LLM 时代各类ChatBot实现简介(一)
随着 LLM 的出现,技术实现也从早期的检索式(构建一个闲聊库,根据用户的提问,检索类似的QA返回给用户);在2022年之前,业界的这类ChatBot创建可以通过Raza、Microsoft Bot Framework、Google Dialogflow等厂商提供的平台来完成,彼时这些ChatBot的任务处理能力主要是通过 关键字规则 + 一些神经网络小模型或者统计模型来实现的,用户在使用的过程会
1. 背景
1.1. 人机交互的变更历史介绍
科技进步的核心价值之一在于持续降低人机交互的认知门槛,这主要体现在交互范式的迭代升级:
-
机械指令阶段(1940s-1970s)以打孔纸带为输入介质,纸质打印为输出界面,交互过程严格依赖二进制编码语言,要求使用者具备专业的计算机操作能力。在这个时代,计算机属于军事科研机构(ENIAC用户)、大型企业技术精英(IBM 360操作员),目标人群极少,对社会价值的拉动效应很低。
-
图形界面革命(1980s-2000s)
鼠标键盘的物理交互配合可视化操作系统,通过WIMP(窗口、图标、菜单、指针)范式将机器语言转化为视觉符号,输入效率提升500%以上(据Nielsen Norman研究),推动个人计算机普及率从1984年的8%跃升至2000年的51%(世界银行数据),计算机走向千家万户,也是美国当年信息化革命的具象。
-
触觉交互时代(2007-2020s)
需要感谢苹果公司把实验室的多点触控技术做成了人人都能用起来的产品方案,电容式多点触控技术重构人机接触面,配合移动设备的空间感知能力,使全球移动互联网用户突破50亿(GSMA 2023报告)。
-
自然语言交互范式(2020s- )
LLM 出现后,带来了新的输入和输出革命,基于『文本/语音/视觉』的多模态输入 + 『文本/语音/视觉』的多模态输出,这套新方案会进一步降低人们操作机器的输入和输出门槛。关键是『机器系统』的认知革命:首次实现人机交互的双向自然化,用户无需学习机器语言(节约87%的学习成本,MIT实验数据),且系统基于 LLM的自然语言理解准确率达到90%+(Stanford HAI基准测试),系统通过意图识别和认知映射主动适配人类思维模式。 -
这种交互范式一个产品形态就是ChatBot。现在很多产品或者产品的Copilot模块以ChatBot的形态展现给用户。本文主要阐述TableQA领域的ChatBot当前遇到的难点和解决思路。
1.2. 新交互范式下ChatBot的分类介绍
按照用户的使用目的,业界ChatBot分为3类型:任务型、闲聊型、咨询型。
-
闲聊型 ChatBot:关注情感满足,以自由对话为主,不限定具体任务或领域,为用户提供娱乐和消遣等功能,例如日常聊天、情感交流等,强调语言的自然性和趣味性;因为用户输入的不可控,Chatbot不知道用户下一句话会说什么,实现与用户聊得越久越好是这类Chatbot 的首要目标。随着 LLM 的出现,技术实现也从早期的检索式(构建一个闲聊库,根据用户的提问,检索类似的QA返回给用户);升级为了生成式(由 LLM 来负责回答)。
-
任务型ChatBot:聚焦指令执行,以完成特定任务为目标。通过多轮对话的方式,系统主动反问用户以收集信息,完成特定操作或服务,例如订餐、酒店预订、天气查询、法律咨询、产品信息查询等。对话流程通常受预定义规则或意图槽位约束,因为用户提问内容的省略、模糊,导致参数缺失、或者 有多个候选参数,需要系统对用户反问来对参数进行补全 或者 澄清。
-
-
在2022年之前,业界的这类ChatBot创建可以通过Raza、Microsoft Bot Framework、Google Dialogflow等厂商提供的平台来完成,彼时这些ChatBot的任务处理能力主要是通过 关键字规则 + 一些神经网络小模型或者统计模型来实现的,用户在使用的过程会感觉bot的对话比较呆板:需要形式化的自然语言表达,容易出现『不了解你的意思』的反馈;多任务的多轮对话能力较弱。
-
在20年,微软的Semantic Machines 团队发布的《Task-Oriented Dialogue as Dataflow Synthesis》论文,介绍了多任务多轮对话的方案,其中Program synthesis的思路在当前 LLM 出现后极大降低了实现门槛。
-
在2022年LLM 出来之后,通过 LLM + function call、以及现在火热的 MCP协议、A2A 协议,让任务型 ChatBot的技术门槛也极大的降低,只需要Prompt+LLM就可以完成链路的实现~~~
-
-
咨询型 ChatBot:强调知识传递,以精准解答用户问题为目标,采用单轮或极简多轮交互模式,表现为“一问一答”形式。答案来源于结构化或非结构化数据,对应的技术方案和难点各不相同。按照依赖的数据类型,主要可以分为4种分类:
注意:这4种分类是基于我当前遇到案例的技术实现方案的种类来划分的,其中『技术方案』主要是指依赖的数据类型,数据类型不同,技术链路的概要流程相似,但技术实现细节差异很大。
2. 咨询型 ChatBot的4种分类简介
2.1. Frequently Asked Questions,简称 FAQ
-
-
示意:
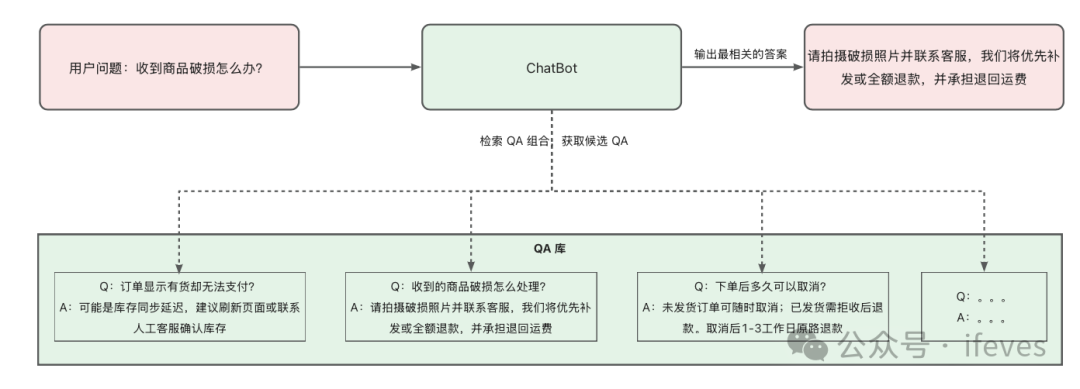
-
用户价值:在业界通常被称为“常见问题解答”,常用于帮助与技术支持场景,例如客服支持、医疗知识问答等,优化用户体验和降低人力成本方面的显著优势。
-
实现思路:这是早期客服系统最常见的方案。通过人工或半自动化方式预先构建标准化的问答知识库,问题库中存储的是问题Q和答案A的组合。当用户提问的问题和组合中Q相似时,系统会返回组合中的答案A。这里需要考虑多个Q和用户问题相似、没有Q和用户问题相似/Q和用户问题相似度低,这种分支情况的处理。
-
难点:落地成本高,需要构建、维护大量问题组合。答案的采纳率主要依赖于问题的覆盖率和更新及时性。
-
2.2. Doc-Based QA(简称 DocQA)
-
-
示意:
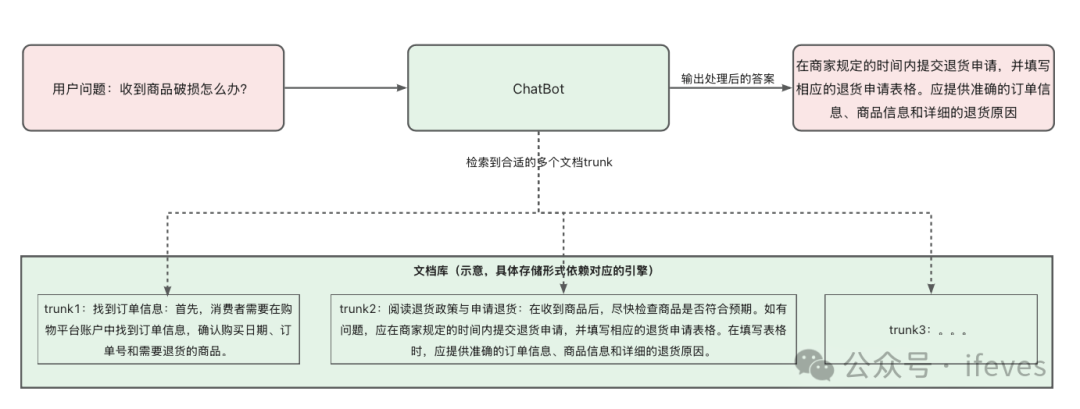
-
用户价值:和FAQ的应用场景类似,但是支持的用户问题覆盖率高,只要文档被召回,就很容易回答用户的问题。
-
实现思路:关键于将非结构化文本转化为可检索的数据单元。这种方案在处理复杂说明、政策法规等场景中具有独特优势。
-
这个方案同样分为2部分:① 数据单元构建阶段:通过对文档分块后,构建可检索的数据(索引、向量等),② 搜索回答阶段:用户提问后,搜索到对应的文档块,然后使用文本模型提前文档摘要进行回答。
-
在LLM出现之前,知识构建阶段主要是基于搜索引擎存储文档;搜索问答阶段,主要使用专用的小模型进行文档摘要。技术门槛高、答案采纳率有提升空间。在LLM出现后,形成了一套基于向量数据库 + LLM 的方案,不需要准备训练文本模型,技术门槛大幅降低。
-
难点:在LLM出现后,技术实现的难点主要聚焦在提升『文档预处理合理性』和『检索召回率』这2个方向上了。
-
2.3. KG-Based QA
-
-
示意:
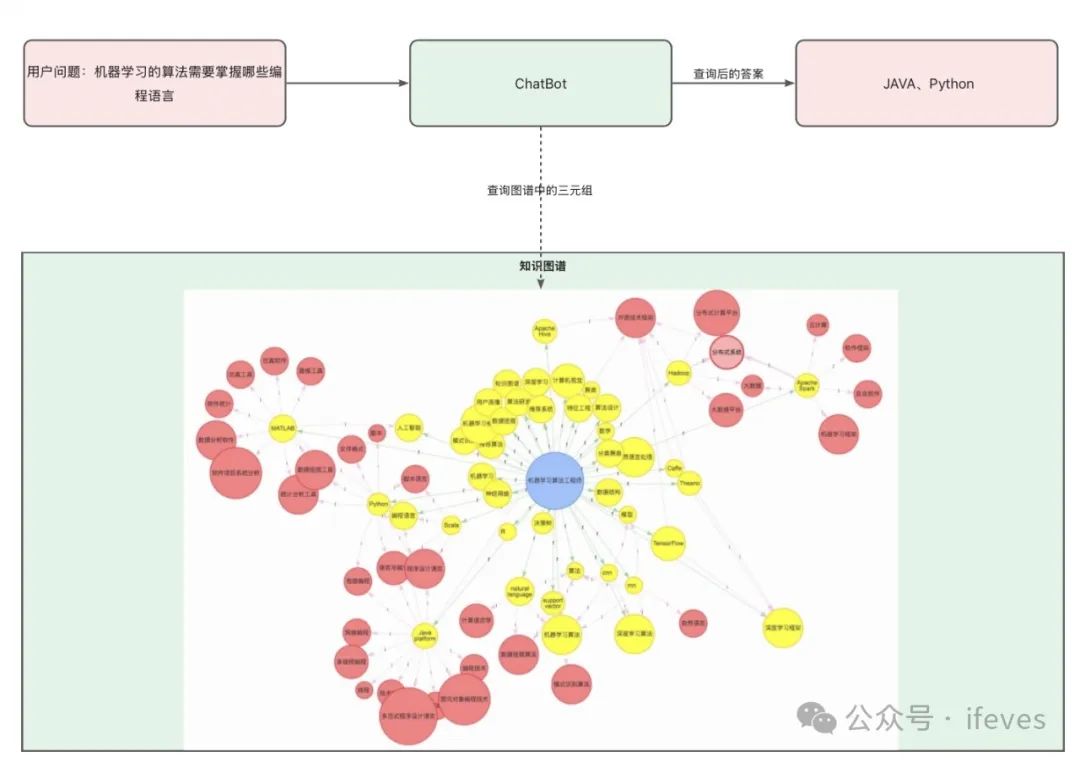
-
用户价值:适用于依赖专家经验进行推理的场景,能够很好之前Doc-Based QA很难回答需要多跳推理能给出答案的提问。
-
实现思路:通过构建领域知识图谱,将用户自然语言问题转化为图结构查询,利用实体关系推理生成答案。相较于其他方案,其核心差异在于引入了语义关联推理能力。
-
这个方案也分为2部分:① 知识图谱构构建阶段:实体抽取与实体关系构建。②基于知识的推理:对用户提问,基于知识图谱完成多跳推理,提升答案的采纳率。
-
难点:知识图谱构建成本、实体与关系构建的准确率与及时性,一直是业界的难点,在LLM出来后,低成本的构建和维护方案才成为可能。
-
优缺点:
-
优点:适用于需要专家经验,才能回答的推理类问题,也是人工智能-符号主义在专家系统中落地的一个关键技术。
-
2.4. Table-Based QA(简称 TableQA)
-
-
示意:
-
-
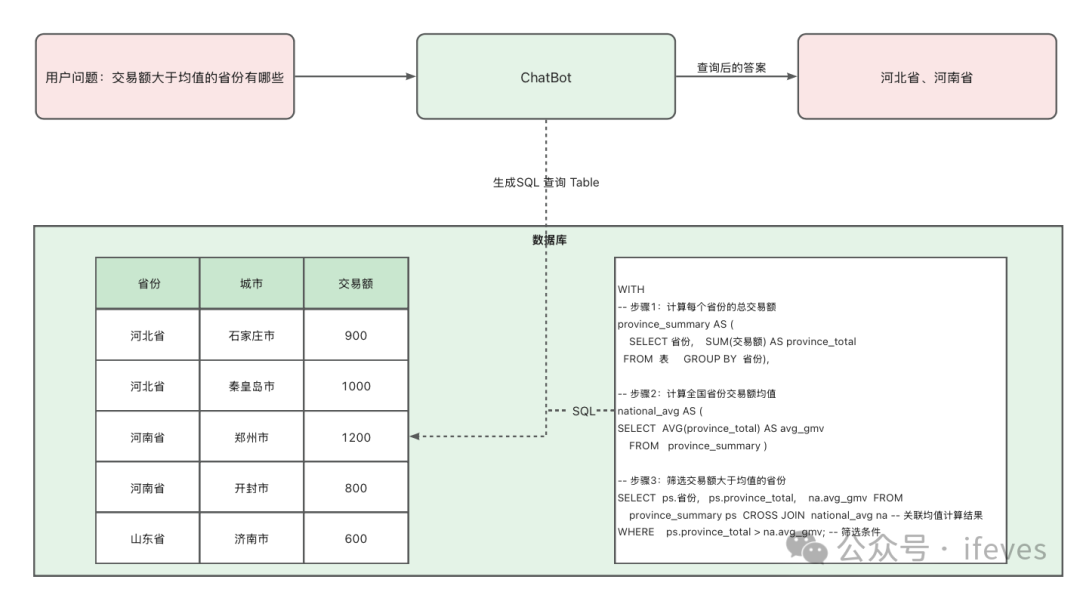
-
-
用户价值:如果能落地(答案准确率达到99.x%),基本上不需要用户做任何特殊的学习,就可以自助进行数据分析。是数据分析平民化、AI+BI 的一个关键技术。
-
实现思路:TableQA是1972年数据库领域提出的一个课题,最早的实现技术是 NLIDB(Natural Language Interfaces to Databases),是通过模板和规则的方法讲用户的提问转换为SQL语句,从而回答用户的问题,一直到2013年 deep learning 和该课题结合,相关技术方案才蓬勃发展。出现了2类技术分支:
-
Table2Text:直接把全表数据给模型,模型根据用户的提问,直接回答用户的问题。相关论文关键词:Table2Text、Table + NLG。这个技术方案可以处理不规则表格(嵌套表格、分层表格等)数据的分析、但是支持的格数据量小。
-
Text2DSL:模型将用户的提问转换为取数DSL,相关论文关键词:Text2SQL、Text2Python等等。这个技术方案通过生成取数的 DSL,从而可以支持海量数据的查询、分析,但是要求表格是结构化的二维表。
-
3. 未完待续
在LLM时代出来后,发现 DocQA 和 TableQA 之 Text2SQL 整体的实现难度已经大幅降低,但是依然有很多关键难点并没有彻底解决,后面会深入介绍我们在实际落地过程中遇到的各种难点以及解决方案
《DocQA 在LLM 时代的RAG的方案及各种难点》
《TableQA 之Text2SQL 在LLM 时代的方案及各种难点》
4. 本文参考
-
《Review of spoken dialogue systems》
-
《A Survey on Dialogue Systems: Recent Advances and New Frontiers》
-
《Task-Oriented Dialogue as Dataflow Synthesis》
-
《S PREADSHEET LLM Encoding Spreadsheets for Large Language Models》
-
《TableRAG Million-Token Table Understanding with Language Models 2410.04739v1》

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)