LangChain源码分析系列·流式(Stream)能力分析
本文是 LangChain 框架源码分析系列文章之一,以工程设计的能力视角切入分析当下最火的大模型应用开发框架。与大模型原理学习对比,学习 LangChain 框架需要做思维模式的转变,关注的重点从 Why 转为 What&How。阅读源码是一个相对枯燥的过程,并且穿插源码在其中一定程度上会影响文章的可读性;为此,结论先行 - LangChain 流式能力的基础是 Python 语言的生成器语法
0.题外话
从框架的命名也可以看出该框架对大模型应用架构的核心抽象是 Chain。“为什么以 chain 为核心抽象?”,如果你有这样的疑问,不要紧张,这是软件从业人员一个很好的习惯。
在大模型应用开发中,"chain"(链式)框架变得越来越流行,设计的选择有很多种,某一种设计得以流行并不是说其是唯一解,而是其所持有的特性被大多数从业人员认可。往往这些特性都是非功能特性,如下:
【模块化】 通过将整个处理流程分解为一系列独立的模块或“链条”,每个模块执行一个特定的功能。这种模块化的设计使得开发者可以更容易地理解和管理复杂的处理流程。每个模块都可以独立开发和测试,降低了代码的耦合度,提高了开发效率和代码质量。
【灵活性】 在链式框架中,添加、移除或替换模块变得非常简单。这种灵活性使得根据需求调整处理流程变得容易,无论是在开发阶段还是在模型已经部署之后。这对于需要频繁更新或迭代模型的应用尤其重要。
【可扩展性】 随着应用需求的增长,可能需要处理更复杂的任务或处理更大的数据集。Chain 框架允许通过简单地添加更多的模块来扩展功能,而不是重写现有的代码。这种设计支持了更好的可扩展性,使得应用能够适应未来的需求变化。
【易于维护和迭代】 由于处理流程被划分为独立的模块,每个模块都有明确的功能和接口,这使得维护和更新变得更加容易。开发者可以单独修改或优化某个模块,而不影响整个系统的其他部分。这对于保持应用的长期可维护性和适应快速变化的技术环境至关重要。
【促进团队协作】 在大型项目中,不同的团队或个人可能负责开发不同的模块。Chain 框架通过定义清晰的模块接口和责任分界,促进了团队之间的协作。每个团队可以独立工作在自己的模块上,只要遵循共同的接口规范,就能保证整个系统的协同工作。
综上,chain 框架提供了一种既灵活又强大的方式来构建和管理大模型应用。这很符合我们分析框架的经验认知。
1.前言
本文是 LangChain 框架源码分析系列文章之一,以工程设计的能力视角切入分析当下最火的大模型应用开发框架。与大模型原理学习对比,学习 LangChain 框架需要做思维模式的转变,关注的重点从 Why 转为 What&How。
阅读源码是一个相对枯燥的过程,并且穿插源码在其中一定程度上会影响文章的可读性;为此,结论先行 - LangChain 流式能力的基础是 Python 语言的生成器语法特性。
2.应用分析
使用 LangChain 构建一个最简单的 Chain :
prompt | model## 完整代码
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
model = ChatOpenAI(model="gpt-4")
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
chain = prompt | model
chain.stream({"topic":"ice cream"})这里出现了 LCEL (LangChain 表达式语言),本文并非 LCEL 的源码分析,所以此处简化来看这段源码。
第一个问题 - chain 是什么类型
model 的对象类型是 ChatOpenAI,prompt 的对象类型是 ChatPromptTemplate,那么 chain 的对象类型是什么?
搞清楚这一点只需要关注一个操作符/两个函数。
操作符 :|
函数 : __or__, __ror__class Runnable(Generic[Input, Output], ABC):
###############
### 大量省略 ###
###############
def __or__(
self,
other: Union[
Runnable[Any, Other],
Callable[[Any], Other],
Callable[[Iterator[Any]], Iterator[Other]],
Mapping[str, Union[Runnable[Any, Other], Callable[[Any], Other], Any]],
],
)-> RunnableSerializable[Input, Other]:
"""Compose this runnable with another object to create a RunnableSequence."""
return RunnableSequence(self, coerce_to_runnable(other))
def __ror__(
self,
other: Union[
Runnable[Other, Any],
Callable[[Other], Any],
Callable[[Iterator[Other]], Iterator[Any]],
Mapping[str, Union[Runnable[Other, Any], Callable[[Other], Any], Any]],
],
)-> RunnableSerializable[Other, Output]:
"""Compose this runnable with another object to create a RunnableSequence."""
return RunnableSequence(coerce_to_runnable(other), self)Tip: "|"通常称为“或”操作符,从函数命名的视角看也是如此;但是此处更合适的称谓是“管道”操作符。为什么一个操作符映射两个函数? __ror__ 是 Python 中的一个特殊方法(或称魔术方法),用于实现反向的“或”操作。这个方法对应于位运算中的“或”操作符(|),但当左侧对象没有实现 __or__ 方法或者 __or__ 方法返回 NotImplemented 时,会尝试调用右侧对象的 __ror__ 方法。在Python中,特殊方法允许开发者定义对象对内置操作的响应。例如, __add__ 方法定义了两个对象使用加号(+)操作符相加时的行为,而 __or__ 方法定义了使用管道符号(|)时的行为。相应地,__ror__ 方法允许一个对象定义当它处于管道操作符的右侧,并且左侧对象没有处理(或者不能处理)该操作时的行为。
通过函数定义,可以清晰的看到 chain 的类型是 RunnableSequence ,或者更准确的答案 RunnableSerializable(具体子类实现可能各有不同)。
第二个问题 - chain 的设计框架
针对这个问题,先给出答案 - chain 设计的核心是 Runnable。引出 Runnable 的方式至少有三种:
1.__or__/__or__ 方法定义在 Runnbale,这是最直接的方式(大部分程序员通过 IDE 的跳转快捷键定位找到);
2.prompt 和 model 均实现 Runnable;
3.__or__/__or__返回结果 RunnableSerializable 向上溯源定位 Runnable。
Tip: 区别于多线程/协程编程的核心接口定义,此处的 Runnable 是专属 LangChain 框架的关键抽象。注意这一点,避免造成理解上的混淆。对 Runnable 的认知可以参照 LangChain 官方文档的 Runnable Interface ,我尽量在还原官方说明的同时谈一下自己的理解:
为了简化个性化定制 chain,抽象定义了"Runnable"协议(protocol),LangChain 的大部分核心组件都实现了 Runnable 协议 - LLM(大语言模型抽象)、parser、prompt、retriever 和 agent 等重要的 LangChain 核心抽象(primitive)。
Tip: 对开发人员来说,将 protocol 和 interface 划等号可能比较别扭,但是从服务化认知体系切入却是很直观的一件事。Runnable 的接口定义给出了 chain 定义 和 chain 调用的标准方式。单独强调 chain 调用是因为,这是与大模型交互的入口,是最合适做源码分析的切入点。chain 调用由如下几个标准方法构成:
•invoke:给定输入调用 chain
•batch:给定一组输入调用 chain
•stream:流式调用 chain ;流式返回大模型响应结果(数据单位为 chunk - 数据单元定义的一种,在传输协议/内存管理等领域很常见)
将这三个方法并列是因为从分类的视角看是三者都是大模型调用的方法,区别在于调用的方式不同;通过批量、流式等特性修饰词,给单纯的调用引入了对应的特性。
上面三个都是同步方法定义,与之关联的也有异步调用的方法定义:
•ainvoke
•abatch
•astream
另外此处还提到两个比较特殊的方法,在介绍流式处理时进行详细介绍:
•astream_log: 除了最终响应之外,还实时流式返回中间步骤结果
•astream_events: 事件驱动机制,截止当前还是一个 beta 版本的能力
Tip: 成熟需软件研发人员,需要对 beta 版本功能有清晰的认知,因为关系到系统稳定性问题。
alpha 版本和 beta 版本的差异式比较明显的,而且 alpha 版本作为一个内部测试阶段的产物通常不会被应用研发人员感知。
### beta 版本
- **发展阶段**:beta 版本通常指的是软件开发过程中的一个阶段,该阶段紧随 alpha 版本之后。在 alpha 阶段,软件通常只有基本功能,并且可能包含很多错误。beta 阶段意味着软件的主要功能已经实现,但仍然需要通过公开测试来查找和修复错误。
- **测试目的**:beta 测试的目的是在发布最终版本之前,让真实用户在实际环境中测试软件,以便开发者可以发现并修复潜在的问题。
- **用户群体**:beta 版本通常面向更广泛的用户群体,这些用户愿意尝试尚未完全稳定的软件,并提供反馈。
总的来说,beta 版本是指软件的一个预发布版本,可能包含多个实验性功能(实验性功能是指具体的、可能不稳定的单个功能或一组功能)。用户在使用 beta 版本或实验性功能时,需要准备好面对潜在的错误和不稳定性,并且通常被鼓励提供反馈以帮助开发者改进产品。
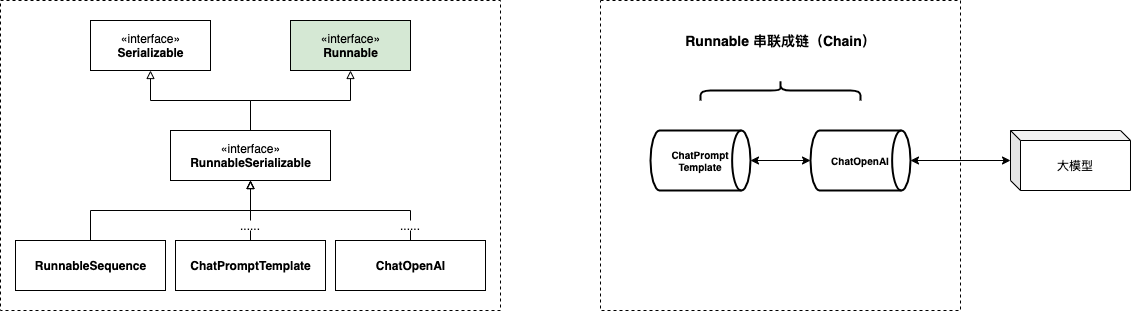
Tip: 注意 Runnable 和 Serializable 都是 LangChain 框架自定义接口,因为软件从业人员对对象命名的规律性,其与我们常规认知的接口存在一定的功能/语义相似性,但是因为是框架自定义,必然存在更多的个性化。3.流式能力
3.1 分析视角
·架构视角
流式(Stream)处理是一种实时数据处理技术,为软件设计带来的最核心特性是实时性;针对大模型应用,流式能力弥补了大模型响应时长过长的问题。流式处理并不是大模型或者 LangChain 的特有设计,作为一种通用能力,其必然沉淀了公共的架构模式,从基本架构和关键组件上看应具备如下几点:
1.流式I/O组件 输入流/输出流,负责处理连续的数据流
2.异步能力
3.管道设计(Pipeline)
4.实用函数集合
在对流式处理架构模式有先验知识之后,可以按照上述几个点剖析 LangChain 对此的设计。
·应用视角
流式能力的支持理论上应该是端到端的,chain 由不同的组件“链”接而成,那么必然意味着组成 chain 的组件都需要支持流式能力 - 这是一个很直观的假设,但是站在应用的视角看,这个假设存疑。
构造 chain 的初衷是用来与大模型做交互,我们不妨以 ChatGPT 应用为例思考这样一个问题 - ChatGPT 是否能够在输入不完整的情况下给出我们预期的结果?很明显不能。将AI大模型替换成真正的人,也需要完整的问题才能给出回答。“当然国人喜欢的话说一半,剩下的自己体会除外。”
上面是一种理论分析,技术上也可以进行解释 - GPT 的 Transformer 模型在处理输入序列时,需要一次性获得整个序列的输入以便计算位置信息并进行自注意力操作。这是因为 Transformer 模型的自注意力机制允许每个输入元素在处理时考虑到序列中的所有其他元素,包括它们的位置关系。因此,模型的这一设计决定了在开始处理任何序列数据之前,整个输入序列及其对应的位置信息必须是已知的。
Tip: 特殊设计都会带来复杂度,流式能力也不例外。
对很多未知的问题进行假设都应该考虑必要性,没有必要性的情况下,即使技术上可行也不会真正被实现;研发人员可以将自身带入框架研发的角色去分析,换我来是否会如此实现。
上面几百个字的啰嗦只是想提出一个假设 - langchain 的流式能力是单向的(仅结果响应支持流式)。如果假设成立,链条上的很多组件对流式能力的支持就是“虚假“的。
·代码视角
分析流式能力的入口可以选择 - Runnable 接口。接口定义了 4 种不同方式的能力实现:
1.stream (sync function)
2.astream (async function)
3.astream_log
4.astream_events
├──libs
│ ├── core
│ │ ├── langchain_core
│ │ │ ├── runnables
│ │ │ │ ├── base.pyclass Runnable(Generic[Input, Output], ABC):
### stream
def stream()
### astream
async def astream()
### astream_log
@overload
def astream_log(...)
@overload
def astream_log(......)
async def astream_log()
### astream_events
@beta_decorator.beta(message="This API is in beta and may change in the future.")
async def astream_events()3.2 stream 源码分析【***核心***】
所有的 Runnable 对象都实现了同步方法 stream 和 astream(异步变种),这些方法设计用于以 chunk 的形式传输最终输出,并在每个 chunk 可用时立即生成和返回。
class Runnable(Generic[Input, Output], ABC):
def stream(
self,
input: Input,
config: Optional[RunnableConfig]=None,
**kwargs: Optional[Any],
)-> Iterator[Output]:
"""
Default implementation of stream, which calls invoke.
Subclasses should override this method if they support streaming output.
"""
yield self.invoke(input, config,**kwargs)从方法定义源码来看,stream 方法体现了流式处理的设计,主要通过以下几个方面:
•生成器设计:Iterator + yield 关键字(标准生成器定义)。生成器(generator)允许逐个产生输出值;这是流式处理的关键,因为它允许在每个输出 chunk 可用时立即返回,而不需要等待整个处理流程完成。
Tip: 生成器是 Python 语言的重要语法特性之一,是实现流式能力的基石。不熟悉的读者可以暂时搁置,后文会有具体说明。•可覆写的方法:注释中提到,子类应该覆写这个方法,如果它们支持流式输出。这意味着 stream 方法的默认实现是一个基础版本,真正的流式处理逻辑应该由子类根据具体的需求来实现。子类可以实现更复杂的逻辑来以 chunk 的形式处理和产生数据。
我们从1个经典的 chain 构成开始:
prompt | model | output_parserfrom langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
model = ChatOpenAI(model="gpt-4")
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
output_parser = StrOutputParser()
chain = prompt | model | output_parser
chain.stream({"topic":"ice cream"})3.2.1 Promot
class ChatPromptTemplate(BaseChatPromptTemplate):
----|>class BaseChatPromptTemplate(BasePromptTemplate, ABC):
----|>class BasePromptTemplate(RunnableSerializable[Dict, PromptValue], Generic[FormatOutputType], ABC):
----|>class RunnableSerializable(Serializable, Runnable[Input, Output]):
----|>class Runnable(Generic[Input, Output], ABC):ChatPromptTemplate 的 stream 方法溯源到 Runnable 接口定义,很明显是不支持流式能力的。
3.2.2 LLM
class ChatOpenAI(BaseChatModel):
----|>class BaseChatModel(BaseLanguageModel[BaseMessage], ABC):class BaseChatModel(BaseLanguageModel[BaseMessage], ABC):
def stream(
self,
input: LanguageModelInput,
config: Optional[RunnableConfig]=None,
*,
stop: Optional[List[str]]=None,
**kwargs: Any,
)-> Iterator[BaseMessageChunk]:
if type(self)._stream == BaseChatModel._stream:
# model doesn't implement streaming, so use default implementation
yield cast(
BaseMessageChunk, self.invoke(input, config=config, stop=stop,**kwargs)
)
else:
config = ensure_config(config)
messages = self._convert_input(input).to_messages()
params = self._get_invocation_params(stop=stop,**kwargs)
options ={"stop": stop,**kwargs}
callback_manager = CallbackManager.configure(
config.get("callbacks"),
self.callbacks,
self.verbose,
config.get("tags"),
self.tags,
config.get("metadata"),
self.metadata,
)
(run_manager,)= callback_manager.on_chat_model_start(
dumpd(self),
[messages],
invocation_params=params,
options=options,
name=config.get("run_name"),
batch_size=1,
)
generation: Optional[ChatGenerationChunk]=None
try:
for chunk in self._stream(
messages, stop=stop, run_manager=run_manager,**kwargs
):
yield chunk.message
if generation is None:
generation = chunk
else:
generation += chunk
assert generation is not None
except BaseException as e:
run_manager.on_llm_error(
e,
response=LLMResult(
generations=[[generation]] if generation else[]
),
)
raise e
else:
run_manager.on_llm_end(LLMResult(generations=[[generation]]))class ChatOpenAI(BaseChatModel):
def _stream(
self,
messages: List[BaseMessage],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> Iterator[ChatGenerationChunk]:
message_dicts, params = self._create_message_dicts(messages, stop)
params = {**params, **kwargs, "stream": True}
default_chunk_class = AIMessageChunk
for chunk in self.client.create(messages=message_dicts, **params):
if not isinstance(chunk, dict):
chunk = chunk.model_dump()
if len(chunk["choices"]) == 0:
continue
choice = chunk["choices"][0]
chunk = _convert_delta_to_message_chunk(
choice["delta"], default_chunk_class
)
generation_info = {}
if finish_reason := choice.get("finish_reason"):
generation_info["finish_reason"] = finish_reason
logprobs = choice.get("logprobs")
if logprobs:
generation_info["logprobs"] = logprobs
default_chunk_class = chunk.__class__
chunk = ChatGenerationChunk(
message=chunk, generation_info=generation_info or None
)
if run_manager:
run_manager.on_llm_new_token(chunk.text, chunk=chunk, logprobs=logprobs)
yield chunk跨两个类 90+ 行代码,看着就挺复杂。但是有一点是简单的,作为大模型的应用层抽象 ChatOpenAI 是支持流式处理的(不支持不会搞那么复杂)。复杂代码的背后一定是相对简单的设计,任何简单的设计要做到面面俱到(考虑边界/极端场景等鲁棒性设计)最后落地的代码都会看起来复杂。本文是一篇源码分析的文章,从这个点开始切入正题,来分析一下流式处理的代码实现。作者本身的技术背景是 Java 主语言出身,在分析源码的过程可能会偏 Java 风格。
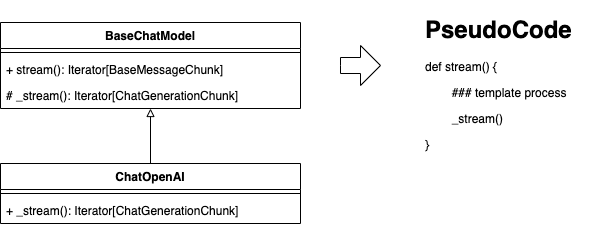
为什么跨两个类对象?上图是一种理解方式,采用模版方法设计模式实现。按照调用顺序,从模版方法开始分析(分析过程采用分治思想)。
if-else 将全局一分为二:
•if 部分
if type(self)._stream == BaseChatModel._stream:
# model doesn't implement streaming, so use default implementation
yield cast(BaseMessageChunk, self.invoke(input, config=config, stop=stop,**kwargs))子类没有覆盖 _stream 方法的情况下,降级为常规调用(stream -> invoke)。这个时候已经失去了传统意义上生成器的意义,yield 关键字存在的价值也仅是保证方法调用模式的一致性。
· else 部分
else 部分代码还是长,借助流程图继续拆解。
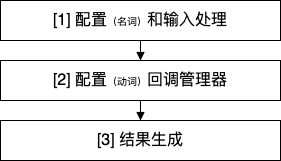
[1] 配置和输入处理
### 配置预处理 RunnableConfig(限定类型的字典数据结构)
config = ensure_config(config)
### 输入格式转换 List[BaseMessage](字符串为基础的数据结构)
messages = self._convert_input(input).to_messages()
### 参数准备 dict(字典数据结构)
params = self._get_invocation_params(stop=stop,**kwargs)
### 参数准备 dict(字典数据结构)
options ={"stop": stop,**kwargs}常见的编码习惯,前置进行变量准备。
[2] 配置回调管理器
Tip: 回调管理器的作用是提供事件响应的 hook,与流式能力本身关系不大
callback_manager = CallbackManager.configure(
config.get("callbacks"),
self.callbacks,
self.verbose,
config.get("tags"),
self.tags,
config.get("metadata"),
self.metadata,)### (run_manager,) 语法说明:元组类型对象的 单元素 解析,可以理解为 python 语言的语法糖(run_manager,)= callback_manager.on_chat_model_start(
dumpd(self),
[messages],
invocation_params=params,
options=options,
name=config.get("run_name"),
batch_size=1,)选择回调的方式完成大模型调用的结果处理。上面仿佛是两个步骤 回调管理器设置 和 事件监听注册 ,但是如果对回调的原理比较熟悉的话,应该可以看出来就是一步回调;回调生效的背后涉及到一套完整的事件响应机制,这种机制通常包含事件监听、事件触发和回调函数的执行三个基本环节。
Tip: 什么是回调?回调是一个很常见的设计,每个研发同事对其都有自身的理解。作者本身理解回调设计是从 IO 模型的同步/异步调用方式入手。
同步调用 - 调用端发出请求之后,线程(或协程等抽象)必须一直等待结果返回;
异步调用 - 调用端发出请求之后,线程(或协程等抽象)立即返回。
针对异步调用,如果调用端不关注返回结果就很完美;但是如果需要处理返回结果该怎么办?回调就是针对这种场景的补充设计,通过事件响应机制结合回调完成异步调用的结果返回处理。运行管理器具体是怎样设计生效的?这个话题的体量足以支撑一片新的文章,因此作者也抽取此部分独立撰写了 《LangChain源码分析系列·回调(Callback)能力分析》 。
[3] 结果生成(***核心***)
生成器【熟悉 Python 生成器的读者可以忽略】
生成器是 Python 语言提供的一种语法特性。生成器使得我们可以定义迭代器函数,能够逐步生成值,而不是一次性生成所有值。生成器通过 yield 关键字来实现这一点,每次调用生成器函数时,它会暂停在 yield 语句处,并返回一个值给调用者。当再次调用生成器时,它会从上次暂停的地方继续执行。
生成器的基本特点
1.使用 yield 关键字:与普通函数不同,生成器函数使用 yield 而不是 return 来返回值。yield 会暂停函数的执行,并把值返回给调用者。
2.保持状态:每次生成器函数暂停时,它会保存当前的执行状态(包括局部变量、指令指针等)。当生成器被重新调用时,它会从上次暂停的地方继续执行。
3.惰性求值:生成器按需生成值,而不是一次性生成所有值。这使得生成器非常适合处理大数据集或流式数据。
生成器的示例
def count_up_to(max):
count = 1
while count <= max:
yield count
count += 1
# 使用生成器for number in count_up_to(5):
print(number)### 输出结果
1
2
3
4
5上面的示例比较好的展示了生成器的语法、常规使用方式和效果。如果没有 yield 关键字,那么打印结果应该是【5】,而不是【1 2 3 4 5】。可以理解为 yield 关键字设定了上下文(参照操作系统线程的PC、寄存器),生成器方法的每次调用都在 yield 指定的位置结束并返回,而下一次方法执行则从 yield 上下文恢复(PC+1,寄存器恢复)继续方法执行。
Tip: 理解生成器还需要关注两个点 - 1.生成器方法是可以嵌套的;2.生成器的使用往往需要与循环强绑定使用。
当然对于第2点是一种常规使用方式,递归等形式同样可以利用生成器能力。综上,生成器这一语法特性带来的 状态保持 和 惰性求值 能力,天然契合流式数据处理。
逻辑解析
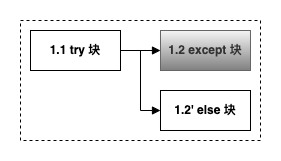
分治思想支持嵌套,故而我们可以针对结果生成部分继续划分(如下图)。结合对生成器的认知,我们将结果生成部分(忽略异常处理1.2)总结为两句话:
1 调用 _stream 逐个获取 chunk 并返回 chunk.message(1.1);
2 存储 _stream 返回的全部结果,并在最终返回之前处理回调事件 on_llm_end (1.1 和 1.2')。
外层分析结束,继续深入分析就需要查看 _stream 的实现,首先,它处于生成器的链条上,自身必然也是一个生成器函数。源码在上文已经给出,此处直接进行分治划分(如下图):
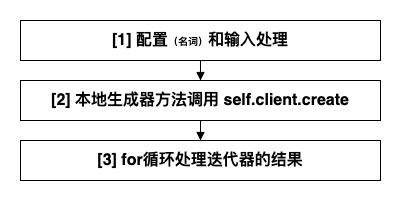
Tip: Python 语言的模块化能力涉及到大量的导入导出行为,在代码溯源过程中会显得无聊且繁琐;但是如果读者关注设计,建议多花点儿时间去考量每一次导入导出背后的必要性。
三个部分中最核心的问题 - client 是什么?
站在代码实现的视角看这个点不是很直观;但是站在功能的视角看还是很直观的 - client 一定是大模型的客户端。
对大模型客户端的认知有两个隐含的点: 1 - 大模型客户端是 LangChain 框架的边界(框架定位);2 - 大模型客户端的实现在框架的开放生态模块(框架的开放特性)。
这两个点的推断可以辅助我们快速定位代码实现的脉络。
开始正式串联代码脉络之前,还需解释一个 Python 语言的知识点 - Pydantic 库。
Pydantic 是一个强大的三方库(非 Python 标准库),专门用于数据验证和数据模型的创建。它利用 Python 的类型提示来声明数据模型,并在实例化时自动进行数据验证和转换。@root_validator() 注解是 Pydantic 库提供的能力,此注解修饰的方法,会在类实例化过程中被调用(用于数据验证和转换);方法包含两个参数【cls - 当前类的类对象, values - 当前类的实例对象(属性)】。
@root_validator()
def validate_environment(cls, values: Dict) -> Dict:
""" 省略部分代码 """
if not values.get("client"):
values["client"] = openai.OpenAI(**client_params).chat.completions
if not values.get("async_client"):
values["async_client"] = openai.AsyncOpenAI(
**client_params
).chat.completions
return values我们找到了 client 的直接定义:
import openai
client = openai.OpenAI(**client_params).chat.completions此时我们已经完成了 langchain 侧的源码剖析,因为已经看到了边界代码( openai 客户端的代码封装)。
因为内网无法访问 OpenAI 官网的原因,此处给出 microsoft 的文档使用说明作为参照《work-with-the-chat-completion-api》(官网对于 chat.completions API 的使用说明)。理所当然的,此接口是支持流式数据返回的(参照 stream 参数)。
3.2.3 Parser
Tip: 本小节的内容很简单,不要设定过于复杂的预期
StrOutputParser 也是不支持流式能力的(溯源 stream 函数 -> Runnable)。但是与 Prompt 不同,parser 是在返回处理链路上的一环,我们原本期望(假设)它是支持流式处理的。由此延伸出一个很有意思的问题,如果 llm 支持流式能力的情况下,parser 不支持流式会呈现出什么样的效果?想看到流式的效果应该怎样应用呢?答案比想象中还要简单,此处简化说明,不再赘述。
此处我们省略部分代码直接给出 StrOutputParser.stream 的效果:返回生成器中首个结果的 str 类型结果。
Runnable.stream -> Runnable.invoke
BaseOutputParser.invoke -> BaseOutputParser.parse_result
-> StrOutputParser.parse问题1 : parser 实际上不会缓冲模型的流输出,而是单独处理每个块。
问题2 : 因此如果期望流式的展示完整的结果,在最终结果处理上还是需要循环的配合。
for chunk in chain.stream({"topic": "ice cream"}):
print(chunk, end="|", flush=True)4.写在最后
本文作为一个框架源码分析系列文章的开篇,选择了个人感兴趣的架构设计模块作为切入点进行剖析。考虑到读者阅读疲劳问题,本文并未完全覆盖初始设定的大纲,astream等板块会补充文章进行说明。
为保证阅读体验,行文大多选择通过问答的方式直接映射说明,但是有一些点是散落在文章各处隐式说明的,需要读者在阅读之后get到某些点(以流式能力的架构视角为例 流式I/O <-> 流式O <-> Parser、异步能力 <-> 回调、管道设计 <-> Chain[链式框架] <-> LCEL <-> 管道操作符)。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 32
32 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)