DeepSeek-OCR:大语言模型驱动的OCR 2.0技术,重新定义文档智能处理
DeepSeek-OCR作为一款以大语言模型为核心的开源OCR工具,通过创新的上下文光学压缩技术,正在探索视觉文本压缩的极限,引领OCR技术从单一字符识别向多模态智能理解的跨越。## 行业现状:从OCR 1.0到2.0的技术革命在数字化转型加速推进的今天,光学字符识别(OCR)技术已成为信息处理的核心基础设施。从企业文档管理到移动应用开发,从学术研究到智慧城市建设,OCR技术的精准度与适应...
DeepSeek-OCR:大语言模型驱动的OCR 2.0技术,重新定义文档智能处理
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-OCR
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-OCR 导语
DeepSeek-OCR作为一款以大语言模型为核心的开源OCR工具,通过创新的上下文光学压缩技术,正在探索视觉文本压缩的极限,引领OCR技术从单一字符识别向多模态智能理解的跨越。
行业现状:从OCR 1.0到2.0的技术革命
在数字化转型加速推进的今天,光学字符识别(OCR)技术已成为信息处理的核心基础设施。从企业文档管理到移动应用开发,从学术研究到智慧城市建设,OCR技术的精准度与适应性直接决定了信息流转的效率。
传统OCR(OCR 1.0)主要由两个独立的模块组成:文字检测与文字识别,这些系统通常基于CNN(卷积神经网络)+ LSTM(长短期记忆网络)的结构,如CRNN、CTC识别模型等。这一阶段的OCR主要解决的是"机器读字"的问题——识别准确率、字体鲁棒性、多语言支持等。
随着信息形式的多样化,文字早已不再是唯一的信息载体。图像、视频、表格、图纸、网页、甚至PDF文档——都成为了新的知识容器。因此,传统的OCR技术,虽然能够识别字符,却往往无法理解图像中的语义关系。它知道一串文字写着什么,却不理解它在页面中的意义——是标题、表格项、还是公式的一部分。
而在2023年之后,大模型技术的爆发彻底改变了视觉理解的格局。以GPT-4V、Gemini 2、Qwen-VL、InternVL等为代表的多模态大模型(VLM,Vision-Language Model)出现,让人工智能真正具备了"同时理解文字与图像"的能力。基于VLM进行OCR的工作,包括文字识别、版面识别(文档结构关系识别)等等,也被称为OCR 2.0。
据市场研究机构Fortune Business Insights报告显示,全球智能文件处理(IDP)市场规模预计将从2025年的105.7亿美元增长到2032年的666.8亿美元,复合年增长率为30.1%。这一增长主要得益于企业数字化转型加速,以及对自动化文档处理需求的不断攀升。
产品亮点:DeepSeek-OCR的核心创新
DeepSeek-OCR是面向多模态文档理解与检索而生的OCR 2.0/VLM模型:它不仅识别文字,更"读懂"文档。典型能力包括:将多页PDF一键转换为结构化Markdown,高保真解析表格/公式,理解并描述图表/示意图/照片的语义;同时支持区域定位与版面要素标注。
1. 统一框架架构
模型采用"视觉编码器 → 投影/对齐(projector)→ 语言解码器"的统一框架:视觉端用ViT系列编码图像为高维token,投影层将视觉表征映射到语言嵌入空间,与LLM在同一语义坐标系内对齐,随后由解码器根据指令(prompt)生成Markdown、LaTeX、JSON或解释性自然语言。
相比传统流水线式OCR(检测→识别→版面分析),这种端到端的对齐与生成能在一个模型里完成文本提取 + 结构理解 + 语义生成,减少误差累积,更适合复杂版面与跨页关联的信息抽取。
2. 上下文光学压缩技术
为同时兼顾效果与效率,DeepSeek-OCR提出上下文光学压缩(Contexts Optical Compression):在保持语义判别力的前提下,用更少的"视觉标记"(visual tokens)去"浓缩"文档关键信息,再交给LLM的推理能力补全上下文关系。
这等于在视觉侧做"语义压缩",在语言侧做"上下文复原"。其结果是:以小体量模型即可覆盖高难度的版面理解任务,显著降低显存与计算开销,同时在PDF→Markdown、表格/公式解析、图像语义描述等核心指标上维持高质量输出。
3. 灵活的部署与使用方式
DeepSeek-OCR支持多种使用场景和部署方式,包括Huggingface transformers推理和vLLM加速推理。模型提供多个参数规模版本,以适应不同的硬件环境和性能需求:
- Tiny: base_size = 512, image_size = 512, crop_mode = False
- Small: base_size = 640, image_size = 640, crop_mode = False
- Base: base_size = 1024, image_size = 1024, crop_mode = False
- Large: base_size = 1280, image_size = 1280, crop_mode = False
- Gundam: base_size = 1024, image_size = 640, crop_mode = True

如上图所示,图片展示了DeepSeek-OCR相关技术内容,包含数字识别示例、OCR模型代码实现及模型层分析可视化图表。这一技术架构充分体现了DeepSeek-OCR在视觉语言对齐方面的创新,为开发者提供了清晰的技术实现路径。
4. 多模态文档解析能力
DeepSeek-OCR在处理复杂文档方面表现出色,能够准确识别和解析各种文档元素,包括文本、表格、公式、图像等,并将其转换为结构化格式。
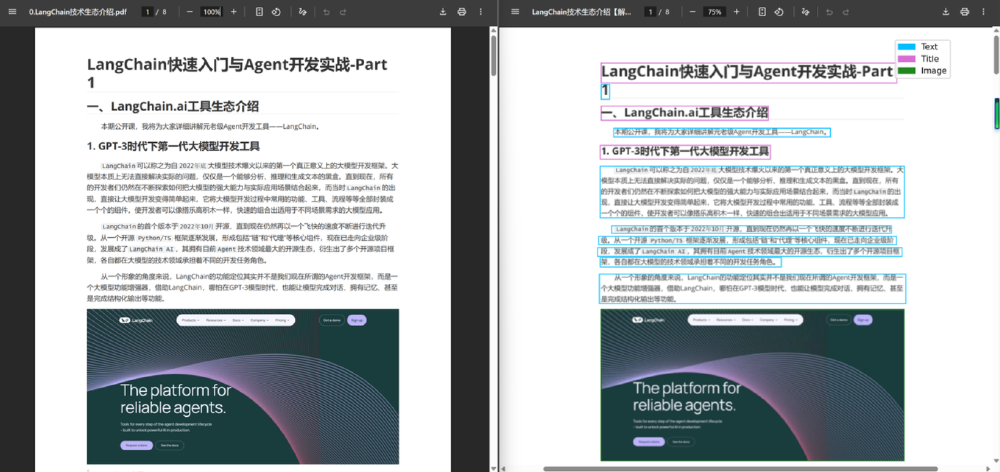
如上图所示,左侧为原始PDF页面(标题为"LangChain快速入门与Agent开发实战-Part 1"),右侧为OCR处理后的界面,通过Text、Title、Image等标签标注文档内容。这一功能展示了DeepSeek-OCR在复杂文档结构理解方面的优势,为构建多模态RAG系统提供了高质量的结构化数据输入。
行业影响与应用场景
DeepSeek-OCR作为OCR 2.0时代的代表产品,正在多个行业领域产生深远影响:
1. 企业文档管理与自动化
在企业环境中,DeepSeek-OCR可以大幅提升文档处理效率,实现合同、发票、报告等各类文档的自动化处理。例如,财务部门可以利用其将多语言发票自动转换为结构化数据,加速报销流程;人力资源部门可以快速解析简历,提取关键信息。
2. 学术研究与教育
对于学术研究人员,DeepSeek-OCR能够将复杂的学术论文(包含公式、图表、表格)转换为可编辑的Markdown格式,大大简化文献综述和知识整理工作。教育机构可以利用其实现多语言教材的数字化,促进知识传播。
3. 多模态RAG系统构建
在信息检索领域,DeepSeek-OCR为构建多模态RAG(检索增强生成)系统提供了关键支持。通过将非结构化文档转换为结构化文本,结合向量数据库,可以实现更精准、更丰富的知识检索和智能问答。
4. 跨语言信息处理
随着全球化进程加速,跨语言信息交互已成为企业、学术机构及个人用户的刚需。DeepSeek-OCR支持多语种识别,能够处理多语言混合场景(如国际会议记录、跨国贸易合同、多语言社交媒体内容),打破语言壁垒。
使用指南与资源
快速开始
要开始使用DeepSeek-OCR,您可以通过以下步骤:
- 克隆仓库:
git clone https://gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-OCR
- 安装依赖:
torch==2.6.0
transformers==4.46.3
tokenizers==0.20.3
einops
addict
easydict
pip install flash-attn==2.7.3 --no-build-isolation
- 基本使用示例:
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True)
model = model.eval().cuda().to(torch.bfloat16)
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'your_image.jpg'
output_path = 'your/output/dir'
res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)
学习资源
- GitHub仓库:https://github.com/deepseek-ai/DeepSeek-OCR
- 模型下载:https://huggingface.co/deepseek-ai/DeepSeek-OCR
- 论文链接:https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
未来展望
随着技术的不断发展,OCR 2.0技术将朝着更智能、更高效、更易用的方向演进。DeepSeek-OCR团队将继续优化模型性能,扩展语言支持范围,并探索更多创新应用场景。未来,我们可以期待看到:
- 更强的多模态理解能力,实现文本、图像、音频等多模态信息的深度融合。
- 更轻量级的模型版本,支持在边缘设备上的高效部署。
- 针对特定行业的定制化解决方案,满足不同领域的专业需求。
- 与大语言模型更深度的集成,打造更强大的智能文档处理系统。
DeepSeek-OCR作为开源项目,欢迎社区贡献和反馈,共同推动OCR技术的发展和创新。
结语
DeepSeek-OCR代表了OCR技术从"能读"到"读懂"的范式转变,它不仅是一个文字识别工具,更是一个真正的"文档理解器"。通过融合大语言模型和计算机视觉技术,DeepSeek-OCR正在重新定义文档智能处理的标准,为企业数字化转型和智能化升级提供强大支持。
无论您是开发者、研究人员,还是企业决策者,DeepSeek-OCR都为您提供了一个探索文档智能处理新可能的强大工具。现在就加入这个快速发展的社区,体验OCR 2.0时代的革命性变化。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)