14 大模型学习——低精度微调
上溢出:超出了数据类型所能表示的最大范围下溢出:结果小于数据类型所能表示的最小范围,导致精度丢失或结果不准确。量化需要安装bitsandbytes:pip install bitsandbytes==0.37.2 -i其他部分不需要修改,修改创建模型代码即可Step4 创建模型# 多卡情况,可以去掉device_map="auto",否则会将模型拆开load_in_8bit=True # 以8位精
·
大模型训练的难点

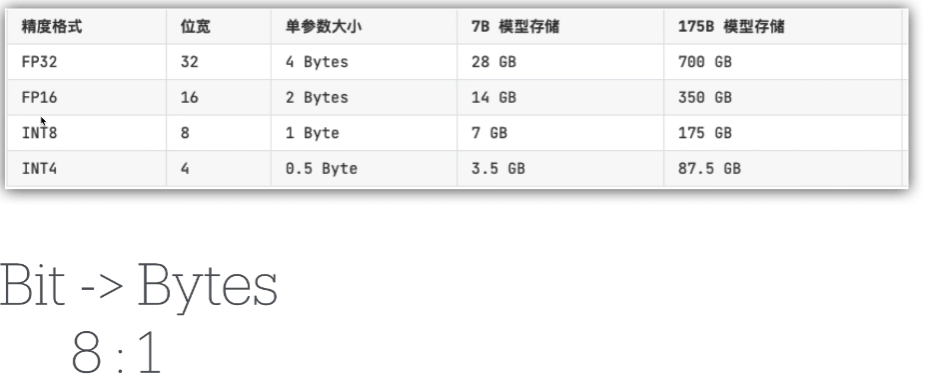
模型训练的显存占用:



一、半精度模型训练
1、半精度定义

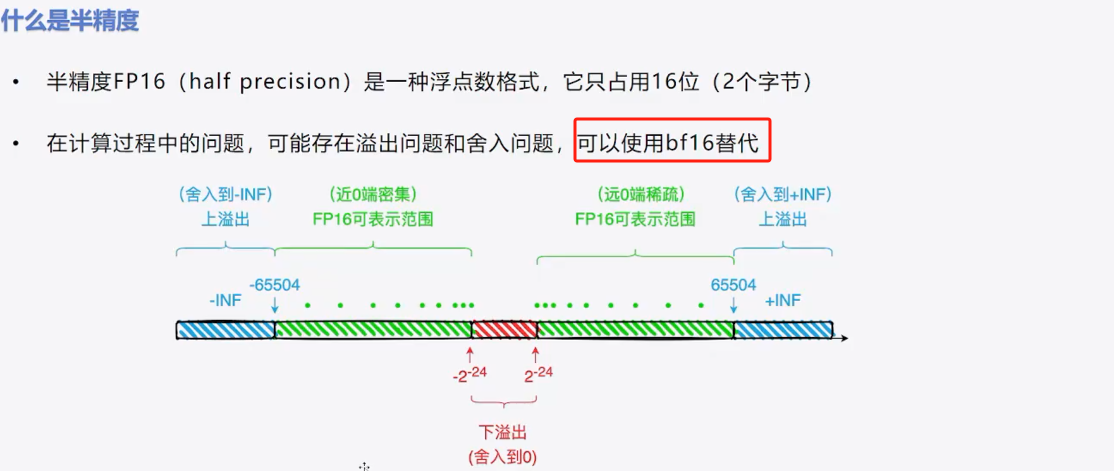
- 上溢出:超出了数据类型所能表示的最大范围
- 下溢出:结果小于数据类型所能表示的最小范围,导致精度丢失或结果不准确。
2、如何启用半精度训练

3、bf16和fp16对比


4、⭐半精度训练实例
(1)模型简介


(2)代码实现
Step1 导入相关包
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, TrainerStep2 加载数据集
ds = Dataset.load_from_disk(r"/root/bigmodel/bigmodel_code/data/alpaca_data_zh")
ds
ds[:3]
Step3 数据集预处理
tokenizer = AutoTokenizer.from_pretrained(r"/root/bigmodel/bigmodel_code/models/Llama-2-7b-ms")
tokenizer#是用于设置填充方向的配置。在自然语言处理(NLP)中,
# 当需要对不同长度的序列进行填充(padding)时,填充的方向可以是左侧(left)或右侧(right)。
# 默认情况下,许多 tokenizer 的填充方向是右侧。
tokenizer.padding_side = "right" # 一定要设置padding_side为right,否则batch大于1时可能不收敛tokenizer.pad_token_id = 2 #表示你将填充(padding)标记的 ID 设置为 2
# Llama分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性
# tokenizer("呀", add_special_tokens=False) def process_func(example):
MAX_LENGTH = 1024 # Llama分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ", add_special_tokens=False)
response = tokenizer(example["output"], add_special_tokens=False)
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.eos_token_id]
attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.eos_token_id]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
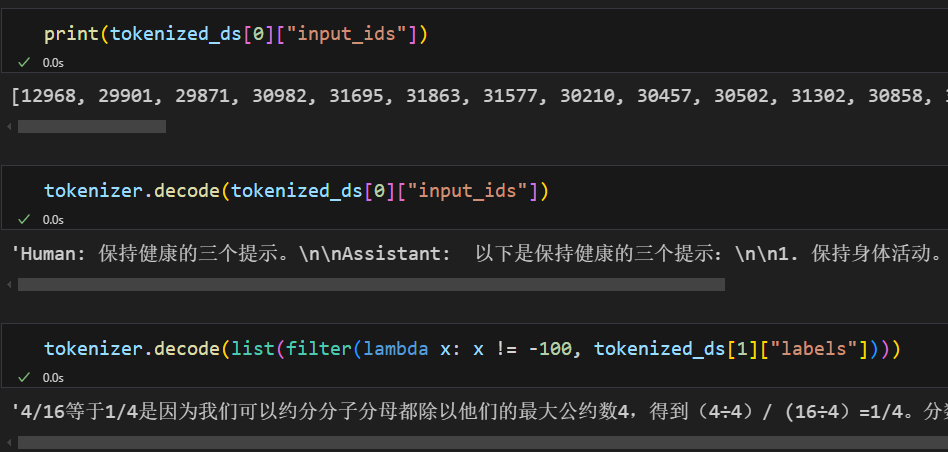
}tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
tokenized_ds
Step4 创建模型
import torch
torch.backends.cuda.enable_mem_efficient_sdp(False) # 多卡时需要设置
torch.backends.cuda.enable_flash_sdp(False) # 多卡时需要设置
# 多卡情况,可以去掉device_map="auto",否则会将模型拆开
# bfloat16(Brain Floating Point 16)是一种16位浮点数格式,由Google开发,主要用于深度学习
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
r"/root/bigmodel/bigmodel_code/models/Llama-2-7b-ms",
low_cpu_mem_usage=True, # 减少 CPU 内存占用
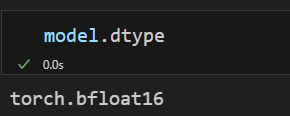
torch_dtype=torch.bfloat16, # 模型加载为 bfloat16 精度
device_map="auto" # 自动分配模型到多卡
)
Lora微调
PEFT Step1 配置文件
from peft import LoraConfig, TaskType, get_peft_model
config = LoraConfig(task_type=TaskType.CAUSAL_LM)
configPEFT Step2 创建模型
model = get_peft_model(model, config)
model
model.enable_input_require_grads() # 开启梯度检查点时,要执行该方法Step5 配置训练参数
args = TrainingArguments(
output_dir="./chatbot",
per_device_train_batch_size=1,
#梯度累积步数
#通过将多个小批量的梯度累积起来,然后一次性更新模型参数,从而在有限的内存资源下实现相当于更大批量的训练效果。
#当累积的步数达到预设的 gradient_accumulation_steps 时,使用累积的梯度更新模型参数,并清零累积的梯度。
#节省内存
#模拟大批量训练
# 提高训练稳定性
gradient_accumulation_steps=16,
logging_steps=10,
num_train_epochs=1,
#梯度检查点,用于减少深度学习模型训练过程中内存占用
#反向传播需要存储前向传播中每一层的中间激活值(activations),以便计算梯度。
# 对于非常深的模型或大批量数据,这些激活值会占用大量内存
#Gradient Checkpointing 的核心思想是只存储部分激活值,并在反向传播时重新计算其他激活值,从而减少内存占用。
gradient_checkpointing=True,
# 是 Adam 优化器中的一个重要参数,用于确保数值稳定性,默认值为 1e-8
adam_epsilon=1e-4
)Step6 创建训练器
trainer = Trainer(
model=model,
args=args,
tokenizer=tokenizer,
train_dataset=tokenized_ds.select(range(6000)), # 选择前6000条进行训练
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)Step7 模型训练
trainer.train()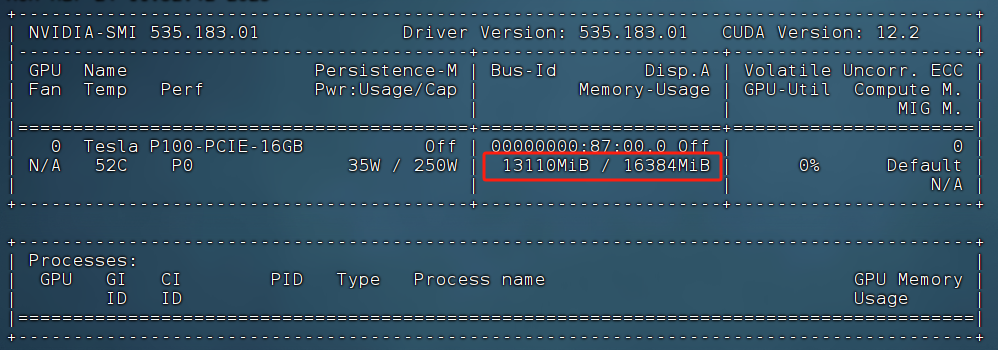

二、8bit训练
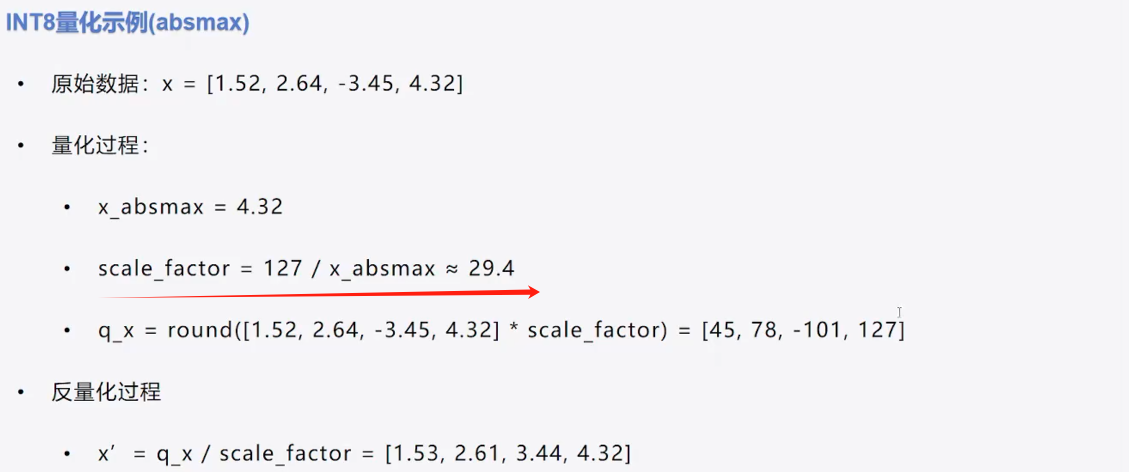
1、量化定义、过程、存在问题




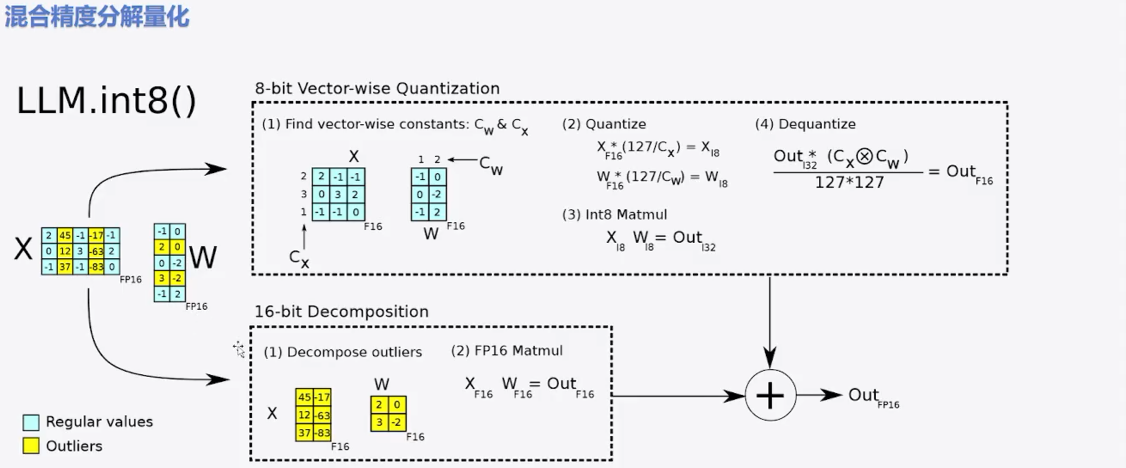
2、混合精度分解量化
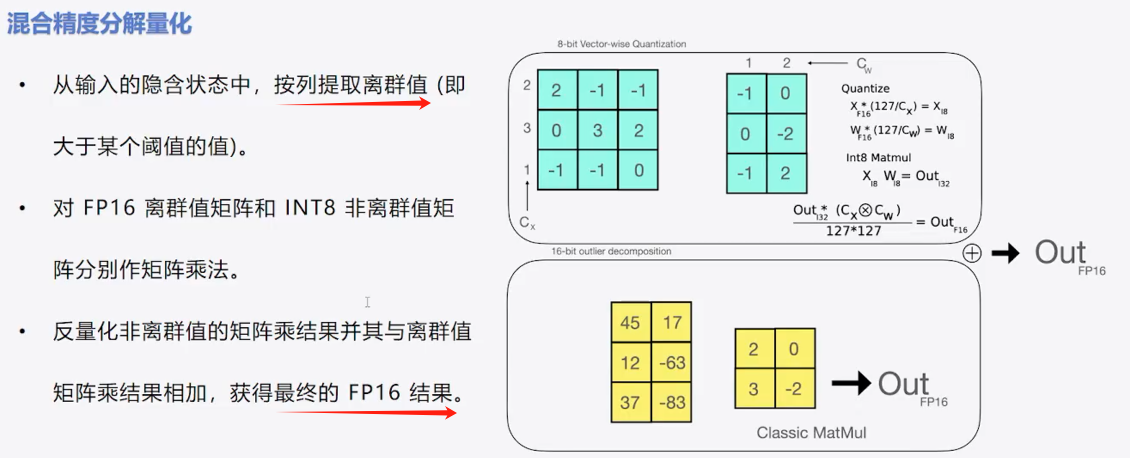
3、代码实现
量化需要安装bitsandbytes:pip install bitsandbytes==0.37.2 -i Simple Index
其他部分不需要修改,修改创建模型代码即可
Step4 创建模型
import torch
# 多卡情况,可以去掉device_map="auto",否则会将模型拆开
model = AutoModelForCausalLM.from_pretrained(
r"/root/bigmodel/bigmodel_code/models/Llama-2-7b-ms",
low_cpu_mem_usage=True,
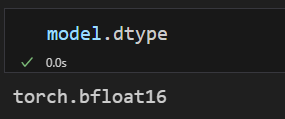
torch_dtype=torch.bfloat16,
device_map="auto",
load_in_8bit=True # 以8位精度加载模型,这可以进一步减少内存使用并可能加速计算,但可能会牺牲一些精度
)

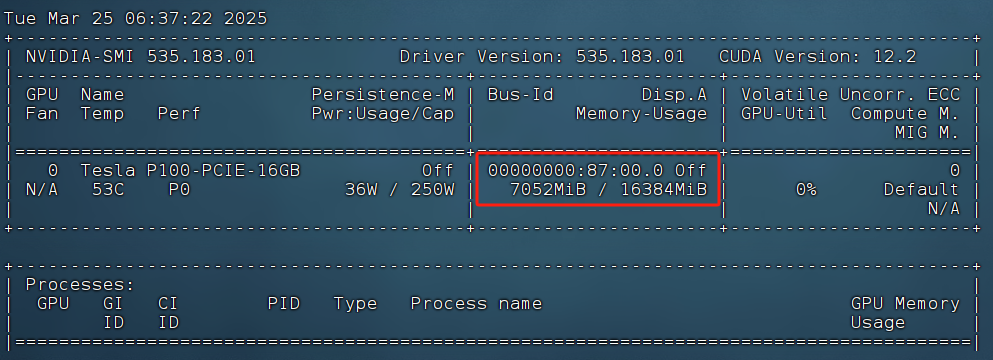
模型加载占用显存
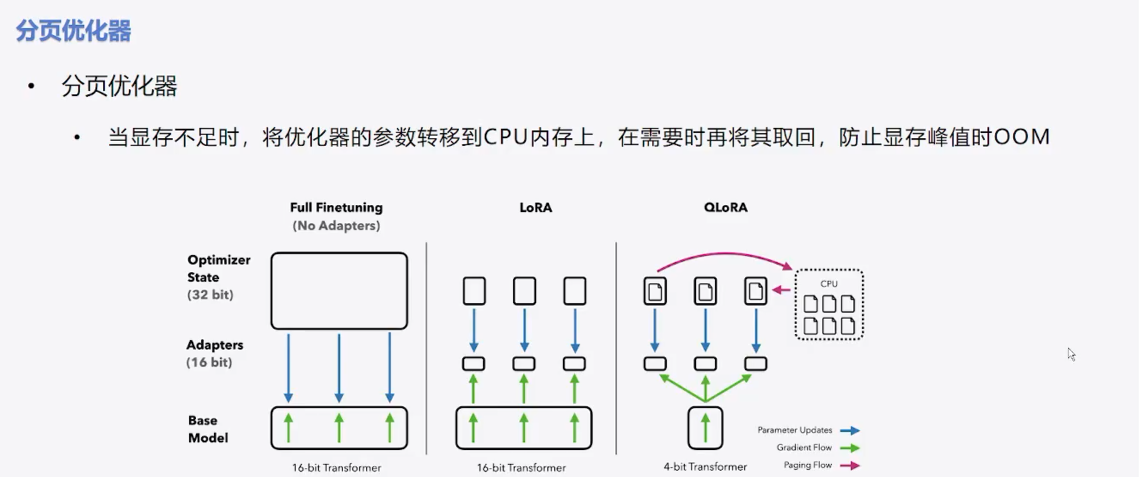
三、QLoRA = 量化(int4) + LoRA
1、QLoRA简介
QLoRA 在 LoRA 的基础上引入了量化技术,进一步压缩模型权重和梯度,从而降低资源需求。
QLoRA = 量化(int4) + LoRA



2、简单线性量化存在的问题及解决方案



- 目标域(Target Domain) 是迁移学习(Transfer Learning)中的一个关键概念,指的是我们希望模型最终能够很好地执行任务的数据分布或领域。
- 源域(Source Domain),即模型最初训练的数据分布或领域。
3、分位数量化
(1)定义

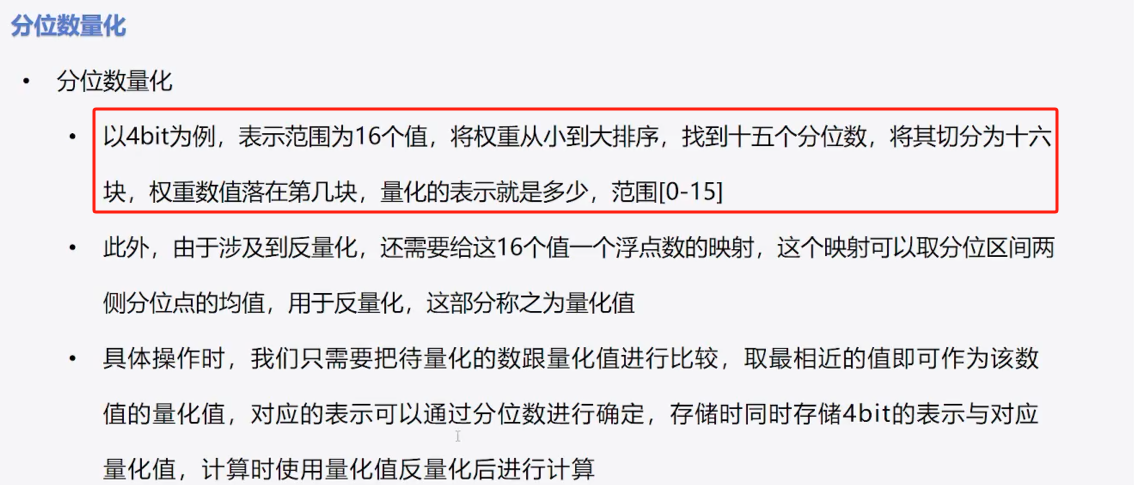
(2)原理




4、分位数量化改进-NF4
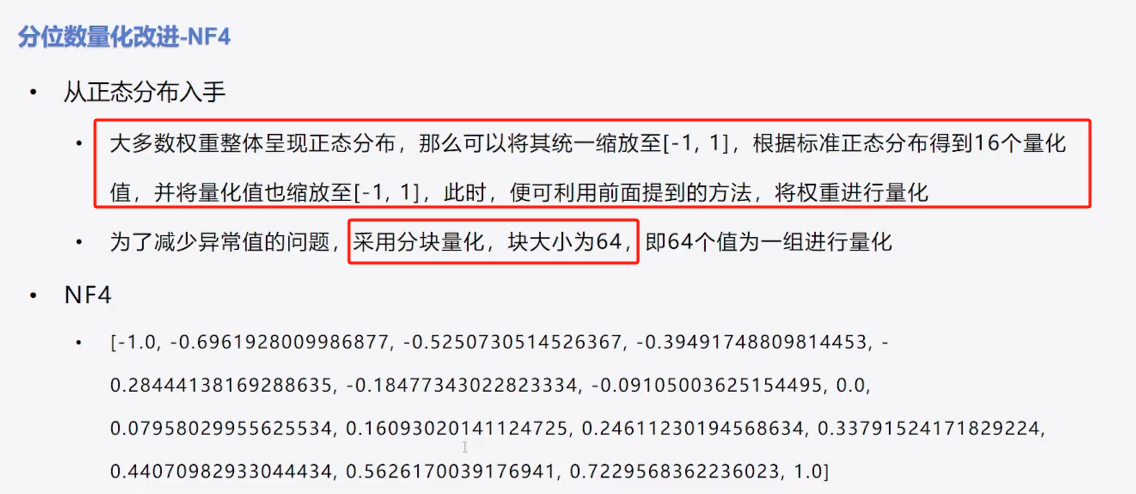



5、代码实现
其他部分不需要修改,修改创建模型代码即可
Step4 创建模型
import torch
# 多卡情况,可以去掉device_map="auto",否则会将模型拆开
model = AutoModelForCausalLM.from_pretrained(
r"/root/bigmodel/bigmodel_code/models/Llama-2-7b-ms",
low_cpu_mem_usage=True,
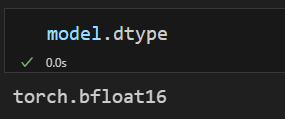
torch_dtype=torch.bfloat16,
device_map="auto",
load_in_4bit=True, # 加载4位量化版本的模型
bnb_4bit_compute_dtype=torch.bfloat16, # 4位量化计算时的数据类型为bfloat16
bnb_4bit_quant_type="nf4", # 4位量化的类型为NF4
bnb_4bit_use_double_quant=True # 使用双重量化
)
模型加载占用显存

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)