关于comfyui的lora的XY图表以及lora炼丹比较(底模)(一)
主要就是判断像不像,取个中间值就行,不然过拟合(太像)就会变成下面这样同样关键词,种子,只是调整了权重所以说,适合的区间就是最好的。
自己练了一个lora,一共出来了5个模型(我设置每两轮一个,一共10轮)
就是上次尝试的那个,炼丹出来必须进行实验对照,然后继续优化,出个0.2之类版本
准备工作
1.自行安装efficiency节点(不懂安装看之前文章)
2.XY图表工作流
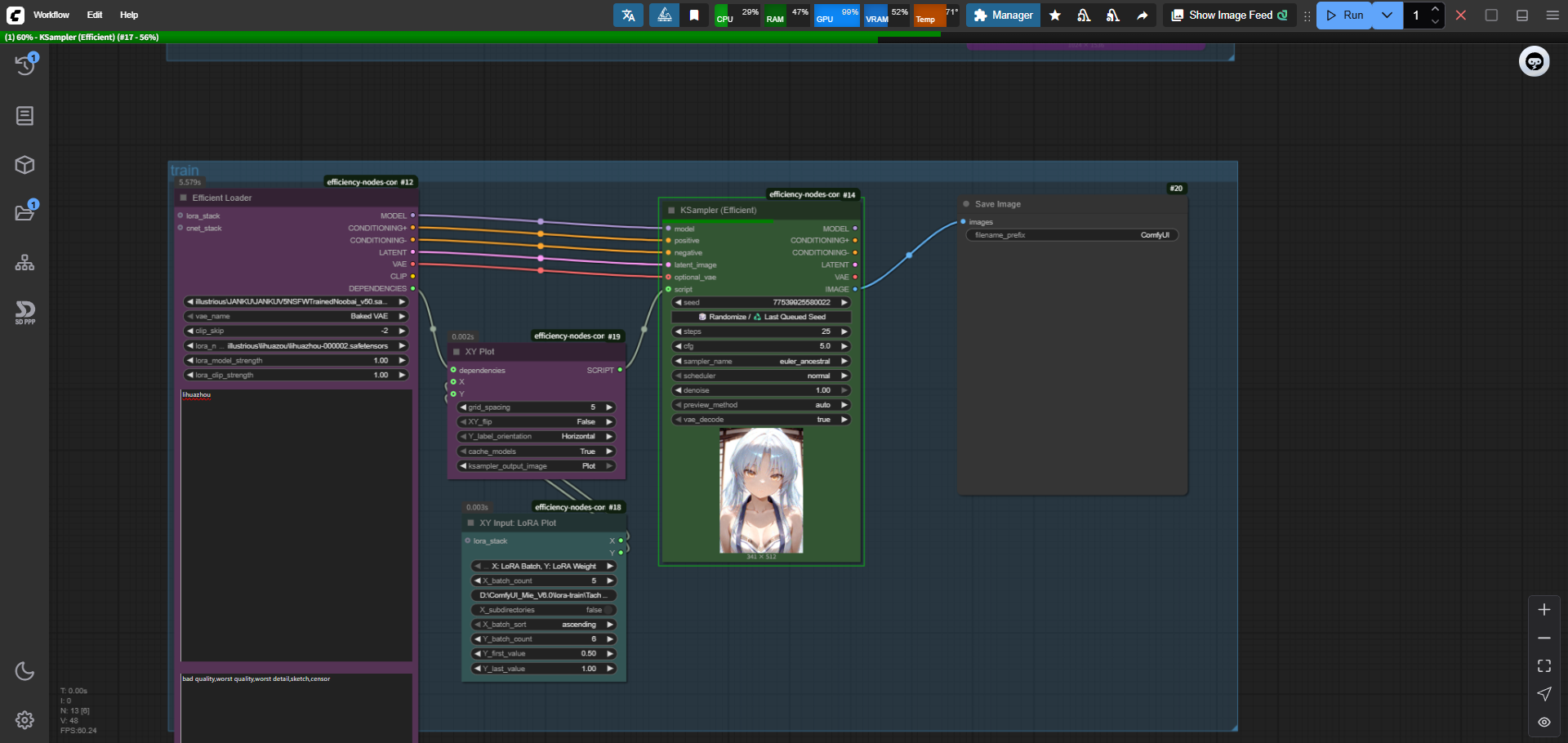
工作流详解
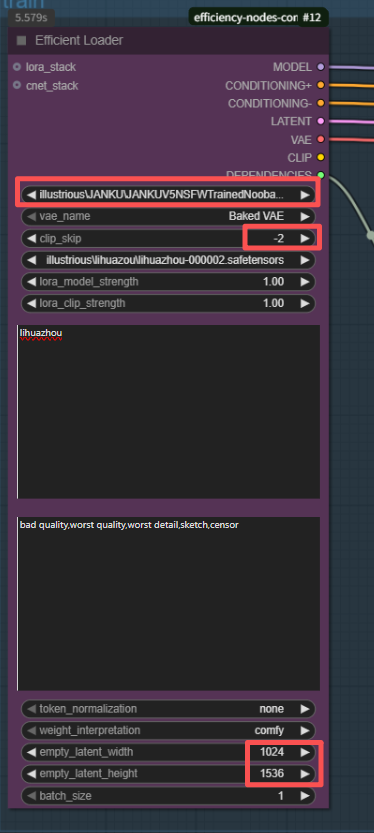
efficient loder
选择checkpoint大模型,clip-skip层数一般是2(训练的时候设置了的,不过是玄学就对了),以及对应的图片宽高(我用了我训练图片的宽高)
至于提示词,自己填写对照组就行,我是用了我自己设置的lora触发词(lihuazhou)
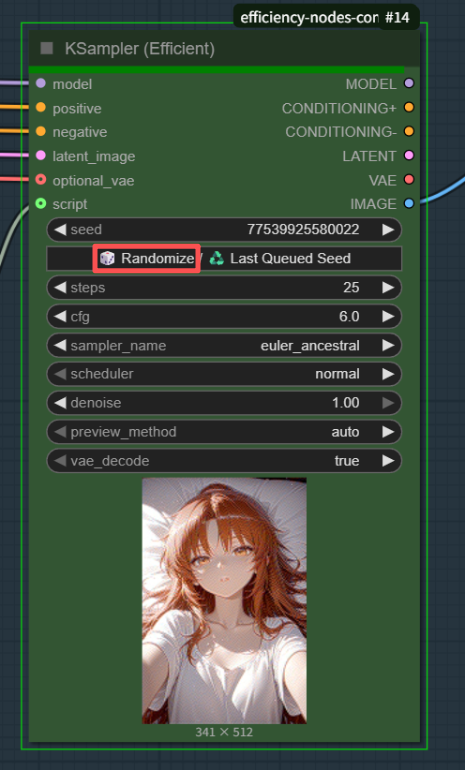
Ksampler(efficient)
不要点那个randomize(随机),然后上面种子自己随便写一个,保证种子不会变(不然怎么对照实验),其他参数根据选择大模型推荐的参数就行
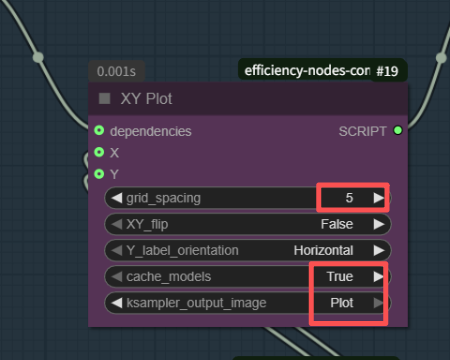
XY plot
这个就是XY图表了,参数按照一样就行
grid-spacing是图片之间的间隔,最好写一点,记得最下面那个输出图片类型,一定要选择plot,不然是一张一张出来的,对比太麻烦
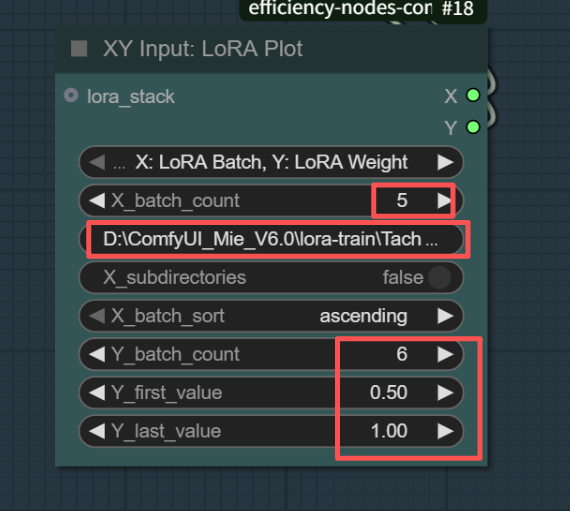
XY Input: LORA Plot
这里有几个参数说一下
第一个就是XY是什么?上面写的很清楚X: LoRA Batch, Y: LoRA Weight(可以自己选择对应的)
x轴是lora个数,所以count自己写(你有几个lora写几个),我这里是5个,下面一定要写对,就是你放的lora文件夹,直接粘贴路径过来就行
Y轴就是lora权重,最下面两个就是起始值,下面我设置了0.5--1.0,Y-count设置分成几个,我这里选择6,就是把0.5到1.0平均分成6个来实验
简单说就是(0.5,0.6,0.7,0.8,0.9,1.0)刚好6个
连线
按照我第一张图片连接就行,说几个注意点
效率节点很方便,基本上你照着连过去就行,平行线
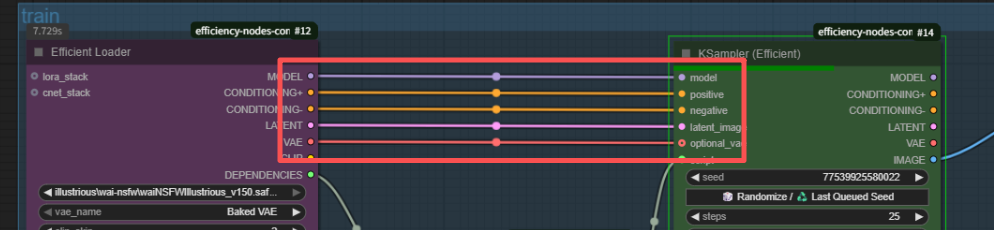
最下面那个DEPENDENCIES就是连接xy脚本用的,对照连接就行,xy也是
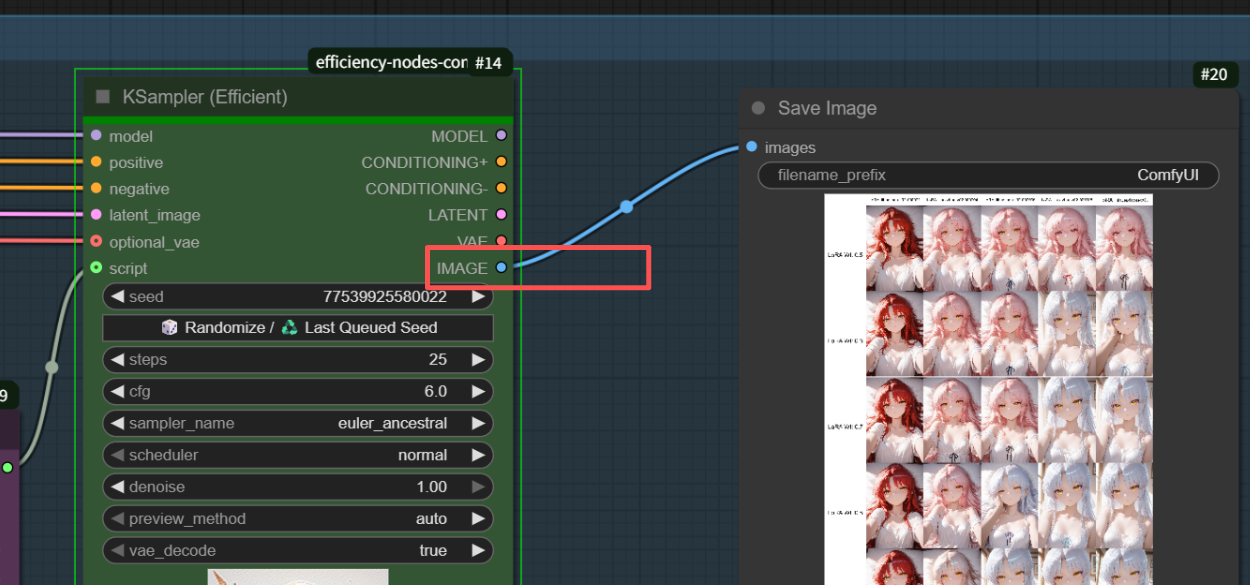
还有效率的k采样器到图片不用经过一个解码过程,已经包含在节点里面了,直接连接保存图片就行
lora对照实验
底模:oneObsession_1424DNsfw.safetensors(就我要硬刚那个,其实不应该用这个)
炼丹的时候我用了触发词:lihuazhou(就是立华奏的拼音)
先用不同的大模型尝试一下
只写触发词
提示词只写lihuazhou
大模型:oneObsession_1424DNsfw

明显有立华奏的影子,可以详细看一下,权重为1的时候基本都过拟合了....
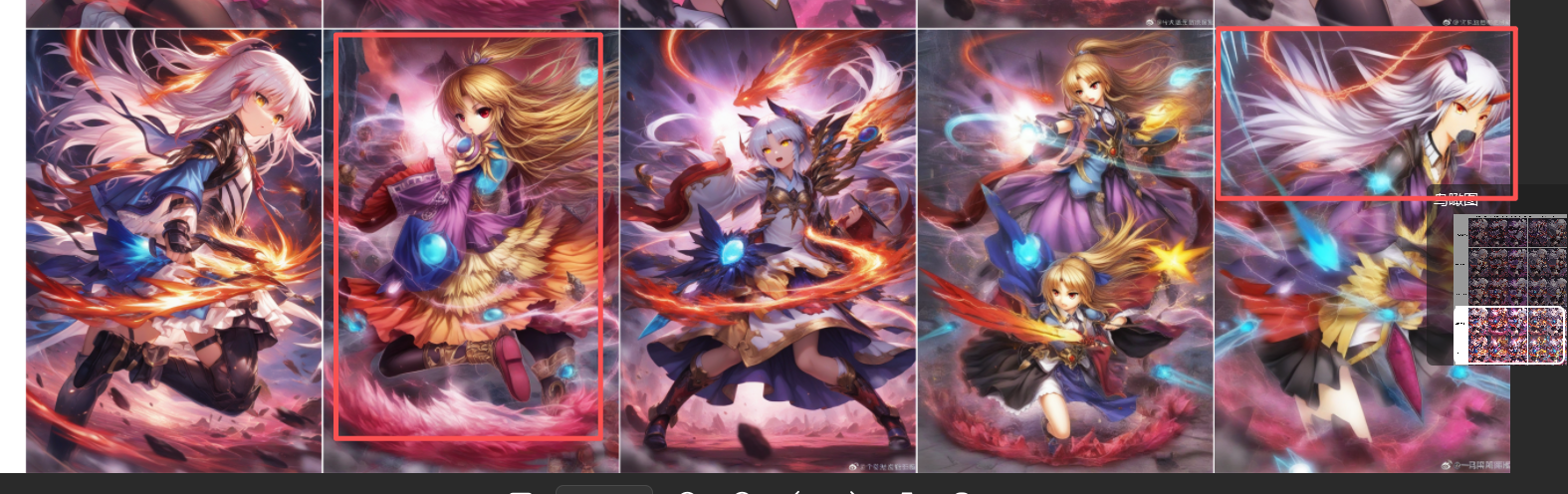
最后一个直接崩坏,暂时看只有06能用(中间那个),再尝试别的模型
大模型:waiNSFWIllustrious_v150

直接给我干哪里来了?找个像的都没有,看来果真只有再原有模型上会好一些,理论上底模得用官方的....什么时候有空写怎么炼丹再记录一下
当然这只是小试牛刀,主要还是下面的测试,不过感觉这一炉丹药有点过拟合了...
完善触发词
这里重点说三遍,一定要写上大模型推荐的提示词,然后我们再考虑lora,因为lora可以根据权重调整的,不然就会出现奇怪的图片
触发词:
1girl,lihuazhou, on bed, school uniform, age regression, upper body, partially unbuttoned,masterpiece, best quality, amazing quality,
大模型:oneObsession_1424DNsfw

感觉还可以,有一张畸变属于正常,换个种子就行,我们详细看一下

最后一个明显过拟合了,太像了.....应该说变得有点2d了
总体看06最好,08也很不错
大模型:waiNSFWIllustrious_v150

完善关键词之后别的模型也还行,详细看一下

权重在0.8-0.9左右最好,02和04可以直接丢了,总体还是06和08最好
大模型:JANKUV5NSFWTrainedNoobai_v50

还是06和08...
总结
主要就是判断像不像,取个中间值就行,不然过拟合(太像)就会变成下面这样
同样关键词,种子,只是调整了权重


所以说,适合的区间就是最好的

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)