多模态大模型Detect Anything量化坐标设计思路
本文仅看Rex-Omni中关于坐标量化的思路。Rex-Omni 的核心思路是:将 “连续坐标回归” 转化为 MLLM 擅长的 “离散 token 预测任务”。因此,任务目标就是让 MLLM “能懂坐标”。
本文仅看Rex-Omni中关于坐标量化的思路。
Detect Anything via Next Point Prediction,https://arxiv.org/abs/2510.12798

Rex-Omni 的核心思路是:将 “连续坐标回归” 转化为 MLLM 擅长的 “离散 token 预测任务”。因此,任务目标就是让 MLLM “能懂坐标”。
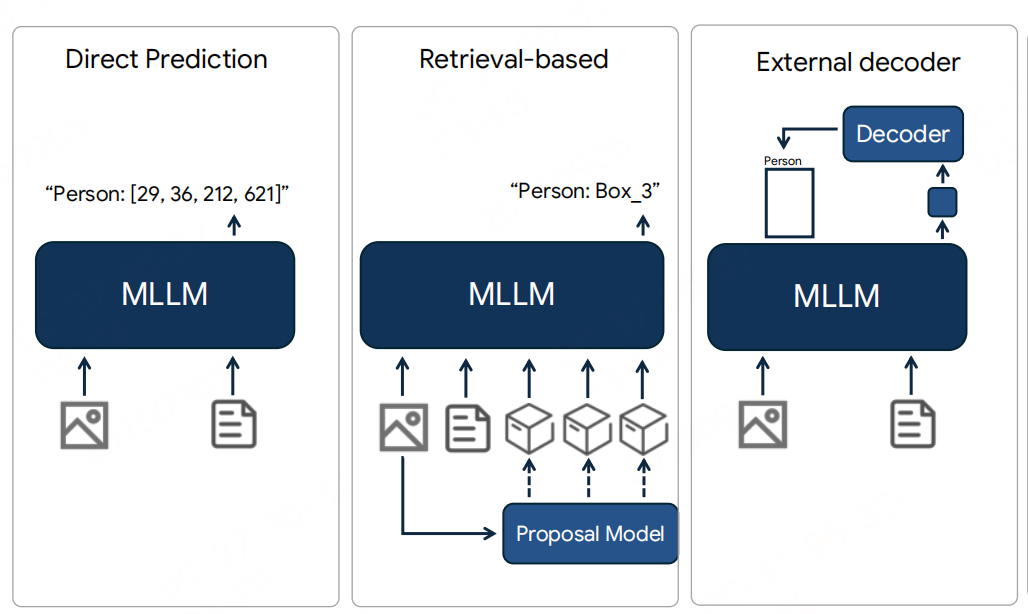

具体做法:
-
坐标量化:将图像坐标系的连续坐标(通常图像尺寸归一化后为01)离散化为**0999的整数范围**。例如,某目标框左上角x坐标为0.321,量化后为321;右下角y坐标为0.876,量化后为876。
- 量化粒度(1000级)的选择:平衡“精度”与“学习难度”——粒度太粗会导致框不准,太细会增加token数量(降低效率),1000级在实验中被验证为最优。
-
特殊token表示坐标:为每个量化后的坐标值(0~999)分配一个专属的特殊token(而非用普通文本token拼接,如“3”“2”“1”表示321)。例如:
- 量化坐标“321”对应特殊token
<321>; - 目标框的4个坐标(x1,y1,x2,y2)=(10,20,40,100)被表示为
<x1> <y1> <x2> <y2>=(<10><20><40><100>)的token序列。
- 量化坐标“321”对应特殊token
-
任务转化为“下一个token预测”:将目标检测任务融入MLLM的核心范式——“序列生成”。例如,输入“检测图像中的猫”,模型需生成“猫 <123> <456> <789> <901>”的序列,其中后4个特殊token即对应猫的目标框。如果是定位文字轮廓(需要多边形),就输出更多符号,比如<10><5><20><5><20><15><10><15>;如果是标点(比如杯子把手),就输出 2 个符号<80><60>。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)