[论文阅读] AI+教育 | 不仅会解题,还会出题!AutoCode 让 LLM 生成 4.2%“自难而解” 的竞赛题,人类专家认可 3.2% 达 ICPC 级
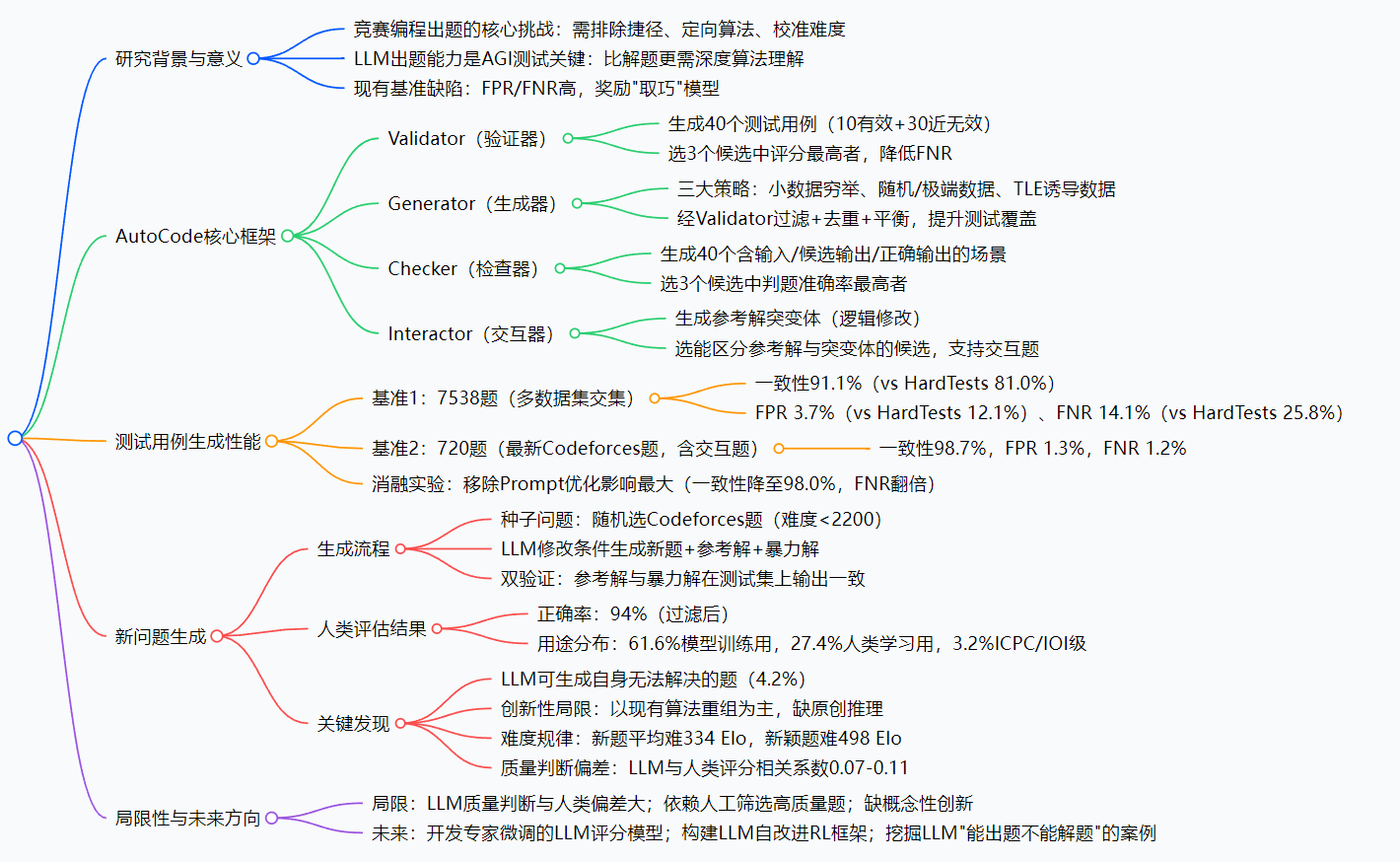
AutoCode提出一种基于LLM的闭环框架,用于生成和验证竞赛编程问题。该框架包含Validator、Generator、Checker和Interactor四大组件,模拟人类出题流程:Validator过滤无效输入以降低假阴性率,Generator通过多策略生成对抗性测试用例以降低假阳性率,Checker确保判题准确性,Interactor支持交互题测试。在7538题基准集上,AutoCode
不仅会解题,还会出题!AutoCode 让 LLM 生成 4.2%“自难而解” 的竞赛题,人类专家认可 3.2% 达 ICPC 级
论文信息
- 论文原标题:AutoCode: LLMs as Problem Setters for Competitive Programming
- 主要作者及研究机构:1University of California San Diego, 2New York University, 3University of Washington, 4Princeton University, 5Canyon Crest Academy, 6OpenAI, 7University of California Berkeley, 8Massachusetts Institute of Technology, 9University of Waterloo, 10Sentient Labs
- 项目主页:Project page: https://livecodebenchpro.com/projects/autocode/overview
1. 一段话总结
AutoCode是由多机构团队提出的、基于LLM的竞赛编程问题生成与测试框架,其核心是闭环多角色Validator-Generator-Checker(含Interactor)架构,通过多轮验证实现竞赛级问题陈述与测试用例生成;在测试用例生成上,AutoCode在7538题基准集上与官方判断一致性达91.1% ,显著优于HardTests等现有方法(≤81%),且在720题复杂Codeforces基准集上一致性提升至98.7% ,同时大幅降低假阳性率(FPR降至3.7%)与假阴性率(FNR降至14.1%);在新问题生成上,AutoCode以随机种子问题为基础,通过参考解与暴力解双验证协议过滤27%有问题的题目,使LLM生成参考解的正确率从86%提升至94%,最终经人类专家验证,61.6%的生成题可用于模型训练,3.2%达ICPC/IOI竞赛级别,且发现LLM能生成自身无法解决的合理问题(约4.2%),但在问题创新性上仍以现有算法重组为主,与人类对质量的判断存在显著偏差(相关系数仅0.07-0.11)。
2. 思维导图(mindmap)
3. 详细总结
1. 研究背景与核心动机
竞赛编程题目设计对专业性要求极高,需满足三大核心条件:排除捷径解法(通过约束、输入分布、边缘案例)、定向考察特定算法(如最大流、动态规划、数据结构)、校准难度超越多数参赛者。而现有LLM能力评估多聚焦解题,忽略出题能力——作者认为,出题能力是LLM通用智能(AGI)的关键测试维度,原因如下:
- 出题比解题更需深度算法理解:解题可依赖模板或部分正确代码,而出题需覆盖所有可能解法的验证(含时间复杂度检测);
- 现有基准数据集缺陷显著:CodeContests+、HardTests等数据集存在高假阳性率(FPR,错误解法被误判正确)与高假阴性率(FNR,正确解法被误判错误),导致模型评估失真;
- 出题能力支撑LLM自改进:高质量新题可用于LLM编程能力的强化学习(RL),推动其向复杂软件开发场景落地。
2. AutoCode核心框架:闭环多角色验证体系
AutoCode的核心是Validator-Generator-Checker(含Interactor)闭环架构,模拟人类出题流程,确保测试用例与新问题的可靠性,各组件细节如下:
| 组件 | 核心功能 | 实现步骤(关键算法) | 核心目标 |
|---|---|---|---|
| Validator | 验证输入是否符合题目约束 | 1. LLM生成40个测试用例(10有效+30近无效);2. 生成3个候选Validator;3. 选评分最高者 | 降低FNR(避免正确解因无效输入失败) |
| Generator | 生成多样化、对抗性测试用例 | 1. 三大策略:小数据穷举(覆盖边界)、随机/极端数据(溢出/精度)、TLE诱导数据(测复杂度);2. 过滤无效输入+去重+平衡 | 降低FPR(识别错误/低效解) |
| Checker | 对比参赛者输出与正确答案,给出判题结果 | 1. LLM生成40个场景(输入+候选输出+正确输出+预期判题);2. 生成3个候选Checker;3. 选准确率最高者 | 确保判题准确性 |
| Interactor | 支持交互式题目(如多轮查询类问题)的测试 | 1. 生成参考解的"突变体"(小逻辑修改,如符号错误、边界漏检);2. 选能区分参考解与突变体的候选 | 填补交互式题目测试空白 |
3. 测试用例生成性能评估
作者设计两大基准集验证AutoCode的测试用例可靠性,关键指标为一致性(与官方判题的吻合度)、FPR(错误解被误判正确的比例)、FNR(正确解被误判错误的比例) 。
3.1 基准1:7538题通用集(多数据集交集)
该数据集来自CodeContests、CodeContests+、HardTests、TACO的交集,无交互式题目,难度略低于常规Codeforces竞赛,对比结果如下:
| 方法 | 一致性(%)(↑) | FPR(%)(↓) | FNR(%)(↓) |
|---|---|---|---|
| CodeContests | 72.9 ± 0.2 | 7.7 ± 0.2 | 46.3 ± 0.3 |
| CodeContests+ | 79.9 ± 0.2 | 8.6 ± 0.2 | 31.6 ± 0.3 |
| TACO | 80.7 ± 0.2 | 11.5 ± 0.2 | 26.9 ± 0.3 |
| HardTests | 81.0 ± 0.2 | 12.1 ± 0.2 | 25.8 ± 0.3 |
| AutoCode | 91.1 ± 0.1 | 3.7 ± 0.1 | 14.1 ± 0.2 |
由表可见,AutoCode的一致性比现有最佳方法(HardTests)提升10.1个百分点,FPR与FNR均降低约50%,显著改善测试可靠性。
3.2 基准2:720题复杂集(最新Codeforces题)
该数据集包含未过滤的近期Codeforces题目(含交互式题目),现有方法因代码未开源无法评估,AutoCode表现如下:
- 一致性:98.7%
- FPR:1.3%
- FNR:1.2%
3.3 消融实验(720题基准)
为验证各组件作用,作者移除单一组件后测试性能,结果如下:
| 配置 | 一致性(%) | FPR(%) | FNR(%) |
|---|---|---|---|
| 移除小数据穷举策略 | 98.4 ± 0.2 | 1.7 ± 0.2 | 1.3 ± 0.3 |
| 移除随机/极端数据策略 | 98.4 ± 0.2 | 1.6 ± 0.2 | 1.3 ± 0.3 |
| 移除TLE诱导数据策略 | 98.6 ± 0.2 | 1.4 ± 0.2 | 1.3 ± 0.3 |
| 移除Prompt优化 | 98.0 ± 0.2 | 1.8 ± 0.2 | 2.9 ± 0.4 |
| AutoCode完整框架 | 98.7 ± 0.1 | 1.3 ± 0.2 | 1.2 ± 0.3 |
结论:Prompt优化对性能影响最大,移除后FNR翻倍;三大生成策略互补,共同降低FPR。
4. 新问题生成流程与评估
AutoCode在测试用例框架基础上,新增双验证协议实现高质量新问题生成,具体流程与结果如下:
4.1 生成流程
- 种子问题选择:随机选取Codeforces题目(难度<2200),模拟人类出题时"基于现有题修改"的习惯;
- LLM生成内容:LLM通过添加/删除/修改条件,生成三部分内容:新问题陈述、高效参考解(std.cpp)、暴力解(brute.cpp,复杂度高但正确性易保证);
- 双验证过滤:用AutoCode生成的测试集运行参考解与暴力解,仅保留两者输出完全一致的题目(暴力解超时除外),过滤27%有问题的题目。
4.2 人类专家评估结果
作者邀请8位资深竞赛编程出题者,按6级标准(Level 1-6,需满足本级及所有低级要求)评估生成题,结果如下:
| 评估级别 | 达标要求 | 达标比例 | 关键说明 |
|---|---|---|---|
| Level 1 | 可解(Solvability=Yes) | 91.6% | 排除不可解题目 |
| Level 2 | 参考解正确(Solution Correctness=Yes) | 76.3% | 经双验证后提升至94% |
| Level 3 | 质量评分≥3(可用于模型训练) | 61.6% | 题目清晰、可解,无严重缺陷 |
| Level 4 | 质量评分≥4(人类学习可用) | 27.4% | 含至少一个巧妙思路 |
| Level 5 | 新颖(Novelty=Yes) | 17.4% | 未在现有竞赛/题库中出现 |
| Level 6 | 质量评分≥5(ICPC/IOI级) | 3.2% | 竞赛级质量,优雅且难度适中 |
4.3 关键发现
- LLM的"出题-解题能力分离":约4.2%的生成题可被人类/其他模型解决,但生成该题的LLM自身无法正确解题,为LLM自改进提供潜在数据;
- 创新性局限:LLM生成题以"现有算法重组"为主(如拼接动态规划与图论),缺乏需原创推理范式的问题,且更侧重考察算法知识而非巧妙观察;
- 难度规律:生成题平均比种子题难334 Elo,其中新颖题平均难498 Elo,非新颖题仅难108 Elo;中等难度种子题(Codeforces 1800-2200分)易生成高质量题;
- 质量判断偏差:LLM自评估与人类评分的相关系数仅0.07(质量)和0.11(新颖性),但人类内部(0.71)、LLM内部(GPT-4o与o3为0.72)一致性高,说明LLM缺乏人类对齐的质量标准。
5. 局限性与未来方向
5.1 主要局限性
- 质量判断依赖人工:LLM无法可靠评估题目的质量与新颖性,需人类筛选竞赛级题目;
- 创新性不足:生成题以现有算法重组为主,缺乏概念性创新;
- 自改进落地难:closed-source LLM(如GPT-5)无RL所需API,开源LLM缺乏成熟的大规模RL框架。
5.2 未来研究方向
- 开发专家微调的LLM评分模型:用人类标注的高质量题库微调LLM,替代人工筛选;
- 构建LLM自改进闭环:将AutoCode生成的高质量题用于RL,提升LLM编程能力;
- 挖掘"LLM能出题不能解题"的案例:无需人工干预,自动识别这类题目,用于针对性能力提升。
4. 关键问题与答案
问题1:AutoCode在测试用例生成上较现有方法(如HardTests)的核心优势是什么?这些优势如何通过具体设计实现?
答案:AutoCode的核心优势是更高的判题一致性、更低的FPR与FNR,在7538题基准集上,一致性达91.1%(HardTests为81.0%),FPR 3.7%(HardTests 12.1%),FNR 14.1%(HardTests 25.8%),优势通过三大设计实现:
- 闭环多角色架构:Validator过滤无效输入(降低FNR),Generator用小数据穷举+随机/极端数据+TLE诱导数据(覆盖边界、复杂度测试,降低FPR),Checker通过场景测试选最优判题逻辑(确保判题准确);
- 多候选择优策略:Validator、Checker、Interactor均生成3个候选,通过针对性测试(如Validator用40个测试用例评分)选最优,避免单一候选的逻辑缺陷;
- 交互式题目支持:Interactor通过生成参考解"突变体",选能区分正确解与错误解的候选,填补现有方法在交互式题目测试上的空白(如720题基准集含交互题,AutoCode仍达98.7%一致性)。
问题2:AutoCode的"双验证协议"如何确保新问题的正确性?该协议对LLM生成参考解的正确率有何提升效果?
答案:"双验证协议"是AutoCode确保新问题正确性的核心机制,具体流程与效果如下:
- 协议设计逻辑:利用"暴力解正确性易验证"的特点(暴力解复杂度高但逻辑简单,如O(n³)的区间统计),将其作为"临时真值",与LLM生成的高效参考解(如O(n)的优化算法)对比;
- 执行步骤:① 用AutoCode的Generator生成覆盖小案例、边缘情况的测试集;② 分别运行参考解与暴力解;③ 仅保留两者输出完全一致的题目(暴力解因超时未输出除外),排除参考解逻辑错误的题目;
- 正确率提升效果:未经过滤时,LLM生成参考解的正确率为86%;经双验证协议过滤后,正确率提升至94%,过滤掉27%因参考解逻辑缺陷导致的"坏题",大幅提升新问题的可靠性。
问题3:LLMs在生成竞赛编程问题时,主要的能力优势与局限是什么?这些局限对未来LLM竞赛编程能力提升有何启示?
答案:LLMs生成竞赛编程问题的能力优势与局限,及对未来的启示如下:
- 能力优势:① 高效的"现有知识重组"能力:可快速基于种子题修改条件,生成考察多算法组合的题目(如将排列问题与区间统计结合);② 高可扩展性:能批量生成符合基础质量要求的题目(61.6%达模型训练标准);③ "出题-解题分离"特性:可生成自身无法解决的合理题目(4.2%),为自改进提供数据;
- 核心局限:① 创新性不足:以现有算法重组为主,缺乏需原创推理范式的问题(如全新的贪心策略设计);② 质量判断偏差:与人类对"新颖性""优雅度"的判断相关性极低(相关系数0.07-0.11);③ 难度控制不稳定:对极难/极简单种子题,难生成高质量题;
- 启示:① 针对性优化创新能力:设计Prompt策略鼓励LLM突破现有算法框架,或引入"人类创新思路标注"微调;② 构建人类对齐的评分模型:用专家标注的高质量题库微调LLM,替代人工筛选;③ 聚焦中等难度种子题:优先以Codeforces 1800-2200分题目为种子,提升高质量题生成效率;④ 挖掘"能出题不能解题"案例:自动识别这类题目,用于LLM薄弱推理环节的强化学习。
研究背景:竞赛编程出题,比解题难多了!
如果把竞赛编程比作“数学考试”,那“解题”就是学生答卷子,“出题”就是老师出卷子——后者要难得多。老师出一道好题,得确保三件事:没捷径可走(不能让学生用简单公式蒙混过关)、考特定知识点(比如只考微积分,不考代数)、难度刚好卡住多数人(不能太简单也不能超纲)。竞赛编程出题也是如此,但现有技术完全跟不上需求。
首先,LLM的“考试范围”太窄了。现在大家只关注LLM会不会“答题”(解题),却忽略了它会不会“出题”。但实际上,出题更能体现真本事:解题时,LLM能靠模板套答案;而出题时,它得预判所有可能的解法,甚至要设计“坑”(比如时间复杂度陷阱),这需要对算法的深度理解。
其次,现有“判分标准”太不靠谱。就像老师判卷时经常误判,现有数据集(比如HardTests)判题时,错误解法常被误判正确(假阳性率FPR高达12.1%),正确解法常被误判错误(假阴性率FNR高达25.8%)。这导致用这些数据集评估LLM时,结果完全失真——可能一个“半吊子”LLM被捧成高手,一个真高手被冤枉成菜鸟。
最后,“题库更新”太慢了。竞赛编程需要大量新题来训练LLM,但人工出题效率极低,一道ICPC级别的题可能要几个专家磨一周。如果能让LLM自动生成高质量新题,就能快速扩充题库,推动LLM编程能力再上台阶。这就是AutoCode诞生的原因:解决“出题难、判题准、题库少”三大痛点。
创新点:AutoCode的3个“独门绝技”
AutoCode之所以能超越现有方法,核心在于它跳出了“单一模块生成”的思路,用3个创新设计构建了闭环能力:
-
多角色闭环架构:首次模拟人类出题全流程,让Validator、Generator、Checker、Interactor各司其职又互相配合。比如Validator先“审题”过滤无效输入,Generator再“编考题”,Checker最后“判分”——就像一个出题小组分工协作,避免了单一模块的片面性。
-
双验证协议过滤“坏题”:针对LLM生成新题时“参考解出错”的问题,AutoCode引入“暴力解”当“裁判”。暴力解虽然效率低(比如O(n³)),但逻辑简单、正确率高,AutoCode让参考解和暴力解在测试集上对答案,只有两者完全一致的题目才保留,直接过滤掉27%的“坏题”。
-
交互题测试“零空白”:之前的方法都搞不定“交互题”(比如需要多轮输入输出的题目,像游戏闯关一样),AutoCode的Interactor会生成“参考解突变体”(比如改个符号、漏个边界判断),专门选能区分“正确解”和“突变体”的测试用例,填补了这一空白。
研究方法和思路:AutoCode是怎么“工作”的?
AutoCode的逻辑很简单:先做好“判题”(测试用例生成),再做好“出题”(新问题生成),两步都靠“多候选+严筛选”保证质量。
第一步:测试用例生成(解决“判题准”问题)
这一步是AutoCode的核心,由3个模块+1个辅助模块协同完成,每个模块都遵循“生成多个候选→筛选最优”的逻辑:
-
Validator(输入验证):当“审题官”,确保测试用例符合题目要求。
- 步骤1:LLM生成40个测试用例,其中10个是明显符合要求的“有效用例”,30个是擦边球“近无效用例”(比如输入值刚好超一点范围)。
- 步骤2:基于这40个用例,生成3个Validator候选(相当于3个审题方案)。
- 步骤3:评分选出最优Validator,避免因“漏看无效输入”导致正确解法失败(降低FNR)。
-
Generator(测试用例生成):当“编题员”,生成能难住错误解法的“坑题”。
- 步骤1:用3大策略生成用例:
- 小数据穷举:覆盖边界情况(比如n=1、n=1e5);
- 随机/极端数据:测试溢出、精度问题(比如超大数、浮点数);
- TLE诱导数据:专门测试时间复杂度(比如让O(n²)解法超时)。
- 步骤2:用Validator过滤无效用例,再去重、平衡用例类型,确保覆盖所有考点。
- 步骤1:用3大策略生成用例:
-
Checker(判题校验):当“判分老师”,确保判题结果准确。
- 步骤1:生成40个“判题场景”,每个场景包含“输入+候选输出+正确输出+预期判题结果”(比如输入[1,2,3],候选输出[3,2,1],正确输出[1,2,3],预期判“错误”)。
- 步骤2:生成3个Checker候选,选在这些场景中准确率最高的,避免判题失误。
-
Interactor(交互题辅助):专门处理交互题,比如需要多轮输入的题目。
- 步骤1:生成“参考解突变体”——在正确参考解上改一点(比如把“>”改成“≥”),制造一个隐蔽的错误解法。
- 步骤2:选能区分“参考解”和“突变体”的测试用例,确保交互题判题准确。
第二步:新问题生成(解决“题库少”问题)
在测试用例框架的基础上,AutoCode增加了“双验证”流程,确保新题质量:
- 选种子题:从Codeforces中随机选难度<2200的题(中等难度最易生成好题)。
- LLM生成内容:让LLM修改题目条件(比如把“求最大值”改成“求第k大值”),同时生成3样东西:新问题陈述、高效参考解(比如O(n)的优化算法)、暴力解(比如O(n²)的简单算法)。
- 双验证过滤:用AutoCode生成的测试集,分别运行参考解和暴力解。只有两者输出完全一致(暴力解超时除外)的题目才保留——这一步直接过滤掉27%参考解出错的“坏题”。
主要成果和贡献:AutoCode到底有多厉害?
AutoCode的成果可以用“两个维度、三个突破”来概括,每一个都实实在在解决了行业痛点。
维度1:测试用例生成(判题更准)
在两个权威基准集上,AutoCode的性能全面超越现有方法,尤其是复杂题目的表现堪称“完美”。
| 测试基准 | 对比方法 | 一致性(与官方判题) | 假阳性率FPR(↓) | 假阴性率FNR(↓) |
|---|---|---|---|---|
| 7538题通用集 | HardTests(现有最佳) | 81.0% | 12.1% | 25.8% |
| 7538题通用集 | AutoCode | 91.1% | 3.7% | 14.1% |
| 720题Codeforces集(含交互题) | 无(现有方法未覆盖) | 98.7% | 1.3% | 1.2% |
价值:从此用LLM评估竞赛编程能力时,不用再担心“误判”——比如一个正确的解法不会被冤枉,一个靠取巧的错误解法也骗不过判题系统。
维度2:新问题生成(题库更多)
AutoCode让LLM生成新题的质量大幅提升,还挖出了LLM的“隐藏能力”。
| 评估指标 | 结果 | 价值说明 |
|---|---|---|
| 参考解正确率(过滤后) | 94%(原86%) | 减少27%的“坏题”,降低人工筛选成本 |
| 模型训练可用题比例 | 61.6% | 快速扩充LLM训练题库,不用全靠人工出题 |
| ICPC/IOI级题目比例 | 3.2% | 生成专业级竞赛题,为赛事提供新题源 |
| “自难而解”题比例 | 4.2% | 发现LLM能出自己不会解的题,为自改进提供数据 |
核心贡献总结
- 技术层面:提出首个“出题+测试”闭环框架,解决了交互题测试、高准确率判题两大技术难题;
- 数据层面:生成大量高质量新题,尤其是“自难而解”题,为LLM编程能力自改进提供了关键数据;
- 应用层面:可直接用于竞赛出题、LLM评估、编程教学,降低人工成本,推动竞赛编程自动化。
总结
AutoCode作为首个基于LLM的竞赛编程“出题+测试”闭环框架,成功解决了现有技术“判题不准、出题质量低、交互题难覆盖”三大痛点。它通过多角色架构实现了91.1%-98.7%的判题一致性,通过双验证协议将新题正确率提升至94%,还发现了LLM“自难而解”的独特能力,为竞赛编程自动化、LLM编程能力自改进提供了新路径。
但AutoCode也有局限:LLM与人类的题目质量判断偏差大,仍需人工筛选竞赛级题目;LLM生成题的创新性以算法重组为主,缺乏原创性。未来若能通过专家微调优化LLM评分模型,或构建LLM自改进RL框架,有望进一步突破这些局限,让竞赛编程真正进入“AI辅助出题”时代。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)