DeepSeek总是崩?教你本地部署离线DeepSeek R1,保姆级教程
在电脑本地部署DeepSeek有很多的好处,不用担心线上模型掉线、数据隐私安全,还可以做很多定制化的应用,比如本地客服、培训教育、企业文档等有很多场景,大家可以多多探索。
最近DeepSeek由于受到大量DDOS攻击,加上访问过热,总是会出现服务器繁忙、无法加载的情况,于是乎我测试在本地电脑部署DeepSeek R1模型,居然测试成功了,而且速度并不比APP慢。
下面会讲到部署本地LLM(大模型)需要的软件,以及相应的电脑配置,这里以DeepSeeK R1各种版本为例。
软件配置
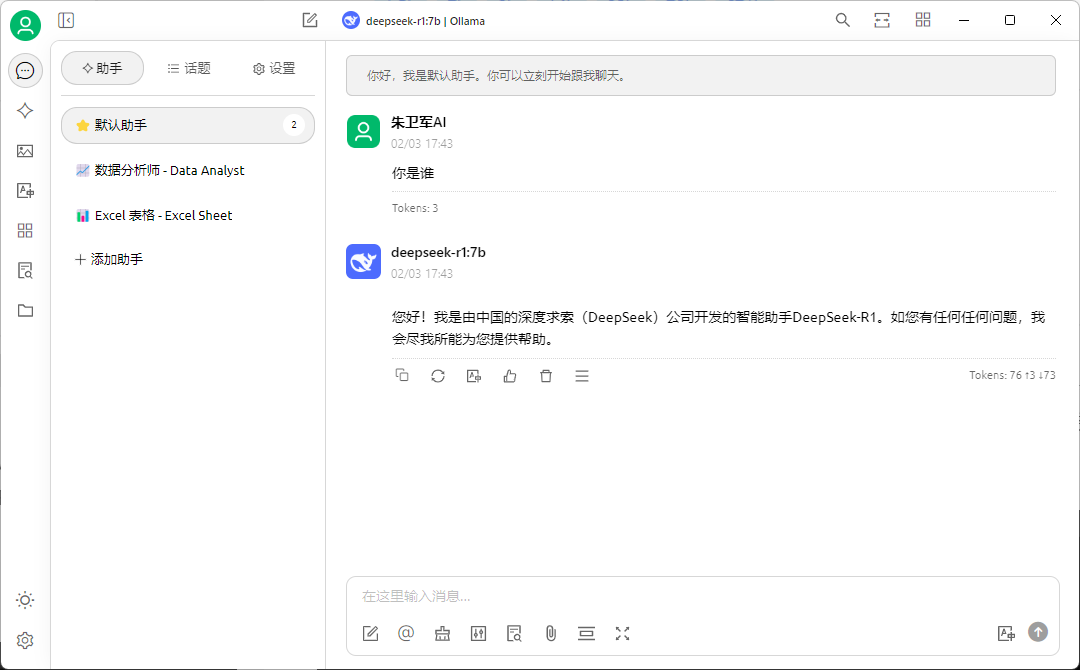
我选择了Ollama作为本地运行LLM的工具,这是一个非常出名的开源软件,Github上有12万Star,主要用来在本地电脑设备下载、部署和使用LLM。
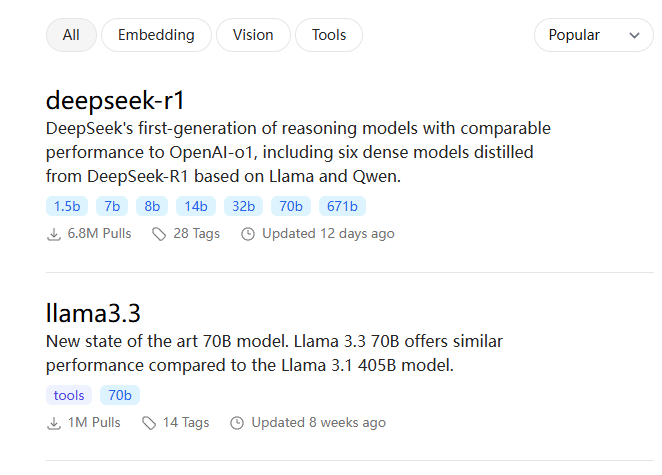
Ollama提供了丰富的LLM库用于下载,比如llama、qwen、mistral以及这次要使用的deepseek r1,而且有不同的参数规模用于选择,适配不同性能的电脑设备。
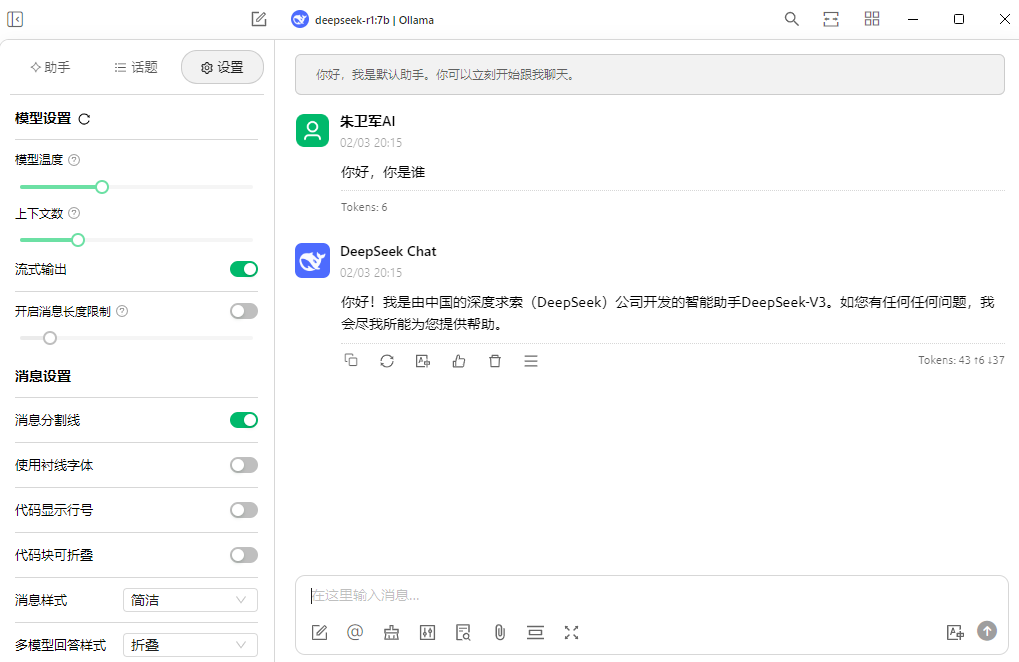
Ollama虽然支持直接使用LLM,但是仅能在命令行来对话,交互功能不尽人意,所以我会使用Cherry-studio来作为前端交互,以Ollama作为后台,来和LLM对话,这就和日常使用的DeepSeek APP类似了。
Ollama交互界面:
Cherry-studio交互界面:
电脑配置要求
很多人担心在本地部署DeepSeek R1,是不是对电脑性能有很高要求,比如CPU、GPU、内存等。
其实不用担心,不同参数规模的模型对电脑性能要求不一样,部署DeepSeek R1 8B规模以下的模型不需要独显也可以运行。
我部署的是7B模型,电脑系统windows 11,配置CPU Intel® Core™ i7-12650H 2.30 GHz,内存16GB,没有独显。
这里科普下,LLM参数规模是指什么,所谓7B是指该模型大约有 70 亿(7 Billion)个参数,参数代表里模型训练过程中需要学习的数值,参数越多,模型能够理解更复杂的信息,给出的回答也越准确和全面。
以下是基本的要求,可以对号入座。
| R1模型版本 | CPU | GPU | 内存 | 存储 |
|---|---|---|---|---|
| 1.5B | Intel Core i5/AMD Ryzen 5 及以上 | 无强制要求,有 1GB 及以上显存可提升性能 | 最低 8GB,推荐 16GB+ | 至少 10GB,建议留更多缓存空间 |
| 7B | Intel Core i7/AMD Ryzen 7 及以上 | 无强制要求,有 4GB 以上显存更好,推荐 8 - 12GB | 最低 16GB,推荐 32GB+ | 至少 12GB,建议 30GB+ |
| 8B | Intel Core i7/AMD Ryzen 7 及以上 | 无强制要求,有 4.5GB 以上显存更好,推荐 8GB+ | 最低 16GB,推荐 32GB+ | 至少 12GB,建议 30GB+ |
| 14B | Intel Core i9/AMD Ryzen 9 及以上 | 8GB 以上,推荐 12GB+,如 RTX 3080 及以上 | 最低 32GB,推荐 64GB | 至少 15GB,建议 50GB+ |
| 32B | 高端多核,强多线程处理能力 | 18GB 左右,建议 24GB+,如 NVIDIA A100 | 32GB+,推荐 64GB+ | 至少 20GB,建议 80GB+ |
| 70B | 服务器级 CPU,如 Intel Xeon 系列 | 40GB 以上,如 NVIDIA H100 | 64GB+,推荐 128GB+ | 至少 30GB,建议 200GB+ |
部署流程
清楚刚刚提到的相关软件和电脑配置后,就可以开始在本地部署DeepSeek R1了。
第一步:下载和安装Ollama
Ollama是运行LLM的软件,可以在Ollama官网下载,网址如下:
https://ollama.com/download
根据对应操作系统下载相应版本,我选择的是windows版。
下载完成后,直接安装即可,安装没有啥配置要求,一路next。
安装好后,电脑上会出现Ollama软件,这里要提示下,打开Ollama后并不会出现传统UI界面,因为Ollama是在后台运行的。

第二步:下载和安装DeepSeek R1
Ollama提供了各种主流开源大模型的资源下载,我这里根据自己电脑配置安装的是DeepSeek R1 7B,如果你电脑配置足够高的话建议安装14B以上的版本,模型性能会远高于7B。
就像一个高中生,其他条件不变情况下,理论上刷过的题越多,考试的分也就越高。
如果你想体验DeepSeek APP上的R1性能,那就需要配置参数671B的版本,这根本无法在个人PC上实现,需要数据中心级别的设备。
下面列举DeepSeek R1模型不同参数规模下的语言理解能力、文本生成质量、推理速度、处理复杂任务能力以及对硬件资源要求,可以参考自己的需求和硬件条件来配置。
| 模型版本 | 语言理解能力 | 文本生成质量 | 推理速度 | 处理复杂任务能力 | 硬件资源需求 |
|---|---|---|---|---|---|
| 1.5B | 理解简单语句,复杂语义有局限 | 基础简单,逻辑连贯一般 | 快,普通 CPU 可用 | 仅处理简单常规任务 | 低 |
| 7B | 较好理解复杂语句和上下文 | 质量明显提升,较自然 | 中等,合适 GPU 满足交互 | 处理常见任务,复杂任务有不足 | 适中 |
| 8B | 理解复杂语义和长文本能力增强 | 更流畅准确,内容更丰富 | 与 7B 相近或略慢 | 应对挑战任务能力提升 | 稍高于 7B |
| 14B | 强,深入理解复杂语境 | 质量高,接近人类写作 | 慢,需强 GPU | 处理复杂长文本和专业问答 | 较高 |
| 32B | 达较高水准,处理极复杂语义 | 卓越,可生成高质量文档 | 慢,需高端 GPU | 处理各类复杂任务,专业出色 | 高 |
| 70B | 顶尖,处理高难度专业任务 | 顶尖,用于专业创作 | 极慢,需硬件集群 | 几乎能处理所有 NLP 任务 | 极高 |
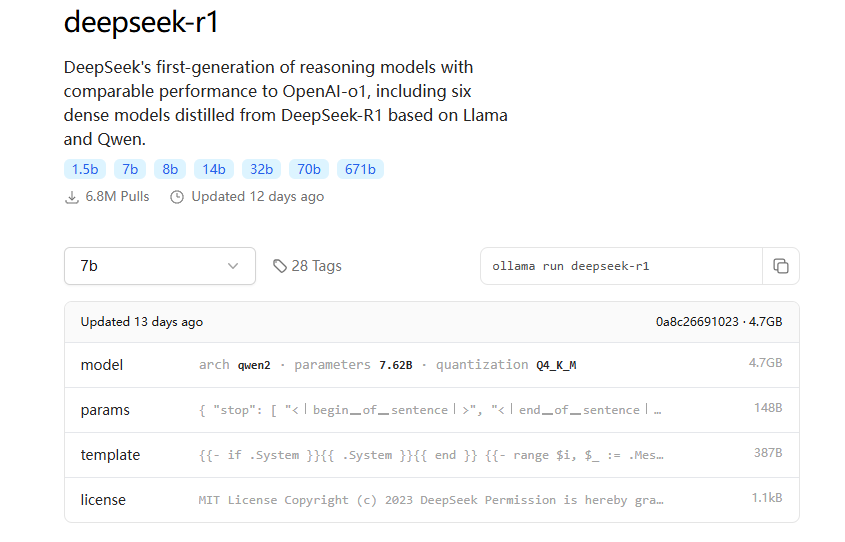
Ollama网站展示了DeepSeek R1的信息,软件大小约4.7GB,详情链接如下:
https://ollama.com/library/deepseek-r1
下载和安装DeepSeek R1 7B非常简单,你只需要快捷键Win+R,输入cmd打开命令行。
然后直接输入以下代码串,按回车键即可:
ollama run deepseek-r1
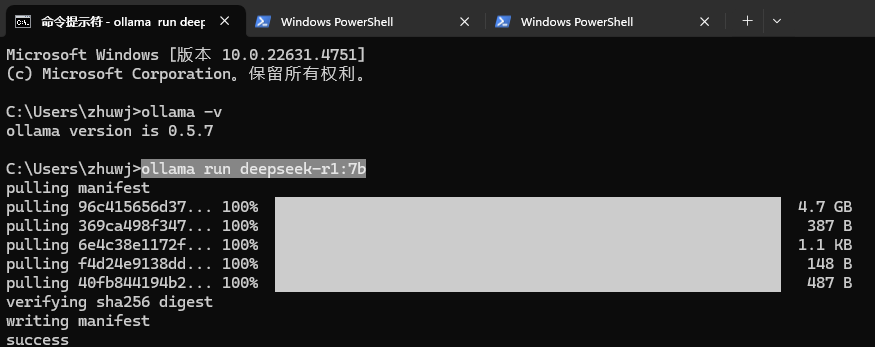
因为ollama已经在后台运行,所以它会直接下载DeepSeek R1 7B模型,并安装好。
当你看到success代表安装成功了(提示下需要科学上网)。
第三步:在ollama上使用DeepSeek R1
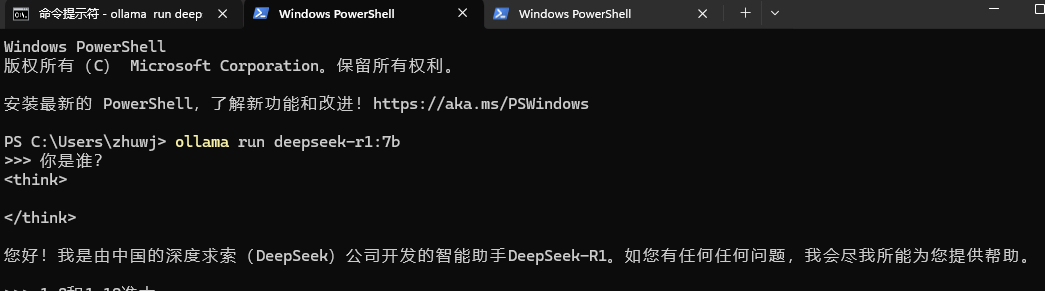
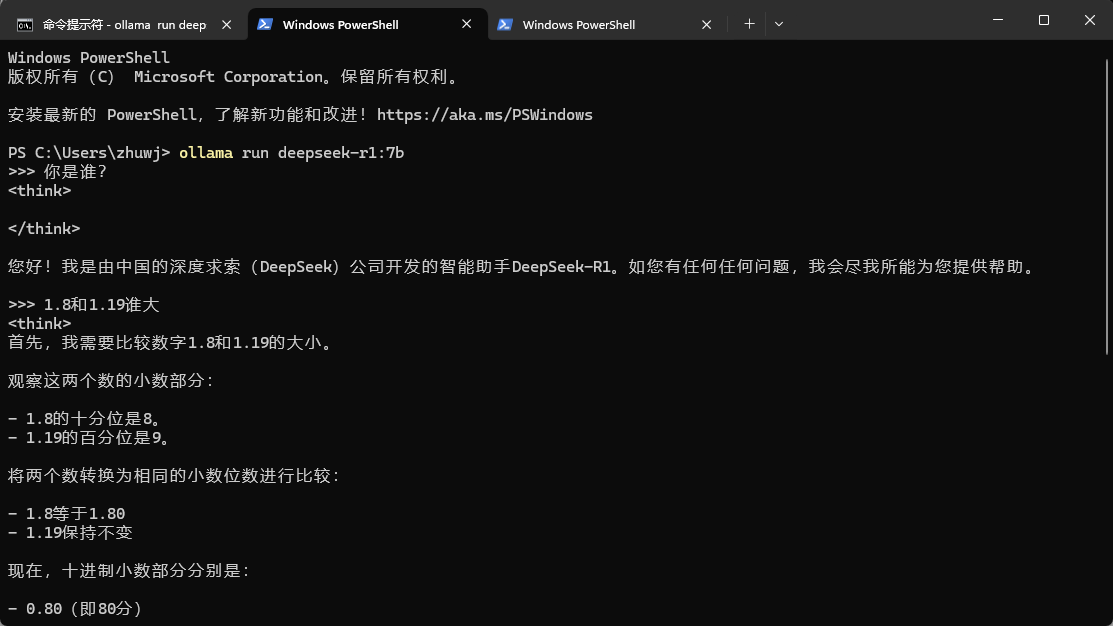
安装好DeepSeek R1 7B模型后,还是打开命令行输入以下代码串,就可以在命令行直接和DeepSeek聊天。
ollama run deepseek-r1
以我的电脑配置来看,模型回复的速度还不错,大概2~5秒就会给出答复。如果你能配置更好的GPU,比如RTX 3060,响应速度应该会非常快,基本在1~2秒左右。
咱们让它写段Python代码,看看编程能力怎么样。
提示:请写个Python脚本,实现产品线合格产品和不合格产品的分类模型,请你模拟参数,指标有尺寸、强度
下面是DeepSeek的思考过程。
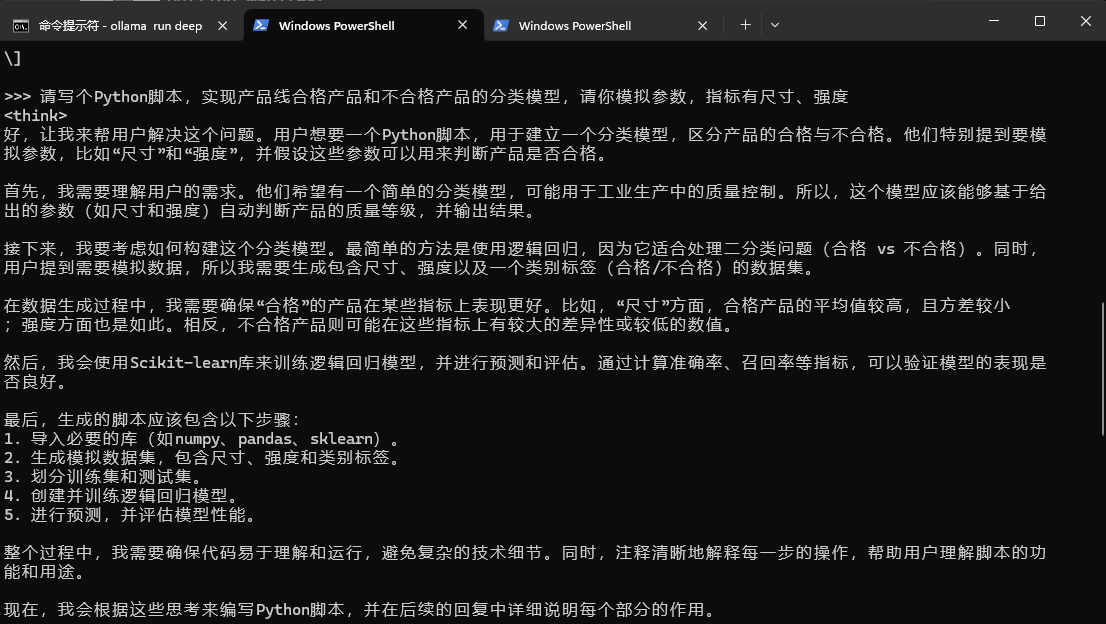
然后是给出的回答。
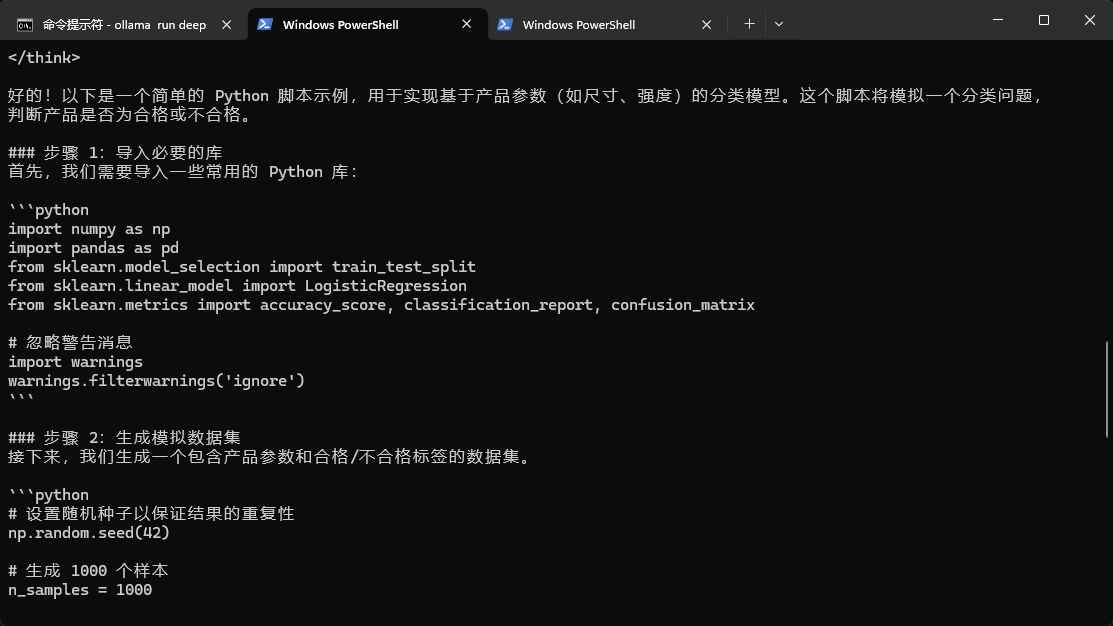
本地部署的DeepSeek回答形式和APP差不多,有思考和正式回答两部分,回答的质量也蛮不错。
但这样的UI界面看着实在是不舒服,不用急,有更好的解决方案。
第四步:在Cherry-studio上使用DeepSeek R1
Cherry-studio是可以运行本地大语言模型并能进行UI交互的桌面客户端,类似于DeepSeek APP,咱们只需要接入刚刚在ollama上配置好的DeepSeek R1模型,就能享受更好用的AI对话界面。
直接在Cherry官网下载软件,一路next安装即可。
https://cherry-ai.com/download
安装好后界面如下。
接下来是配置ollama并选择DeepSeek R1 7B模型。
点击右下角的设置按钮,模型服务选择ollama。
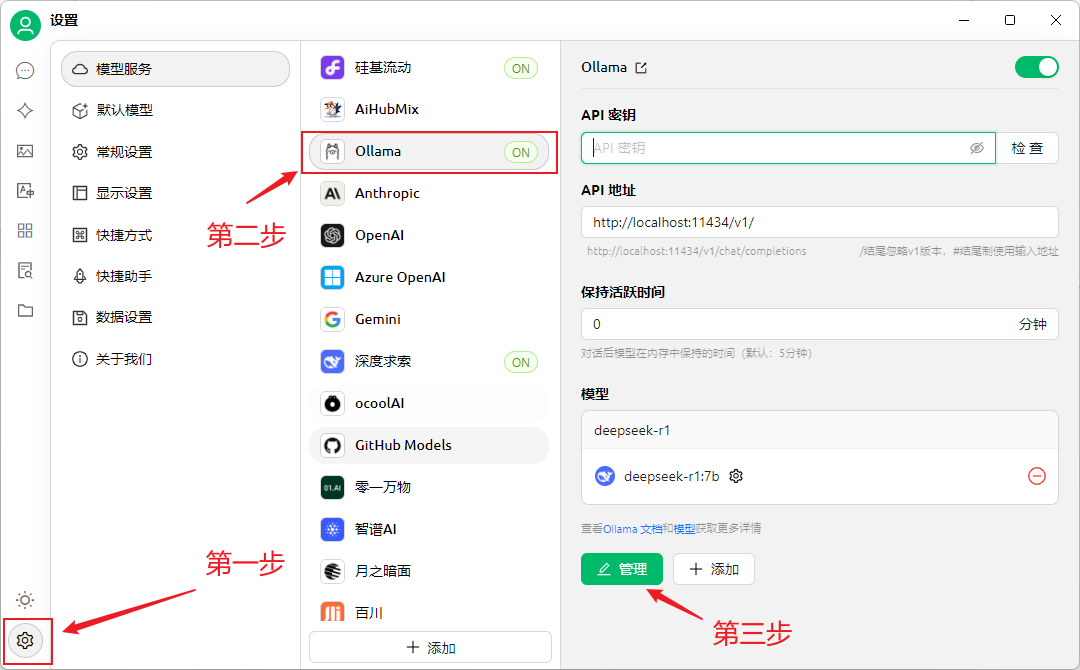
然后选择DeepSeek R1 7B模型,我之前也下载了llama3.1,所以这里都会显示出来。
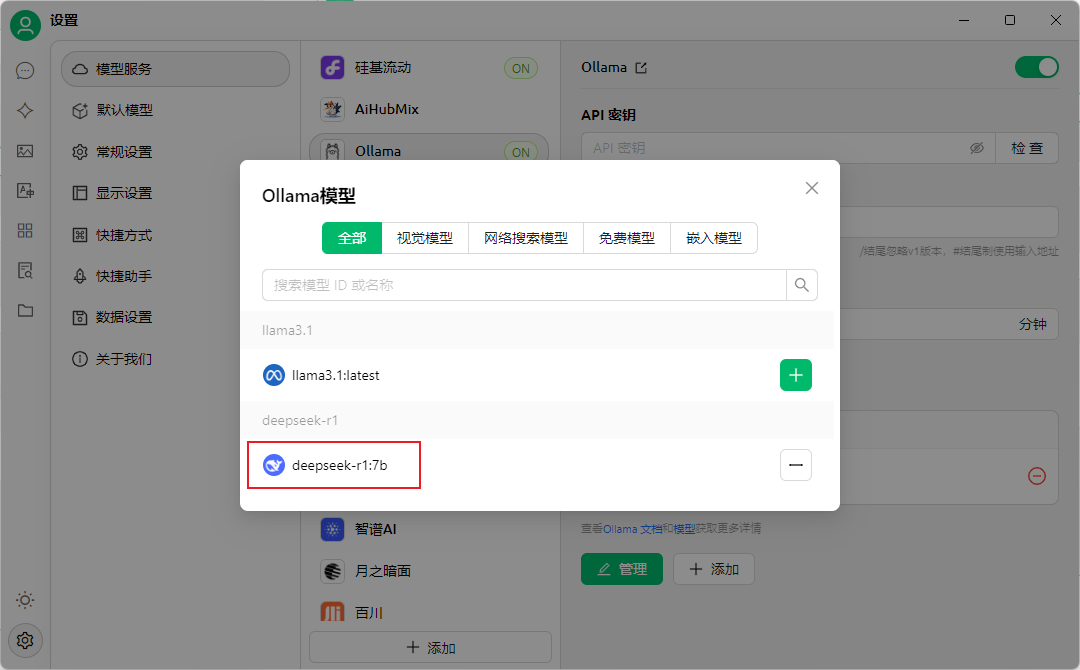
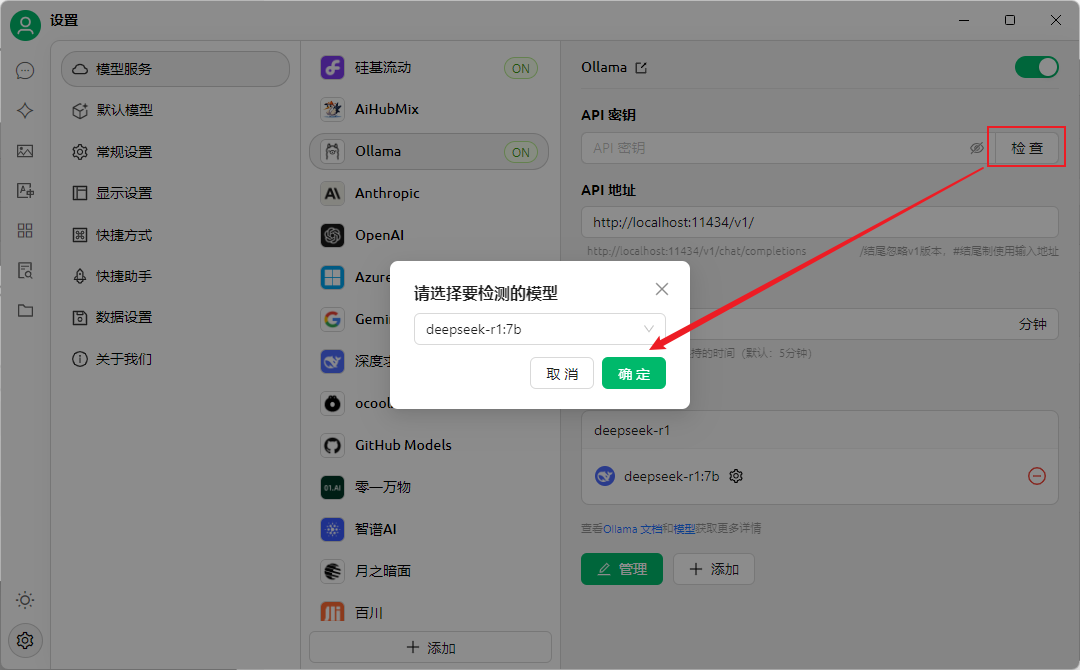
最后点击检查,没有问题即代表配置成功了。
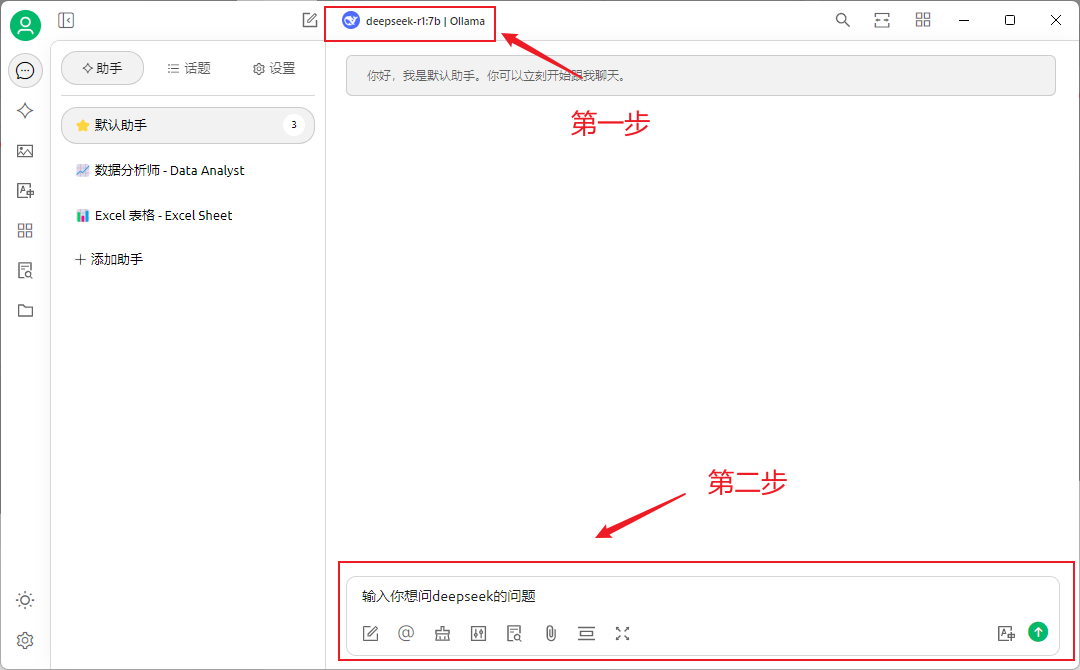
回到对话框界面,选择DeepSeek R1 7B模型,就可以开始对话。
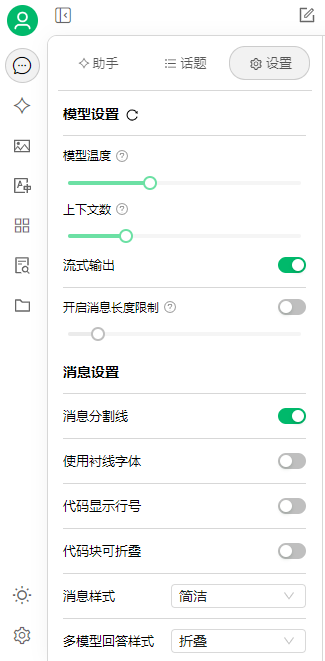
你可以设置模型对话的配置,比如模型温度、上下文数、长度限制,还有消息显示的设置等等。
这里简单说下模型温度是一个取值通常在 0 到 1 之间(也可大于 1)的超参数,它用于控制模型生成文本时的随机性和创造性程度。
如果是写作创意类对话则数值越大越好,如果是编程和数学推理类的对话则数值越大越好。
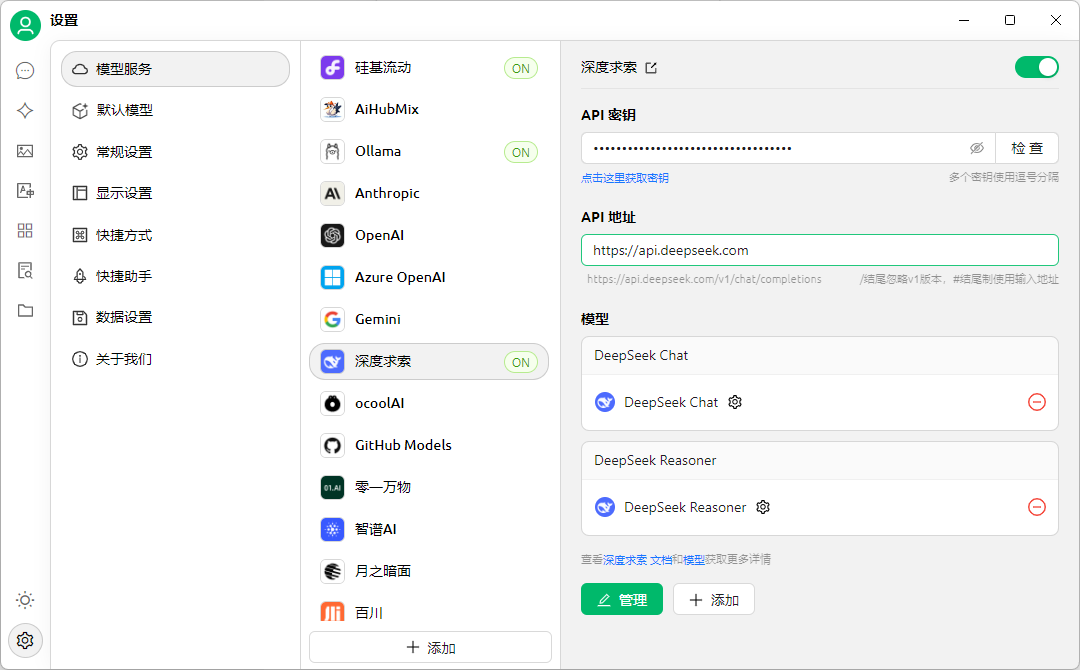
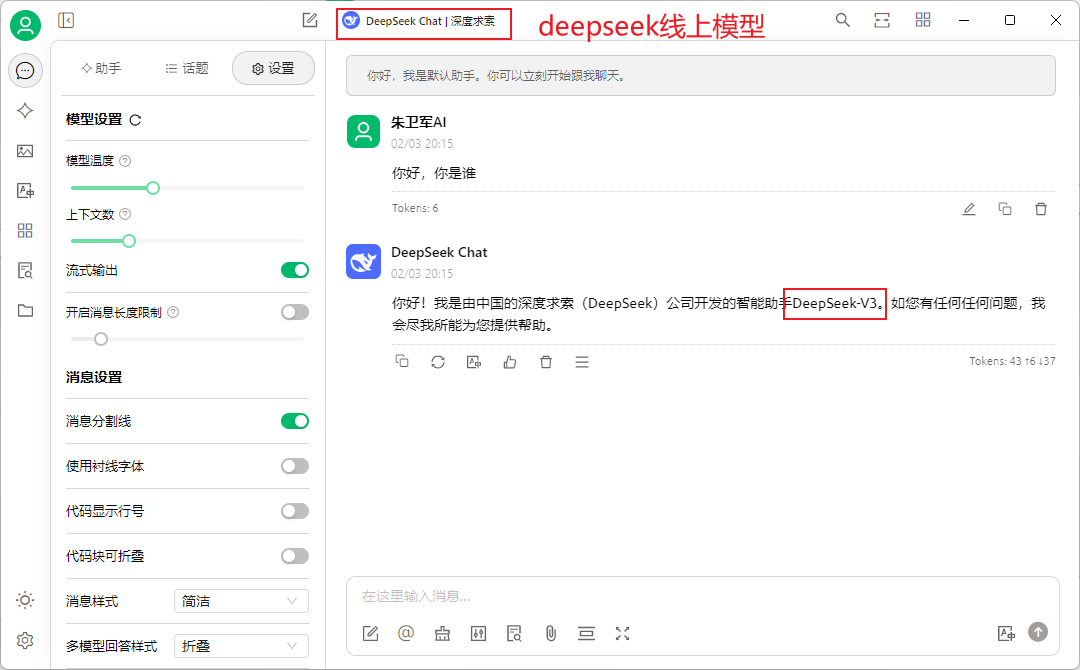
Cherry上还有很多高级的配置,比如接入DeepSeek官方API实现线上模型的对话,配置也很简单,输入key即可。
补充:使用LM Studio配置本地大模型
LM Studio也是一款在本地运行大模型的应用,和ollama类似,不过拥有交互式UI界面,相当于ollama+cherry的组合体。
LM Studio可以从HuggingFace存储库下载任何兼容的模型文件,并部署到本地。
简单介绍下HuggingFace,HuggingFace是一个大模型存储平台,提供了大量预训练模型、数据集,其中就包括DeepSeek R1。
最后
在电脑本地部署DeepSeek有很多的好处,不用担心线上模型掉线、数据隐私安全,还可以做很多定制化的应用,比如本地客服、培训教育、企业文档等有很多场景,大家可以多多探索。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 30
30 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)