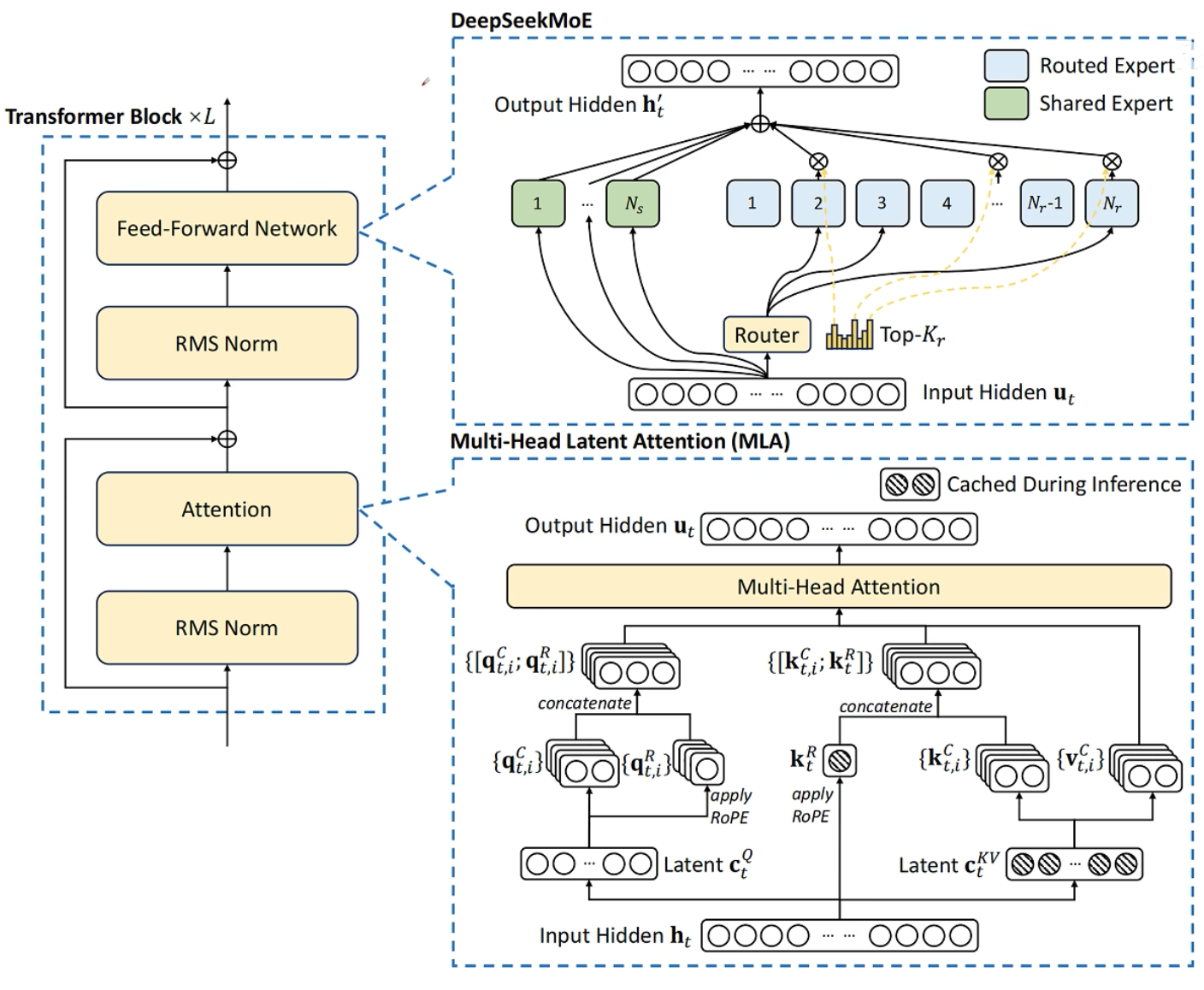
DeepSeek MLA详解
DeepSeek MLA详解
·
DeepSeek MLA详解
回顾
Attention的计算过程
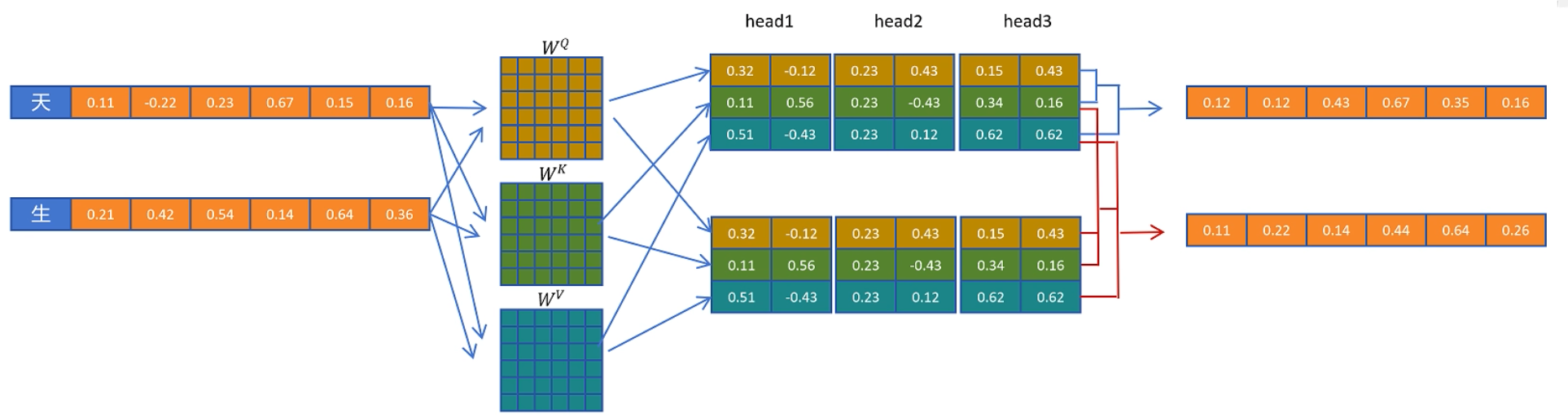
- 首先计算出第一个token的Q、K、V得到第一个token的attention,并缓存该token的K、V,
- 其次依据第一个token的K和第二个token的 Q、K,再结合第一个token的V和第二个token的V,得到第二个token的attention,并缓存第二个token的K、V
- 剩余的token一次类推
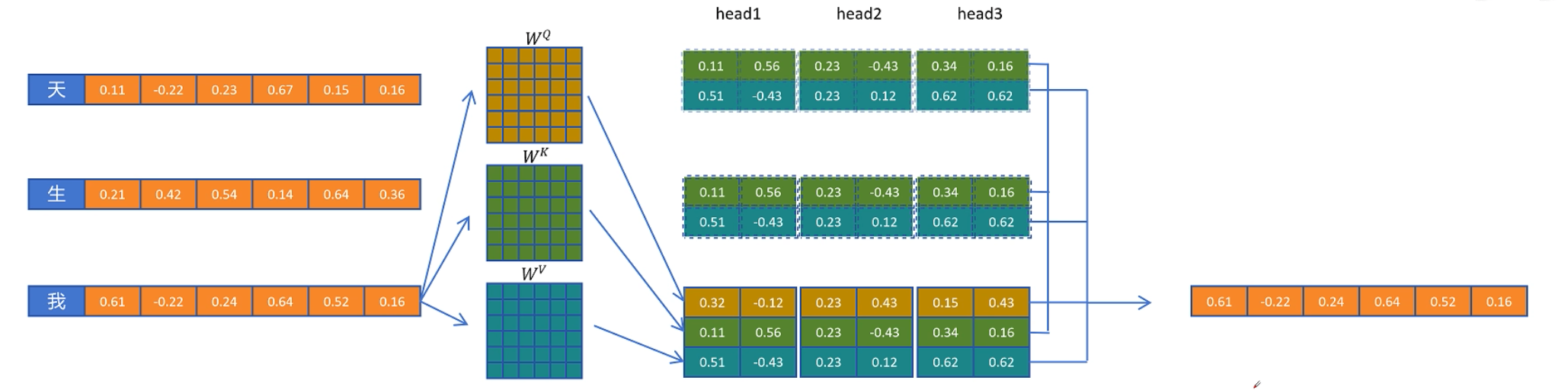
优缺点
- KV cache 减少了推理的计算量,加快了推理速度
- 随着 序列的越来越长,KV cache占用的显存也越来越来,也就是用宝贵的空间换速度
尝试的解决方法
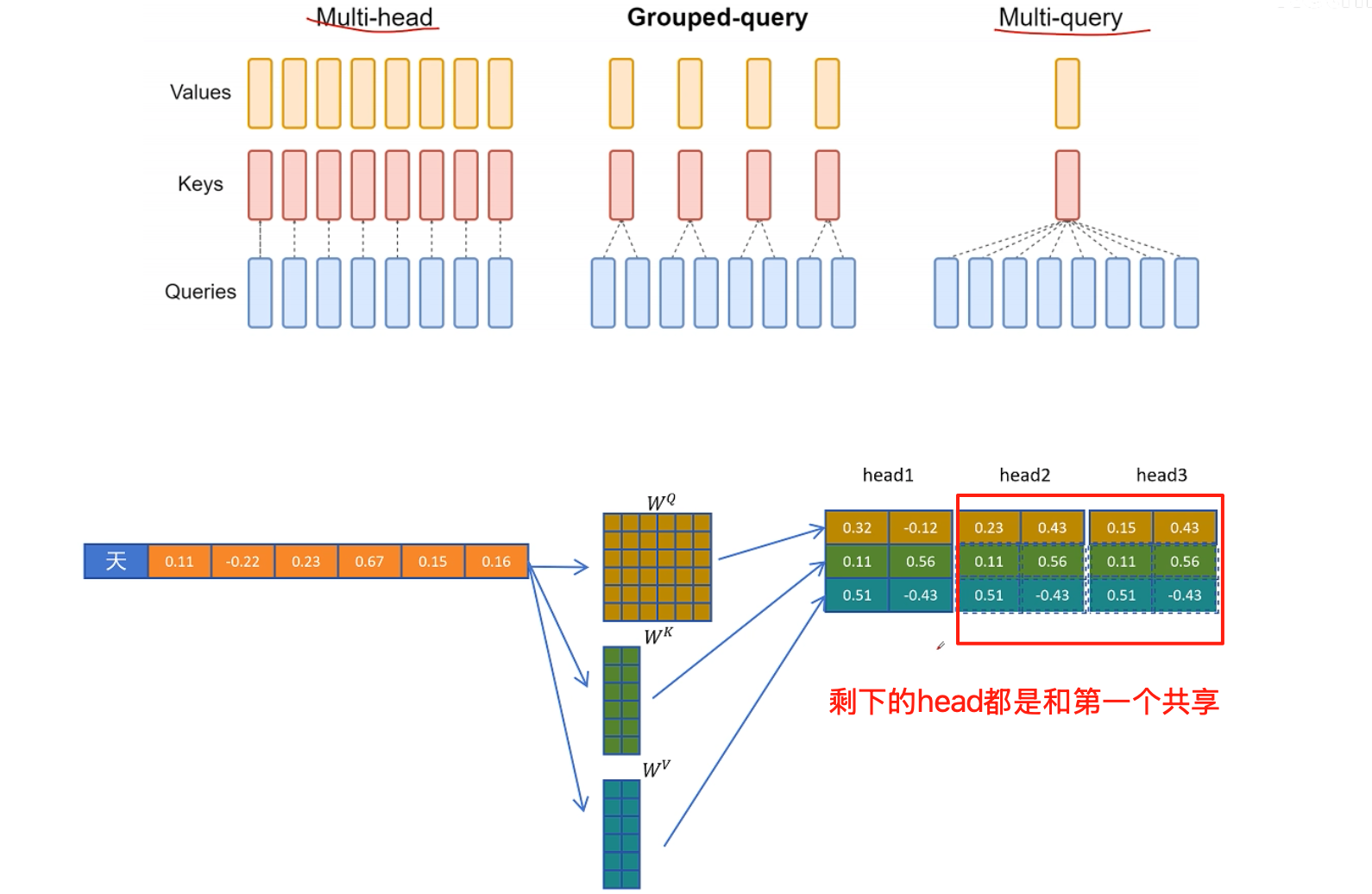
multi-query 虽然减少了缓存量,但是大大降低了性能,所以有了GQA。以下是性能对比,为了实验更公平,gqa、mqa,参数少就增加了层数,保证参数量几乎一致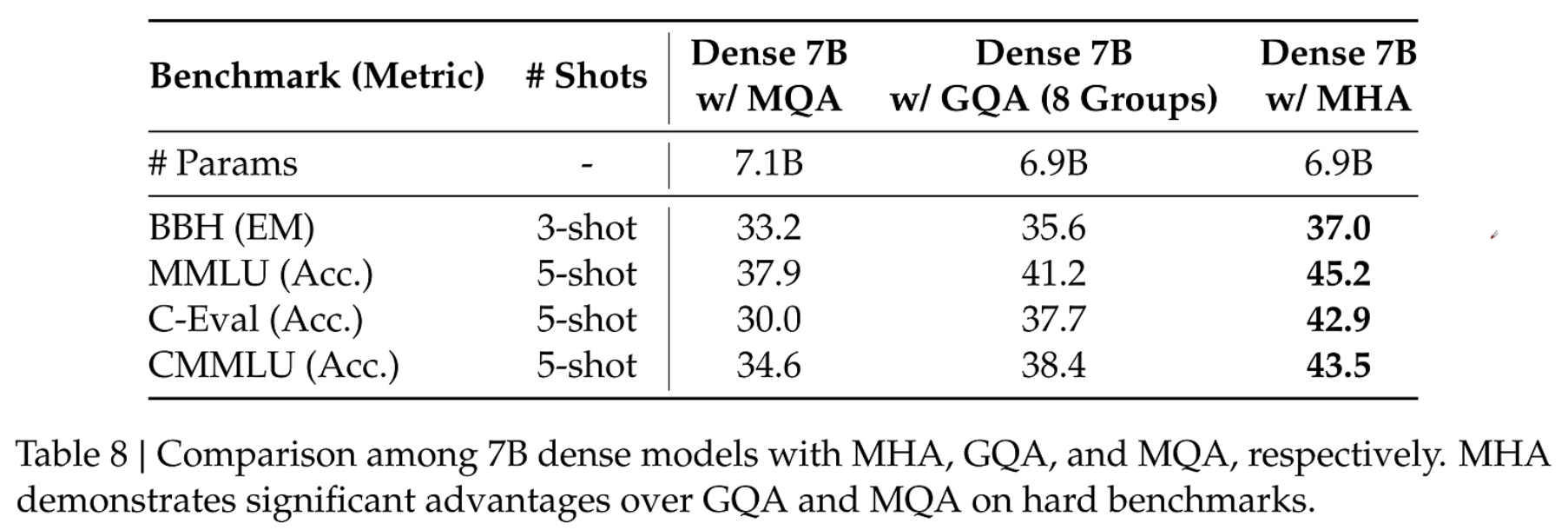
那么有没有既能减少KV catch 又能保证模型性能的做法呢?那就是MLA
MLA的计算过程

首先使用一个压缩矩阵Wdkv 得到cache,使用时在使用两个矩阵 Wuk 和 Wuv 解压得到K、V,再进行attention计算,但是在使用两个矩阵解压时,引入了新的计算,这不是和减少计算量相违背吗?
带缓存的推理过程
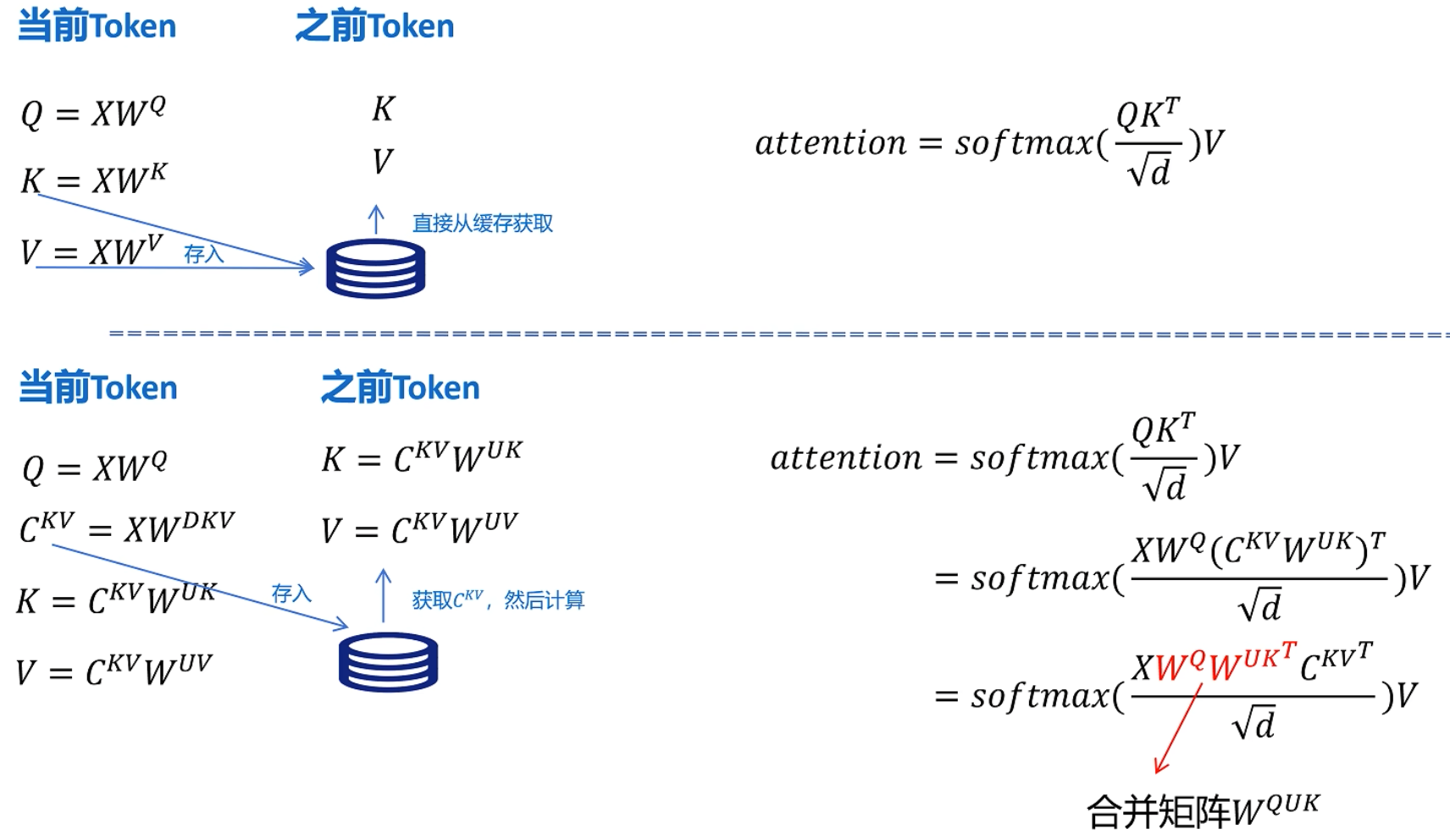

以上不再过多赘述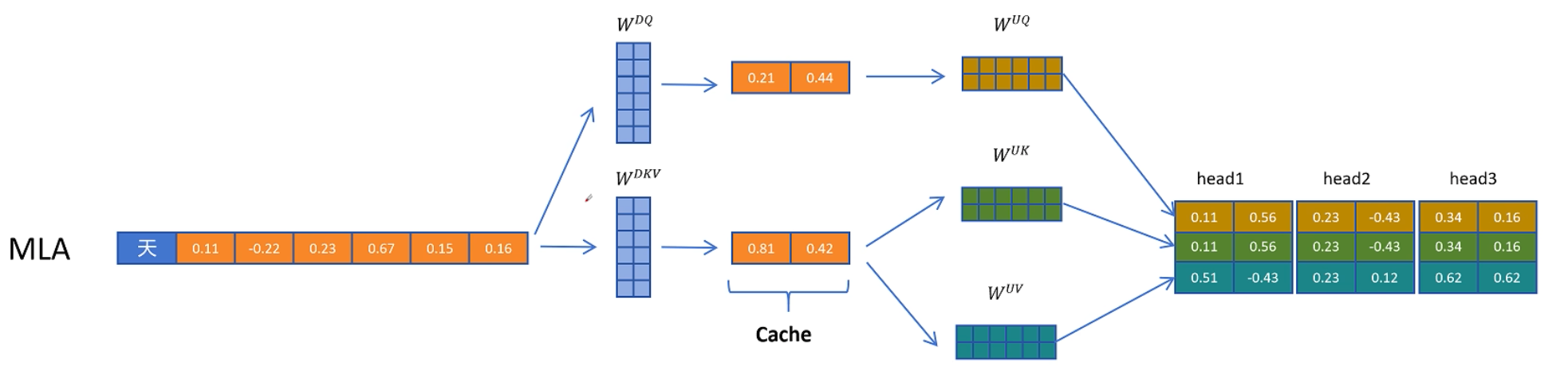
在deepseek中不仅压缩了K、V还压缩了Q。但是q的无需缓存
以上过程看似很好,但是忽略了一个问题:整个过程中没有加入位置信息-- 旋转位置编码
旋转位置编码
旋转位置编码显示在大模型中 默认的位置编码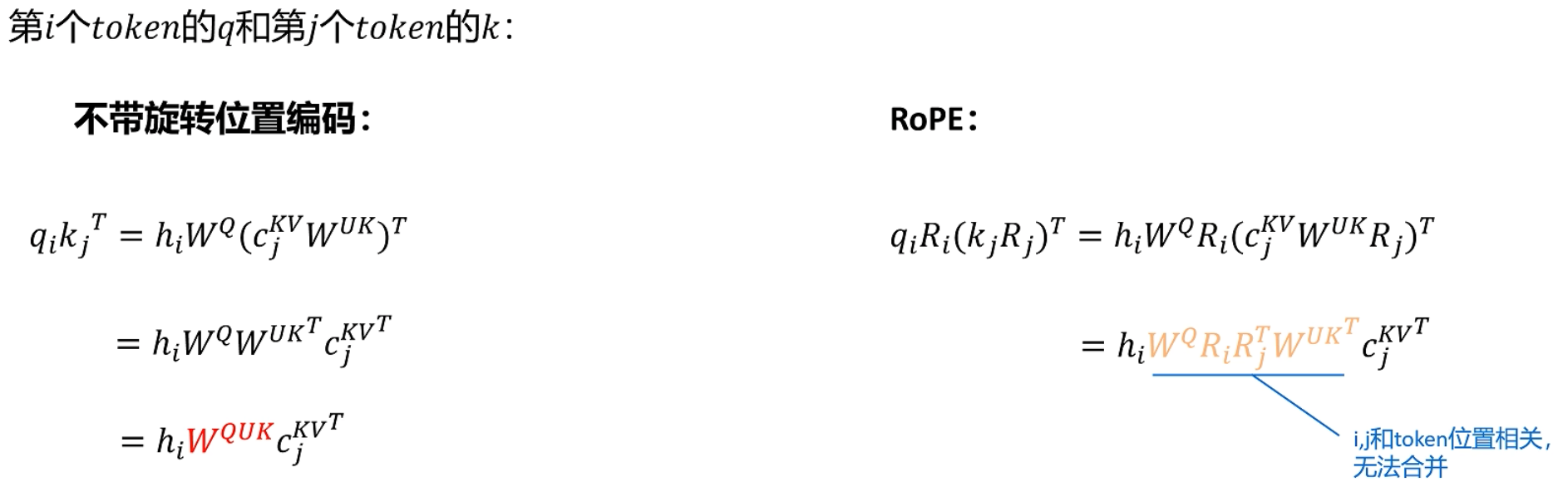
由于旋转位置编码和位置有关系,无法使用不带旋转位置编码的矩阵融合方式消除减压操作,所以提出了为Q、K额外增加一些维度,表示位置信息。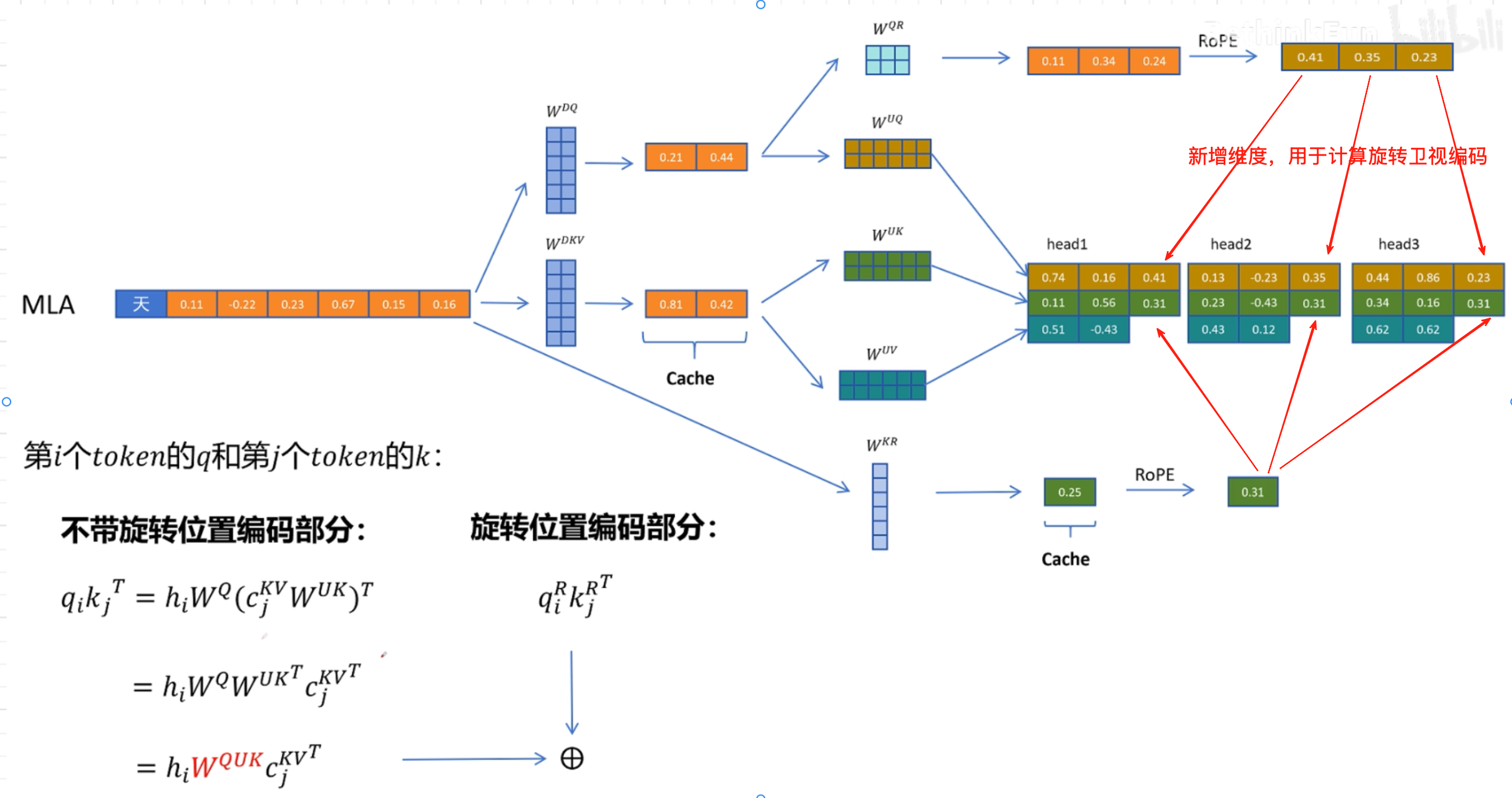
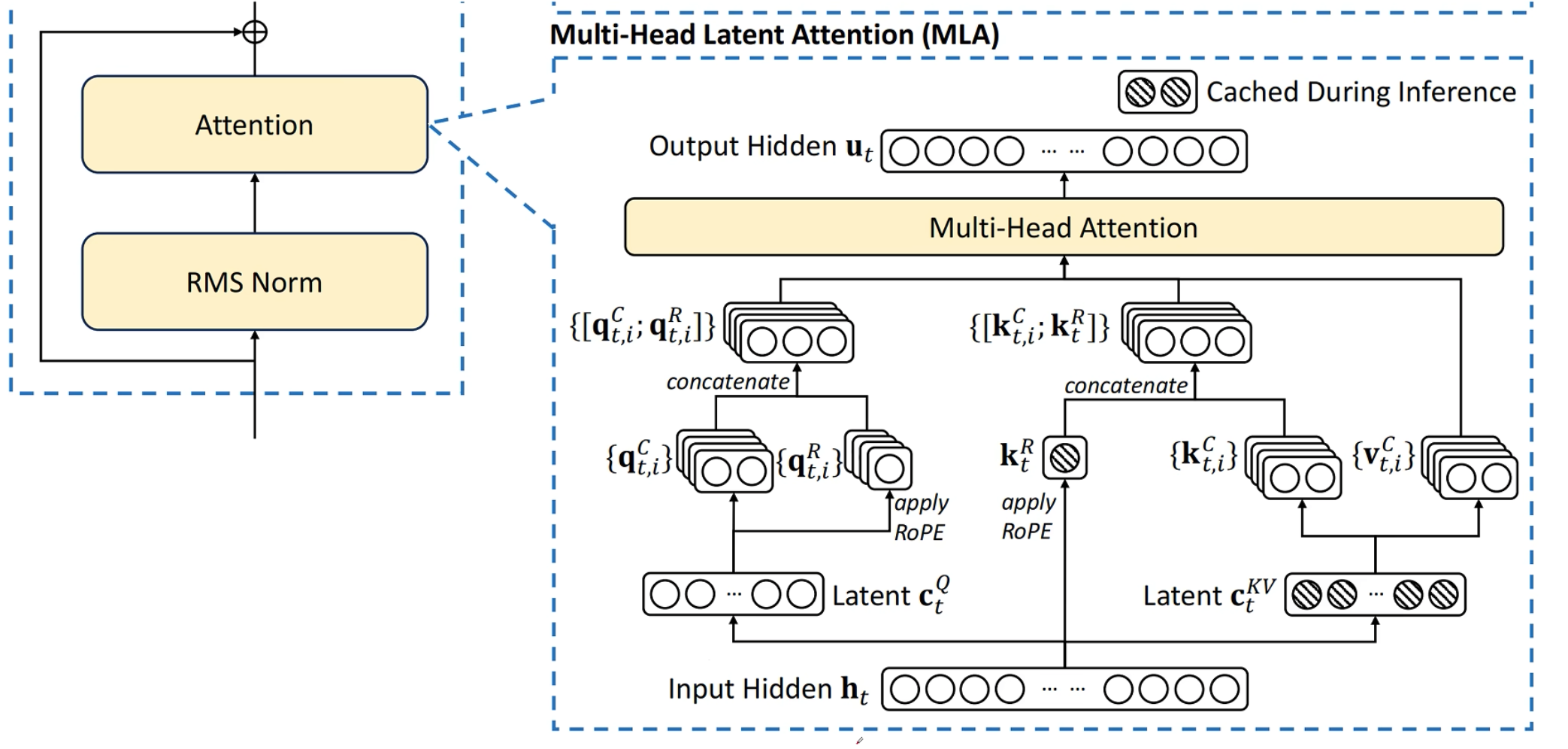
图中阴影部分是需要缓存的

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)