文献阅读(4)——轻量级LoRA模块(LamRA)——(1)
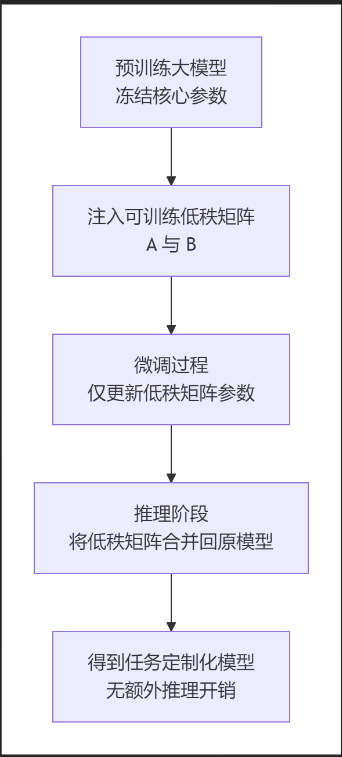
轻量级LoRA(Low-Rank Adaptation,低秩适应)模块是一种用于高效微调大模型的先进技术。它的核心思想非常巧妙:**不直接修改大模型庞大的原始参数,而是通过注入一个极其精简的、“外挂”式的可训练模块来让模型适应新任务。**下面这张流程图清晰地展示了LoRA从微调到推理的完整工作流程。
文章目录
一:问题
1:什么是轻量级LoRA模块?,为了增强LMM的通用检索和重新排序的能力,他应该插在LMM的哪里?
轻量级LoRA(Low-Rank Adaptation,低秩适应)模块是一种用于高效微调大模型的先进技术。它的核心思想非常巧妙:**不直接修改大模型庞大的原始参数,而是通过注入一个极其精简的、“外挂”式的可训练模块来让模型适应新任务。**下面这张流程图清晰地展示了LoRA从微调到推理的完整工作流程。
1:核心原理:低秩适应的智慧
LoRA的聪明之处在于它基于一个关键的观察:当大模型去适应一个新任务时,其所需的参数更新(ΔW)其实具有很低的“内在秩”(rank)。这意味着,尽管模型本身的权重矩阵可能非常大(例如2000x2000),但真正需要调整的部分可以用两个小得多的矩阵(例如2000x10和10x2000)的乘积来有效近似
1:它的工作方式可以概括为以下几个要点:
冻结主干:预训练好的大模型参数被完全“冻结”,在微调过程中保持不变,这就保护了模型已经学到的通用知识。
注入适配器:在模型的关键层(通常是Transformer结构中的注意力层,如Query和Value的投影层)旁,注入一对可训练的低秩矩阵A和B。其中,矩阵A通常用随机高斯分布初始化,矩阵B初始化为零,以确保训练开始时适配器不干扰模型原有输出。
数学表达:对于原始权重矩阵W,其更新过程表示为 W’ = W + BA。这里的B ∈ ℝ^(d×r), A ∈ ℝ^(r×k),而秩r远小于原始矩阵的维度d和k(例如,r=8,而d和k可能是1024)。
问题 1:随即高斯分布(正态分布)是啥?
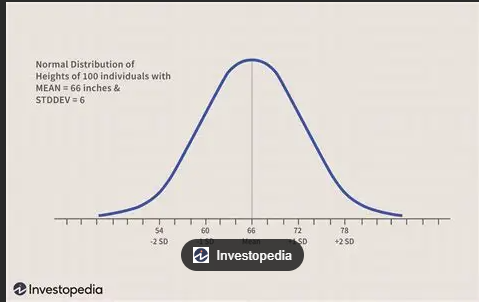
1:初识高斯分布
随机高斯分布是一种非常常见的概率分布,其曲线呈对称的钟形(钟形曲线)。在这种分布中,数值更倾向于集中在平均值附近,远离平均值的数值出现概率较低,在深度学习中,我们经常使用均值为0、方差较小的正态分布来初始化权重,比如 N(0, 0.01),这样可以在训练初期让激活值和梯度保持在一个稳定的范围内。
2:LoRA的初始化策略与原理
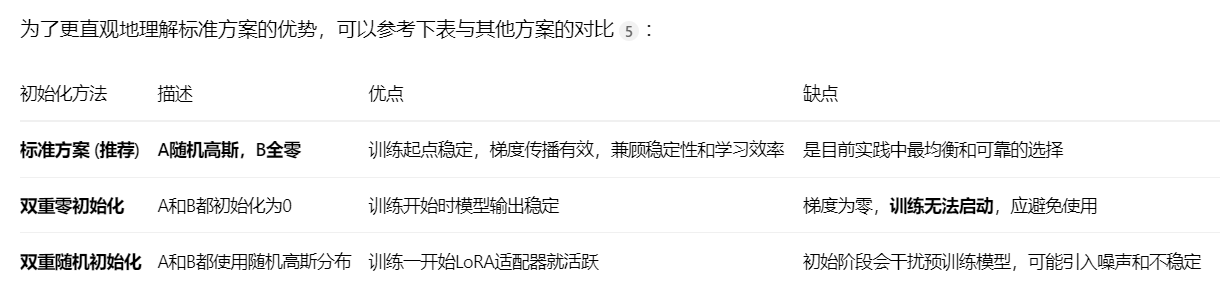
LoRA通过注入两个小的低秩矩阵A和B来微调大模型,而无需更新全部参数。其标准初始化策略如下:
矩阵A:使用随机高斯分布初始化(例如,均值为0,标准差为 σ)。
矩阵B:初始化为全零矩阵。
这种“A随机,B为零”的组合并非随意之举,其背后有深刻的工程智慧:
保证训练起点稳定:由于B初始为0,在训练刚开始时,低秩更新量 ΔW = B*A的结果也是0。这意味着模型的输出与原始的预训练模型完全一致,不会因随机更新而产生初始扰动,有效保护了模型在预训练阶段学到的宝贵知识。
确保有效的梯度流:虽然B初始为0,但随机的A矩阵使得B在训练的第一步就能获得非零梯度并开始更新。而B一旦开始更新,就能带动A的更新。这种设计打破了参数更新的对称性,避免了训练陷入“死循环”,使得学习过程能够顺利启动。
打破对称性:如果A也初始化为0,那么所有参数在起始点完全对称,梯度将为零,模型无法开始有效的学习。
3:与其他初始化方案的对比
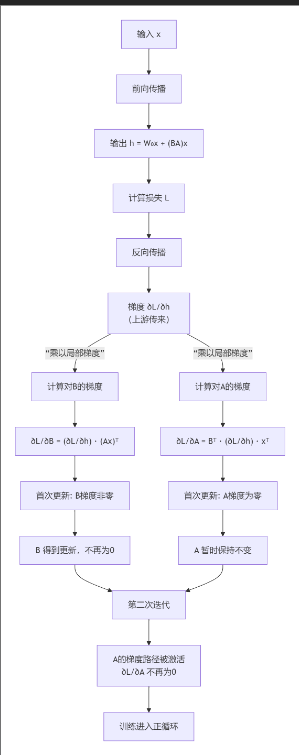
问题 2:为什么,矩阵A,B都初始化为0,梯度就会为0,训练无法启动?
当矩阵A和B都初始化为0时,会导致前向传播的输出不变且反向传播的梯度消失,从而形成一个“死循环”,训练完全无法启动。
1:深入理解:为什么梯度会消失?
根据链式法则,损失函数L对矩阵A和B的梯度计算如下(简化版):

由于梯度直接依赖于A或B本身的值,当它们都是0时,无论上游传来的梯度信号 ∂L/∂ΔW是什么,最终计算结果都是0。没有梯度,优化器(如SGD或Adam)就无法对A和B做出任何调整,因此训练在第一步就卡住了。
2:完整工作流程
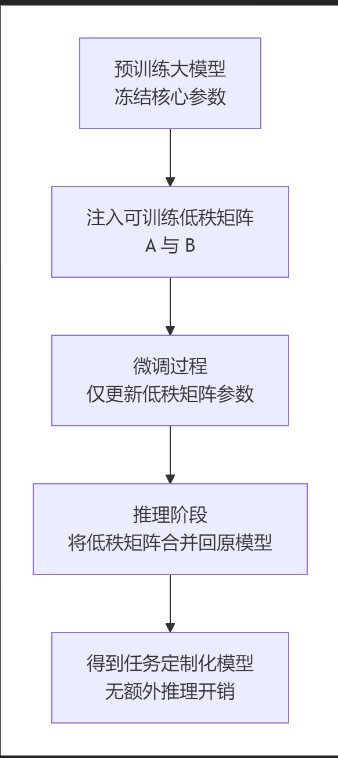
结合上面的流程图,我们来分步详解LoRA的工作流程:
1:准备与注入
首先,选择一个预训练好的基础模型(如LLaMA、GPT等),并锁定其所有参数。然后,根据新任务的需求,确定将LoRA模块插入到模型的哪些部分(通常是注意力机制中的Q、K、V、O投影层)。同时,需要设定一个关键的超级参数——秩(r),它决定了低秩矩阵的大小,是平衡模型能力与效率的核心。
2:微调训练
在微调阶段,只有注入的LoRA适配器(矩阵A和B)中的参数会被优化。基础模型的权重保持不变。由于需要训练的参数数量极剧减少(可能仅为原模型总量的0.1%到1%),训练所需的计算资源、显存和时间都大幅降低,使得在消费级GPU上微调大模型成为可能。
3:推理部署
训练完成后,可以将学习到的低秩更新(BA)直接合并到原始权重中:W’ = W + BA。合并后的模型就是一个独立的新模型,在推理时不会产生任何额外的计算或延迟,保持了和原模型一样的推理速度。另一种更灵活的方式是保持LoRA适配器独立,在推理时根据需要动态加载不同的适配器,让同一个基础模型快速切换不同技能。
总而言之,LoRA技术通过一种巧妙且高效的方式,释放了大模型的定制化潜力,使其能够更便捷地适应各种细分场景,是当前大模型领域一项至关重要的技术。
2:如图所示:LamRA中LamRA-Ret的工作流程是怎么样的?
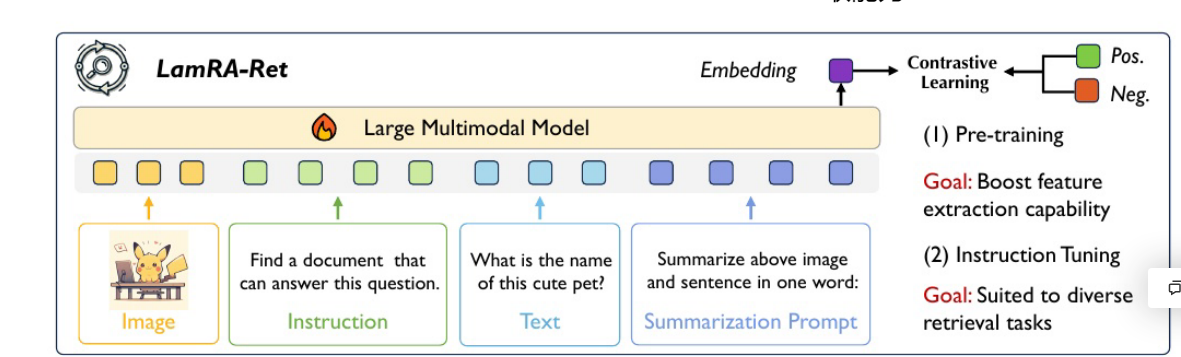
要理解 LamRA-Ret 的工作流程,需从 ** 预训练(Pre-training)和指令微调(Instruction Tuning)** 两个阶段展开,结合多模态输入与对比学习的逻辑详细分析:
1:阶段 1:预训练(Pre-training)—— 增强特征提取能力
预训练的核心目标是让模型学习多模态特征的统一表示,并通过对比学习强化 “正样本(匹配的多模态对)” 和 “负样本(不匹配的多模态对)” 的区分能力。
1:步骤 1:多模态输入与编码
模型接收图像(Image)、指令(Instruction)、文本(Text)、摘要提示(Summarization Prompt) 四种多模态输入:
图像:如示例中的皮卡丘图片,通过模型的视觉编码器转换为视觉特征。
指令:如 “Find a document that can answer this question.”,通过文本编码器转换为文本特征。
文本:如 “What is the name of this cute pet?”,同理转换为文本特征。
摘要提示:如 “Summarize above image and sentence in one word:”,也转换为文本特征。
这些特征会被输入到Large Multimodal Model(大型多模态模型)中,经过多层编码(图中不同颜色的模块),最终输出统一的嵌入向量(Embedding)(紫色方块)。
2:步骤 2:对比学习(Contrastive Learning)
对比学习的目标是让 “匹配的多模态输入对”(正样本,Pos.)的嵌入向量相似度高,“不匹配的对”(负样本,Neg.)相似度低。
正样本构建:将语义匹配的多模态输入(如 “皮卡丘图像” 与 “它的名字是皮卡丘” 的文本)作为正样本对。
负样本构建:将语义不匹配的多模态输入(如 “皮卡丘图像” 与 “其他宠物的文本描述”)作为负样本对。
模型通过计算嵌入向量之间的相似度(如余弦相似度),并最小化对比损失(让正样本对的相似度尽可能大,负样本对的相似度尽可能小),从而优化模型参数,使其能更精准地捕捉多模态数据的语义关联。
2:阶段 2:指令微调(Instruction Tuning)—— 适配多样检索任务
指令微调的核心目标是让模型适配不同类型的检索任务,理解人类指令的意图,并输出符合任务要求的检索结果。
1:步骤 1:多样化指令输入
模型接收各种类型的 “指令 - 多模态数据” 对,例如:
检索类指令:“Find a document that can answer this question.” 结合图像 / 文本,要求模型检索相关文档。
问答类指令:“What is the name of this cute pet?” 结合图像,要求模型回答问题。
摘要类指令:“Summarize above image and sentence in one word:” 结合图像和文本,要求模型生成摘要。
这些指令覆盖了 “检索、问答、摘要” 等多样检索任务,让模型学习不同指令的语义意图。
2:步骤 2:任务适配训练
模型在预训练的基础上,针对 “指令 + 多模态输入” 的组合进行微调:
模型将指令、图像、文本等输入编码为嵌入向量后,根据指令的意图(如 “检索”“问答”),调整输出的嵌入表示,使其更贴合任务需求。
例如,对于 “检索文档” 的指令,模型会优化嵌入向量,使其能与目标文档的嵌入向量更精准匹配;对于 “生成摘要” 的指令,模型会优化嵌入向量,使其能生成简洁的摘要文本。
3:最终输出与应用
经过 “预训练 + 指令微调” 后,LamRA-Ret 模型具备了以下能力:
对图像、文本、指令等多模态数据的统一特征表示能力;
对 “检索、问答、摘要” 等多样检索任务的意图理解与适配能力。
3:如图所示,LamRA中LamRA-Rerank的工作流程是怎么样的?
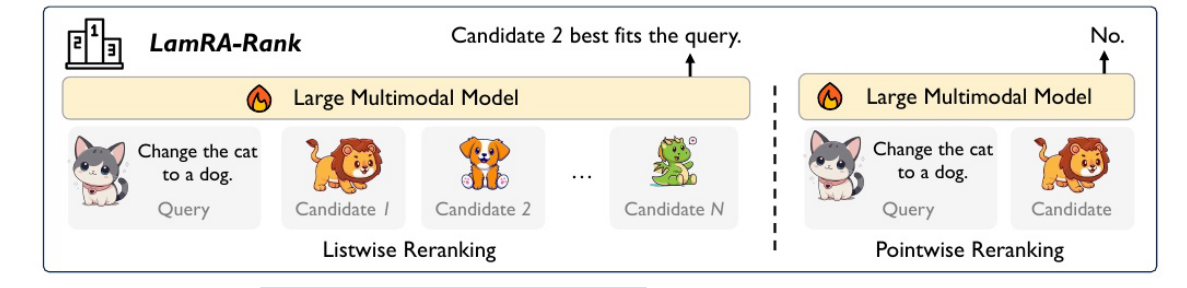
要理解 LamRA-Rerank 的工作流程,需从 Listwise Reranking(列表式重排序)和Pointwise Reranking(点式重排序) 两种策略分别分析,以下是详细拆解:
1:Listwise Reranking(列表式重排序)
列表式重排序的核心是对多个候选对象(Candidate)整体建模,直接输出 “最匹配查询的候选”。
1:步骤 1:输入多模态查询与候选列表
查询(Query):多模态输入,例如图中的 “Change the cat to a dog.”(文本指令 + 猫咪图像)。
候选列表(Candidate 1~N):多个待匹配的多模态对象,例如图中的狮子、小狗、龙等图像。
2:步骤 2:多模态模型编码与排序
将 “查询 + 候选列表” 输入 Large Multimodal Model(大型多模态模型):
模型对 “查询” 和每个 “候选” 进行多模态编码(融合文本、图像等信息)。
计算 “查询” 与每个 “候选” 的语义相似度,并基于相似度对候选列表进行整体排序。
3:输出最优候选
模型直接判断 “哪个候选最匹配查询”,例如图中输出 “Candidate 2 best fits the query.”(候选 2 最匹配)。
2:Pointwise Reranking(点式重排序)
式重排序的核心是对每个候选对象单独建模,判断 “该候选是否匹配查询”。
1:步骤 1:输入多模态查询与单个候选
查询(Query):与列表式一致,例如 “Change the cat to a dog.”(文本 + 图像)。
单个候选(Candidate):例如图中的狮子图像。
2:步骤 2:多模态模型编码与二分类判断
将 “查询 + 单个候选” 输入 Large Multimodal Model:
模型对 “查询” 和 “候选” 分别进行多模态编码,并计算两者的语义关联度。
基于关联度输出二分类结果:“No.”(不匹配,如图所示)或 “Yes.”(匹配)。
3:步骤 3:遍历所有候选,完成重排序
对所有候选重复 “点式判断” 步骤,最终根据 “匹配 / 不匹配” 的结果对候选列表进行重排序。
3:两种策略的差异与适用场景

4:总结
LamRA-Rerank 通过 “列表式整体排序” 和 “点式单独判断” 两种策略,利用大型多模态模型对 “查询 - 候选” 的多模态语义关联进行建模,从而实现对候选对象的精准重排序,满足不同检索场景下的需求。
4:LamRA-Ret 和 LamRA-Rank 之间的关系是怎么样的?
1:模块分工:LamRA-Ret 是 “检索器”,LamRA-Rank 是 “重排序器”
LamRA-Ret(检索器):负责从海量数据中初步筛选出与查询相关的候选对象(可以是文本、图像等多模态数据)。例如,当你查询 “皮卡丘的图片” 时,LamRA-Ret 会从数据库中检索出一批可能相关的图片(如皮卡丘、其他宝可梦、卡通角色等)。
LamRA-Rank(重排序器):负责对 LamRA-Ret 检索出的候选对象进一步精细化排序,判断 “哪个候选最匹配查询”,从而提升最终的检索精度。
2:“从 LamRA-Ret 的输出中输入单个或多个候选项” 的详细解读
这句话的核心是 LamRA-Rank 的输入来源于 LamRA-Ret 的输出,且支持两种输入形式:
1:输入 “多个候选项”:Listwise Reranking(列表式重排序)
LamRA-Ret 输出一批候选对象(如 10 个与查询相关的图片),将这 “多个候选项” 作为整体输入到 LamRA-Rank。
LamRA-Rank 对这一批候选进行整体语义建模与排序,直接输出 “最匹配查询的候选”。例如,从 10 个图片中选出 “最像皮卡丘” 的那一张。
2:输入 “单个候选项”:Pointwise Reranking(点式重排序)
LamRA-Ret 输出单个候选对象(如某一张图片),将这 “单个候选项” 输入到 LamRA-Rank。
LamRA-Rank 对该候选进行单独的语义匹配判断,输出 “是否匹配查询” 的二分类结果(如 “是” 或 “否”)。例如,判断这张图片 “是否是皮卡丘”。
3:最终目的:“进一步提高检索性能”
LamRA-Ret 负责 “粗筛”(找出可能相关的候选),但可能存在 “排序不准” 的问题(比如把不太相关的候选排在前面)。而 LamRA-Rank 通过对 “单个或多个候选项” 的精细化重排序,能修正这种误差,让最匹配的候选排在最前,从而提升整个检索流程的准确性和用户体验。
简单来说,LamRA-Ret 先 “海选” 出一批候选人,LamRA-Rank 再对这些候选人进行 “最终面试”(可以一次面多个,也可以一个个面),选出最适合的那一个,以此提高检索的最终效果。
5:从LamRA-Ret中输出的100个候选者,并将其中的99个作为硬否定,是不是这个意思?
1:背景:重排序模型的训练需要 “正负样本”
重排序模型(如 LamRA-Rank)的训练目标是区分 “与查询匹配的候选” 和 “与查询不匹配的候选”。因此,需要构建:
正样本:与查询语义完全匹配的候选(如 “查询是‘皮卡丘图片’,正样本是‘皮卡丘的图’”)。
负样本:与查询语义不匹配的候选(如 “其他宝可梦的图”“卡通人物的图”)。
2:“硬否定” 的定义与作用
“硬否定” 是指 “看似相关但实际不匹配的候选”,这类候选的特点是:
从 “初始检索结果”(如 LamRA-Ret 的输出)中筛选而来;
与查询有一定的表面关联(比如同属一个类别、有部分相似特征),但语义上并不匹配;
对模型训练 “更具挑战性”,能强迫模型学习更精细的语义区分能力。
3:该场景中 “作为硬否定” 的具体操作
在这句话中,流程是:
用 LamRA-Ret(初始检索模型) 对每个查询检索出 “前 100 个候选对象”;
其中,与查询语义完全匹配的候选是 “正样本”;
而剩下的 99 个候选(看似相关但实际不匹配)则被作为 “硬否定”(负样本)。
这样构建的负样本不是 “完全无关的噪声”,而是 “有一定干扰性的硬负样本”,能让重排序模型(LamRA-Rank)在训练中学习到更精准的语义区分能力,从而提升重排序的性能。
4:总结
“作为硬否定” 是指将 “初始检索结果中看似相关但实际不匹配的候选” 作为挑战性负样本,用于重排序模型的训练,以强化模型对 “语义匹配度” 的精细判断能力。
6:LamRA 框架中用于提升检索精度的关键步骤——点重排序
1:点重排序的工作流程
点重排序的核心思想是:让模型学会判断“一个”候选与查询的相关性。其训练流程可以概括为以下几个步骤:
获取候选列表:首先,使用已经训练好的检索模型(LamRA-Ret)为每个查询从庞大的候选库中快速检索出前100个最可能相关的候选。这100个候选里通常既包含真正的正确答案(正样本),也包含许多容易混淆的错误答案(难负样本)。
构建训练样本对:对于每一个查询(q),训练时我们会从这前100个候选列表中随机选取一个负面候选(c_neg),同时,数据集中已提供了该查询对应的真实正面候选(c_pos)。这样就构成了一个训练样本对:(q, c_pos) 和 (q, c_neg)。
模型学习与损失计算:将 (q, c_pos) 和 (q, c_neg) 分别输入到重排序模型(LamRA-Rank)中。模型的任务是为每个 (q, c) 对输出一个相关性判断,理想情况下是对于 (q, c_pos) 输出 YES,对于 (q, c_neg) 输出 NO。交叉熵损失 函数会计算模型的预测结果与这个期望结果(“正确答案”)之间的差距。损失值越小,说明模型判断得越准确。通过优化这个损失,模型就逐渐学会了如何区分相关与不相关的候选。
2:举例说明:图文检索场景

3:训练过程如下

4:技术目标与价值
点重排序的核心价值在于精细化相关度判断。初始检索模型(LamRA-Ret)可能更关注全局特征(如是否有猫),而重排序模型(LamRA-Rank)则能利用大型多模态模型强大的语义理解能力,进行更深层次的推理,区分那些“看起来有点像”但实际不匹配的候选,从而显著提升最终排序结果的Top-1准确率。
值得一提的是,LamRA框架还提供了另一种 “列表重排序(Listwise Reranking)” 方式,它是将多个候选作为一个列表同时输入模型,让模型直接输出最相关候选的排名。点重排序精度高但计算成本也高,列表重排序效率更高但受模型上下文长度限制,两者可以互补 。
7:LamRA框架中的列表重排序
LamRA框架中的列表重排序(Listwise Reranking)是一种高效的训练技术,它通过让模型直接比较多个候选并找出最佳答案,来显著提升检索系统的排序精度。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)