DeepSeek 演进历程(2023.11 — 2025.12)
摘要: DeepSeek(深度求索)从2023年至今完成了从追赶者到AGI领跑者的蜕变,其发展分为五个阶段: V1阶段(2023-2024初):聚焦代码与数学能力,以DeepSeek Coder V1在开发者圈层引爆,击败千亿参数模型。 V2阶段(2024年中):通过MLA(多头潜在注意力)和MoE架构实现极致成本优势,发动“价格战”成为企业首选。 V3阶段(2024年底):采用FP8训练和MTP
站在 2025年12月5日 回望,DeepSeek(深度求索)的发展历程不仅仅是一家中国 AI 公司的成长史,更是一部“以极致算法效率对抗算力暴力”的教科书。从早期的追随者到如今定义 AGI 推理路线的领跑者,DeepSeek 用五个关键代际完成了从“追赶”到“超越”的华丽转身。
以下是其技术演进与市场爆发的完整复盘。
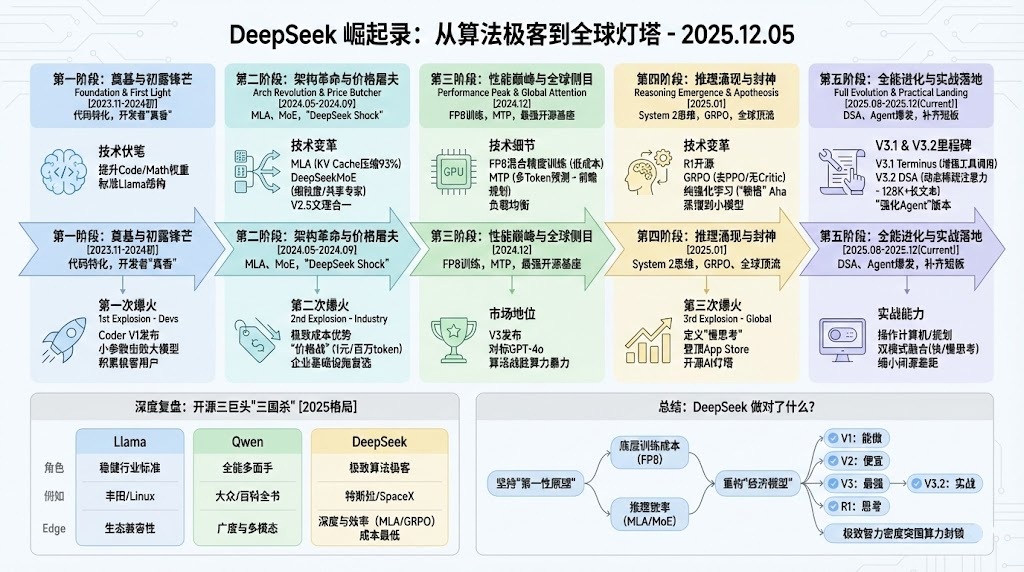
第一阶段:奠基与初露锋芒 (V1 & Coder)
时间:2023年11月 - 2024年初
关键词:代码特化、开发者圈层的“真香”时刻
在 DeepSeek 刚入局时,开源世界还是 Llama 2 的天下。DeepSeek V1 在架构上并没有进行激进魔改,主要沿用了标准的 Llama 结构(Dense Transformer)。但团队敏锐地抓住了一个核心策略:在预训练语料中大幅提升代码(Code)和数学(Math)的权重。
-
技术伏笔:这种数据配比不仅为了刷榜,更因为代码和数学是提升模型逻辑推理能力的基石。
-
第一次爆火(开发者圈):当 DeepSeek Coder V1 发布时,它成为了第一个引爆点。凭借仅 6.7B/33B 的参数量,它在代码生成任务上击败了许多千亿参数模型,甚至逼近 GPT-4。
-
市场反响:程序员群体率先抛弃 Copilot 转向 DeepSeek,GitHub 和 Hugging Face 下载量激增。这为 DeepSeek 积累了第一批死忠“极客”用户。
第二阶段:架构革命与价格屠夫 (V2 & V2.5)
时间:2024年5月 - 2024年9月
关键词:MLA、MoE、行业圈的“DeepSeek Shock”
如果说 V1 证明了“能做”,V2 则证明了“能做得极度便宜”。这一阶段,DeepSeek 从堆参数转向了拼架构,确立了其“效率至上”的路线。
-
技术变革(里程碑级):
-
MLA (多头潜在注意力):针对大模型推理显存瓶颈(KV Cache),首创 MLA 技术,通过低秩矩阵分解将 KV Cache 压缩了 93%。
-
DeepSeekMoE (混合专家):引入“细粒度专家”和“共享专家”机制,解决了 MoE 模型知识碎片化的问题,在保持高性能的同时大幅降低计算量。
-
-
第二次爆火(行业圈):得益于架构带来的极致成本优势,DeepSeek 发动了震惊行业的“价格战”。百万 token 仅需 1 元人民币的定价,被行业称为“DeepSeek Shock”。这迫使阿里云(Qwen)和百度跟进降价,DeepSeek 从此成为企业接入 AI 的基础设施首选。
-
V2.5 的统一:9月,V2.5 实现了“文理合一”,结束了通用模型与代码模型左右互搏的局面。
第三阶段:性能巅峰与全球侧目 (V3)
时间:2024年12月
关键词:FP8 训练、MTP、最强开源基座
在算力受限(如 H800 禁令)的背景下,DeepSeek V3 的出现被美国科技圈视为“奇迹”。它证明了算法优化可以战胜硬件堆叠。
-
技术细节:
-
FP8 混合精度训练:在 671B 超大模型上全程使用 FP8 训练,将训练成本压缩至惊人的 278 万 GPU 小时(约 600 万美元),远低于美国同行。
-
MTP (多 Token 预测):打破传统,让模型一次预测后续多个 Token,强迫模型进行“前瞻性规划”,大幅提升逻辑连贯性与训练效率。
-
负载均衡:解决了 MoE 训练中专家负载不均的难题(Auxiliary-loss-free)。
-
-
市场地位:V3 综合性能对标 GPT-4o,成为当时最强的开源基座。
第四阶段:推理涌现与封神 (R1)
时间:2025年1月
关键词:System 2 思维、GRPO、全球顶流
这是 DeepSeek 真正的巅峰时刻。当 OpenAI 对 o1 模型的推理细节遮遮掩掩时,DeepSeek 直接开源了 R1,定义了“慢思考”的技术标准。
-
技术变革:
-
GRPO (Group Relative Policy Optimization):摒弃了昂贵的 PPO 算法(无需 Critic 模型),通过分组相对优劣比较来优化策略,大幅降低强化学习资源消耗。
-
纯强化学习 (Pure RL / R1-Zero):证明了无需人类标注,仅靠规则奖励(如数学对错),模型就能通过“顿悟”(Aha Moment)自主演化出反思与纠错能力。
-
蒸馏 (Distillation):将 R1 的超级大脑“传授”给小模型,让 7B/8B 模型也具备了越级的逻辑能力。
-
-
第三次爆火(全球公众):DeepSeek APP 登顶美国 App Store,股价波动波及英伟达。它不再只是“中国模型”,而是变成了“开源 AI 的灯塔”。
第五阶段:全能进化与实战落地 (V3.1 - V3.2)
时间:2025年8月 - 2025年12月(当前)
关键词:DSA、Agent 爆发、补齐短板
为了解决“逻辑强但工具弱”的问题,最新的 V3.2 版本专注于实战与长文本。
-
V3.1 (Terminus):8月发布,重点修补了中英混合输出问题,并大幅增强了 Function Calling(工具调用)能力。
-
V3.2 (最新里程碑 - 2025.12.01):
-
DSA (DeepSeek Sparse Attention):引入动态稀疏注意力机制,不再关注所有历史信息,而是动态筛选重要信息。这使得模型在处理 128K+ 超长文本时,计算量大幅下降且精度不减。
-
Agent 能力爆发:V3.2 被定义为“强化 Agent”版本。在操作计算机、多步任务规划等复杂评测中,它大幅缩小了与闭源模型(如最新的 Gemini 3.0 Pro)的差距。
-
双模式融合:完美融合了“快思考”(Chat)和“慢思考”(Reasoning),让用户可以自如控制思考深度。
-
深度复盘:开源三巨头的“三国杀”
在 2025 年的格局中,Meta 的 Llama、阿里的 Qwen 和 幻方的 DeepSeek 形成了差异明显的“三足鼎立”:
| 模型系列 | Llama (Meta) | Qwen (Alibaba) | DeepSeek (High-Flyer) |
| 角色定位 | 稳健的行业标准 | 全能的多面手 | 极致的算法极客 |
| 类比 | 丰田 / Linux | 大众 / 百科全书 | 特斯拉 / SpaceX |
| 核心优势 | 生态兼容性。所有工具(vLLM, LoRA)第一时间适配,虽然笨重但最稳。 | 广度与多模态。从视觉到音频全覆盖,长文本积累深厚,像个博学家。 | 深度与效率。专注于代码、数学和逻辑。架构最激进(MLA/GRPO),成本最低。 |
| 护城河 | 全球开发者习惯 | 丰富的业务场景落地 | “比你聪明,还比你便宜 10 倍” |
总结:DeepSeek 做对了什么?
DeepSeek 的成功在于坚持了“第一性原理”。
它没有盲目跟随硅谷堆砌算力,而是从底层的训练成本(FP8)和推理效率(MLA/MoE)入手,彻底重构了模型的“经济模型”。
-
V1 证明了能做。
-
V2 证明了能做得便宜(MLA)。
-
V3 证明了能做得最强(FP8/MTP)。
-
R1 证明了能思考(GRPO)。
-
V3.2 证明了能实战(DSA/Agent)。
这就是 DeepSeek 截止目前的故事——一个关于在资源受限环境下,通过极致的智力密度(算法创新)突围算力封锁的传奇。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)