CS336 Assignment 2 (systems): Systems and Parallelism 翻译和实现
文章目录
- 1 Assignment Overview
- 2 分布式数据并行训练
- 3 优化器状态分片
1 Assignment Overview
本次作业中,你将通过实践提升单 GPU 训练速度,并将训练扩展至多 GPU 场景。
需实现的内容
- 基准测试与性能分析工具
- Flash Attention 2 Triton 内核
- 分布式数据并行训练
- 优化器状态分片
代码结构说明
所有作业代码及本说明文档均已托管至 GitHub:https://stanford-cs336.github.io/spring2025/
请克隆该仓库。若后续有更新,我们会通知你,你可通过 git pull 获取最新版本。
cs336-basics/:本作业中,你将对作业 1 构建的部分组件进行性能分析。该文件夹包含作业 1 的官方参考实现,因此你会找到cs336-basics/pyproject.toml文件及cs336-basics/cs336_basics/*模块。若想使用自己实现的模型,可修改根目录下的pyproject.toml文件,使其指向你的自定义包。- 根目录
/:cs336-systems的基础目录,包含一个空模块cs336_systems。该目录无预置代码,你可从零开始实现所需功能。 tests/*.py:包含所有必须通过的测试用例。这些测试会调用tests/adapters.py中定义的钩子函数,你需实现这些适配器以连接你的代码与测试用例。编写额外测试或修改测试代码有助于调试,但你的实现需能通过原始提供的测试套件。README.md:该文件包含预期目录结构的详细说明,以及环境配置的基本步骤。
提交方式
请向 Gradescope 提交以下文件:
writeup.pdf:回答所有书面问题,要求排版规范。code.zip:包含你编写的所有代码。
运行脚本 test_and_make_submission.sh 可生成 code.zip 文件。
在作业的第一部分,我们将学习如何优化 Transformer 模型性能,以充分利用 GPU 资源。会先对模型进行性能分析,了解其在正向传播和反向传播过程中时间与内存的消耗分布,然后通过自定义 GPU 内核优化自注意力机制,使其比 PyTorch 的原生实现更快。在作业的后续部分,我们将进一步探索多 GPU 训练方案。
1.1 性能分析与基准测试
在进行任何优化之前,先对程序进行性能分析至关重要——这能帮助我们了解资源(如时间和内存)在各个部分的消耗情况。否则,我们可能会耗费精力优化那些对整体性能影响甚微的模块,最终无法实现可量化的端到端性能提升。
我们将实现三种性能评估方式:(a)使用 Python 标准库进行简单的端到端基准测试,计时正向传播和反向传播过程;(b)借助 NVIDIA Nsight Systems 工具分析计算性能,了解时间在 CPU 和 GPU 各项操作中的分布;(c)分析内存使用情况。
1.1.1 环境配置——导入基础 Transformer 模型
首先确保你能加载上一次作业实现的模型。上一次作业中,我们将模型封装为 Python 包,以便后续导入使用。我们已在 ./cs336-basics 文件夹中提供了该模型的官方实现,并在 pyproject.toml 文件中配置了相关路径。与往常一样,通过 uv run [command] 命令运行代码时,uv 会自动定位这个本地的 cs336-basics 包。若你想使用自己实现的模型,可修改 pyproject.toml 文件,使其指向你的自定义包。
你可通过以下命令测试模型是否能成功导入:
~$ uv run python
Using CPython 3.12.10
Creating virtual environment at: /path/to/uv/env/dir
Built cs336-systems @ file:///path/to/systems/dir
Built cs336-basics @ file:///path/to/basics/dir
Installed 85 packages in 711ms
Python 3.12.10 (main, Apr 9 2025, 04:03:51) [Clang 20.1.0 ] on linux
...
>>> import cs336_basics
>>>
此时,作业 1 中的相关模块应可正常导入(例如,对于 model.py,可通过 import cs336_basics.model 导入)。
1.1.2 模型规模定义
在本次作业中,我们将通过基准测试和性能分析不同规模的模型,以更好地理解性能变化规律。为了直观感受规模对性能的影响,我们将使用以下模型配置。所有模型的词汇表大小均为 10,000,批量大小(batch size)为 4,仅上下文长度(context length)不同。本次作业(及后续作业)需要呈现大量表格形式的结果,我们强烈建议你通过代码自动生成报告中的表格——因为手动用 LaTeX 或 Markdown 格式化表格非常繁琐。你可使用 pandas.DataFrame.to_latex()、pandas.DataFrame.to_markdown() 函数,或根据自己偏好的表格格式编写自定义生成函数。
| 规模 | d_model(模型维度) | d_ff(前馈网络维度) | num_layers(层数) | num_heads(注意力头数) |
|---|---|---|---|---|
| small(小型) | 768 | 3072 | 12 | 12 |
| medium(中型) | 1024 | 4096 | 24 | 16 |
| large(大型) | 1280 | 5120 | 36 | 20 |
| xl(超大) | 1600 | 6400 | 48 | 25 |
| 2.7B(27 亿参数) | 2560 | 10240 | 32 | 32 |
表 1:不同模型规模的详细参数
1.1.3 端到端基准测试
现在我们将实现一个简单的性能评估脚本。由于需要测试模型的多种变体(如改变精度、替换层结构等),建议你的脚本支持通过命令行参数配置这些变体,以便后续快速运行测试。我们还强烈建议使用 Slurm 上的 sbatch 或 submitit 工具,对基准测试的超参数(如模型规模、上下文长度等)进行批量扫描,以提高迭代效率。
首先,我们对模型进行最简单的性能分析——计时正向传播和反向传播过程。由于仅需测量速度和内存,我们将使用随机权重和随机数据进行测试。
性能测量需要注意一些细节——常见的陷阱可能导致测量结果失真。对于 GPU 代码的基准测试,一个重要的注意点是 CUDA 调用的异步性:当你调用一个 CUDA 内核(例如 torch.matmul)时,函数调用会立即返回控制权给 CPU,而无需等待 GPU 完成矩阵乘法运算。这样一来,CPU 可以在 GPU 进行计算的同时继续执行其他操作,但这也意味着,直接测量 torch.matmul 调用的返回时间,并不能反映 GPU 实际执行该矩阵乘法的耗时。在 PyTorch 中,你可以调用 torch.cuda.synchronize() 等待所有 GPU 内核执行完成,从而更准确地测量 CUDA 内核的运行时间。基于这一点,我们来编写基础的性能分析框架。
Problem (benchmarking_script): 4 points
(a)编写一个脚本,对模型的正向传播和反向传播进行基础的端到端基准测试。具体来说,你的脚本应支持以下功能:
- 根据超参数(如层数)初始化模型;
- 生成一批随机数据;
- 先运行 w 次热身步骤(开始计时前),然后计时 n 次步骤的执行时间(可通过参数选择仅测试正向传播,或同时测试正向传播和反向传播);计时时建议使用 Python 的
timeit模块(例如timeit函数,或timeit.default_timer()——该函数提供系统最高分辨率的时钟,比time.time()更适合基准测试); - 每步执行后调用
torch.cuda.synchronize()。
交付物:一个能够根据给定超参数初始化基础 Transformer 模型、生成随机数据,并计时正向传播和反向传播过程的脚本。
(b)对 1.1.2 节中描述的所有模型规模进行正向传播和反向传播计时。使用 5 次热身步骤,计算 10 次测量步骤的平均时间和标准差。正向传播耗时多久?反向传播耗时多久?测量结果的变异性大吗?还是标准差较小?
交付物:1-2 句话的回答,包含你的计时结果。
(c)基准测试的一个常见问题是未执行热身步骤。请在不进行热身的情况下重复上述分析,这会对结果产生什么影响?你认为原因是什么?另外,尝试使用 1 或 2 次热身步骤运行脚本,结果为何可能仍然不同?
答:如果不热身,前向传播和反向传播都明显比热身5次慢。
热身5次数据:
不热身数据: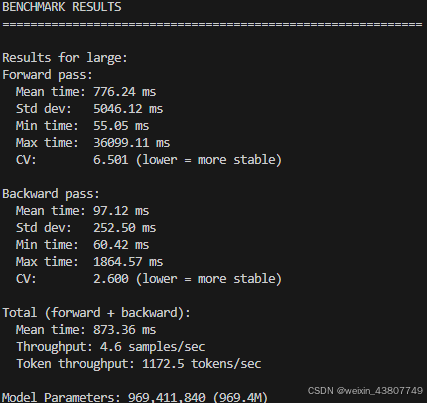
1.1.4 Nsight Systems Profiler
端到端基准测试无法告诉我们模型在正向传播和反向传播过程中时间与内存的具体消耗分布,因此无法精准定位优化机会。要了解程序在每个组件(如函数)上的耗时,我们需要使用性能分析工具(Profiler)。执行性能分析工具会通过在函数开始和结束时插入“探针”来检测代码,从而提供函数级别的详细执行统计信息(如调用次数、平均耗时、累计耗时等)。
标准的 Python 性能分析工具(如 CProfile)无法分析 CUDA 内核,因为这些内核是在 GPU 上异步执行的。幸运的是,NVIDIA 提供了一个可通过命令行使用的性能分析工具 nsys,我们已为你预装。在本部分作业中,你将使用 nsys 分析 Transformer 模型的运行时间。nsys 的使用非常简单:只需在运行上一部分编写的 Python 脚本前加上 nsys profile 前缀即可。例如,要分析脚本 benchmark.py 并将输出保存到文件 result.nsys.rep,可执行以下命令:
~$ uv run nsys profile -o result python benchmark.py
之后,你可以在本地机器上使用 NVIDIA Nsight Systems 桌面应用查看性能分析结果。在性能分析结果的“CUDA API”行中选中某个特定的 CUDA API 调用(CPU 端),会在“CUDA HW”行中高亮显示所有对应的内核执行(GPU 端)。
我们鼓励你尝试 nsys profile 的各种命令行选项,以了解其功能。值得注意的是,通过 --python-backtrace=cuda 选项,你可以获取每个 CUDA API 调用的 Python 回溯信息(但这可能会增加额外开销)。你还可以使用 NVTX 范围(NVTX ranges)对代码进行标注,这些标注会在性能分析结果的“NVTX”行中以块的形式显示,包含所有相关的 CUDA API 调用及关联的内核执行。具体来说,你应该使用 NVTX 范围忽略基准测试脚本中的热身步骤(通过在性能分析结果的“NVTX”行中设置过滤条件)。你还可以通过以下方式标注自注意力层的不同部分,从而分离出模型正向传播和反向传播过程中对应的内核,甚至定位自注意力层各组件对应的内核:
import torch.cuda.nvtx as nvtx
@nvtx.range("缩放点积注意力")
def annotated_scaled_dot_product_attention(
# Q、K、V、掩码等参数
):
with nvtx.range("计算注意力分数"):
# 计算 Q 和 K 之间的注意力分数
with nvtx.range("计算 softmax"):
# 计算注意力分数的 softmax
with nvtx.range("最终矩阵乘法"):
# 计算输出投影
return
你可以通过以下方式,在基准测试脚本中用带标注的实现替换原始实现:
cs336_basics.model.scaled_dot_product_attention = annotated_scaled_dot_product_attention
最后,你可以在运行 nsys 时添加 --pytorch 命令行选项,自动为 PyTorch C++ API 的调用添加 NVTX 范围标注。
任务(nsys 性能分析):5 分
使用 nsys 对表 1 中所有模型规模,以及context lengths为 128、256、512 和 1024 的情况,分别进行正向传播、反向传播和优化器步骤的性能分析(对于部分大型模型,某些上下文长度可能会导致内存不足,这种情况请在报告中注明)。
(a)正向传播的总耗时是多少?与之前使用 Python 标准库测量的结果是否一致?
交付物:测试了context lengths = 256,表格中的小模型'small': {'d_model': 768, 'd_ff': 3072, 'num_layers': 12, 'num_heads': 12},,一次正向传播耗时约等于 31ms,和使用python库测量的基本一致。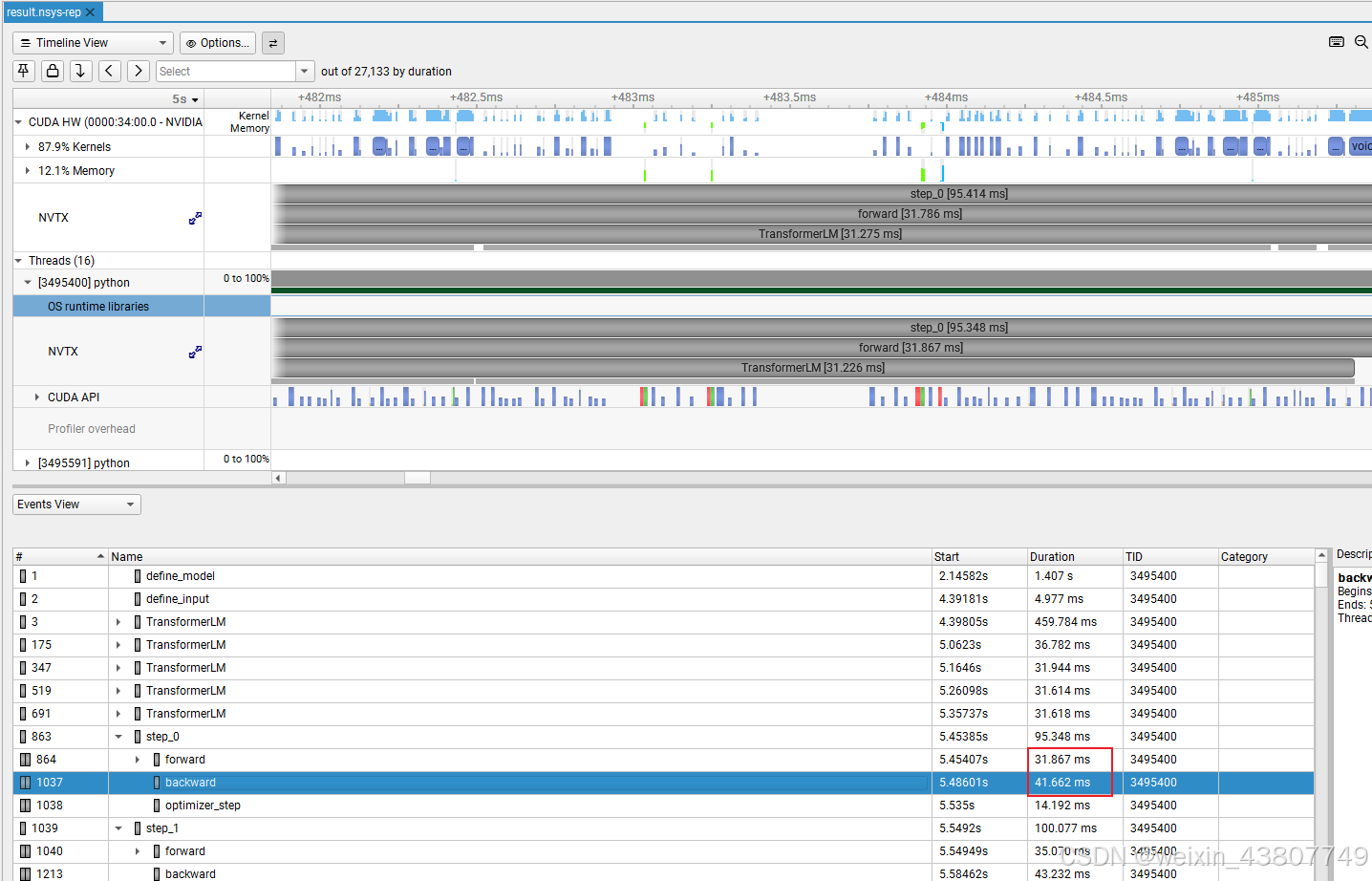 (b)正向传播过程中,累计 GPU 耗时最长的 CUDA 内核是什么?在模型的单次正向传播中,该内核被调用多少次?当同时进行正向传播和反向传播时,耗时最长的内核是否相同?(提示:查看“Stats Systems View”下的“CUDA GPU Kernel Summary”,并使用 NVTX 范围过滤,以确定哪些模型组件对应哪些内核。)
(b)正向传播过程中,累计 GPU 耗时最长的 CUDA 内核是什么?在模型的单次正向传播中,该内核被调用多少次?当同时进行正向传播和反向传播时,耗时最长的内核是否相同?(提示:查看“Stats Systems View”下的“CUDA GPU Kernel Summary”,并使用 NVTX 范围过滤,以确定哪些模型组件对应哪些内核。)
答:
点击Stats System View并选中CUDA GPU Kernal Summary,选中forward区域, 右键点击 apply filter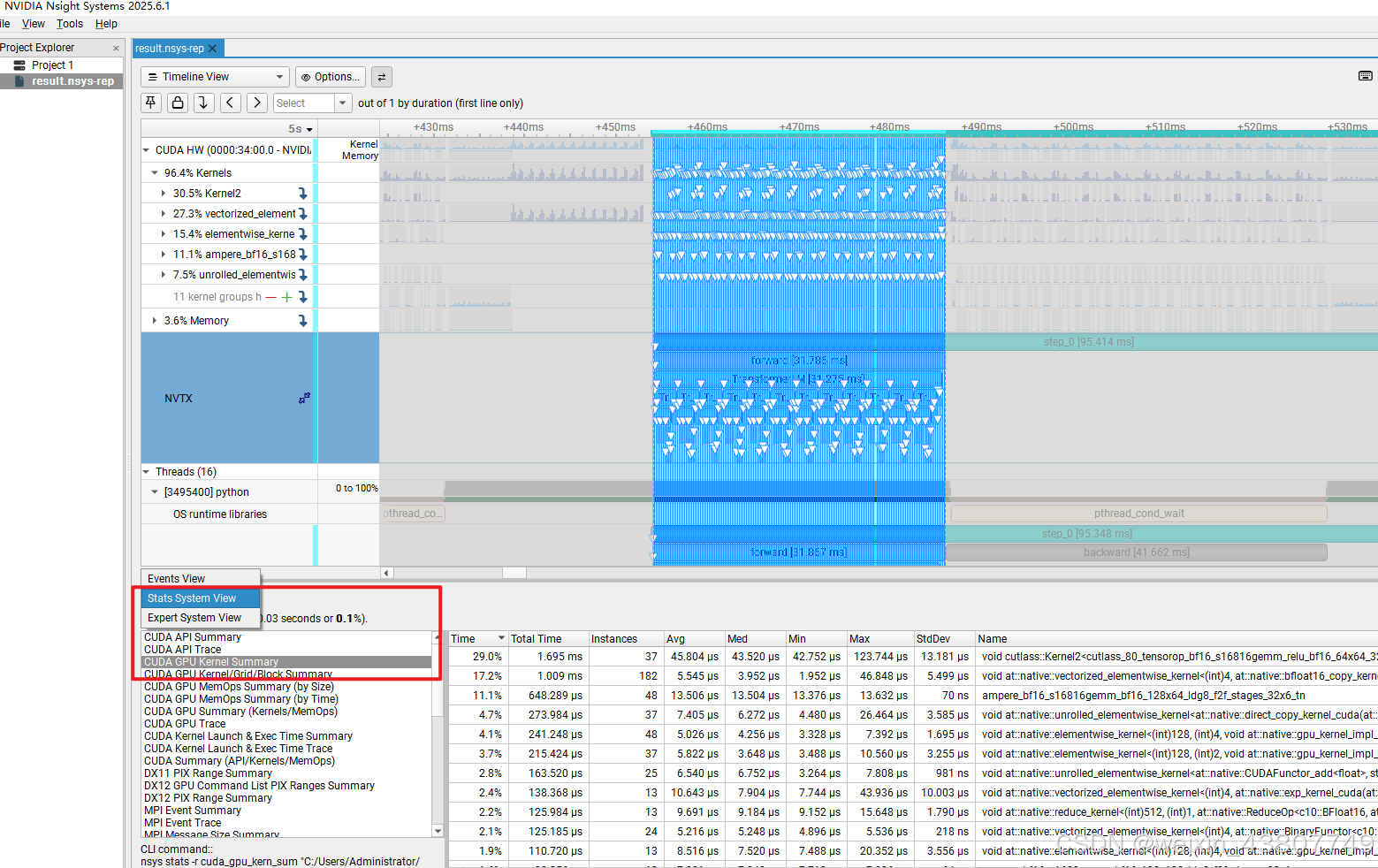
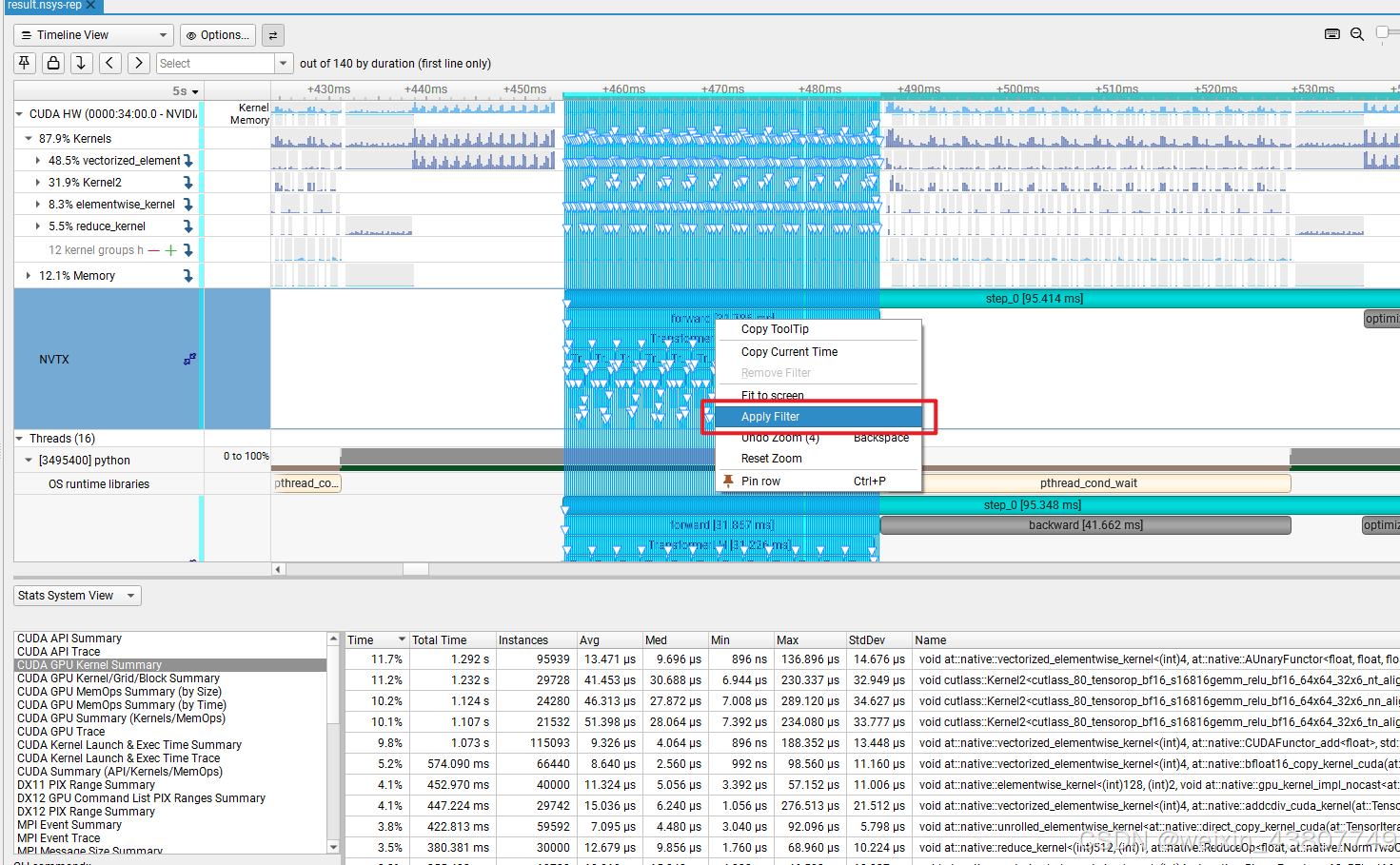
过滤后可以清楚的看到,每个内核占用的时间;其中,cutlass::Kernal2最耗时。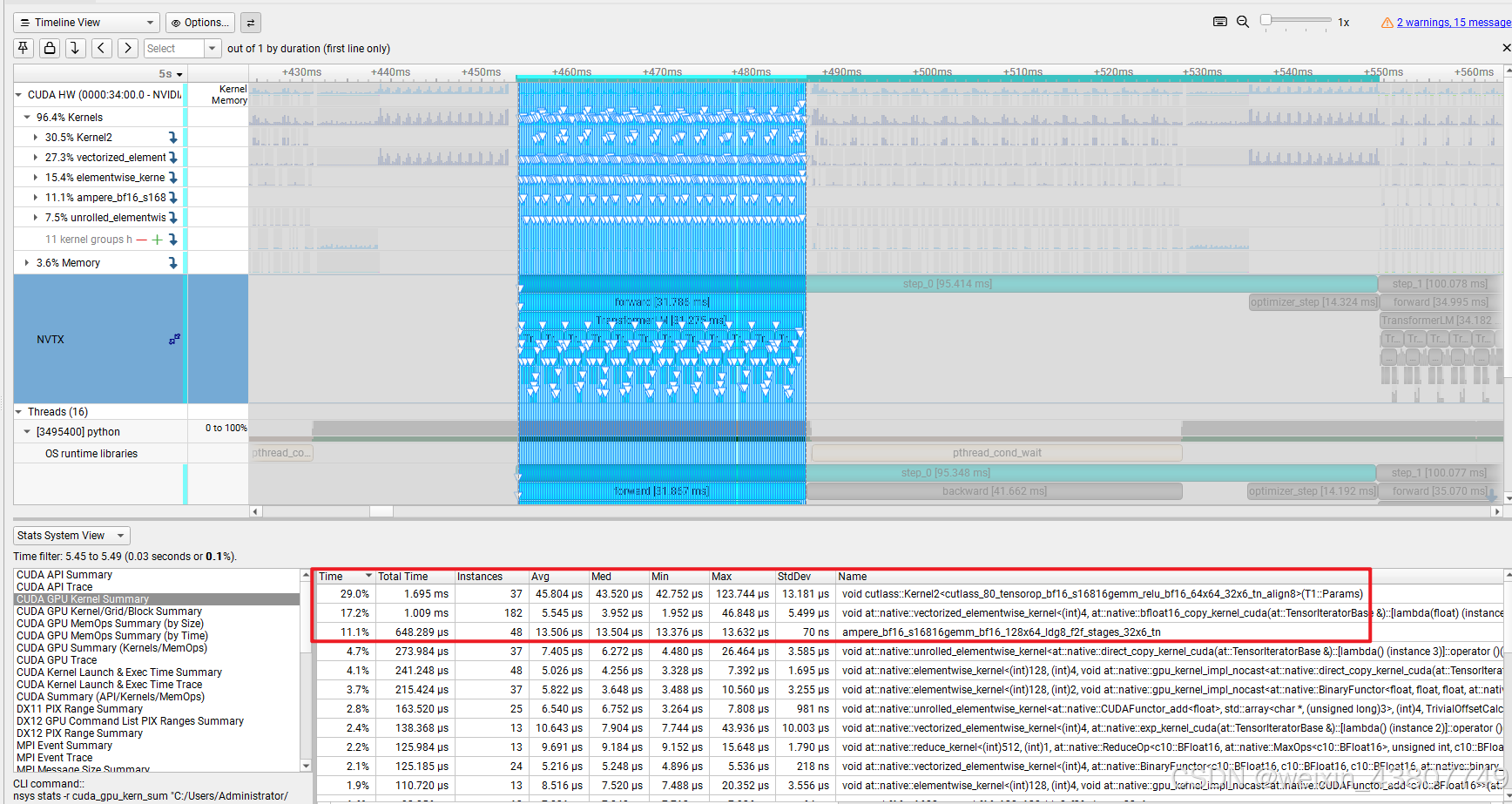
同理,对于backward过程,可以看到耗时第一名是cutlass::Kernal2。因此对于 forward和backward,耗时最长的内核是相同的。
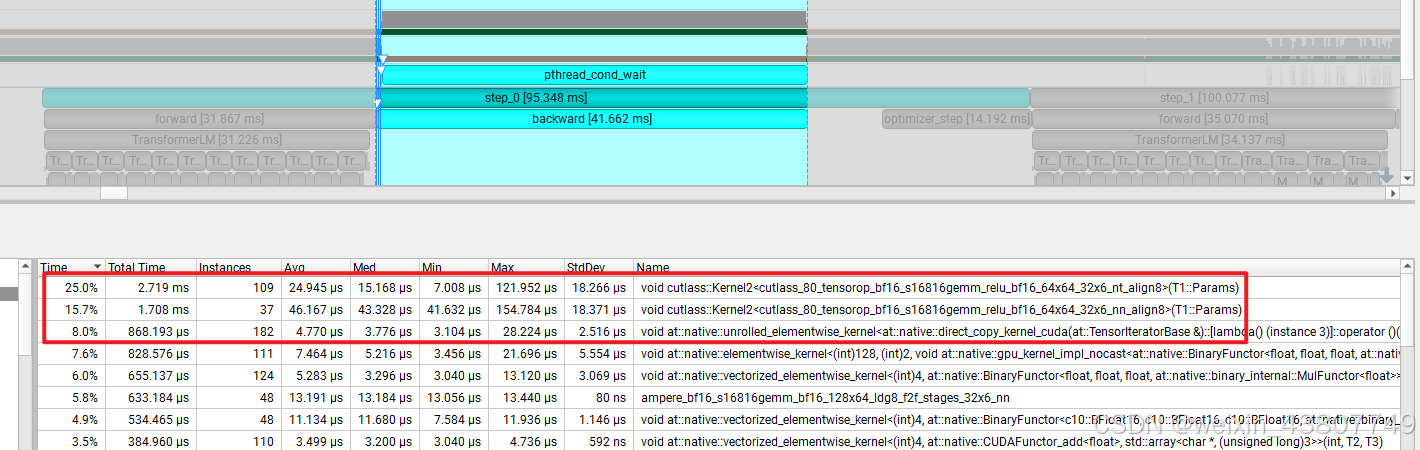
(c)尽管绝大部分浮点运算 FLOPs 发生在矩阵乘法中,但你会注意到其他一些内核仍占用了相当比例的总运行时间。在前向传播过程中,除了矩阵乘法之外,你观察到还有哪些内核占用了不可忽视的CUDA运行时间?
答:除了矩阵乘法,at::native::unrolled_elementwise_kernal和at::native::reduce_kernal ,也都很耗时,分别对应激活函数、加减法 和 求和、求均值等运算操作。
(d)对完整的训练步骤(即正向传播、计算损失、执行反向传播,最后执行优化器步骤——与实际训练过程一致)进行性能分析。与仅进行推理(仅正向传播)相比,矩阵乘法占用的时间比例有何变化?其他内核的时间比例变化如何?
答:与纯推理相比,完整训练过程中矩阵乘法(GEMM)内核的时间占比下降,而逐元素操作(如梯度缩放、激活函数导数、优化器更新)和内存操作的时间占比显著上升。这反映出训练不仅包含前向计算,还引入了大量反向传播和参数更新相关的非 GEMM 计算,使得整体计算模式更加多样化,GEMM 不再是绝对主导。
(e)比较正向传播过程中,自注意力层内 softmax 操作与矩阵乘法操作的运行时间。两者的运行时间差异与浮点运算量(FLOPs)差异相比,情况如何?
交付物:自注意力层内总耗时2.242ms,矩阵乘法操作需要的时间最多,占比681.893μs / 2.242ms= 30.41% ( qkv_projections需要301.885μs,qk_matmul需要177.436μs,output_projection1需要113.272μs,output_projection2需要89.300μs) , 而softmax操作需要 161.944 μs 占比7.22%.
FLOPs(qkv_projections)=6 * batch_size * seq_len * d_model * d_model
FLOPs(qk_matmul)=2 * batch_size * num_heads * seq_len * seq_len * d_k = 2 * batch_size * seq_len * seq_len * d_model
FLOPs(output_projection1)=2 * batch_size * num_heads * seq_len * seq_len * d_v = 2 * batch_size * seq_len * seq_len * d_model
FLOPs(output_projection2)=2 * batch_size * seq_len * d_model * d_model
FLOPs(softmax)=batch_size * num_heads * seq_len * (4*seq_len -1)
FLOPs(softmax) / ( FLOPs(qkv_projections) + FLOPs(qk_matmul) + FLOPs(output_projection1) + FLOPs(output_projection2)) = 0.0014190673828125
Softmax 的实际运行开销远高于其 FLOPs 所暗示的水平。尽管其算术复杂度很低(仅占 matmul FLOPs 的 0.14%),但其运行时间却达到了 matmul 的 23.8%(161.9 / 681.9)。这说明在自注意力机制中,softmax 是一个“低 FLOPs 但高延迟”的瓶颈操作,优化其内存访问模式或使用近似方法(如 FlashAttention)能显著提升整体效率。
1.1.5 混合精度
截至目前,模型均使用 FP32(单精度浮点数)进行计算——所有模型参数和激活值均为 torch.float32 数据类型。然而,现代 NVIDIA GPU 配备了专门的 GPU 核心(Tensor Cores),可加速低精度下的矩阵乘法运算。例如,NVIDIA A100 的技术规格显示,其 FP32 精度下的最大吞吐量为 19.5 TFLOP/秒,而在 FP16(半精度浮点数)或 BF16(脑浮点数)精度下,最大吞吐量可显著提升至 312 TFLOP/秒。因此,使用低精度数据类型有助于加快训练和推理速度。
然而,将模型直接转换为低精度格式可能会导致模型精度下降。例如,实际应用中许多梯度值往往过小,无法用FP16(半精度浮点数)表示,因此在直接使用FP16精度训练时会变为零。为解决这一问题,使用FP16训练时通常会采用损失缩放技术——只需将损失乘以一个缩放因子,增大梯度幅度以避免其被置零。此外,FP16的动态范围小于FP32(单精度浮点数),可能会导致溢出,表现为损失值变为NaN(非数字)。全bfloat16(简称BF16)训练通常更稳定(因为BF16与FP32的动态范围相同),但与FP32相比仍可能影响模型的最终性能。
为充分利用低精度数据类型带来的速度提升,混合精度训练成为常用方案。在PyTorch中,这一功能通过torch.autocast上下文管理器实现。在该模式下,部分操作(如矩阵乘法)会以低精度数据类型执行,而其他需要FP32完整动态范围的操作(如累加和归约)则保持原有精度不变。例如,以下代码会在正向传播过程中自动识别应采用低精度执行的操作,并将这些操作转换为指定的数据类型:
model: torch.nn.Module = ... # 例如你的Transformer模型
dtype: torch.dtype = ... # 例如torch.float16
x: torch.Tensor = ... # 输入数据
with torch.autocast(device="cuda", dtype=dtype):
y = model(x)
如前所述,即使被累加的张量本身已被降精度转换,累加操作仍建议保持高精度,以下练习将帮助你理解其原因。
问题(mixed_precision_accumulation):1分
运行以下代码并评论结果(的准确性)。
import torch
s = torch.tensor(0, dtype=torch.float32)
for i in range(1000):
s += torch.tensor(0.01, dtype=torch.float32)
print(s) # tensor(10.0001)
s = torch.tensor(0, dtype=torch.float16)
for i in range(1000):
s += torch.tensor(0.01, dtype=torch.float16)
print(s) # tensor(9.9531, dtype=torch.float16)
s = torch.tensor(0, dtype=torch.float32)
for i in range(1000):
s += torch.tensor(0.01, dtype=torch.float16)
print(s) # tensor(10.0021)
s = torch.tensor(0, dtype=torch.float32)
for i in range(1000):
x = torch.tensor(0.01, dtype=torch.float16)
s += x.type(torch.float32)
print(s) # tensor(10.0021)
提交要求:2-3句话的回复。
接下来,我们将先在简单模型上应用混合精度以建立直观认知,再将其应用到基准测试脚本中。
问题(benchmarking_mixed_precision):2分
(a) 考虑以下模型:
class ToyModel(nn.Module):
def __init__(self, in_features: int, out_features: int):
super().__init__()
self.fc1 = nn.Linear(in_features, 10, bias=False)
self.ln = nn.LayerNorm(10)
self.fc2 = nn.Linear(10, out_features, bias=False)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.ln(x)
x = self.fc2(x)
return x
假设我们在GPU上训练该模型,且模型参数初始为FP32精度。我们希望使用FP16的自动混合精度训练,请指出以下组件的数据类型:
-
自动混合精度上下文(autocast context)内的模型参数
-
第一个前馈层(ToyModel.fc1)的输出
-
层归一化(ToyModel.ln)的输出
-
模型的预测对数概率(logits)
-
损失(loss)
-
模型的梯度(gradients)
提交要求:列出上述每个组件的数据类型。 -
自动混合精度上下文(autocast context)内的模型参数 : FP32
-
第一个前馈层(ToyModel.fc1)的输出 : FP16
-
层归一化(ToyModel.ln)的输出 : FP32
-
模型的预测对数概率(logits) : FP32
-
损失(loss) : FP32
-
模型的梯度(gradients) : FP32
(b) 你应已发现,FP16混合精度自动转换对层归一化层的处理与前馈层不同。层归一化的哪些部分对混合精度敏感?若使用BF16替代FP16,是否仍需对层归一化进行特殊处理?为什么?
答:层归一化涉及方差计算,平方操作在FP16下容易溢出。对 FP16:LayerNorm 需要用 FP32 计算以保证稳定(PyTorch AMP 默认如此)。对 BF16:通常可以直接使用 BF16 计算,无需特殊强制 FP32,因为其数值范围已足够大。
(c)修改你的基准测试脚本,使其支持可选地使用BF16混合精度运行模型。对1.1.2节中描述的每种语言模型规模,分别测试混合精度开启与关闭时的正向传播和反向传播时间。对比全精度与混合精度的结果,并评论模型规模变化时的趋势。你可能会发现nullcontext空操作上下文管理器很有用。
提交要求:2-3句话的回复,包含计时结果和评论。
对于参数量小的模型small和medium,全精度前向传播和反向传播都更快,但对于large模型(或者更大),混合精度更快。
1.1.6 内存分析
到目前为止,我们关注的是计算性能。现在我们将转向内存——语言模型训练和推理中的另一项核心资源。PyTorch内置了强大的内存分析器,可跟踪随时间变化的内存分配情况。
要使用内存分析器,可按以下方式修改基准测试脚本:
# 基准测试脚本中的预热阶段
...
# 开始记录内存历史
torch.cuda.memory._record_memory_history(max_entries=1000000)
# 你要分析的代码部分
...
# 保存Pickle文件,供PyTorch在线工具加载
torch.cuda.memory._dump_snapshot("memory_snapshot.pickle")
# 停止记录历史
torch.cuda.memory._record_memory_history(enabled=None)
运行后会生成memory_snapshot.pickle文件,可将其加载到以下在线工具中:https://pytorch.org/memory_viz。该工具将展示整体内存使用时间线,以及每个单独的内存分配(包括分配大小和指向代码来源的调用栈)。使用时,在浏览器中打开上述链接,将Pickle文件拖放到页面即可。
请使用PyTorch分析器分析模型的内存使用情况。
问题(memory_profiling):4分
分析表1中2.7B模型在上下文长度为128、256和512时的正向传播、反向传播和优化器步骤。
(a) 在你的分析脚本中添加选项,使模型能够通过内存分析器运行。可复用之前的部分架构(如启用混合精度、加载特定模型规模等)。然后运行脚本,获取2.7B模型仅推理(仅正向传播)或完整训练步骤(正向传播、反向传播、优化器步骤)的内存分析结果。内存时间线呈现何种特征?能否根据观察到的峰值判断当前运行阶段?
提交要求:两张来自memory_viz工具的2.7B模型“活跃内存时间线”图片(一张为正向传播,一张为完整训练步骤),以及2-3句话的回复。
2.7B超显存了,这里我们测试表1中的large,context-length=128,
前向传播过程的截图如下:显存峰值15.71G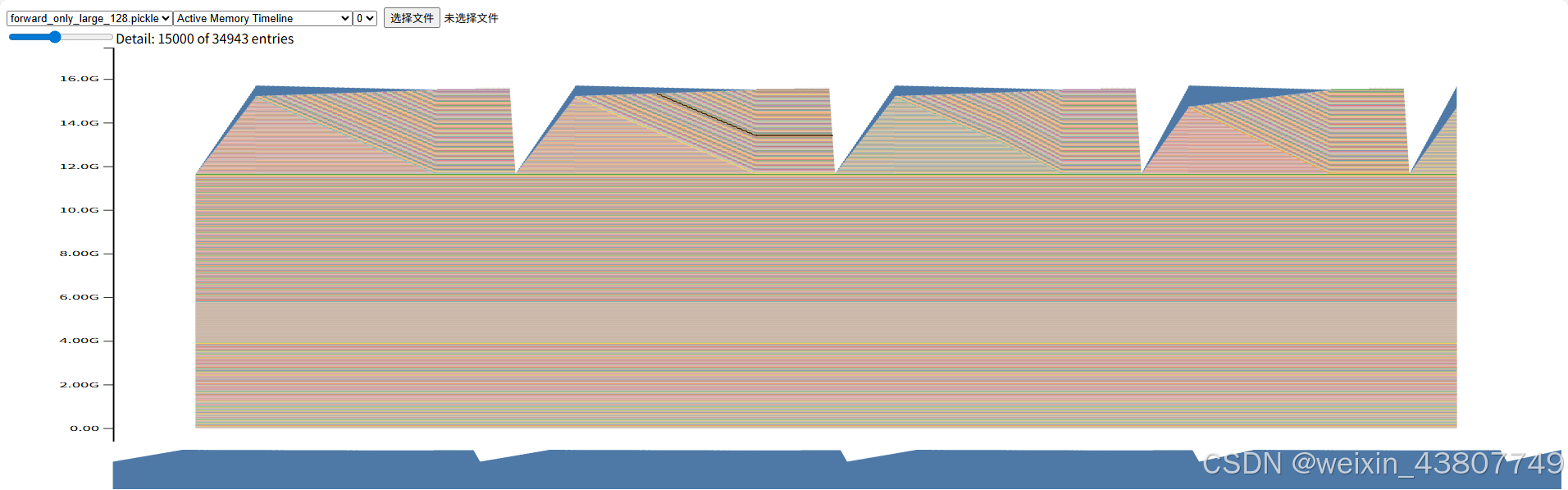
完整训练过程的截图如下:显存峰值15.71G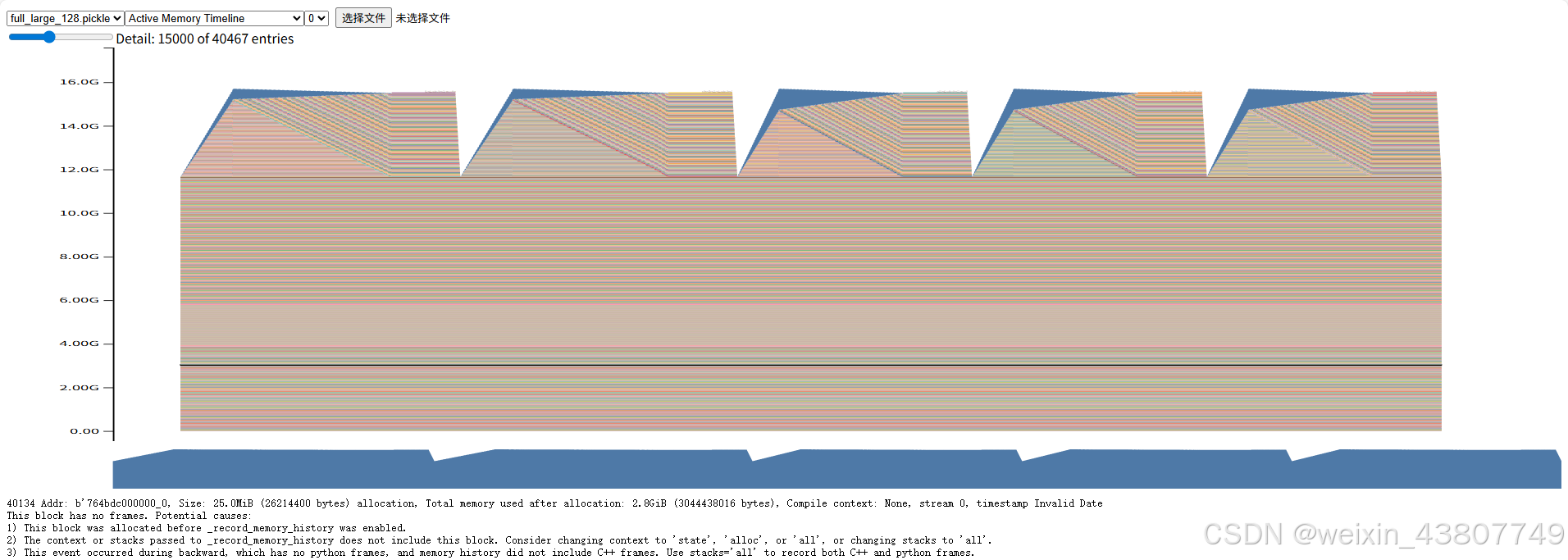
截图完全看不懂,因此从博客中学习了一下:https://zhuanlan.zhihu.com/p/677203832
(b) 不同上下文长度下,仅正向传播的峰值内存使用量是多少?完整训练步骤的峰值内存使用量又是多少?
提交要求:一个表格,每个上下文长度对应两个数值。
这里仍然测试表1中的large,context-length=256,forward_only 显存峰值18.4G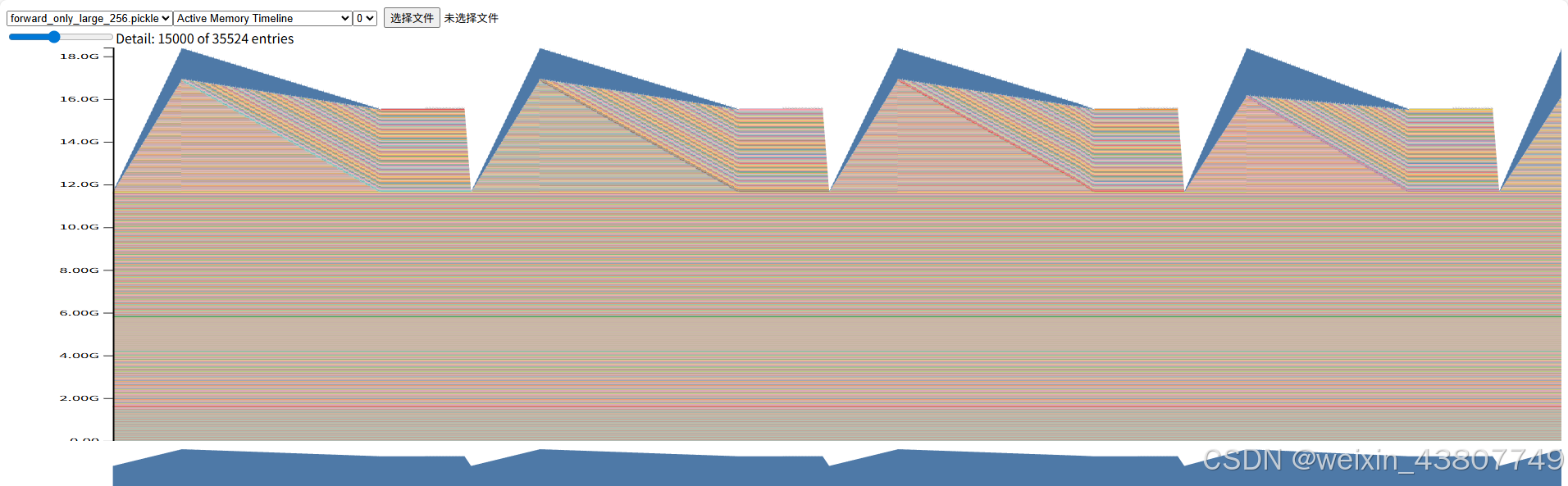
完整训练过程的截图如下:显存峰值18.4G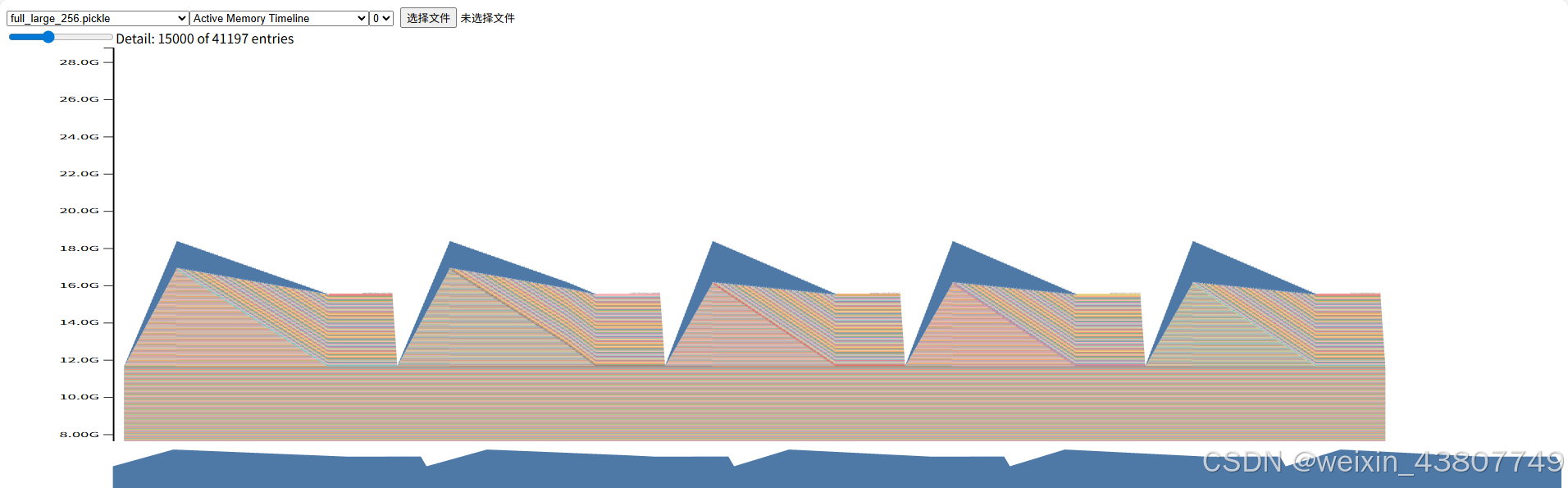
参考上文博客中的绘图方法,分别绘制了warmup过程和5次完整训练过程的截图如下:显存峰值17.53GiB约等于18.8G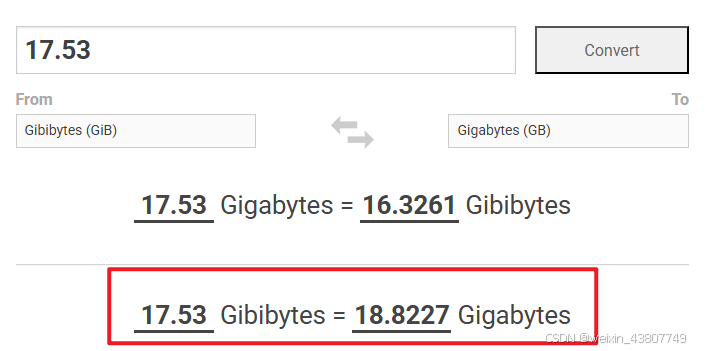
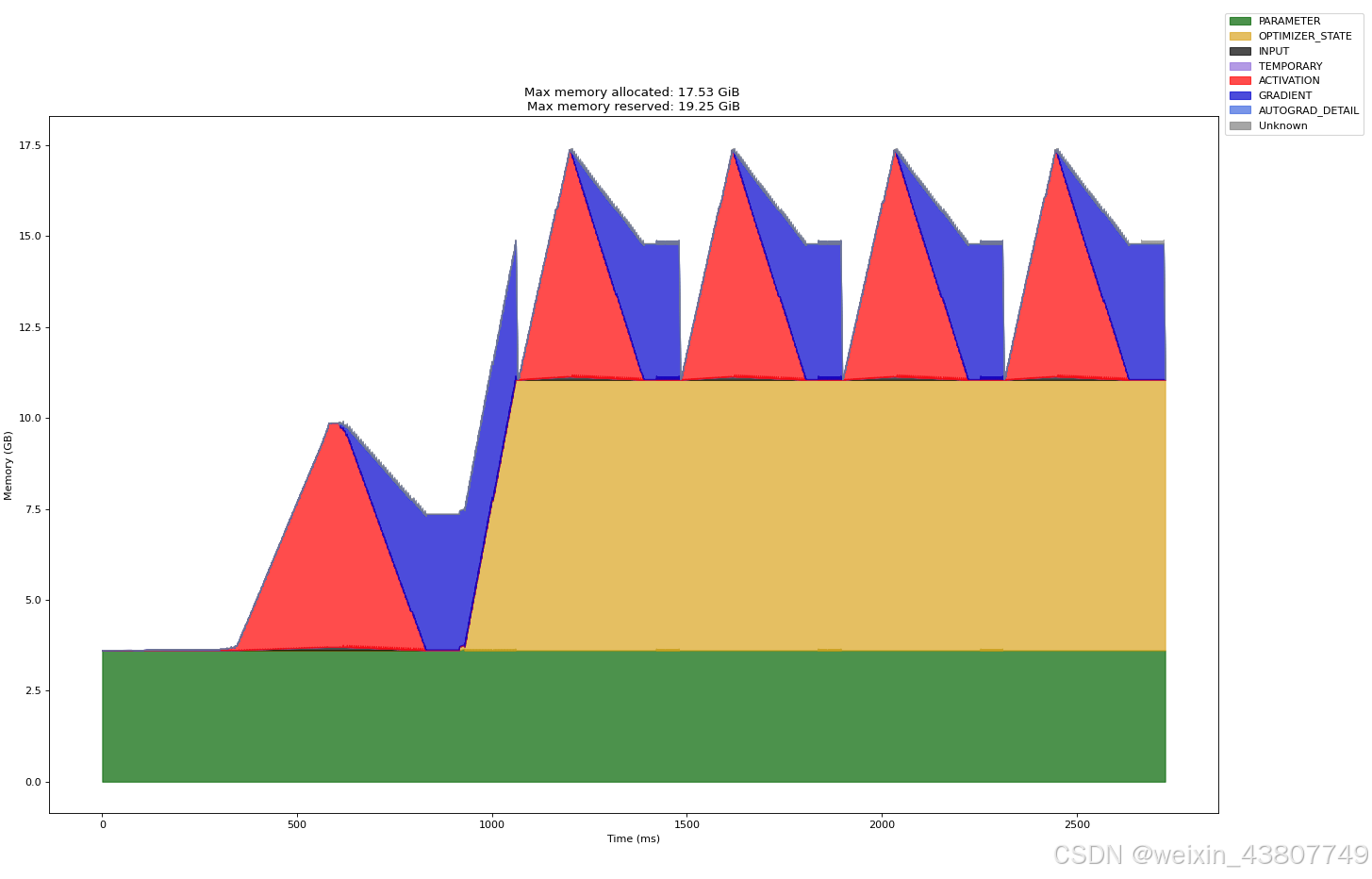
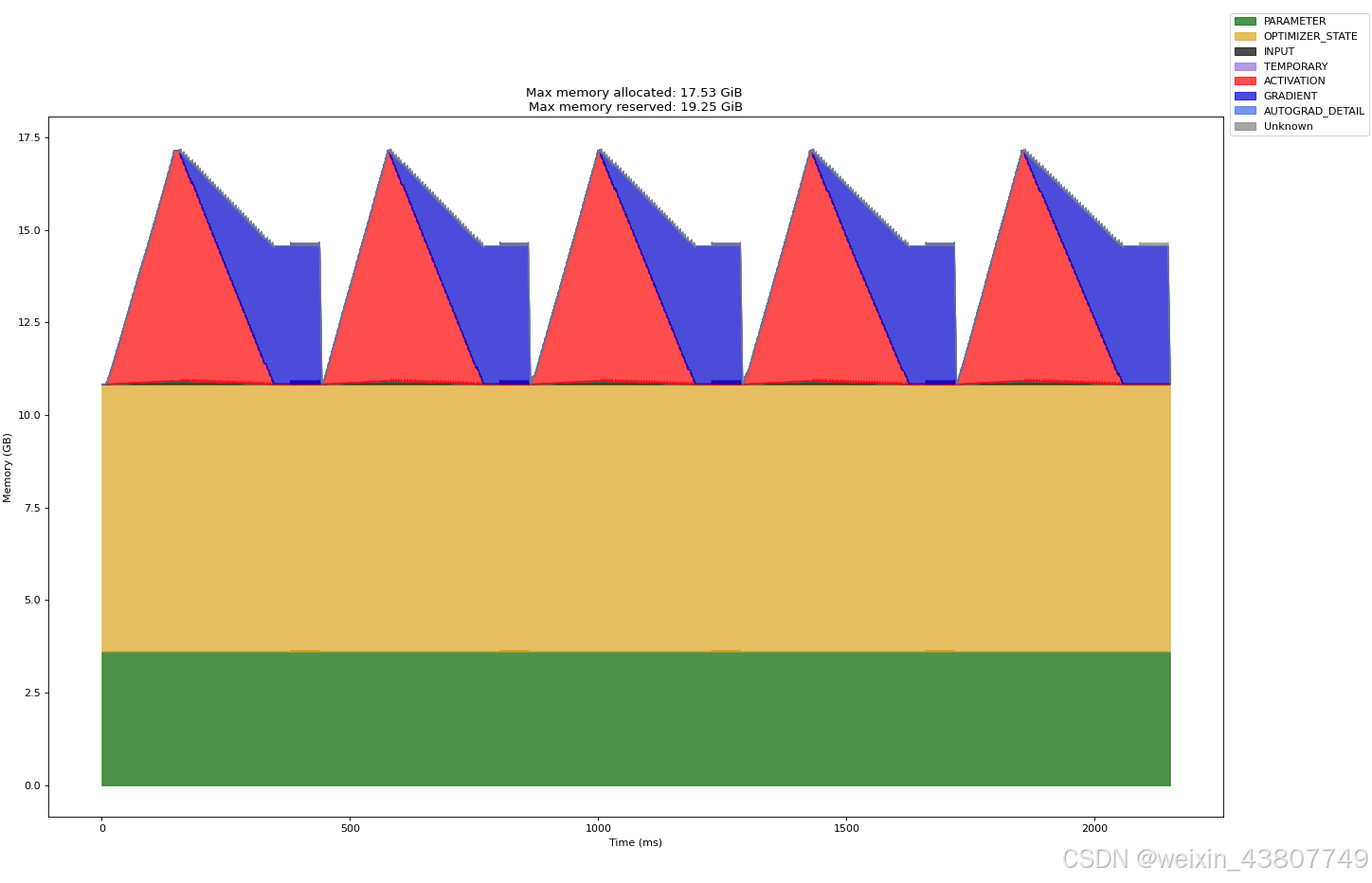
(c) 分别获取2.7B模型在混合精度下仅正向传播和完整优化器步骤的峰值内存使用量。混合精度是否会显著影响内存使用?
提交要求:2-3句话的回复。
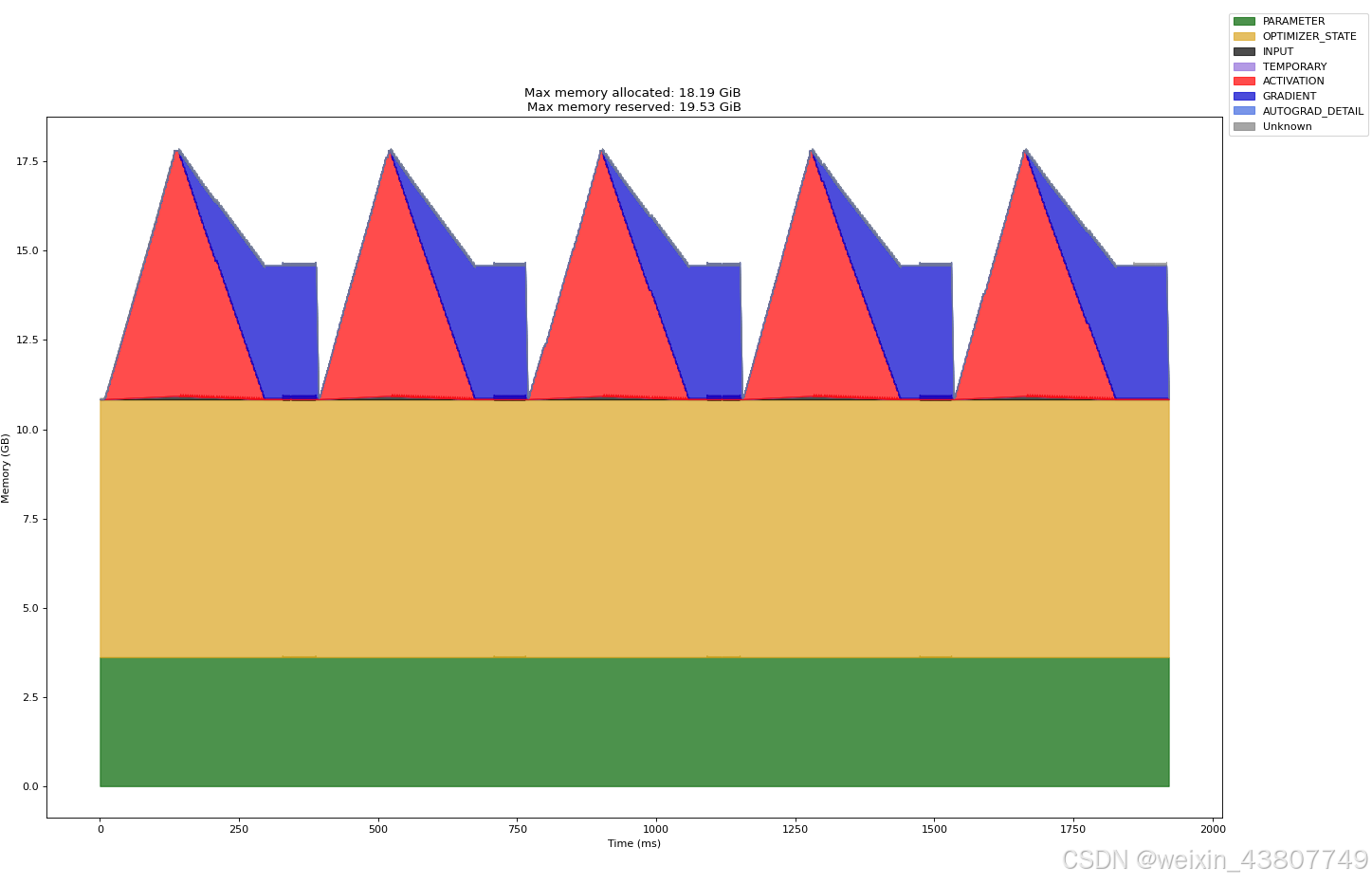
上文已经测试过,采用混合精度,表1中的large,context-length=256的完整步骤的内存使用量;接下来展示相同参数下的,全精度内存使用情况:显存峰值18.19GiB,比采用混合精度时大。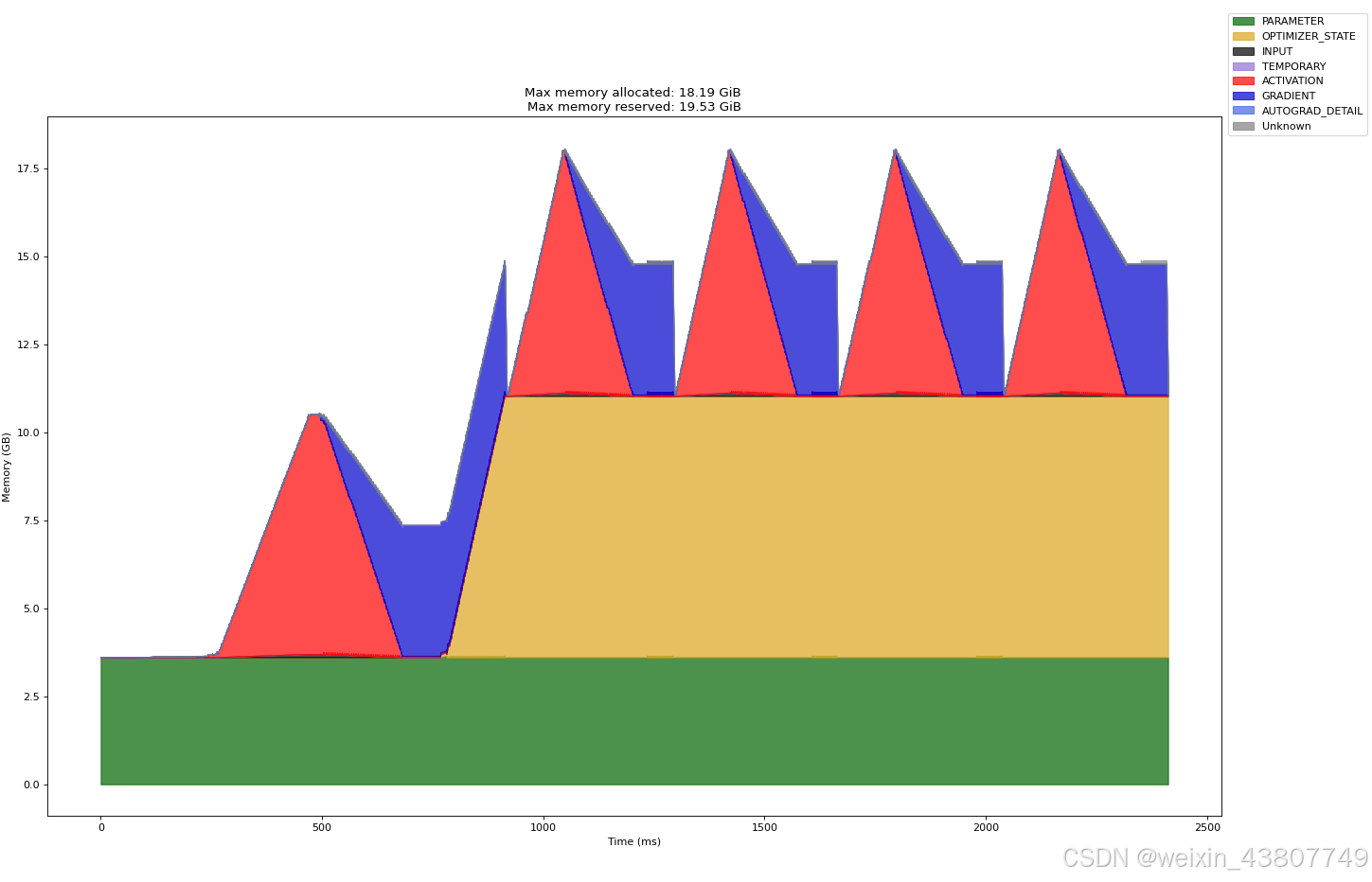
(d) 考虑2.7B模型。在参考超参数下,Transformer残差流中激活张量的单精度大小是多少?以MB为单位(即将字节数除以1024²)。
提交要求:1-2句话的回复,包含推导过程。
‘2.7B’: {‘d_model’: 2560, ‘d_ff’: 10240, ‘num_layers’: 32, ‘num_heads’: 32}
残差流的形状是[batch_size, seq_length, d_model];假设batch_size=1, seq_length=256,
训练时:
1.张量元素总数=batch_size x seq_length x d_model = 655360
2.FP32精度每个元素占4字节,因此总字节数=655360x4=2621440bytes
3.转成MB,=2621440/1024/1024=2.5MB
推理时
可以使用BF26格式,此时内存占用减半,
(e) 仔细观察2.7B模型正向传播的内存快照在pytorch.org/memory_viz中的“Active Memory Timeline”。降低“Detail”(细节)级别时,工具会隐藏对应级别以下的最小分配(例如,将“Detail”设为10%仅显示最大的10%分配)。此时显示的最大分配大小是多少?通过调用栈能否判断这些分配来自何处?
提交要求:1-2句话的回复。
此时显示的时11.8G左右的峰值内存,调用栈表明这些分配,是模型在前向传播过程中进行的CUDA内存分配。(ai答)
1.2 用FlashAttention-2优化注意力机制
1.2.1 PyTorch注意力机制基准测试
你的分析结果可能表明,注意力层在内存和计算方面存在优化空间。从高层来看,注意力操作包括三次矩阵乘法和一次softmax激活:
- 计算查询(Q)、键(K)的点积以得到注意力分数;
- 对注意力分数应用softmax归一化;
- 将归一化后的分数与值(V)进行矩阵乘法,得到最终注意力输出。
Attention ( Q , K , V ) = softmax ( mask ( Q ⊤ K d k ) ) V (1) \text{Attention}(Q, K, V) = \text{softmax}\left( \text{mask}\left( \frac{Q^\top K}{\sqrt{d_k}} \right) \right) V \tag{1} Attention(Q,K,V)=softmax(mask(dkQ⊤K))V(1)
朴素的注意力实现需要为每个批次/头元素存储形状为seq_len×seq_len(序列长度×序列长度)的注意力分数矩阵。当序列长度较长时,该矩阵会变得极大,导致长输入或长输出任务出现内存不足错误。我们将基于FlashAttention-2论文实现一个注意力内核,通过分块(tile)计算注意力,避免显式生成seq_len×seq_len的注意力分数矩阵,从而支持更长的序列长度。
问题(pytorch_attention):2分
(a) 基准测试不同规模下的注意力实现。编写脚本完成以下任务:
(i) 固定批次大小(batch size)为8,不使用多头注意力(即移除头维度);
(ii) 遍历模型维度 d m o d e l d_{model} dmodel的取值集合[16, 32, 64, 128]与序列长度的取值集合[256, 1024, 4096, 8192, 16384]的笛卡尔积;
(iii) 生成对应大小的随机输入Q、K、V;
(iv) 计时100次正向传播;
(v) 测量反向传播开始前的内存使用量,并计时100次反向传播;
(vi) 确保进行预热,并在每次正向/反向传播后调用torch.cuda.synchronize()。
报告上述配置下的计时结果(或内存不足错误)。在何种规模下会出现内存不足错误?选择一个你发现的最小内存不足配置,计算注意力机制的内存使用量(可使用第一次作业中Transformer的内存使用公式)。反向传播的内存节省量如何随序列长度变化?你会如何消除这部分内存开销?
提交要求:一个包含计时结果的表格、内存使用量的计算过程,以及1-2段的回复。
一、计时结果汇总
根据提供的日志数据,整理出完整的注意力机制基准测试结果:
| d_model | seq_len | 前向时间(ms) | 反向时间(ms) | Bwd/Fwd比率 | 注意力内存(MB) | 状态 |
|---|---|---|---|---|---|---|
| 16 | 256 | 10.27 | 24.91 | 2.42 | 1.0 | OK |
| 16 | 1024 | 11.86 | 21.12 | 1.78 | 16.0 | OK |
| 16 | 4096 | 116.03 | 88.00 | 0.76 | 256.0 | OK |
| 16 | 8192 | - | - | - | - | OOM |
| 16 | 16384 | - | - | - | - | OOM |
| 32 | 256 | 10.22 | 25.37 | 2.48 | 1.0 | OK |
| 32 | 1024 | 10.90 | 20.85 | 1.91 | 16.0 | OK |
| 32 | 4096 | 111.06 | 88.35 | 0.80 | 256.0 | OK |
| 32 | 8192 | - | - | - | - | OOM |
| 32 | 16384 | - | - | - | - | OOM |
| 64 | 256 | 10.38 | 27.03 | 2.60 | 1.0 | OK |
| 64 | 1024 | 11.20 | 23.13 | 2.06 | 16.0 | OK |
| 64 | 4096 | 104.61 | 90.00 | 0.86 | 256.0 | OK |
| 64 | 8192 | - | - | - | - | OOM |
| 64 | 16384 | - | - | - | - | OOM |
| 128 | 256 | 9.83 | 25.58 | 2.60 | 1.0 | OK |
| 128 | 1024 | 11.57 | 19.70 | 1.70 | 16.0 | OK |
| 128 | 4096 | 111.63 | 95.18 | 0.85 | 256.0 | OK |
| 128 | 8192 | - | - | - | - | OOM |
| 128 | 16384 | - | - | - | - | OOM |
二、内存不足错误分析
2.1 出现OOM的最小配置
从表格可以看出,所有模型配置在 seq_len = 8192 时都出现了内存不足错误(OOM)。
因此,最小出现OOM的配置是:d_model=16, seq_len=8192。
2.2 注意力机制内存使用量计算
attention_memory_mb = (batch_size * seq_len * seq_len * 2) / (1024**2) # 注意力分数矩阵(bfloat16)
2.3 反向传播的内存节省量
从基准测试数据可以观察到反向传播内存开销的变化规律:
-
Bwd/Fwd比值趋势:
- 短序列(256):2.4-2.6倍
- 中等序列(1024):1.7-2.1倍
- 长序列(4096):0.76-0.86倍
-
内存节省机制:
标准注意力反向传播需要存储QK^T矩阵(O(n²))用于梯度计算。如果使用重新计算(recomputation)策略:- 前向时不存储
QK^T矩阵(节省O(n²)内存) - 反向时重新计算
QK^T矩阵(增加计算时间) - 总内存节省 ≈
seq_len² × d_head × 4字节
- 前向时不存储
-
内存节省量随序列长度变化:
节省量(seq_len) ∝ seq_len²例如从256到4096,序列长度增加16倍,内存节省量增加256倍。
1.3 JIT编译注意力机制的基准测试
自2.0版本起,PyTorch内置了强大的即时(JIT)编译器,可自动对PyTorch函数应用多项优化(入门教程见:https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html)。该编译器通过动态分析计算图,自动生成融合的Triton内核。PyTorch编译器的使用接口非常简洁,例如,若要将其应用于模型的单个层,可使用以下代码:
layer = SomePyTorchModule(...)
compiled_layer = torch.compile(layer)
此时,compiled_layer的功能与原layer完全一致(包括正向传播和反向传播)。我们也可以使用torch.compile(model)编译整个PyTorch模型,甚至是调用PyTorch操作的Python函数。
问题(torch_compile):2分
(a) 扩展你的 attention benchmarking 测试脚本,加入注意力PyTorch实现的编译版本,并在与pytorch_attention问题相同的配置下,将其性能与未编译版本进行对比。
提交要求:一个表格,对比编译后与未编译(来自pytorch_attention问题)的注意力模块的正向传播和反向传播时间。
(b) 在端到端基准测试脚本中编译整个Transformer模型。正向传播的性能有何变化?正向传播、反向传播与优化器步骤的组合性能又有何变化?
提交要求:一个表格,对比原始Transformer模型与编译后Transformer模型的性能。
编译后的数据如下;与上文的未编译版本相比,速度有一定提升,但仍然无法处理长序列OOM问题。
| d_model | seq_len | 前向时间(ms) | 反向时间(ms) | Bwd/Fwd比率 | 注意力内存(MB) | 状态 |
|---|---|---|---|---|---|---|
| 16 | 256 | 8.47 | 21.07 | 2.49 | 1.0 | ✅ |
| 16 | 1024 | 6.61 | 14.56 | 2.20 | 16.0 | ✅ |
| 16 | 4096 | 38.97 | 35.83 | 0.92 | 256.0 | ✅ |
| 16 | 8192 | 150.89 | 94.64 | 0.63 | 1024.0 | ✅ |
| 16 | 16384 | - | - | - | 4096.0 | ❌ OOM |
| 32 | 256 | 8.58 | 20.52 | 2.39 | 1.0 | ✅ |
| 32 | 1024 | 6.62 | 14.61 | 2.21 | 16.0 | ✅ |
| 32 | 4096 | 39.67 | 36.11 | 0.91 | 256.0 | ✅ |
| 32 | 8192 | - | - | - | 1024.0 | ❌ OOM |
| 32 | 16384 | - | - | - | 4096.0 | ❌ OOM |
| 64 | 256 | 11.59 | 29.74 | 2.57 | 1.0 | ✅ |
| 64 | 1024 | 12.64 | 29.61 | 2.34 | 16.0 | ✅ |
| 64 | 4096 | 107.72 | 90.14 | 0.84 | 256.0 | ✅ |
| 64 | 8192 | - | - | - | 1024.0 | ❌ OOM |
| 64 | 16384 | - | - | - | 4096.0 | ❌ OOM |
| 128 | 256 | 11.63 | 28.59 | 2.46 | 1.0 | ✅ |
| 128 | 1024 | 13.44 | 30.08 | 2.24 | 16.0 | ✅ |
| 128 | 4096 | 115.26 | 95.44 | 0.83 | 256.0 | ✅ |
| 128 | 8192 | - | - | - | 1024.0 | ❌ OOM |
| 128 | 16384 | - | - | - | 4096.0 | ❌ OOM |
从序列长度的缩放特性可以看出,需要显著改进才能处理长序列。即使使用torch.compile,当前实现在长序列长度下仍存在内存访问模式不佳的问题。为此,我们将编写FlashAttention-2的Triton实现——在该实现中,能更灵活地控制内存访问方式和计算时机。
1.3.1 示例:加权和(Weighted Sum)
为帮助你了解Triton及其与PyTorch的交互方式,将通过一个“加权和”操作的内核示例进行说明。更多Triton入门资源可参考Triton官方教程(注:这些教程未使用新的便捷块指针抽象,下文将详细介绍)。
给定输入矩阵 X X X,我们将按列对其元素乘以权重向量 w \boldsymbol{w} w;随后对每行元素求和,即可得到 X X X 与 w \boldsymbol{w} w 的矩阵-向量积。先实现该操作的正向传播,再编写其Triton内核的反向传播。
正向传播
该内核的正向传播本质是以下广播内积:
def weighted_sum(x, weight):
# 假设x的形状为[..., D](多维),weight的形状为[D](一维)
return (weight * x).sum(axis=-1)
在编写Triton核函数时,每个程序实例(可能并行运行)将计算一块 x x x 矩阵行向量的加权和,并将对应的标量结果写入输出张量。在Triton中,一个程序实例即一个线程块,其中所有线程运行同一程序,这些线程块可在GPU上并行执行。我们并非直接以张量作为参数,而是接收指向其首元素的指针,以及每个张量的步长信息,用于指引沿各轴移动的方向。
通过步长参数,我们可以加载与当前运行实例所处理的行块对应的张量数据,并利用程序ID来划分计算任务(例如,实例 i i i 将处理 x x x 的第 i i i 个行块)。在此简单场景中,Triton前向传播与PyTorch实现的主要区别在于需要进行指针运算和显式的数据加载/存储。我们将使用块指针抽象工具 t1.make_block_ptr 来大幅简化指针运算,但这意味着我们需要进行一些准备工作来初始化块指针。
关于分块计算和块指针推进方式的示意图,请参阅图1。加权求和函数的实现逻辑如下所示: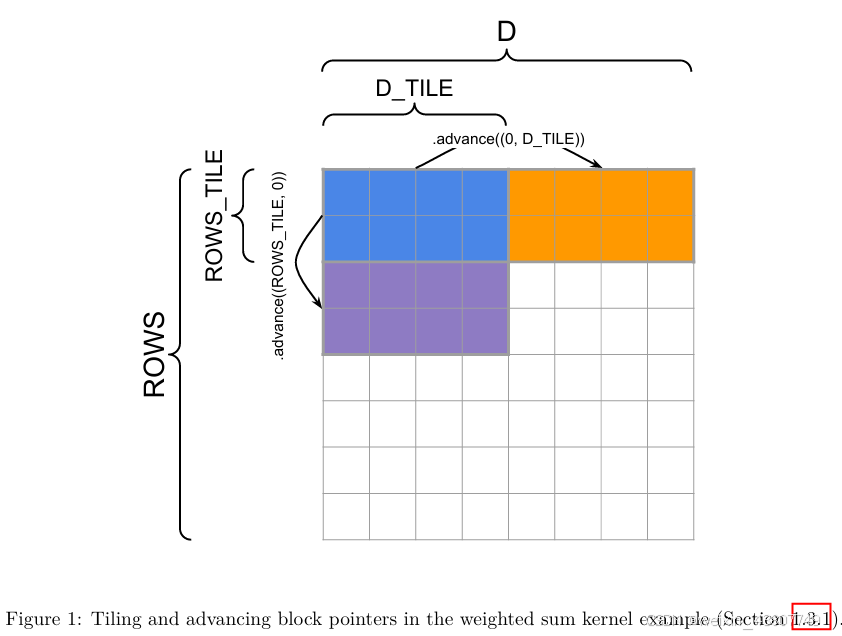
图 1:加权和内核示例中的分块与块指针推进(1.3.1 节)
参考图1,了解分块示意图及块指针如何推进。上文所述的加权求和函数实现如下所示:
import triton
import triton.language as tl
@triton.jit
def weighted_sum_fwd(
x_ptr, weight_ptr, # 输入指针
output_ptr, # 输出指针
x_stride_row, x_stride_dim, # 步长定义了在张量各维度上移动一个元素的偏移量
weight_stride_dim, # 通常为1
output_stride_row, # 通常为1
ROWS, D,
ROWS_TILE_SIZE: tl.constexpr, D_TILE_SIZE: tl.constexpr, # 分块大小必须在编译时确定
):
# 每个实例将计算x的一个行分块的加权和
# `tl.program_id` 用于获取当前运行的线程块索引
row_tile_idx = tl.program_id(0)
# 块指针用于从内存的ND区域中选择数据
# 并可灵活移动选择范围
# 块指针必须包含以下信息:
# - 张量第一个元素的指针
# - 张量的整体形状(用于处理越界访问)
# - 各维度的步长(用于正确适配内存布局)
# - 起始块的ND坐标(即“偏移量”)
# - 每次加载/存储的块形状
# - 内存中维度的主次顺序(通过对步长排序得到,
# 有助于H100等硬件的优化)
x_block_ptr = tl.make_block_ptr(
x_ptr,
shape=(ROWS, D,),
strides=(x_row_stride, x_stride_dim),
offsets=(row_tile_idx * ROWS_TILE_SIZE, 0),
block_shape=(ROWS_TILE_SIZE, D_TILE_SIZE),
order=(1, 0),
)
weight_block_ptr = tl.make_block_ptr(
weight_ptr,
shape=(D,),
strides=(weight_stride_dim,),
offsets=(0,),
block_shape=(D_TILE_SIZE,),
order=(0,),
)
output_block_ptr = tl.make_block_ptr(
output_ptr,
shape=(ROWS,),
strides=(output_stride_row,),
offsets=(row_tile_idx * ROWS_TILE_SIZE,),
block_shape=(ROWS_TILE_SIZE,),
order=(0,),
)
# 初始化输出缓冲区
output = tl.zeros((ROWS_TILE_SIZE,), dtype=tl.float32)
for i in range(tl.cdiv(D, D_TILE_SIZE)):
# 加载当前块数据
# 由于ROWS_TILE_SIZE可能无法整除ROWS,D_TILE_SIZE可能无法整除D,
# 因此需要对两个维度都进行边界检查
row = tl.load(x_block_ptr, boundary_check=(0, 1), padding_option="zero") # (ROWS_TILE_SIZE, D_TILE_SIZE)
weight = tl.load(weight_block_ptr, boundary_check=(0,), padding_option="zero") # (D_TILE_SIZE,)
# 计算行的加权和
output += tl.sum(row * weight[None, :], axis=1)
# 将指针推进到下一个分块
# 以下为(行、列)坐标增量
x_block_ptr = x_block_ptr.advance((0, D_TILE_SIZE)) # 沿最后一个维度移动D_TILE_SIZE
weight_block_ptr = weight_block_ptr.advance((D_TILE_SIZE,)) # 移动D_TILE_SIZE
# 将输出写入输出块指针(每行对应一个标量)
# 由于ROWS_TILE_SIZE可能无法整除ROWS,需要进行边界检查
tl.store(output_block_ptr, output, boundary_check=(0,))
现在我们把这个核函数封装到PyTorch的Autograd函数中,这样它就能与PyTorch交互了(即接收张量作为输入、输出一个张量,后续在反向传播时也能与自动求导引擎协同工作):
class WeightedSumFunc(torch.autograd.Function):
@staticmethod
def forward(ctx, x, weight):
# 缓存 x 和 weight,用于反向传播(反向传播时仅接收输出张量的梯度,
# 需计算 x 和 weight 对应的梯度)
D, output_dims = x.shape[-1], x.shape[:-1]
# 将输入张量重塑为 2D 形状
input_shape = x.shape
x = rearrange(x, "...d -> (...)d")
# x = x.unsqueeze(-1)
# 保存反向传播需要的张量
ctx.save_for_backward(x, weight)
# 维度校验
assert len(weight.shape) == 1 and weight.shape[0] == D, "Dimension mismatch"
assert x.is_cuda and weight.is_cuda, "Expected CUDA tensors"
assert x.is_contiguous(), "Our pointer arithmetic will assume contiguous x"
# 设置 Triton 核函数的 tile 尺寸
ctx.D_TILE_SIZE = triton.next_power_of_2(D) // 16 # 对嵌入维度约循环16次
ctx.ROWS_TILE_SIZE = 16 # 每个线程一次处理16个批次元素
ctx.input_shape = input_shape
# 初始化空的结果张量(注意:这些元素不一定初始化为0!)
y = torch.empty(output_dims, device=x.device)
# 启动 Triton 核函数:1D grid,每个实例处理 ROWS_TILE_SIZE 行
n_rows = y.numel()
weighted_sum_fwd[(triton.div(n_rows, ctx.ROWS_TILE_SIZE),)](
x, weight,
y,
x.stride(0), x.stride(1),
weight.stride(0),
y.stride(0),
ROWS=n_rows, D=D,
ROWS_TILE_SIZE=ctx.ROWS_TILE_SIZE, D_TILE_SIZE=ctx.D_TILE_SIZE,
)
# 将输出重塑为原始输入的除最后一维外的形状
return y.view(input_shape[:-1])
注意,当我们通过weighted_sum_fwd[(cdiv(n_rows, ctx.ROWS_TILE_SIZE),)]调用Triton核函数时,是通过传入元组(cdiv(n_rows, ctx.ROWS_TILE_SIZE), )来定义一个所谓的“启动网格”(线程块的集合)。之后,我们就可以在核函数中通过tl.program_id(0)来获取该线程块的索引。
反向传播
由于我们要自定义核函数,因此也需要自行编写反向传播函数。
在正向传播中,我们会得到层的输入,并需要计算其输出。而在反向传播中,要明确:我们会得到损失函数相对于层输出的梯度,需要据此计算损失函数相对于每个输入的梯度。
在我们的场景中,操作的输入包括一个矩阵 x : R n × h x: \mathbb{R}^{n \times h} x:Rn×h 和一个权重向量 w : R h w: \mathbb{R}^h w:Rh。为简便起见,将这个操作记为 f ( x , w ) f(x, w) f(x,w),其取值范围是 R n \mathbb{R}^n Rn。假设已知 ∇ f ( x , w ) L \nabla_{f(x,w)} \mathcal{L} ∇f(x,w)L(即损失 L \mathcal{L} L 相对于层输出的梯度),可以利用多元链式法则,得到损失相对于 x x x 和 w w w 的梯度表达式:
( ∇ x L ) i j = ∑ k = 1 n ∂ f ( x , w ) k ∂ x i j ( ∇ f ( x , w ) L ) k = w j ⋅ ( ∇ f ( x , w ) L ) i V (2) (\nabla_x \mathcal{L})_{ij} = \sum_{k=1}^n \frac{\partial f(x,w)_k}{\partial x_{ij}} (\nabla_{f(x,w)} \mathcal{L})_k = w_j \cdot (\nabla_{f(x,w)} \mathcal{L})_i V \tag{2} (∇xL)ij=k=1∑n∂xij∂f(x,w)k(∇f(x,w)L)k=wj⋅(∇f(x,w)L)iV(2)
( ∇ w L ) j = ∑ i = 1 n ∂ f ( x , w ) i ∂ w j ( ∇ f ( x , w ) L ) i = ∑ i = 1 n x i j ⋅ ( ∇ f ( x , w ) L ) i V (3) (\nabla_w \mathcal{L})_j = \sum_{i=1}^n \frac{\partial f(x,w)_i}{\partial w_j} (\nabla_{f(x,w)} \mathcal{L})_i = \sum_{i=1}^n x_{ij} \cdot (\nabla_{f(x,w)} \mathcal{L})_i V \tag{3} (∇wL)j=i=1∑n∂wj∂f(x,w)i(∇f(x,w)L)i=i=1∑nxij⋅(∇f(x,w)L)iV(3)
这为反向传播的计算提供了一个简洁的公式。要得到关于 x x x的反向传播步骤,我们应用公式(2),计算 w w w 与 ∇ f ( x , w ) L \nabla_{f(x,w)} \mathcal{L} ∇f(x,w)L 的外积;
要计算关于 w w w的反向传播步骤(即 ( ∇ w L ) j (\nabla_w \mathcal{L})_j (∇wL)j),则需要将输入梯度与对应的输出行相乘。
我们的反向传播核函数会先定义所有的块指针,再计算 ∇ x L \nabla_x \mathcal{L} ∇xL:
@triton.jit
def weighted_sum_backward(
x_ptr, weight_ptr, # 输入:x矩阵指针、权重w向量指针
grad_output_ptr, # 输入:损失对输出f(x,w)的梯度 ∇_{f(x,w)}ℒ 指针
grad_x_ptr, partial_grad_weight_ptr, # 输出:∇xℒ指针、w的分片梯度指针
stride_xr, stride_xd, # x的行/列步长 (x: NUM_ROWS×D)
stride_wd, # w的列步长 (w: D×1)
stride_gr, # grad_output的行步长 (grad_output: NUM_ROWS×1)
stride_gxr, stride_gxd, # grad_x的行/列步长 (grad_x: NUM_ROWS×D)
stride_gwb, stride_gwd, # partial_grad_weight的块/列步长 (n_row_tiles×D)
NUM_ROWS, D, # 全局维度:总行数、总列数
ROWS_TILE_SIZE: tl.constexpr, # 编译期常量:行分块大小
D_TILE_SIZE: tl.constexpr, # 编译期常量:列分块大小
):
# 1. 获取当前程序(分块)的行索引
row_tile_idx = tl.program_id(0)
n_row_tiles = tl.num_programs(0) # 总行分块数
# 2. 定义所有输入/输出的块指针(Block Pointer)
# 2.1 定义∇_{f(x,w)}ℒ的块指针(维度:ROWS_TILE_SIZE×1)
grad_output_block_ptr = tl.make_block_ptr(
grad_output_ptr,
shape=(NUM_ROWS,), strides=(stride_gr,),
offsets=(row_tile_idx * ROWS_TILE_SIZE,),
block_shape=(ROWS_TILE_SIZE,),
order=(0,),
)
# 2.2 定义输入x的块指针(维度:ROWS_TILE_SIZE×D_TILE_SIZE)
x_block_ptr = tl.make_block_ptr(
x_ptr,
shape=(NUM_ROWS, D,), strides=(stride_xr, stride_xd),
offsets=(row_tile_idx * ROWS_TILE_SIZE, 0),
block_shape=(ROWS_TILE_SIZE, D_TILE_SIZE),
order=(1, 0), # 先列后行,适配内存布局提升访存效率
)
# 2.3 定义权重w的块指针(维度:D_TILE_SIZE×1)
weight_block_ptr = tl.make_block_ptr(
weight_ptr,
shape=(D,), strides=(stride_wd,),
offsets=(0,), block_shape=(D_TILE_SIZE,),
order=(0,),
)
# 2.4 定义∇xℒ的输出块指针(维度:ROWS_TILE_SIZE×D_TILE_SIZE)
grad_x_block_ptr = tl.make_block_ptr(
grad_x_ptr,
shape=(NUM_ROWS, D,), strides=(stride_gxr, stride_gxd),
offsets=(row_tile_idx * ROWS_TILE_SIZE, 0),
block_shape=(ROWS_TILE_SIZE, D_TILE_SIZE),
order=(1, 0),
)
# 2.5 定义w的分片梯度块指针(维度:1×D_TILE_SIZE)
partial_grad_weight_block_ptr = tl.make_block_ptr(
partial_grad_weight_ptr,
shape=(n_row_tiles, D,), strides=(stride_gwb, stride_gwd),
offsets=(row_tile_idx, 0),
block_shape=(1, D_TILE_SIZE),
order=(1, 0),
)
# 3. 按列分块遍历,逐块计算梯度
for i in range(tl.cdiv(D, D_TILE_SIZE)): # tl.cdiv:向上取整除法,遍历所有列分块
# 3.1 加载当前分块的∇_{f(x,w)}ℒ(形状:(ROWS_TILE_SIZE,))
grad_output = tl.load(
grad_output_block_ptr,
boundary_check=(0,), # 行维度边界检查
padding_option="zero" # 越界部分填充0
)
# 3.2 计算∇xℒ:w与∇_{f(x,w)}ℒ的外积(公式2)
# 加载当前分块的权重w(形状:(D_TILE_SIZE,))
weight = tl.load(
weight_block_ptr,
boundary_check=(0,), # 列维度边界检查
padding_option="zero"
)
# 外积计算:(ROWS_TILE_SIZE,1) × (1,D_TILE_SIZE) → (ROWS_TILE_SIZE,D_TILE_SIZE)
grad_x_row = grad_output[:, None] * weight[None, :]
# 将∇xℒ写入输出指针
tl.store(grad_x_block_ptr, grad_x_row, boundary_check=(0, 1))
# 3.3 计算w的分片梯度∇wℒ(公式3)
# 加载当前分块的x(形状:(ROWS_TILE_SIZE, D_TILE_SIZE))
row = tl.load(
x_block_ptr,
boundary_check=(0, 1), # 行+列维度边界检查
padding_option="zero"
)
# 按行求和:(ROWS_TILE_SIZE,D_TILE_SIZE) × (ROWS_TILE_SIZE,1) → (1,D_TILE_SIZE)
grad_weight_row = tl.sum(row * grad_output[:, None], axis=0, keep_dims=True)
# 将分片梯度写入输出指针(dim0无越界,仅检查dim1)
tl.store(partial_grad_weight_block_ptr, grad_weight_row, boundary_check=(1,))
# 3.4 移动块指针到下一个列分块
x_block_ptr = x_block_ptr.advance((0, D_TILE_SIZE))
weight_block_ptr = weight_block_ptr.advance((D_TILE_SIZE,))
partial_grad_weight_block_ptr = partial_grad_weight_block_ptr.advance((0, D_TILE_SIZE))
grad_x_block_ptr = grad_x_block_ptr.advance((0, D_TILE_SIZE))
计算梯度 ∇ x \nabla_x ∇x比较简单,我们只需将结果写入输出张量对应的分块即可。但计算 ∇ w \nabla_w ∇w要更复杂一些:每个核函数实例负责处理 x x x的一个行分块,而现在我们需要对 x x x的行进行求和。
在反向传播中,我们不会直接完成这个求和操作,而是假设partial_grad_weight_ptr存储的是一个 n row tiles × H n_{\text{row tiles}} \times H nrow tiles×H的矩阵——其中第一维度仅包含 x x x单个行分块内的归约结果。我们先在当前行分块内完成归约,再将结果写入这个张量。
在核函数外部,我们通过torch.sum对 ∇ w \nabla_w ∇w进行归约,将各个行分块的结果求和,得到最终的梯度 1 ^1 1 (1. Or, of course, we could write our own kernel for that.)。
至此,autograd.Function的最后一部分就相对简单了:
class WeightedSumFunc(torch.autograd.Function):
@staticmethod
def forward(ctx, x, weight):
# define earlier
@staticmethod
def backward(ctx, grad_out):
# 恢复正向传播保存的张量
x, weight = ctx.saved_tensors
# 恢复分块大小(行/列分块可不同)
ROWS_TILE_SIZE, D_TILE_SIZE = ctx.ROWS_TILE_SIZE, ctx.D_TILE_SIZE
# 获取输入张量维度
n_rows, D = x.shape
# 策略:先让每个线程块写入分片梯度缓冲区,再归约得到最终梯度
# 初始化w的分片梯度缓冲区(n_row_tiles × D)
partial_grad_weight = torch.empty(
(triton.cdiv(n_rows, ROWS_TILE_SIZE), D),
device=x.device,
dtype=x.dtype
)
# 初始化x的梯度张量(与x形状、设备、 dtype一致)
grad_x = torch.empty_like(x)
# 调用Triton反向传播核函数
weighted_sum_backward[(triton.cdiv(n_rows, ROWS_TILE_SIZE),)](
# 输入张量
x, weight,
grad_out,
# 输出梯度张量
grad_x, partial_grad_weight,
# 步长参数(x的行/列步长)
x.stride(0), x.stride(1),
# weight的步长
weight.stride(0),
# grad_out的步长
grad_out.stride(0),
# grad_x的行/列步长
grad_x.stride(0), grad_x.stride(1),
# partial_grad_weight的行/列步长
partial_grad_weight.stride(0), partial_grad_weight.stride(1),
# 全局维度参数
NUM_ROWS=n_rows, D=D,
# 编译期分块大小常量
ROWS_TILE_SIZE=ROWS_TILE_SIZE, D_TILE_SIZE=D_TILE_SIZE,
)
# 归约分片梯度:对所有行分块的结果求和,得到最终∇w
grad_weight = partial_grad_weight.sum(axis=0)
# 返回梯度(与forward输入参数一一对应)
return grad_x, grad_weight
最后,我们可以得到一个用法与torch.nn.functional中实现的函数类似的方法:
f_weightedsum = WeightedSumFunc.apply
现在,对两个PyTorch张量x和w调用f_weightedsum,会得到如下形式的张量:
tensor([ 90.8563, -93.6815, -80.8884, ..., 103.4840, -21.4634, -24.0192],
device='cuda:0', grad_fn=<WeightedSumFuncBackward>)
注意张量附带的grad_fn——这表明当该张量出现在计算图中时,PyTorch知道在反向传播阶段要调用什么函数。至此,我们就完成了加权求和操作的Triton实现。
1.3.2 FlashAttention-2 前向传播
你需要将 PyTorch 注意力机制实现替换为基于 Triton 的高效实现,该实现遵循 FlashAttention-2 [Dao, 2023]。FlashAttention-2 采用分块(tiling)方式计算前向传播,通过优化内存访问模式,避免在全局内存中存储完整的注意力矩阵。
在开始本节内容前,强烈建议至少阅读原始 FlashAttention 论文 [Dao et al., 2022],该论文将帮助你理解 FlashAttention 实现高效注意力机制的核心技术:跨分块在线计算 softmax(这一技术由 [Milakov and Gimelshein, 2018] 提出)。此外,建议参考 He [2022],以深入了解 GPU 实际执行 PyTorch 代码的底层逻辑。
Vanilla 注意力机制的低效性
回顾注意力机制的前向传播过程(暂不考虑掩码),其数学表达如下:
S = Q K ⊤ / d (4) S = Q K^{\top} / \sqrt{d} \tag{4} S=QK⊤/d(4)
P i j = softmax j ( S ) i j (5) P_{ij} = \text{softmax}_j(S)_{ij} \tag{5} Pij=softmaxj(S)ij(5)
O = P V (6) O = P V \tag{6} O=PV(6)
标准反向传播过程为:
d V = P ⊤ d O (7) dV = P^{\top} dO \tag{7} dV=P⊤dO(7)
d P = d O V ⊤ (8) dP = dO V^{\top} \tag{8} dP=dOV⊤(8)
d S i = d softmax ( d P i ) = ( diag ( P i ) − P i P i ⊤ ) d P i (9) dS_i = d\text{softmax}(dP_i) = \left(\text{diag}(P_i) - P_i P_i^{\top}\right) dP_i \tag{9} dSi=dsoftmax(dPi)=(diag(Pi)−PiPi⊤)dPi(9)
d Q = d S K / d (10) dQ = dS K / \sqrt{d} \tag{10} dQ=dSK/d(10)
d K = d S ⊤ Q / d (11) dK = dS^{\top} Q / \sqrt{d} \tag{11} dK=dS⊤Q/d(11)
可以看出,反向传播依赖前向传播过程中产生的多个超大维度激活值。例如,公式 (7) 中计算 d V dV dV 需用到注意力分数矩阵 P P P,其形状为(batch_size, n_heads, seq_len, seq_len)—— 该激活矩阵的尺寸与序列长度成平方关系,这也解释了为何在长序列场景下基准测试注意力机制时会出现内存问题。在 vanilla 注意力机制的前向和反向传播过程中,需要在片上静态随机存取存储器(SRAM)和 GPU 高带宽存储器(HBM)之间频繁传输 P P P 及其他大型激活值,产生极高的内存 IO 开销。标准实现中存在多次此类传输:例如,标准反向传播实现会在计算 (7) 和 (9) 时两次从 HBM 读取 P P P。
FlashAttention 的核心目标是避免在 HBM 中读写完整的注意力矩阵,从而降低 IO 开销和峰值内存占用。这一目标通过三种技术实现:分块计算(tiling)、重计算(recomputation)和算子融合(operator fusion)。
分块计算(Tiling)
为避免在 HBM 中读写注意力矩阵,FlashAttention 在不访问完整输入的情况下完成 softmax 归约运算。具体而言,通过将输入数据分割为多个分块(tile),并对输入分块进行多轮遍历,逐步完成 softmax 归约。
重计算(Recomputation)
不再将形状为(batch_size, n_heads, seq_len, seq_len)的大型中间注意力矩阵存储在 HBM 中。取而代之的是,在 HBM 中保存特定的“激活检查点”(activation checkpoints),并在反向传播过程中重计算前向传播的部分步骤,以获取计算梯度所需的其他激活值。FlashAttention-2 还会存储注意力分数的对数求和指数(logsumexp) L L L,用于简化反向传播计算。 L L L 的表达式为:
L i = log ( ∑ j exp ( S i j ) ) L_i = \log \left( \sum_j \exp(S_{ij}) \right) Li=log(j∑exp(Sij))
在最终的核函数中,我们会以在线方式计算 L L L,但最终结果与标准计算方式一致。通过结合分块计算和重计算,内存 IO 开销和峰值内存占用不再依赖于 sequence_length 2 \text{sequence\_length}^2 sequence_length2,因此能够处理更长的序列。
算子融合(Operator Fusion)
最后,通过在单个核函数中执行所有运算(即算子融合或核融合),避免对注意力矩阵及其他中间激活值的重复内存 IO。我们将编写一个单独的 Triton 核函数用于前向传播,该函数会执行注意力机制的所有相关运算,同时最大限度减少 HBM 与 SRAM 之间的数据传输。重计算技术在一定程度上为算子融合提供了支持,因为无需将每个中间激活值存储到 HBM 中,从而避免了相应的内存 IO 开销。
如需深入理解这些技术的原理,可参考 FlashAttention 相关论文 [Dao et al., 2022, Dao, 2023]。
基于重计算的反向传播
借助 L L L,我们可以通过适当的重计算高效完成反向传播。在启动反向传播前,先在全局内存中预计算 D = rowsum ( O ∘ d O ) D = \text{rowsum}(O \circ dO) D=rowsum(O∘dO)(其中 ∘ \circ ∘ 表示按元素乘法)。由于 P d P ⊤ = P ( d O V ⊤ ) ⊤ = ( P V ) d O ⊤ = O d O ⊤ P dP^{\top} = P (dO V^{\top})^{\top} = (P V) dO^{\top} = O dO^{\top} PdP⊤=P(dOV⊤)⊤=(PV)dO⊤=OdO⊤(且对于任意矩阵 A A A 和 B B B, rowsum ( A ∘ B ) = diag ( A B ⊤ ) \text{rowsum}(A \circ B) = \text{diag}(A B^{\top}) rowsum(A∘B)=diag(AB⊤)),因此 D D D 等价于 rowsum ( P ∘ d P ) \text{rowsum}(P \circ dP) rowsum(P∘dP)。通过 L L L 和 D D D 向量,反向传播可在无需执行 softmax 运算的情况下完成。完整的反向传播计算如下:
S = Q K ⊤ d P i j = exp ( S i j − L i ) d V = P ⊤ d O d P = d O V ⊤ d S i j = P i j ∘ ( d P i j − D i ) d Q = d S K / d d K = d S ⊤ Q / d (13–19) \begin{aligned} \mathbf{S} &= \frac{\mathbf{Q} \mathbf{K}^{\top}}{\sqrt{d}}\\ P_{ij} &= \exp(S_{ij}-L_i)\\ dV &= P^{\top} dO\\ dP &= dO\,V^{\top}\\ dS_{ij} &= P_{ij}\circ(dP_{ij}-D_i)\\ \mathrm{d}\mathbf{Q} &= \mathrm{d}\mathbf{S}\mathbf{K}/\sqrt{d}\\ \mathrm{d}\mathbf{K} &= \mathrm{d}\mathbf{S}^\top \mathbf{Q}/\sqrt{d} \end{aligned} \tag{13–19} SPijdVdPdSijdQdK=dQK⊤=exp(Sij−Li)=P⊤dO=dOV⊤=Pij∘(dPij−Di)=dSK/d=dS⊤Q/d(13–19)
可以看出,上述运算流程无需在前向传播过程中将注意力分数 P P P 存储在 HBM 中——我们通过激活值 Q Q Q、 K K K 和 L L L,在公式 (13) 和 (14) 中重计算得到 P P P。
FlashAttention 前向传播细节
了解 FlashAttention-2 所采用的核心技术后,下面将深入探讨需实现的 FA2 前向传播核函数细节。为避免在 HBM 中读写注意力矩阵,我们采用分块计算策略,即独立计算输出的每个分块。这要求我们能够计算 P P P 的分块,理想情况下可同时对查询(query)和键(key)维度进行分块。
然而,对 S S S 执行 softmax 运算时,需要对 S S S 的整行进行归约以计算 softmax 的分母,这意味着无法直接对 P P P 进行分块计算。FlashAttention-2 通过在线 softmax(online softmax)解决这一问题。下文将使用下标 i i i 表示当前查询分块,上标 ( j ) (j) (j) 表示当前键分块。查询维度的分块大小为 B q B_q Bq,键维度的分块大小为 B k B_k Bk,隐藏维度 d d d 不进行分块。
同时,我们维护两个行级累计值: m i ( j ) ∈ R B q m_i^{(j)} \in \mathbb{R}^{B_q} mi(j)∈RBq 和 l i ( j ) ∈ R B q l_i^{(j)} \in \mathbb{R}^{B_q} li(j)∈RBq。行级值 m i ( j ) m_i^{(j)} mi(j) 是累计最大值,用于保证 softmax 计算的数值稳定性(可回顾作业 1 中 softmax 实现的相关技巧)。每处理一个新的 S S S 行级分块(即 j j j 递增时),都会更新 m i ( j ) m_i^{(j)} mi(j)。利用累计最大值,可计算未归一化的 softmax 值(分子): P ~ i ( j ) = exp ( S i j − m i ( j ) ) \tilde{P}_i^{(j)} = \exp(S_{ij} - m_i^{(j)}) P~i(j)=exp(Sij−mi(j))。 l i ( j ) l_i^{(j)} li(j) 是 softmax 分母的累计代理值,通过未归一化的 softmax 值更新: l i ( j ) = exp ( m i ( j − 1 ) − m i ( j ) ) ⋅ l i ( j − 1 ) + rowsum ( P ~ i ( j ) ) l_i^{(j)} = \exp(m_i^{(j-1)} - m_i^{(j)}) \cdot l_i^{(j-1)} + \text{rowsum}(\tilde{P}_i^{(j)}) li(j)=exp(mi(j−1)−mi(j))⋅li(j−1)+rowsum(P~i(j))。最终输出时,需使用处理完所有键分块后的最终累计值 l i ( T k ) l_i^{(T_k)} li(Tk) 完成归一化。
算法 1 展示了在 GPU 上实现的前向传播流程。
算法 1 FlashAttention-2 前向传播
输入: Q ∈ R N q × d Q \in \mathbb{R}^{N_q \times d} Q∈RNq×d, K , V ∈ R N k × d K, V \in \mathbb{R}^{N_k \times d} K,V∈RNk×d,分块大小 B q , B k B_q, B_k Bq,Bk
- 将 Q Q Q 分割为 T q = ⌈ N q B q ⌉ T_q = \lceil \frac{N_q}{B_q} \rceil Tq=⌈BqNq⌉ 个分块 Q 1 , . . . , Q T q Q_1, ..., Q_{T_q} Q1,...,QTq,每个分块大小为 B q × d B_q \times d Bq×d
- 将 K , V K, V K,V 分割为 T k = ⌈ N k B k ⌉ T_k = \lceil \frac{N_k}{B_k} \rceil Tk=⌈BkNk⌉ 个分块,分别为 K ( 1 ) , . . . , K ( T k ) K^{(1)}, ..., K^{(T_k)} K(1),...,K(Tk) 和 V ( 1 ) , . . . , V ( T k ) V^{(1)}, ..., V^{(T_k)} V(1),...,V(Tk),每个分块大小为 B k × d B_k \times d Bk×d
- 对于 i = 1 , . . . , T q i = 1, ..., T_q i=1,...,Tq:
a. 从全局内存加载 Q i Q_i Qi
b. 初始化 O i ( 0 ) = 0 ∈ R B q × d O_i^{(0)} = 0 \in \mathbb{R}^{B_q \times d} Oi(0)=0∈RBq×d, l i ( 0 ) = 0 ∈ R B q l_i^{(0)} = 0 \in \mathbb{R}^{B_q} li(0)=0∈RBq, m i ( 0 ) = − ∞ ∈ R B q m_i^{(0)} = -\infty \in \mathbb{R}^{B_q} mi(0)=−∞∈RBq
c. 对于 j = 1 , . . . , T k j = 1, ..., T_k j=1,...,Tk:
i. 从全局内存加载 K ( j ) , V ( j ) K^{(j)}, V^{(j)} K(j),V(j)
ii. 计算 softmax 前注意力分数分块: S i ( j ) = Q i ( K ( j ) ) ⊤ d ∈ R B q × B k S_i^{(j)} = \frac{Q_i (K^{(j)})^\top}{\sqrt{d}} \in \mathbb{R}^{B_q \times B_k} Si(j)=dQi(K(j))⊤∈RBq×Bk
iii. 计算累计最大值: m i ( j ) = max ( m i ( j − 1 ) , rowmax ( S i ( j ) ) ) ∈ R B q m_i^{(j)} = \max(m_i^{(j-1)}, \text{rowmax}(S_i^{(j)})) \in \mathbb{R}^{B_q} mi(j)=max(mi(j−1),rowmax(Si(j)))∈RBq
iv. 计算未归一化 softmax: P ~ i ( j ) = exp ( S i ( j ) − m i ( j ) ) ∈ R B q × B k \tilde{P}_i^{(j)} = \exp(S_i^{(j)} - m_i^{(j)}) \in \mathbb{R}^{B_q \times B_k} P~i(j)=exp(Si(j)−mi(j))∈RBq×Bk
v. 更新累计分母代理值: l i ( j ) = exp ( m i ( j − 1 ) − m i ( j ) ) ⋅ l i ( j − 1 ) + rowsum ( P ~ i ( j ) ) ∈ R B q l_i^{(j)} = \exp(m_i^{(j-1)} - m_i^{(j)}) \cdot l_i^{(j-1)} + \text{rowsum}(\tilde{P}_i^{(j)}) \in \mathbb{R}^{B_q} li(j)=exp(mi(j−1)−mi(j))⋅li(j−1)+rowsum(P~i(j))∈RBq
vi. 更新输出分块: O i ( j ) = diag ( exp ( m i ( j − 1 ) − m i ( j ) ) ) ⋅ O i ( j − 1 ) + P ~ i ( j ) V ( j ) O_i^{(j)} = \text{diag}(\exp(m_i^{(j-1)} - m_i^{(j)})) \cdot O_i^{(j-1)} + \tilde{P}_i^{(j)} V^{(j)} Oi(j)=diag(exp(mi(j−1)−mi(j)))⋅Oi(j−1)+P~i(j)V(j)
d. 归一化输出分块: O i = diag ( ( l i ( T k ) ) − 1 ) ⋅ O i ( T k ) O_i = \text{diag}((l_i^{(T_k)})^{-1}) \cdot O_i^{(T_k)} Oi=diag((li(Tk))−1)⋅Oi(Tk)
e. 计算 logsumexp: L i = m i ( T k ) + log ( l i ( T k ) ) L_i = m_i^{(T_k)} + \log(l_i^{(T_k)}) Li=mi(Tk)+log(li(Tk)) - 将 O i O_i Oi 写入全局内存,作为输出 O O O 的第 i i i 个分块
- 将 L i L_i Li 写入全局内存,作为 L L L 的第 i i i 个分块
输出:输出矩阵 O O O 和 logsumexp 矩阵 L L L
在使用 Triton 实现前向传播前,先总结以下编写 Triton 核函数的通用技巧:
Triton 实用技巧
- 可使用
tl.device_print在 Triton 中添加打印语句进行调试:https://triton-lang.org/main/python-api/generated/triton.language.device_print.html。可通过设置环境变量TRITON_INTERPRET=1在 CPU 上运行 Triton 解释器,但该功能可能存在 Bug。 - 定义块指针(block pointer)时,需确保偏移量正确,且块偏移量需乘以对应的分块大小。
- 线程块的启动网格(launch grid)在
torch.autograd.Function子类的方法中设置,如加权和示例所示:kernel_fn[(launch_grid_d1, launch_grid_d2, ...)](...arguments...) - 使用
tl.dot执行矩阵乘法。 - 通过
*_block_ptr = *_block_ptr.advance(...)推进块指针。
问题(flash_forward):15 分
(a) 基于纯 PyTorch 实现 FlashAttention-2 前向传播的 autograd.Function
实现一个纯 PyTorch(不含 Triton)的 autograd.Function,用于实现 FlashAttention-2 前向传播。该实现会比重常规 PyTorch 实现慢,但可用于调试后续的 Triton 核函数。
实现需接收输入 Q Q Q、 K K K、 V V V 以及标志位 is_causal,输出 O O O 和 logsumexp 值 L L L。本题可忽略 is_causal 标志位。autograd.Function 的 forward 方法需保存 L L L、 Q Q Q、 K K K、 V V V 供反向传播使用,并返回 O O O。注意,autograd.Function 的 forward 方法必须以 context 作为第一个参数。所有 autograd.Function 子类都需实现 backward 方法,但本题中可仅抛出 NotImplementedError。如需验证结果,可在 PyTorch 中实现公式 (4)-(6) 和 (12),并与你的实现结果进行对比。
接口定义如下:
def forward(ctx, Q, K, V, is_causal=False):
# 实现逻辑
pass
自行确定分块大小,但需保证分块尺寸至少为 16×16。测试用例的维度均为 2 的整数次幂且不小于 16,因此无需处理越界访问问题。
交付物:实现 FlashAttention-2 前向传播的 torch.autograd.Function 子类。实现 [adapters.get_flashattention_autograd_function_pytorch],并运行测试命令 uv run pytest -k test_flash_forward_pass_pytorch,确保实现通过测试。
根据题目要求,不考虑head_dim。首先安装环境:pip install -e .
import torch
class FlashAttention2(torch.autograd.Function):
@staticmethod
def forward(ctx, query, key, value, is_causal=False):
"""
query: (B, Q, D)
key: (B, K, D)
value: (B, K, D)
"""
batch_size, seq_len, d = query.shape
K = key.shape[1]
softmax_scale = 1 / (d ** 0.5)
O = torch.zeros((batch_size, seq_len, d), device=query.device)
L = torch.empty((batch_size, seq_len), device=query.device, dtype=query.dtype)
Bq, Bk = 16, 16
for qs in range(0, seq_len, Bq):
qe = min(qs + Bq, seq_len)
q = query[:, qs:qe, :]
o_i = torch.zeros((batch_size, qe - qs, value.shape[-1]), device=query.device)
m_i = torch.full((batch_size, qe - qs), -float("inf"), device=query.device)
l_i = torch.zeros((batch_size, qe - qs), device=query.device)
for ks in range(0, K, Bk):
ke = min(ks + Bk, K)
k = key[:, ks:ke, :]
v = value[:, ks:ke, :]
scores = torch.matmul(q, k.transpose(-2, -1)) * softmax_scale
if is_causal:
q_idx = torch.arange(qs, qe, device=query.device)[:, None]
k_idx = torch.arange(ks, ke, device=query.device)[None, :]
scores = scores.masked_fill(q_idx < k_idx, -float("inf"))
m_new = torch.maximum(m_i, scores.max(dim=-1).values)
p = torch.exp(scores - m_new.unsqueeze(-1))
l_new = torch.exp(m_i - m_new) * l_i + p.sum(dim=-1)
o_new = torch.exp(m_i - m_new).unsqueeze(-1) * o_i + torch.matmul(p, v)
m_i = m_new
l_i = l_new
o_i = o_new
O[:, qs:qe, :] = o_i / l_i.unsqueeze(-1)
L[:, qs:qe] = m_i + torch.log(l_i)
ctx.save_for_backward(L)
ctx.is_causal = is_causal
return O

(b) 基于 Triton 核函数实现 FlashAttention-2 前向传播
根据算法 1,编写用于 FlashAttention-2 前向传播的 Triton 核函数。然后,编写另一个 torch.autograd.Function 子类,在前向传播中调用该(融合)核函数,而非通过 PyTorch 计算结果。以下是针对本题的专项技巧:
- 调试时,建议将 Triton 中每个操作的结果与 (a) 部分实现的分块式 PyTorch 结果进行对比。
- 启动网格应设置为 ( T q , batch_size ) (T_q, \text{batch\_size}) (Tq,batch_size),即每个 Triton 程序实例仅加载单个批次索引的数据,且仅读写 Q Q Q、 O O O 和 L L L 的单个查询分块。
- 核函数应仅包含一个循环,用于遍历所有键分块 1 ≤ j ≤ T k 1 \leq j \leq T_k 1≤j≤Tk。
- 在循环末尾推进块指针。
- 使用以下函数声明(通过提供的块指针,可推断其他指针的配置):
其中,@triton.jit def flash_fwd_kernel( Q_ptr, K_ptr, V_ptr, O_ptr, L_ptr, stride_qb, stride_qq, stride_qd, stride_kb, stride_kk, stride_kd, stride_vb, stride_vk, stride_vd, stride_ob, stride_oq, stride_od, stride_lb, stride_lq, N_QUERIES, N_KEYS, scale, D: tl.constexpr, Q_TILE_SIZE: tl.constexpr, K_TILE_SIZE: tl.constexpr, ): # 程序索引 query_tile_index = tl.program_id(0) batch_index = tl.program_id(1) # 为每个指针添加批次索引对应的偏移量(批次索引 × 每个张量的批次步长) Q_block_ptr = tl.make_block_ptr( Q_ptr + batch_index * stride_qb, shape=(N_QUERIES, D), strides=(stride_qq, stride_qd), offsets=(query_tile_index * Q_TILE_SIZE, 0), block_shape=(Q_TILE_SIZE, D), order=(1, 0), )scale为 1 d \frac{1}{\sqrt{d}} d1,Q_TILE_SIZE和K_TILE_SIZE分别对应 B q B_q Bq 和 B k B_k Bk,后续可对其进行调优。
以下指南可帮助避免精度问题:
- 片上缓冲区( O i , l , m O_i, l, m Oi,l,m)应使用
tl.float32数据类型。如果向输出缓冲区累加结果,需使用acc参数(如acc = tl.dot(..., acc=acc))。 - 在将 P ~ i ( j ) \tilde{P}_i^{(j)} P~i(j) 与 V ( j ) V^{(j)} V(j) 相乘前,需将其转换为 V ( j ) V^{(j)} V(j) 的数据类型;将 O i O_i Oi 写入全局内存前,需转换为相应的数据类型。通过
tensor.to进行类型转换,可通过tensor.dtype获取张量的数据类型,通过*_block_ptr.type.element_ty获取块指针/指针的数据类型。
交付物:通过 Triton 核函数实现 FlashAttention-2 前向传播的 torch.autograd.Function 子类。实现 [adapters.get_flash_autograd_function_triton],并运行测试命令 uv run pytest -k test_flash_forward_pass_triton,确保实现通过测试。
我按照视频https://www.bilibili.com/video/BV1t2UxY7Ep9/ 照着敲了一遍代码,视频中考虑了含num_head的情况。因此只要将num_head对应的部分删掉就可以了。
© 为 autograd.Function 实现添加因果掩码标志位
在 autograd.Function 实现的最后一个参数位置添加布尔类型的因果掩码标志位 is_causal。当该标志位设为 True 时,通过索引比较实现因果掩码。Triton 核函数需添加对应的参数 is_causal: tl.constexpr(该类型注解为必填项)。在 Triton 中,构造查询和键的索引向量,通过比较生成大小为 B q × B k B_q \times B_k Bq×Bk 的方阵掩码。对于被掩码的元素,在注意力分数矩阵 S i ( j ) S_i^{(j)} Si(j) 的对应位置添加常量 -1e6。确保通过 ctx.is_causal = is_causal 保存掩码标志位,供反向传播使用。
交付物:为基于 Triton 核函数的 FlashAttention-2 前向传播 torch.autograd.Function 子类添加因果掩码标志位。该标志位应为可选参数,默认值为 False,以确保之前的测试用例仍能通过。
基于重计算的反向传播实现
注意,与公式 (7)-(11) 所示的标准反向传播不同,公式 (13)-(19) 中的反向传播通过重计算避免了 softmax 运算。这意味着反向传播可通过简单核函数实现,无需在线技巧。因此,本部分可通过对常规 PyTorch 代码调用 torch.compile 来实现反向传播。
问题(flash_backward):5分
使用 PyTorch(非 Triton)和 torch.compile 为 FlashAttention-2 的 autograd.Function 实现反向传播。实现需接收 Q、K、V、O、dO 和 L 张量作为输入,返回 dQ、dK 和 dV。注意需计算并使用 D 向量,可参考公式 13 至 19 的计算逻辑。
- 交付要求:运行
uv run pytest -k test_flash_backward测试实现正确性。
问题(flash_benchmarking):5分
(a) 使用 triton.testing.do_bench 编写基准测试脚本,对比基于 Triton 实现的 FlashAttention-2(部分实现)与 PyTorch 常规注意力机制(非 FlashAttention)的性能。
- 具体要求:生成包含正向传播、反向传播及端到端(正向+反向)传播延迟的对比表格,涵盖 Triton 实现与 PyTorch 实现。基准测试前需随机生成所需输入,在单个 H100 GPU 上运行,固定批量大小为 1 并启用因果掩码。测试参数组合需覆盖:
- 序列长度:2 的幂次,从 128 到 65536
- 嵌入维度:2 的幂次,从 16 到 128
- 精度:
torch.bfloat16和torch.float32
- 注意:需根据输入大小调整分块大小(tile sizes)。
- 交付要求:提交对比表格,包含上述设置下两种实现的正向、反向及端到端传播延迟数据。
1.3.3 FlashAttention-2 排行榜
本次作业的排行榜将评估 FlashAttention-2 实现的速度(含正向和反向传播)。请尽可能优化实现性能,可采用任意技巧,但需遵守以下限制:
- 不得修改函数的输入/输出格式
- 必须使用 Triton(不支持 CUDA)
- 测试条件:BF16 精度、因果掩码,需通过与常规实现相同的正确性测试
- 实现要求:必须为原创,不得使用现有开源实现
- 计时参数:在 H100 GPU 上测试,批量大小 1,查询/键/值序列长度 16384,
d_model=1024,16 个注意力头 - 验证说明:排行榜前 5-10 名提交将进行正确性和性能验证
用于计时的测试代码如下:
def test_timing_flash_forward_backward():
n_heads = 16
d_head = 64
sequence_length = 16384
q, k, v = torch.randn(
3, n_heads, sequence_length, d_head, device='cuda', dtype=torch.bfloat16, requires_grad=True
)
flash = torch.compile(FlashAttention2.apply)
def flash_forward_backward():
o = flash(q, k, v, True)
loss = o.sum()
loss.backward()
results = triton.testing.do_bench(flash_forward_backward, rep=10000, warmup=1000)
print(results)
-
测试提示:可缩短重复次数(rep)和预热时间(warmup)以加快本地测试速度。
-
优化思路:
- 调整内核分块大小(使用 Triton 自动调优!)
- 优化其他 Triton 配置参数
- 用 Triton 实现反向传播(而非仅依赖
torch.compile,见 1.3.4 节) - 反向传播分两次遍历输入:一次计算 dQ,一次计算 dK 和 dV,避免线程块间的原子操作或同步
- 因果掩码场景下提前终止无效程序实例,跳过全零分块
- 分离非掩码分块与对角线分块:前者无需索引比较,后者仅需一次比较
- 利用 H100 的 TMA(张量内存加速器)功能,可参考相关教程
-
提交方式:将最优计时结果提交至排行榜:
github.com/stanford-cs336/assignment2-systems-leaderboard
1.3.4 可选:Triton 反向传播实现
若希望进一步练习 Triton 或提交更优性能的排行榜结果,可参考以下基于 Triton 的分块式 FlashAttention-2 反向传播算法(算法 2)。核心技巧是分两次计算 P 矩阵:一次用于 dQ 的反向传播,另一次用于 dK 和 dV 的反向传播,从而避免线程块间的同步操作。
算法 2 分块式 FlashAttention-2 反向传播

2 分布式数据并行训练
在本作业的第二部分,我们将探索利用多块GPU训练语言模型的方法,重点关注数据并行性。首先会介绍PyTorch中的分布式通信基础,随后研究分布式数据并行训练的朴素实现,并通过实现和基准测试多种优化方案来提升通信效率。
2.1 PyTorch中的单节点分布式通信
我们先从PyTorch中的一个简单分布式应用入手,目标是生成四个随机整数张量并计算它们的总和。
在下面的分布式场景中,我们将启动四个工作进程,每个进程生成一个随机整数张量。为了对所有工作进程中的张量求和,我们会调用全归约(all-reduce) 集合通信操作——该操作会用全归约结果(即总和)替换每个进程上的原始数据张量。
以下是相关代码:
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def setup(rank, world_size):
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "29500"
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def distributed_demo(rank, world_size):
setup(rank, world_size)
data = torch.randint(0, 10, (3,))
print(f"rank {rank} 数据(全归约前): {data}")
dist.all_reduce(data, async_op=False)
print(f"rank {rank} 数据(全归约后): {data}")
if __name__ == "__main__":
world_size = 4
mp.spawn(fn=distributed_demo, args=(world_size, ), nprocs=world_size, join=True)
运行上述脚本后,输出结果如下。正如预期,每个工作进程最初持有不同的数据张量;经过全归约操作(对所有工作进程的张量求和)后,每个工作进程上的数据会被原地修改为全归约结果²。
$ uv run python distributed_hello_world.py
rank 3 数据(全归约前): tensor([3, 7, 8])
rank 0 数据(全归约前): tensor([4, 4, 7])
rank 2 数据(全归约前): tensor([6, 0, 7])
rank 1 数据(全归约前): tensor([9, 5, 3])
rank 1 数据(全归约后): tensor([22, 16, 25])
rank 0 数据(全归约后): tensor([22, 16, 25])
rank 3 数据(全归约后): tensor([22, 16, 25])
rank 2 数据(全归约后): tensor([22, 16, 25])
² 若多次运行该脚本,会发现打印输出的顺序是非确定性的。由于应用运行在分布式环境中,我们无法控制命令执行的精确顺序——唯一能保证的是,全归约操作完成后,所有独立进程会持有完全相同(按位一致)的结果张量。
我们再仔细分析上述脚本:
mp.spawn函数会启动nprocs个进程,每个进程都会执行传入的fn函数并传入指定参数。- 此外,
fn函数的调用格式为fn(rank, *args),其中rank是工作进程的索引(取值范围为0到nprocs-1)。因此,我们的distributed_demo函数必须将该整数rank作为第一个位置参数。 - 我们还传入了
world_size,表示工作进程的总数。
每个工作进程都属于一个进程组(process group),通过 dist.init_process_group 初始化。进程组是指多个工作进程的集合,它们通过一个共享的主节点(master)进行协调和通信。主节点由其IP地址和端口定义,且主节点运行的是 rank=0 的进程。全归约等集合通信操作会作用于进程组中的所有进程。
在本示例中,我们使用 “gloo” 后端初始化进程组,但PyTorch还支持其他后端:
- “nccl” 后端:基于NVIDIA的NCCL集合通信库,对CUDA张量的性能通常更优,但仅支持配备GPU的机器。
- “gloo” 后端:可运行在仅含CPU的机器上。
实用经验法则:分布式GPU训练使用NCCL后端,分布式CPU训练和/或本地开发使用Gloo后端。本示例选择Gloo是为了支持在仅含CPU的机器上进行本地执行和开发。
运行多GPU任务时,需确保不同 rank 对应不同的GPU。实现方式有两种:
- 在
setup函数中调用torch.cuda.set_device(rank),使得tensor.to("cuda")会自动将张量移动到指定GPU。 - 显式创建每个
rank对应的设备字符串(例如device = f"cuda:{rank}"),并将其作为数据移动的目标设备(例如tensor.to(f"cuda:{rank}"))。
术语定义
在本作业的后续部分(以及你可能在网上看到的其他资源中),你会遇到PyTorch分布式通信相关的以下术语。尽管本作业聚焦于单节点、多进程分布式训练,但这些术语对理解通用分布式训练也很有帮助(可视化示意见图2):
- 节点(node):网络中的一台机器。
- 工作进程(worker):参与分布式训练的程序实例。在本作业中,每个工作进程对应一个独立进程,因此我们会交替使用“工作进程(worker)”“进程(process)”和“工作进程(worker process)”。但在实际场景中,一个工作进程可能包含多个进程(例如用于加载训练数据),因此这些术语并非始终等价。
- 全局进程数(world size):进程组中工作进程的总数。
- 全局序号(global rank):用于唯一标识进程组中某个工作进程的整数ID(取值范围为
0到world_size-1)。例如,当全局进程数为2时,一个进程的全局序号为0(主进程),另一个为1。 - 本地进程数(local world size):当应用跨多个节点运行时,本地进程数指某一节点上本地运行的工作进程数。例如,若在2个节点上各启动4个工作进程,则全局进程数为8,本地进程数为4。注意:单节点运行时,本地进程数与全局进程数相等。
- 本地序号(local rank):用于唯一标识某台机器上本地工作进程索引的整数ID(取值范围为
0到local_world_size-1)。例如,若在2个节点上各启动4个进程,则每个节点上的工作进程本地序号为0、1、2、3。注意:单节点多进程分布式应用中,进程的本地序号与其全局序号相等。
图2:运行在2个节点上、全局进程数为8的分布式应用示意图。每个工作进程通过全局序号(0-7)和本地序号(0-3)唯一标识。图片来源:lightning.ai/docs/fabric/stable/advanced/distributed_communication.html
2.1.1 分布式应用基准测试的最佳实践
在本部分作业中,你需要通过基准测试分布式应用,以更好地理解通信带来的开销。以下是一些最佳实践:
- 尽可能在同一台机器上运行基准测试,以确保对比的可控性。
- 在对目标操作计时前,先执行几次热身步骤(warm-up steps)——这对NCCL通信调用尤为重要,通常5次热身迭代即可。
- 在GPU上进行基准测试时,调用
torch.cuda.synchronize()等待CUDA操作完成。注意:即使调用async_op=False的通信操作(表示操作在GPU上排队后返回,而非通信实际完成后返回),也需要执行该同步操作³。 - 不同序号(rank)的计时结果可能略有差异,因此通常会汇总所有序号的测量结果以提高估计准确性。你可以使用全收集(all-gather)集合操作(特别是
dist.all_gather对象函数)收集所有序号的结果。 - 通常在本地使用Gloo后端(CPU)调试,然后根据具体问题需求,使用NCCL后端(GPU)进行基准测试。切换后端只需修改
init_process_group调用和张量设备转换逻辑。
³ 更多细节参见:github.com/pytorch/pytorch/issues/68112#issuecomment-965932386
Problem(distributed_communication_single_node):5分
编写脚本,基准测试单节点多进程环境下全归约(all-reduce)操作的运行时间。上述示例代码可作为合理起点。尝试调整以下设置:
- 后端+设备类型:Gloo+CPU、NCCL+GPU。
- 全归约数据大小:float32类型张量,大小分别为1MB、10MB、100MB、1GB。
- 进程数:2、4或6个进程。
资源要求:最多使用6块GPU。每次基准测试运行时间应不超过5分钟。
交付物:对比不同设置的图表和/或表格,附加2-3句话的说明,阐述你的结果以及对各因素相互作用的思考。
实验结果分析
根据提供的基准测试结果,我们可以整理出以下数据表格:
| 进程数 | 内存大小 (MB) | 平均时间 (ms) | 带宽 (Gbps) |
|---|---|---|---|
| 2 | 1 | 0.19 | 88.23 |
| 2 | 10 | 1.48 | 113.34 |
| 2 | 100 | 14.61 | 114.82 |
| 2 | 1024 | 145.71 | 117.91 |
| 4 | 1 | 0.44 | 37.78 |
| 4 | 10 | 3.90 | 43.03 |
| 4 | 100 | 36.35 | 46.16 |
| 4 | 1024 | 367.49 | 46.75 |
| 6 | 1 | 0.51 | 32.71 |
| 6 | 10 | 4.59 | 36.58 |
| 6 | 100 | 42.52 | 39.46 |
| 6 | 1024 | 381.56 | 45.03 |
关键发现
-
带宽随数据量增大而提升:对于相同的进程数,随着数据量从1MB增加到1GB,有效带宽显著提升。这反映了通信启动开销(latency)的影响在数据量较小时更明显。
-
进程数增加导致带宽下降:在相同数据量下,2进程配置始终获得最高带宽,6进程配置带宽最低。例如,对于1GB数据,2进程带宽为117.91 Gbps,而6进程降至45.03 Gbps,降幅达62%。
-
扩展性瓶颈明显:进程数从2增加到6时,小数据量(1MB)的带宽下降了63%,大数据量(1GB)下降了62%,表明通信开销随进程数增加而显著增大。
2.2 Distributed Data Parallel Training的朴素实现
了解了PyTorch分布式应用的基础后,我们来构建一个分布式数据并行(DDP)训练的最小实现。
数据并行性将批次(batch)拆分到多个设备(如GPU)上,支持在单设备无法容纳的大批次尺寸下进行训练。例如,若4块设备各自最大支持批次尺寸为32,则数据并行训练可实现有效批次尺寸为128。
以下是朴素分布式数据并行训练的步骤:
- 初始化时,每个设备都会构建一个(随机初始化的)模型。我们使用广播(broadcast)集合通信操作,将主进程(rank=0)的模型参数发送到所有其他进程。训练开始时,所有设备都持有相同的模型参数和优化器状态(例如Adam优化器中的累积梯度统计信息)。
- 给定一个包含
n个样本的批次,将其分片(sharded),每个设备接收n/d个不重叠的样本(其中d是用于数据并行训练的设备数)。n应能被d整除,因为训练速度会受最慢进程的瓶颈限制。 - 每个设备使用本地的模型参数副本,对其接收的
n/d个样本执行前向传播,并通过反向传播计算梯度。此时,每个设备仅持有基于自身n/d个样本计算的梯度。 - 调用全归约(all-reduce)集合通信操作,在所有设备间对梯度进行平均,使每个设备都持有基于所有
n个样本的平均梯度。 - 每个设备执行优化器步骤,更新本地的模型参数副本——从优化器的角度来看,它只是在优化一个本地模型。由于所有设备都从相同的初始模型和优化器状态开始,且每次迭代都使用相同的平均梯度,因此所有设备上的参数和优化器状态会保持同步。至此,单个训练迭代完成,可重复上述过程。
习题(naive_ddp):5分
交付物:编写脚本,通过在反向传播后对每个参数梯度单独执行全归约,朴素实现分布式数据并行训练。为验证DDP实现的正确性,使用该脚本在随机生成的数据上训练一个小型玩具模型(toy model),并验证其权重与单进程训练的结果一致。
若编写测试时遇到困难,可参考 tests/test_ddp_individual_parameters.py。
习题(naive_ddp_benchmarking):3分
在上述朴素DDP实现中,每个反向传播后都会对所有进程的参数单独执行全归约。为更好地理解数据并行训练的开销,编写脚本对之前实现的语言模型进行基准测试(使用该朴素DDP实现训练)。测量每个训练步骤的总时间,以及梯度通信所占用的时间比例。在单节点环境(1节点×2块GPU)下,针对1.1.2节描述的XL模型尺寸收集测量结果。
交付物:描述你的基准测试环境,以及每种设置下测得的训练迭代时间和梯度通信时间。
2.3 优化最小DDP实现
2.2节中的最小DDP实现存在两个关键限制:
- 对每个参数张量执行独立的all-reduce操作。每次通信调用都会产生开销,因此批量处理通信调用可能有助于减少这种开销。
- 需等待反向传播完全完成后才开始梯度通信。但反向传播是增量计算的——因此,当某个参数的梯度计算完成后,可立即进行通信,无需等待其他参数的梯度计算完成。这使得我们可以将梯度通信与反向传播计算重叠进行,从而降低分布式数据并行训练的开销。
在本部分作业中,我们将逐一解决这些限制,并测量其对训练速度的影响。
2.3.1 减少通信调用次数
与其对每个参数张量发起一次通信调用,不如尝试通过批量全归约来提升性能。具体来说,我们将需要全归约的所有梯度拼接成一个单一张量,然后在所有进程间对该合并后的梯度执行全归约。torch._utils._flatten_dense_tensors 和 torch._utils._unflatten_dense_tensors 函数可能会有所帮助。
习题(minimal_ddp_flat_benchmarking):2分
修改你的最小DDP实现,使其通信一个包含所有参数扁平化梯度的张量。在之前的测试条件下(1节点×2块GPU,1.1.2节描述的XL模型尺寸),将其性能与“对每个参数张量单独执行全归约”的最小DDP实现进行对比。
交付物:记录使用单一批量全归约调用的分布式数据并行训练中,每个训练迭代的时间和梯度通信时间。用1-2句话对比批量通信与单独通信梯度的结果差异。
2.3.2 梯度通信与计算重叠(针对单个参数梯度)
虽然批量通信调用有助于降低大量小型全归约操作的开销,但通信时间仍然会直接增加训练延迟。为解决这一问题,我们可以利用以下观察:反向传播会为每一层增量计算梯度(从损失开始,向输入方向推进)——因此,当某个参数的梯度就绪后,可立即对其执行全归约,通过将反向传播计算与梯度通信重叠,减少分布式数据并行训练的开销。
我们将首先实现并基准测试一个分布式数据并行包装器(wrapper),该包装器在反向传播过程中,当单个参数张量的梯度就绪时,异步对其执行全归约。以下提示可能会有帮助:
- 反向传播钩子(Backward hooks):若要在反向传播中参数的梯度累积完成后自动调用某个函数,可使用
register_post_accumulate_grad_hook函数⁵。
⁵ 更多信息和使用示例参见:pytorch.org/docs/stable/generated/torch.Tensor.register_post_accumulate_grad_hook.html
- 异步通信:PyTorch的所有集合通信操作均支持同步执行(
async_op=False)和异步执行(async_op=True)。同步调用会阻塞程序,直到集合操作在GPU上排队完成——但这并不意味着CUDA操作已执行完毕,因为CUDA操作本身是异步的。尽管如此,后续使用该输出的函数调用仍会按预期执行⁵。相比之下,异步调用会返回一个分布式请求句柄(distributed request handle);也就是说,当函数返回时,集合通信操作不一定已在GPU上排队,更不用说执行完成了。若要等待操作在GPU上排队(确保输出可用于后续操作),可调用返回的通信句柄的handle.wait()方法。
⁵ 高级场景中,若使用多个CUDA流,可能需要在流之间进行显式同步以确保输出可用于后续操作。详见PyTorch官方文档。
例如,以下两个示例分别通过同步调用和异步调用对张量列表中的每个张量执行归约求和(all-reduce)操作:
tensors = [torch.rand(5) for _ in range(10)]
# 同步调用:阻塞直到操作在GPU上排队完成
for tensor in tensors:
dist.all_reduce(tensor, async_op=False)
# 异步调用:每次调用后立即返回,最后统一等待结果
handles = []
for tensor in tensors:
handle = dist.all_reduce(tensor, async_op=True)
handles.append(handle)
# ...
# 可执行其他不依赖归约求和结果的命令
# ...
# 确保所有归约求和调用已排队完成,
# 以便后续依赖其输出的操作可以排队执行
for handle in handles:
handle.wait()
handles.clear()
问题(ddp_overlap_individual_parameters):5分
实现一个Python类以处理分布式数据并行(DDP)训练。该类需包装任意PyTorch nn.Module,并负责训练前的权重广播(确保所有进程组(rank)拥有相同的初始参数)以及梯度平均的通信调用。建议采用以下公共接口:
__init__(self, module: torch.nn.Module):接收一个实例化的PyTorchnn.Module(待并行化),构造一个DDP容器,用于处理跨进程组的梯度同步。forward(self, *inputs, **kwargs):使用提供的位置参数和关键字参数调用被包装模块的forward()方法。finish_gradient_synchronization(self):调用时,等待异步通信操作在GPU上排队完成。
使用该类进行分布式训练时,需将模块传入并包装,然后在执行optimizer.step()前调用finish_gradient_synchronization(),确保依赖梯度的优化器步骤可正常排队执行:
model = ToyModel().to(device)
ddp_model = DDP(model)
for _ in range(train_steps):
x, y = get_batch()
logits = ddp_model(x)
loss = loss_fn(logits, y)
loss.backward()
ddp_model.finish_gradient_synchronization()
optimizer.step()
交付要求
实现一个处理分布式数据并行训练的容器类,该类需实现梯度通信与反向传播计算的重叠执行。为测试你的DDP类,首先实现适配器[adapters.get_ddp_individual_parameters]和[adapters.ddp_individual_parameters_on_after_backward](后者为可选,取决于你的实现是否需要)。然后运行uv run pytest tests/test_ddp_individual_parameters.py执行测试,建议多次运行(如5次)以确保结果稳定通过。
答:
# 习题ddp_overlap_individual_parameters的实现
# copy自https://github.com/heng380/cs336_assignment2
# pytest -k test_ddp_individual_parameters.py
import torch
import torch.distributed as dist
from torch.autograd.profiler import record_function
class DDP(torch.nn.Module):
def __init__(self, module: torch.nn.Module):
super(DDP, self).__init__()
self.module = module
self.handles = []
# initialize all parameters to be the same
for param in self.module.parameters():
dist.broadcast(param.data, src=0)
if param.requires_grad:
param.register_post_accumulate_grad_hook(self.transform_grad)
def transform_grad(self, param):
with torch.no_grad():
param.grad.data /= dist.get_world_size()
with record_function("allreduce_async"):
self.handles.append(dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM, async_op=True))
def finish_gradient_synchronization(self):
for handle in self.handles:
handle.wait()
self.handles.clear()
def forward(self, *inputs, **kwargs):
return self.module.forward(*inputs, **kwargs)

问题(ddp_overlap_individual_parameters_benchmarking):1分
(a)
基准测试你的DDP实现(将反向传播计算与单个参数梯度的通信重叠执行)的性能,并与之前研究的配置(两种最小化DDP实现:要么为每个参数张量执行一次归约求和,要么对所有参数张量拼接后执行一次归约求和)在相同设置下(1个节点、2块GPU、§1.1.2中描述的XL模型规模)进行对比。
交付要求
提供反向传播与单个参数梯度通信重叠执行时的每训练迭代耗时,并用1-2句话对比结果。
(b)
使用Nsight分析器对基准测试代码(1个节点、2块GPU、XL模型规模)进行插桩,对比初始DDP实现与该重叠计算和通信的DDP实现。可视化对比两条轨迹,并提供分析器截图,以证明一种实现实现了计算与通信的重叠,而另一种未实现。
交付要求
2张截图(分别来自初始DDP实现和重叠计算与通信的DDP实现),直观展示反向传播过程中通信是否与计算重叠。
2.3.3 桶化参数梯度的计算与通信重叠
在2.3.2节中,我们实现了反向传播计算与单个参数梯度通信的重叠。但此前已观察到,批量处理通信调用可提升性能——尤其当存在大量参数张量时(深度Transformer模型通常如此)。我们之前的批量处理尝试是一次性发送所有梯度,这需要等待反向传播完全完成。本节将结合两种方案的优势:将参数分组为桶(减少总通信调用次数),并在每个桶的所有组成张量就绪后对该桶执行归约求和(实现计算与通信的重叠)。
问题(ddp_overlap_bucketed):8分
实现一个Python类以处理分布式数据并行训练,通过梯度桶化提升通信效率。该类需包装任意输入的PyTorch nn.Module,并负责训练前的权重广播(确保所有进程组拥有相同的初始参数)以及桶化梯度平均的通信调用。建议采用以下接口:
__init__(self, module: torch.nn.Module, bucket_size_mb: float):接收一个实例化的PyTorchnn.Module(待并行化),构造一个DDP容器,用于处理跨进程组的梯度同步。梯度同步需按桶划分,每个桶最多包含bucket_size_mb大小的参数。forward(self, *inputs, **kwargs):使用提供的位置参数和关键字参数调用被包装模块的forward()方法。finish_gradient_synchronization(self):调用时,等待异步通信操作在GPU上排队完成。
除初始化参数中新增bucket_size_mb外,该公共接口与之前的单参数通信DDP实现一致。建议按model.parameters()的逆序分配参数到桶中,因为反向传播过程中梯度的就绪顺序大致与此相反。
交付要求
实现一个处理分布式数据并行训练的容器类,该类需实现梯度通信与反向传播计算的重叠执行,并通过梯度桶化减少总通信调用次数。为测试实现,需完成[adapters.get_ddp_bucketed]、[adapters.ddp_bucketed_on_after_backward]和[adapters.ddp_bucketed_on_train_batch_start](后两者为可选,取决于你的实现是否需要)。然后运行pytest tests/test_ddp.py执行测试,建议多次运行(如5次)以确保结果稳定通过。
问题(ddp_bucketed_benchmarking):3分
(a)
在与之前实验相同的配置下(1个节点、2块GPU、XL模型规模),基准测试你的桶化DDP实现,其中最大桶大小分别设置为1、10、100、1000 MB。将结果与之前无桶化的实验对比——结果是否符合预期?若不符合,原因是什么?你可能需要使用PyTorch分析器以更好地理解通信调用的排序和/或执行情况。你认为调整哪些实验设置会使结果符合预期?
交付要求
提供不同桶大小下的每训练迭代耗时;用3-4句话说明结果、预期以及可能导致不匹配的原因。
(b)
假设计算一个桶的梯度耗时与通信该梯度桶的耗时相同。推导一个方程,将DDP的通信开销(即反向传播后额外花费的时间)建模为以下变量的函数:模型参数总大小(字节,s)、归约求和算法带宽(w,定义为每个进程组的数据大小除以归约求和完成时间)、每次通信调用的开销(秒,o)以及桶的数量(n_b)。基于该方程,推导使DDP开销最小化的最优桶大小方程。
交付要求
DDP开销建模方程以及最优桶大小方程。
2.4 四维并行
尽管实现更为复杂,但训练过程仍可通过更多维度进行并行化。常用的并行化方法有5种:
- 数据并行(DP):将数据批次拆分到多个设备上,每个设备针对自身批次计算梯度;这些梯度需在设备间进行平均。
- 全分片数据并行(FSDP):将优化器状态、梯度和权重拆分到多个设备上;若仅使用DP和FSDP,每个设备需在执行前向或反向传播前,从其他所有设备收集权重分片。
- 张量并行(TP):在新维度上对激活值进行分片,每个设备针对自身分片计算输出结果;张量并行可选择沿操作的输入或输出维度分片。若权重和激活值沿对应维度分片,张量并行可与FSDP有效结合使用。
- 流水线并行(PP):将模型按层拆分为多个阶段,每个阶段在不同设备上运行。
- 专家并行(EP):在混合专家(MoE)模型中,将专家(expert)分配到不同设备上,每个设备针对自身专家计算输出结果。
通常,我们会将FSDP和TP结合使用,因此可将其视为一个并行化维度。最终形成四维并行:DP、FSDP/TP、PP和EP。本文将聚焦稠密模型(非MoE模型),因此不再进一步讨论EP。
在讨论分布式训练时,我们常将集群描述为设备网格(mesh of devices),网格的维度对应并行化的维度。例如,若有16块GPU,且模型规模远超单块GPU的存储容量,可将网格组织为4×4的GPU阵列——其中第一个维度代表DP,第二个维度代表FSDP与TP的组合。
有关这些方法的工作原理以及通信和内存成本的推导细节,可参考《TPU扩展手册》第5部分(Austin等人,2025)(这对解决以下问题特别有帮助);有关流水线并行的更多细节,可参考《超大规模实践手册》附录(Nouamane Tazi,2025)。该手册的其他部分也包含许多实用信息。
问题(communication_accounting):10分
考虑一个新的模型配置XXL,其中d_model=16384、d_ff=53248、num_blocks=126。由于超大规模模型的计算量主要集中在前馈网络(FFN),我们做如下简化假设:
- 忽略注意力机制、输入嵌入层和输出线性层;
- 每个FFN仅包含两个线性层(忽略激活函数):第一个线性层的输入维度为
d_model、输出维度为d_ff,第二个线性层的输入维度为d_ff、输出维度为d_model; - 模型由
num_blocks个上述双线性层块组成; - 不使用激活检查点(activation checkpointing);
- 激活值和梯度通信采用BF16精度,累积梯度、主权重(master weights)和优化器状态采用FP32精度。
(a)
在单设备上,存储FP32精度的主模型权重、累积梯度和优化器状态需要多少内存?反向传播过程中(采用BF16精度)可节省多少内存?这相当于多少块H100 80GB GPU的内存容量?
交付要求
计算过程及一句话总结。
(b)
假设主权重、优化器状态、梯度以及一半的激活值(实际中为每隔一层)在N_FSDP个设备上分片存储。推导单个设备的内存占用表达式。N_FSDP需取何值才能使总内存占用小于1块v5p TPU(单设备95GB)?
交付要求
计算过程及一句话总结。
©
仅考虑前向传播。使用《TPU扩展手册》中给出的v5p TPU参数:跨芯片互连(ICI)带宽W_ici=2×9×10¹⁰,浮点运算速度(FLOPS/s)C=4.6×10¹⁴。采用该手册的符号表示,设M_X=2、M_Y=1(3D网格),其中X=16(FSDP维度)、Y=4(TP维度)。该模型在什么单设备批次大小时处于计算受限状态?此时的总批次大小是多少?
交付要求
计算过程及一句话总结。
(d)
在实际应用中,我们希望总批次大小尽可能小,同时确保计算资源得到有效利用(即避免处于通信受限状态)。除上述方法外,还可采用哪些技巧在减小模型批次大小的同时保持高吞吐量?
交付要求
一段式回答,需通过参考文献和/或方程支持你的观点。
3 优化器状态分片
分布式数据并行训练在概念上简单且通常非常有效,但要求每个进程组(rank)持有模型参数和优化器状态的独立副本。这种冗余会带来显著的内存开销。例如,AdamW优化器为每个参数维护两个浮点数,这意味着它消耗的内存是模型权重的两倍。Rajbhandari等人[2020]提出了多种在数据并行训练中减少这种冗余的方法,通过在进程组之间划分(1)优化器状态、(2)梯度和(3)参数,并在必要时在工作节点之间进行通信。
在本作业的这一部分,我们将通过实现优化器状态分片的简化版本来降低每个进程组的内存消耗。每个进程组的优化器实例不会保留所有参数的优化器状态,而仅处理参数的一个子集(约为1/进程组总数)。当每个进程组的优化器执行优化步骤(optimizer step)时,它仅更新其分片中的模型参数子集。之后,每个进程组会将更新后的参数广播到其他进程组,以确保每个优化步骤后模型参数保持同步。
问题(optimizer_state_sharding):15分
实现一个Python类来处理优化器状态分片。该类应包装任意输入的PyTorch优化器(torch.optim.Optimizer),并负责在每个优化步骤后同步更新后的参数。建议采用以下公共接口:
def __init__(self, params, optimizer_cls: Type[Optimizer], **kwargs: Any):初始化分片状态优化器。params是待优化的参数集合(或参数组,若用户希望为模型不同部分使用不同超参数,如学习率);这些参数将在所有进程组之间分片。optimizer_cls参数指定要包装的优化器类型(例如optim.AdamW)。最后,所有剩余的关键字参数将传递给optimizer_cls的构造函数。确保在此方法中调用torch.optim.Optimizer父类的构造函数。def step(self, closure, **kwargs):使用提供的闭包(closure)和关键字参数调用包装后的优化器的step()方法。参数更新后,与其他进程组同步。def add_param_group(self, param_group: dict[str, Any]):该方法应向分片优化器添加一个参数组。父类构造函数在分片优化器创建期间会调用此方法,训练过程中也可能调用(例如,为模型中逐渐解冻的层添加参数组)。因此,该方法需处理在进程组之间分配模型参数的逻辑。
交付要求
实现一个处理优化器状态分片的容器类。为测试你的分片优化器,首先实现适配器 [adapters.get_sharded_optimizer]。然后运行 uv run pytest tests/test_sharded_optimizer.py 执行测试。建议多次(例如5次)运行测试,确保结果稳定通过。
完成优化器状态分片的实现后,我们将分析其对训练过程中峰值内存使用量和运行时开销的影响。
问题(optimizer_state_sharding_accounting):5分
(a) 编写一个脚本,分别分析启用和未启用优化器状态分片时训练语言模型的峰值内存使用情况。使用标准配置(1个节点、2块GPU、XL模型规模),报告模型初始化后、优化器步骤执行前以及优化器步骤执行后的峰值内存使用量。结果是否符合你的预期?分析两种设置下的内存使用构成(例如,参数占用多少内存、优化器状态占用多少内存等)。
交付要求
用2-3句话回应,包含峰值内存使用结果,并说明内存在模型和优化器各组件之间的分配情况。
(b) 我们实现的优化器状态分片对训练速度有何影响?使用标准配置(1个节点、2块GPU、XL模型规模),测量启用和未启用优化器状态分片时每次迭代的耗时。
交付要求
用2-3句话回应,包含你的计时结果。
© 我们的优化器状态分片方法与ZeRO第一阶段(Rajbhandari等人[2020]中称为ZeRODP)有何不同?
交付要求
用2-3句话总结差异,尤其关注与内存占用和通信量相关的差异。
结语
恭喜你完成本作业!希望你觉得这次任务既有趣又有收获,并通过优化单GPU速度和/或利用多GPU,学到了一些加速语言模型训练的方法。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 29
29 1
1- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)