Python - 爬虫;Scrapy框架之中间件(Middleware)(三)
添加自定义 User-AgentWin64;return None # 继续处理请求在'myproject.middlewares.CustomUserAgentMiddleware': 543, # 543 是优先级,数字越小优先级越高。
阅读本文前先参考
https://blog.csdn.net/MinggeQingchun/article/details/145904572
在Scrapy框架中,中间件(Middleware)是一种用于处理请求和响应的核心组件。它们可以在Scrapy引擎的请求和响应处理的管道中插入额外的处理步骤。中间件可以用来执行多种任务
如:
1、请求和响应的修改:在请求被发送或响应被下载后进行修改。
2、日志记录:记录关键事件,如请求的发出和响应的接收。
3、错误处理:处理请求失败的情况,例如重试失败的请求。
4、爬虫限制:例如设置爬虫的速度限制或者限制爬取的深度。
5、用户代理设置:修改请求头中的用户代理字符串。
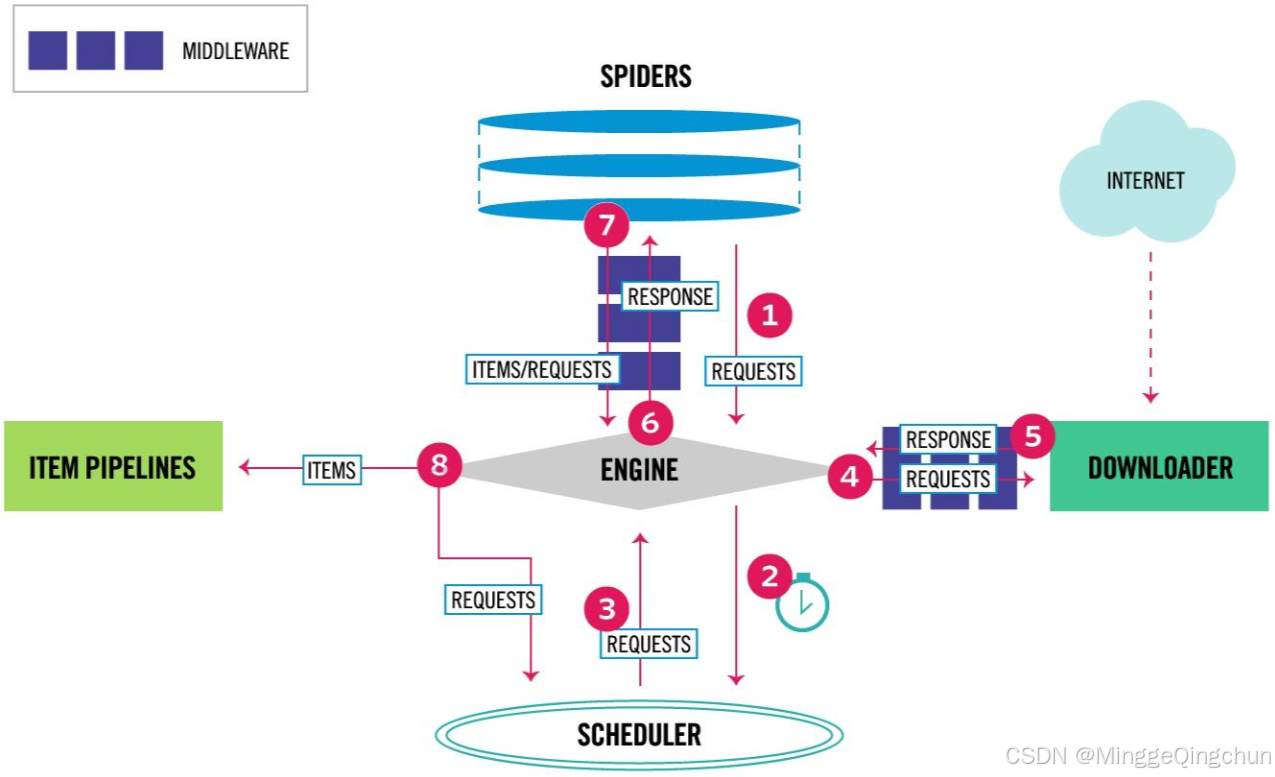
中间件的工作流程
1、初始化:当 Scrapy 启动时,from_crawler 方法被调用,并传入 crawler 对象。中间件从 crawler.settings 中获取代理列表,并实例化 RandomProxyMiddleware
2、处理请求:每次 Scrapy 发出请求时,process_request 方法被调用。中间件从代理列表中随机选择一个代理,并将其添加到请求的 meta 属性中
3、记录日志:中间件会记录使用的代理信息,方便调试和监控
一、Scrapy 中间件(Middleware)的分类
1、下载器中间件(Downloader Middleware)
官方文档:Downloader Middleware — Scrapy 2.12.0 documentation
下载器中间件用于处理发出的请求和下载的响应,它们在请求到达下载器之前或响应到达引擎之前执行。这类中间件可以用于:
修改请求头(比如User-Agent、Cookies等)
设置代理(如IP代理)
处理重定向
管理请求失败的重试机制
捕获和处理下载过程中发生的异常
下载器中间件的主要方法包括:
-
process_request(request, spider)
在请求发送到下载器之前调用。可以修改请求(如添加 headers、代理等),或者直接返回一个Response对象以跳过下载器。 -
process_response(request, response, spider)
在下载器返回响应后调用。可以修改响应内容,或者返回一个新的Request对象以重新发起请求。 -
process_exception(request, exception, spider)
当下载器或process_request方法抛出异常时调用。可以处理异常,例如重试请求或返回一个自定义的Response对象。
/**
* 处理每一个经过下载器的请求
*
* @param request 待处理的请求对象(scrapy.http.Request)
* @param spider 当前正在运行的爬虫实例
* @return
* --------------- 可以返回 None,表示继续处理这个请求。
* --------------- 可以返回 scrapy.http.Response,则中间件会返回这个响应对象并跳过下载过程,直接把响应传递给爬虫。
* --------------- 可以返回 scrapy.exceptions.IgnoreRequest 异常,则请求会被丢弃,触发 spider 的 request_dropped 信号。
*/
process_request(self, request, spider)process request
在request对象传往downloader的过程中和将下载结果返回给engine过程中调用。当返回不同类型的值的时候,行为也不一样:
| 返回值 | 行为 |
| None | 一切正常,继续执行其他的中间件链 |
| Response | 停止调用其他process_request和process_exception函数,也不再继续下载该请求,然后调用process_response的流程 |
| Request | 不再继续调用其他process_request函数,交由调度器重新安排下载 |
| IgnoreRequest | rocess_exception函数会被调用,如果没有此方法,则request.errback会被调用,如果errback也没有,则此异常会被忽略,甚至连日志都没有 |
/**
* 处理下载器返回的响应
*
* @param request 产生这个响应的请求对象(scrapy.http.Request)
* @param response 当前的响应对象(scrapy.http.Response)
* @param spider 当前的爬虫实例
* @return
* --------------- 可以返回 response 对象(或者修改后的新 response 对象),继续交给下一个中间件处理或直接给爬虫。
* --------------- 可以返回一个新的 scrapy.http.Request,该请求会重新被调度和下载。
* --------------- 可以抛出 scrapy.exceptions.IgnoreRequest 异常,表示忽略此请求。
*/
process_response(self, request, response, spider)process_response
在将下载结果返回给engine过程中被调用
| 返回值 | 行为 |
| Response | 继续调用其他中间件的process_response |
| Request | 不再继续调用其他process_request函数,交由调度器重新安排下载 |
| IgnoreRequest | 则request.errback会被调用,如果errback也没有,则此异常会被忽略,甚至连日志都没有 |
/**
* 当下载器或者 process_request/process_response 方法抛出异常时,调用此方法处理异
*
* @param request 产生这个响应的请求对象(scrapy.http.Request)
* @param exception 抛出的异常对象
* @param spider 当前的爬虫实例
* @return
* --------------- 可以返回 None,继续交由其他中间件处理。
* --------------- 可以返回一个 scrapy.http.Response 对象,表示已经处理了该异常并提供了替代的响应。
* --------------- 可以返回一个 scrapy.http.Request 对象,以重新调度此请求。
*/
process_exception(self, request, exception, spider)process_exception
在下载过程中出现异常,或者在process_request中抛出IgnoreRequest异常的时候调用
| 返回值 | 行为 |
| Response | 开始中间件链的process_response处理流程 |
| Request | 不再继续调用其他process_request函数,交由调度器重新安排下载 |
| None | 继续调用其他中间件里的process_exception函数 |
from_crawler(cls, crawler)函数
在Scrapy框架中,from_crawler 类方法是用于从爬虫的配置中初始化一个组件(如Item Pipeline, Middleware等)的一种方式。这种方法允许你将组件的初始化与爬虫的配置紧密绑定,使得配置更加灵活和集中
from_crawler 是一个类方法,用于初始化中间件实例,并将 Scrapy 的 Crawler 对象传递给它。Crawler 对象包含了整个 Scrapy 运行时环境,包括配置、信号和扩展等。通过 from_crawler 方法,中间件可以轻松访问这些资源,从而实现更复杂的功能
在编写自定义中间件时,有时需要访问 Scrapy 的配置信息、信号或其他核心组件。from_crawler 方法使这一过程变得简单和直观。它的主要优势包括:
1、访问配置:可以轻松获取 Scrapy 的设置(settings)
2、连接信号:能够注册和处理 Scrapy 的信号(signals)
3、统一初始化:提供一种统一的方式来初始化中间件实例
实现 from_crawler 方法
1、在 Item Pipeline 中使用
在 Item Pipeline 中使用 from_crawler 方法:
import scrapy
from scrapy.utils.project import get_project_settings
class MyPipeline(object):
def __init__(self, some_setting):
self.some_setting = some_setting
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
some_setting = settings.get('MY_SETTING')
return cls(some_setting)在 settings.py 中设置 MY_SETTING:
MY_SETTING = 'some_value'
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
}2、在 Middleware 中使用
在 Middleware 中使用 from_crawler 方法的方式与在 Pipeline 中类似
import scrapy
from scrapy.utils.project import get_project_settings
class MyMiddleware(scrapy.SpiderMiddleware):
def __init__(self, some_setting):
self.some_setting = some_setting
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
some_setting = settings.get('MY_SETTING')
return cls(some_setting)在 settings.py 中设置 MY_SETTING:
MY_SETTING = 'some_value'
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.MyMiddleware': 543,
}scrapy自带下载器中间件
官网文档:Downloader Middleware — Scrapy 2.12.0 documentation
{
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
}在Scrapy下的default_settings.py文件中
D:\xx\项目\env\Lib\site-packages\scrapy\settings\default_settings.py

2、爬虫中间件(Spider Middleware)
官方文档:Spider Middleware — Scrapy 2.12.0 documentation
爬虫中间件用于处理爬虫生成的请求以及接收到的响应。在引擎把响应交给爬虫处理之前,或者爬虫生成的请求交给引擎之前,爬虫中间件都有机会对这些对象进行处理。具体应用场景包括:
对爬虫产生的请求进行过滤或修改
处理从下载器返回的响应,比如进行一些前置的数据清理
修改从爬虫传出的项目(item)
爬虫中间件的主要方法包括:
-
process_spider_input(response, spider)
在响应传递给爬虫之前调用。可以对响应进行处理,或者抛出异常以阻止响应传递给爬虫。 -
process_spider_output(response, result, spider)
在爬虫返回结果(Items 或 Requests)之后调用。可以修改爬虫的输出结果。 -
process_spider_exception(response, exception, spider)
当爬虫处理响应时抛出异常时调用。可以处理异常,例如记录日志或返回替代结果。
/**
* 当下载器将响应传递给爬虫之前,调用此方法处理响应
*
* @param response 下载器返回的响应对象
* @param spider 当前的爬虫实例
* @return
* --------------- 如果返回 None,响应将继续传递给爬虫处理。
* --------------- 可以抛出 scrapy.exceptions.IgnoreRequest,表示忽略此请求和响应,不会传递给爬虫。
*/
process_spider_input(self, response, spider)/**
* 处理爬虫返回的结果(通常是 item 或新的 request)
*
* @param response 传递给爬虫的响应对象
* @param result 爬虫返回的结果,通常是生成器或列表,包含 Item 对象、Request 对象等
* @param spider 当前的爬虫实例
* @return 必须返回一个可迭代对象,包含 Item 对象或 Request 对象。如果需要,可以对结果进行过滤或修改。
*/
process_spider_output(self, response, result, spider)/**
* 当爬虫在处理响应过程中抛出异常时,调用此方法处理异常
*
* @param response 导致异常的响应对象
* @param exception 抛出的异常对象
* @param spider 当前的爬虫实例
* @return
* --------------- 如果返回 None,Scrapy将继续处理该异常。
* --------------- 如果返回一个可迭代对象,将替代爬虫返回的结果。
*/
process_spider_exception(self, response, exception, spider)/**
* 处理爬虫开始时生成的初始请求
*
* @param start_requests 爬虫开始时生成的初始请求(可迭代对象)
* @param spider 当前的爬虫实例
* @return 必须返回一个可迭代对象,包含 Request 对象。
*/
process_start_requests(self, start_requests, spider)3、内置中间件
请求robots.txt文件,并解析其中的规则。
scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware
执行带Basic-auth验证的请求
scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware
下载请求超时最大时长
scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware
设置默认的请求头信息
scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware
设置请求头信息里的User-Agent
scrapy.downloadermiddlewares.useragent.UserAgentMiddleware
如果下载失败,是否重试,重试几次
scrapy.downloadermiddlewares.retry.RetryMiddleware
实现Meta标签重定向
scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware
实现压缩内容的解析(比如gzip)
scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware
实现30x的HTTPcode的重定向
scrapy.downloadermiddlewares.redirect.RedirectMiddleware
实现对cookies的设置管理
scrapy.downloadermiddlewares.cookies.CookiesMiddleware
实现IP代理
scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware
下载信息的统计
scrapy.downloadermiddlewares.stats.DownloaderStats
自定义中间件示例
以下是一个简单的下载器中间件示例,用于为每个请求添加自定义的 User-Agent:
class CustomUserAgentMiddleware:
def process_request(self, request, spider):
# 添加自定义 User-Agent
request.headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
return None # 继续处理请求在 settings.py 中启用中间件:
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomUserAgentMiddleware': 543, # 543 是优先级,数字越小优先级越高
}中间件的执行顺序
Scrapy 中间件的执行顺序由优先级(priority)决定,优先级是一个整数值,数字越小,优先级越高。Scrapy 内置了一些默认中间件,它们的优先级可以在官方文档中查看。
常用内置中间件
Scrapy 提供了一些内置中间件,例如:
-
UserAgentMiddleware:用于设置 User-Agent。
-
RetryMiddleware:用于重试失败的请求。
-
HttpProxyMiddleware:用于设置代理。
二、中间件应用
1、实现随机 User-Agent
1、在 Scrapy 项目的 middlewares.py 文件中自定义一个下载器中间件类,在这个中间件中,process_request 方法会为每个请求随机选择一个 User-Agent。
import random
class RandomUserAgentMiddleware:
def __init__(self, user_agents):
self.user_agents = user_agents
@classmethod
def from_crawler(cls, crawler):
return cls(
# 获取 settings.py 中的配置
user_agents=crawler.settings.get('USER_AGENTS')
)
def process_request(self, request, spider):
# 从集合中随机取一个元素
user_agent = random.choice(self.user_agents)
if user_agent:
request.headers['User-Agent'] = user_agent2、在 Scrapy 项目的 settings.py 文件中配置中间件,并提供一个 User-Agent 列表。
# 配置多个 USER_AGENT
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.5211 SLBChan/25",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Firefox/57.0 Safari/537.3"
]
# 开启下载器中间件
DOWNLOADER_MIDDLEWARES = {
"myproject.middlewares.RandomUserAgentMiddleware": 543,
}
# 关闭 robots.txt 检查
ROBOTSTXT_OBEY = False3、验证是否成功
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫名字,用于运行爬虫时候使用的值,必须唯一
name = "baidu"
# 允许爬虫的URL必须在此字段内;genspider时可以指定;如qianmu.com意味www.qianmu.com和http.qianmu.org下的链接都可以爬取
allowed_domains = ["www.baidu.com"]
# 爬虫的入口地址,可以多个
start_urls = ["https://www.baidu.com"]
# 框架请求start_urls成功后,会调用parse方法
def parse(self, response):
print("随机 User-Agent:", response.request.headers['User-Agent'])4、运行
(1)Terminal控制台运行
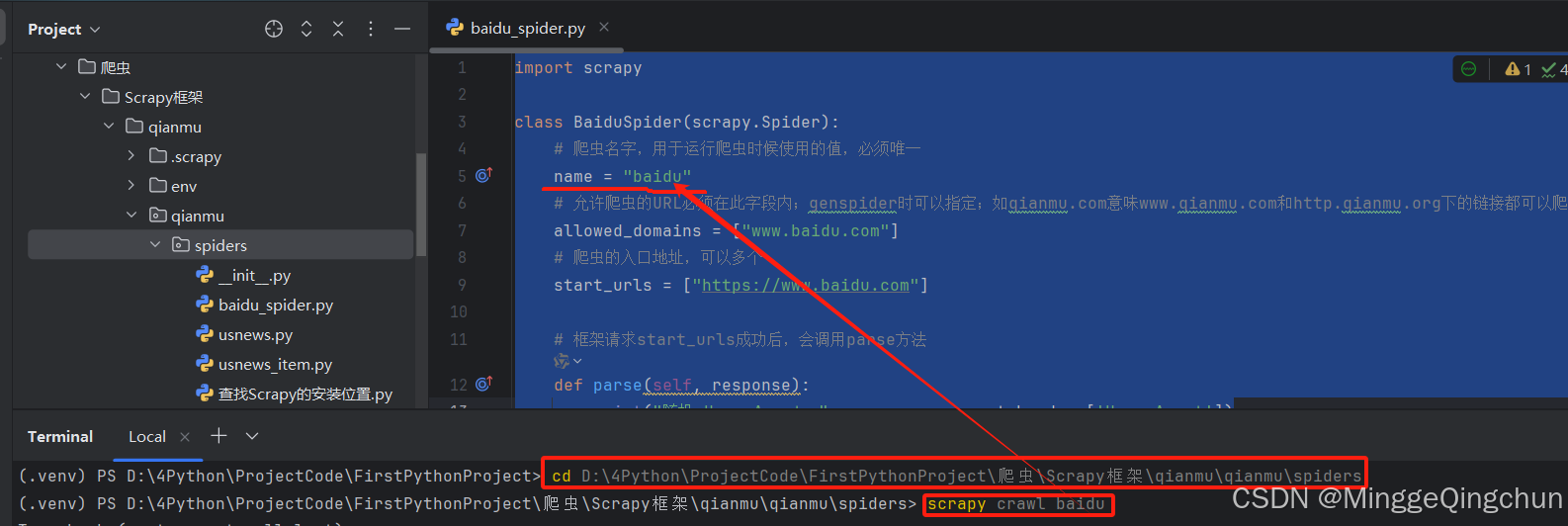
(2)配置环境变量运行
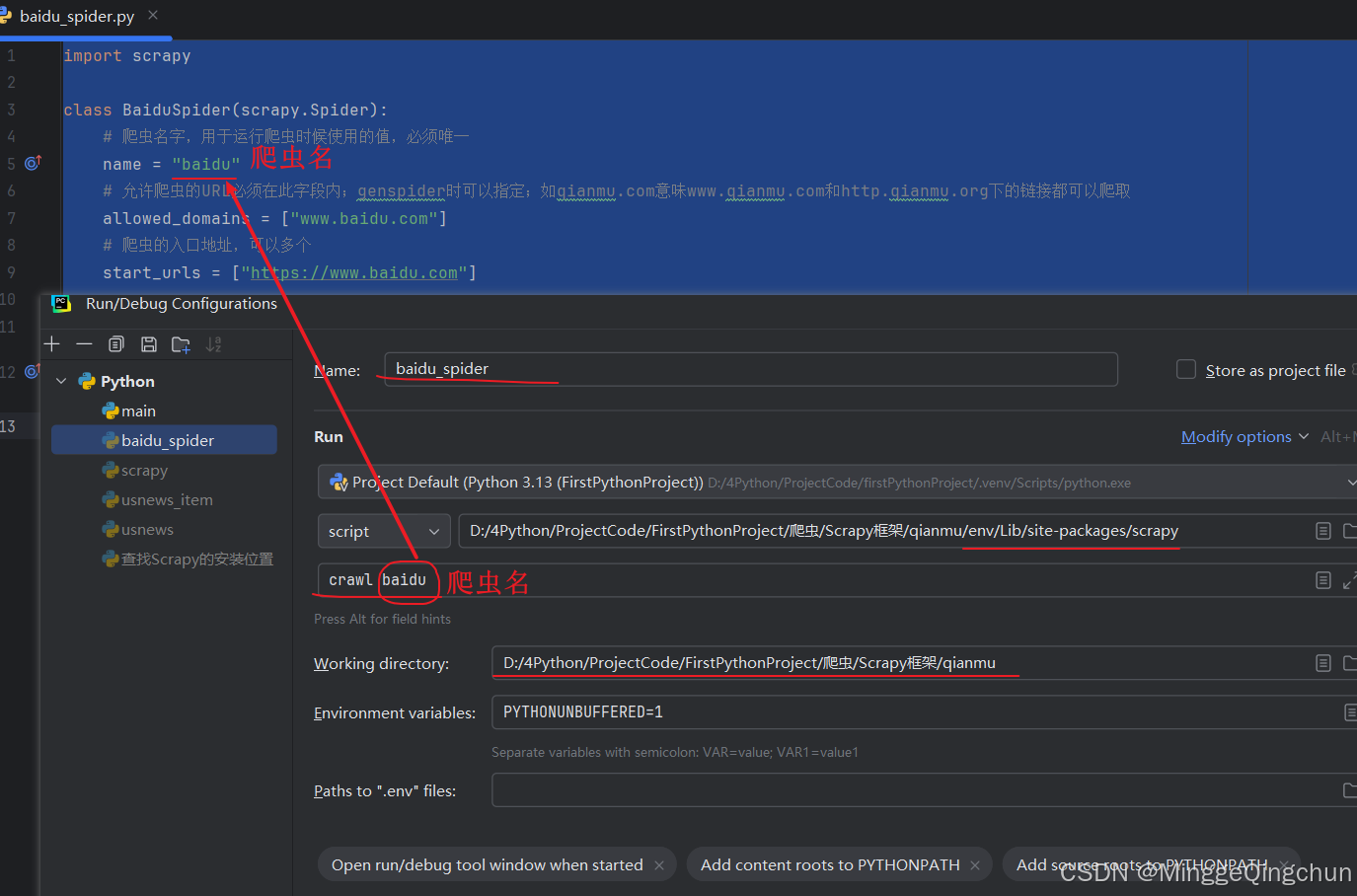
2、实现随机 IP 代理
1、在 Scrapy 项目的 middlewares.py 文件中自定义一个下载器中间件类
(1)简易版
import random
import base64
class RandomProxyMiddleware:
def __init__(self, proxies):
self.proxies = proxies
@classmethod
def from_crawler(cls, crawler):
# 从 settings.py 中获取 PROXIES 列表
return cls(
proxies=crawler.settings.get('PROXIES')
)
def process_request(self, request, spider):
# 随机选择一个代理
proxy = random.choice(self.proxies)
if '@' in proxy:
# 配置带账号密码的
credentials, proxy_url = proxy.split('@')
proto, credentials = credentials.split('//')
proto = proto + "//"
auth = base64.b64encode(credentials.encode('utf-8')).decode('utf-8')
request.headers['Proxy-Authorization'] = 'Basic ' + auth
request.meta['proxy'] = proto + proxy_url
else:
# 配置无账号密码的
request.meta['proxy'] = proxy(2)优化版
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
import base64
import random
from collections import defaultdict
from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
from scrapy.exceptions import NotConfigured
from urllib3 import request
# 自定义一个简单的动态IP代理
class RandomProxyIPSimpleMiddleware:
def __init__(self, proxies):
self.proxies = proxies
@classmethod
def from_crawler(cls, crawler):
# 从 settings.py 中获取 PROXIES 列表
return cls(
proxies=crawler.settings.get('PROXIES')
)
def process_request(self, request, spider):
# 随机选择一个代理
proxy = random.choice(self.proxies)
if '@' in proxy:
# 配置带账号密码的
credentials, proxy_url = proxy.split('@')
proto, credentials = credentials.split('//')
proto = proto + "//"
auth = base64.b64encode(credentials.encode('utf-8')).decode('utf-8')
request.headers['Proxy-Authorization'] = 'Basic ' + auth
request.meta['proxy'] = proto + proxy_url
else:
# 配置无账号密码的
request.meta['proxy'] = proxy
# 自定义一个动态IP代理
class RandomProxyIPMiddleware(object):
def __init__(self, settings):
# 2、初始化配置以及相关变量
self.proxies = settings.getlist('PROXIES')
self.status = defaultdict(int)
self.max_failed = 3
@classmethod
def from_crawler(cls, crawler):
# 1、创建中间件对象
# 是否开启HTTPPROXY_ENABLED开关,默认开启
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#std-setting-HTTPPROXY_ENABLED
if not crawler.settings.getbool('HTTPPROXY_ENABLED'):
raise NotConfigured
return cls(crawler.settings)
def process_request(self, request, spider):
# 3、为每个Request对象分配一个随机IP代理
if not request.meta.get('proxy') and request.url not in spider.start_urls:
request.meta['proxy'] = random.choice(self.proxies)
def process_response(self, request, response, spider):
# 4、请求成功则调用process_response
cur_proxy = request.meta.get('proxy')
# 是否被对方封禁
if response.status in (401, 403):
# 给相应失败IP次数+1
self.status[cur_proxy] += 1
print(f'{cur_proxy}代理被对方封禁,失败次数:{self.status[cur_proxy]}')
# 当某个IP失败次数累计到一定数量
if self.status[cur_proxy] >= self.max_failed:
print(f'{cur_proxy}代理连获取错误响应码{response.status}')
# 认为该IP被对方封禁了,从代理池中将该IP删除
self.remove_proxy(cur_proxy)
del request.meta['proxy']
# 将该请求重新安排下载调度
return request
return response
def process_exception(self, request, exception, spider):
# 4、请求失败则调用process_exception
cur_proxy = request.meta.get('proxy')
# 如果本次请求使用了代理,则认为该IP被对方封禁了,从代理池中将该IP删除
if cur_proxy and isinstance(exception, (ConnectionRefusedError, TimeoutError)):
print(f'{cur_proxy}代理获取错误:{exception}')
self.remove_proxy(cur_proxy)
del request.meta['proxy']
return request
def remove_proxy(self, proxy):
if proxy in self.proxies:
self.proxies.remove(proxy)
print(f'{proxy}代理被对方封禁,从代理池中删除')
2、在 Scrapy 项目的 settings.py 文件中配置中间件,并提供一个代理列表。
# 关闭 robots.txt 检查
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# 最大并发请求数
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 8 # 32
# 设置下载中间件超时时间
DOWNLOAD_TIMEOUT = 10
# 开启下载器中间件
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
"qianmu.middlewares.RandomProxyIPMiddleware": 540,
"qianmu.middlewares.RandomUserAgentMiddleware": 542,
"qianmu.middlewares.QianmuDownloaderMiddleware": 543,
}
# 定义代理列表,代理太多可以存在数据库中
PROXIES = [
# 无密码的写法
'http://172.16.xxx.xxx:8888',
# 带账号密码的写法,代理ip需要在服务商处进行购买
'http://user:pass@172.18.xxx.xxx:1688',
]
参考文章

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)