千万级数据查询优化:查询分离+ES实战避坑指南
一、业务场景:何时需要查询分离?
1、、适用场景分析
✅ 数据查询缓慢:单表数据量超千万,复杂联表查询耗时增长
✅ 写操作相对频繁:写入压力尚可接受,但读取压力巨大
✅ 数据需要频繁更新:所有数据都可能被修改(区别于冷热分离)
2、架构对比:查询分离 vs 传统架构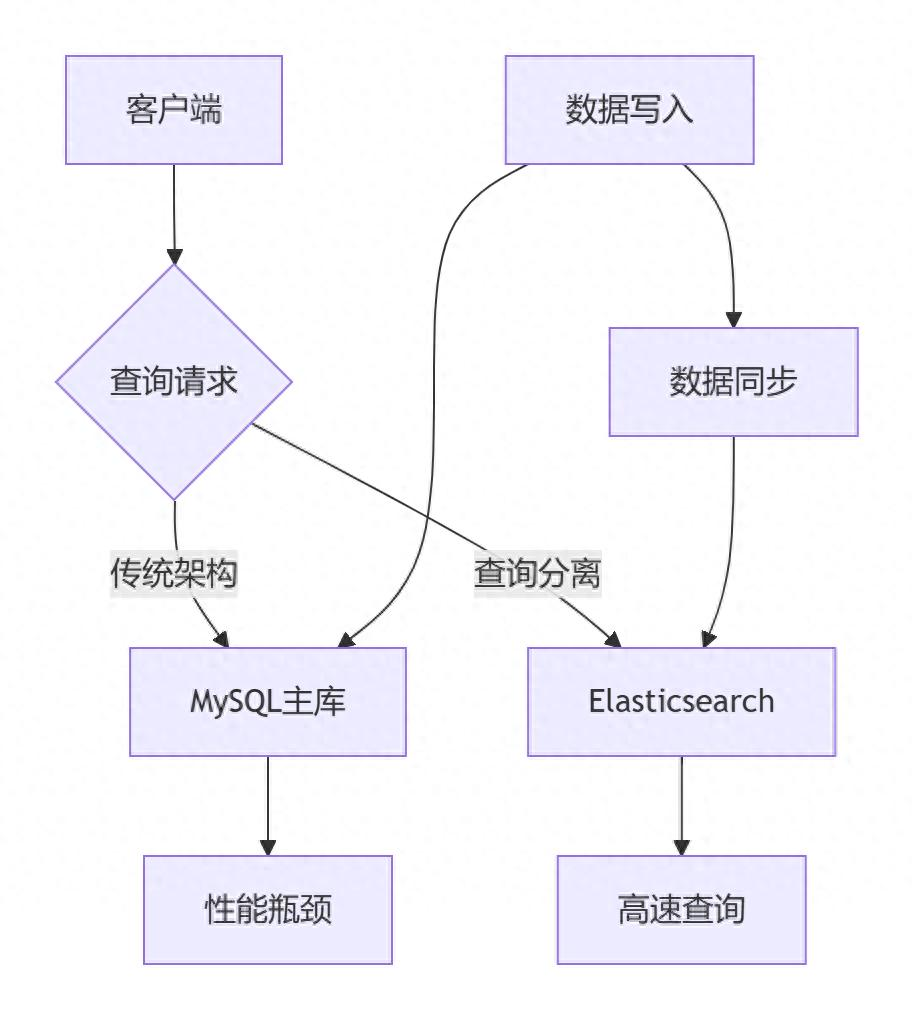
二、 查询分离核心实现方案
三种同步方案对比
1、推荐方案:MQ异步处理
架构流程图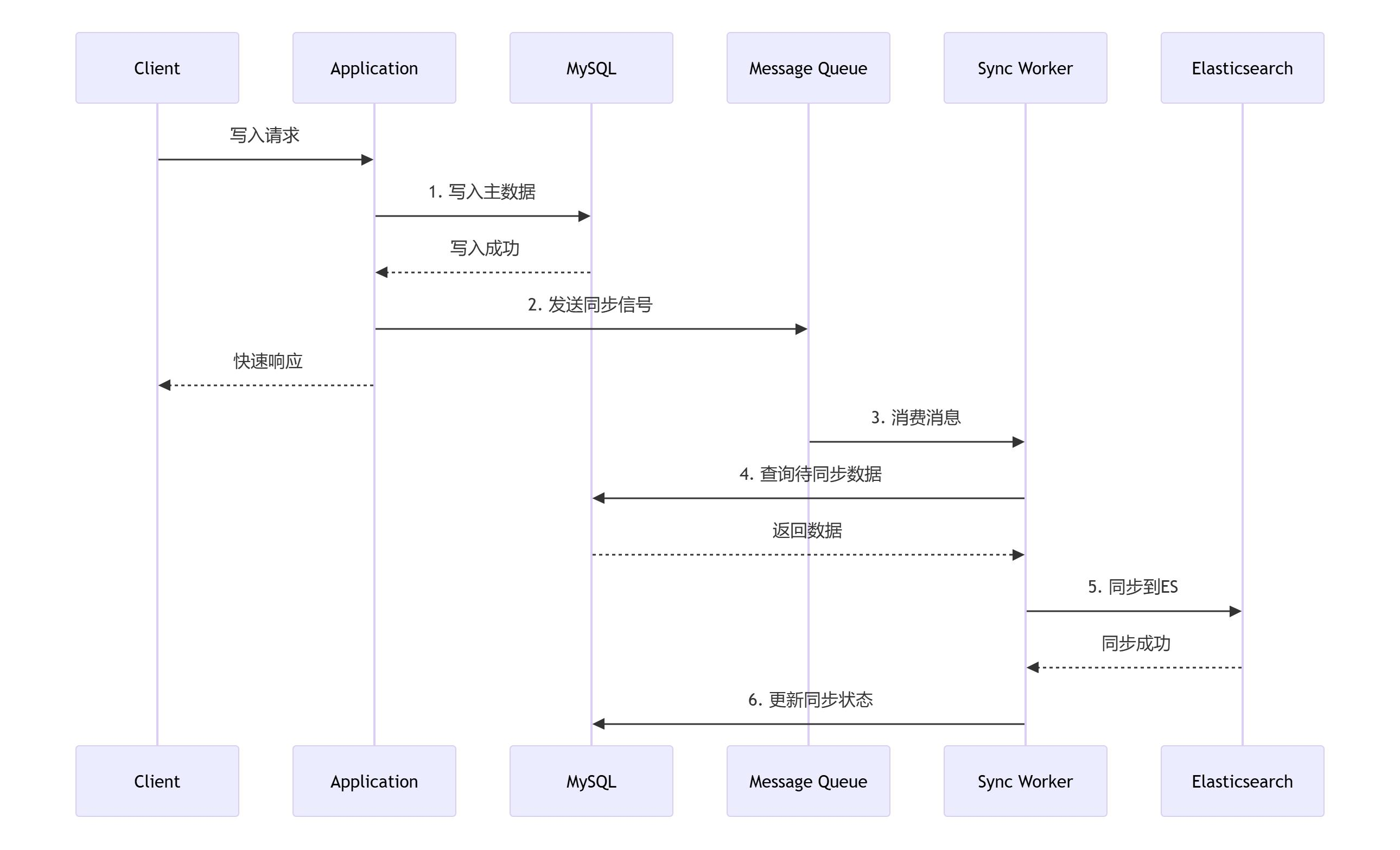
2、核心代码实现
a、数据写入服务(DataWriteService.java)
Service
@Slf4j
public class DataWriteService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private RocketMQTemplate rocketMQTemplate;
public void createOrder(OrderDTO orderDTO) {
// 1. 写入MySQL主库
Order order = convertToOrder(orderDTO);
order.setNeedSyncEs(true); // 标记需要同步
order.setLastUpdateTime(LocalDateTime.now());
orderMapper.insert(order);
// 2. 发送MQ消息(仅发送ID,不包含完整数据)
rocketMQTemplate.convertAndSend("ORDER_SYNC_TOPIC",
OrderSyncMessage.builder()
.orderId(order.getId())
.operationTime(LocalDateTime.now())
.build());
log.info("订单创建成功,已发送同步消息,订单ID: {}", order.getId());
}
}
@Data
@Builder
class OrderSyncMessage {
private Long orderId;
private LocalDateTime operationTime;
}
b、数据同步消费者(DataSyncConsumer.java)
2. 数据同步消费者(DataSyncConsumer.java)
@Component
@Slf4j
public class DataSyncConsumer {
@Autowired
private OrderMapper orderMapper;
@Autowired
private OrderESRepository orderESRepository;
@RocketMQMessageListener(
topic = "ORDER_SYNC_TOPIC",
consumerGroup = "order-sync-consumer"
)
public void syncOrderData(OrderSyncMessage message) {
try {
// 批量查询需要同步的订单(避免消息重复消费问题)
List<Order> pendingOrders = orderMapper.selectPendingSyncOrders(
Collections.singletonList(message.getOrderId()));
if (!pendingOrders.isEmpty()) {
// 转换为ES文档格式
List<OrderESDocument> esDocuments = convertToESDocuments(pendingOrders);
// 批量同步到ES
orderESRepository.bulkSave(esDocuments);
// 更新同步状态(乐观锁控制)
orderMapper.batchUpdateSyncStatus(pendingOrders, false);
log.info("成功同步 {} 个订单到ES", pendingOrders.size());
}
} catch (Exception e) {
log.error("订单数据同步失败, orderId: {}", message.getOrderId(), e);
throw new RuntimeException("同步失败,触发重试", e);
}
}
}
3、Elasticsearch实战详解
a、数据模型设计:宽表模式
MySQL关系模型 vs ES文档模型
// MySQL中的多表关联(需要JOIN查询)
orders表:id, user_id, total_amount, status
users表:id, username, phone
order_items表:id, order_id, product_name, price, quantity
// ES文档模型(宽表,无需JOIN)
{
"orderId": "202410290001",
"totalAmount": 299.00,
"status": "COMPLETED",
"user": {
"userId": 1001,
"username": "张三",
"phone": "13800138000"
},
"orderItems": [
{
"productName": "iPhone 15",
"price": 5999.00,
"quantity": 1
},
{
"productName": "AirPods",
"price": 1299.00,
"quantity": 1
}
],
"createTime": "2024-10-29T10:30:00"
}
b、ES索引映射配置
/ orders索引映射配置
PUT /orders
{
"mappings": {
"properties": {
"orderId": { "type": "keyword" },
"totalAmount": { "type": "double" },
"status": { "type": "keyword" },
"createTime": { "type": "date" },
"user": {
"properties": {
"userId": { "type": "long" },
"username": {
"type": "text",
"fields": { "keyword": { "type": "keyword" } }
},
"phone": { "type": "keyword" }
}
},
"orderItems": {
"type": "nested",
"properties": {
"productName": { "type": "text" },
"price": { "type": "double" },
"quantity": { "type": "integer" }
}
}
}
},
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"refresh_interval": "1s"
}
}
c、复杂查询示例
多条件组合查询
// 查询用户"张三"在2024年10月完成的、金额大于100元的手机订单
SearchRequest searchRequest = new SearchRequest("orders");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("user.username.keyword", "张三"))
.must(QueryBuilders.termQuery("status.keyword", "COMPLETED"))
.must(QueryBuilders.rangeQuery("totalAmount").gte(100))
.must(QueryBuilders.wildcardQuery("orderItems.productName", "*手机*"))
.must(QueryBuilders.rangeQuery("createTime")
.gte("2024-10-01")
.lte("2024-10-31"));
sourceBuilder.query(boolQuery);
sourceBuilder.from(0);
sourceBuilder.size(10);
sourceBuilder.sort("createTime", SortOrder.DESC);
searchRequest.source(sourceBuilder);
SearchResponse response = elasticsearchClient.search(searchRequest, RequestOptions.DEFAULT);
4、关键陷阱与解决方案
a、数据一致性保障
读写分离的数据状态提示
4. 关键陷阱与解决方案
4.1 数据一致性保障
读写分离的数据状态提示
@Service
public class OrderQueryService {
public OrderDetailDTO getOrderDetail(Long orderId) {
// 1. 先查ES(快速路径)
Optional<OrderESDocument> esOrder = orderESRepository.findById(orderId);
if (esOrder.isPresent()) {
OrderDetailDTO result = convertToDTO(esOrder.get());
// 添加数据状态提示
result.setDataStatus("实时数据");
return result;
}
// 2. ES查不到或需要强一致性时查MySQL
Order order = orderMapper.selectById(orderId);
OrderDetailDTO result = convertToDTO(order);
result.setDataStatus("实时数据(主库直接查询)");
return result;
}
}
b、深度分页优化
使用search_after替代from/size
// 错误的深度分页方式(性能差)
SearchRequest badRequest = new SearchRequest("orders");
SearchSourceBuilder badSource = new SearchSourceBuilder();
badSource.from(10000); // 深度分页,性能急剧下降
badSource.size(10);
// 正确的search_after方式
SearchRequest goodRequest = new SearchRequest("orders");
SearchSourceBuilder goodSource = new SearchSourceBuilder();
goodSource.size(10);
// 使用上一页最后一条记录的排序值
Object[] searchAfter = new Object[]{1698562800000L, "202410280001"};
goodSource.searchAfter(searchAfter);
goodSource.sort("createTime", SortOrder.ASC);
goodSource.sort("orderId", SortOrder.ASC);
5、完整实施方案 checklist
a、上线前检查清单
- ES索引映射设计和性能测试
- MQ消息积压监控和告警配置
- 数据同步延迟监控(设置阈值告警) 同
- 步失败重试机制和死信队列处理
- 历史数据迁移方案和验证
b、性能监控指标
// 关键监控指标示例
@Component
public class SyncMetrics {
// 同步延迟监控
@Autowired
private MeterRegistry meterRegistry;
public void recordSyncDelay(LocalDateTime createTime) {
Duration delay = Duration.between(createTime, LocalDateTime.now());
meterRegistry.timer("es.sync.delay").record(delay);
}
public void recordSyncSuccess() {
meterRegistry.counter("es.sync.success").increment();
}
public void recordSyncFailure() {
meterRegistry.counter("es.sync.failure").increment();
}
}
总结
查询分离架构是解决大数据量查询性能问题的有效方案,但需要综合考虑数据一致性、系统复杂度和运维成本。通过合理的架构设计 + Elasticsearch的深度优化,可以构建出支撑千万级数据的高性能查询系统

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)