2024 Mathematics Detect-Then-Resolve: Enhancing Knowledge Graph Conflict Resolution with LLM
论文基本信息
- 题目: Detect-Then-Resolve: Enhancing Knowledge Graph Conflict Resolution with Large Language Model (先检测后解决:利用大语言模型增强知识图谱冲突解决)
- 作者: Huang Peng, Pengfei Zhang, Jiuyang Tang, Hao Xu, Weixin Zeng
- 机构: National University of Defense Technology (国防科技大学)
- 发表期刊/年份: Mathematics, 2024
- 关键词:
- Knowledge Graph (KG): 知识图谱
- Conflict Resolution: 冲突解决,在知识融合过程中,识别并处理来自不同知识源的矛盾或不一致信息的过程。
- Large Language Model (LLM): 大语言模型
摘要(详细复述)
- 背景: 在知识图谱(KG)的知识融合过程中,冲突解决是确保融合后数据准确性的关键环节。然而,现有方法在处理包含未见实体的外部三元组时常常面临困难,因为它们依赖于KG内部有限的知识。此外,现有方法大多忽略了在解决冲突之前的冲突检测步骤,而这一步对于准确的真值推断至关重要。
- 方案概述: 本文提出了一种名为CRDL (Conflict Resolution with Detection and LLM) 的创新方法。该方法巧妙地结合了冲突检测和大语言模型(LLM)来识别真值三元组。首先,通过冲突检测,CRDL针对不同类型的关系和属性(一对一 vs. 非一对一)实施了精准的过滤策略。接着,通过精心设计的提示(Prompt)工程,将相关信息注入到LLM中,使其能够有效识别包含未见实体的三元组。
- 主要结果/提升: 实验结果表明,CRDL方法显著优于基线模型。具体而言,与当前最先进的方法相比,CRDL在召回率(Recall)上提升了56.4%,在F1分数(F1-score)上提升了68.2%。
- 结论与意义: 这些结果清晰地展示了CRDL方法在性能和有效性上的巨大提升。进一步的消融实验和分析也证实了CRDL框架中各个组件的重要性,为知识图谱冲突解决领域提供了一个更强大、更鲁棒的解决方案。
研究背景与动机
-
学术/应用场景与痛点:
知识图谱因其不完整性,需要不断从外部数据源(如其他KG或开放网络文本)进行知识融合以补充信息。然而,融合过程不可避免地会引入与现有知识相冲突的信息,例如,一个KG中记录(Himalayas, located_in, Asia),而外部源则声称(Himalayas, located_in, Africa)。如果不解决这类冲突,KG的准确性将受到严重损害,进而影响下游应用(如问答系统、推荐系统)的可靠性。 -
主流路线与局限:
当前冲突解决方法主要面临两大挑战:- 处理未见实体的能力有限: 传统方法(如基于规则、概率图模型或机器学习)严重依赖KG内部已有的知识和结构。当外部三元组的尾实体在KG中从未出现过时(即“unseen entities”),这些方法由于缺乏先验知识,很难判断其真伪。
- 忽略冲突检测的重要性: 现有方法往往默认所有待融合的三元组都与KG中的某个事实存在冲突,然后试图在所有候选项中“选出最优”。这种“一刀切”的做法忽略了一个重要事实:关系具有不同类型。
- 一对一 (1-to-1) 关系: 如
located_in,一个实体只能有一个真实值。此时,新旧知识必然存在冲突。 - 非一对一 (non-1-to-1) 关系: 如
student_of,一个导师可以有多个学生。此时,新的三元组(Chadwick, student_of, Rutherford)与KG中已有的(Bohr, student_of, Rutherford)可能并不冲突,两者都可以是事实。
现有方法不区分这两种情况,可能导致对非一对一关系的过度过滤,从而遗漏了本应被接纳的“潜在真理”。
- 一对一 (1-to-1) 关系: 如
如下表所示,现有工作存在明显局限:
| 代表性工作方向 | 优点 | 不足之处 |
|---|---|---|
| 传统冲突解决方法 | 在处理已知实体和有充足数据源的场景下,能较好地评估数据源的可信度。 | 1. 无法处理包含未见实体的三元组。 2. 忽略了关系的语义信息(如1-to-1 vs. non-1-to-1),导致不精确的冲突判断。 |
| 开放知识图谱补全 (Open KGC) | 专注于识别包含未见实体的新事实,具有一定的开放世界处理能力。 | 1. 知识来源受限于预训练语言模型的内在知识,可能产生幻觉。 2. 同样没有显式地进行冲突检测,可能引入与现有KG矛盾的新事实。 |
| 基于LLM的KG补全 | 利用LLM强大的常识知识和推理能力,可以处理更广泛的实体和关系。 | 缺乏针对冲突解决任务的专门设计,直接应用时效果不佳,需要精细的Prompt工程。 |
本文的核心动机正是要解决上述两大痛点,通过引入“先检测后解决”的范式,并利用LLM强大的开放世界知识,构建一个既能精确判断冲突,又能有效处理未见实体的冲突解决框架。
问题定义(形式化)
-
输入:
- 一个先验知识图谱 KG={E,R,A,V,Tr,Ta}KG = \{E, R, A, V, T_r, T_a\}KG={E,R,A,V,Tr,Ta},其中:
- E,R,A,VE, R, A, VE,R,A,V 分别代表实体、关系、属性和值的集合。
- Tr⊆E×R×ET_r \subseteq E \times R \times ETr⊆E×R×E 是关系三元组集合。
- Ta⊆E×A×VT_a \subseteq E \times A \times VTa⊆E×A×V 是属性三元组集合。
- 一个从外部来源提取的“声明”集合(claims)C={(h,r,t)∣h∈E,r∈R∪A}C = \{(h, r, t) | h \in E, r \in R \cup A\}C={(h,r,t)∣h∈E,r∈R∪A}。这些声明的头实体 hhh 和关系/属性 rrr 存在于 KGKGKG 中,但尾实体/值 ttt 可能是未见过的。
- 一个先验知识图谱 KG={E,R,A,V,Tr,Ta}KG = \{E, R, A, V, T_r, T_a\}KG={E,R,A,V,Tr,Ta},其中:
-
输出:
- 一个真值集合 C∗⊆CC^* \subseteq CC∗⊆C,即从所有声明中识别出的所有正确的三元组。
-
目标函数:
最大化识别出的真值集合 C∗C^*C∗ 的准确性,通常通过 Precision, Recall, 和 F1-score 来衡量。
创新点
- 提出了“先检测后解决 (Detect-Then-Resolve)”的新范式:本文首次将冲突检测作为知识图谱冲突解决流程中的一个独立且关键的步骤。通过将关系/属性显式地划分为“一对一”和“非一对一”两类,并为它们设计不同的处理策略,该方法能够更精确地进行真值推断,避免了对非冲突信息的误伤,从而在保留潜在真理的同时减少错误识别。
- 设计了知识图谱嵌入与LLM协同的混合过滤机制:CRDL巧妙地结合了两种技术的优势。它首先利用基于知识图谱嵌入(KGE)的评分函数(本文称之为“perplexity”)对所有声明进行初步筛选,快速过滤掉明显错误的高分声明。然后,对于更复杂的非一对一关系,它将筛选后的候选声明交由**大语言模型(LLM)**进行深度语义判断。这种“快筛+精判”的混合机制,既利用了KGE在结构化知识上的高效性,又借助了LLM在处理开放世界和未见实体时的强大能力。
- 构建了结构化的三段式Prompt工程:为了充分激发LLM在冲突解决任务中的潜力,本文设计了一套包含任务声明 (Task declaration)、示例 (Demonstrations) 和输入声明 (Input claims) 的三段式Prompt模板。特别地,它通过“三元组翻译”技术,将KG中与头实体相关的结构化事实转化为自然语言描述作为示例,极大地帮助LLM理解实体上下文,从而做出更准确的判断。
方法与核心思路(重点展开)
整体框架
CRDL方法的整体框架如下图所示,它主要包含训练阶段和推理阶段。
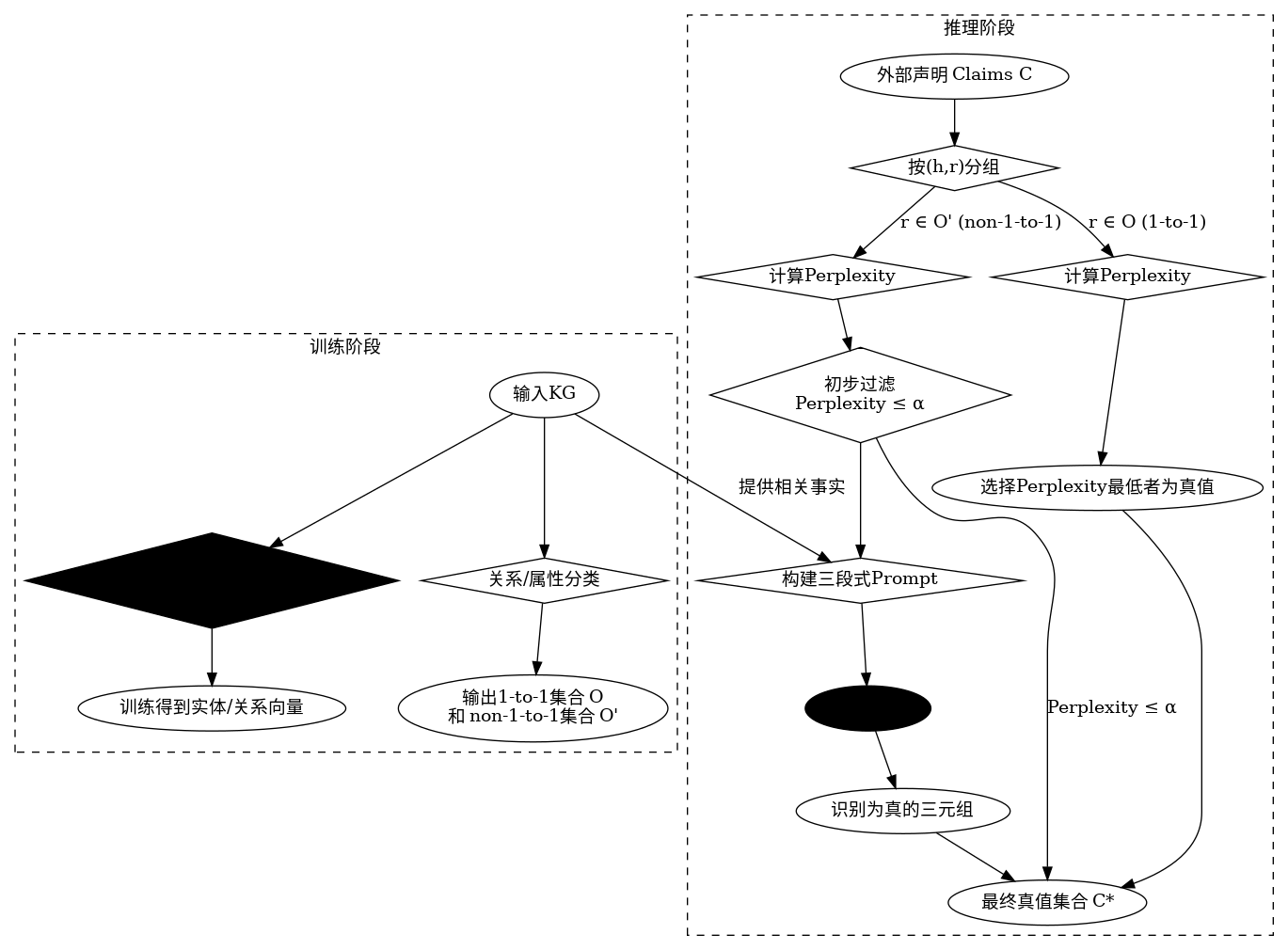
该流程图展示了CRDL方法的工作流程。在训练阶段,模型学习知识图谱的嵌入表示并对关系进行分类。在推理阶段,对于外部声明,方法根据关系的类型(一对一或非一对一)采用不同策略:一对一关系直接通过嵌入得分选择最优声明;非一对一关系则先通过得分进行初步过滤,然后利用大语言模型(LLM)进行最终判断。
步骤分解与模块详解
1. 知识图谱嵌入 (KG Embedding)
- 目的: 将KG中的实体、关系和属性映射到低维向量空间,以便量化三元组的合理性。
- 方法:
- 对于关系三元组 (h,r,t)(h, r, t)(h,r,t),采用 TransE 模型。其评分函数(本文称为perplexity)定义为:
fr(h,r,t)=∣∣h+r−t∣∣1 f_r(h, r, t) = ||\mathbf{h} + \mathbf{r} - \mathbf{t}||_1 fr(h,r,t)=∣∣h+r−t∣∣1
其中 h,r,t\mathbf{h}, \mathbf{r}, \mathbf{t}h,r,t 是对应的向量嵌入,∣∣⋅∣∣1||\cdot||_1∣∣⋅∣∣1 是L1范数。 - 对于属性三元组 (e,a,v)(e, a, v)(e,a,v),评分函数定义为:
fa(e,a,v)=∣eTa−v∣ f_a(e, a, v) = |\mathbf{e}^T \mathbf{a} - v| fa(e,a,v)=∣eTa−v∣
其中 e,a\mathbf{e}, \mathbf{a}e,a 是实体和属性的嵌入,vvv 是数值。
- 对于关系三元组 (h,r,t)(h, r, t)(h,r,t),采用 TransE 模型。其评分函数(本文称为perplexity)定义为:
- 训练: 使用边际损失函数 (margin-based loss) 进行训练,以最小化正样本的评分,同时最大化负样本的评分。
L=∑(h,r,t)∈Tr∪Ta∑(h,r,t′)∈Tr′∪Ta′[γ+f(h,r,t)−f(h,r,t′)]+ \mathcal{L} = \sum_{(h,r,t) \in T_r \cup T_a} \sum_{(h,r,t') \in T_r' \cup T_a'} [\gamma + f(h,r,t) - f(h,r,t')]_+ L=(h,r,t)∈Tr∪Ta∑(h,r,t′)∈Tr′∪Ta′∑[γ+f(h,r,t)−f(h,r,t′)]+
其中 γ\gammaγ 是边际超参数,t′t't′ 是通过随机替换尾实体生成的负样本,[⋅]+=max(0,⋅)[\cdot]_+ = \max(0, \cdot)[⋅]+=max(0,⋅)。核心思想是让正确三元组的向量表示在空间中比错误三元组的更“紧凑”。
2. 冲突检测 (Conflict Detection)
- 目的: 区分关系和属性的类型,为后续的差异化处理策略提供依据。
- 方法: 遍历KG中的所有关系和属性,根据其函数性(functionality)进行分类。
- 一对一 (1-to-1) 关系/属性集合 OOO 的定义为:
O={r∣∀h∈E,#{t′∣(h,r,t′)∈Tr∪Ta}=1} O = \{r | \forall h \in E, \#\{t'|(h,r,t') \in T_r \cup T_a\} = 1\} O={r∣∀h∈E,#{t′∣(h,r,t′)∈Tr∪Ta}=1}
其中 #A\#A#A 表示集合A的基数。即对于任意头实体hhh,关系rrr最多只能连接到一个尾实体。 - 非一对一 (non-1-to-1) 集合 O′O'O′ 则是 R∪AR \cup AR∪A 中除去 OOO 的剩余部分。
- 一对一 (1-to-1) 关系/属性集合 OOO 的定义为:
3. 冲突解决 (Conflict Resolution)
这一步是框架的核心,根据冲突检测的结果,采用两种不同的策略。
-
策略一:针对1-to-1关系/属性
- 机理: 由于1-to-1关系只允许存在一个真值,因此对于一组具有相同头实体 hhh 和关系 r∈Or \in Or∈O 的声明 Ch,rC_{h,r}Ch,r,它们必然是相互冲突的。
- 解决方法: 直接选择perplexity最低的那个声明作为唯一的真值。
CO∗={(h,r,t)∣r∈O,(h,r,t)=argminc∈Ch,rf(h,r,t)} C_O^* = \{(h,r,t) | r \in O, (h,r,t) = \arg\min_{c \in C_{h,r}} f(h,r,t)\} CO∗={(h,r,t)∣r∈O,(h,r,t)=argc∈Ch,rminf(h,r,t)} - 直观解释: 这个策略基于一个假设:KGE模型学到的向量空间中,最符合KG结构的三元组(即得分/perplexity最低的)最可能是正确的。
-
策略二:针对non-1-to-1关系/属性
- 机理: 对于这类关系,多个声明可能同时为真。因此不能简单地“N选1”。需要一种更强大的机制来判断每个声明的独立真伪。
- 解决方法: 采用一个两阶段的过滤流程。
- 基于Perplexity的初步过滤: 首先,保留所有perplexity低于一个预设阈值 α\alphaα 的声明。这可以快速筛掉大量明显不合理的声明。
{(h,r,t)∈Ch,r∣r∈O′,f(h,r,t)≤α} \{(h,r,t) \in C_{h,r} | r \in O', f(h,r,t) \leq \alpha\} {(h,r,t)∈Ch,r∣r∈O′,f(h,r,t)≤α} - 基于LLM的精细过滤: 将通过初筛的、以及perplexity高于阈值的剩余声明 C~h,r\tilde{C}_{h,r}C~h,r,输入到LLM中进行最终判断。
- 基于Perplexity的初步过滤: 首先,保留所有perplexity低于一个预设阈值 α\alphaα 的声明。这可以快速筛掉大量明显不合理的声明。
4. 基于LLM的过滤与Prompt工程
-
目的: 利用LLM的常识和推理能力,判断那些KGE模型难以处理的、尤其是包含未见实体的声明的真伪。
-
Prompt设计: 为了让LLM能理解任务并发挥最大效能,Prompt被设计为三个部分:
- 任务声明 (Task Declaration): 明确告知LLM其任务是“识别三元组中的真值”,并说明输入格式。这是一个固定的引导部分。
- 示例 (Demonstrations): 这是最关键的部分。为了让LLM了解输入声明中头实体 eee 的上下文,算法会从KG中随机采样 kkk 个与 eee 相关的、已知的真实三元组 DeD_eDe。
De={(e,r,t)∣r∈R∪A,t∈E∪V,(e,r,t)∈Tr∪Ta} D_e = \{(e,r,t) | r \in R \cup A, t \in E \cup V, (e,r,t) \in T_r \cup T_a\} De={(e,r,t)∣r∈R∪A,t∈E∪V,(e,r,t)∈Tr∪Ta}
然后,通过一个“三元组翻译 (Triple translation)”模块(如图4所示,本身也由LLM完成),将这 kkk 个结构化的三元组转换成一段流畅的自然语言描述。例如,(Spring Harbor Hospital, located_in, Westbrook)和(Spring Harbor Hospital, function, Healthcare)会被翻译成:“Spring Harbor Hospital is a healthcare facility located in Westbrook, Maine…”。这段描述为LLM提供了关于头实体的背景知识。 - 输入声明 (Input Claims): 将待判断的声明 C~h,r\tilde{C}_{h,r}C~h,r 以列表形式输入,并要求LLM对每一个声明给出一个“True”或“False”的判断。
-
最终真值集合: 对于non-1-to-1关系,最终的真值集合 CO′∗C_{O'}^*CO′∗ 由两部分组成:通过perplexity初筛的声明,以及通过LLM精筛并判断为真的声明。
CO′∗={(h,r,t)∈Ch,r∣r∈O′,f(h,r,t)≤α}∪{(h,r,t)∈C~h,r∣LLM(h,r,t)=1} C_{O'}^* = \{(h,r,t) \in C_{h,r}|r \in O', f(h,r,t) \leq \alpha\} \cup \{(h,r,t) \in \tilde{C}_{h,r}|LLM(h,r,t) = 1\} CO′∗={(h,r,t)∈Ch,r∣r∈O′,f(h,r,t)≤α}∪{(h,r,t)∈C~h,r∣LLM(h,r,t)=1}
伪代码 (Algorithm 1)
// 算法 1: CRDL 算法描述
Input: KG, Claims C, 超参数 γ, α, k, EPOCHS
Output: 真值集合 C*
1: 预处理和初始化嵌入
2: 初始化模型参数
3: C* := ∅
// 训练阶段
4: for epoch = 1 to EPOCHS do
5: 计算损失 L (基于公式3)
6: 更新模型参数和嵌入
7: end for
// 推理阶段
8: 基于公式4对所有关系和属性分类,得到 O 和 O'
9: for each claim group C_h,r in C do
10: if r in O then // 1-to-1 关系
11: 基于公式6找到 C_o* (perplexity最低的)
12: C* := C* ∪ C_o*
13: else // non-1-to-1 关系
14: C_o'* := ∅
15: for each claim c = (h,r,t) in C_h,r do
16: if f(h,r,t) ≤ α then
17: C_o'* := C_o'* ∪ {c} // 通过初筛
18: else
19: 构建Prompt (包含任务声明、示例、输入声明c)
20: if LLM(c) == 1 then // LLM判断为真
21: C_o'* := C_o'* ∪ {c}
22: end if
23: end if
24: end for
25: C* := C* ∪ C_o'*
26: end if
27: end for
28: Return C*
伪代码解读: 算法首先进行KGE模型的训练。训练完成后,进入推理阶段。它遍历按(头实体, 关系)分组后的所有声明。如果关系是1-to-1类型,则直接选择得分最低的声明作为真值。如果关系是非1-to-1类型,则进行两步过滤:先保留得分低于阈值α的声明,然后将其余的声明交给LLM判断,将LLM判断为真的也加入结果集。最终,合并所有识别出的真值并返回。
实验设置
- 数据集: 使用由OKELE创建的数据集。该数据集包含从Freebase衍生的10个流行实体类别,每个类别1200个实体,共计191,759个三元组。部分三元组被作为先验KG,其余作为待验证的声明。
- 评价指标: Precision §, Recall ®, 和 F1-score。
Precision=TPTP+FPRecall=TPTP+FNF1=2⋅P⋅RP+R \text{Precision} = \frac{TP}{TP+FP} \quad \text{Recall} = \frac{TP}{TP+FN} \quad \text{F1} = \frac{2 \cdot P \cdot R}{P+R} Precision=TP+FPTPRecall=TP+FNTPF1=P+R2⋅P⋅R - 实现细节:
- 硬件: Intel Core i7-12700F CPU, 32 GB RAM, NVIDIA GeForce RTX 3090 GPU。
- 超参数: 边际 γ=5\gamma=5γ=5,概率阈值 α=0.5\alpha=0.5α=0.5,LLM示例采样数 k=5k=5k=5,嵌入维度 de=768d_e=768de=768 (来自预训练BERT),学习率 lr=0.01lr=0.01lr=0.01,训练轮次 EPOCHS=50EPOCHS=50EPOCHS=50。
- LLM: 使用 GPT-3.5-turbo 的API。
实验结果与分析
主结果表分析
表2. 整体性能对比
| 模型 | Precision | Recall | F1-Score |
|---|---|---|---|
| TruthFinder | 0.279 | 0.374 | 0.320 |
| OKELE | 0.459 | 0.485 | 0.472 |
| TKGC | 0.524 | 0.491 | 0.507 |
| ChatGPT (直接调用) | 0.417 | 0.477 | 0.445 |
| CRDL (本文) | 0.959 | 0.768 | 0.853 |
| CRDL w/o LLM | 0.911 | 0.271 | 0.418 |
| CRDL w/o CD | 0.920 | 0.749 | 0.826 |
- 核心结论:
- CRDL性能卓越: CRDL在所有指标上均大幅领先所有基线模型,其F1-score (0.853) 比次优的TKGC (0.507) 提升了约68.2%,展示了其架构的巨大优越性。
- 直接调用LLM效果不佳: “ChatGPT”基线表明,没有经过精心Prompt工程的LLM,无法很好地理解任务,性能甚至不如一些传统模型。
- 消融实验证明了组件的必要性:
- CRDL w/o LLM: 移除了LLM模块后,Recall从0.768骤降至0.271。这证明了LLM在识别KGE模型无法覆盖的、尤其是包含未见实体的外部三元组方面,扮演了至关重要的角色。
- CRDL w/o CD: 移除了冲突检测(Conflict Detection)模块后,Precision和Recall均有下降(F1-score从0.853降至0.826)。这说明,对关系类型进行区分并采取不同策略,能够有效提升真值识别的准确性。
K-Shot Demonstrations 分析
表3 & 图5. 不同k值下的性能
| k-Shot | Precision | Recall | F1-Score |
|---|---|---|---|
| 0-shot | 0.953 | 0.715 | 0.817 |
| 1-shot | 0.960 | 0.754 | 0.844 |
| 3-shot | 0.958 | 0.755 | 0.845 |
| 5-shot | 0.959 | 0.768 | 0.853 |
| 7-shot | 0.953 | 0.751 | 0.840 |
- 核心结论:
- 示例至关重要: 从0-shot到1-shot,Recall有显著提升(从0.715到0.754),证明了为LLM提供关于头实体的上下文信息(即Demonstrations)是极其有效的。
- 存在最优示例数量: Recall在k=5时达到峰值,之后随着k增大反而下降。这表明,过多的示例可能会引入不相关或冗余的信息,干扰LLM的判断。这为Prompt工程中的示例数量选择提供了重要的实践指导。
- Precision对k不敏感: Precision在不同k值下保持相对稳定,说明只要提供了示例,LLM的判断准确度就很高,而示例数量主要影响其“找全”真理的能力(Recall)。
复现性清单
- 代码/数据: 论文明确指出数据集可在
https://github.com/nju-websoft/OKELE获取。但未提及是否开源其自身代码。 - 模型权重: KGE部分的嵌入是现场训练的,LLM部分使用的是GPT-3.5-turbo的API,无特定权重提供。
- 环境与依赖版本: 未详细说明,但提及了硬件配置。
- 运行命令/配置文件: 未提供。
结论与未来工作
-
结论: 本文提出的CRDL框架,通过整合冲突检测和LLM,有效地解决了知识图谱冲突解决中的核心挑战。实验证明,该方法不仅确保了融合后KG的正确性和可靠性,还显著提升了处理包含未见实体的外部知识的能力,为构建更准确、更全面的知识图谱提供了强有力的工具。
-
未来工作:
- 处理罕见/长尾实体: 当前方法可能受限于LLM对罕见实体的知识储备。未来可以探索如何利用LLM识别和处理知识库中信息不足的长尾实体。
- 处理动态和时序KG: 将CRDL框架扩展到能够处理随时间变化的动态知识图谱。
- 与其他知识融合任务结合: 探索将冲突解决与实体对齐等其他知识融合任务相结合,以实现相互促进和整体效果的提升。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 18
18 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)