解析transformer——1: Embedding层
本文解析了Transformer中的Embedding层,介绍了三种自然语言表示方法:同义词字典、基于计数的方式和基于推理的Embedding。重点讨论了Transformer中Input/Output Embedding层的实现,包括参数矩阵E的共享和乘以√d_model的操作。最后提供了基于PyTorch的Embedding层实现代码,展示了如何继承nn.Embedding类并添加√d_mod
·
解析transformer——1: Embedding层
1. 表示自然语言(token)方式
为了表示自然语言,出现过下面3种方式。
- 同义词字典
- 基于计数的方式
- 基于推理的方式(embedding)
同义词字典:人工将同一类的词归为一类,可以利用图结构来表达局部与整体等关系。
基于计数的方式: 基于分布式假设(某个单词的含义是由它周围单词形成),对于语料库you say goodbye and i say hello .
在设定窗口为1的情况下,可以得到统计结果:
| you | say | goodbye | and | i | hello | . | |
|---|---|---|---|---|---|---|---|
| say | 1 | 0 | 1 | 0 | 1 | 1 | 0 |
统计结果即为token的向量表示,say的向量表示为[1,0,1,0,1,1,0]
基于推理方式(embedding): 基于分布式假设,可以通过语料库的小部分进行训练获得token的向量表示。
参考资料:深度学习进阶: 自然语言处理 第2,3章
2. transformer的embedding层
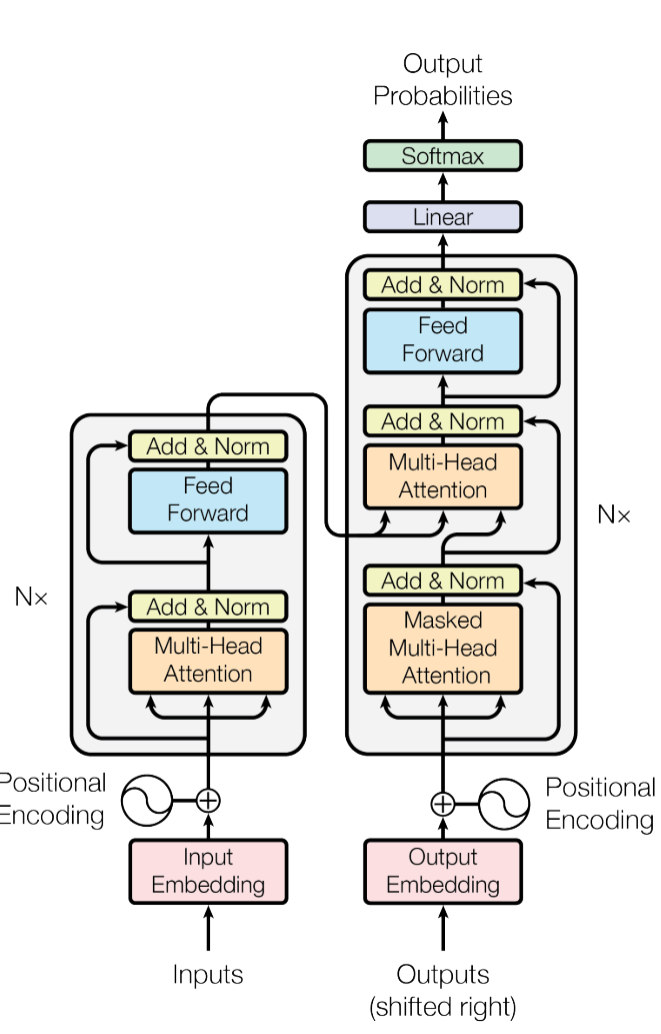
- embedding层出现在2个位置: input Embedding, Output Embedding,设其参数矩阵为E, 矩阵大小 vocab_size * dmodeld_{model}dmodel
- embedding层中,还需要乘以参数dmodel\sqrt{d_{model}}dmodel 即E[token_id] * dmodel\sqrt{d_{model}}dmodel
- inut_Embedding, Output_Embedding共享参数矩阵E, Linear层使用矩阵ETE^{T}ET
3. 代码实现
利用pytorch实现的embedding封装实现。
import torch.nn as nn
import torch.nn.functional as F
import torch
vocab_size = 10
d_model = 3
device = 'cuda' if torch.cuda.is_available() else 'cpu'
is_test = True
class MyEmbedding(nn.Embedding):
def __init__(self, num_embeddings, embedding_dim, device):
self.num_embeddings = num_embeddings
self.embedding_dim = embedding_dim
self.device = device
super().__init__(self.num_embeddings, self.embedding_dim, device=device)
def forward(self, input_ids):
return super().forward(input_ids) * torch.sqrt(torch.tensor(self.embedding_dim).to(device))
embedding = MyEmbedding(num_embeddings=vocab_size, embedding_dim=d_model, device=device)
if is_test:
output = embedding(torch.tensor([1], dtype=torch.long).to(device))
print(output)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)