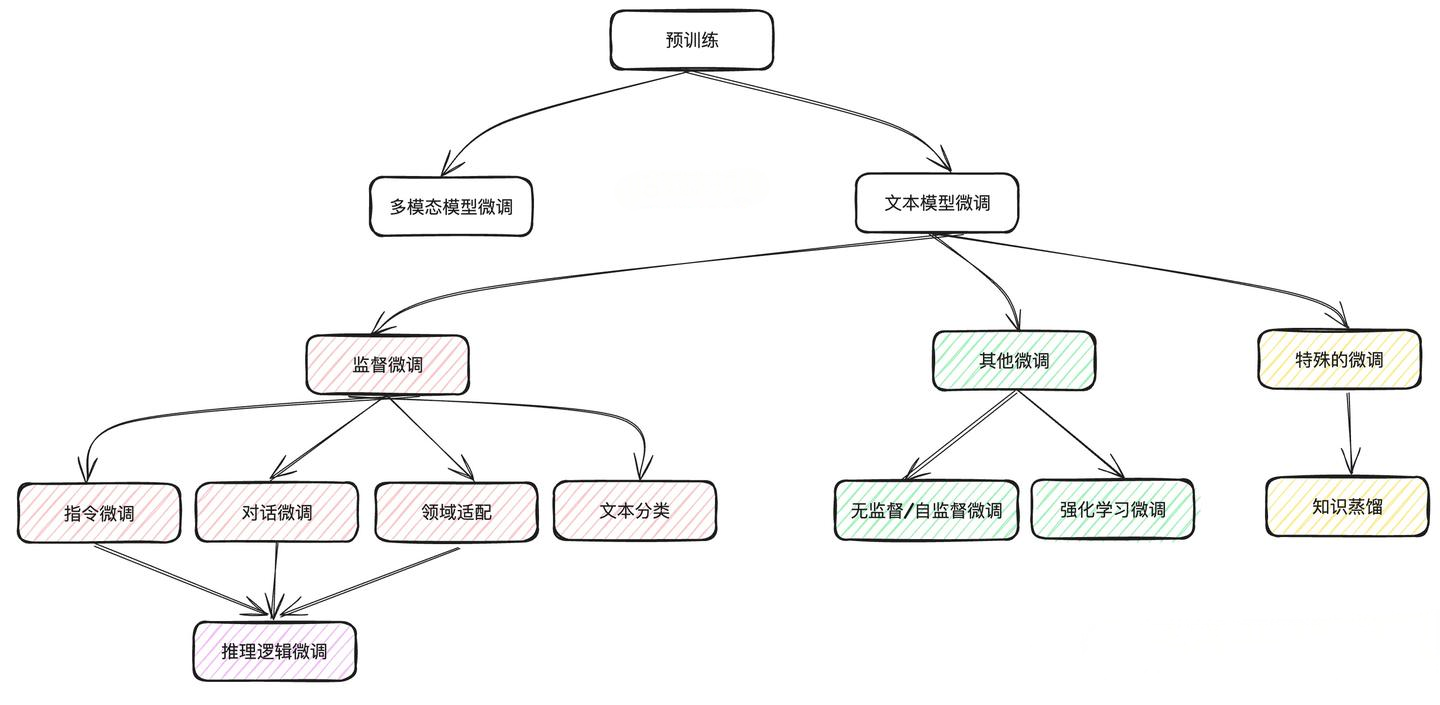
从“训练范围”分
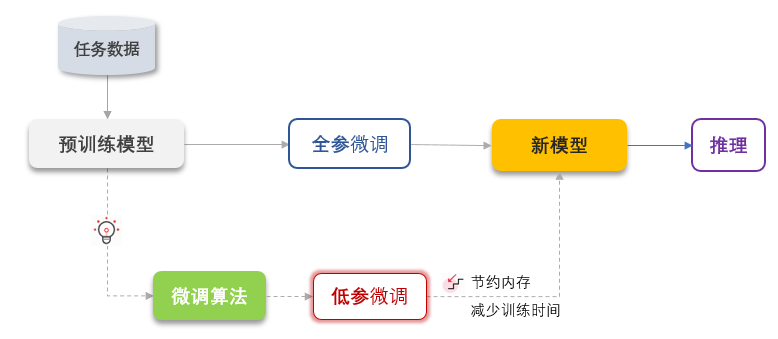
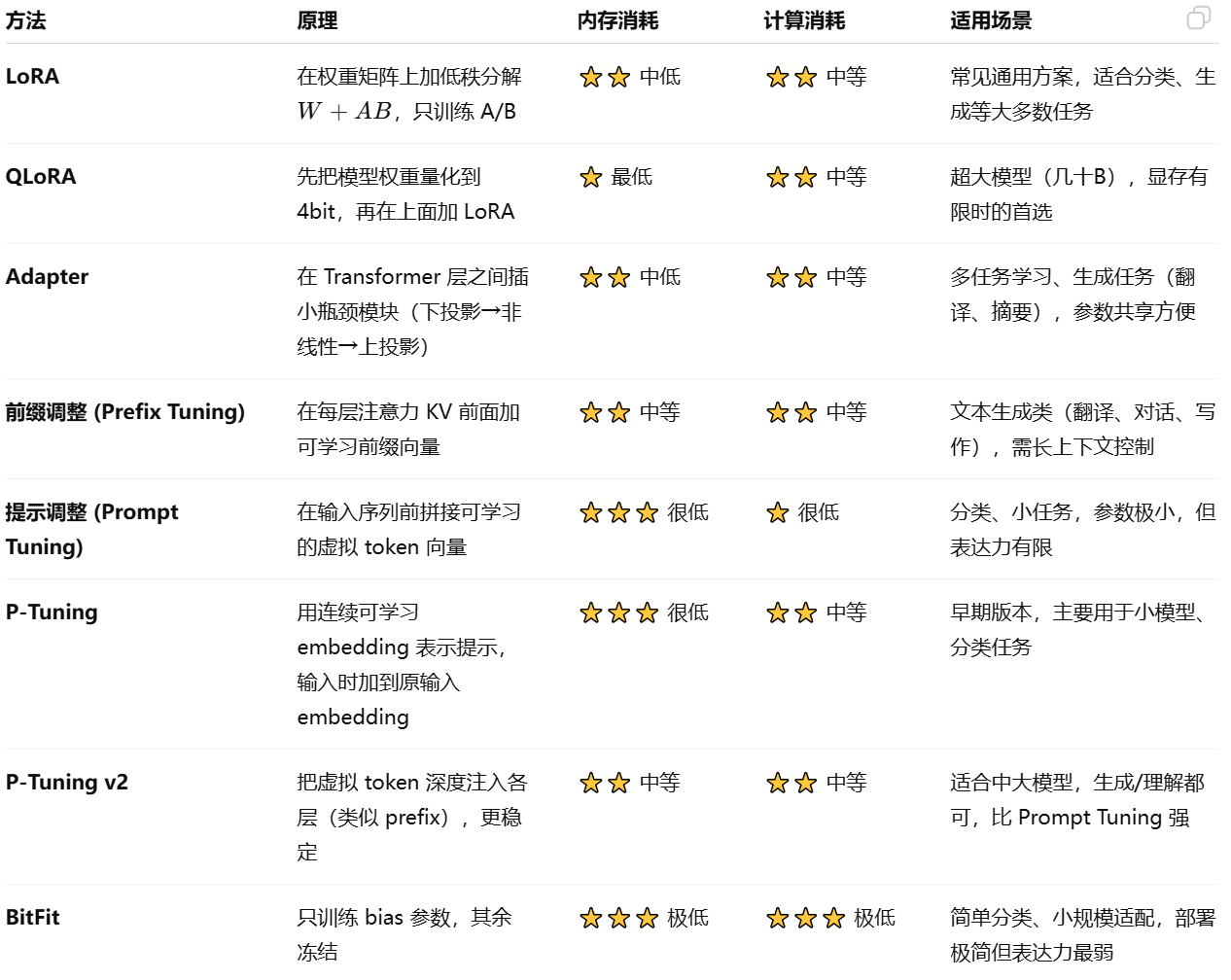
根据调整参数的范围来划分,微调分为全量微调(带入全部数据微调)和高效微调PEFT(只带入部分数据微调或加入新模块)。
全量微调算力消耗大,但对模型能力改造更彻底;高效微调则类似“四两拨千斤”,通过修改部分参数调整模型整体能力 。
全量微调 Full-Parameter Fine-Tuning
全量微调把整个模型的所有参数都解冻,然后在新数据上重新训练一遍。
全量微调最核心应用场景是全量指令微调(全参SFT)。
应用场景:研究机构训练 ChatGLM、Falcon-Chat、LLaMA-2-Chat 这类“官方对话模型”时,常常就是全量指令微调。
好处是:
- 灵活度最高,模型几乎能完全适配到你的任务,效果可能最好;
- 不需要额外“外挂模块”,直接产出一个新的模型。
但缺点也显而易见:
- 资源需求极高:显存、算力、时间都要爆炸多。
- 容易灾难性遗忘:就是学了你这点小数据后,把原来在大语料里学的通识知识“覆盖掉”,结果模型反而变蠢了。
- 不好回滚:一旦训练坏了,得从头再来。
高效微调 Parameter-Efficient Fine-Tuning, PEFT
旨在通过最小化微调参数数量和计算复杂度,提升预训练模型在新任务上的表现,从而减轻大型预训练模型的训练负担。
即使在计算资源受限的情况下,PEFT技术也能够利用预训练模型的知识快速适应新任务,实现有效的迁移学习。因此,PEFT不仅能提升模型效果,还能显著缩短训练时间和计算成本。
应用场景:
- 对话风格微调:可按特定需求调整模型对话风格,如客服、虚拟助理场景,微调少量参数,提供针对性、个性化对话体验。
- 知识灌注:将外部或领域特定信息快速集成到预训练模型,用少量标注数据微调,助模型理解专业知识,提升问答能力。
- 推理能力提升:用于提升大模型推理能力,在复杂任务中更高效理解长文本、推理隐含信息,提高推理准确性。
- Agent能力(Functioncalling能力)提升:在多任务协作等场景,通过针对性微调,让模型学会精准策略、解析参数和执行指令,表现更高效智能 。
高效微调有两种思路:
1.只调整小部分原有参数
把模型里某些层的参数“解冻”,只训练这几层,其他保持不动。
开销小,但能调整的能力有限。
2.加可训练参数到输入序列
不动模型本身,直接在输入序列上做手脚。它像是在“喂数据”时加了些额外的信息,引导模型输出。
3.加新模块
原始参数保持冻结不变,在关键位置(通常是线性层)插入一个“低秩适配器”,这个适配器本身参数很少。训练时只更新这个新加的小模块,原始大模型的参数完全不动。用的时候就是 “原始参数 + 小模块参数” 一起算。
这样做的好处有:
- 显存省(因为参数量少很多)
- 原始大模型不被破坏(你随时可以卸下 LoRA,恢复成原版)。
还有笔者认为最好的一点,这种方法允许多任务多风格可以并行(给同一个基座模型挂不同 LoRA 模块就行)
从“训练目标"分
根据想要模型学会什么来划分,微调分为普通任务微调(让模型专精于某个固定任务:翻译、分类、摘要等)和指令微调(让模型学会执行多种自然语言指令,成为通用助手)
普通任务微调 Task-Specific Fine-Tuning
目标是让模型在某个固定任务上表现更好,比如“中译英翻译”、“情感分类”。它只会干这一件事。
指令微调 Supervised Fine-Tuning
目标是让模型学会理解并执行各种自然语言任务指令。它能学到一个“模式”:先理解你要干什么,再生成结果。是把“通用大模型”变成“会聊天、会听话”的关键步骤(ChatGPT、ChatGLM 都是靠这个)。
数据一般是三元组格式:{"instruction": "...", "input": "...", "output": "..."}
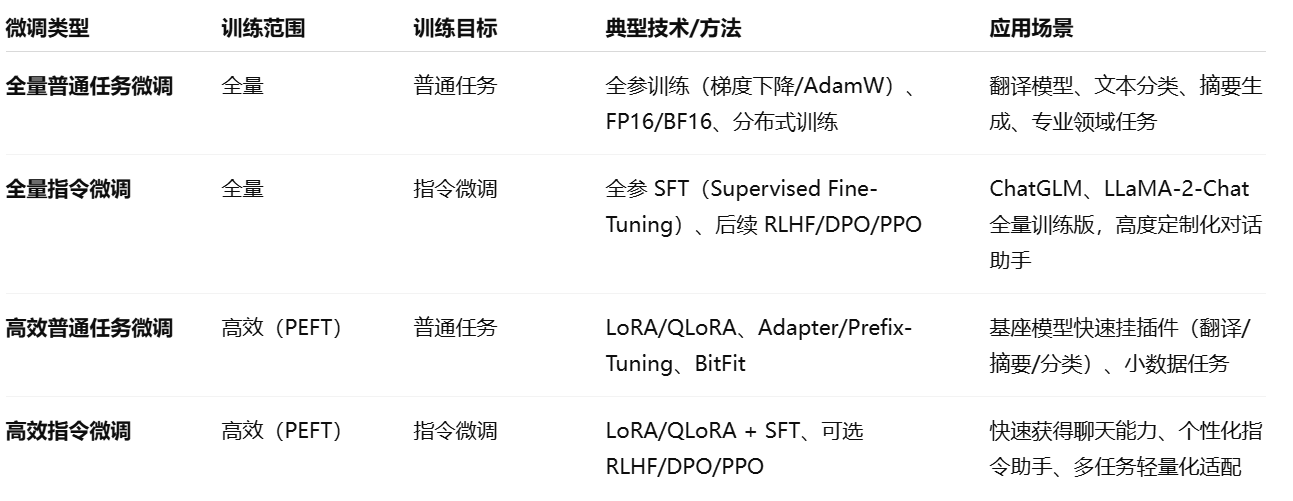
- 全量 + 普通任务微调 → 训练一个超会翻译的全新模型(但只能翻译)。
- 高效 + 普通任务微调 → 用 LoRA 给模型挂个“翻译插件”。
- 全量 + 指令微调 → 把基座变成一个 ChatGLM、LLaMA-2-Chat 这种全能对话助手。
- 高效 + 指令微调 → 在你的基座上挂个“听话助手 LoRA 模块”,轻量化就能获得聊天能力。
微调的基本流程
常见的微调流程如下:
- 选择基础模型:选择一个预训练好的大语言模型,如BERT、GPT-3等。
- 数据准备:选择与任务相关的数据集。对数据进行预处理,包括清洗、分词、编码等。
- 问题准备:准备一些问题,对微调前的模型进行测试,便于后续对比效果。
- 设置微调参数:设定学习率、训练轮次(epochs)、批处理大小(batch size)等超参数。
- 执行微调:加载预训练的模型和权重。根据任务需求对模型进行必要的修改,如更改输出层。选择合适的损失函数和优化器。使用选定的数据集进行微调训练,包括前向传播、损失计算、反向传播和权重更新。
- 查看效果:使用上面的问题,对微调后的模型进行测试,对比效果。
- 继续微调(可选):当效果不尽人意时,可以继续调整。
- 导出模型:微调结束后,得到处理好的模型。
3.大模型的经典网络架构
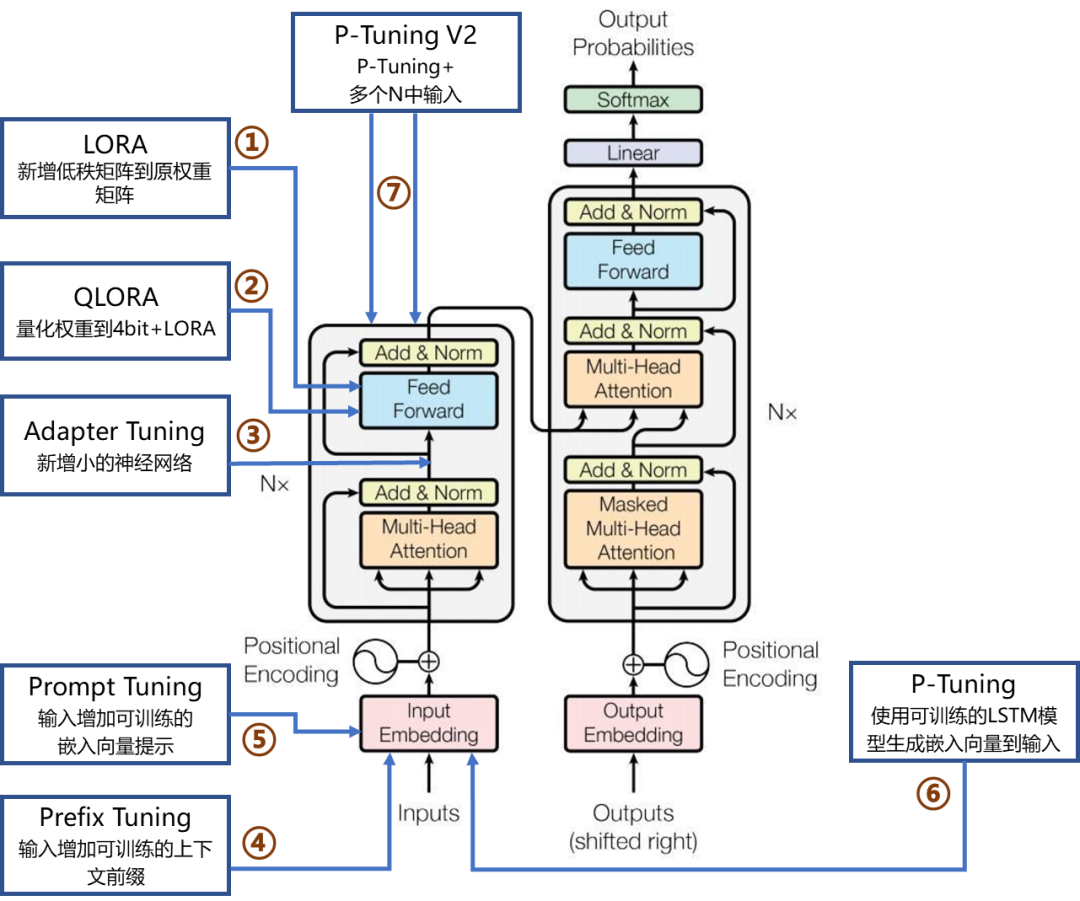
要深入理解各类微调手段,首先需要对网络架构有一个基本的认识。我们以GPT系列中的Transformer为例,该架构包含了众多模块,而我们讨论的各种微调技术通常是对这些模块中的特定部分进行优化,以实现微调目的。
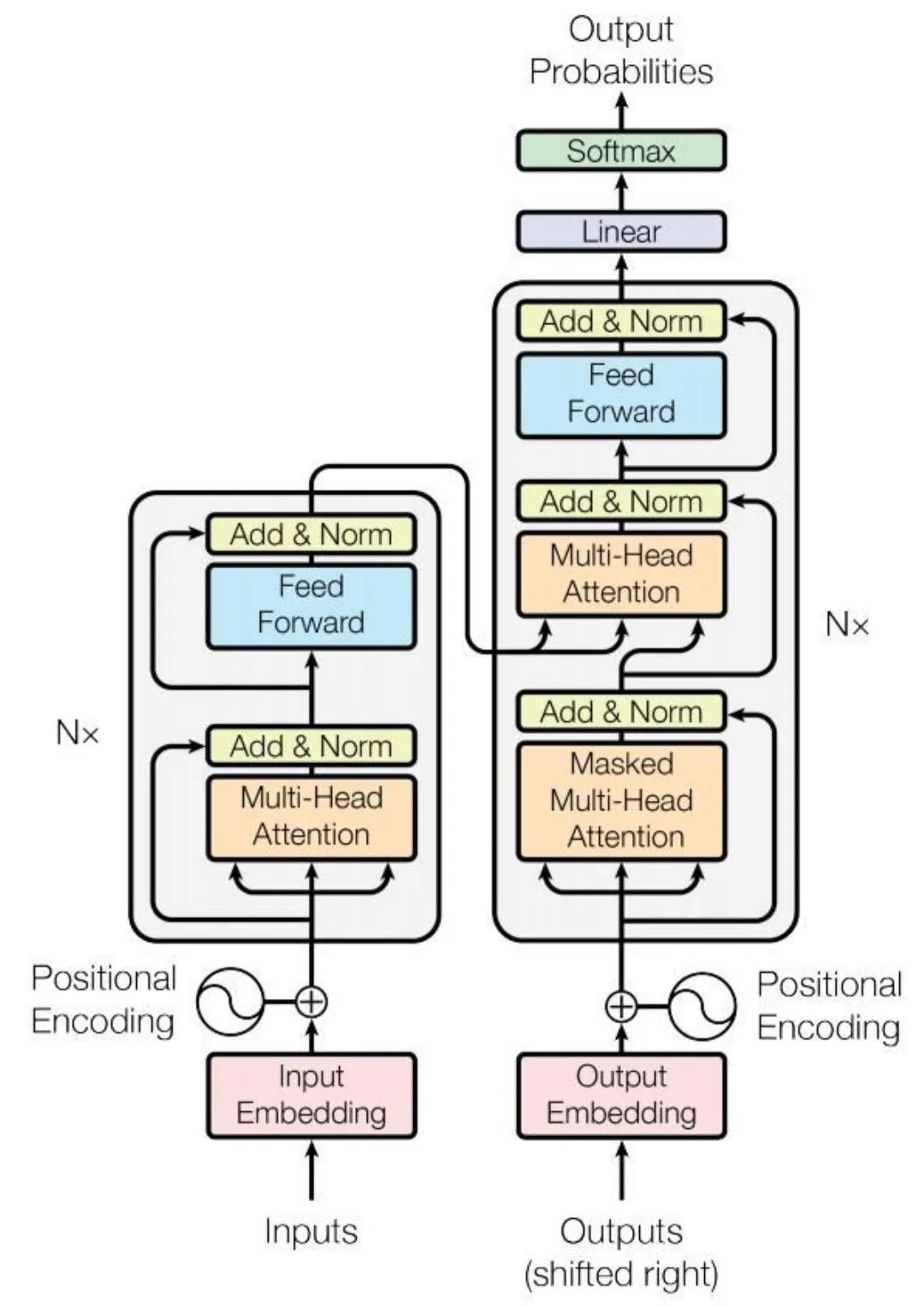
输入嵌入层(Input Embedding)
- 输入(Inputs):模型的输入环节,通常为单词或符号序列。
- 输入嵌入(Input Embedding):此步骤将输入序列(例如句中的每个单词)转化为嵌入表示,即能够表征单词语义信息的高维向量 Token Embedding
- 位置编码(Positional Encoding/Position Embedding):鉴于Transformer不依赖序列,并行处理所有输入 token。位置编码旨在提供序列中单词位置的信息,这些编码添加到输入嵌入中,确保模型即便同时处理输入也能够利用单词的顺序信息。
最终的输入向量 = Token Embedding + Position Embedding
编码器层(Encoder,左边)
- Nx:指示有N个相同的编码器层叠加而成。每个编码器层包括两个主要子层:多头自注意力机制和前馈神经网络。之前我们说的 输入向量 = Token Embedding + Position Embedding,将会送进第一个编码器层。
- 多头自注意力(Multi-Head Attention):注意力机制允许模型在处理每个单词时考虑到输入序列中的所有单词。多头表示模型并行学习输入数据的不同表示,比如语法关系、语义关系、上下文线索都能同时捕捉。
- 残差连接和归一化(Add & Norm):注意力层后面跟着残差连接和层归一化,有助于防止深层网络中的梯度消失问题,并稳定训练过程。
- 前馈神经网络(Feed Forward):全连接神经网络处理自注意力层的输出,每个 token 的向量单独经过两层线性变换 + 非线性激活,进一步加工表示。
解码器层(Decoder,右侧)
- 解码器亦包含多个相同的层,每层包括三个主要子层:掩蔽的多头自注意力机制、多头自注意力机制和前馈神经网络。
- 输入(outputs):解码器的输入是目标序列的前 n-1 个 token(也就是“已经生成的词”),目标是预测 下一个 token。
- 掩蔽多头自注意力(Masked Multi-Head Attention):与编码器的多头自注意力机制类似,但为确保解码顺序性,预测下一个词时,只能看到之前已经生成的词。
- 前馈神经网络(Feed Forward):与编码器相同,每个子层之后也有加法和归一化步骤。
输出嵌入层和输出过程
- 解码器端的嵌入层将目标序列转换为向量形式,即把解码器的隐藏向量映射到输出词汇向量空间。
- 线性层(Linear)和Softmax层:解码器的输出通过线性层映射到一个更大的词汇空间,Softmax函数将输出转换为概率分布,也就是计算Transformer 的隐藏向量映射回词表的概率分布。
二、微调的常用技术
1.全指令微调
原理
在预训练的基座模型上,把所有参数都解冻,用“指令-输入 → 输出”格式的数据(SFT 数据)进行监督训练,使模型在“听懂并执行自然语言指令”这一能力上达到更高水平。
分属
指令微调、全量微调
效果
模型会变得非常贴合指令数据,学会“照指令说话”。
代价
因为是全参训练,资源开销和风险同样很大(显存、算力、遗忘风险)。
常见场景
研究机构训练 ChatGLM、Falcon-Chat、LLaMA-2-Chat 这类“官方对话模型”时,常常就是全量指令微调。
下图表示了7种主流高效微调方法在Transformer网络架构中的作用位置及其简要说明,接下来将详细介绍每一种方法。
2.LoRA
原理
在模型的决定性层次中引入小型、低秩的矩阵来实现模型行为的微调,而无需对整个模型结构进行大幅度修改。
常见做法是:在注意力层(比如 Q、V 投影矩阵)旁边插入一些“小适配器”。训练时只更新这些适配器,而原始模型参数保持不变;推理时,可以把这些小模块和原始参数合并,不影响模型推理速度
分属
高效微调---加模块 高效微调---伪改参数
注意,LoRA不会直接训练原始权重矩阵 W,所以原权重本身参数值在训练时不更新。
然而,在前向计算时,LoRA 会把训练得到的低秩矩阵乘积AB 叠加到原权重上。但这个叠加过程是动态的,每次预测或推理时,输出中的权重看起来被修改了,但是实际上权重本身没有变。
操作流程
- 选择基座模型(比如 LLaMA、ChatGLM 等)
- 确定微调目标权重矩阵:首先在基座模型中识别出需要微调的权重矩阵,这些矩阵一般位于模型的多头自注意力和前馈神经网络部分。
- 训练适配器:该步骤分为两个操作。首先引入两个维度较小的低秩矩阵A和B。假设原始权重矩阵的尺寸为dd,则A和B的尺寸可能为d*r和r*d,其中r远小于d。然后计算低秩更新,通过这两个低秩矩阵的乘积AB来生成一个新矩阵,其秩(即r)远小于原始权重矩阵的秩。这个乘积实际上是对原始权重矩阵的一种低秩近似调整。
- 结合原始权重:最终,新生成的低秩矩阵AB被叠加到原始权重矩阵上。因此,原始权重经过了微调,但大部分权重维持不变。这个过程可以用数学表达式描述为:新权重 = 原始权重 + AB
优势
- 训练参数少:只需更新极小部分参数(通常小几十M),比全量动辄几百G小得多
- 显存友好:一张普通显卡也能跑,成本低
- 效果接近全量微调:很多任务里差别并不大
- 可组合性强:不同任务的 LoRA 模块可以插拔,多个 LoRA 还能叠加
不足
- 能力有限:只改小部分参数,对一些需要大范围更新的任务可能不够
- 依赖基座模型:适配器必须和底层基座模型匹配,不能跨模型通用
- 可能损失一点精度:在一些复杂任务里不如全量微调
使用场景
微调大型预训练语言模型(如GPT-3或BERT)
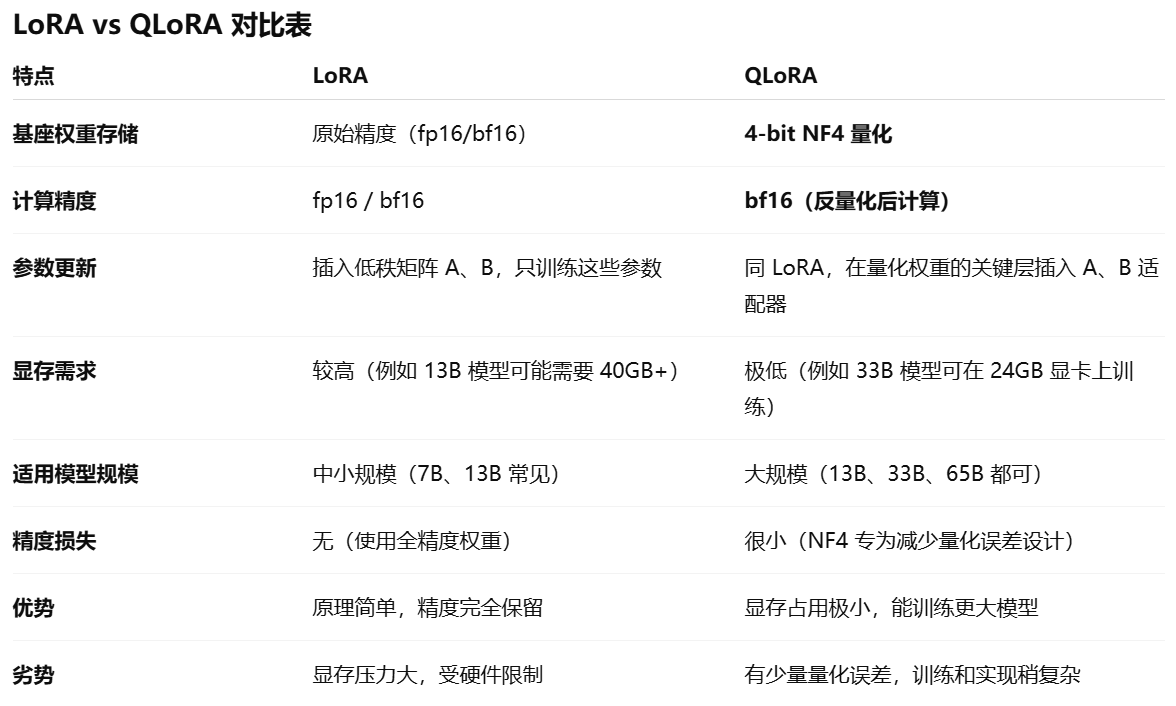
3.QLoRA
原理
QLoRA(Quantized Low-Rank Adaptation)是一种结合了LoRA(Low-Rank Adaptation)方法与深度量化技术的高效模型微调手段。
核心在于:NF4 (NormalFloat 4-bit) 存储,bf16 (BrainFloat16) 计算。
分属
高效微调---加模块
操作流程
- 4-bit 量化:QLoRA 在加载基座模型时,把原始权重量化成 NF4 (NormalFloat 4-bit) 存储,计算时再映射到 bf16 (BrainFloat16)。这种做法极大地减少了模型存储需求,同时保持了模型精度的最小损失。
NF4(NormalFloat 4-bit)是专门为神经网络权重设计的低精度格式,比普通的 int4/float4 更贴近权重分布,所以量化后精度损失更小。
- 冻结量化权重:基座模型的权重不参与训练,只是以 4-bit 格式存储并在需要时反量化。
- 反量化计算:QLoRA先以4-bit格式加载模型,训练时将数值反量化到bf16进行训练,这样大幅减少了训练所需的显存。例如,33B的LLaMA模型可以在24 GB的显卡上进行训练。
训练的时,算子不能直接用 4-bit 做梯度更新,因此在计算时需要反量化到 bf16 (BrainFloat16),这样保证训练的数值稳定性。
fp16和bf16都是 16 位浮点数格式,主要用于深度学习里做高效计算。区别主要在精度分布,
- fp16 更精细,但容易溢出/下溢。
- bf16 粗糙一些,但范围大,很适合训练。
- 在关键层插入 LoRA:和标准 LoRA 一样,在注意力或 MLP 层加上低秩适配器,只训练这些小矩阵。
4bit量化压缩
在4位量化中,每个权重由4个比特表示。
量化过程中需选择最重要的值并将它们映射到16个可能的值之一。首先确定量化范围(例如-1到1),然后将这个范围分成16个区间,每个区间对应一个4-bit值。然后,原始的32位浮点数值将映射到最近的量化区间值上。
优势
- 显存极省:4-bit + LoRA,能在单卡 24GB 甚至更小显存上跑超大模型微调。
- 保留效果:论文实验表明,QLoRA 在很多任务上的效果和全精度微调几乎一致。
- 推理轻便:可以直接部署量化模型,LoRA adapter 可灵活切换。
- 成本友好:硬件要求低,让个人/小团队也能玩大模型。
不足
- 精度影响:需要设计合适的映射和量化策略,以最小化精度损失对性能的影响
- 训练速度下降:量化运算有开销,可能比纯 FP16 慢一些。
- 对硬件依赖高:需要支持高效的 4-bit 运算(比如 NVIDIA GPU + bitsandbytes)。
- 兼容性问题:某些模型结构或库版本对 NF4 / paged optimizers 兼容不好。
使用场景
QLoRA 最适合大模型场景(几十 B 参数),小模型上用 LoRA 就够了,不必上量化。
与LoRA对比
4.适配器调整(Adapter Tuning)
原理
与LoRA技术类似,适配器调整的目标是在保留预训练模型原始参数不变的前提下,使模型能够适应新的任务。
适配器调整的方法,在模型的每个层或选定层(通常是 Transformer 层)之间插入小型可训练的神经网络模块,称为“适配器”,原始模型的参数则保持不变。
分属
高效微调---加模块 高效微调---伪修改参数(注:参照LoRA微调的原因)
操作流程
- 选择基座模型:如 BERT、RoBERTa、GPT 系列等。
- 插入 adapter 模块:一般放在 Transformer 的前馈层(FFN)或注意力层(Attention)之后。
- 设定瓶颈维度 𝑟:常见选择是 𝑑=1024,𝑟=64即大幅降维。
- 冻结基座权重:在微调过程中,原有的预训练模型参数保持不变,保证预训练知识不被破坏。
- 训练:只更新 adapter 的参数,显存和算力需求大幅下降。
- 推理:加载基座 + 任务专属 adapter。需要切换任务时,只替换 adapter 即可。
Adapter结构
Adapter 模块通常设计成一个瓶颈结构(bottleneck architecture):
-
降维(down projection):先把输入降到一个低维空间r。
-
非线性变换:在低维空间中通过非线性激活函数(如 ReLU、GELU)进行特征调整。
-
升维(up projection):再把结果投影回原始维度d。
-
残差连接:最终把 adapter 的输出加到原始输入上,确保模型稳定性。
假设原始 Transformer 层的 FFN 矩阵是 1024×4096 这种大块头。Adapter 模块只用 1024×64 + 64×1024,大大缩小了规模。
优势
- 高效:训练参数数量可减少 90% 以上,大幅节省显存和存储。
- 模块化与可移植性:不同任务的 adapter 可以像“插件”一样快速切换,不必重新训练整模型。
- 多任务学习:同一个基座可以加载多个 adapter 并行使用,实现任务组合。
- 保持预训练知识:基座参数冻结,避免灾难性遗忘(catastrophic forgetting)。
不足
- 推理延迟:每一层增加一个额外的前馈网络,推理速度略有下降。
- 效果有限:对于需要大规模知识重塑的任务(如跨模态、跨语言)性能可能弱于全量微调。
- 比 LoRA 更重:Adapter 的参数量和推理开销通常大于 LoRA,因此在新一代 PEFT 方法(QLoRA)出现后,它的应用热度有所下降。
使用场景
- 多任务 NLP:如 GLUE、SuperGLUE 上的快速适配。
- 跨语言微调:如在 XLM-R 上加载不同语言的 adapter。
- 存储受限场景:只需保存 adapter 参数,而不是整个大模型。
- 工业部署:在一台服务器上维护一个基座模型,为不同业务加载不同的 adapter 插件。
如果我们有一个大型文本生成模型,它通常用于执行广泛的文本生成任务。若要将其微调以生成专业的金融报告,我们可以在模型的关键层中加入适配器。在微调过程中,仅有适配器的参数会根据金融领域的数据进行更新,使得模型更好地适应金融报告的写作风格和术语,同时避免对整个模型架构进行大幅度调整。
与LoRA和QLoRA对比

LoRA:低秩矩阵 AB 在前向计算时动态叠加到 W 上 → 输出改变,但 W 本身不更新
Adapter:新增小模块输出通过残差直接加到隐藏表示上 → 输出改变,但 W 完全不参与
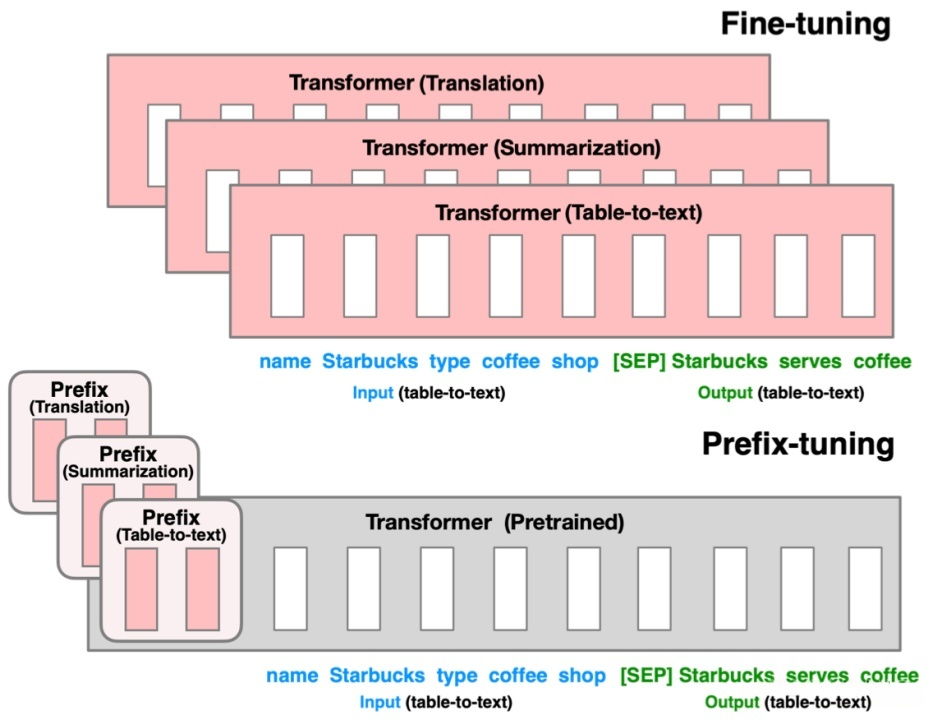
5.前缀调整(Prefix Tuning)
在预训练模型的输入序列前添加可训练、任务特定的前缀向量,用来引导模型的行为。
原理
预训练的 Transformer 每一层都有自注意力 (Self-Attention),每一层都会对输入做一次 “Query–Key–Value” 注意力计算。
前缀调整会在每一层的 attention 模块里,给 Key 和 Value 拼上这段“虚拟 token”(不是真实文本,而是可训练的连续向量),像是给模型“上下文暗示”。
这样,模型在预测时就会被这段前缀“牵着走”,输出符合目标任务。
总的来说就是,前缀调整利用了 Transformer 的每一层都有 self-attention 的特点,把前缀信号层层注入,从而影响整个生成过程。
在自然语言里,token 本来是离散的,比如 "我"、"happy" 这种词,必须先经过 embedding 转成连续向量,才能进入神经网络。
前缀(Prefix) 则不是实际存在的词或字符,而是一段直接在向量空间里定义的 embedding。它不需要有对应的“词表里的 token”,直接就是一堆可以被梯度更新的向量。所以也被称作“连续可微的虚拟标记”
分属
高效微调---加可训练参数到输入
操作流程
- 备基座模型:加载预训练好的 GPT、T5、BART 等。
- 初始化前缀:前缀可以是随机初始化的一段 embedding;也可以从已有的 embedding 里取(比如单词“task-specific”)作为起点。
- 拼接输入:输入 = [前缀向量] + [instruction/input tokens]。
- 训练方式:前缀向量通过反向传播更新;模型主体参数保持冻结;损失依旧是 cross-entropy(最大似然)。
- 推理阶段:只需把训练好的前缀加上去,基座模型就能表现出任务特性。
优势
这种方法的优势在于不需要调整模型的所有权重,而是通过在输入中添加前缀来调整模型的行为,从而节省大量的计算资源,同时使得单一模型能够适应多种不同的任务。
不足
- 表现有限:在复杂任务或需要深层语义改造的场景下,效果通常不如 LoRA 或全量微调。
- 依赖基座能力:前缀本身没有“知识”,它只是调动基座已有知识;如果基座模型本身对任务没学过,前缀调整很难补足。
- 任务泛化差:一个前缀通常只能服务一个任务,跨任务复用性差。
使用场景
文本生成、对话、机器翻译等生成类任务。
6.提示调整(Prompt Tuning)
大模型本来是靠提示词(prompt)来引导输出,比如问 GPT「翻译下面这句话」它才会翻但手工写提示词效率低、迁移性差。
所以研究者想到:能不能让提示本身也变成可训练的参数,直接学到最优的 prompt?
原理
在输入序列的前面,加上一段虚拟的提示 token embedding。在微调时,只更新这段提示 embedding,其余模型参数保持冻结。
分属
高效微调---加可训练参数到输入
操作流程
- 构造输入:把一段“提示向量” + 原始输入文本拼接起来,送入模型。
- 前向传播:模型处理时,会把提示向量当作输入 token 的一部分。
- 计算损失:用下游任务(比如分类、生成)的损失来指导训练。
- 参数更新:只更新提示向量 embedding,不改动大模型权重。
不足
表达能力比前缀调整弱,因为提示调整只在输入层起作用,而没有深入到每一层。
与前缀调整对比
Prompt Tuning(提示调整):在输入层加一段可训练的虚拟 token embedding(只在输入最前面),训练时只更新这些 embedding。
Prefix Tuning(前缀调整):在每一层 attention 的 Key/Value 端注入可训练的前缀(通常是每层的 K/V 向量),从而在每层都持续影响注意力计算。
原理层面差异
作用位置
Prompt:只拼接在 input embeddings 前面(输入层)。
Prefix:在每个 Transformer 层的 attention 中,把 prefix 当作额外的 Key/Value(或直接扩展 attention 的 K/V),因此每层 attention 都能直接“看到”前缀信息。
信息传递方式
Prompt:前缀经过模型层层传播,信息可能被稀释或变形。
Prefix:前缀在每层都直接参与注意力计算,信息更直接、更稳定。
可表达能力
Prefix 通常比 Prompt 更强(尤其是生成/复杂任务),因为它在每层都能提供额外的注意力上下文。
实现复杂度
Prompt 简单(只需修改输入 embedding)。
Prefix 需要改 attention 的前向(或利用模型支持的 past_key_values / prefix hooks),实现复杂度高一点。
计算与内存差异
1.Prompt Tuning
- 增加的计算/显存主要是输入序列变长(prompt_len)。只在第一层构建额外 embedding,然后像普通 token 一样走完整向前。
- 对 attention 的影响:第一层 attention 的 K/V 长度增加,之后层是正常长度(但因为第一层输出包含 prompt 信息,后续层会有隐式影响)。
- 实现最简单、开销最小(适合极端受限场景)。
2.Prefix Tuning
- 每层 attention 的 K/V 都被扩展(prefix_len × num_layers),所以 attention 的计算量和内存占用会比 prompt 高(尤其 prefix_len×num_layers 较大时)。
- 但前缀通常比在输入直接拼接更多“控制能力”,所以在参数/效果比上常更划算(特别是生成任务)。
- 如果 prefix 是通过 MLP 动态产生 K/V(P-Tuning v2),会额外有小量计算但能节省参数表示。
7.P-Tuning
P-Tuning 其实就是 Prompt Tuning 的一个升级版
原理
Prompt Tuning中的token 使用静态的、可训练的虚拟标记嵌入,在初始化后保持固定,除非在训练过程中更新。
而P-Tuning进一步改进,通过一个小的神经网络(通常是 BiLSTM + MLP)来动态生成虚拟标记嵌入,允许根据输入数据的不同生成不同的嵌入,提供更高的灵活性和适应性,适合需要精细控制和理解复杂上下文的任务。
P-Tuning 的核心就是:虚拟 token 不再是死的,而是活的,通过小网络生成,具有上下文关系,表达能力更强。
分属
高效微调---加可训练参数到输入
优势
- 更灵活:LSTM可以捕捉输入数据中的时间序列特征,更好地理解和适应复杂的、顺序依赖的任务,如文本生成或序列标注。
- 改进的上下文理解:LSTM因其循环结构,擅长处理和理解长期依赖关系和复杂的上下文信息。
- 参数共享和泛化能力:在P-Tuning中,LSTM模型的参数可以在多个任务之间共享,这提高了模型的泛化能力,并减少了针对每个单独任务的训练需求。而在提示调整中,每个任务通常都有其独立的虚拟标记嵌入,这可能限制了跨任务泛化的能力。
- 和 prefix-tuning 有点像:但 P-Tuning 主要还是工作在“输入侧 embedding 层”,不像 prefix-tuning 那样直接去改动 Transformer 各层的 KV 缓存。
不足
方法相对复杂,因为它涉及一个额外的LSTM模型来生成虚拟标记嵌入。
与Prompt Tuning对比
Prompt Tuning 的输入
输入:[e1][e2][e3] + "这部电影令人振奋"
[e1][e2][e3] = 一堆直接存储的可训练向量P-Tuning 的输入
输入:[f(id1)][f(id2)][f(id3)] + "这部电影令人振奋"
f = 小网络(BiLSTM + MLP),输出的 embedding8.P-Tuning v2
P-Tuning v2是P-Tuning的进一步改进版,在P-Tuning中,连续提示被插入到输入序列的嵌入层中,除了语言模型的输入层,其他层的提示嵌入都来自于上一层。这种设计存在两个问题:
- 第一,它限制了优化参数的数量。由于模型的输入文本长度是固定的,通常为512,因此提示的长度不能过长。
- 第二,当模型层数很深时,微调时模型的稳定性难以保证;模型层数越深,第一层输入的提示对后面层的影响难以预测,这会影响模型的稳定性。
原理
P-Tuning v2去掉BiLSTM ,直接用一个 更轻量的 MLP 生成虚拟 token。同时不仅在第一层插入连续提示,而是在多层都插入连续提示,且层与层之间的连续提示是相互独立的(有点像 Prefix Tuning 的思路)。
分属
高效微调---加可训练参数到输入
优势
可训练的参数量增加,使得P-Tuning v2在应对复杂的自然语言理解(NLU)任务和小型模型方面,相比原始P-Tuning具有更出色的效能。
与Prompt Tuning、P-Tuning对比

9.BitFit(Bias-Term Fine-Tuning)
原理
训练偏置项(bias),把模型里面庞大的权重矩阵全部冻结
一个 Transformer 里面有很多层,每层有:
- 线性层:𝑊𝑥+𝑏
- LayerNorm:带有缩放和偏移参数
偏置 b就是那个加在结果上的小向量,BitFit只更新这些b。
分属
高效微调---直接改动参数
操作流程
- 加载预训练模型;
- 冻结所有权重矩阵;
- 只让 bias 参与反向传播更新;
- 损失函数和正常微调一样(比如交叉熵)。
优点
-
极度参数高效:只训练 bias,通常参数量占总模型的 0.1%~0.5%;
-
实现简单:代码里基本就是把 bias 设置为
requires_grad=True,其他全冻结; -
效果 surprisingly 好:在分类、情感分析等小任务上,和全量微调差距不大
局限
-
表达能力有限:bias 只能平移输出分布,无法像 LoRA 那样学复杂的变换;
-
对生成类任务弱:在文本生成、对话任务上效果一般;
-
任务依赖性强:一些复杂任务需要模型学到新的模式,单靠 bias 不够。
使用场景
- 小规模任务 / 轻量级任务。比如情感分类、新闻分类、意图识别这类 句子级/段落级分类任务。这些任务对模型的需求不是学新知识,而是调整已有分布,所以只改 bias 就够用了。
- 低资源环境。设备显存小,或者下游任务非常多(需要为上百个小任务都训练一个专属 adapter/LoRA 的话太费参数)。BitFit 的参数开销比 LoRA、Adapter 还小,几乎可以忽略不计。
- 模型快速定制。如果你想在不同任务上快速尝试,而不想大改模型。只训练 bias,很容易部署,推理时开销和原模型一模一样。
三、微调的相关平台
1.数据集平台
Hugging Face
Hugging Face(简称 HF)是一个围绕 机器学习 / 大语言模型 / NLP 的超级生态平台,可以把它理解成 GitHub + AI 社区 + 工具集 的结合体。
Transformers 库
提供各种预训练模型(BERT, GPT, T5, LLaMA 等)的实现。一行代码就能调用上千个模型。
Datasets 库
超级多的数据集,一行代码加载,自动处理。
Model Hub(模型库)
类似 GitHub 仓库,但专门用来分享模型。上面有几十万模型,可以直接下载使用。
Datasets Hub(数据集库)
全球用户上传的数据集,免费用。

GitCode 的 AI 社区
HF虽然比较好用,但可能需要一些魔法手段才能连接上。退而求其次,可以使用一些国内的数据集网站。比如GitCode 的 AI 社区。
2.基座模型
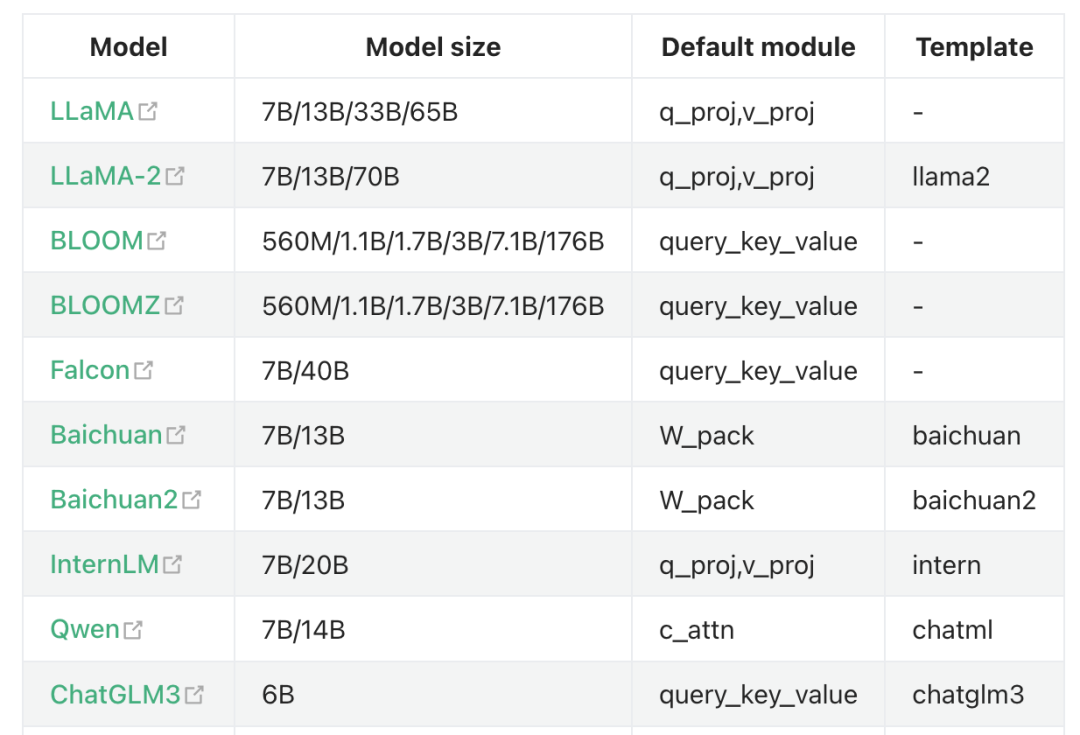
3.微调平台
1.unsloth

unsloth 是一个专为大型语言模型(LLM)设计的微调框架,旨在提高微调效率并减少显存占用。 它通过手动推导计算密集型数学步骤并手写 GPU 内核,实现了无需硬件更改即可显著加快训练速度。
简单来说,Unsloth 采用了某些优化技术,可以帮助我们在比较低级的硬件设备资源下更高效的微调模型。在 Unsloth 出现之前,模型微调的成本非常高,普通人根本就别想了,微调一次模型至少需要几万元,几天的时间才能完成。
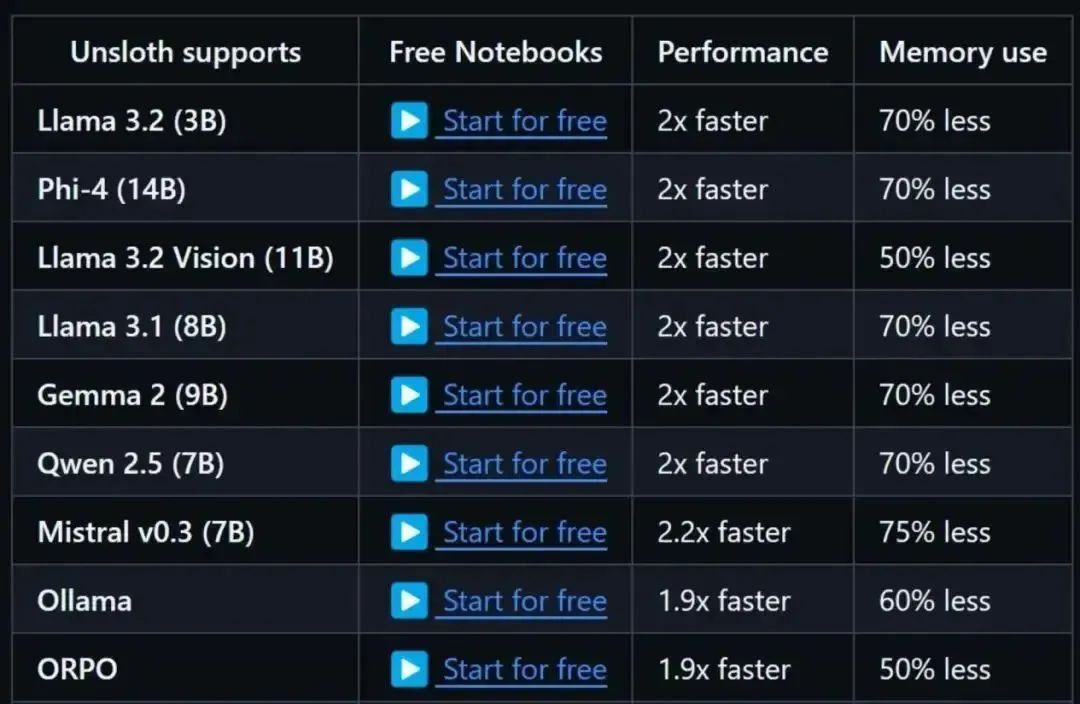
unsloth 与 HuggingFace 生态兼容,能轻松结合 transformers、peft、trl 等库,实现模型的监督微调(SFT)和直接偏好优化(DPO),仅需改变模型加载方式,无需修改现有训练代码。
主要功能点
- 高效微调:unsloth 深度优化,让 LLM 微调速度提 2 - 5 倍,显存使用量减约 80%,准确度无明显下降。
- 广泛模型支持:支持各类主流模型,用户按需选模型微调。
- 兼容性:与 HuggingFace 生态系统兼容,结合 transformers、peft 等库,改模型加载方式,就能实现 SFT 和 DPO,无需大幅修改现有训练代码。
- 内存优化:通过 4 位和 16 位的 QLoRA/LoRA 微调,显著降低显存占用,资源受限环境也能大幅微调 。
核心优势
- 显著提升微调效率,比传统方法省时。
- 降低硬件要求,优化显存使用,可在小显存 GPU 上微调大模型。
- 开源免费,在 Google Colab 或 Kaggle Notebooks 可免费试用,易上手。
unsloth 为大语言模型微调提供高效低成本方案,适合资源有限的开发者和研究人员。
2.LLaMa-Factory

LLaMA-Factory 是一个统一且高效的微调框架,旨在为超过 100 种大型语言模型(LLMs)和视觉 语言模型(VLMs)提供便捷的微调支持。 用户能够灵活地定制模型以适应各种下游任务。
主要功能和特点:
- 广泛支持:LLaMA-Factory 支持超 100 个 LLMs 和 VLMs 微调,含 Llama 3、GLM-4 等最新版本。
- 高效微调:集成多方法提升训练速度、减少显存占用。
- 多模态支持:除文本任务,还支持多种任务类型。
- 实验监控:提供 LlamaBoard 等丰富监控工具。
- 快速:提供多种界面,结合 vLLM worker 实现高效推理。
更多详细内容与教程可以参考
3.ms-SWIFT

ms-swift(Scalable lightWeight Infrastructure for Fine-Tuning)是魔搭社区(ModelScope)开发的高效微调和部署框架,为研究人员和开发者提供大模型与多模态大模型训练、推理、评测、量化和部署一站式解决方案。
- ms-swift 支持超 450 种大型模型(LLMs)及 150 多种多模态大模型(MLLMs)训练和部署。涵盖 Qwen2.5、InternLM3 等众多最新版本及多模态模型。
- 多样化训练技术:oRA、Llama-Pro 等框架满足不同微调需求。
- 轻量级微调:支持 LoRA 等多种方法,降低资源消耗。
- 分布式训练:支持 DDP 等技术。推理加速:提供 BNBWQ 等量化方法,支持用 vLLM 和 LMDeploy 进行推理等。支持多模态训练及相关任务。
- 用户友好界面:基于 Gradio 提供操作界面,简化大模型全链路流程 。
四、微调与强化学习训练、模型蒸馏、奖励学习等概念辨析
微调 Fine-tuning
- 核心思想:拿预训练好的模型,用人工准备的样本(输入→输出)去再训练,让模型更适合某个任务。
- 训练目标:通过少量的标注数据对预训练模型进行优化,适应具体任务(如文本分类、问答、生成 等)
- 数据需求:有监督数据(指令+答案)。
- 典型场景:常用于下游任务如情感分析、机器翻译、推荐系统等
- 特点:训练稳定,效果可控,但只能学“老师给的答案”,不能自己探索。计算量相对较小,能够在有限的数据和计算资源下提升模型在特定任务上的性能。
强化学习 Reinforcement Learning (RL)
- 核心思想:强化学习是决策优化过程,通过“试错”和反馈学习最优策略。智能体与环境交互获奖励信号,据反馈调整策略,长期优化。
- 训练目标:通常不依赖于预定义的数 据集,而是依赖于与环境的持续交互,最大化累计奖励。
- 数据需求:奖励信号(可以是环境反馈、规则函数或人工打分)。
- 典型场景:游戏AI(如AlphaGo)、机器人控制、自动驾驶。
- 特点:能优化“偏好”和“风格”,但训练不稳定,容易崩(exploration、奖励黑客)。
模型蒸馏 Knowledge Distillation
- 核心思想:将复杂、计算密集型教师模型知识转移到小型、高效学生模型。常通过教师模型生成软标签或行为模仿指导学生模型训练。
- 训练目标:让学生模型的概率分布逼近老师的 。
- 数据需求:老师模型输出(soft labels / logits),可能还混合少量真实数据。
- 典型场景:大模型压缩成小模型,加速推理、节省算力。
- 特点:蒸馏核心是知识迁移,在模型压缩和部署有优势。学生模型性能接近教师模型,参数量少、计算高效。
奖励学习 Reward Learning
- 核心思想:训练一个奖励模型(Reward Model, RM),输入模型的生成,输出一个分数,表示好坏。
- 训练目标:让 RM 学会预测“人类偏好”或“质量好坏”。
- 数据需求:人工排序/偏好数据(比如两条答案,人选更好的那个)。
- 典型场景:对齐人类偏好、调整模型回答风格与语气
- 特点:奖励学习本身不是训练大模型,而是训练“打分员”。
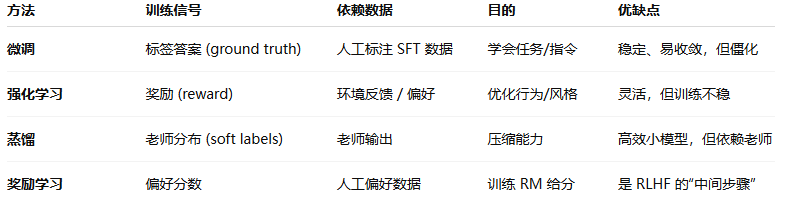
微调:老师告诉你标准答案。
强化学习:你自己去试,做好有奖励,做坏没奖励。
蒸馏:小孩照抄老师的解题步骤。
奖励学习:先训练一个“评分老师”,后面 RL 用它打分。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)