滚动时域马尔可夫博弈自动驾驶策略
本文提出一种融合博弈论与马尔可夫决策过程的自动驾驶换道策略,通过合作与非合作博弈建模车辆交互,并采用滚动时域方法动态优化决策。该方法在MATLAB/Simulink/dSPACE实时仿真环境中验证,结果表明其能有效寻找安全换道间隙,行为表现类人,适用于混合交通场景下的强制变道任务。
滚动时域马尔可夫博弈自动驾驶策略
塞尔达尔·科斯昆ç,电气与电子工程师协会会员,张青宇ç,电气与电子工程 师协会学生会员,以及雷扎·兰加里ç,电气与电子工程师协会高级会员
摘要
本文提出了一种新颖的类人自动驾驶换道算法。为此,我们通过融合博弈论与马尔可夫决策过程,提出了一种多智能体决策方案,构建了一个马尔可夫博弈(MG)。在该决策过程中,通过合作博弈(max − max)和非合作博弈(max − min)两种方式,以数学上可处理的形式刻画了目标车辆(SV)与交通车辆(T V s)之间的交互:在合作博弈中,车辆为实现集体目标而做出决策;在非合作博弈中,车辆则为实现个体目标而决策。玩家的策略通过滚动时域(RH)方法进行计算,该方法通过优化策略,在考虑当前和未来约束的情况下寻找最优解。所提出的方案在一个基于 MATLAB/Simulink/dSPACE实时模拟器构建的人在环(HIL)环境中进行了评估,其中由马尔可夫博弈引导的SV控制器与程序化生成的T V s以及一辆人工驾驶车辆(HV)进行交互。实验结果表明,该马尔可夫博弈驾驶策略能够在多车移动交通中找到安全的换道间隙,且行为表现与人类驾驶员在强制变道中的行为一致。
一、引言
变道操作会加剧交通拥堵,并在交通管理中构成重大的安全问题[1]。人们普遍认为,车辆自动化能够以潜在安全且有效的方式消除这些复杂的驾驶任务[2],[3]。为实现这一目标,自动驾驶车辆依赖车载传感器来确定驾驶模式,例如跟驰、超车或前方汇入,这些任务通常都需要可靠的控制/决策能力。在包含自动驾驶车辆和人工驾驶车辆的混合交通环境中,准确的驾驶员行为建模至关重要。在此背景下,人类驾驶员的认知功能在路径规划与导航(涵盖短时间与长时间范围)、车辆物理控制以及紧急威胁评估与碰撞避免方面是一个重要问题。自动驾驶车辆不仅必须充分考虑人类在驾驶普通车辆时所执行的这些功能,还必须以自身独特的方式将这些功能有机结合,从而实现可靠且安全的自动驾驶。
准确的驾驶员行为建模需要理解自动驾驶的目标。本文研究了一种类人的强制变道问题。
换道行为对应的驾驶策略可能会导致交通拥堵和/或碰撞。驾驶员决策策略通常以决策动作的最大安全或效用奖励为目标,在随机且不确定的环境中,已被建模为单一智能体决策者,采用马尔可夫决策过程(MDPs)和部分可观测马尔可夫决策过程进行建模,如[4],[5],[6],和[7]所述。然而,换道决策涉及多辆车辆之间的相互作用。博弈论(GT)能够处理智能车辆之间的交互问题(IV s),从而我们可以为IV s[8]构建更鲁棒的换道模型。北田(Kita)在[9]中提出了合流让行场景下车与车之间博弈理论交互模型,明确考虑了一对合流车辆与直行车辆的交互关系,双方从自身角度选择最优动作,由此构成一个二人非零和非合作博弈。Talebpour在et al.[10]中研究了网联环境下的换道模型,利用不完全信息的概念求解二人非零和非合作博弈。Wang在et al.[11]中提出了一种微分博弈方法,受控车辆根据对其他车辆预期行为的估计来执行决策。Yu在et al.[12]中考虑了一种类人化的博弈论换道模型,该模型通过转向灯、横向移动以及驾驶员的激进程度来描述与周围驾驶员的交互。Meng在et al.中提出了一种基于滚动时域控制思想的博弈论动态换道决策设计([13])。决策会随着自动驾驶车辆获取新信息而不断更新([14])。由于交通环境高度动态,当前时刻计算出的决策可能在下一步时间已不再适用。为了利用最新接收的信息动态更新决策,我们借鉴了已在模型预测控制理论中广泛应用的滚动时域控制思想。基本思路是从初始状态到终止状态,在一个移动的时间窗口内通过优化计算出一系列决策序列;随着时间推进,结合新的信息重复执行相同的优化过程(N)。
本文提出的主要贡献在于开发了一种适用于自动驾驶车辆的驾驶员行为模型和换道决策策略,该策略涉及一种结合MDP(马尔可夫决策过程)和博弈论的多智能体决策策略,从而形成一个马尔可夫博弈(MG)。我们进一步表明,无论是合作的(即玩家共同最大化其目标)还是非合作的(即玩家竞争实现各自目标)博弈解决方案属于该框架,并利用滚动时域(RH)方法来处理随着时间推移接收到的新信息,从而形成动态决策策略。我们通过使用驾驶模拟器进行的实人参与研究来展示该方法。
本文结构如下:第二节介绍问题描述、预备知识以及交通的MDP(马尔可夫决策过程)类型建模。第三节推导了马尔可夫博弈解。第四节展示了所提出方法在人在回路场景下的实验结果。第五节得出结论与研究展望。
II. 问题描述和预备知识
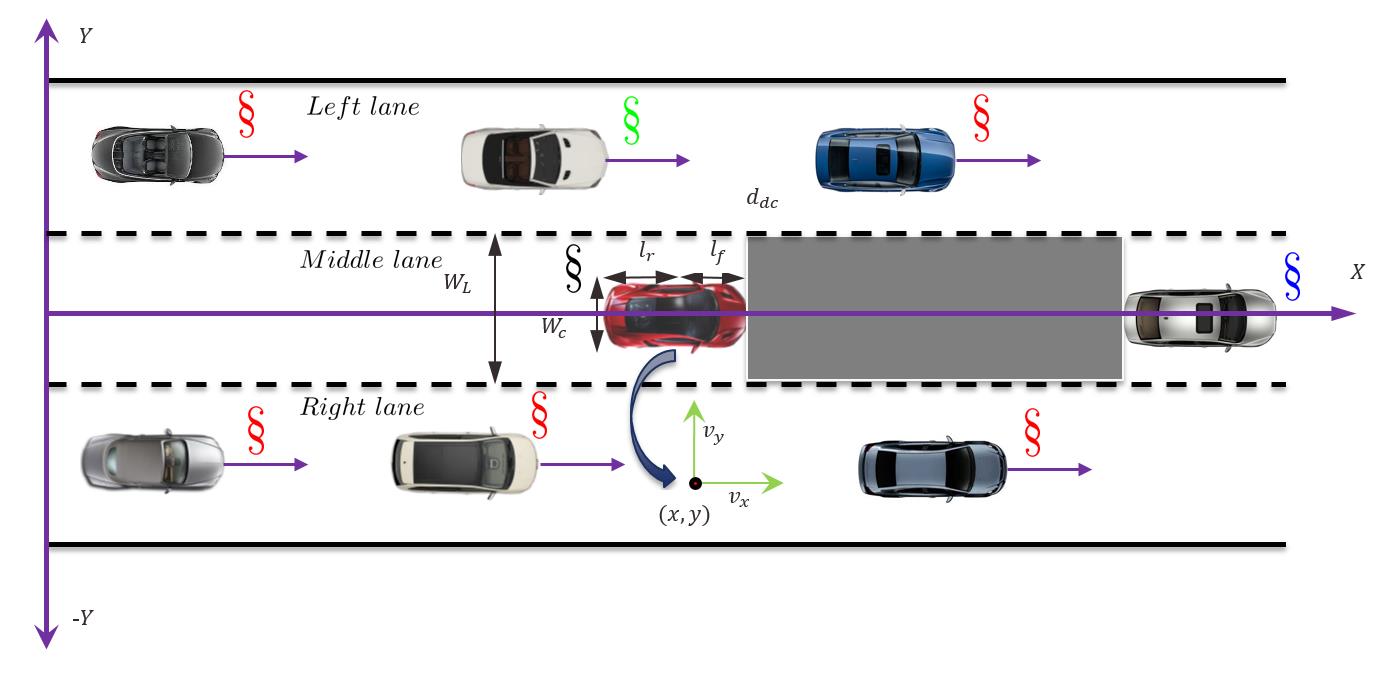
有两种类型的变道:自主变道和强制变道。在第一种类型中,驾驶员寻求获得更好的交通条件;而在第二种类型中,驾驶员必须变道以避免事故发生。图1展示了SV(即中间车道的红色汽车)因前方存在静止车辆而需要进行强制变道的情况。我们假设右车道和左车道均有可用间隙,但SV必须调整其速度,并在合适的间隙中完成并道,如图2所示。我们特别关注以下问题:如何为自动驾驶与人类驾驶员之间的安全变道设计一种策略。
为此,我们考虑采用一个质点运动学模型来描述所有车辆在纵向方向上的运动:
$$
x(k+1)= x(k)+ v(k)\Delta+ \frac{1}{2} u(k)\Delta^2 \quad (1)
$$
$$
v(k+1)= v(k)+ u(k)\Delta \quad (2)
$$
其中 $k+ 1$ 表示在当前时间$k$、采样时间为$\Delta$时的下一个离散时间增量,$u(k)$表示在时间$k$的加速度。定义状态向量 $\xi(k)=[x(k)\ v(k)]^T$,可写出如下紧凑的离散状态空间方程:
$$
\xi(k+1)=\begin{pmatrix}1 & \Delta \ 0 & 1\end{pmatrix} \xi(k)+\begin{pmatrix}\frac{1}{2}\Delta^2 \ \Delta\end{pmatrix} u(k) \quad (3)
$$
A. 自动驾驶中的马尔可夫决策过程网格世界建模
道路被建模为有限时间范围内的网格世界,每个矩形对象表示沿行驶方向的通行时间。矩形的大小取决于车辆标称速度和数据采集的采样时间。状态是世界中矩形对象的数量,动作是连接这些状态的加速度。采用MDP(马尔可夫决策过程),通过设计奖励的选择来促使车辆以期望的方式行驶。累积奖励是通过从起始状态到网格世界中终止状态的一条路径来最大化。术语policy被定义为给定MDP(马尔可夫决策过程)的整体解决方案。智能体的目标是利用一种optimal策略,即从初始状态$s_0$开始,通过选择动作到达目标终止状态,并获得最大奖励。
B. 状态-动作描述
回想一下,前方道路构成一个网格世界,位置$(x(k), y(k))$对应SV和T V s在下一步时间所行驶的位置。对于SV而言,终止状态是各个间隙,每个间隙都由SV评估以用于并道。从终止状态开始,通过后向传播为每一个中间状态赋值。在行驶的每个时刻$k$,SV的目标是从初始状态朝给定的终止状态行驶,并沿累积最大奖励的方向前进,其动作集为纵向加速度,即$u_{SV_x}$。由于SV会考虑其周围所有可能的间隙,间隙的数量通过变道动作成为状态空间的一部分,即$lc_{SV}$。在此设定中,共有$N/\Delta$步。请注意,在此马尔可夫类型网格世界中,T V s仅通过纵向行驶和纵向加速度动作$u_{TV_x}$来最大化或最小化目标函数。形式化表述如下:
$$
\text{states}={s(k)=(x(k), y(k)), \text{2D position}, #\text{gap}, \text{number of gaps}}
$$
$$
\text{actions}={a_{SV}(k)=(u_{SV_x}(k), lc_{SV}(k)), a_{TV}(k)= u_{TV_x}(k)}
$$
在图2中,SV针对T V s之间的间隙。通过在纵向方向上使用加速度,调整位置,并完成并道换道。
C. 滚动时域决策
考虑公式(3),其中动态演化不受扰动影响。则可以通过模型预测确切的未来行为。假设通过传感器可获得完整状态测量,可以从当前时刻$k$开始,在固定的时间区间$N$内,即$k+ N$,在一组约束$h$和目标函数$V$下预测状态。借鉴滚动时域(RH)的思想,我们提出基于马尔可夫博弈的决策策略的以下求解步骤:
- 从时刻$k$开始,在$N$步内预测所有状态值
- 在时刻$k$,针对当前状态$\xi(k)$,考虑所有约束$h$,在视界$N$上求解目标函数$V$的优化问题,即$[k, k+ N]$
- 仅应用结果动作序列中的第一个动作输入
- 测量下一时刻的状态$k+ 1$,并从$k+1$到$N+1$执行相同的优化,即$[k+1, k+N+1]$
当达到稳态条件,即实现安全并道时,解决方案终止。这种新方法确保随着交通新信息的获取而动态执行动作。
III. 马尔可夫博弈
马尔可夫博弈(MG)是马尔可夫决策过程和重复博弈的广义解。其主要区别在于多个智能体/玩家在给定环境中共同决定动作。因此,解决方案结果会因其他智能体的动作而不同[15]。这正是博弈论方法致力于从不同智能体视角解决的问题。参考文献[16]对此进行了全面阐述。在自动驾驶中,将博弈引入MDP(马尔可夫决策过程)解的主要目标是考虑交通模型中驾驶员之间的交互。众所周知,驾驶过程中存在大量驾驶员行为场景,而博弈论方法可以通过数学建模对可能的交互特征进行刻画,从而使自动驾驶车辆在决策阶段能够捕捉个体反应。一个多智能体MG由元组〈P, S, A, T, R, γ〉表示:
- $P= 1, 2,…, p$是智能体集合
- $S$是$s(k)$在时间$k$的所有可能状态的集合
- $A_p(k)$且$p \in P$是智能体$p$在时间$k$可用的所有可能动作空间$a_p(k)$
- $T$是$S \times A_p \times S \rightarrow[0, 1]$是转移函数,其中$T(s(k+1)|a_p(k), s(k))$表示在时间$k$智能体$p$在状态$s(k)$执行动作$a_p(k)$后进入状态$s(k+ 1)$的概率
- $R_p$是$S\times A_p \times S \rightarrow \mathbb{R}$是奖励函数,其中$R_p(s(k+1)|s(k), a_p(k))$表示智能体$p$在状态$s(k+1)$通过在状态$s(k)$执行动作$a_p(k)$所获得的奖励
- $\gamma$是折扣因子,$0< \gamma< 1$
在MG理论中执行决策需要对贝尔曼动态规划方程进行迭代,直到其收敛到一个定义的无穷小误差界。第一种方法是对价值函数$V_p(s(k+ 1))$进行迭代,其中$k+ 1$表示下一步时间,用于描述在时间$k$时,在策略$\phi_p(k)$下,针对玩家$p$的动作集合$a_p(k)$,状态$s(k+ 1)$的价值。玩家$p$寻找能够获得最大期望奖励的最优动作序列,该序列称为最优策略或策略。第二种方法是通过从一个最大化期望奖励的最优策略开始,对策略函数进行迭代,该策略会导出一组最优动作[17]。我们采用第一种方法,针对max−max博弈,值迭代解的贝尔曼方程如下所示一个预测时域$N$:
$$
V_p(s(k+1))= \max_{a_1(k),a_2(k)} \sum_{k=1}^{N}[R_p(s(k+1)|s(k), a_1(k), a_2(k))+ \gamma\sum_{s’(k)} T(s(k+1)|s(k), a_1(k), a_2(k))\times V_p(s’(k))],
$$
Optimal策略$\phi_p^*$是集合中最大化可执行操作,即,
$$
a_{(1,2)}(1), a_{(1,2)}(2),…, a_{(1,2)}(n)
$$
其中$n$是预测时域的终止时间,使得
$$
\phi_p^*(s(k))= \arg\max_{a_1(k),a_2(k)} \sum_{k=1}^{N}[R_p(s(k+1)|s(k), a_1(k), a_2(k))+ \gamma\sum_{s’(k)} T(s(k+1)|s(k), a_1(k), a_2(k))\times V_p(s’(k))].
$$
值迭代解的贝尔曼方程针对在预测时域$N$上的max−min博弈给出:
$$
V_p(s(k+1))= \max_{a_1(k)} \min_{a_2(k)} \sum_{k=1}^{N}[R_p(s(k+1)|s(k), a_1(k), a_2(k))+ \gamma\sum_{s’(k)} T(s(k+1)|s(k), a_1(k), a_2(k))\times V_p(s’(k))],
$$
Optimal策略$\phi_p^*$是集合中最大化动作对最坏情况响应
$$
a_{(1,2)}(1), a_{(1,2)}(2),…, a_{(1,2)}(n)
$$
其中$n$是预测时域的终止时间,使得
$$
\phi_p^*(s(k))= \arg\max_{a_1(k)}[\min_{a_2(k)} \sum_{k=1}^{N}[R_p(s(k+1)|s(k), a_1(k), a_2(k))+ \gamma\sum_{s’(k)} T(s(k+1)|s(k), a_1(k), a_2(k))\times V_p(s’(k))]].
$$
我们现在可以考虑多个智能体相互作用的博弈场景,其中解的结果取决于各个智能体的动作对或策略。从定义可以看出,MG最重要的特征之一是奖励和转移函数依赖于所有智能体的动作,而在MDP(马尔可夫决策过程)情况下,它们仅依赖于单个智能体的动作。一些重要说明:
- 状态的值取决于个体动作
- 到某一状态的转移取决于个体动作
- 玩家可能有不同的动作
- 博弈不改变系统状态
- 玩家的策略表示为马尔可夫博弈的整体行为
我们希望找到每个状态下玩家的均衡点。在均衡状态下的个体策略称为最佳响应,通过纳什均衡解来实现给定博弈中的最大奖励。
A. 双矩阵博弈的纳什均衡[18]
考虑一个双人非零和(或一般和)博弈,其收益矩阵为$M_1$和$M_2$;一对$M_1$和$M_2$构成一个双矩阵博弈,其中$M_1$和$M_2$大小相同。玩家$p$的收益$R_p$是矩阵$M_p$中对应的元素。$M_p$的行对应玩家1的$a_1 \in A_1$,列对应玩家2的$a_2 \in A_2$。
该双矩阵博弈的纯策略纳什均衡:
$$
R_1(a_1^ , a_2^ ) \ge R_1(a_1, a_2^ ), \forall a_1 \in A_1.
$$
$$
R_2(a_1^ , a_2^ ) \ge R_2(a_1^ , a_2), \forall a_2 \in A_2.
$$
每个广义和折扣博弈至少存在一个平稳策略均衡点[16]定理4.6.4,见第219页。
B. 马尔可夫博弈建模与提出的算法
我们现在为图3所示交通环境中的多智能体设置一个博弈。博弈论建模的主要基本思想是,可以在换道过程中考虑车辆的所有潜在行为。得益于大量可能的行为,我们能够在换道中实现最佳性能。图3显示了SV和T V s及其行驶方向。假设所有车辆都配备了激光雷达/雷达传感器,因此车辆可以获得交通信息(在不确定性范围内)。SV尽可能多地考虑与周围车辆的交互,最多考虑到当前可用间隙的数量。图3显示了一组博弈配对,但总共针对六个间隙进行了六场博弈。
合作与非合作博弈均被建立并求解。以下定义了SV和T V s的个体支付函数或称为目标:
$$
U_{SV}(s(k+1), a_{SV}(k), s(k))=\%1 \Psi_i(k)/\tau_i(k) + \%2\pi(k), \quad (4a)
$$
$$
U_{TV}(s(k+1), a_{TV}(k), s(k))=\%1 \Psi_i(k)/\tau_i(k), \quad (4b)
$$
$$
U_{TV}(s(k+1), a_{TV}(k), s(k))=\%1\Psi_i(k), \quad (4c)
$$
其中变量包括:车辆间的纵向距离,即$\Psi_i$,到达该间隙的时间,即$\tau_i$,以及与前导车辆的剩余纵向空间,即$\pi$;$i= 1, 2,…, n_{gap}$, $\%1,\%2$为用户定义的权重项。该关系式中,$\%1/\%2 < 1$用于安全,$\%1/\%2 > 1$用于空间考量。间隙的收益取决于调整阶段,即$\tau_i$。例如,即使间隙长度$\Psi_i$较大,$\tau_i$也会在奖励函数中使其价值降低,因为它会除以该值。与前导车辆的剩余纵向空间,即$\pi$,也是一个重要元素,因为当SV接近前导车时,其值并不理想。
在公式(4a)中,为SV定义的第一个支付,即$U_{SV}$,是博弈论中用于分析博弈解的一种表示法。我们仍然使用奖励符号$R$,因为在马尔可夫网格世界中求解了一组重复博弈。第二个支付公式(4b)适用于T V进行合作博弈的情况。在这种情况下,T V将制定策略,通过打开间隙和/或最小化其前方间隙的行驶时间,使SV能够更快地完成变道过程。公式(4c)中的最后一个支付考虑了T V s不合作且尽可能缩小前方间隙的情况。SV的目标是针对其周围任何可用间隙,最大化T V s最坏情况下的响应。这确实是驾驶员不礼貌时最常见的场景,也是交通事故的主要原因之一。最优最大化与最小化策略是智能体$p$在状态值函数$V_p$下的纳什均衡的纯策略,即$\phi_p^ (k) \ge \phi_p(k)$和$\phi_p^ (k) \le \phi_p(k)$。奖励方程(5)对SV的定义与(4a)相同,只是其值依赖于T V和SV的动作。T V s的奖励方程也可以以相同方式写出。本文中的转移是确定性的,即$T(s(k+1)|\phi_p(k), s(k))= 1$。
$$
R(s(k+1), a_{SV}(k), a_{TV}(k), s(k))=\%1 \Psi_i(k)/\tau_i(k) + \%2\pi(k). \quad (5)
$$
定义:在合作的MG中,SV和TV的纳什均衡是从两个玩家的角度来看的最优最大化点$(\phi_{SV}^ (k), \phi_{TV}^ (k))$,使得
$$
V_{SV}(s(k+1)|\phi_{SV}^ (k), \phi_{TV}^ (k)) \ge V_{SV}(s(k+1)|\phi_{SV}(k), \phi_{TV}^ (k)), \forall\phi_{SV},
$$
$$
V_{TV}(s(k+1)|\phi_{SV}^ (k), \phi_{TV}^ (k)) \ge V_{SV}(s(k+1)|\phi_{SV}^ (k), \phi_{TV}(k)), \forall\phi_{TV}.
$$
非合作MG中的SV的纳什均衡和T V是从SV的角度来看最优的最大化最坏情况下的策略点$(\phi_{SV}^ (k), \phi_{TV}^ (k))$,使得
$$
V_{SV}(s(k+1)|\phi_{SV}^ (k), \phi_{TV}^ (k)) \ge V_{SV}(s(k+1)|\phi_{SV}(k), \phi_{TV}^ (k)), \forall\phi_{SV},
$$
$$
V_{TV}(s(k+1)|\phi_{SV}^ (k), \phi_{TV}^ (k)) \le V_{SV}(s(k+1)|\phi_{SV}^ (k), \phi_{TV}(k)), \forall\phi_{TV}.
$$
定义:如果存在一个均衡且满足马尔可夫性质,即下一个状态仅依赖于当前状态(而非状态历史),则该均衡点称为马尔可夫完美均衡。
当为玩家定义了收益和策略后,下一步是寻找最优策略。在所提出的博弈定义中,策略由变道转向和纵向加速度曲线(即动作)组成,对于SV而言包括这两者,而对于TV s仅包含纵向加速度曲线(即动作)。合作型一般非零和马尔可夫博弈的解从每个玩家的角度最大化奖励,意味着最优动作是在系统每个状态下使得没有任何玩家能够获得更高收益的最佳动作组合。另一方面,非合作型非零和马尔可夫博弈对于SV的目标是在选择间隙的过程中最大化对T V s最不利反应情况下的性能。
针对离散纵向加速度$u_x =[u_{xmin}, u_{xmax}]$,为每个目标间隙构建收益矩阵。回顾在所考虑的典型场景中,SV针对他们前方的每一个间隙均与T V s进行六次博弈,但我们仅输出SV的策略和一个T V针对一个目标间隙的策略。接下来给出用于合作的和非合作的马尔可夫博弈的以下算法:
$$
\phi_{SV}^ (s(k)), \phi_{TV}^ (s(k))= \arg\max_{a_{SV}(k),a_{TV}(k)} \sum_{k=1}^{N}[R_p(s(k+1)|s(k), a_{SV}(k), a_{TV}(k))+ \gamma\sum_{s’(k)} T(s(k+1)|s(k), a_{SV}(k), a_{TV}(k))\times V_p(s’(k))], \quad (6a)
$$
$$
\phi_{SV}^ (s(k)), \phi_{TV}^ (s(k))= \arg\max_{a_{SV}(k)}[\min_{a_{TV}(k)} \sum_{k=1}^{N}[R_p(s(k+1)|s(k), a_{SV}(k), a_{TV}(k))+ \gamma\sum_{s’(k)} T(s(k+1)|s(k), a_{SV}(k), a_{TV}(k))\times V_p(s’(k))]], \quad (6b)
$$
where
$$
\phi_{SV}^ (s(k)), \phi_{TV}^ (s(k))=(u_{SV_x}^ (k), lc_{SV}^ (k), u_{TV_x}^*(k))
$$
$$
\phi_{SV}(s(k)), \phi_{TV}(s(k))=(u_{SV_x}(k), lc_{SV}(k), u_{TV_x}(k)), \quad (7)
$$
具有马尔可夫完美均衡
$$
V_p(s(k+1)|u_{SV_x}^ (k), lc_{SV}^ (k), u_{TV_x}^ (k)) \ge V_p(s(k+1)|u_{SV_x}^ (k), lc_{SV}(k), u_{TV_x}(k)), \forall lc_{SV}(k), \forall u_{TV_x}(k), \quad (8a)
$$
$$
V_p(s(k+1)|u_{SV_x}^ (k), lc_{SV}^ (k), u_{TV_x}^ (k)) \le V_p(s(k+1)|u_{SV_x}^ (k), lc_{SV}(k), u_{TV_x}(k)), \forall lc_{SV}(k), \forall u_{TV_x}(k), \quad (8b)
$$
$$
V_p(s(k+1)|u_{SV_x}^ (k), lc_{SV}^ (k), u_{TV_x}^ (k)) \ge V_p(s(k+1)|u_{SV_x}(k), lc_{SV}^ (k), u_{TV_x}(k)), \forall u_{SV_x}(k), \forall u_{TV_x}(k), \quad (9a)
$$
$$
V_p(s(k+1)|u_{SV_x}^ (k), lc_{SV}^ (k), u_{TV_x}^ (k)) \le V_p(s(k+1)|u_{SV_x}(k), lc_{SV}^ (k), u_{TV_x}(k)), \forall u_{SV_x}(k), \forall u_{TV_x}(k), \quad (9b)
$$
$$
V_p(s(k+1)|u_{SV_x}^ (k), lc_{SV}^ (k), u_{TV_x}^ (k)) \ge V_p(s(k+1)|u_{SV_x}(k), lc_{SV}(k), u_{TV_x}^ (k)), \forall u_{SV_x}(k), \forall lc_{SV}(k), \quad (10b)
$$
受限于
$$
(x_p(k+1), v_p(k+1)) =\begin{pmatrix}1 & \Delta(k) \ 0 & 1\end{pmatrix}(x_p(k), v_p(k))^T +\begin{pmatrix}\frac{1}{2}\Delta(k)^2 \ \Delta(k)\end{pmatrix} u_{px}(k), \quad (11)
$$
$$
u_{px}^{\min} \le u_{px}(k) \le u_{px}^{\max}, \quad (12)
$$
$$
\Delta u_p^{\min} \le \Delta u_p(k) \le \Delta u_p^{\max}, \quad (13)
$$
$$
\text{sgn}(\Delta u_p(k+1))= \text{sgn}(\Delta u_p(k)), \quad (14)
$$
$$
v_{px}^{\min} \le v_{px}(k) \le v_{px}^{\max}, \quad (15)
$$
$$
\tau_p^i(k) \le N, i= 1, 2,.., n_{gap}, \quad (16)
$$
$$
\min(G_p^i) \le \Psi_p^i(k), i= 1, 2,.., n_{gap}, \quad (17)
$$
$$
\pi_p(k) \ge \min(\pi_p). \quad (18)
$$
合作博弈的目标函数值在公式(6a)中根据玩家的相互动作定义。该博弈的解在预测时域N内的所有状态上最大化两个玩家的累积奖励。然而,公式(6b)给出的非合作博弈值函数意味着SV最大化T V的最坏情况反应。公式7展示了两种博弈中玩家相应的最优策略或策略对。在合作博弈中,最大化纳什均衡解(max− max)是在公式(8a)、(9a)、(10a)所有其他候选中的最优策略对。非合作博弈解的修正目标见公式(6b),通过最优对(max−min)在公式(7)中实现。对于前方间隙,T V的最优动作候选是公式(8b)、(9b)中所有最小化T V奖励的动作候选中的下界。另一方面,SV的最优动作候选仍然是公式(10b)中价值函数的上界。车辆运动学模型如(11)所示。玩家的纵向加速度边界和加加速度边界由公式(12)、(13)给出,而符号变化约束(确保因改变加速度方向而不会失去变道机会)见公式(14)。公式(15)用于限制玩家的速度,条件$\tau_i(k) \le N$则在公式(16)中限制了在预测时域N内调整阶段的玩家p的解。此外,还检查了玩家p前方的最小间隙条件,并分别通过公式(17)和(18)将换道前的安全剩余间隙纳入设计。需要注意的是,公式(16‐18)的约束仅适用于SV。如果不存在间隙和/或没有候选解,则始终存在一种通过减速保持在当前车道的解决方案。
C. 速度跟踪、横向目标和跟车模型
MG解决方案控制所有车辆的纵向速度。这简单意味着由MG确定的策略以参考速度的形式应用,然后被SV和T V s用于实现它们的共同或独立目标,即
$$
u_{SV_x}= K(v_{ref_{SV}} − v_{SV_x}), \quad u_{TV_x}=K(v_{ref_{TV}} − v_{TV_x}).
$$
横向动力学与公式(3)相同,且SV的目标位置为选定车道的车道中央,即
$$
u_{SV_y} = K(y_{ref_{SV}} − y_{SV}).
$$
为了确保换道前后T V s和SV的交通流顺畅,提出了以下跟车公式,该公式是智能跟车模型(IDM)[19]的改进版本:
$$
u_{TV_x} = K\left[1 -\left(\frac{x^* (x_0, v_{TV}, T)}{x_{current}}\right)^2\right]. \quad (19)
$$
其中$x^* = x_0 + v_{TV} T$。$x_0$是跟随前导车TV的TV车辆在特定车头时距$T$及其速度$v_{TV}$下的最小间隙。后随TV车辆会对前导车TV的速度变化做出反应,并保持一个与期望车头时距成比例的车头时距值。该模型被表征为跟车领导模型,类似于最优速度模型Bando et al.[20],但额外增加了实现车辆之间安全车头距离的目标。当SV在两条T V s之间变换车道时,SV由后随车辆T V跟随,而SV则跟随前导车T V。


IV. 实验结果
实验中采用了一个三车道高速公路场景,如图5所示,包含多辆汽车。所有车辆均在车道中央行驶。T V s的速度与SV的速度无关。车辆仅单向行驶,即不考虑倒车行驶,且可初始位于不同车道上。换道前后车流的运行由公式(19)中的启发式跟车模型维持。WL为车道宽度。
图5中所示的距离ddc是从Lead车辆起算的关键距离。为了避免该交通冲突,SV进行了换道。SV的最小间隙由$G_{SV_i} \le \Psi_{SV_i}=\psi+ \Delta v_{SV} t_{lc}$定义,其中$\psi$为常数,$\Delta v_{SV}$是SV与需并入该间隙的TV之间的速度差,在此间隙中进行博弈以完成并道,$t_{lc}$为平均换道持续时间。换道前的安全剩余间隙,即$\min(\pi_p)$,确保一旦发起换道,可在$t_{lc}$内安全完成。ddc为介入距离(图5中的黑色阴影区域),其定义为
$$
d_{dc}= v_{initial_{SV}} T+\frac{(v_{initial_{SV}})^2}{2u_{x_{SV}}},
$$
其中第一项为车头时距,第二项为后方Lead车辆以最大恒定减速度停车所需的距离。选择进入哪个间隙完全可通过调节权重来控制。


表I 仿真中使用的设计参数
| 参数 | 值 | 参数 | 值 | 参数 | 值 |
|---|---|---|---|---|---|
| %1 | 1 | lr | 2.65 m | uy | [-3,3] m/s² |
| %2 | N/A | Wc | 1.95 m | Δux | [-1,1] m/s³ |
| Δk | 0.1 secs | N | 4 secs | Δuy | [-0.1,0.1] m/s³ |
| tlc | 2 secs | vx | [0,30] m/s | yref | [-3.3,3.3] m |
| ψ | 5 m | vy | [-5,5] m/s | x0 | 5 m |
| WL | 3.3 m | γ | 0.5 N/A | T | 1 sec |
| K | 5 N/A | ||||
| T1 | 1.2 secs | T2 | 1.6 secs |
表II 车辆初始条件
| 车辆编号 | 纵向位置 (m) | 纵向速度 (m/s) | 横向位置 (m) | 横向速度 (m/s) |
|---|---|---|---|---|
| SV | 70 | 22 | 0 | 0 |
| TV1 | 80 | 23 | 3.3 | 0 |
| TV2(HV) | 60 | 25 | 3.3 | 0 |
| TV3 | 19 | 23 | 3.3 | 0 |
| TV4 | 96 | 20 | -3.3 | 0 |
| TV5 | 67 | 20 | -3.3 | 0 |
| TV6 | 42 | 20 | -3.3 | 0 |
| Lead | 250 | 0 | 0 | 0 |
值。例如,如果希望更重视纵向安全间距,SV会根据保持更长的纵向距离来确定其未来的策略。然而,如果目标是尽快完成换道,SV则会寻求更近的间隙。算法在驾驶中进行了测试


 和合作(b)场景的策略)
和合作(b)场景的策略)

以T2= 1.6 secs的车头时距跟随TV5。在左车道中,TV3不跟随HV,因为TV3被用作独立智能体,主要是为了分析其对SV的间隙选择阶段的驾驶影响。在实验1和实验2中,我们展示了两种场景:第一种场景中所有车辆均为非合作的,第二种场景中车辆为合作的¹。两个实验采用相同的车辆初始条件。在两种场景中,SV后方均无跟随车辆。该设计包含三个主要阶段:a) 换道前阶段,此时T V s处于跟车模式,SV具有初始速度,而HV独立行驶;b) 马尔可夫博弈阶段,此时SV需要换道,并开始与T V s和HV进行交互。根据所选择的间隙,SV和T V生成换道策略;最后是c) 换道后阶段,除HV外,所有车辆均处于跟车模式。设计参数见表I,表II显示了车辆的初始条件。
实验1
在实验1中,SV在图9(a)中以初始速度22 m/s开始行驶,在其行驶车道上遇到车辆障碍物Lead,并开始寻找可能的间隙。左侧车道中的HV(TV2)如图6(a)所示,阻挡了SV。SV开始与T V s和HV进行博弈交互,通过使用转向灯瞄准TV5前方的间隙。SV预测TV5的运动行为,并在3.7 secs开始减速,以调整自身速度,因为在右车道上的T V s正以20 m/s的速度行驶。在每个时刻k,该问题在N的求解窗口内求解,且仅有首个决策以加速度的形式应用于SV和TV5。随后,求解窗口移至下一步时间。注意到TV5在4.2 secs(0.5 secs反应延迟)开始对SV作出反应,并试图通过加速阻止变道,如图8(a)所示。SV最大化TV5策略的下界,如图8(a)所示,并成功在TV5前方完成并道,如图6(b)所示。当SV跨越车道线时,它开始跟随TV4,而TV5则以T= 1 secs跟随SV,如图9(a)所示。
B. 实验2
在实验2中,SV以相同的初始速度启动。由于HV采取合作的方式,即在图9(b)中通过减速让行,SV便切入其前方。SV的最优策略是立即向左变道,通过加速范围内操作以避免与Lead车辆发生碰撞一段较短的时间。SV在图4(b)中打开转向灯,并继续加速一小段时间,以与HV保持良好距离后进行并道。在图8(b)中,SV的计算策略是其目标的最优动作序列。由于HV是循环中的独立智能体,其行为由模拟器用户控制。该最优策略使得相对于HV的合作响应,能够实现更高的速度和更短的调整时间,这明显有利于提升交通的安全与通行效率。SV的横向轨迹如图7(a)所示,在HV(TV2)前方完成并道。需要指出的是,当SV超过Lead车辆后,实验即终止。从稳定性角度来看,整体交通流在有限运行时间后达到稳态。
C. 讨论
本研究提出的方法生成了一组加速度序列,即自动驾驶与联网车辆的策略。所生成的策略仅在状态空间中的纵向行驶路径上实施,以实现并道所需的安全变道条件。当并道开始时,跟车模型确保所有车辆在纵向方向上的车队稳定性。因此,本文提出的自动驾驶的核心思想分为两个主要阶段:马尔可夫博弈和跟驰。本研究的主要方法论在于突出驾驶员交互性交通行为对决策过程的影响。由于求解过程中使用了所有车辆的预测信息,计算负担成为一个重要的考虑因素。这直接受到采样时间的影响。由于更新频率会影响优化解的数量,而在线实现至关重要,过高的更新频率可能导致问题的可追溯性丢失。
由于保持强制变道的基本要求,实验呈现出类似的初始条件。针对不同的换道问题(例如自由变道),可以提出不同的设置和考虑因素来评估所提出的框架。设计的另一个要素是参数的选择。由于任何决策策略都依赖于研究中选择的参数,因此如果场景局限于特定的交通仿真,也可以进一步研究全面的设计参数选择方法。但由于所提出方案的多学科性质,这超出了本文的范围。因此,指出在代表性场景中考察SV和HV特性仍能证明所提出方法在多动作交通流中的可靠性。
五、结论与未来工作
在本研究中,我们提出了一种马尔可夫博弈方法,以更好地对多智能体决策中的交通环境进行建模。所提出的数学框架联合评估离散决策序列,以实现相互或排他的目标。该方法以滚动时域方式生成策略,在策略制定中考虑了车辆的预测行为。例如执行。此外,进行了人在回路实验以展示所提出方法的工作原理。后续研究将集中在确定驾驶员协作性和横向驾驶行为的方法,以更好地分析驾驶员意图。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)