AI Agent开发全攻略:从零基础入门到精通,这一篇就够了!
狭义上的Agent:完全无人监督、自主拆解目标、寻找资源、使用工具,完成全部工作的系统广义上的Agent:指以 LLM(大语言模型)为核心驱动,具备基础任务响应与外部交互能力的系统市面上百分之99的Agent应用,其实只属于广义-简单Agent的范畴一个真正完整且智能的智能Agent系统,以下五个能力缺一不可Planning:自行对任务进行详细拆解,完成执行方案规划Action:根据方案,按流程一
文章系统介绍了AI Agent开发的全流程,包括Agent定义、五大核心能力(规划、执行、观察、工具调用、学习)、开发三阶段(架构选择、功能实现、工程优化)及具体实现方法。重点阐述了最小上下文原则、ReAct工作模式、上下文工程和提示词工程等关键技术,并提供了工程优化策略。文章强调真正的Agent需要超越简单API调用,具备完整智能系统特征,是未来AI应用的重要发展方向。
不是写一个 Prompt,调用 Api,加上几个函数处理,就叫“Agent 应用”
Agent is all you need我想抛出一个“暴论”:沉淀足够深的“领域专家”,配合“Ai应用工程师”,进行Agent开发,能够自动化一切该领域人能完成的开发工作
一、什么是Agent
狭义上的Agent:完全无人监督、自主拆解目标、寻找资源、使用工具,完成全部工作的系统广义上的Agent:指以 LLM(大语言模型)为核心驱动,具备基础任务响应与外部交互能力的系统市面上百分之99的Agent应用,其实只属于广义-简单Agent的范畴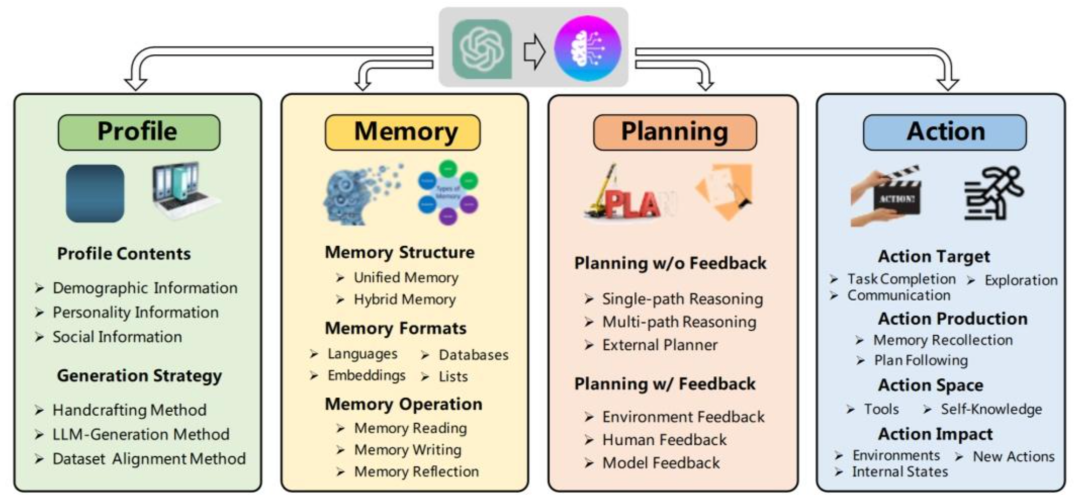
一个真正完整且智能的智能Agent系统,以下五个能力缺一不可
- Planning:自行对任务进行详细拆解,完成执行方案规划
- Action:根据方案,按流程一步步执行
- Observation:在Action过程中,应当能动态感知环境反应,动态调整规划
- Tool_call:具备精准调用外部工具来解决任务的能力
- Learning:能自主学习好坏case、外部新知识、新工具,不断进化
在目前的Ai Coding领域:
- 目前图形化的cursor和命令行claude-code,在前4个能力上已做的相当完备
- 但是最后一个——Agent的自主学习能力,尚任重道远
- 它要求Agent能自动学习新知识、调用新工具、学习交互的good case、bad case转化为经验
二、怎么做出一个Agent
广义上的功能性Agent开发流程大体上可以分为三个阶段****架构选择、功能实现、工程优化
- 架构选择阶段:根据业务特点、QPS、准确率、稳定性等需求选择合适的编程语言/工作流平台、后端服务架构
- 功能实现阶段:实现业务的Agent解决方案
- 工程优化阶段:
- 准确率优化
- 效率优化
- 成本问题
这里我想重点讨论功能实现和工程优化;怎么才能做好这两个阶段呢?
2.1功能实现阶段
2.1.1How?Why?
如何让Agent能够完美地完成任务?
多项研究表明——因为Transformer架构固有局限,随上下文逐步增长,LLM注意力逐渐分散,回归能力逐渐下降大模型的生成过程本质是预测,会根据用户给出的信息,逐渐去“预测”最优质的回答大模型接收到的上下文,本质上就是一种信息,用于消除预测过程中的不确定性,降低其信息熵
我认为,在Agent开发过程中**,完美遵守下面两个原则,就可以——开发出一个可用、高效的Agent**
- 最小上下文原则:每次交互中,给大模型的上下文尽可能小
- 最低信息熵原则:需要清晰、精确、完整地表述需要大模型完成的任务
因此:和大模型交互,其实就是一种语言的艺术——最少的词语,完成最完整意图的表述
2.1.2How to do?
应该怎么做才能完美遵守上面的原则呢?
-
工具调用:正确指导LLM在合适的时候用对应的工具,而不是给多个工具让它选择
-
上下文管理
-
只给主agent最重要的关键信息,sub agent去filter其他信息
-
不重要的信息/当下用不到的历史信息,不代入上下文
-
使用外部存储技术,存储在文件/数据库/临时变量中;在需要时再做回归
-
非必要,不Ai:固定的流程使用固定函数完成,不要为了用Agent而用
-
在需要LLM动态执行的模块,一定要给出最精致的prompt——最准确的上下文信息
2.2工程优化阶段
功能完整后,如何让Agent在线上环境稳定、高效、低成本地运行?
- 准确率/稳定性优化:整个工作流必须以高准确率完成用户的需求
- 效率优化:步骤合并、任务并行
- 成本问题:更小的模型、更小的上下文窗口、蒸馏后的模型
2.2.1准确率/稳定性优化
大模型每次输出都不稳定,Agent的多次调用,会导致结果更加不稳定可以用一个不太严谨的计算方式来理解假设单轮回答符合对的期望是0.8,那经过10次迭代,0.8^10,正确回答的期望就是0.1074
实用技巧——完成Agent输出的超高准确率
-
任务拆解:将复杂任务拆分别更细粒度子步骤,减少单步误差累计
-
多轮校验机制:关键的中间结果增加校验,无效则重新规划&生成
-
异常兜底策略:预设每一个节点的故障处理方案
-
工具超时、接口报错、多轮准确率不达标等问题;都要建立流程上的兜底或信息上的兜底
-
定制化微调:总结Agent历史调用链中的good case,合并为数据集,进行微调
2.2.2效率优化
- 步骤合并与剪枝:剔除冗余步骤,简化非必要流程;固定步骤函数化
- 任务并行处理:支持多工具/子任务同时执行
- 预处理缓存:缓存高频复用数据(避免重复请求、计算)
- 模型优化:使用更小参数的模型
- 响应优先级调度:高实时性任务实时调用,近线任务采用离线推理
2.2.3成本优化
-
模型优化:
-
轻量化:在能完成任务的前提下,尽量选小参数模型(我实践中:小参模型迭代多次,效果一般好过大参模型一次生成)
-
模型蒸馏:对模型微调后再蒸馏
-
上下文窗口压缩:通过摘要、关键词提取、文本精简、无关信息filter等
-
资源动态调度:非高峰时段减少算力节点,高峰时段动态扩容
2.3如何让agent乖乖听话
一个Agent其实是由多个小模块组成的,其实Agent的开发过程和“搭积木”很像在搭积木过程中,需要不断地回过头去检查当下的结果——是否多用了零件、桌子有没有少一个腿、房间会不会太小了那么,想用积木搭好一个城堡,我们应该怎么做呢?
- 建筑图纸:整个城堡应该有多少层、多少个房间、最终是什么样子、什么设计风格
- 完成小模块:先拼接好书桌、床、电视机等一个又一个小模块
- 模块协同:将一个又一个小模块“协同”起来,成为一个大城堡
完成整个城堡的过程其实和Agent常用也是最有效的工作模式ReAct几乎一摸一样:Reasoning、Action、ObservationReAct 模式的核心是通过 “推理 - 行动 - 感知” 的闭环循环,让 Agent 具备处理复杂任务的能力其设计逻辑可拆解为三个核心环节及闭环机制:
- Reasoning(推理):Agent 会先解析用户需求,拆解目标为可执行的步骤,并判断当前是否需要调用工具。
- Action(行动):按推理阶段的规划执行具体操作,包括直接生成内容或调用外部工具
- Observation(观察):接收并解析行动阶段的输出(如工具返回结果、错误信息),判断是否符合预期
- 若数据完整,则将结果反馈给推理环节,进入下一轮规划;若出现异常,则触发推理环节重新决策
还有其他很多设计模式,但是其实核心思想都类似,这里不再展开:Cot、AutoGPT…
三、最近很火的上下文工程是啥
上下文工程来源
- 对经典的文本这单一模态而言,使用llm的唯一方式是一次性的一问一答
- 为了提出更好的问题引导更好的回答,发展出了提示词工程
- 为了多轮对话、多模态支持、信息更全面、与环境交互,在提示词工程上发展出来上下文工程
研究表明:当关键信息位于文本中段时,召回率下降40%以上LLM 的本质是概率预测模型,若输入的冗余信息过多,必然会干扰其对核心逻辑的判断,导致精准度与召回率下降。我在 Agent 应用开发实践中对此深有体会:每次与 LLM 交互时,传递的信息必须经过筛选,只保留 “足够必要” 的内容因此,Agent 开发其实就是在进行上下文工程 —— 在 LLM 需要输出的每个阶段,精准供给它完成任务所需的关键信息;无论是 tool_call 的返回结果、用户的原始输入,还是环境变量,本质上都是需纳入考量的上下文,并无主次之分,唯有全面且精简地整合,才能让 LLM 高效输出
- 上下文工程的本质:就是模型输入整理
- 无论是:user_prompt、system_prompt、tool_call_para、tool_call_result、env_state都是chat_history
- 在每个需要交互的节点,应当从chat_history中拿出哪些内容,经过拼接、优化、整理后
- 给到模型,就是上下文工程要做的工作
四、如何用好提示词
OpenAI 提到 6 条大的原则:
1.Write clear instructions(写出清晰的指令)
2.Provide reference text(提供参考文本)
3.Split complex tasks into simpler subtasks(将复杂的任务拆分为更简单的子任务)
4.Give the model time to “think”(给模型时间「思考」)
5.Use external tools(使用外部工具)
6.Test changes systematically(系统地测试变更)
4.1先激活再思考
先通过精准提问,让对应领域上下文信息,加入LLM的chat_history,再提出问题样例1
q:请你告诉我什么是shiro550漏洞,一般攻击者怎么利用它a:这漏洞是因为低版本shiro框架中..q:我测试一个靶机,存在shiro550漏洞,你帮我看看,我这个请求包为什么没有work,请求包如下:..
样例2
q:请你帮我总结/my_path/to_test_file/test.py文件中的代码逻辑a:这是一个爬虫的工具类,它通过..q:请你帮我修改代码,增强他的反爬绕过能力
4.2结构化提示词
类似XML格式
<instruction>你希望 Claude 执行的主要任务或目标</instruction><context>任务的背景信息,比如涉及的框架、业务逻辑、团队规范等</context><code_example>可以参考的代码片段、接口规范或已有实现</code_example>
JSON格式提示词样例
{ "task": "generate_product_review","parameters": { "product_type": "智能手机", "product_name": "XPhone Pro", "key_features": ["6.7英寸OLED屏幕", "5000mAh电池", "1亿像素摄像头", "骁龙8 Gen3处理器"], "review_perspective": ["性能体验", "续航能力", "拍照效果", "性价比"], "tone": "客观中立,略带专业分析", "word_count": "500-800", "structure": { "include_introduction": true, "include_feature_analysis": true, "include_pros_cons": true, "include_conclusion": true }, "requirements": [ "避免使用夸张修辞", "针对每个核心功能给出具体评价", "对比同价位机型的优势与不足", "数据支撑评价(如续航具体时长、跑分数据等)", "提及目标用户群体适配性", "分析系统优化对硬件性能的影响" ] }}
4.3提示词工程
-
few shot (少样本学习)
-
人工给出几个示例激活模型在特定任务的思考模式
-
Chain of thought(思维链COT)
-
概念:通过中间推理步骤——实现复杂推理能力
-
因为大模型本质是预测下一个词出现的概率,通过中间步骤引导,增加向正确方向预测的概率
-
Few-Shot + Cot:少样本学习配合思维链
-
Zero-Shot-Cot:在样本结尾加入引导逐步思考的Prompt
-
eg:买了10个苹果,给了邻居2个苹果和修理工2个苹果,又买了5个苹果吃了1个,还剩下多少苹果?让我们逐步思考
-
Auto-Cot:对用户问题聚类后,抽样出每类中心问题,使用简单启发式Zero-Shot-Cot生成推理链
-
准备步骤:问题聚类、抽样、用简单启发式Zero-Shot-Cot生成推理链
-
回答步骤:问题分类、回归该类问题的cot_prompt、合并user_prompt和cot_prompt、llm.invoke(merge_prompt)
-
自我一致性:
-
概念:通过少样本思维链,采样多个不同推理路径、用多个推理结果进行多轮投票
-
角色扮演
-
ReACT
-
…
五、Api调用Tips
- 通过动态步长温度、随机数种子,增加多轮投票中的随机性&强制不使用缓存
- 模型回复被截断,并不是上下文不够,很多模型有默认输出 token限制,需要设置 maxtokens参数
- 在逻辑性强的任务里,用 json 格式的提示词效果很好
- few-shot 在标准化输出任务中表现很好
- 根据不同任务特性调节温度
- 有时模型怎么都不能满足好一个需求,可能是这个模型能力不够 or 模型不适合这个任务
- 动态化提示词.format/.replace
- 做提示词版本管理很重要
六、最后聊两句
最后,我想抛出一个观点:在当下LLM既没有想象中那么强,归根结底,他只是一个工具,使用者水平决定了他的能力边际LLM更没有我们想的那么菜,我们可以完全相信算法工程师迭代基座模型的速度和大模型应用工程师的工程能力但是我对ai的发展十分有信心,在可预见的将来,他能够替代掉绝大部分的编码工作Agent is all you need到时候作为工程师的技术护城河,我想除了足够深刻的垂类领域知识,就是超越常人的LLM工具驾驭能力
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献128条内容
已为社区贡献128条内容

所有评论(0)