批量网页信息抓取+Deepseek模型完成信息匹配
DeepSeek-V3 正式发布deepseek模型的具体内容可以去了解一下。国产开源,便宜,这对国内用户很友好。当然,国内其他AI工具也不错,个人推荐而已,这里并没有拉踩的意思(勿喷,理解)。
批量网页信息抓取+Deepseek模型完成信息匹配
0 使用前说明
~
需要有一些python知识
需要有一些网页结构知识
需要对大模型有一些了解(比如Chat-GPT,就是对话问答,你问一个问题,它会给你一个答案,这个答案的准确性需要你们自己去验证)
首先说明一下我使用的软件版本(软件版本无所谓,用的时候大致匹配就行,减少出现问题的概率):
Anaconda3-2021.05-Windows-x86_64.exe 和 pycharm-community-2021.3.2.exe
注意:遵纪守法!
补:如果需要的信息在PDF和图片中,其实也是可以提取的,但是需用到用python进行PDF文字提取和OCR文字识别,将其转换为文本信息(功能实现不麻烦稍微写一下就行),然后再用AI模型进行信息匹配就行。你要是用其他AI模型对PDF和图片直接进行信息提取和匹配也行,效果都是一样的。网页信息提取不出来的,这里没有解决方法。
————————————————
1 DeepSeek-V3模型
可以通过多个渠道了解这个模型
模型介绍
首先是微信公众号的推送:DeepSeek-V3 正式发布
其次,你可以在GitHub上了解其模型:deepseek
还有其文章:DeepSeek-V3 Technical Report
模型的具体内容可以去了解一下。
选择DeepSeek的原因: 国产,开源,便宜,这对国内用户很友好。当然,国内其他AI工具也不错,个人推荐而已,这里并没有拉踩的意思(勿喷,理解)。
模型使用
这里web对话窗口就不介绍了,大家自己去尝试就行。
需要说明的是这个API接口:API接口
里面的信息可以看一下,有说明文档,价格说明。我使用的时候(2025-01-15)送了10元,所以没充钱,后续希望开发团队保持(谢谢)!!!
进入API平台之后可以创建一个 API key ,参考下面的步骤:
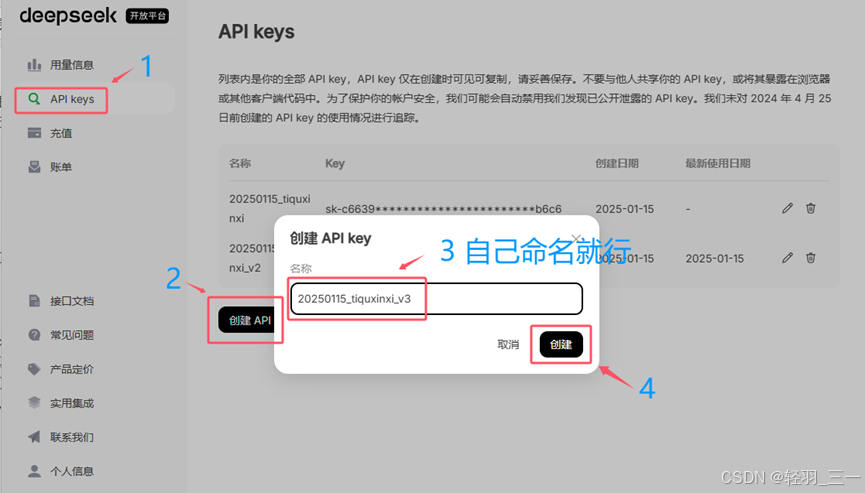
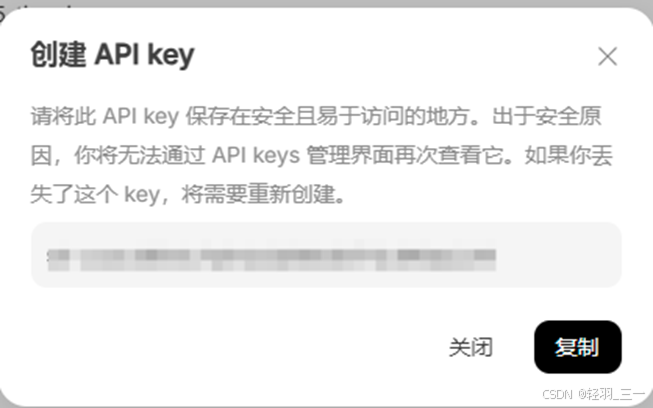
后面可以得到一个 key,下面打码的地方,复制好之后做好保存,后续需要用到。
2 python项目
接下来需要用到python来编写代码了。
创建虚拟环境
建议重新创建一个虚拟环境,避免和你前面做的项目所用的库造成冲突。(我使用的python版本是3.9,其他版本没试过,可以自己尝试一下)
要是不会创建虚拟环境,可以找一下其他教程,有很多。实在不行可以参考我上一个博客 ~~。
安装相应库
安装相应的库,最好用一下镜像源(用自己习惯的就好)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple openai
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple bs4
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple re
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lxml
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
如果你是初学者,不懂在哪里进行库的安装,可以直接在你创建的项目下面找到这个终端(Terminal),然后逐行输入上面的 pip 代码就行,正常来说,你前面创建虚拟环境时,如果是指定python版本的话,这里的安装的库会对应python版本的,如果报错的话,自己找一下原因并解决一下吧。

代码示例
这里简单放一个代码,你们可以根据自己的需求进行修改,后面我结合网页结构做一下说明。(这个代码是批量进行处理的)
#!/usr/bin/python
# -*- coding: utf-8 -*-
from openai import OpenAI
# 创建 API 客户端
client = OpenAI(api_key="###", base_url="https://api.deepseek.com") # api_key="###" 中把 ### 改为自己的key
import requests
from bs4 import BeautifulSoup
import re
from lxml import etree
import pandas as pd
def comein_url(url):
# 设置请求头,模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
}
# 请求网页
response = requests.get(url, headers=headers)
# 设置编码为 'utf-8'(如果网页使用的是这种编码)
response.encoding = 'utf-8'
return response
# 定义一个函数来提取信息
def extract_info(text):
info = {}
lines = text.split("\n")
for line in lines:
if "**" in line:
key = line.split("**")[1].strip()
value = line.split(":")[-1].strip() if ":" in line else line.split(":")[-1].strip()
info[key] = value
return info
# 定义一个函数来标准化数据
def standardize_data(info):
standardized = {
"学校": info.get("学校", "未提供"),
"院系": info.get("院系", "未提供"),
"姓名": info.get("姓名", "未提供"),
"性别": info.get("性别", "未提供"),
"职称": info.get("职称", "未提供"),
"籍贯": info.get("籍贯", "未提供"),
"博士毕业院校": info.get("博士毕业院校", "未提供"),
"博士毕业年份": info.get("博士毕业年份", "未提供"),
}
return standardized
def remove_special_characters(text):
# 保留字母、数字、中文和空格
return re.sub(r'[^\w\s]', '', text)
def reback_answer(tiwen):
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": tiwen},
],
stream=False
)
text = response.choices[0].message.content
return text
# 如果不清楚过程变量的内容,可以print一下,看看是不是准确
# 需要看学院的网页确定结构,然后修改相应代码
url_v1 = 'https://ems.xju.edu.cn/szll.htm' # 这里需要改
response_v1 = comein_url(url_v1)
if response_v1.status_code == 200:
print("请求成功")
page_v1_text = response_v1.text
#数据解析
tree_v1 = etree.HTML(page_v1_text)
tree_v1_ul_list = tree_v1.xpath('//div[@class="sidebar fl"]//ul') # 这里需要修改
tree_v1_a_list = tree_v1.xpath('//div[@class="sidebar fl"]//ul/li/a') # 这里需要修改
data_list = []
for tree_v1_a in tree_v1_a_list:
# 第一层,寻找教授/副教授
tree_v1_a_text_content = tree_v1_a.xpath('./text()')[0] # 这里需要修改
tree_v1_a_href_value = tree_v1_a.xpath('@href')[0] # 获取 <a> 标签中的 href 属性值 # 这里需要修改
# print("text1:", tree_v1_a_text_content)
# 设置条件, 按需判断,需要将后面的内容(到else前面)全部选择,然后TAB一下
# if tree_v1_a_text_content == "副教授":
# # print("text1:", tree_v1_a_text_content)
###################################### 拼接网址
url_v1_pitch_v1 = url_v1.split('.htm')[0]
url_v2_pitch_v1 = tree_v1_a_href_value.split('/')[1]
url_v2 = url_v1_pitch_v1 + "/" + url_v2_pitch_v1
####################################### 从这里进入第二个界面
response_v2 = comein_url(url_v2)
page_v2_text = response_v2.text
tree_v2 = etree.HTML(page_v2_text)
# 确定页数
tree_v2_page_num_element = tree_v2.xpath('//span[@class="p_pages"]//span') # 这里需要修改
tree_v2_page_num = len(tree_v2_page_num_element) - 4 ## 排除 ”首页”。“上一页”,“下一页”,“尾页”,四项,所以减4 # 这里需要修改
for tree_v2_i in range(1,tree_v2_page_num+1):
# 看具体网页情况,以新疆大学经济与管理学院为例,是从1开始的,但是代码的1表示该网页的最后一页
url_v2_pitch_v2 = url_v2.split('.htm')[0]
url_v3 = url_v2_pitch_v2 + "/" + str(tree_v2_i) + ".htm"
if tree_v2_i == tree_v2_page_num:
url_v3 = url_v2
# print(url_v3)
###################################### 这里看网页的教师信息
response_v3 = comein_url(url_v3)
page_v3_text = response_v3.text
tree_v3 = etree.HTML(page_v3_text)
tree_v3_ul_list = tree_v1.xpath('//ul[@class="teach-list"]/li') # 这里需要修改
tree_v3_a_list = tree_v1.xpath('//ul[@class="teach-list"]/li/a') # 这里需要修改
for tree_v3_a in tree_v3_a_list:
###################################### 这里进入每个老师的界面
tree_v3_a_href_value = tree_v3_a.xpath('@href')[0] # 获取 <a> 标签中的 href 属性值 # 这里需要修改
# print("tree_v3_a_href_value:",tree_v3_a_href_value)
url_v3_pitch_v1 = url_v3.split('/szll')[0]
url_v4 = url_v3_pitch_v1 + "/" + tree_v3_a_href_value
###################################### 这里看教师的具体信息
response_v4 = comein_url(url_v4)
page_v4_text = response_v4.text
tree_v4 = etree.HTML(page_v4_text)
soup = BeautifulSoup(response_v4.text, 'html.parser')
soup_txt = soup.text
cleaned_text = re.sub(r'\n+', '\n', soup_txt)
# print("文本信息:", cleaned_text)
# 这里可以修改问题,比如,根据名字确定性别,如果不确定,在输出时可以进行说明
tiwenxinxi_v1 = "从下面的文本: /n "
tiwenxinxi_v2 = " /n 匹配需要的信息:学校、姓名、院系、性别、职称、籍贯、博士毕业院校、博士毕业年份)"
tiwenxinxi_total = tiwenxinxi_v1 + cleaned_text + tiwenxinxi_v2
# print("文本信息:", tiwenxinxi_total)
tiwen = remove_special_characters(tiwenxinxi_total)
answer = reback_answer(tiwen)
# 提取信息
info = extract_info(answer)
# 标准化数据
standardized_info = standardize_data(info)
# 将标准化后的数据添加到列表中
data_list.append(standardized_info)
# 将数据列表转换为DataFrame
df = pd.DataFrame(data_list)
# 按指定顺序排列列
columns_order = [
"学校", "院系", "姓名", "性别", "职称", "籍贯", "博士毕业院校", "博士毕业年份"
]
df = df[columns_order]
# 这里进行修改,修改文件输出路径和文件名
output_path = r"C:\Users\HP\Desktop\111" # 这里需要修改
output_name = "信息表.csv" # 这里需要修改
output_file = output_path + "\\" + output_name
# 保存到CSV文件
df.to_csv(output_file, index=False, encoding="utf-8-sig")
print("标准化信息已保存到 '标准化信息表.csv'")
else:
print(f"请求失败,状态码:{response_v1.status_code}")
3 网页结构
了解网页
这里只是举个例子哈,并没有借此做一下乱七八糟的事情。
以某学校某学院的教师信息为例:
下面是学校教师的网页:
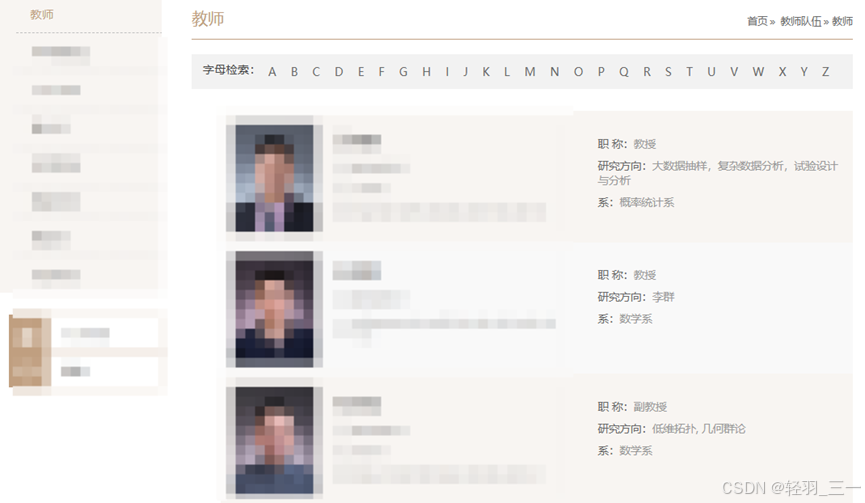
查看网页结构,这一步的目标就是:找到每一个教授具体的网址url:
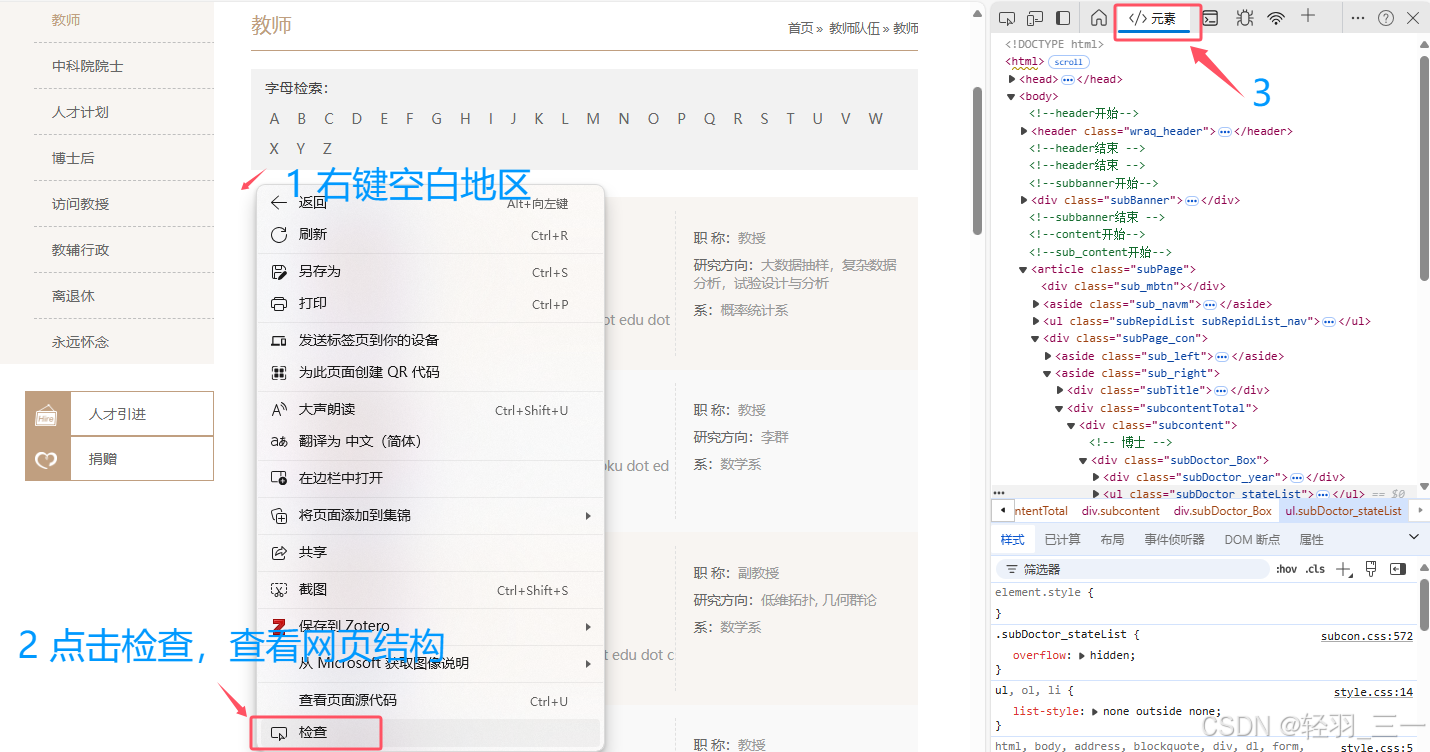
了解网页排版结构,得到相应的信息:
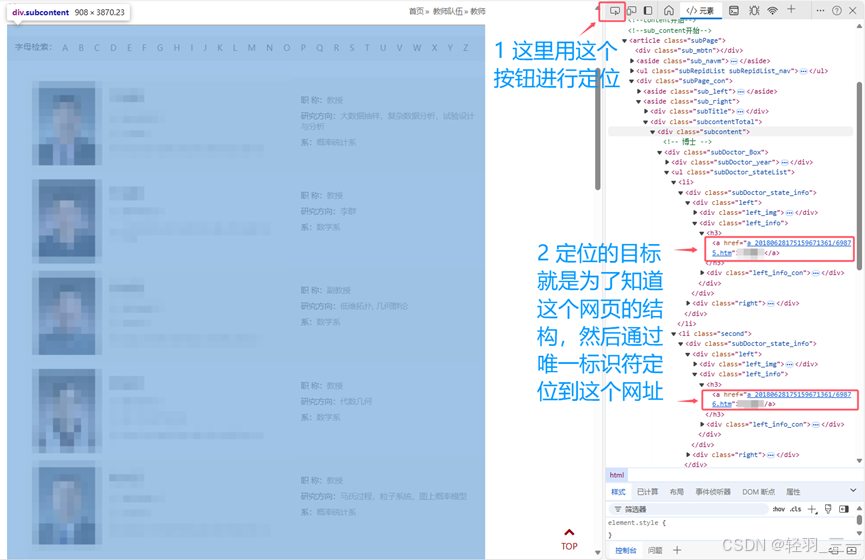
换个其他的网页:类似的目的。
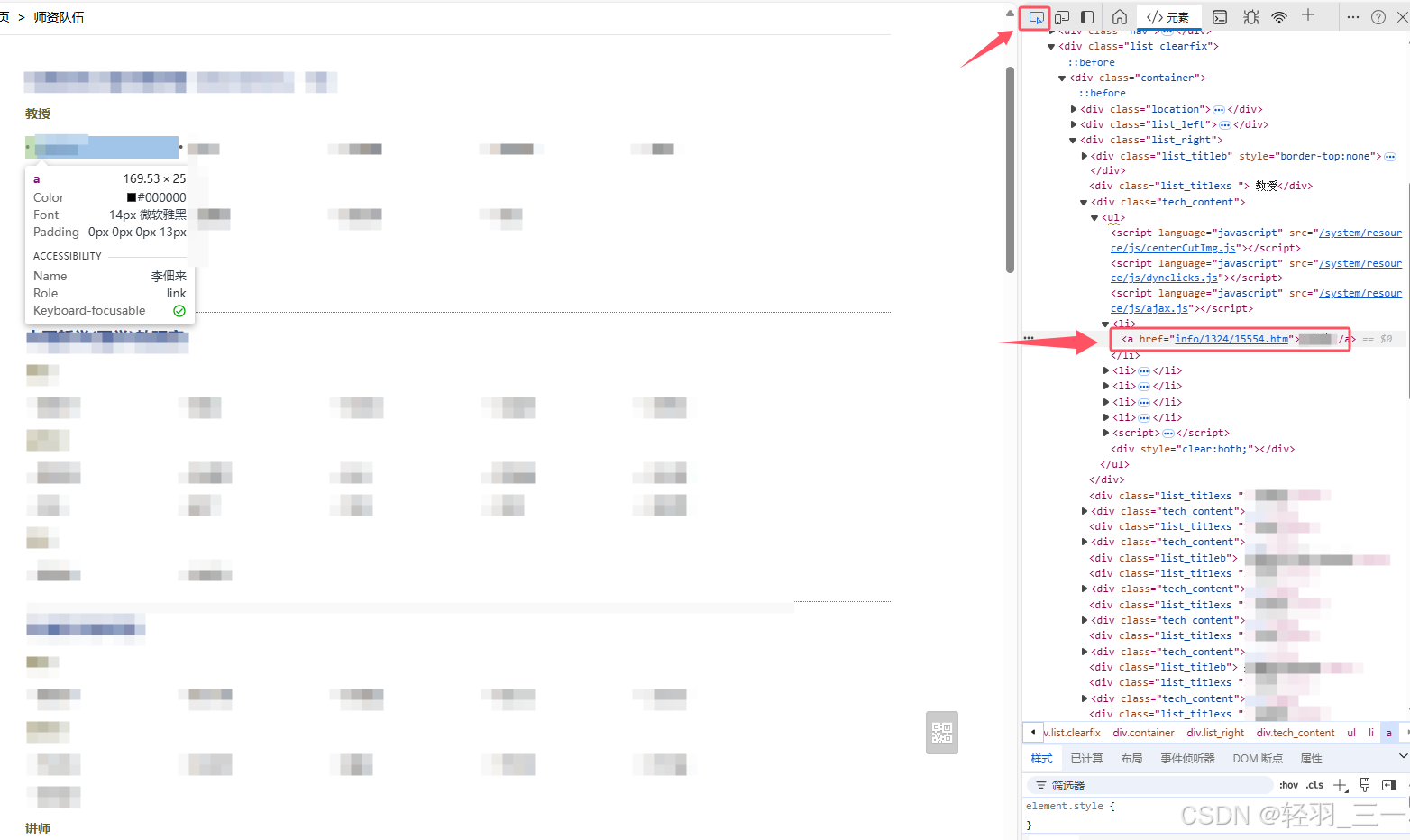
代码说明
首先引用库,这里需要修改的的是 api_key=“###” 里面的 key 字符串。
#!/usr/bin/python
# -*- coding: utf-8 -*-
from openai import OpenAI
# 创建 API 客户端
client = OpenAI(api_key="###", base_url="https://api.deepseek.com") # api_key="###" 中把 ### 改为自己的key
import requests
from bs4 import BeautifulSoup
import re
from lxml import etree
import pandas as pd
这个是为了统一文本编码,减少特殊字符带来报错的概率。↓
#!/usr/bin/python
# -*- coding: utf-8 -*-
根据查询到的网页结构进行修改。↓
# 如果不清楚过程变量的内容,可以print一下,看看是不是准确
# 需要看学院的网页确定结构,然后修改相应代码
# 一部分注释的内容是我之前做的案例,可供参考,自己进行修改
url_v1 = 'https://philosophy.whu.edu.cn/szdw1.htm' # 这里需要改
response_v1 = comein_url(url_v1)
page_v1_text = response_v1.text
#数据解析
tree_v1 = etree.HTML(page_v1_text)
tree_v1_a_list = tree_v1.xpath('//div[@class="tech_content"]//li/a') # 这里需要修改
data_list = []
index = 0
其中:url_v1 = 'https://philosophy.whu.edu.cn/szdw1.htm' # 这里需要改
这里需要修改问学院网站的网址;
这里tree_v1_a_list = tree_v1.xpath('//div[@class="tech_content"]//li/a') # 这里需要修改
这里需要根据前面了解到的网页结构按需修改,div[@class=“tech_content”]这里要找到合适class名称进行修改,把这个**“tech_content”**修改为你需要的,正常来说,后一个信息的网址应该都有一个指定的class名称,后面的“//li/a”也是需要自己领悟一下网页结构的排版;双//表示多层级,单/表示下一层级。
接着 # 第一层,寻找教师信息 tree_v1_a_href_value = tree_v1_a.xpath('@href')[0] # 获取 <a> 标签中的 href 属性值 # 这里需要修改 # print("text1:", tree_v1_a_href_value) ###################################### 拼接网址 url_v1_pitch_v1 = url_v1.split('/szdw1.htm')[0] url_v1_pitch_v2 = "/info" + tree_v1_a_href_value.split("info")[1] url_v2 = url_v1_pitch_v1 + "/" + url_v1_pitch_v2 print("text",str(index),":", url_v2)
这里需要根据后面的网址进行拼接修改,也可以参考前面第二节的代码示例;
最后修改一下文件保存路径和文件名:# 这里进行修改,修改文件输出路径和文件名 output_path = r"C:\Users\HP\Desktop\网页信息抓取" # 这里需要修改 output_name = "信息表1.csv" # 这里需要修改 output_file = output_path + "\\" + output_name
后面需要匹配的信息可以根据自己需要增删修改。
最终代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from openai import OpenAI
# 创建 API 客户端
client = OpenAI(api_key="###", base_url="https://api.deepseek.com") # api_key="###" 中把 ### 改为自己的key
import requests
from bs4 import BeautifulSoup
import re
from lxml import etree
import pandas as pd
def comein_url(url):
# 设置请求头,模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
}
# 请求网页
response = requests.get(url, headers=headers)
# 设置编码为 'utf-8'(如果网页使用的是这种编码)
response.encoding = 'utf-8'
return response
# 定义一个函数来提取信息
def extract_info(text):
info = {}
lines = text.split("\n")
for line in lines:
if "**" in line:
key = line.split("**")[1].strip()
value = line.split(":")[-1].strip() if ":" in line else line.split(":")[-1].strip()
info[key] = value
return info
# 定义一个函数来标准化数据
def standardize_data(info):
standardized = {
"学校": info.get("学校", "未提供"),
"院系": info.get("院系", "未提供"),
"姓名": info.get("姓名", "未提供"),
"性别": info.get("性别", "未提供"),
"职称": info.get("职称", "未提供"),
"籍贯": info.get("籍贯", "未提供"),
"博士毕业院校": info.get("博士毕业院校", "未提供"),
"博士毕业年份": info.get("博士毕业年份", "未提供"),
}
return standardized
def remove_special_characters(text):
# 保留字母、数字、中文和空格
return re.sub(r'[^\w\s]', '', text)
# 这个函数就是通过提问,然后得到response返回,返回答案的格式与前面 extract_info 和 standardize_data 两个格式的内容一致,
# 后续可以自己先问问题,然后再设置格式,自己弄就好
def reback_answer(tiwen):
'''
:param tiwen: 提问的文本问题
:return: 返回答案
'''
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": tiwen},
],
stream=False
)
text = response.choices[0].message.content
return text
# 如果不清楚过程变量的内容,可以print一下,看看是不是准确
# 需要看学院的网页确定结构,然后修改相应代码
# 一部分注释的内容是我之前做的案例,可供参考,自己进行修改
url_v1 = 'https://philosophy.whu.edu.cn/szdw1.htm' # 这里需要改
response_v1 = comein_url(url_v1)
page_v1_text = response_v1.text
#数据解析
tree_v1 = etree.HTML(page_v1_text)
tree_v1_a_list = tree_v1.xpath('//div[@class="tech_content"]//li/a') # 这里需要修改
data_list = []
index = 0
for tree_v1_a in tree_v1_a_list:
index += 1
# 这里做一个范例,只提取前20条数据,后续有问题自己尝试解决一下
if index < 20:
# 第一层,寻找教师信息
tree_v1_a_href_value = tree_v1_a.xpath('@href')[0] # 获取 <a> 标签中的 href 属性值 # 这里需要修改
# print("text1:", tree_v1_a_href_value)
###################################### 拼接网址
url_v1_pitch_v1 = url_v1.split('/szdw1.htm')[0]
url_v1_pitch_v2 = "/info" + tree_v1_a_href_value.split("info")[1]
url_v2 = url_v1_pitch_v1 + "/" + url_v1_pitch_v2
print("text",str(index),":", url_v2)
###################################### 这里看教师的具体信息
response_v4 = comein_url(url_v2)
page_v4_text = response_v4.text
tree_v4 = etree.HTML(page_v4_text)
soup = BeautifulSoup(response_v4.text, 'html.parser')
soup_txt = soup.text
cleaned_text = re.sub(r'\n+', '\n', soup_txt)
# print("文本信息:", cleaned_text)
# 这里可以修改问题,比如,根据名字确定性别,如果不确定,在输出时可以进行说明
tiwenxinxi_v1 = "从下面的文本: /n "
tiwenxinxi_v2 = " /n 匹配需要的信息:学校、姓名、院系、性别、职称、籍贯、博士毕业院校、博士毕业年份"
tiwenxinxi_total = tiwenxinxi_v1 + cleaned_text + tiwenxinxi_v2
# print("文本信息:", tiwenxinxi_total)
tiwen = remove_special_characters(tiwenxinxi_total)
answer = reback_answer(tiwen)
# 提取信息
info = extract_info(answer)
# 标准化数据
standardized_info = standardize_data(info)
# 将标准化后的数据添加到列表中
data_list.append(standardized_info)
# 将数据列表转换为DataFrame
df = pd.DataFrame(data_list)
# 按指定顺序排列列
columns_order = [
"学校", "院系", "姓名", "性别", "职称", "籍贯", "博士毕业院校", "博士毕业年份"
]
df = df[columns_order]
# 这里进行修改,修改文件输出路径和文件名
output_path = r"C:\Users\HP\Desktop\网页信息抓取" # 这里需要修改
output_name = "信息表1.csv" # 这里需要修改
output_file = output_path + "\\" + output_name
# 保存到CSV文件
df.to_csv(output_file, index=False, encoding="utf-8-sig")
print("标准化信息已保存到 '标准化信息表.csv'")
结果: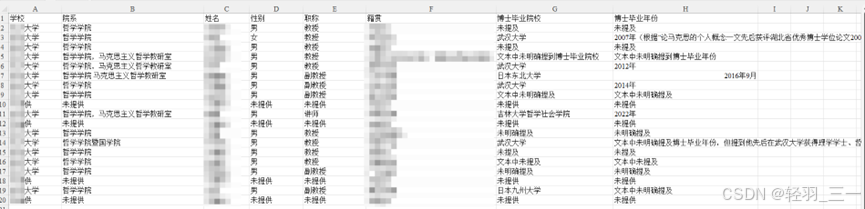

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)