论文精读·JUDGELM: FINE-TUNED LARGE LANGUAGE MODELS ARE SCALABLE JUDGES
在开放式场景中评估大型语言模型(llm)是具有挑战性的,因为现有的基准和度量不能全面地度量它们。为了解决这个问题,我们建议将法学硕士作为可扩展的法官(JudgeLM)进行微调,以便在开放式基准测试中高效地评估法学硕士。我们首先提出了一个全面、大规模、高质量的数据集,其中包含任务种子、llms生成的答案和gpt -4生成的判断,用于微调高性能裁判,以及评估裁判的新基准。我们对JudgeLM进行了7B
JUDGELM: FINE-TUNED LARGE LANGUAGE MODELS ARE SCALABLE JUDGES
Evaluating Large Language Models (LLMs) in open-ended scenarios is challenging because existing benchmarks and metrics can not measure them comprehensively. To address this problem, we propose to fine-tune LLMs as scalable judges (JudgeLM) to evaluate LLMs efficiently and effectively in open-ended benchmarks. We first propose a comprehensive, large-scale, high-quality dataset containing task seeds, LLMs-generated answers, and GPT-4-generated judgments for fine-tuning high-performance judges, as well as a new benchmark for evaluating the judges. We train JudgeLM at different scales from 7B, 13B, to 33B parameters, and conduct a systematic analysis of its capabilities and behaviors. We then analyze the key biases in fine-tuning LLM as a judge and consider them as position bias, knowledge bias, and format bias. To address these issues, JudgeLM introduces a bag of techniques including swap augmentation, reference support, and reference drop, which clearly enhance the judge’s performance. JudgeLM obtains the state-of-the-art judge performance on both the existing PandaLM benchmark and our proposed new benchmark. Our JudgeLM is efficient and the JudgeLM-7B only needs 3 minutes to judge 5K samples with 8 A100 GPUs. JudgeLM obtains high agreement with the teacher judge, achieving an agreement exceeding 90% that even surpasses human-to-human agreement1. JudgeLM also demonstrates extended capabilities in being judges of the single answer, multimodal models, multiple answers, multi-turn chat, etc.
在开放式场景中评估大型语言模型(llm)是具有挑战性的,因为现有的基准和度量不能全面地度量它们。为了解决这个问题,我们建议将法学硕士作为可扩展的法官(JudgeLM)进行微调,以便在开放式基准测试中高效地评估法学硕士。我们首先提出了一个全面、大规模、高质量的数据集,其中包含任务种子、llms生成的答案和gpt -4生成的判断,用于微调高性能裁判,以及评估裁判的新基准。我们对JudgeLM进行了7B、13B、33B等不同尺度的参数训练,并对其能力和行为进行了系统的分析。然后,我们以法官的身份分析了微调LLM中的关键偏差,并将其视为位置偏差、知识偏差和格式偏差。为了解决这些问题,JudgeLM引入了一系列技术,包括交换增强、参考支持和参考删除,这些技术明显提高了法官的表现。JudgeLM在现有的PandaLM基准和我们提出的新基准上都获得了最先进的法官性能。我们的JudgeLM效率很高,使用8个A100 gpu, JudgeLM- 7b只需要3分钟就可以判断5K个样本。JudgeLM与teacher judge的一致性很高,一致性超过90%,甚至超过了人与人之间的一致性1。JudgeLM还展示了作为单答案、多模式模型、多答案、多回合聊天等法官的扩展功能。
关键词:微调 + 基准测试
论文概括

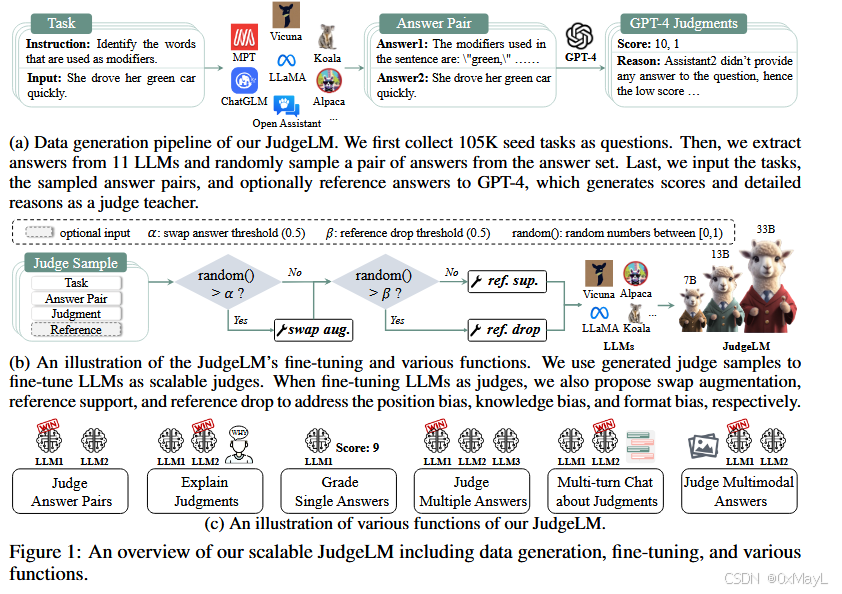
作者针对三个如下偏见提出了微调的解决策略:
- 位置偏见:就是微调时交换位置,而不是推理时交换位置

- 知识偏见:简单来说就是收集GPT-4的答案作为参考答案
- 格式偏见:就是给定参考和不给定参考的答案一致,作者称之为格式偏见。作者在训练时随机删除训练样本的参考。


实验
客观指标(objective metrics):与 GPT-4 或人工评审的一致率(agreement)、精度、召回率、F1 等。
可靠性指标(reliability metrics):包括交换前后一致性(consistency)及偏向度(bias toward 1st/2nd)。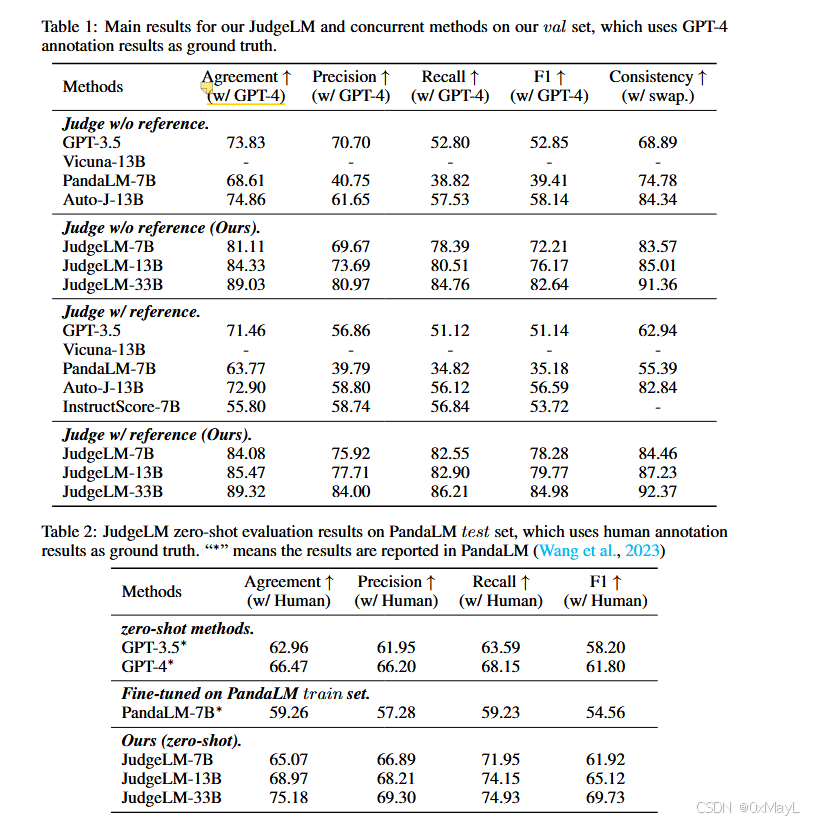

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)