OpenCV图像预处理(二)
一、图像的翻转与变换
1.图像翻转
opencv中,图像的翻转为镜像旋转,以图像的中心为原点。
语法:
img = cv.flip(img, flipcode)
-
flipcode == 0 垂直翻转 沿x轴 上下翻转
-
flipcode == 1 水平翻转 沿y轴,左右翻转
-
flipcode == -1 水平+垂直翻转
2.图像的仿射变换
任何图像的仿射变换都是建立在点的变换基础上,所以说只要懂了每个点是怎么变的,也就搞懂了图形的变换。
假设一个点原点坐标为(x0,y0),变换后坐标为(x,y)
[xy1]=[cosθ −sinθ (1−cosθ)tx+ty∗sinθsinθ cosθ (1−cosθ)ty+tx∗sinθ0 0 1]∗[x0y01] \begin{array}{l l l}{{\left[\begin{array}{c}{{x}}\\{{y}}\\{1} \end{array}\right]=\left[\begin{array}{l l l}{{\cos\theta~~-\sin\theta~~(1-\cos\theta)t_{x}+t_{y}*\sin\theta}}\\{{\sin\theta~~~\cos\theta~~~~~(1-\cos\theta)t_{y}+t_{x}*\sin\theta}}\\{{0~~~~~~~~~~~~~0~~~~~~~~~~~~~1}} \end{array}\right]*\left[\begin{array}{c}{{x_{0}}}\\{{y_{0}}}\\{{1}}\end{array}\right]}}\end{array}
xy1
=
cosθ −sinθ (1−cosθ)tx+ty∗sinθsinθ cosθ (1−cosθ)ty+tx∗sinθ0 0 1
∗
x0y01
其中θ是点旋转的角度,(1−cosθ)tx+ty∗sinθ(1-\cos\theta)t_{x}+t_{y}*\sin\theta(1−cosθ)tx+ty∗sinθ 是x0平移的距离,(1−cosθ)ty+tx∗sinθ(1-\cos\theta)t_{y}+t_{x}*\sin\theta(1−cosθ)ty+tx∗sinθ是y0平移的距离。
矩阵
M=[cosθ −sinθ (1−cosθ)tx+ty∗sinθsinθ cosθ (1−cosθ)ty+tx∗sinθ0 0 1] M=\left[\begin{array}{l l l}{{\cos\theta~~-\sin\theta~~(1-\cos\theta)t_{x}+t_{y}*\sin\theta}}\\{{\sin\theta~~~\cos\theta~~~~~(1-\cos\theta)t_{y}+t_{x}*\sin\theta}}\\{{0~~~~~~~~~~~~~0~~~~~~~~~~~~~1}} \end{array}\right] M=
cosθ −sinθ (1−cosθ)tx+ty∗sinθsinθ cosθ (1−cosθ)ty+tx∗sinθ0 0 1
是点(x0,y0)的变换矩阵,当等式两边同时左乘一个M的逆矩阵,就能得到目标图像和原图的关系,即目标图像的每个点反映射到原图上。
对图像做仿射变换,用到的是**cv2.warpAffine()**函数
cv2.warpAffine(img,M,dsize)
img:输入图像,即原图。
M:一个2x3的变换矩阵,类型为np.float32,不同的变换可通过不同方法得到,下面会讲。
dsize:目标图像(即输出图像)的尺寸大小
所以,做图像仿射变换的重点就是获取旋转矩阵M。
1.图像旋转
让图像按照某个指定的点旋转一定的角度
cv2.getRotationMatrix2D()函数
作用 – 获取旋转矩阵M
cv2.getRotationMatrix2D(center,angle,scale)
center:旋转中心点
angle:旋转角度,单位为度,逆时针为正,顺时针为负。
scale:缩放比例
2.图像平移
实现图像平移,其变化矩阵M为: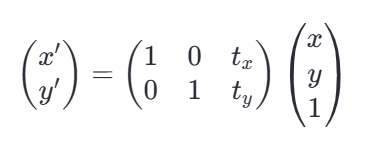
txt_xtx和tyt_yty表示点分别在x方向上和y方向上的平移量
该矩阵M可以通过numpy数组直接定义
import cv2 as cv
import numpy as np
# 仿射变换平移
# 读图
kita = cv.imread("./kita.jpg")
kita = cv.resize(kita,(580, 580))
# 定义平移量
tx = 80
ty = 120
# 定义平移矩阵
M = np.float32([[1, 0, tx],[0, 1, ty]])
# 实现仿射变换
dst = cv.warpAffine(kita, M, (580, 580))
cv.imshow("dst", dst)
cv.waitKey(0)
cv.destroyAllWindows()
3.图像缩放
实现图像缩放的变换矩阵M为:
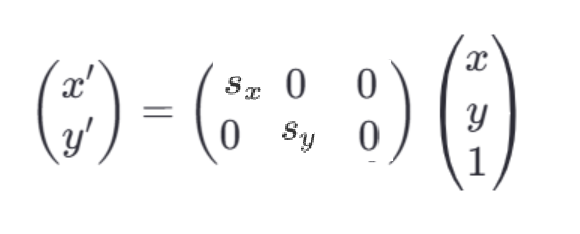
其中sxs_xsx和sys_ysy为缩放因子,代表各个方向上的缩放比例,图像的整体缩放比例sx∗sys_x*s_ysx∗sy
例:
import cv2 as cv
import numpy as np
# 仿射变换缩放
# 读图
kita = cv.imread("./kita.jpg")
kita = cv.resize(kita,(580, 580))
# 定义缩放因子
sx = 0.5
sy = 0.5
# 定义缩放矩阵
M = np.float32([[sx, 0, 0], [0, sy, 0]])
# 实现仿射变换
dst = cv.warpAffine(kita, M, (580, 580))
cv.imshow("dst", dst)
cv.waitKey(0)
cv.destroyAllWindows()
4.图像剪切
剪切操作能够改变图像的形状,即**将一个形状的某一维平移,另一维保持不变,从而使图形倾斜变形,但面积保持不变。**剪切前后的图像面积不变。
在矩阵形式下可表示为:
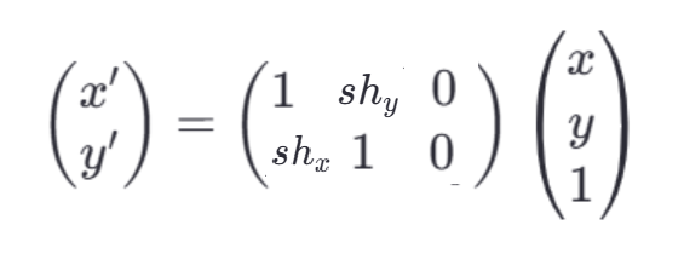
3.图像的插值方法
在上述的图像仿射变换我们可以知道,目标图像的每个像素点会反映射到原图上,插值算法就是用来处理目标图像中每个点的像素值。使用插值算法的目的是为了解决图像缩放或者旋转等操作时,由于像素之间的间隔不一致而导致的信息丢失和图像质量下降的问题。原始图像的某些像素坐标可能不再是新图像中的整数位置,这时就需要使用插值算法来确定这些非整数坐标的像素值。
插值方法作为**cv2.warpAffine()**中的参数使用
1.最近邻值法
最近邻插值法是一种最简单、最快速的图像插值方法。
当图像发生缩放、旋转、仿射变换等几何变换时,需要为新图像中的像素点重新确定像素值,而最近邻法的核心思想是:
让目标图像中某个像素点的值,等于原图中与之最接近的像素点的值。
CV2.INTER_NEAREST
new_img1=cv.warpAffine(img,M,(w,h),flags=cv2.INTER_NEAREST)
2.双线性插值
双线性插值的核心思想就是: 根据这个点周围最近的 4 个像素点的灰度值进行加权平均,权重根据距离决定。
双线性插值可以看作是点分别在x方向和y方向上做了两次插值法,并且这两次插值也是按照距离加权平均。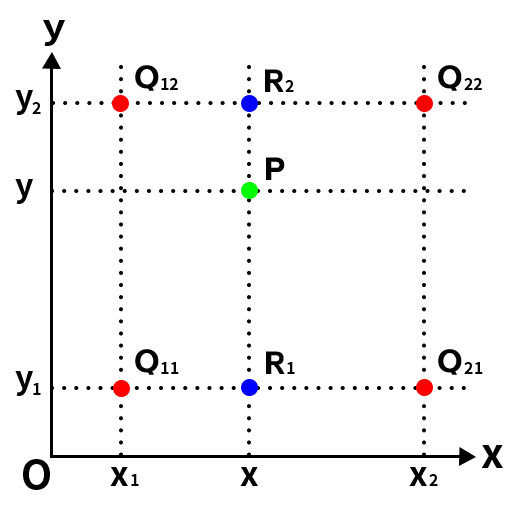
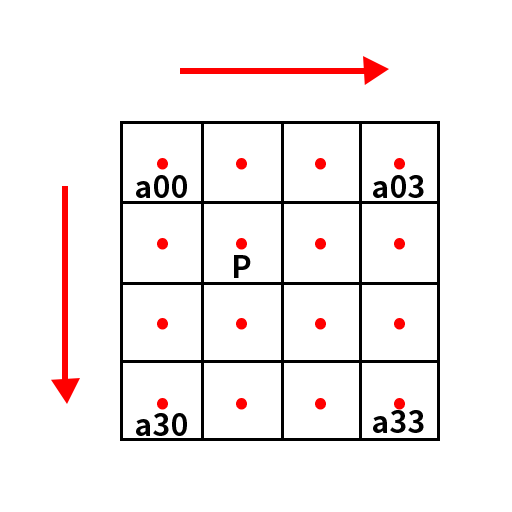
图中P点为目标图像像素点反映射到原图上的点,周围的点分别为Q12、Q22、Q11、Q21, 要插值的P点不在其周围点的连线上,这时候就需要用到双线性插值法。
然后根据Q11、Q21得到R1的插值,根据Q12、Q22得到R2的插值,然后根据R1、R2得到P的插值即可,这就是双线性插值。以下是计算过程:
首先计算R1和R2的插值:
f(R1)≈x2−xx2−x1f(Q11)+x−x1x2−x1f(Q21) f(R_{1})\approx\frac{x_{2}-x}{x_{2}-x_{1}}f(Q_{11})+\frac{x-x_{1}}{x_{2}-x_{1}}f(Q_{21}) f(R1)≈x2−x1x2−xf(Q11)+x2−x1x−x1f(Q21)
f(R2)≈x2−xx2−x1f(Q12)+x−x1x2−x1f(Q22) f(R_{2})\approx\frac{x_{2}-x}{x_{2}-x_{1}}f(Q_{12})+\frac{x-x_{1}}{x_{2}-x_{1}}f(Q_{22}) f(R2)≈x2−x1x2−xf(Q12)+x2−x1x−x1f(Q22)
然后根据R1和R2计算P的插值:
f(P)≈y2−yy2−y1f(R1)+y−y1y2−y1f(R2) f(P)\approx{\frac{y_{2}-y}{y_{2}-y_{1}}}f(R_{1})+{\frac{y-y_{1}}{y_{2}-y_{1}}}f(R_{2}) f(P)≈y2−y1y2−yf(R1)+y2−y1y−y1f(R2)
这样就得到了P点的插值。注意此处如果先在y方向插值、再在x方向插值,其结果与按照上述顺序双线性插值的结果是一样的。这就是双线性插值法的基本原理。
cv2.INTER_LINEAR
new_img1=cv.warpAffine(img,M,(w,h),flags=cv.INTER_LINEAR)
3.像素区域插值法
该方法主要用于对图片缩小的处理,其原理为:**将目标图像中的某个像素反映射回原图时,计算它在原图中所对应的面积区域,然后把这个区域的像素进行平均。**可以想象为:
- 每个目标像素是一个“小方格”
- 看这个方格在原图中覆盖了多少个像素
- 然后对这些被覆盖的像素进行加权平均
- 得到目标像素的值
注意:当图像处理为放大图像时,此时工作原理与缩小不同。
- 如果图像放大的比例是整数倍,那么其工作原理与最近邻插值类似;
- 如果放大的比例不是整数倍,那么就会调用双线性插值进行放大。
cv2.INTER_AREA
new_img1=cv.warpAffine(img,M,(w,h),flags=cv2.INTER_AREA)
4.双三次插值法
与双线性插值法类似,只不过是双线性插值法的plus版,使用的是 16 个邻近像素(4×4 区域) 的加权平均来估算目标像素值的方法,对图像的放大更平滑、更自然,边缘也更锐利。
其核心原理:按两个方向分别插值:
- 横向(x方向):先对每一行做三次插值 → 得到4个中间值
- 纵向(y方向):再对这4个中间值再做一次三次插值 → 得到最终像素值
cv2.INTER_CUBIC
new_img1=cv.warpAffine(img,M,(w,h),flags=cv2.INTER_CUBIC)
5.Lanczos插值
Lanczos插值方法与双三次插值思路一样,不同的是图像的像素点范围变为了8*8,并且不再使用BiCubic函数来计算权重,而是换了一个公式计算权重。这里不再多介绍,想详细了解数学原理可查阅其他文章。
cv2.INTER_LANCZOS4
new_img1=cv.warpAffine(img,M,(w,h),flags=cv2.INTER_LANCZOS4)
各种插值方法总结:
| 方法 | 使用像素数量 | 图像放大效果 | 图像缩小效果 | 运算速度 | OpenCV参数 | 推荐使用场景 |
|---|---|---|---|---|---|---|
| 最近邻插值 | 1 | ❌ 马赛克明显 | ✅ 可接受 | ✅✅✅ 最快 | cv2.INTER_NEAREST |
实时处理、低质量缩放、快速需求 |
| 双线性插值 | 4(2×2) | ✅ 较平滑 | 一般 | ✅✅ 中等 | cv2.INTER_LINEAR |
通用图像缩放、深度学习预处理 |
| 像素区域插值 | 多个区域平均 | ❌ 不推荐 | ✅✅✅ 最佳 | ✅✅ 中等 | cv2.INTER_AREA |
图像缩小时、压缩图片、防止失真 |
| 双三次插值 | 16(4×4) | ✅✅ 非常平滑 | ✅ 较好 | ❌ 较慢 | cv2.INTER_CUBIC |
图像高质量放大、图像编辑/美化 |
| Lanczos插值 | 多(通常8×8) | ✅✅✅ 超清晰 | ✅✅ 非常优秀 | ❌❌ 最慢 | cv2.INTER_LANCZOS4 |
高保真放大缩小、打印、大屏展示等场景 |
4.边缘填充
图片经过旋转等操作后,某些点可能已经超出图片范围,而空缺的像素点会默认使用黑色(0,0,0)填充,边缘填充的作用就是对这些空缺的位置进行处理,用不同的方式进行填充。
边缘填充作为cv.warpAffine()的参数borderMode,若无该参数,则默认使用黑色填充空缺部分。
new_img1=cv.warpAffine(img,M,(w,h),flags,borderMode)
| 填充方式名称 | OpenCV参数 | 原理说明 | 效果示意 | |
|---|---|---|---|---|
| 边界复制 | cv2.BORDER_REPLICATE |
复制最边缘一行/列的像素值向外扩展 | 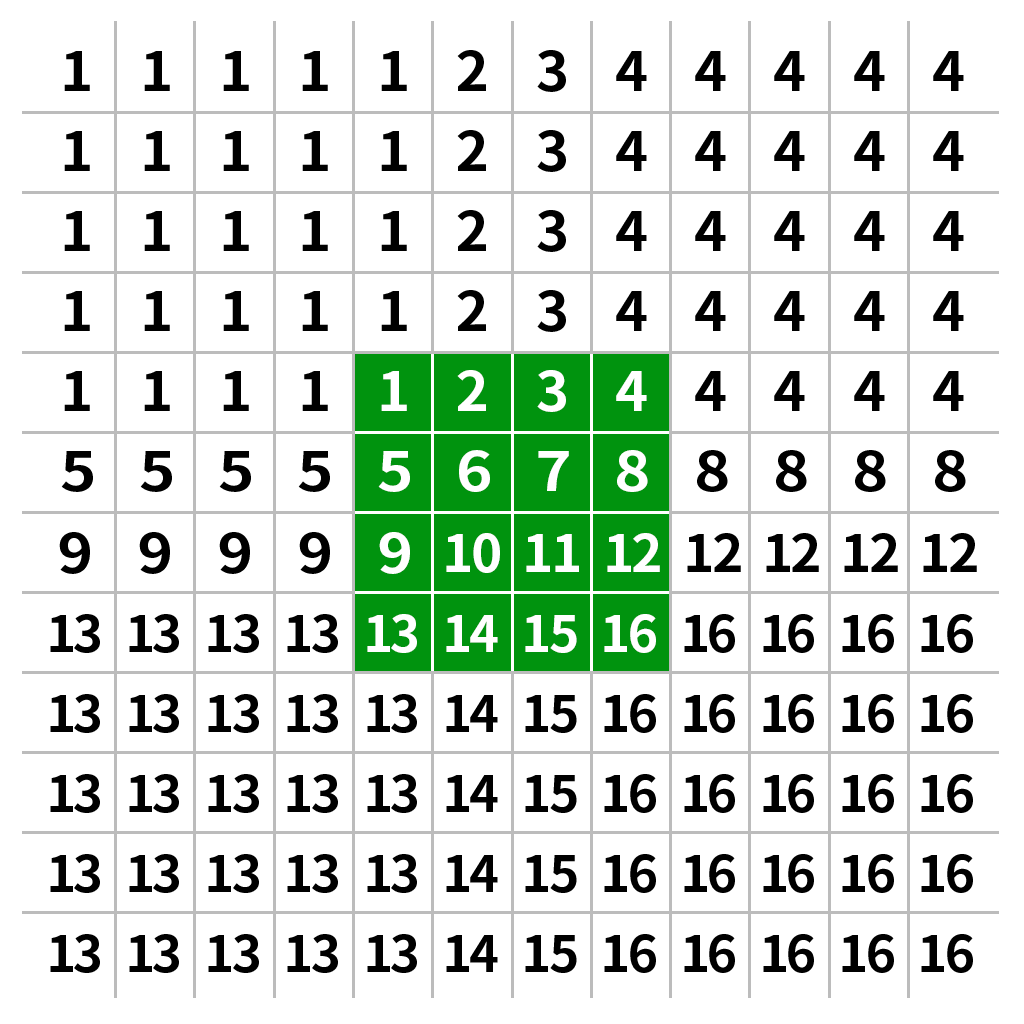 |
|
| 边界反射填充(复制边缘) | cv2.BORDER_REFLECT |
镜像翻转边界,重复边界元素本身 | 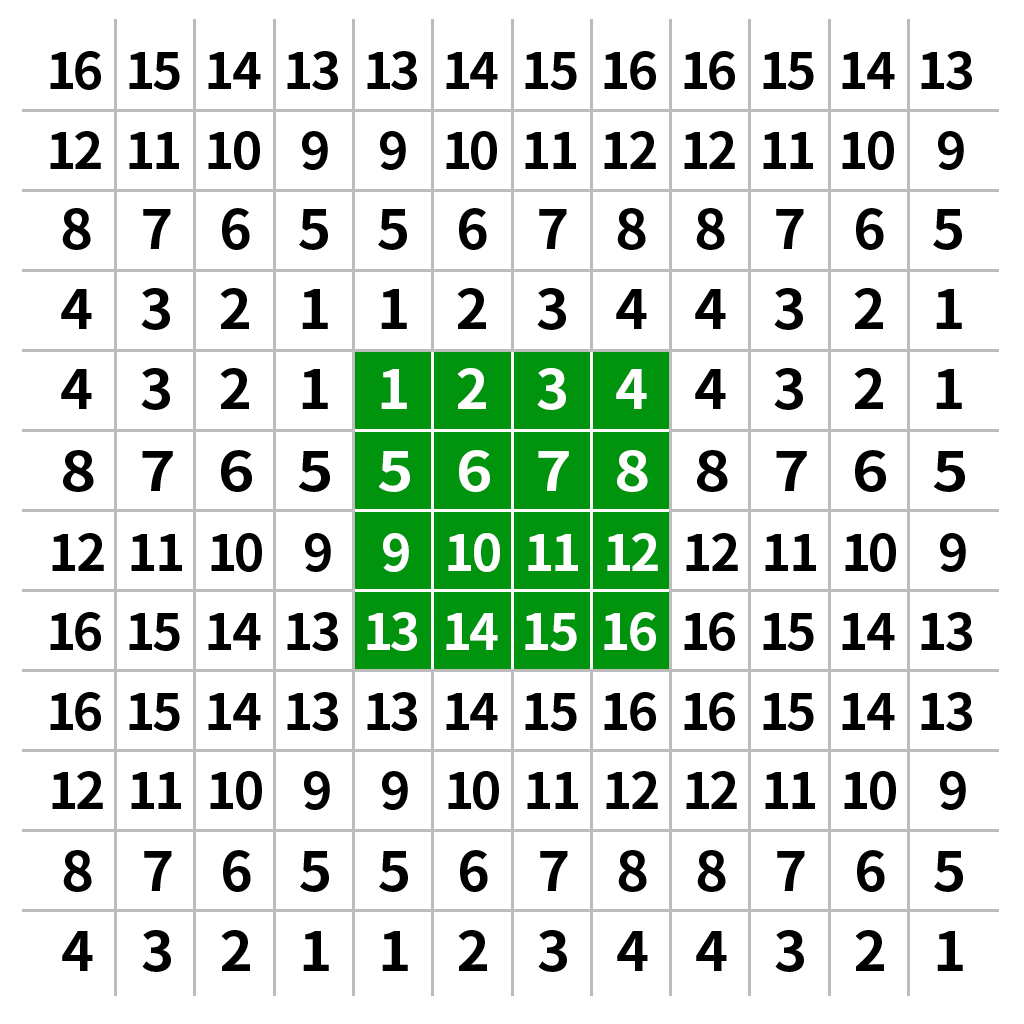 |
|
| 反射填充(不复制边缘) | cv2.BORDER_REFLECT_101或cv2.BORDER_DEFAULT |
镜像翻转边界,不包含边缘像素本身 | 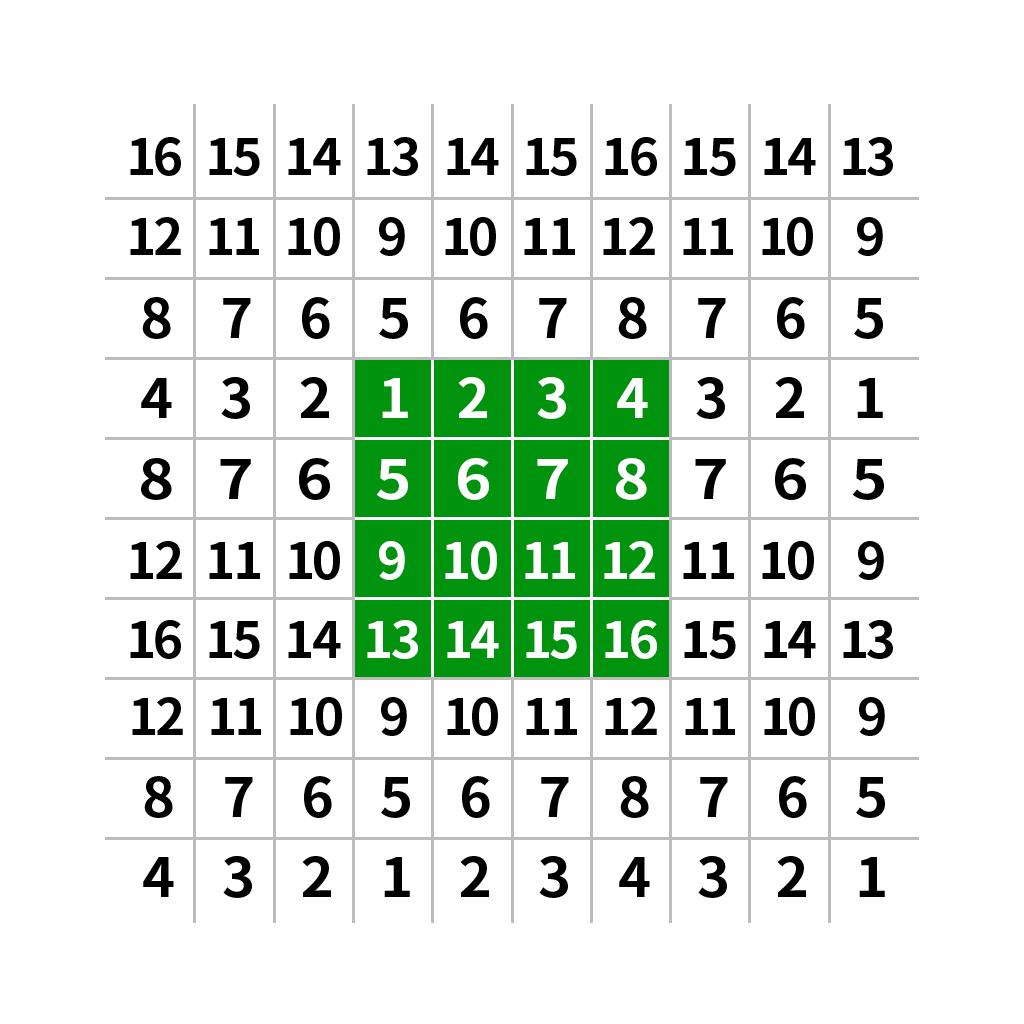 |
|
| 边界包裹 | cv2.BORDER_WRAP |
将图像看作环状结构,左边连接右边、上下相接 | 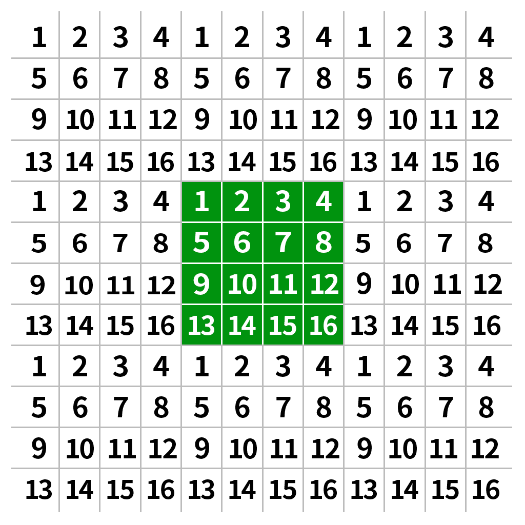 |
|
| 边界常数填充 | cv2.BORDER_CONSTANT |
使用指定的常数值填充图像边界 | 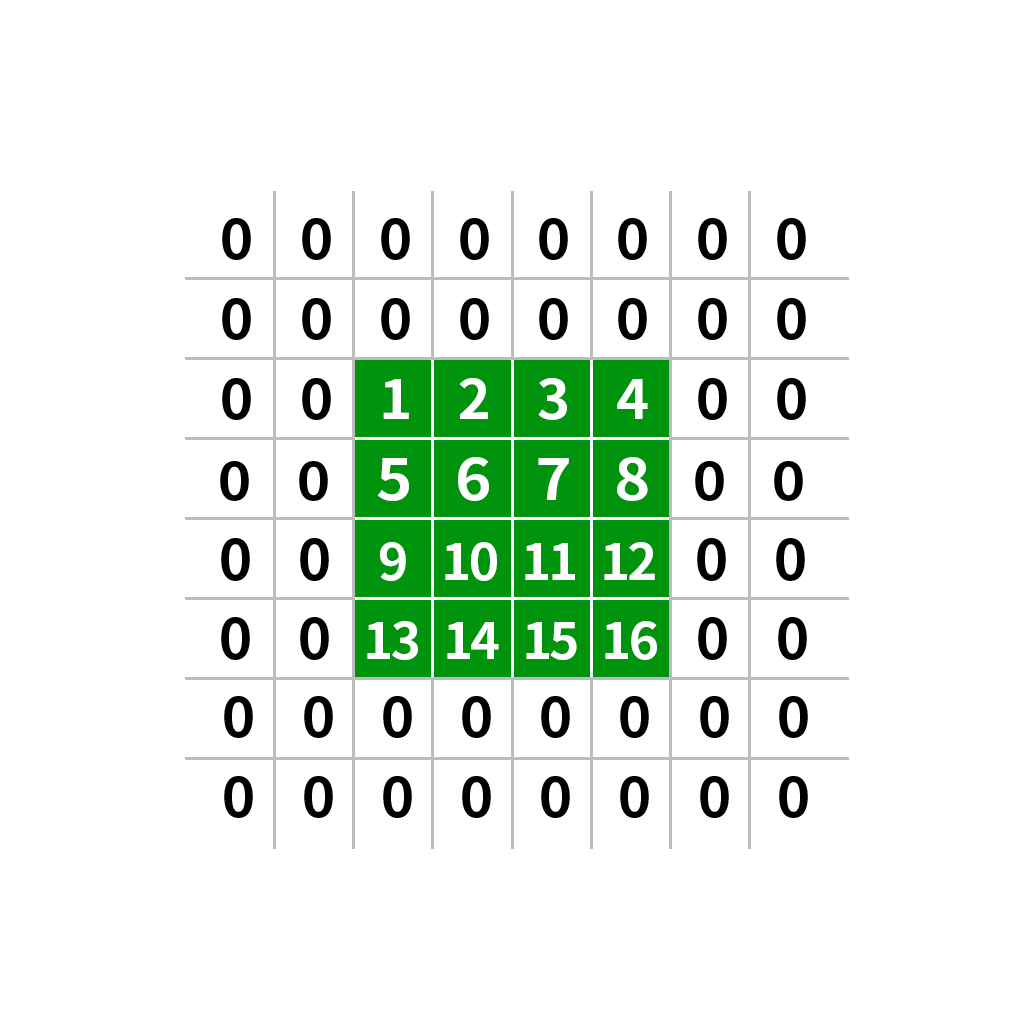 |
|
5.图像校正(透视变换)
透视变换(Perspective Transformation),也叫投影变换,是图像处理中的一种几何变换,用于将图像从一个视角变换到另一个视角。
它能够模拟 相机视角的变化,因此可以处理图像中由透视产生的畸变,例如拍摄一张倾斜的纸张并将其“拉正”。
以下是方式变换的数学原理:
设我们有一个点$ (x,y,z)在三维空间中,并且我们想要将其投影到二维平面上。我们可以先将其转换为齐次坐标,在三维空间中,并且我们想要将其投影到二维平面上。我们可以先将其转换为齐次坐标,在三维空间中,并且我们想要将其投影到二维平面上。我们可以先将其转换为齐次坐标, (x,y,z),然后进行透视投影,得到了经过透视投影后的二维坐标,然后进行透视投影,得到了经过透视投影后的二维坐标,然后进行透视投影,得到了经过透视投影后的二维坐标 (x′,y′)。通过将。通过将。通过将 X和和和Y$ 分别除以ZZZ,我们可以模拟出真实的透视效果。
与仿射变换一样,透视变换也有自己的透视变换矩阵:
[XYZ]=[a11a12a13a21a22a23a31a32a33]∗[xy1] \begin{array}{l l l}{{\left[\begin{array}{c}{{X}}\\{{Y}}\\{Z} \end{array}\right]=\left[\begin{array}{c c c}{{a_{11}}}&{{a_{12}}}&{{a_{13}}}\\ {{a_{21}}}&{{a_{22}}}&{{a_{23}}}\\ {{a_{31}}}&{{a_{32}}}&{{a_{33}}}\end{array}\right]*\left[\begin{array}{c}{{x}}\\{{y}}\\{{1}}\end{array}\right]}}\end{array}
XYZ
=
a11a21a31a12a22a32a13a23a33
∗
xy1
即
X=a11⋅x+a12⋅y+a13 X=a_{11}\cdot x+a_{12}\cdot y+a_{13} X=a11⋅x+a12⋅y+a13
Y=a21⋅x+a22⋅y+a23 Y=a_{21}\cdot x+a_{22}\cdot y+a_{23} Y=a21⋅x+a22⋅y+a23
Z=a31⋅x+a32⋅y+a33 Z=a_{31}\cdot x+a_{32}\cdot y+a_{33} Z=a31⋅x+a32⋅y+a33
由此可得新的坐标的表达式为:
x′=XZ=a11⋅x+a12⋅y+a13a31⋅x+a32⋅y+a33 x^{\prime}={\frac{X}{Z}}={\frac{a_{11}\cdot x+a_{12}\cdot y+a_{13}}{a_{31}\cdot x+a_{32}\cdot y+a_{33}}} x′=ZX=a31⋅x+a32⋅y+a33a11⋅x+a12⋅y+a13
y′=YZ=a21⋅x+a22⋅y+a23a31⋅x+a32⋅y+a33 y^{\prime}={\frac{Y}{Z}}={\frac{a_{21}\cdot x+a_{22}\cdot y+a_{23}}{a_{31}\cdot x+a_{32}\cdot y+a_{33}}} y′=ZY=a31⋅x+a32⋅y+a33a21⋅x+a22⋅y+a23
其中x、y是原始图像点的坐标,x′x^{\prime}x′、y′y^{\prime}y′是变换后的坐标,a11,a12,…,a33则是一些旋转量和平移量,由于透视变换矩阵的推导涉及三维的转换,所以这里不具体研究该矩阵,只要会使用就行,而OpenCV里也提供了getPerspectiveTransform()函数用来生成该3*3的透视变换矩阵。
得到变换矩阵M的方法:
getPerspectiveTransform(src,dst)
src:原图上需要处理的的四个点坐标,用于定义原图中的一个四边形区域
dst:透视变换后src四个点在新目标图像的四个坐标。
获得变换矩阵M后,使用warpPerspective()函数即可进行透视变化计算:
cv2.warpPerspective(src, M, dsize, flags, borderMode)
src:输入图像。
M:透视变换矩阵,通过getPerspectiveTransform函数计算得到。
dsize:输出图像的大小。它可以是一个Size对象,也可以是一个二元组。
flags:插值方法的标记。
borderMode:边界填充的模式。
示例:
import cv2 as cv
import numpy as np
# 读图
card = cv.imread("./3.png")
shape = card.shape
# 获取透视变换矩阵
# 原图中卡片的四个角点:左上、右上、左下、右下 顺序不一定为这个,但pt2和pt1的点顺序要一致
# [[178, 100], [487, 134], [124, 267], [473, 308]]
pt1 = np.float32([[178, 100], [487, 134], [124, 267], [473, 308]])
pt2 = np.float32([[0, 0], [shape[1], 0],[0, shape[0]], [shape[1], shape[0]]])
M = cv.getPerspectiveTransform(pt1, pt2)
# 透视变换 cv2.warpPerspective(src, M, dsize, flags, borderMode)
dst = cv.warpPerspective(card, M, (shape[1], shape[0]), cv.INTER_LINEAR, borderMode=cv.BORDER_REFLECT)
cv.imshow("org", card)
cv.imshow("card", dst)
cv.waitKey(0)
cv.destroyAllWindows()
原图:
处理后:
6.图像掩膜
掩膜(Mask)是一张 与原图像大小相同的图像,通常是二值图像(只有黑白/0或255),用来在图像处理时**指定“操作区域”**或“忽略区域”。
它就像一张“蒙版”,决定哪些像素需要被处理,哪些像素保持原样,即白色的部分为感兴趣部分——需要进行处理,黑色部分不处理。
1.掩膜创建
创建掩膜的方法很多,因为从掩膜的本质上看,掩膜就是一个二值化图像。
创建掩膜的常见方式
| 方法类别 | 函数/原理 | 说明与示例 |
|---|---|---|
| 颜色阈值法 | cv2.inRange() |
提取某种颜色范围,例如提取红色区域 |
| 固定区域法 | numpy操作或绘图函数 |
手动框定感兴趣区域(ROI),例如绘制圆形、矩形 |
| 二值化法 | cv2.threshold() 自适应二值化等 |
通过灰度值划分区域,获取亮/暗区域 |
示例:
该案例使用的是使用inRange()设定颜色范围创建掩膜——即针对某种特定颜色创建掩膜,为了方便设定颜色范围,会将图片的颜色空间转换为HSV颜色空间。
import cv2 as cv
import numpy as np
# 图像掩膜
# 读图
demo = cv.imread("./demo.png")
demo = cv.resize(demo, (640, 640))
# 转为HSV颜色空间
hsv = cv.cvtColor(demo, cv.COLOR_BGR2HSV)
# 定义颜色范围 黄色
low = np.array([26, 43, 46])
high = np.array([34, 255, 255])
# 创建掩膜 cv.inRange(img, low, high) 传hsv颜色空间下的图像
mask = cv.inRange(hsv, low, high)
cv.imshow("old", demo)
cv.imshow("mask", mask)
cv.waitKey(0)
cv.destroyAllWindows()
原图: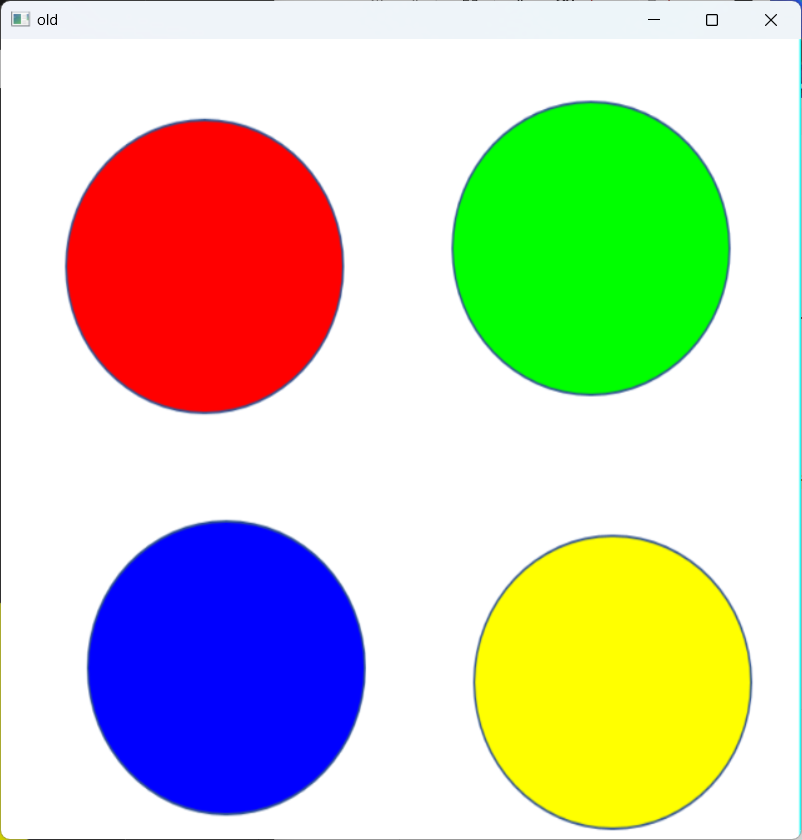
掩膜:
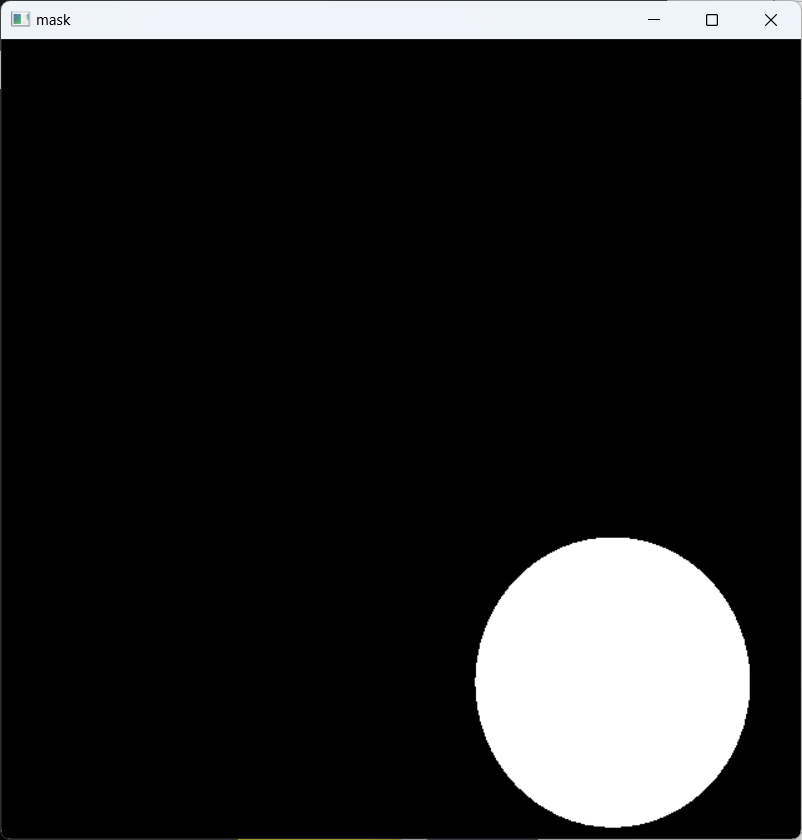
2.颜色提取
图像提取的核心原理就是用创建好的掩膜和原图做位与操作。我们要提取的颜色部分在掩膜中是白色(255,255,255),任何颜色与白色进行按位与获得的颜色都为该颜色本身,而黑色(0,0,0)与任何颜色进行位与运算所得的颜色都是黑色。
cv2.bitwise_and(src1,src2[,mask])
src1:原始图像
src2:当应用掩膜时,这个参数经常是src1本身,即对同一个图像进行操作;如果对两个不同的图像执行按位与操作(例如,将两张图片的某些部分组合在一起),可以分别将它们作为 src1 和 src2 输入到 cv2.bitwise_and() 函数中,创建复杂的图像效果或进行图像合成。
mask:掩膜(可选)。输入数组元素只有在该掩膜非零时才被处理。是一个8位单通道的数组,尺寸必须与src1和src2相同。
示例:
import cv2 as cv
import numpy as np
# 图像掩膜
# 读图
demo = cv.imread("./demo.png")
demo = cv.resize(demo, (640, 640))
# 转为HSV颜色空间
hsv = cv.cvtColor(demo, cv.COLOR_BGR2HSV)
# 定义颜色范围
low = np.array([26, 43, 46])
high = np.array([34, 255, 255])
# 创建掩膜 cv.inRange(img, low, high) 传hsv颜色空间下的图像
mask = cv.inRange(hsv, low, high)
cv.imshow("old", demo)
cv.imshow("mask", mask)
print(demo.shape)
print(mask.shape)
# 颜色提取 cv.bitwise_and(src1, src2[, mask]) 提取黄色部分
dst = cv.bitwise_and(demo, demo, mask=mask)
cv.imshow("dst", dst)
cv.waitKey(0)
cv.destroyAllWindows()
效果图:

3.颜色替换
因为掩膜的大小与原图相同并且像素位置一一对应,所以我们可以通过使用布尔索引去更改原图中制作掩膜那部分的像素值,即完成颜色替换。
示例:
将原图中红色部分改为蓝色。
import cv2 as cv
import numpy as np
# 图像掩膜
# 读图
demo = cv.imread("./demo.png")
demo = cv.resize(demo, (640, 640))
# 转为HSV颜色空间
hsv = cv.cvtColor(demo, cv.COLOR_BGR2HSV)
# 定义颜色范围
low = np.array([0, 43, 46])
high = np.array([10, 255, 255])
# 创建掩膜 cv.inRange(img, low, high) 传hsv颜色空间下的图像
mask = cv.inRange(hsv, low, high)
cv.imshow("old", demo)
cv.imshow("mask", mask)
# 颜色替换 利用布尔索引替换原图片颜色
arr = mask == 255
demo[arr] = (255, 0, 0)
cv.imshow("change",demo)
cv.waitKey(0)
cv.destroyAllWindows()
原图:
更改颜色后:

7.图像添加水印
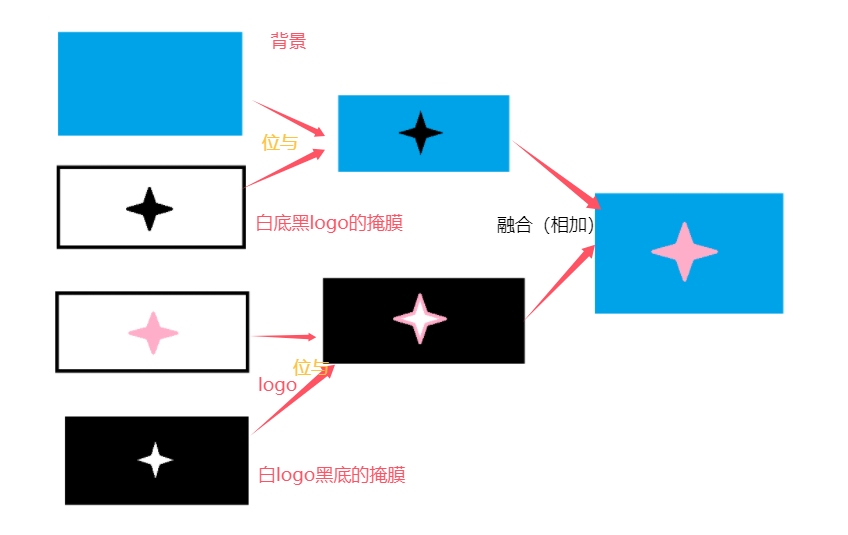
在图像中添加水印可以理解为将水印(logo)提取出来然后叠加到另一张图片上。logo的提取方法与掩膜的颜色提取类似,但是在提取出logo后不能直接与图像相加(若直接相加可能会导致部分饱和),所以需要在ROI区域(图片添加水印的区域)制作一个掩膜提取该区域的背景,最后相加,得到带水印的图片。
其思路图主要为
示例:
import cv2 as cv
import numpy as np
# 读图
bg = cv.resize(cv.imread("./bg.png"), (1080, 612))
logo = cv.resize(cv.imread("./RAS.jpg"),(320, 180))
h, w, c = logo.shape
roi = bg[:h, :w]
# 转灰度
gray = cv.cvtColor(logo, cv.COLOR_BGR2GRAY)
# 二值化
# 黑logo白底 与上背景 提取背景
_, mask1 = cv.threshold(gray, 200, 255, cv.THRESH_BINARY)
bg1 = cv.bitwise_and(roi, roi, mask=mask1)
cv.imshow("mask1", mask1)
cv.imshow("bg1", bg1)
# 白logo黑底 与上logo 提取logo
_, mask2 = cv.threshold(gray, 200, 255, cv.THRESH_BINARY_INV)
logo1 = cv.bitwise_and(logo, logo, mask=mask2)
cv.imshow("mask2", mask2)
cv.imshow("logo1", logo1)
# 融合
roi[:] = cv.add(bg1, logo1)
cv.imshow("roi", roi)
cv.imshow("bg", bg)
cv.waitKey(0)
cv.destroyAllWindows()
roi区域即为我们要插入logo的图片区域,这里设置的是图片起始点即左上角位置。反阈值法获得的是白logo黑底的图片,与上logo后能够提取logo颜色,但该图片不能与背景直接相加(饱和),所以需要在背景图上抠出logo的那一部分:阈值法把logo变为白底黑字,与上背景图,可以得到具有黑色logo的背景图,此时再进行相加就可以完成图片的合成。
原背景:

logo:

融合后:

以上就是博主在学习OpenCV图像处理时的一些总结,此文章为个人学习中所作笔记,如有任何错误请及时指正博主,感谢浏览~ovo

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)