斯坦福CS224n深度学习与自然语言处理课程笔记
深度学习的出现,为计算机视觉、语音识别、自然语言处理等多个领域带来了革命性的改变。在本节中,我们将探讨深度学习的基础知识以及它在NLP中的独特优势和面临的挑战。BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer的预训练模型,由Google在2018年提出。BERT的一个主要创新是采用了双向Tra

简介:斯坦福大学的CS224n课程深入探讨了自然语言处理(NLP)和深度学习技术,包括文本预处理、循环神经网络、长短时记忆网络、Transformer模型、BERT等预训练方法。通过系统的笔记整理,学生可以掌握从基础到高级的NLP技术,以及在情感分析、机器翻译等实际问题中的应用。本课程内容覆盖了自然语言处理的基础知识、深度学习原理、词嵌入技术、注意力机制、Transformer模型、预训练模型、应用实例以及最新的NLP研究进展。 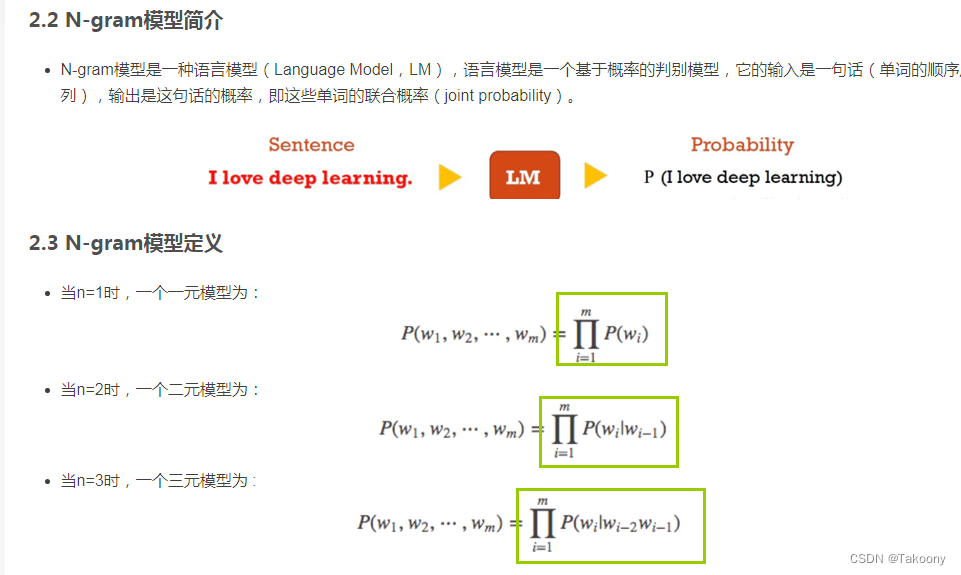
1. 自然语言处理基础概念
自然语言处理(NLP)作为计算机科学和人工智能领域中的一个重要分支,它涉及到让计算机理解、解析、生成人类语言的各种技术。本章将介绍自然语言处理的基础概念,为深入理解后续章节中的技术细节和应用实践打下基础。
1.1 语言模型与语言处理任务
语言模型是NLP的核心组成部分,它对输入的文本数据建立统计模型,用于预测下一个词、生成文本或者评估句子的合理性。语言处理任务可以包括机器翻译、情感分析、文本摘要、问答系统等,它们均依赖于语言模型的辅助。
1.2 自然语言处理的应用场景
NLP的应用场景广泛且多样,包括但不限于医疗健康、金融服务、法律咨询、教育、客户服务等。通过理解和处理人类语言,NLP技术极大地提高了信息处理的效率,扩展了人与计算机交互的边界。
随着深度学习技术的引入,NLP技术实现了质的飞跃,为诸如语音识别、文本到语音的转换、语言翻译等提供了更加准确和自然的处理能力。下一章将探讨深度学习在NLP中的具体应用。
2. 深度学习在NLP中的应用
深度学习已经成为自然语言处理(NLP)领域的核心技术之一。它通过大规模神经网络结构挖掘和学习数据中的复杂模式,为理解和生成语言提供了新的可能性。
2.1 深度学习技术概述
深度学习的出现,为计算机视觉、语音识别、自然语言处理等多个领域带来了革命性的改变。在本节中,我们将探讨深度学习的基础知识以及它在NLP中的独特优势和面临的挑战。
2.1.1 人工神经网络基础
人工神经网络(ANNs)是一种旨在模拟人脑处理信息机制的算法模型。神经网络由大量的节点(或称“神经元”)和它们之间的连接构成。每个连接都有一个权重,它会在神经元的激活函数中发挥作用。
在NLP中,神经网络通常用于捕捉文本数据中的非线性特征和模式。例如,一个简单的前馈神经网络可以被训练来预测词性或者进行情感分析。
# 一个简单的前馈神经网络例子,使用Keras框架构建
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(input_dim,)))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
在这段代码中,我们定义了一个简单的深度神经网络模型,其中包含一个输入层、一个隐藏层和一个输出层。输入层接受输入数据,隐藏层使用ReLU激活函数处理信息,输出层则用Sigmoid激活函数进行二分类任务。
2.1.2 深度学习的优势与挑战
深度学习的优势在于它强大的特征学习能力,无需人工设计复杂的特征,可以自动从大规模数据中提取高阶特征。这对于处理自然语言这种高度复杂的数据结构来说尤为重要。
然而,深度学习也面临不少挑战。首先是数据依赖性强,需要大量标注数据进行训练。其次是计算资源消耗大,特别是训练大型模型需要昂贵的硬件支持。另外,深度学习模型的“黑箱”特性导致模型的决策过程难以解释。
2.2 深度学习与NLP的结合
随着深度学习技术的发展,其与NLP的结合为各种NLP任务带来了前所未有的性能提升,包括语言模型、机器翻译、文本生成等领域。
2.2.1 模型在NLP中的角色
在NLP任务中,深度学习模型通过学习大量的语料数据,可以捕捉语言的规律和模式。例如,循环神经网络(RNN)及其变种LSTM和GRU,能够处理序列数据并学习文本中的时间依赖性。
# LSTM模型代码示例,使用Keras框架
from keras.models import Sequential
from keras.layers import LSTM, Dense
model = Sequential()
model.add(LSTM(128, return_sequences=True, input_shape=(timesteps, input_dim)))
model.add(LSTM(128))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
在上述代码中,我们构建了一个双层LSTM网络。第一层返回序列,用于构建与前一时间步相关的记忆;第二层则把这种序列记忆整合为最终的输出。
2.2.2 深度学习框架选择与使用
目前,有许多成熟的深度学习框架可供选择,如TensorFlow、PyTorch、Keras等。这些框架有着不同的优劣之处,用户可以根据项目需求、团队熟悉程度和性能等因素进行选择。
使用这些框架时,通常涉及以下步骤:模型构建、数据准备、训练过程、模型评估和模型部署。以下是一个模型构建和训练的简化流程:
# 模型构建和训练的简化流程示例
import tensorflow as tf
# 构建模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(input_dim,)),
tf.keras.layers.Dense(num_classes, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(train_data, train_labels, epochs=10)
# 评估模型
test_loss, test_acc = model.evaluate(test_data, test_labels)
在这个例子中,我们首先构建了一个简单的全连接神经网络模型,然后编译该模型并使用训练数据进行训练。训练完成后,我们使用测试数据对模型进行了评估。在选择框架和进行模型训练时,合理的选择和调参是获得高性能模型的关键。
3. 词嵌入技术详解
3.1 词嵌入的基本概念
3.1.1 词嵌入的起源与必要性
词嵌入技术是一种将单词表示为实数向量的方法。这些向量捕捉单词之间的语义关系,并且能够以数学的方式表示单词的含义。在自然语言处理中,词嵌入已经成为了至关重要的预处理步骤,因为它提供了一种在多维空间中计算词语相关性的能力。
词嵌入起源于早期的one-hot编码,这是一种简单的单词表示方法,每个单词对应一个很长的向量,该向量在单词对应的索引位置为1,其他位置为0。然而,这种表示方法不能有效地表达单词之间的关系,因此随着深度学习的发展,词嵌入技术应运而生。
利用深度学习技术,我们可以训练出一个模型来学习词嵌入,这些嵌入是连续的向量,并且可以捕捉到复杂的语言特征。一个著名的词嵌入模型是Word2Vec,它通过预测一个词在文本中的上下文或通过预测上下文中的词来学习这些向量。
3.1.2 词嵌入技术的演进
自词嵌入技术诞生以来,它经历了不断的演变和发展。起初,Word2Vec和GloVe等模型在词嵌入领域占据了主导地位,它们通过大规模的文本数据学习到了单词的分布式表示。随着研究的深入,模型开始更加注重上下文信息的捕捉,FastText模型应运而生,它通过考虑单词的内部结构来提高嵌入的质量。
FastText将每个单词表示为子词单元(如前缀和后缀)的集合,这有助于模型更好地处理词形变化和未登录词。此外,随着预训练语言模型的流行,如BERT和GPT系列,词嵌入进一步融入了深度上下文化的表示中,使得词嵌入技术更加成熟和精细。
3.2 词嵌入模型的实现与应用
3.2.1 Word2Vec模型详解
Word2Vec模型是最著名的词嵌入模型之一,它基于一个简单的神经网络架构来训练词嵌入。Word2Vec有两种主要的训练架构:CBOW(Continuous Bag of Words)和Skip-gram。CBOW模型通过给定上下文来预测目标词,而Skip-gram模型则是通过目标词来预测上下文。
在CBOW中,上下文单词的嵌入被平均化并输入到一个隐藏层,接着是一个输出层,输出层尝试预测目标词。模型训练的目标是最大化给定上下文时目标词出现的概率。
下面是一个简单的CBOW模型的伪代码示例:
# CBOW模型伪代码
context = [get_context_words_for_target(target)]
context_vector = average(context) # 对上下文单词的向量求平均
output_vector = cbow_model(context_vector) # 经过隐藏层和输出层
target_vector = embedding_matrix[target]
loss = calculate_loss(output_vector, target_vector) # 计算损失函数
backpropagate(loss) # 反向传播更新权重
在训练过程中,通过大量这样的迭代,模型逐渐学习到每个单词的分布式表示。这些向量可以捕捉到词义和句法之间的关系,并且可以用于各种下游NLP任务。
3.2.2 GloVe模型详解
GloVe模型是另一种流行的词嵌入方法,它通过构建一个全局单词-单词共现矩阵来学习词嵌入。与Word2Vec不同,GloVe模型利用了单词共现的统计信息,这个矩阵是一个反映单词间共现次数的矩阵。
GloVe模型的训练过程涉及最小化嵌入向量与共现矩阵之间的差异。这种方法认为,通过统计的手段可以更好地学习到单词间的语义关系。一个单词的嵌入可以看作是对它的共现单词的预测,因此,共现信息可以提供关于单词含义的有用线索。
下面是GloVe模型的训练伪代码:
# GloVe模型伪代码
for target, context in training_data:
target_vector = embedding_matrix[target]
context_vector = embedding_matrix[context]
numerator = target_vector * context_vector.T # 分子计算
denominator = sum(embedding_matrix[k] * context_vector.T for k in context) # 分母计算
# 对分子和分母进行指数运算并计算损失
loss = log(numerator / denominator)
backpropagate(loss) # 反向传播更新权重
GloVe模型在许多NLP任务上都展现出了优秀的表现,并且它的词嵌入是上下文无关的,这意味着它不依赖于上下文来表示词义。
3.2.3 FastText模型详解
FastText是由Facebook开发的,旨在改进传统词嵌入方法的一些限制。与Word2Vec不同,FastText不是将文本作为单词序列来处理,而是将文本视为字符n-gram序列。这种方法的优点是,它能够处理生词(Out-Of-Vocabulary, OOV)问题,并且在捕捉词形变化方面表现得更好。
FastText在表示一个单词时,会将其分解为所有的子词单元,并将这些子词单元的嵌入向量进行平均或加权平均来得到最终的单词嵌入。这样的表示能够更精确地表达单词的意思,尤其是对于形态丰富的语言。
下面是一个使用FastText进行单词嵌入的伪代码:
# FastText模型伪代码
for word in vocabulary:
for n in range(min_n, max_n+1): # n为n-gram的大小
n_grams = generate_n_grams(word, n)
for gram in n_grams:
gram_vector = embedding_matrix[gram]
# 可以选择平均或加权平均等方式来聚合n-grams的向量
word_vector += gram_vector
word_vector /= len(n_grams) # 归一化处理
通过捕捉单词的内部结构,FastText模型能够提供更加丰富和细致的单词表示,这在许多NLP任务中都是非常有用的。
以上内容涵盖了词嵌入技术的基本概念和发展历程,并展示了三种流行的词嵌入模型:Word2Vec、GloVe和FastText。每一模型都有其独特的优势和适用场景,研究者和从业者可以根据具体任务的需求来选择最合适的模型。词嵌入技术作为NLP的基础技术之一,其在未来的发展和优化将对整个领域产生深远的影响。
4. 循环神经网络及变种
4.1 RNN的基本原理
4.1.1 RNN结构与工作方式
循环神经网络(Recurrent Neural Network,RNN)是一种专门处理序列数据的神经网络结构。不同于传统的全连接神经网络或卷积神经网络,RNN在设计上能够利用自身的记忆功能,将前一时刻的输出作为当前时刻输入的一部分,从而对序列数据进行建模。这种结构特别适合处理文本、语音、时间序列等数据。
RNN的工作方式可以类比为人的记忆过程。假想一个句子:“我吃了一个苹果。”在理解这句话时,我们的大脑会记住“吃”的动作发生在“苹果”之前,并且理解“我”是这句话的主语。类似地,RNN通过隐藏层状态(即记忆)来保存之前信息,并在处理序列中的每一个元素时使用这些记忆。
RNN的结构图示例如下:
graph LR
A[输入x(t)] -->|x(t)| B[RNN单元]
B --> C[隐藏状态h(t)]
C -->|h(t)| D[输出y(t)]
E[输入x(t+1)] -->|x(t+1)| B
在上图中,$x(t)$ 表示时间步 $t$ 的输入,$h(t)$ 表示时间步 $t$ 的隐藏状态,$y(t)$ 表示时间步 $t$ 的输出。RNN在每个时间步都会接收新的输入,并根据当前输入和之前隐藏状态计算出新的隐藏状态。
4.1.2 时间序列数据处理能力
RNN最突出的能力是处理时间序列数据。时间序列数据是指随时间变化的数据,例如股票价格、天气记录、语音信号等。这类数据的关键特点是数据点之间存在时间依赖性,即当前的数据点可能依赖于之前的数据点。
RNN利用其隐藏状态对这些依赖进行建模。在理论上,RNN可以捕获任意长度的序列依赖。但在实践中,由于梯度消失或梯度爆炸的问题,标准的RNN难以学习长距离的依赖关系。这是因为在反向传播过程中,随着时间步的增加,梯度要么迅速衰减至零,要么指数级增长,导致训练过程变得极其不稳定。
为了解决这一问题,RNN的变种如长短时记忆网络(LSTM)和门控循环单元(GRU)被提出,它们通过引入门控机制来调节信息的流动,从而能够有效地处理长期依赖。
4.2 RNN变种及优化策略
4.2.1 LSTM与GRU模型对比
长短期记忆网络(Long Short-Term Memory,LSTM)和门控循环单元(Gated Recurrent Unit,GRU)是两种改进型的RNN,它们都通过特殊的门控机制来解决标准RNN难以处理长距离依赖的问题。
LSTM的结构包含了三个门:
- 遗忘门:决定哪些信息应该从单元状态中丢弃。
- 输入门:决定哪些新信息应该存储在单元状态中。
- 输出门:决定下一个隐藏状态的输出。
GRU是LSTM的一种简化版本 ,它将遗忘门和输入门合并为一个更新门,并将单元状态和隐藏状态合并为一个状态。GRU的结构较为简单,需要调整的参数较少,因此在某些情况下能够更快速地训练。
在实际应用中,LSTM和GRU各有优势。通常需要通过实验来确定使用哪种模型会取得更好的结果。LSTM在处理复杂的长序列数据时表现更优,而GRU在数据量较少或者计算资源有限的情况下可能是更好的选择。
下面是一个LSTM单元的代码实现,包含遗忘门、输入门和输出门的工作逻辑:
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def lstm_cell(xt, ht_1, ct_1, Wf, Wb, Wc, Wp):
ft = sigmoid(np.dot(Wf, np.concatenate([ht_1, xt])))
it = sigmoid(np.dot(Wi, np.concatenate([ht_1, xt])))
ct = ft * ct_1 + it * np.tanh(np.dot(Wc, np.concatenate([ht_1, xt])))
ot = sigmoid(np.dot(Wo, np.concatenate([ht_1, xt])))
ht = ot * np.tanh(ct)
return ht, ct
# 假设的前一时刻状态
ht_1 = np.zeros((1, hidden_size))
ct_1 = np.zeros((1, hidden_size))
# 当前时刻的输入
xt = np.random.randn(1, input_size)
# 权重矩阵
Wf, Wi, Wc, Wo = np.random.randn(4, hidden_size, input_size + hidden_size)
# LSTM单元的执行
ht, ct = lstm_cell(xt, ht_1, ct_1, Wf, Wi, Wc, Wo)
在这个代码中, lstm_cell 函数展示了LSTM单元的单步计算过程。 sigmoid 函数用于计算门控的激活值,而 np.tanh 用于计算输出和新状态。
4.2.2 双向RNN和注意力机制的结合
双向RNN(Bi-directional RNN,Bi-RNN)是一种能够同时利用序列过去和未来信息的循环神经网络。在标准的RNN中,每个时间步的输出只依赖于过去的信息。而Bi-RNN通过添加一个反向的RNN来弥补这一不足,使得网络在每个时间步都能够同时看到过去和未来的上下文信息。
具体地,Bi-RNN由两个并行的RNN组成,一个向前正向处理序列(从第一个时间步到最后一个时间步),另一个则向后反向处理序列(从最后一个时间步到第一个时间步)。然后将两个RNN在每个时间步的隐藏状态拼接起来,作为最终的输出。
然而,Bi-RNN仍然有一个限制:它在处理时间步t时,依然只能够使用到时间步t的固定上下文。因此,注意力机制被引入到RNN中,以提高模型捕捉重要信息的能力。
注意力机制(Attention Mechanism)允许模型在处理每个时间步时动态地关注序列中的不同部分,而不是简单地依赖于固定窗口内的上下文。注意力机制的一个核心思想是为序列中每个元素分配一个“注意力权重”,代表其对当前处理步骤的重要性。
以下是注意力机制在RNN中的一个简化的伪代码示例:
def attention_weights(prev_hidden_state, encoder_outputs):
attention_scores = np.dot(prev_hidden_state, encoder_outputs.T)
attention_weights = softmax(attention_scores)
return attention_weights
def context_vector(attention_weights, encoder_outputs):
context_vector = np.dot(attention_weights, encoder_outputs)
return context_vector
# 假定 encoder_outputs 是编码器输出的所有隐藏状态
# prev_hidden_state 是前一时间步的隐藏状态
attention_weights = attention_weights(ht, encoder_outputs)
context_vector = context_vector(attention_weights, encoder_outputs)
在这段代码中, attention_weights 函数计算每个时间步的注意力权重,而 context_vector 函数计算基于这些权重的上下文向量。 softmax 是一个常用的激活函数,用来将加权分数转换为概率分布,代表注意力权重。
注意力机制不仅可以应用于RNN,还广泛地用于Transformer模型,这在后面的章节中会有详细介绍。通过结合双向RNN和注意力机制,模型能够对输入序列有更深入的理解,显著提升在NLP任务上的表现。
5. 注意力机制原理
在深度学习和自然语言处理(NLP)领域,注意力机制已经成为一种核心的组成部分,特别是在处理具有长距离依赖关系的问题时,它能够显著提高模型的性能。注意力机制允许模型在预测的每一步对输入序列的不同部分给予不同程度的“注意力”,从而捕捉关键信息并抑制不相关的部分。本章将深入探讨注意力机制的起源、理论基础、实现方法和在NLP中的应用案例。
5.1 注意力机制的概念与发展
5.1.1 注意力机制的起源
注意力机制的概念最初来源于人类视觉注意力的研究,后来被引入到机器学习领域,尤其是在机器翻译任务中。它模仿了人类在处理视觉或语言信息时的集中注意力的行为。在NLP中,注意力机制允许模型动态地关注输入序列中相关的单词或短语,而不需要固定长度的窗口或预定义的规则,使得模型可以更加灵活和高效地处理文本数据。
5.1.2 注意力机制的理论基础
从理论上讲,注意力机制是一种方式,用于在给定的上下文中对输入信息进行加权。在序列到序列(seq2seq)模型中,注意力机制通过一个权重矩阵来计算源序列和目标序列之间的对齐关系。权重的计算依赖于序列中每个元素与当前生成步骤的相关性。这种方法与传统的全序列输入的神经网络模型相比,可以更好地处理长距离依赖问题,因为模型可以动态地“记住”重要信息,并在需要时调用这些信息。
5.2 注意力机制的实现与应用
5.2.1 自注意力机制详解
自注意力(self-attention),也称为内部注意力,是注意力机制的一种形式,它直接在序列的不同位置计算权重。自注意力机制通过计算序列中每个元素与其他所有元素之间的相似度来确定权重。然后,这些权重用于创建一个新的表示,该表示融合了整个序列的信息。
自注意力机制的关键在于它的计算效率和并行化能力。不同于循环神经网络(RNN)或长短期记忆网络(LSTM)在时间步上逐步处理信息,自注意力允许同时处理序列中的所有元素,显著提高了训练速度和效率。
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# Split the embedding into self.heads different pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Einsum does matrix multiplication for query*keys for each training example
# with every other training example, don't be confused by einsum
# it's just a way to do matrix multiplication with the last two dimensions
# and broadcasted over the batch size and heads
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return out
上述代码展示了自注意力机制的一个简单实现。自注意力层接受四个参数:values(值)、keys(键)、queries(查询)和mask(可选的掩码),并返回自注意力的输出。掩码用于遮蔽序列中不应该关注的某些部分,这在处理变长序列时特别有用。
5.2.2 注意力在NLP中的应用案例
注意力机制广泛应用于多种NLP任务中,包括文本摘要、问答系统、机器翻译和情感分析等。在这些任务中,注意力机制能够帮助模型理解句子中的关键部分,从而提供更准确的预测和生成。
以机器翻译为例,注意力机制允许翻译模型在生成每个词时关注输入句子的不同部分。例如,在将英文翻译成法文时,模型可以专注于与当前生成的法文词相对应的英文词汇。这种方法与传统的基于规则或短语的翻译方法相比,能够提供更自然、更流畅的翻译结果。
通过本章节的介绍,我们可以看到注意力机制在深度学习和NLP中的重要性以及它如何促进了模型的发展。下一章节将深入探讨Transformer模型的架构,这是一种完全基于自注意力机制构建的模型,已经彻底改变了NLP领域。
6. Transformer模型架构
Transformer模型自2017年被提出以来,就因其在自然语言处理(NLP)领域的出色表现而成为了研究热点。它解决了传统序列模型难以并行计算的问题,并引入了多头注意力机制,极大地提升了模型处理长序列文本的能力。本章节将探讨Transformer模型的诞生和深入解析其架构。
6.1 Transformer模型的诞生
6.1.1 传统序列模型的局限性
在Transformer模型出现之前,RNN(循环神经网络)及其变种LSTM(长短时记忆网络)和GRU(门控循环单元)是处理序列数据的主流方法。这些模型能够捕捉序列中的时间依赖性,但在训练长序列时存在梯度消失或爆炸的问题,并且难以并行处理,导致训练效率低下。
6.1.2 Transformer模型创新点
为了解决这些问题,Transformer模型摒弃了传统循环结构,采用基于注意力机制的自注意力(self-attention)来处理序列信息。Transformer通过自注意力机制同时处理序列中所有位置的信息,这不仅大大提高了并行处理的能力,而且使得模型能够更加有效地捕捉长距离的依赖关系。
6.2 Transformer模型深入解析
6.2.1 编码器和解码器结构
Transformer模型由编码器(Encoder)和解码器(Decoder)两部分组成。编码器负责处理输入序列,解码器则用于生成输出序列。每个编码器和解码器都包含多个相同结构的层,这些层通过堆叠来增强模型的表达能力。
6.2.2 多头注意力机制详解
Transformer的核心组件是多头注意力机制。它将输入序列分割成多个子序列,并在每个子序列上并行地计算自注意力,然后将这些注意力头的结果拼接起来,通过一个线性层进行输出。多头注意力机制的引入使模型能够同时关注输入序列的不同位置,增强了模型捕捉复杂模式的能力。
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(q, k, v, mask=None):
"""
计算缩放点积注意力
q: 查询向量
k: 键向量
v: 值向量
mask: 遮蔽张量,用于防止注意力被分配给某些位置
"""
d_k = q.size(-1)
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention = F.softmax(scores, dim=-1)
output = torch.matmul(attention, v)
return output, attention
在上述代码块中,我们定义了一个函数来计算缩放点积注意力。参数 q , k , v 分别是查询、键和值的向量。函数内部首先计算查询和键向量的点积,然后进行缩放,接着应用一个掩码来防止某些位置的信息被处理,最终通过softmax函数得到注意力权重,并将其应用于值向量来获取输出。
多头注意力机制是Transformer模型的核心优势之一,其允许模型在不同的表示子空间学习到不同的信息,并且在多个头之间并行化计算,这显著提高了模型的效率和性能。
Transformer模型架构的进一步拓展
Transformer模型的架构除了提供高效的并行计算机制外,还具有很好的扩展性。我们可以增加模型的深度(即层数),也可以通过调整多头注意力机制中头的数量来控制模型的宽度,以此来提升模型的能力以适应不同的任务需求。
在实际应用中,Transformer的架构经过了多次优化和改进,如加入位置编码来处理序列中元素的顺序信息,应用层标准化(Layer Normalization)来稳定训练过程等。这些改进使得Transformer模型在机器翻译、文本摘要、问答系统等NLP任务中取得了前所未有的成绩。
在本章中,我们已经探讨了Transformer模型的诞生背景、其架构的核心组件及其深入解析。在下一章节中,我们将进一步探索预训练模型的出现,如BERT及其变种,并通过实际案例分析NLP的应用实例。
7. 预训练模型与NLP应用实例
预训练模型已成为自然语言处理(NLP)领域的核心技术之一。这种模型通过在大量文本数据上进行预训练,学习语言的通用表示,然后在特定的下游任务上进行微调(fine-tuning),显著提高了NLP任务的性能。
7.1 预训练模型的概念与优势
7.1.1 预训练模型的发展背景
在深度学习技术成熟之前,基于规则和统计的NLP方法通常需要大量的手工特征工程。预训练模型的出现,尤其是在深度学习框架中,极大地改变了这一局面。通过在大规模语料上进行预训练,模型可以自动捕捉到语言的深层次特征,减少了对专业领域知识的依赖。
7.1.2 预训练模型的关键技术
预训练模型的关键技术之一是大规模语料库的构建,这些语料库需要覆盖广泛的语言现象。其次,预训练过程中使用的算法,如BERT、GPT、ELMo等,通常采用掩码语言模型(Masked Language Model, MLM)或者下一个句子预测(Next Sentence Prediction, NSP)任务来预训练模型。这种预训练方法能够引导模型学习到丰富的词汇和句子层面的表征。
7.2 BERT及其变种模型介绍
7.2.1 BERT模型详解
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer的预训练模型,由Google在2018年提出。BERT的一个主要创新是采用了双向Transformer作为其编码器,这允许模型同时考虑左边和右边的上下文信息。BERT在预训练时使用了MLM和NSP两个任务,这使得模型在微调阶段能更好地适用于多种NLP任务。
7.2.2 BERT模型在NLP任务中的应用实例
BERT模型一经推出,就在多种NLP基准测试中取得了新的SOTA(State of the Art)成绩。其应用实例包括文本分类、问答系统、命名实体识别等。BERT通过微调可以有效地适应不同的下游任务,显著提高了这些任务的性能。
7.3 NLP应用实例与案例分析
7.3.1 机器翻译任务实战
预训练模型在机器翻译任务中也有出色表现。通过在大量的平行语料上预训练,模型能够学习到跨语言的语义和语法结构,进而在翻译任务中实现更准确的语言转换。BERT和其他预训练模型可以联合神经机器翻译(NMT)系统使用,通过fine-tuning提升翻译质量。
7.3.2 情感分析案例研究
情感分析是判断文本情感倾向的任务,包括正面、负面、中立等类别。借助预训练模型,可以构建高性能的情感分析系统。这些模型能够捕捉到文本中的微妙情感差异,并在不同领域的情感分析任务中灵活调整。
代码块示例
下面是一个简化的BERT模型在情感分析任务上的应用代码示例:
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import Trainer, TrainingArguments
# 初始化分词器和预训练模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# 编码输入文本
inputs = tokenizer('I love this product!', 'This is a bad product.', return_tensors='pt', padding=True, truncation=True)
# 前向传播得到预测结果
outputs = model(**inputs)
predictions = outputs.logits.argmax(-1)
# 实例化训练参数
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
)
# 定义训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset
)
# 训练模型
trainer.train()
这段代码展示了如何使用Hugging Face的 transformers 库来加载BERT预训练模型,并在情感分析任务上进行微调。代码中省略了数据准备部分,但实际应用中需要创建训练集和验证集。
在本章中,我们详细了解了预训练模型的概念、优势,以及BERT模型的核心技术和应用实例。第七章的后半部分还深入探讨了预训练模型在机器翻译和情感分析等NLP应用中的实战案例。借助预训练模型,NLP领域已实现了跨时代的进步,同时也为未来的创新奠定了坚实的基础。
简介:斯坦福大学的CS224n课程深入探讨了自然语言处理(NLP)和深度学习技术,包括文本预处理、循环神经网络、长短时记忆网络、Transformer模型、BERT等预训练方法。通过系统的笔记整理,学生可以掌握从基础到高级的NLP技术,以及在情感分析、机器翻译等实际问题中的应用。本课程内容覆盖了自然语言处理的基础知识、深度学习原理、词嵌入技术、注意力机制、Transformer模型、预训练模型、应用实例以及最新的NLP研究进展。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)