机器人视觉-语言-动作模型:面向实际应用的综述 (下)
25年9月来自东京大学、牛津大学和德州 Austin 的论文“Vision-Language-Action Models for Robotics: A Review Towards Real-World Applications”。随着越来越多的研究致力于将大语言模型 (LLM) 和视觉-语言模型 (VLM) 的进展应用于机器人技术,视觉-语言-动作 (VLA) 模型最近获得广泛关注。通过大规模
25年9月来自东京大学、牛津大学和德州 Austin 的论文“Vision-Language-Action Models for Robotics: A Review Towards Real-World Applications”。
随着越来越多的研究致力于将大语言模型 (LLM) 和视觉-语言模型 (VLM) 的进展应用于机器人技术,视觉-语言-动作 (VLA) 模型最近获得广泛关注。通过大规模统一视觉、语言和动作数据(传统上这些数据是分开研究的),VLA 模型旨在学习能够泛化到不同任务、目标、具身和环境中的策略。这种泛化能力有望使机器人能够在极少甚至无需额外任务特定数据的情况下解决新下游任务,从而促进更灵活、更具可扩展性的实际部署。与以往仅关注动作表征或高级模型架构的研究不同,本研究提供全面的全栈综述,整合 VLA 系统的软件和硬件组件。具体而言,本文对 VLA 进行系统性综述,涵盖其策略和架构转型、架构和构建模块、特定模态的处理技术以及学习范式。此外,为了支持 VLA 在实际机器人应用中的部署,还回顾常用的机器人平台、数据收集策略、公开数据集、数据增强方法和评估基准。通过这项全面的综述,本文旨在为机器人社区提供将 VLA 应用于实际机器人系统的实用指导。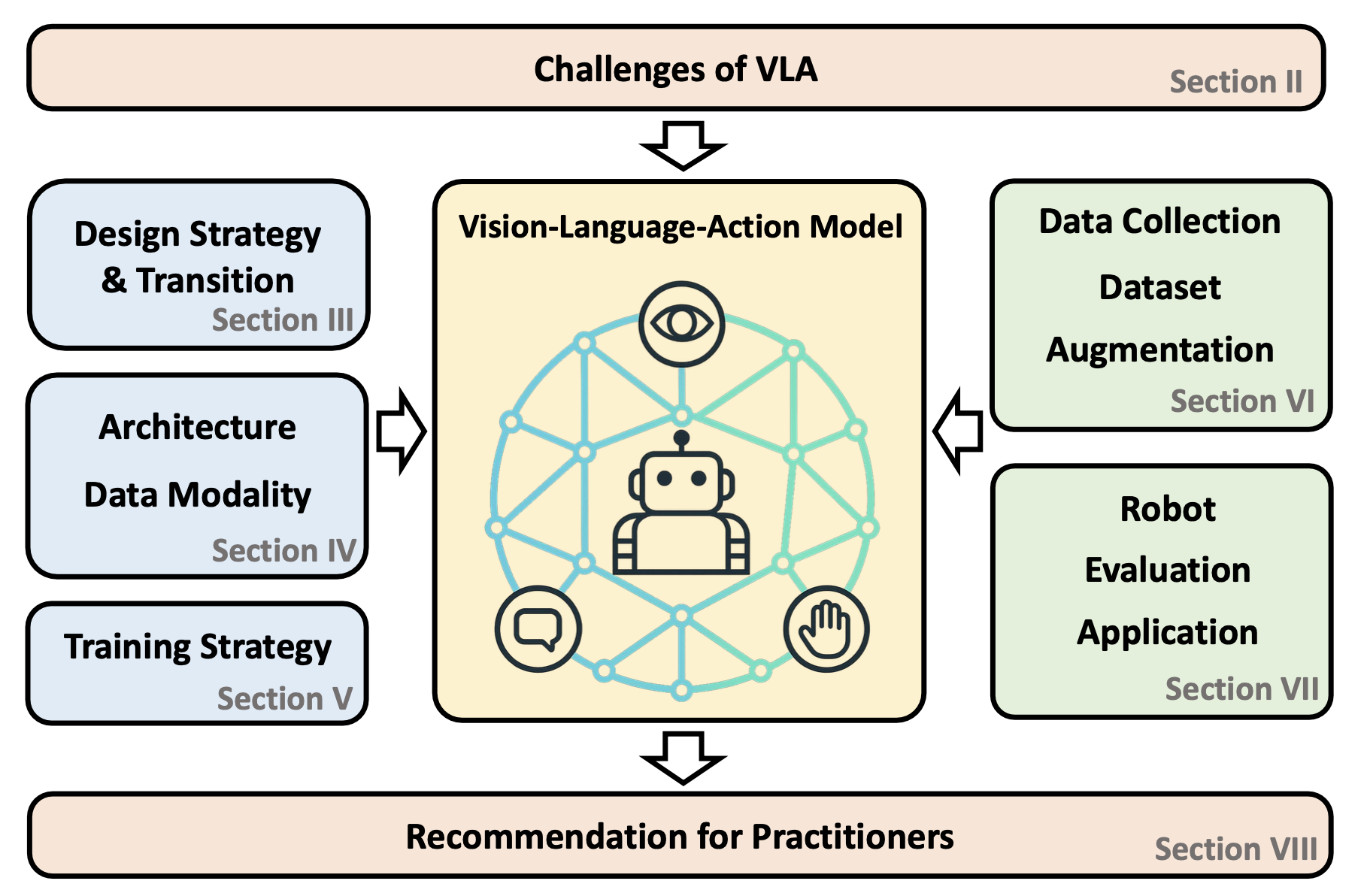
。。。。。。继续。。。。。。
将视觉-语言-动作(VLA)模型的训练方法分为监督学习、自监督学习和强化学习。
监督学习
大多数 VLA 模型都是使用监督学习在包含图像、语言和动作对的数据集上进行训练的。由于许多 VLA 都基于 LLM 构建,因此训练通常被表述为下一个 token 预测任务。动作损失函数的选择取决于动作头的架构,例如 MLP、扩散模型或流匹配网络,以确保每种模型类型都有适当的监督。
VLA 训练通常包含两个阶段:预训练和后训练。在许多情况下,首先使用在网络规模数据上预训练的 LLM 或 VLM 作为训练的初始主干。虽然有些模型是从头开始训练的,但更常见的是使用已经获得常识性知识的预训练 VLM 进行初始化训练,以增强泛化能力。预训练通常使用数据集进行,例如人类演示、异构机器人演示或与机器人规划相关的 VQA 数据集。与 LLM 类似,数据规模在 VLA 预训练中起着至关重要的作用。利用海量且多样化的数据集,可以开发出在各种任务和具体实现中具有更强泛化的 VLA 模型。在预训练阶段,预训练的 VLM 通常经过全面微调,以适应机器人相关领域。
预训练完成后,将使用特定于任务或机器人的数据集进行后训练。在此阶段,数据质量往往比数量更重要,并且数据集通常比预训练中使用的数据集更小。微调策略因实现而异。在某些情况下,整个模型都会经过全面微调,而在其他情况下,调整仅限于动作头。
此外,上下文学习(in-context learning)——一种最初为 LLM 开发的技术——也已被应用于甚大机器人系统(VLA)。上下文学习 VLA 模型并非明确地基于演示数据进行微调,而是在测试时以少量人类遥操作轨迹为条件,推断出合适的动作。例如,ICRT [250] 引入一个框架,其中提供 1~3 个远程操作演示作为提示,使模型能够以零样本的方式生成相应的机器人动作。
自监督学习
自监督学习偶尔会被纳入视觉-语言-动作 (VLA) 模型的训练中,主要有三个目的。
模态对齐侧重于学习 VLA 模型中跨模态的时间和任务级一致性。例如,TRA [251] 使用对比学习在共享潜空间内对齐当前状态和未来状态的表征,从而实现时间对齐。类似地,任务对齐是通过对比目标将语言指令嵌入与目标图像的嵌入对齐来实现的。
视觉表征学习旨在使用诸如掩码自编码(例如 MAE [129])、对比学习(例如 CLIP [25])和自蒸馏(例如 DINOv2 [46])等技术从图像或视频中提取视觉特征。这些预训练模型在 VLA 中被广泛用作基础视觉编码器。
潜动作表征学习利用自监督技术来学习动作嵌入。通过从初始图像和目标图像中提取潜动作,并利用初始图像和提取的潜动作重建目标图像,该模型无需明确标注即可学习有意义的动作表征。这种方法具有高度可扩展性,非常适合处理大型未标注数据集。
强化学习
虽然 VLA 通常通过模仿学习进行训练,但单纯的模仿学习面临着诸多挑战,例如无法处理新行为以及需要足够大规模和高质量的专家演示。为了解决这些问题,一些现有技术探索对 VLA 进行微调或使用强化学习 (RL) 训练低级策略,例如 PPO [252] 和 SAC [253]。这些方法大致可分为以下两类,如图所示。
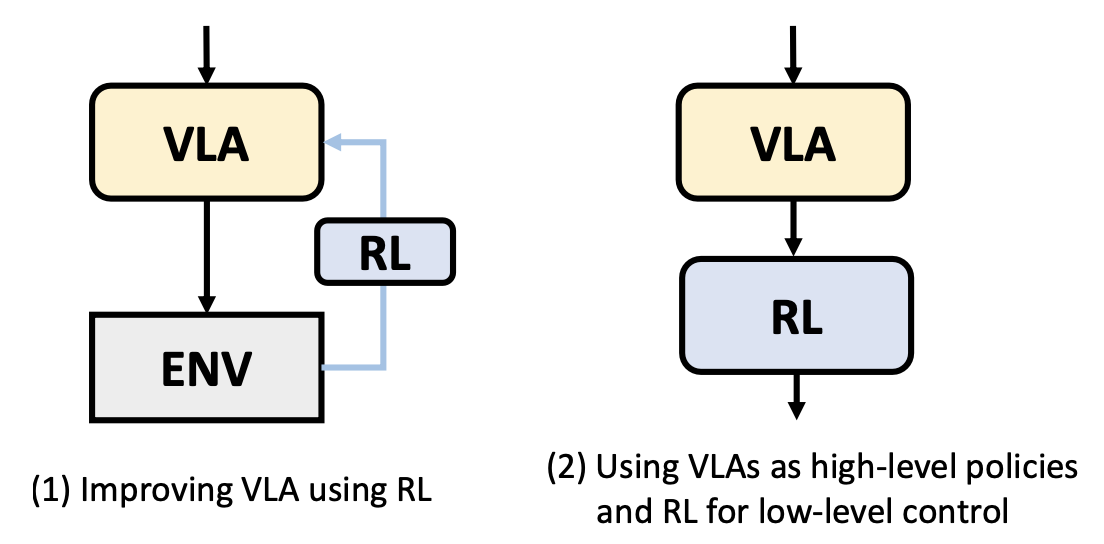
(1)利用强化学习改进 VLA。近期研究利用强化学习来提高 VLA 模型的鲁棒性、适应性和实际性能。一些方法使用强化学习对 VLA 进行微调,并将任务成功或失败作为奖励信号。
(2)使用 VLA 作为高级策略,并使用 RL 作为低级控制。这类方法将高级决策委托给 VLA,而低级控制则由经过 RL 训练的策略处理。
尽管越来越多的 VLA 方法结合强化学习,但由于样本效率低下、探索不安全以及计算效率低下,大多数先前的研究仍然局限于模拟或简化的真实世界设置。
训练阶段
训练视觉-语言-动作 (VLA) 模型通常涉及多个阶段,每个阶段针对特定的学习方面。预训练旨在获得通用能力并提升其在不同机器人实现之间的迁移能力。当预训练的视觉-语言模型 (VLM) 用作 VLA 模型的主干时,必须对其进行适配以适应机器人领域,从而有效地将语言和视觉理解应用于实际行动。接下来是后训练阶段,在此阶段,使用高质量的机器人演示数据进一步完善模型,以提高其在特定下游任务上的性能。
预训练
预训练在塑造 VLA 模型的泛化能力和语义基础方面发挥着关键作用。近期预训练流程中的关键策略和设计选择,包括大规模多模态数据、强大的 VLM 主干网络和训练稳定性技术促进有效的策略初始化。
数据规模和来源。训练数据的规模和异质性显著影响 VLA 模型在不同场景、目标和任务中的泛化能力。近期的模型越来越多地利用结合机器人演示、网络规模的视觉语言语料库和结构化注释的大规模数据集,以提升语义理解和视觉运动基础。
这些方法表明,VLA 训练数据不仅在规模上,而且在结构和模态上都日益丰富。通过对动作、语义基础和推理任务进行联合训练,现代 VLA 获得更丰富的表征,从而支持稳健的策略学习和泛化。
VLM 主干模型。近期 VLA 模型中的一种常见做法是利用已在大规模网络数据上预训练的视觉-语言模型 (VLM)。这种策略使模型能够继承广泛的视觉和语言先验知识,包括常识知识、语义基础和推理能力。通过将低级感知基础与动作策略学习分离,预训练的 VLM 提供一个灵活的基础,可以在有限的额外监督下适应各种机器人任务。
梯度隔离。训练 VLA 模型的一个新兴趋势是防止梯度从动作头流入视觉语言主干网络 [293]。允许来自随机初始化的动作头的梯度传播可能会损害预训练的表示,导致训练不稳定且效率低下。先前的研究表明,这种梯度隔离形式显著提高训练的稳定性和效率 [293]。GR00T N1.5 [24] 也可能出于类似的原因完全冻结 VLA 模型。同样,RevLA [294] 也通过逐渐反转主干网络权重来解决灾难性遗忘问题,这一方法受到模型合并的启发。
稳定性和效率启发式方法。Re-Mix [295] 根据超额损失调整各个数据集的采样权重,这量化每个域内剩下的策略改进潜力。
后训练
与依赖于大规模多样化数据集的预训练相比,后训练需要高质量的、针对特定机器人和任务的数据。由于完全微调通常需要大量的计算资源,因此一种替代策略是仅微调动作头,同时保持主干网络权重不变。另一种方法是使用低秩自适应 (LoRA) [296],它能够在计算效率上实现微调,同时将性能损失降至最低。
此外,BitVLA [297] 引入一种基于蒸馏的方法来量化视觉编码器,旨在实现内存高效的训练。具体而言,通过将全精度编码器蒸馏成量化的学生模型,将视觉编码器压缩到 1.58 位。该策略在性能损失降至最低的情况下实现了显著的内存节省,从而有助于在资源受限的系统上高效部署。
冻结主干网络 vs. 完全微调。在将预训练的视觉-语言模型 (VLM) 用于机器人任务时,一个关键的设计选择是冻结视觉-语言主干还是进行全面的微调。这个决定涉及多个维度的根本性权衡:计算效率、域适配、性能-资源折衷和知识保留。
推理
为了解决实际执行过程中的延迟问题,实时分块 (RTC) [298] 引入一种异步动作生成策略。RTC 通过修复先前执行的动作并按序列生成后续动作来减少延迟。该方法使用软掩码来保持与过去轨迹的时间一致性,同时基于更新的感知输入实现动态重新规划。
此外,DeeR-VLA [299] 经过训练,可以在 Transformer 的每一层进行动作预测。如果从两个连续层预测的动作之间的差异较小,则跳过剩余层以加速推理。VLA-Cache [300] 通过识别静态 token 并重用先前步骤中计算的特征来提高推理速度。
如图所示:机器人使用 VLA 研究—— 包括机械手、手/夹持器、移动机器人、四足机器人和人形机器人;数据收集方法—— 包括遥控操作、智体设备和人类数据收集;公开可用的数据集——包括人类自我中心数据、模拟数据和现实世界机器人数据;视觉、语言和动作的增强;各种评估基准。
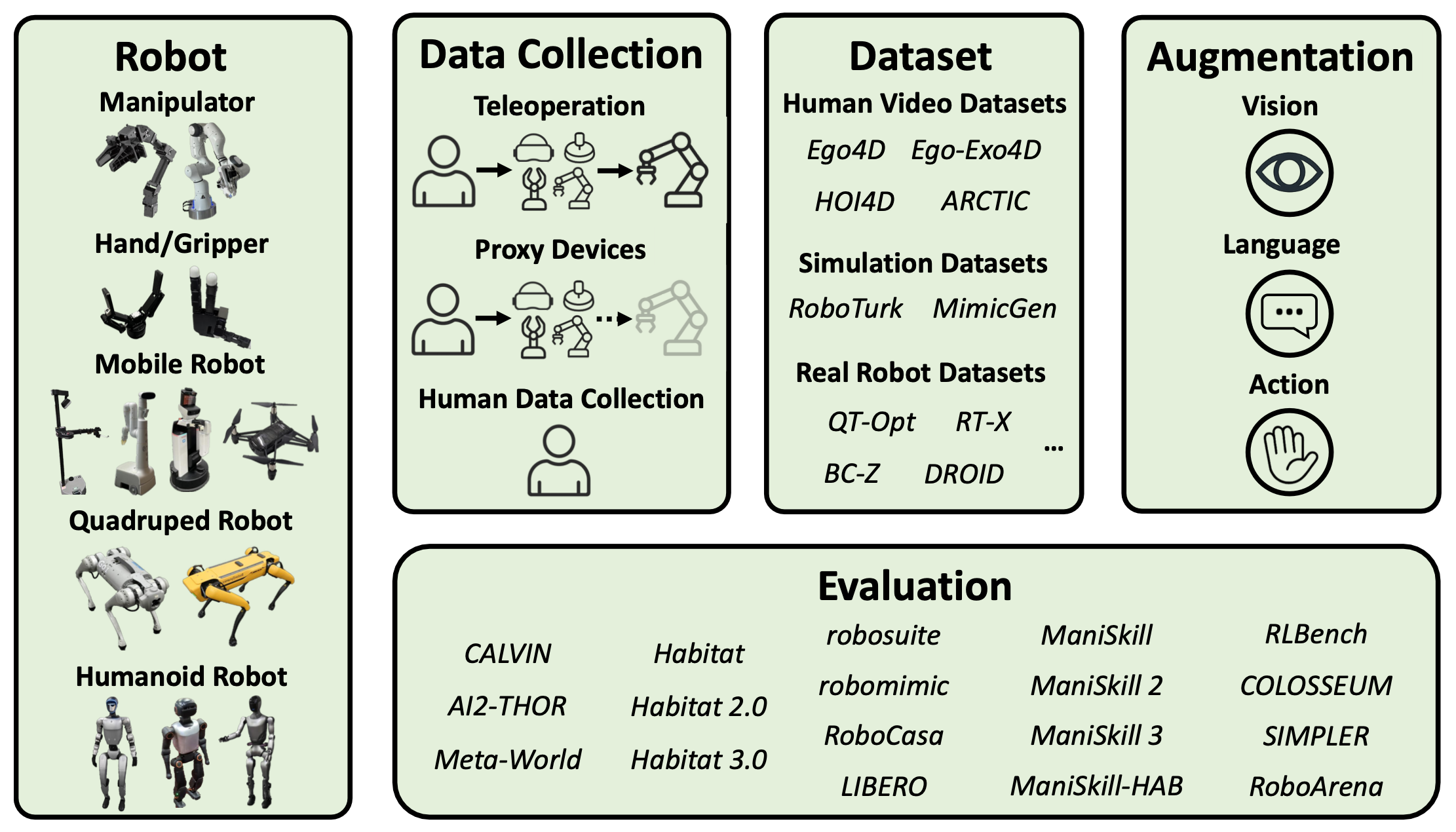
VLA 的数据收集
训练 VLA 模型需要获取大量高质量数据。以下讨论基于真实设备的方法,合成仿真数据另外介绍。
远程操作。在这种方法中,操作人员直接控制机器人,并实时记录操作演示,从而能够收集高质量的轨迹。该方法构成了许多 VLA 数据集的基础。例如,ALOHA [301] 采用单侧远程操作装置,由双臂 WidowX 250 机器人作为引导机器人,双臂 ViperX-300 机器人作为跟随机器人。跟随机器人模仿引导机器人的动作,从而能够捕获精确的操作数据。移动 ALOHA [302] 通过将系统安装在移动基座上,扩展这一框架,从而能够收集移动操作演示。 ALOHA 框架经过多次迭代发展。ALOHA 2 引入改进的硬件组件,例如升级的抓手(gripper)和重力补偿机制,以及开源硬件和仿真环境 [303]。基于这一升级平台,ALOHA Unleashed 研究大规模模仿学习 [304]。此外,Bi-ACT [305] 引入双边控制,以实现主机器人和跟随机器人之间更灵敏的交互;而 GELLO [306] 则通过采用按比例调整连杆长度的缩小型跟随机器人来调整系统。
与需要主从两个机器人同时工作的主-从方法相比,许多先前的研究已经提出一些方法来减轻人类操作员的负担并降低遥操作系统的总体成本。例如,AnyTeleop [307] 使用 MediaPipe [308] 通过单个 RGB 摄像头估计人手的位置和方向,并通过 CuRobo [309] 将这些信息重新定位到机器人上,以实现遥操作。ACE [310] 将使用外骨骼设备的精确腕部追踪与 Mediapipe 的手部姿势估计相结合,以实现精确的遥操作。OpenTelevision [311] 瞄准人形机器人的应用,利用 Apple Vision Pro 进行手部和头部姿势估计,以实现遥操作和基于主动视觉的操作。Bunny-VisionPro [312] 也采用 Apple Vision Pro,但更加注重触觉反馈和实时系统集成。
除了这些方法之外,还可以通过更直接的VR 控制方法来收集数据,例如 3D 鼠标或游戏控制器。虽然这些替代方案简化了设置并消除了对可穿戴设备或基于视觉的姿态估计系统的需求,但它们在复制自然人体运动时保真度可能会降低。
使用智体设备进行数据收集。直接控制物理机器人对扩展数据收集提出了重大挑战。通过将人体运动与物理机器人控制分离,最近的方法通过使用智体设备实现了更直观、灵活和可扩展的数据收集。例如,UMI [313] 是一个配备 GoPro 相机的手持式夹持器,其 6 自由度轨迹是使用视觉 SLAM 估计的。收集到的数据可用于训练策略,稍后通过将 UMI 安装为机器人的末端执行器,机器人可以在数据收集过程中无需物理参与的情况下重现演示的运动。最近,LBM [314] 利用 UMI 收集 32 小时的演示。DexUMI [315] 通过用五指机械手代替简单的夹持器,将这一概念扩展到灵巧操作。人类演示者佩戴外骨骼手套,该手套配备与目标机器人相同的摄像头和触觉传感器,从而可以忠实地传输记录的手部动作。基于类似的原理,Dobb-E [316] 使用类似于 Hello Stretch 末端执行器的杆状装置来捕捉人类演示。RUMs [317] 通过增加收集任务的多样性、结合故障检测机制和改进网络架构,进一步增强了这一范例。这些改进使机器人仅通过预训练就能泛化到各种各样的任务中。DexCap [318] 是一种数据收集设备,它在 Rokoko EMF 手套上安装 Realsense T265 摄像头,用于双手,并在胸部安装额外的 Realsense T265 和 L515 传感器,从而实现基于 SLAM 的 6 自由度腕部姿势估计和基于手套的手部姿势跟踪。相比之下,DexWild [319] 通过使用 EMF 手套结合双手掌心摄像头以及通过外部摄像头进行 ArUco 标记跟踪,解决 DexCap 的布线复杂性和 SLAM 标定挑战。
人体数据收集。这种方法通过记录自然的人类行为来收集数据,而不依赖于模仿机器人末端执行器的智体设备。这种方法最简单的形式是将 GoPro 摄像机或麦克风安装在用户头上,以捕捉第一人称视觉和听觉数据,通常还会补充惯性测量单元 (IMU) 或注视信息。该技术已广泛应用于大规模以自我为中心的数据集,例如 Ego4D 和 EPIC-KITCHENS [130], [155], [156]。可穿戴传感技术的最新进展使得使用小型智能眼镜(例如 Meta 的 Project Aria)可以实现更自然、更可扩展的数据收集。这些设备促进丰富数据集的开发,包括 Ego Exo4D、HOT3D、HD EPIC 和 Aria Everyday Activities [320]–[323]。利用这些数据集,一些先前的研究已经直接从人类演示数据训练机器人策略。例如,EgoMimic 和 EgoZero 通过模仿以自我为中心的人类行为来学习视觉运动控制 [324], [325]。同样,其他研究使用 Apple Vision Pro 等设备收集的数据来训练基于自然人体运动的人形机器人策略 [326]。
数据收集流程。数据收集在训练 VLA 模型中起着关键作用。这些模型需要大规模、高质量的数据集,并且必须精心设计数据采集流程以确保效率和多样性。在 RT-1 [16] 的案例中,使用一个框架收集大规模真实机器人数据集,该框架从精心策划的指令集中采样指令和随机初始状态。这种方法能够收集各种任务和环境中的演示,由人类操作员执行采样的指令以生成多样化且平衡的数据。 RoboTurk [327] 使用 iPhone 开发一个 6 自由度遥操作界面,从而能够通过众包平台收集大规模机器人操作演示 [328]。
此外,先前的研究 [329]、[330] 证明用自然语言注释预收集数据集的有效性。例如,语言表数据集 [329] 收集了遥操作轨迹,随后通过众包添加语言注释,从而形成一个包含约 600,000 条语言标记轨迹的大规模数据集。同样,DROID [330] 在 18 个研究机构开展分布式数据收集,收集 564 个场景和 86 个任务的 76,000 条轨迹和 350 小时的交互数据,随后通过众包平台用自然语言对这些数据进行注释。
然而,由于人工注释成本高昂,近期趋势越来越多地利用 VLM 等基础模型来自动化注释过程。ECoT [86] 和 EMMA-X [331] 使用 Grounding DINO [175] 和 SAM [145] 将物体检测和夹持器定位结合起来,并使用 Gemini 1.0 进行高级规划和子任务生成,以生成自动注释。NILS [332] 是一个框架,它可以分割长视界机器人视频并在没有人工干预的情况下生成语言注释。它集成了多个 VLM,根据物体状态变化和夹持器运动来检测关键状态,并使用 LLM 生成自然语言指令。RoboMIND [333] 也采用基于 Gemini [334] 的注释系统,并通过使用 VLA 模型进行预训练,展示显著的性能提升。
虽然这些方法比人工事后注释更具成本效益和可扩展性,但它们面临着诸如细粒度场景理解和幻觉等挑战。尤其是在像 ECoT 这样完全依赖文本的方法中,更容易出现与实际视觉上下文不一致的情况。基于视觉输入的方法(例如 EMMA-X)或整合多种感知模态的方法(例如 NILS)已被证明能够有效解决这些问题。
VLA 数据集
由于 VLA 的开发建立在 LLM 和 VLM 的进步之上,因此大量基于网络的数据集被利用。这些数据集主要分为三大类。
人体数据集。收集人体数据比收集机器人数据具有更高的可扩展性,因为它不需要访问物理机器人、进行精确标定或安全-紧要的执行环境。虽然第三人称视觉数据仍在使用,但第一人称数据对于 VLA 预训练尤为重要,因为它更接近现实世界机器人(尤其是配备头戴式传感器或类人机器人)接收的感知输入。因此,第一人称视觉数据现已被广泛用作预训练 VLA 模型的关键资源。例如,Ego4D [130] 是规模最大、最全面的以自我为中心的视频数据集之一,包含来自 9 个国家/地区 74 个城市的 800 多名参与者的 3000 多个小时的头戴式 RGB 素材。其他值得注意的例子包括记录日常厨房活动的 EPIC-KITCHENS [155], [156] 和捕捉细粒度人机交互的 HOI4D [344]。一些数据集专门针对操控任务。OAKINK2 [345] 和 H2O [346] 使用 RGB-D 传感器和运动捕捉系统捕捉双手物体操控。 ARCTIC [347] 专注于通过灵巧的双手操作与铰接体进行交互,而 EgoPAT3D [348] 则侧重于从自我中心视角预测人类动作目标。
此外,基于智能眼镜记录设备的出现使得以自我为中心的数据收集更加自然、更加隐蔽。值得注意的例子包括 Aria Everyday Activities [323];融合自我为中心和外向中心视角的 Ego-Exo4D [320];专注于细粒度手部-物体追踪的 HOT3D [321];以及扩展以自我为中心烹饪数据的 HD-EPIC [322]。这些数据集经常用于 VLA 模型的预训练,通常通过 LAPA [22] 等潜动作预测方法进行。尽管并非以自我为中心,但 HowTo100M [349]、Something-Something V2 [350] 和 Kinetics-700 [351] 等大规模视频语言数据集也用于模型预训练,有时也适用于 VLA 相关任务。随着 VLA 研究越来越多地采用具有类人感官配置的人形机器人和系统,以自我为中心的数据集,尤其是那些捕捉自然、目标导向行为的数据集,预计将发挥越来越重要的作用。
模拟数据集。长期以来,模拟环境一直被用于以可扩展、安全且经济高效的方式生成机器人数据集。它们支持受控数据收集和场景配置的灵活操作,使其特别适合模仿学习和大规模模型预训练。例如,RoboTurk [327] 包含 MuJoCo 物理引擎 [352] 中 Sawyer 机器人的任务演示,这些演示是通过云端的远程人类遥操作收集的。然而,在模拟中收集大规模演示数据,尤其是通过远程操作,仍然非常耗时。为了缓解这一限制,MimicGen [353] 引入一个框架,用于从少量专家演示中生成大规模数据集。它将演示分解为以目标为中心的子任务,并通过将它们转换并重新组合成新场景来合成新轨迹。DexMimicGen [354] 将这种方法扩展到更复杂的实例,例如双臂机器人和多指手。
与此同时,诸如 COSMOS [269] 之类的大规模视频世界模型已被开发出来,用于生成多样化的想象轨迹,为 VLA 模型提供丰富且可扩展的训练数据。
尽管模拟在早期 VLA 研究中发挥了核心作用,但随着大规模现实世界机器人数据集(参见真实机器人数据集)的日益普及,其主导地位已经下降。尽管如此,模拟仍然是生成多样化、可控数据的有力工具,尤其是在现实世界数据收集不切实际或成本过高的情况下。
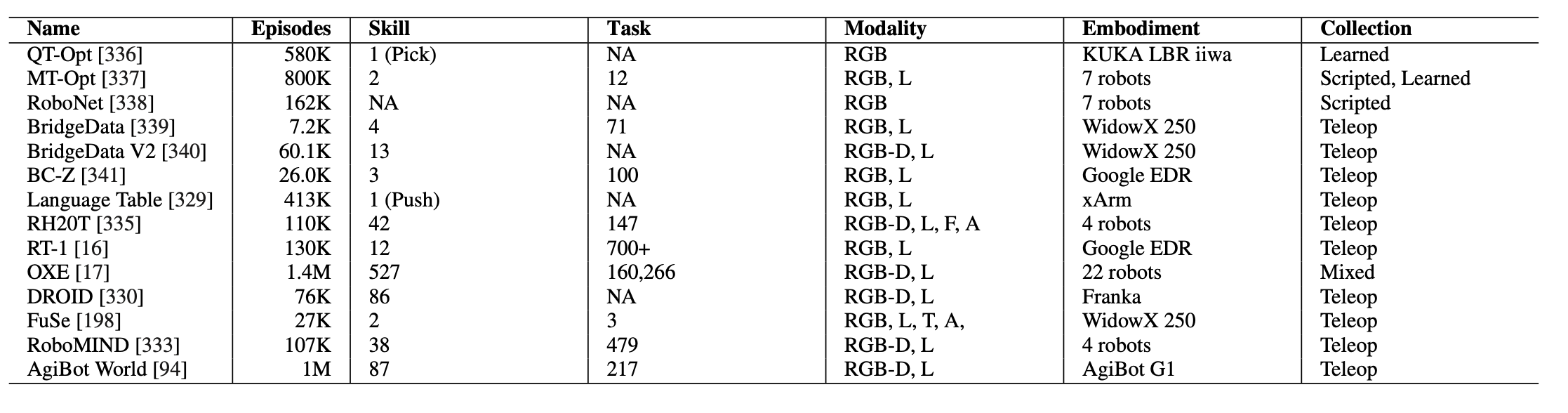
真实机器人数据集。真实机器人数据集在 VLA 模型的开发和评估中发挥着至关重要的作用。这些数据集是在物理机器人硬件上收集的,提供了多样化的体现、逼真的交互和丰富的感官输入,这些对于训练能够泛化到现实世界任务的模型至关重要。MIME [355] 是首批大规模机器人数据集之一。它包含 20 个任务的 8.2K 条轨迹,包括配对的人类演示和人类对 Baxter 机器人的动觉教学。同时,QT-Opt [336] 也已推出,其中包含使用七个 KUKA LBR iiwa 机械臂在四个月内收集的 580,000 次抓取尝试。MT-Opt [337] 是 QT-Opt 的扩展,它将任务范围扩展到抓取之外,以支持更广泛的操作技能。RoboNet [338] 包含从七种机器人类型(Sawyer、Baxter、WidowX、Franka Emika Panda、KUKA LBR iiwa、Fetch 和 Google Robot)收集的 162,000 条轨迹。尽管这些轨迹是使用随机或基于规则的动作(而不是专家演示)生成的,但该数据集支持跨不同平台和环境的泛化研究。 BridgeData [339] 是使用 Oculus Quest 2 和 WidowX 250 机器人通过 VR 远程操作收集的。它包含 10 种环境和 71 个任务的 7200 条轨迹。这项工作的扩展,BridgeData V2 [340],将数据集扩展到 24 种不同环境中的 60000 条轨迹。BC-Z [341] 涉及 12 个谷歌机器人,由 7 名人类远程操作员操作,执行 100 多项操作任务。额外的数据是通过在人工监督下执行策略收集的,最终产生 25900 条轨迹。Language Table [329] 包含 600000 条块操作轨迹(现实世界轨迹 413K 条,模拟轨迹 181K 条),并配有自然语言指令。数据是通过长时间的无目标演示收集的,并通过众包进行注释,以支持指令条件训练。 RH20T [335] 提供从四个机器人(Franka Emika Panda、UR5、KUKA LBR iiwa 和 Flexiv Rizon)收集的多模态数据,涵盖 147 个任务和 7 种配置。与早期数据集不同,它包含同步的 RGB-D、6 轴力-扭矩、关节扭矩和音频信号,支持多模态感知和控制。RT-1 [16] 包含使用 13 个谷歌机器人在 17 个月内收集的 130,000 条真实机器人演示轨迹。它为基于 Transformer 的 RT 系列 VLA 模型奠定基础,用于实现实时的指令调节行为。最后,Open-X (OXE) 数据集 [17] 使用 RLDS 模式将许多数据集(包括 RT-1、BC-Z、BridgeData 和 Language Table)统一为标准化格式 [356]。 OXE 数据集由 21 个机构和 173 位作者参与的大规模合作开发,是迄今为止最全面、应用最广泛的真实机器人 VLA 数据集之一。
为了进一步推进 VLA 研究,已经发布几个其他真实机器人数据集。DROID [330] 是一个大型数据集,包含 13 个机构使用标准化硬件设置收集的 76,000 条轨迹。每个参与实验室都使用配备 Robotiq 2F-85 夹持器的 Franka Emika Panda 机械臂、两个外部立体摄像头和一个腕戴式摄像头。与聚合来自异构机器人平台数据的 Open X-Embodiment 数据集不同,DROID 确保跨环境和具身的一致性,使其非常适合基准测试。FuSe [198] 提供使用 WidowX 250 平台收集的 27,000 条多模态轨迹。该机器人配备外部摄像头、腕式摄像头、DIGIT 触觉传感器、麦克风和惯性测量单元 (IMU),从而能够为 VLA 任务提供丰富的跨模态学习。RoboMIND [333] 提供从各种机器人形态(包括单臂、双臂、人形和灵巧手配置)收集的 107,000 条轨迹。该数据集强调形态和操作策略的多样性,支持泛化和迁移研究。AgiBot World Dataset [94] 是一个海量数据集,包含使用 100 多个 AgiBot G1 机器人收集的 100 万条轨迹。其前所未有的规模使其能够在高度多样化的条件下训练大型 VLA 模型。除了这些主要版本之外,还推出了一些针对特定任务或特定平台的数据集,包括与任务无关的机器人游戏 [357]、[358]、Jaco Play [359]、Cable Routing [360]、Berkeley Autolab UR5 [361]、TOTO [362] 和 RoboSet [363]。此外,还出现以导航为重点的 VLA 数据集,例如 SACSoN [364]、SCAND [365]、RECON [366] 和 BDD100K [367],它们支持移动平台上的指令遵循和目标导向行为。最后,诸如 RoboVQA [368] 之类的专用数据集,针对特定于机器人的问答系统,进一步拓宽 VLA 应用的范围,使其超越了操作和导航。
下表所示VLA的真实世界机器人数据集:
面向 VLA 的数据增强
鉴于收集数据集的高成本,各种数据增强方法应运而生,旨在扩展现有数据集。这些方法涵盖多种模态,包括视觉、语言和动作。
视觉增强。在大多数计算机视觉任务中,旋转、裁剪和缩放等增强技术通常用于提升泛化能力。然而,在机器人技术领域,机器人的具身性及其与摄像头的空间关系至关重要,此类变换可能会扭曲这些关系,并对性能产生负面影响。为了解决这个问题,近期提出使用图像生成模型(例如稳定扩散 [137])进行具身感知增强的方法。
语言增强。DIAL [374] 从一小组手动标记的轨迹-指令对种子集开始。VLM 在该种子集上进行训练,以计算轨迹和指令之间的相似度。同时,LLM 生成种子指令的不同释义,形成一个庞大的候选池。然后,使用训练的 VLM 将这些轨迹与剩余的未标记轨迹进行匹配,并分配前 k 个最相似的指令。生成的数据集用于训练 RT-1 [16]。
动作增强。由于动作与机器人的物理行为和具身直接相关,因此增强动作数据通常具有挑战性。应对这一挑战的一种常用方法是通过交互式方法扩展数据集,例如 DAgger [375],它迭代地收集已学习策略访问过状态下的专家动作。类似地,CCIL [376] 通过学习局部平滑的动力学模型,在策略遇到分布外状态时生成校正数据。它合成引导机器人从新状态回到专家访问过状态的动作,并将生成的校正数据与原始演示相结合,以完善策略。
以下总结 VLA 研究的关键实践方面,包括所使用的机器人类型、数据收集方法、公开可用的数据集和增强技术,以及用于评估模型性能的评估协议。
用于 VLA 的机器人
机械手。机械手是 VLA 研究中最常用的机器人,包括单臂和双臂配置。这些机械手通常具有 5、6 或 7 个自由度 (DoF)。这些机械手的关节配置和连杆长度各不相同。这些机械手用于执行各种任务,包括物体抓取和重定位、组装、操纵变形体以及钉孔插入。
手/夹持器。此类别指的是安装在上述机械手上作为末端执行器的手和夹持器。这些机器的设计各不相同:LEAP Hand [379] 有四个手指;Robotiq Gripper 和 UMI [313] 是两个手指;其他机器人则是五个手指。一些系统还使用吸盘或特定任务的夹持器,例如 Shake-VLA [380]。ALOHA、ARX 和 PiPER 等平台通常默认包含两个手指的夹持器。两个手指的夹持器适合抓取,而四个手指和五个手指的机械手则支持工具使用和手内操作。
移动机器人。VLA 研究中涉及的移动机器人包括轮式平台和移动机械臂,后者将机械臂与移动基座相结合。移动平台拥有超越固定臂或夹持器的运动和环境交互能力,支持涉及导航和动态场景参与的任务。某些型号,例如 RT-1,能够同时执行导航和操作。
四足机器人。四足机器人以其类似动物的运动方式为特征,由于其能够在非结构化和不平坦的环境中导航,因此在 VLA 研究中越来越受到重视。基于强化学习的控制策略。这些平台不仅提供运动能力,还可以配备机械手,以支持各种操作任务。
人形机器人。人形机器人的特点是其身体结构与人类相似,是 VLA 研究中探索的另一类平台。在先前的研究中,经常使用 Fourier GR-1、Unitree G1、Unitree H1 和 Booster T1。这些系统通常拥有两条腿、两条臂和连接到末端执行器的五指手。它们与人类相似的形态使其非常适合在为人类设计的空间中操作,并有助于与基于人体运动数据集训练的 VLA 兼容。
VLA 评估
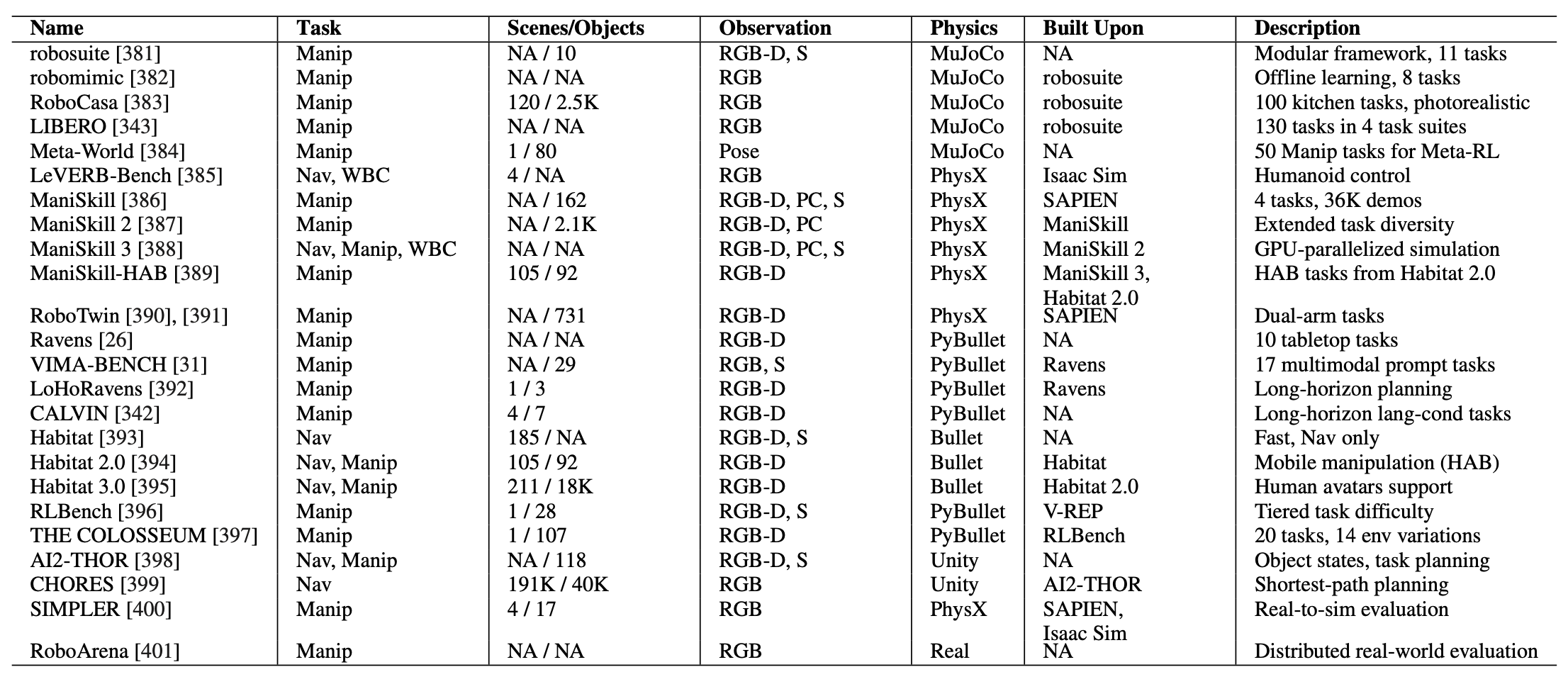
VLA 模型的评估指标仍然定义不明确,尤其是在现实世界中。由于具身、安全问题以及有限的可重复性等因素的差异,评估其在实体机器人上的泛化能力颇具挑战性。因此,大多数评估都是在模拟环境中进行的,标准化的环境和基准测试有助于在不同方法之间进行公平的比较。
MuJoCo。基于 MuJoCo [352],已经开发多个模拟环境来支持机器人操作研究。例如,robosuite [381] 是一个模块化模拟框架,其中机器人、竞技场和任务对象均使用 MJCF 文件组成,提供 11 项操作任务。robomimic [382] 在 robosuite 的基础上,引入一个系统性的基准测试,用于评估机器人操作演示中的学习效果。robomimic 基准测试包含使用 Franka Emika Panda 机器人执行的 8 项任务。
RoboCasa [383] 进一步扩展 robosuite,它整合涵盖各种机器人平台上 100 项任务的大规模、逼真的场景,从而支持更广泛的泛化和迁移学习研究。目前,评估 VLA 模型最广泛使用的基准测试是 LIBERO [402],它是为语言条件操作任务而设计的。它提供 4 个任务套件,共包含 130 项任务,均由 Franka Emika Panda 机器人执行:LIBERO-SPATIAL 侧重于物体之间的空间推理,LIBERO-OBJECT 针对物体类别识别,LIBERO-GOAL 评估对物体操作目标的理解,LIBERO-100 集成了前三个套件以评估组合泛化能力。此外,Meta-World [384] 是另一个基于 MuJoCo 构建的模拟环境,旨在评估多任务和元强化学习。它包含 50 个使用 Sawyer 机械臂执行的不同任务,可以评估跨不同操作技能的泛化能力。
PhysX。IsaacLab [403] 是一个基于 IsaacSim 构建的 GPU 加速框架,它使用 PhysX 作为其底层物理引擎。它提供一套全面的机器人学习工具,包括各种各样的机器人、环境和传感器,以及照片级逼真的渲染功能。LeVERB-Bench [385] 也基于 IsaacSim 构建,专注于全身类人机器人控制,包含 154 个视觉-语言任务和 460 个纯语言任务。
此外,ManiSkill [386]–[388] 构建于 SAPIEN 仿真平台 [404] 之上,其底层物理引擎也基于 PhysX,可作为从 3D 视觉输入中学习物体操控技能的综合基准测试。它涵盖了涉及关节和变形体、移动性和各种机器人形态的各种任务,并提供大规模演示数据,支持高效、高质量的模拟。ManiSkill-HAB [389] 是一个专注于物体重排列任务的基准测试,遵循 Habitat 2.0 [394] 中引入的 Home Assistant 基准 (HAB)。此外,SAPIEN 上还开发其他几个基准测试集,例如 RoboCAS [405](评估复杂物体排列环境中的机器人操作)和 DexArt [406](专注于使用多指手操作铰接物体)。最近,RoboTwin [390], [391] 被提议作为双臂操作的基准测试集,提供 50 个任务、731 个物体和 5 种不同的实现方式。
PyBullet。Ravens [26] 是一个使用 PyBullet [407] 实现包含 10 个桌面操作任务的基准测试集。VIMA-BENCH [31] 扩展该基准测试集,增加了 17 个任务,允许基于多模态提示的任务规范。LoHo-Ravens [392] 是另一个扩展测试集,用于评估桌面操作场景中的长远规划能力。此外,CALVIN [342] 提供基于自然语言指令的长视界操作模拟和基准测试,其中包括由 Franka Emika Panda 机器人执行的 34 项操作任务。此外,Habitat [393]–[395] 是一个主要由 Meta 开发的模拟框架。
V-REP。RLBench [396] 是第一个大规模的模仿和强化学习基准测试,使用 V-REP [408] 和 PyRep [409] 构建。它包含使用 Panda 机器人执行的 100 个操作任务。 THE COLOSSEUM [397] 建立在 RLBench 之上,是一个基准测试集,旨在系统地评估机器人操作策略在环境变化下的泛化能力。THE COLOSSEUM 包含 20 个操作任务,涉及 14 种环境扰动。
Unity。AI2-THOR 是一个基于 Unity 引擎构建的逼真的交互式 3D 仿真环境,提供四个任务套件,例如 iTHOR、RoboTHOR、ProcTHOR-10K 和 ArchitecTHOR [398], [410], [411],涵盖各种各样的室内环境。此外,SPOC [399] 引入 CHORES,这是 AI2-THOR 的扩展,旨在作为导航任务中最短路径规划的基准测试集。
其他。虽然并非严格意义上的基于模拟的基准测试,但一些研究已经提出评估协议来评估 VLA 模型的能力。
迈向 VLA 的真实且可扩展的评估。人们越来越重视在与现实世界高度相似的条件下进行评估,这导致真实模拟基准测试和可扩展系统的开发,用于对 VLA 模型进行分布式真实世界评估。SIMPLER [400] 通过最小化视觉和控制域之间的差距,实现在模拟环境中对基于真实世界数据训练的策略进行评估,从而实现模拟和真实世界性能之间的高度相关性。 RoboArena [401] 是一个分布式框架,用于在现实世界中对 VLA 模型进行大规模、公平且可靠的评估。它对部署在七所大学的机器人网络进行成对比较,结果由中央服务器汇总,生成全球排名。该系统基于 DROID 平台构建。
下表所示VLA评估的基准:任务包括导航(Nav)、操控(Manip)和全身控制(WBC)。观察模式包括RGB-D(图像 +深度)、S(语义分割)和PC(点云)。
实际应用
主要是将机器人平台(包括机械手、手、移动机器人、四足动物和人形机器人)用于 VLA 模型的开发和评估。
(略)
实际工作建议
基于近期 VLA 研究的洞见,为现实世界机器人系统中设计、训练和部署 VLA 模型提供切实可行的建议。主要包括数据收集、架构选择和模型适配方面的实用策略。
1)优先考虑多样化和高质量的数据集。跨任务、目标和具身的鲁棒泛化依赖于使用涵盖视觉、语言和动作模式的大规模高质量数据集进行训练。从业者应致力于收集或利用能够提供广泛任务覆盖、环境多变性和具身多样性的数据集。这种多样性对于提升 VLA 策略的鲁棒性和可迁移性至关重要。
2)优先考虑通过生成式方法生成连续动作。虽然生成连续动作(而非依赖于离散化的 token)在近期文献中已得到越来越广泛的认可,但生成连续动作对于实现流畅且精确的机器人行为仍然至关重要。鼓励从业者采用诸如扩散或流匹配之类的生成式方法,以便在实际环境中实现高保真控制。
3)在预训练期间尝试梯度隔离。允许随机初始化的动作头的梯度传播到预训练的 VLM 主干网络可能会降低已经捕获常识性知识学习表征的质量。为了稳定训练并保留主干网络中的语义知识,鼓励从业者冻结主干网络或应用梯度隔离机制。事实证明,这种方法可以同时提高训练效率和最终性能。
4)从轻量级自适应方法入手。对大型 VLA 模型进行全面微调通常计算量巨大。作为第一步,无法使用 GPU 集群的从业者可以只微调动作头,同时保持主干网络冻结。或者,像 LoRA 这样的方法可以实现参数高效的微调,在性能和资源消耗之间实现良好的平衡。
5)结合世界模型或潜动作学习以实现可扩展性。在涉及人形机器人的场景中,由于人体形态的相似性,在预训练过程中结合人体视频数据可能特别有利。然而,由于此类数据集通常缺乏明确的动作注释,因此学习可在预训练过程中用作替代动作目标的潜动作表示将大有裨益。此外,世界模型的预测能力可以支持更有效的规划和推理,尤其是在操作任务中。通过预测未来的观察结果,世界模型有助于实现更好的长时域控制和多模态基础,正如 FLARE [139] 等先前工作所证明的那样。
6)采用多任务学习来增强用于动作生成的表征。虽然在网络规模数据上预训练的 VLM 提供强大的语义基础,但它们的表征并不总是直接适用于下游控制。结合诸如 affordance 估计、关键点检测、未来状态预测和目标对象分割等辅助任务,可以鼓励模型学习更符合动作生成要求的表征。这些任务支持空间推理、时间预测和物理交互建模,最终提高模型将感知转化为有效控制的能力。
未来工作方向 (略)
数据模态
推理
持续学习
强化学习
安全
失败检测和恢复
评估
应用

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献215条内容
已为社区贡献215条内容

所有评论(0)