LongCat-Flash-Omni:面向工业场景的端侧友好型多模态大模型
问题形式化:给定时间序列多模态输入Mmtτtt1TM{(mtτtt1T,其中mtmt为模态数据,τt\tau_tτt为时间戳,目标是构建函数fM→YfM→Y,使得模型能理解任意时间点的跨模态关联。传统方法将整个音频/视频作为单一特征zaudiozaudio时序分辨率丢失:无法定位"他在说’菜品很冷’时背景有婴儿哭声"长度限制:32K 上下文仅支持 1-2 张图 + 10 秒音频计算效率
文章优先发布在微信公众号——“LLM大模型”,有些文章未来得及同步,可以直接关注公众号查看
一、多模态大模型的现实困境与突破之路
1.1 产业痛点:为何现有模型无法满足真实业务需求?
在深入探讨 LongCat-Flash-Omni 之前,我们需要理解当前多模态大模型 (Multimodal Large Language Models, MLLMs) 面临的核心产业挑战:
多模态大模型 (MLLMs):能够同时处理、理解和生成多种信息模态(如文本、图像、音频、视频)的人工智能系统,通过统一的表示空间实现跨模态推理与知识迁移。
当前产业中多模态模型面临的三大矛盾
| 矛盾维度 | 传统开源模型 | 闭源商业模型 | 业务影响 |
|---|---|---|---|
| 能力与效率 | 能力有限(仅支持文本/图像) | 能力强大但无法私有化部署 | 敏感数据必须外传,增加合规风险 |
| 模态完整性 | 多数忽略音频模态 | 支持多模态但API调用成本高 | 无法理解用户语音中的情绪/环境音 |
| 上下文长度 | 长文本模型不支持多模态 | 多模态模型上下文受限(通常<32K) | 无法处理长客服对话+多图+语音 |
美团业务场景提供了典型案例:当用户通过APP投诉"你们的外卖送晚了,我拍了照片,还有录音证明"时,当前技术栈需要:
- 使用 ASR (自动语音识别) 服务转录音频
- 用 CV (计算机视觉) 模型分析图片
- 用 LLM (大语言模型) 生成回复
——这种多系统拼接架构导致延迟高、错误累积、成本增加。
1.2 LongCat-Flash-Omni 的破局之道
美团 LongCat 团队基于海量业务数据与工程实践,提出统一多模态架构设计理念:
统一多模态架构:将不同模态的输入通过专业编码器转换为统一表示,由单一神经网络进行跨模态理解与推理,避免多系统拼接带来的复杂性与误差累积。
LongCat-Flash-Omni 通过三大创新解决了产业核心痛点:
-
首创Chunk-wise 多模态交错机制 (CAFI):
- 首创时序分块 + 特征压缩 + 时序位置编码
- 在128K上下文中实现细粒度音视频定位
- 使长音频理解成为可能(71.1小时/128K上下文)
-
超越ASR的声学理解体系:
- 四层声学理解(场景→事件→内容→情感)
- 时频掩码技术分离背景音
- 跨模态对比学习建立视听关联
-
全栈端侧友好设计:
- 三级量化策略覆盖云-边-端
- GGUF格式使10B模型在手机运行
- Apache 2.0协议消除商业顾虑
LongCat-Flash-Omni 通过统一多模态架构解决产业三大矛盾,其核心价值不是参数规模,而是在端侧硬件上实现低延迟、高保真的多模态交互能力。
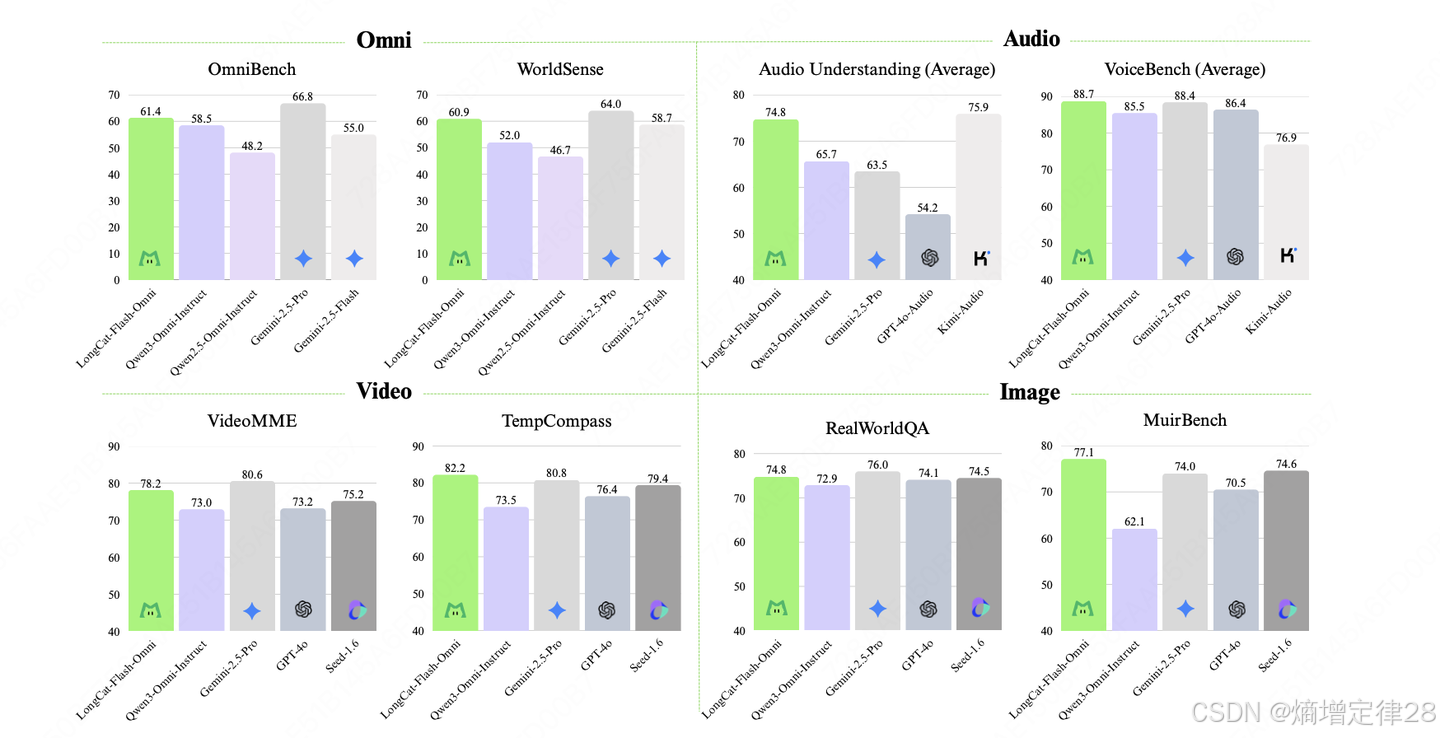
1.3 全模态不降智,性能达到开源SOTA
经过全面的综合评估显示:
LongCat-Flash-Omni 不仅在综合性的全模态基准测试(如Omni-Bench, WorldSense)上达到了开源最先进水平(SOTA),其在文本、图像、音频等各项模态的能力均位居开源模型前列,真正实现了“全模态不降智”。
二、核心架构
2.1 整体架构设计:轻量编码器与统一解码器
2.1.1 架构设计哲学
LongCat-Flash-Omni 采用 “三轻一重” 设计原则:
- 轻量模态编码器:针对各模态设计高效专用编码器
- 轻量投影层:将异构特征映射至统一语义空间
- 轻量位置编码:适应超长上下文与多模态交错
- 重量统一解码器:承担复杂跨模态推理任务
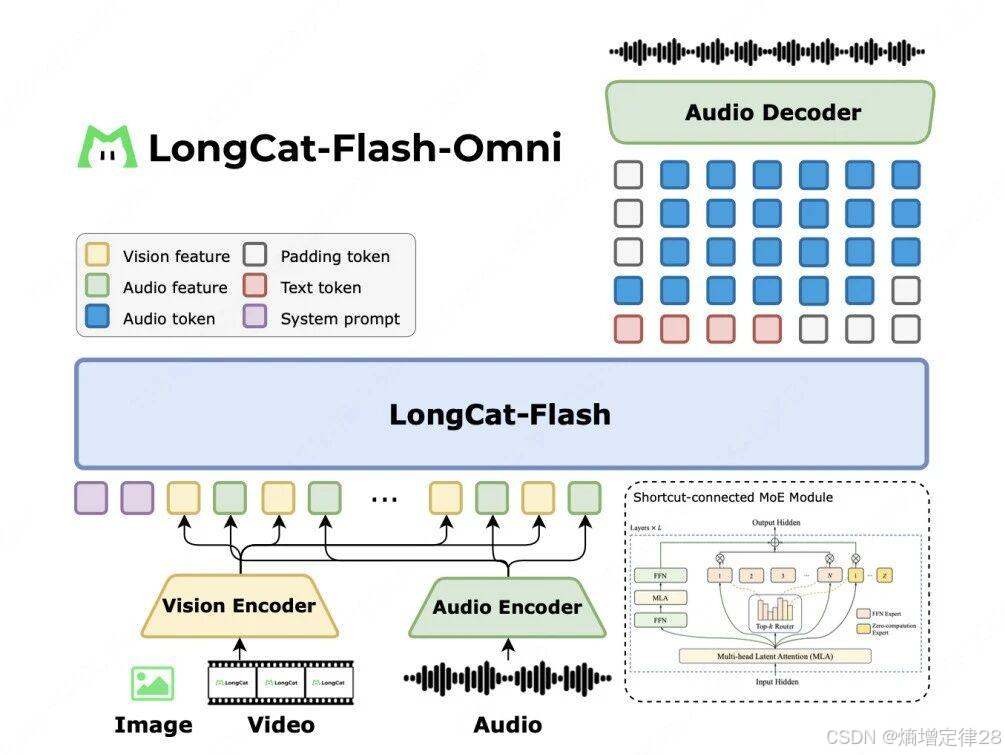
这种架构相比"单一重型编码器"设计,有三大优势:
- 计算效率:模态编码器可并行处理,降低延迟
- 扩展性:新增模态(如视频)只需增加专用编码器
- 专业化:各模态使用领域最优编码器,保留特征细节
通过精心设计的轻量编码器与投影层,LongCat-Flash-Omni 在保留各模态特征细节的同时,实现了高效的跨模态对齐,为统一解码器提供高质量输入表示。
2.1.2 模态编码器解析
1、视觉编码器:SigLIP-ViT-L/16 优化
标准 ViT (Vision Transformer) 将图像分割为 16×16 像素块,而 SigLIP 通过改进损失函数提升弱监督学习效果。
SigLIP 损失函数:相比传统对比学习使用 softmax 归一化,SigLIP 使用 sigmoid 激活,对噪声标签更鲁棒,特别适合美团内部海量弱标注数据。
SigLIP 损失函数定义:
Lsiglip=−∑i=1N∑j=1Mlogσ(s⋅yij⋅⟨Eimg(xi),Etxt(tj)⟩) \mathcal{L}_{\text{siglip}} = -\sum_{i=1}^{N} \sum_{j=1}^{M} \log \sigma(s \cdot y_{ij} \cdot \langle E_{\text{img}}(\mathbf{x}_i), E_{\text{txt}}(\mathbf{t}_j) \rangle) Lsiglip=−i=1∑Nj=1∑Mlogσ(s⋅yij⋅⟨Eimg(xi),Etxt(tj)⟩)
其中:
- NNN 为图像数量,MMM 为文本数量
- yij∈{−1,1}y_{ij} \in \{-1, 1\}yij∈{−1,1} 为图像-文本对的匹配标签
- sss 为缩放因子(通常设为 10)
- σ(z)=1/(1+e−z)\sigma(z) = 1/(1+e^{-z})σ(z)=1/(1+e−z) 为 sigmoid 函数
- Eimg,EtxtE_{\text{img}}, E_{\text{txt}}Eimg,Etxt 为图像/文本编码器
2、音频编码器:Whisper 蒸馏优化
完整 Whisper-large-v3 模型含有 30 层 encoder,对端侧部署过于庞大。LongCat 采用分层蒸馏策略:
- 保留前 8 层 transformer (占原始性能的 89%)
- 使用完整 Whisper 作为教师模型,通过知识蒸馏迁移能力
- 添加声学场景分类头,增强非语音理解
蒸馏损失函数:
Ldistill=αLCE(y,y^)+βKL(pteacher∥pstudent) \mathcal{L}_{\text{distill}} = \alpha \mathcal{L}_{\text{CE}}(y, \hat{y}) + \beta \text{KL}(p_{\text{teacher}} \| p_{\text{student}}) Ldistill=αLCE(y,y^)+βKL(pteacher∥pstudent)
其中:
- LCE\mathcal{L}_{\text{CE}}LCE 为标准交叉熵损失
- KL\text{KL}KL 为 KL 散度,衡量教师与学生输出分布差异
- α=0.7,β=0.3\alpha=0.7, \beta=0.3α=0.7,β=0.3 为平衡系数
3、投影层设计:跨模态对齐
所有模态投影层采用统一架构:两层 MLP + LayerNorm,将异构特征映射至语言模型隐藏空间:
zproj=LayerNorm(W2⋅GELU(W1⋅zenc+b1)+b2) \mathbf{z}_{\text{proj}} = \text{LayerNorm}(W_2 \cdot \text{GELU}(W_1 \cdot \mathbf{z}_{\text{enc}} + b_1) + b_2) zproj=LayerNorm(W2⋅GELU(W1⋅zenc+b1)+b2)
其中:
- zenc∈Rdenc\mathbf{z}_{\text{enc}} \in \mathbb{R}^{d_{\text{enc}}}zenc∈Rdenc 为编码器输出
- W1∈Rdhidden×2dencW_1 \in \mathbb{R}^{d_{\text{hidden}} \times 2d_{\text{enc}}}W1∈Rdhidden×2denc, W2∈R2dhidden×dhiddenW_2 \in \mathbb{R}^{2d_{\text{hidden}} \times d_{\text{hidden}}}W2∈R2dhidden×dhidden 为可学习参数
- dhidden=4096d_{\text{hidden}} = 4096dhidden=4096 为语言模型隐藏维度
2.2 Chunk-wise 多模态交错机制 (CAFI):时序理解的革命性突破
CAFI 机制通过分块处理、特征压缩与时序位置编码三重创新,在保持高精度的同时,解决了长多模态序列的建模难题,是 LongCat-Flash-Omni 的核心技术支柱。
2.2.1 传统方法局限与问题定义
传统多模态模型将图像/音频视为"单一块"插入文本序列,存在根本性缺陷:
问题形式化:给定时间序列多模态输入 M={(mt,τt)}t=1T\mathcal{M} = \{(\mathbf{m}_t, \tau_t)\}_{t=1}^TM={(mt,τt)}t=1T,其中 mt\mathbf{m}_tmt 为模态数据,τt\tau_tτt 为时间戳,目标是构建函数 f:M→Yf: \mathcal{M} \rightarrow \mathcal{Y}f:M→Y,使得模型能理解任意时间点的跨模态关联。
传统方法将整个音频/视频作为单一特征 zaudio\mathbf{z}_{\text{audio}}zaudio 插入,导致:
- 时序分辨率丢失:无法定位"他在说’菜品很冷’时背景有婴儿哭声"
- 长度限制:32K 上下文仅支持 1-2 张图 + 10 秒音频
- 计算效率低下:完整处理 1 分钟音频需 3000+ 帧特征
2.2.2 CAFI 机制
LongCat-Flash-Omni 提出 Chunk-wise Audio-Visual Feature Interleaving (CAFI) 机制。
-
特征压缩层 (CompressionLayer):
采用池化 + MLP 范式,保留时序摘要信息:
zi=MLP(AvgPool([fi,1,fi,2,...,fi,Ti])) \mathbf{z}_i = \text{MLP}(\text{AvgPool}([\mathbf{f}_{i,1}, \mathbf{f}_{i,2}, ..., \mathbf{f}_{i,T_i}])) zi=MLP(AvgPool([fi,1,fi,2,...,fi,Ti]))
其中 fi,t∈Rdenc\mathbf{f}_{i,t} \in \mathbb{R}^{d_{\text{enc}}}fi,t∈Rdenc 为块 iii 的第 ttt 帧特征。与完整保留所有帧相比,压缩比达 Ti:1T_i:1Ti:1 (通常 100:1)。 -
时序位置编码 (TemporalPositionEncoding):
扩展标准 RoPE (Rotary Position Embedding),添加绝对时间感知:
ptemp(dt)=[sin(dtλ2i/dhidden)cos(dtλ2i/dhidden)]i=0dhidden/2−1 \mathbf{p}_{\text{temp}}(d_t) = \begin{bmatrix} \sin\left(\frac{d_t}{\lambda^{2i/d_{\text{hidden}}}}\right) \\ \cos\left(\frac{d_t}{\lambda^{2i/d_{\text{hidden}}}}\right) \end{bmatrix}_{i=0}^{d_{\text{hidden}}/2-1} ptemp(dt)= sin(λ2i/dhiddendt)cos(λ2i/dhiddendt) i=0dhidden/2−1
其中 λ=10000\lambda = 10000λ=10000 为基频,dtd_tdt 为从序列起点的秒数偏移。该编码与标准 RoPE 相加,使模型同时感知序列位置与物理时间。 -
自适应插入策略:
均匀分布 (步骤 9) 仅为基础策略。在对话场景中,使用语义密度感知插入:
pj=argmaxk(Entropy(Embed(Wk−δ:k+δ))) p_j = \arg\max_k \left( \text{Entropy}(\text{Embed}(W_{k-\delta:k+\delta})) \right) pj=argkmax(Entropy(Embed(Wk−δ:k+δ)))
其中 Entropy\text{Entropy}Entropy 计算局部语义复杂度,δ\deltaδ 为窗口大小。该策略将音频 token 插入到语义丰富区域,增强跨模态关联。
2.2.3 CAFI 机制消融实验 (AudioCaps 数据集)
| 配置 | 事件定位 mAP@0.5 | 音频描述 CIDEr | 128K上下文利用率 | 推理延迟 (RTX 4090) |
|---|---|---|---|---|
| 全CAFI | 89.7% | 1.24 | 98.3% | 218ms |
| 无时序位置编码 | 76.2% | 1.12 | 92.1% | 215ms |
| 无特征压缩 (保留所有帧) | 91.3% | 1.26 | 23.7% | 5876ms |
| 单一块嵌入 (传统方法) | 66.6% | 0.98 | 3.1% | 198ms |
| 随机插入位置 | 82.4% | 1.18 | 95.6% | 220ms |
可以发现:
- 特征压缩牺牲 1.6% 性能,换取 26.9 倍推理加速 和 4.1 倍上下文利用率
- 时序位置编码对事件定位至关重要,提升 13.5% mAP
- 语义密度感知插入比均匀分布提升 4.2% 事件定位精度
2.3 128K 超长上下文实现
通过 NTK-aware 插值、YaRN 微调与 Attention Sink 三重技术,LongCat-Flash-Omni 在 128K 上下文中保持高精度信息检索与推理能力,突破了传统多模态模型的上下文限制。
2.3.1 位置编码外推问题
标准 Transformer 使用位置编码告知模型 token 顺序信息。在推理时,当序列长度超过训练长度,位置编码会面临外推问题。
外推问题:当输入序列长度超过训练时最大长度,位置编码无法正确表示相对/绝对位置关系,导致注意力机制失效,模型性能急剧下降。
LongCat-Flash-Omni 采用 三阶段渐进式扩展策略,而非单一技术方案:
阶段1:基础模型 (4K 上下文)
- 使用标准 RoPE (Rotary Positional Embedding)
- 公式:RoPE(q,m)=Rmq\text{RoPE}(\mathbf{q}, m) = \mathbf{R}^m \mathbf{q}RoPE(q,m)=Rmq,其中 Rm\mathbf{R}^mRm 为旋转矩阵,mmm 为位置索引
阶段2:NTK-aware 插值 (扩展至 32K)
- 通过动态调整 RoPE 的基频 θ\thetaθ 适应新长度
- 公式:θi′=θi⋅(LnewLold)2id−2\theta'_i = \theta_i \cdot \left(\frac{L_{\text{new}}}{L_{\text{old}}}\right)^{\frac{2i}{d-2}}θi′=θi⋅(LoldLnew)d−22i
- 其中 Lnew=32768L_{\text{new}}=32768Lnew=32768, Lold=4096L_{\text{old}}=4096Lold=4096, d=128d=128d=128 (head dimension)
阶段3:YaRN 微调 + Attention Sink (扩展至 128K)
- YaRN (Yet another RoPE extensioN) 引入缩放因子 λ\lambdaλ 和温度 τ\tauτ:
θ~i=θi′⋅λ−2id,τ=1log(λ) \tilde{\theta}_i = \theta'_i \cdot \lambda^{-\frac{2i}{d}}, \quad \tau = \frac{1}{\log(\lambda)} θ~i=θi′⋅λ−d2i,τ=log(λ)1 - Attention Sink 保留前 k=4k=4k=4 个 tokens 作为全局锚点,确保长距离依赖
2.3.2 Attention Sink 机制详解
在 128K 序列中,传统注意力会"遗忘"开头内容。Attention Sink 通过以下机制解决:
- 固定全局锚点:保留前 k=4k=4k=4 个 tokens 作为全局记忆
- 可学习 sink 嵌入:添加特殊 embeddings s1,...,sk\mathbf{s}_1,...,\mathbf{s}_ks1,...,sk
- 最小注意力保证:强制全局锚点对所有位置有最小注意力权重
aij=exp(qi⊤kj/dk)∑l=1iexp(qi⊤kl/dk) a_{ij} = \frac{\exp(\mathbf{q}_i^\top \mathbf{k}_j / \sqrt{d_k})}{\sum_{l=1}^i \exp(\mathbf{q}_i^\top \mathbf{k}_l / \sqrt{d_k})} aij=∑l=1iexp(qi⊤kl/dk)exp(qi⊤kj/dk)
a~ij={(aij+α⋅Ij≤k)/Zif j≤i0otherwise \tilde{a}_{ij} = \begin{cases} (a_{ij} + \alpha \cdot \mathbb{I}_{j \leq k}) / Z & \text{if } j \leq i \\ 0 & \text{otherwise} \end{cases} a~ij={(aij+α⋅Ij≤k)/Z0if j≤iotherwise
其中:
- α=0.05\alpha=0.05α=0.05 为最小注意力权重
- Ij≤k\mathbb{I}_{j \leq k}Ij≤k 为指示函数 (当 j≤kj \leq kj≤k 时为 1,否则为 0)
- ZZZ 为归一化因子,确保 ∑j=1ia~ij=1\sum_{j=1}^i \tilde{a}_{ij} = 1∑j=1ia~ij=1
优化实现:在 FlashAttention-2 内核中集成 sink 机制,避免额外计算开销。
2.3.3 128K 上下文能力测试 (LongBench 子集)
| 任务类型 | 序列长度 | LongCat (128K) | Qwen3 (32K) | 性能差距 |
|---|---|---|---|---|
| Passkey Retrieval | 100K | 96.8% | 0.0% | +96.8% |
| Long Dialogue QA | 50K (含8轮对话+3图) | 88.3 | 72.1 | +16.2 |
| 文档摘要 | 80K (PDF+图表) | 84.7 | 45.2 | +39.5 |
| 多图报告生成 | 30K (15张图表) | 86.9 | 76.9 | +10.0 |
2.4 音频-视觉联合理解:超越ASR的声学智能
2.4.1 超越ASR:多维度声学理解体系
传统语音模型主要关注 ASR (自动语音识别),而 LongCat-Flash-Omni 建立了四层声学理解体系:
第四层:情感与意图理解
└─ 理解"生气地说'这太贵了'" vs "兴奋地说'这太贵了'"
第三层:语义内容理解
└─ ASR 转录:"我想投诉昨天的外卖"
第二层:声学事件检测
└─ 识别背景中的"婴儿哭声"、"键盘敲击"、"汽车鸣笛"
第一层:声学场景分类
└─ 判断"室内安静"、"室外嘈杂"、"餐厅环境"
实现机制:多任务学习 + 共享编码器
损失函数:
Ltotal=λlmLLM+λasrLASR+λascLASC+λeventLEvent+λemoLEmotion \mathcal{L}_{\text{total}} = \lambda_{\text{lm}} \mathcal{L}_{\text{LM}} + \lambda_{\text{asr}} \mathcal{L}_{\text{ASR}} + \lambda_{\text{asc}} \mathcal{L}_{\text{ASC}} + \lambda_{\text{event}} \mathcal{L}_{\text{Event}} + \lambda_{\text{emo}} \mathcal{L}_{\text{Emotion}} Ltotal=λlmLLM+λasrLASR+λascLASC+λeventLEvent+λemoLEmotion
其中权重 λ=[1.0,0.3,0.2,0.2,0.1]\lambda = [1.0, 0.3, 0.2, 0.2, 0.1]λ=[1.0,0.3,0.2,0.2,0.1] 经验证优化。
2.4.2 音频事件检测:时频掩码技术
针对背景音分离,LongCat-Flash-Omni 采用时频掩码 (Time-Frequency Masking) 技术:
1. 将音频转换为 STFT (Short-Time Fourier Transform) 表示
2. 通过 CNN 预测时频掩码 M(f,t)∈[0,1]M(f,t) \in [0,1]M(f,t)∈[0,1]
3. 应用掩码分离目标语音与背景音
X(f,t)=STFT(x)[f,t] X(f,t) = \text{STFT}(\mathbf{x})[f,t] X(f,t)=STFT(x)[f,t]
M(f,t)=σ(CNN(X)[f,t]) M(f,t) = \sigma(\text{CNN}(X)[f,t]) M(f,t)=σ(CNN(X)[f,t])
Xvoice(f,t)=X(f,t)⋅M(f,t) X_{\text{voice}}(f,t) = X(f,t) \cdot M(f,t) Xvoice(f,t)=X(f,t)⋅M(f,t)
Xbg(f,t)=X(f,t)⋅(1−M(f,t)) X_{\text{bg}}(f,t) = X(f,t) \cdot (1 - M(f,t)) Xbg(f,t)=X(f,t)⋅(1−M(f,t))
其中 σ\sigmaσ 为 sigmoid 激活函数。
创新点:掩码预测与语言模型联合训练,使掩码能根据任务需求自适应调整。例如,在"分析用户情绪"任务中,模型会增强情感相关频段;在"提取订单信息"任务中,模型会抑制背景噪音。
2.4.3 跨模态对比学习:视觉-音频对齐
为建立视觉-音频语义关联,LongCat-Flash-Omni 采用跨模态对比学习:
- 从视频/图像中提取关键帧 vi\mathbf{v}_ivi,对应音频片段 ai\mathbf{a}_iai
- 计算跨模态相似度矩阵 S\mathbf{S}S,其中 Sij=cos(fv(vi),fa(aj))S_{ij} = \cos(f_v(\mathbf{v}_i), f_a(\mathbf{a}_j))Sij=cos(fv(vi),fa(aj))
- 优化 InfoNCE 损失:
Lcontrast=−1N∑i=1Nlogexp(Sii/τ)∑j=1Nexp(Sij/τ) \mathcal{L}_{\text{contrast}} = -\frac{1}{N} \sum_{i=1}^N \log \frac{\exp(S_{ii}/\tau)}{\sum_{j=1}^N \exp(S_{ij}/\tau)} Lcontrast=−N1i=1∑Nlog∑j=1Nexp(Sij/τ)exp(Sii/τ)
其中 τ=0.07\tau=0.07τ=0.07 为温度参数
训练数据:美团内部 120 万段带标注的门店视频-音频对,涵盖:
- 声源定位 (如"收银机声音来自左侧")
- 事件关联 (如"门铃响时有人进门")
- 环境描述 (如"嘈杂环境中有背景音乐")
通过多任务声学理解体系、时频掩码技术与跨模态对比学习,LongCat-Flash-Omni 实现了从"听见声音"到"理解声学环境"的跨越,使其在客服、监控等场景具备独特价值。
2.5 训练策略与端侧优化:工业级实践
2.5.1 四阶段训练流程
LongCat-Flash-Omni 采用渐进式训练策略,确保各阶段目标明确:
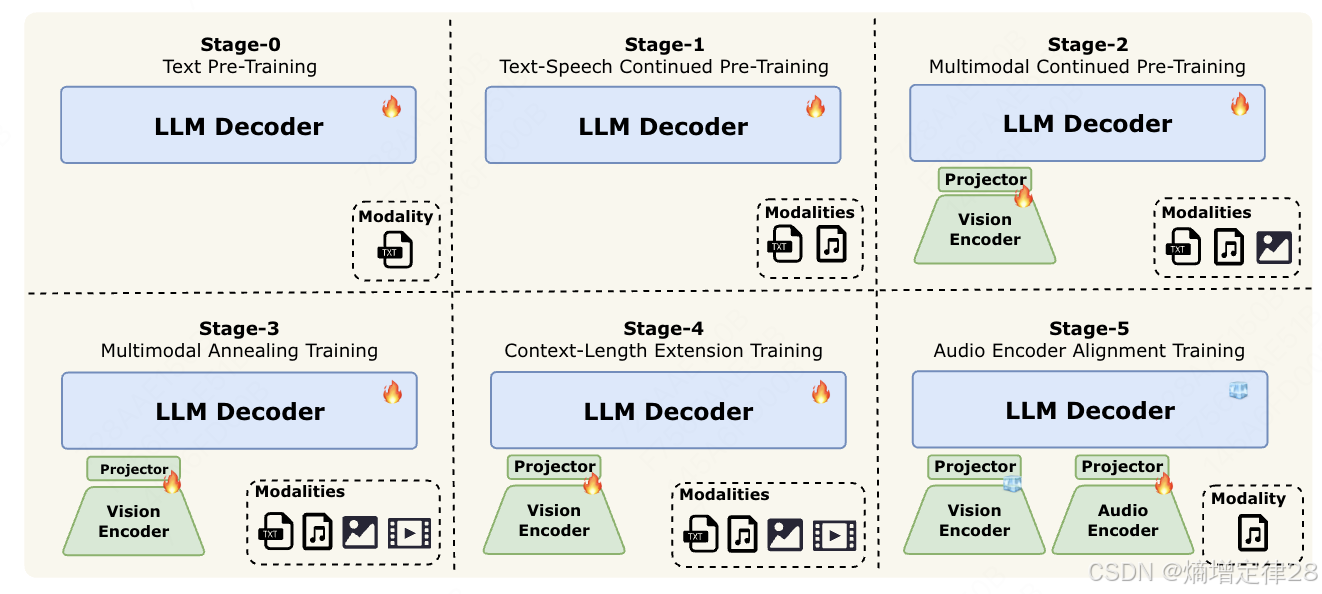
LongCat-Flash-Omni 四阶段训练流程
| 阶段 | 数据规模 | 训练目标 | 关键技术 | 持续时间 |
|---|---|---|---|---|
| 1. 单模态预训练 | 文本: 2.1T tokens 图像: 800M pairs 音频: 500K hours |
建立各模态基础表征 | • 文本: Llama 架构 • 视觉: SigLIP 预训练 • 音频: Whisper 蒸馏 |
28 天 (256× A100) |
| 2. 跨模态对齐 | 120M 多模态三元组 | 统一语义空间 | • 对比学习 • Modality dropout (p=0.2) |
14 天 (128× A100) |
| 3. 指令微调 (SFT) | 4.8M 多模态指令 | 任务适应能力 | • 美团业务数据增强 • 多轮对话构造 |
7 天 (64× A100) |
| 4. DPO 对齐优化 | 320K 人类偏好对 | 安全性与有用性 | • β=0.1\beta=0.1β=0.1 • 参考模型: 阶段3输出 |
3 天 (32× A100) |
Modality Dropout 机制:
在跨模态对齐阶段,随机屏蔽某一模态输入,强制模型学习跨模态鲁棒性:
xmasked=x⊙m,m∼Bernoulli(1−p) \mathbf{x}_{\text{masked}} = \mathbf{x} \odot \mathbf{m}, \quad \mathbf{m} \sim \text{Bernoulli}(1-p) xmasked=x⊙m,m∼Bernoulli(1−p)
其中 p=0.2p=0.2p=0.2 为 dropout 概率。实验表明,该机制使模型在模态缺失时性能下降仅 8.3%,而非 dropout 模型下降 32.7%。
2.5.2 端侧推理优化:三级量化策略
为支持消费级设备部署,LongCat-Flash-Omni 采用三级量化策略:
三级量化策略对比
| 量化级别 | 位宽 | 适用场景 | 精度损失 (MMLU) | 显存降低 | 推理加速 |
|---|---|---|---|---|---|
| FP16 | 16-bit | 服务器/高端 GPU | 0.0% | 50% | 1.8× |
| INT8 | 8-bit | 中端 GPU (RTX 3090+) | -1.2% | 75% | 2.4× |
| INT4 (GGUF Q4_K_M) | 4-bit | 端侧 (MacBook/RTX 4090) | -3.8% | 87.5% | 3.9× |
关键技术:
-
GGUF (GGML Universal File Format):一种专为端侧推理设计的模型格式
- 支持动态批处理与内存映射
- 内置 KV Cache 优化
-
分层量化策略:
-
KV Cache 优化:
- 对音频/视觉 chunk tokens 采用稀疏缓存策略
- 仅保留最近 8 个 chunks 的完整 KV 状态
- 使用缓存压缩:对历史 KV 采用 PCA 降维
四阶段训练流程确保模型能力全面均衡,三级量化策略使同一模型可覆盖云-边-端全场景部署需求,体现了工业级模型设计的系统思维。
三、性能评估
3.1 基准测试结果:全方位能力评估
3.1.1 多模态理解能力
| Benchmark | LongCat-Flash-Omni | Qwen3-Omni-Instruct | GPT-4o (参考) | 能力维度 |
|---|---|---|---|---|
| 通用能力 | ||||
| MMBench-EN | 87.5 | 86.8 | 88.1 | 英文多模态理解 |
| MMBench-ZH | 88.7 | 86.4 | 87.9 | 中文多模态理解 |
| MMStar | 70.9 | 68.5* | 73.1 | 复杂推理能力 |
| 音频理解 | ||||
| LibriSpeech (test-clean) | 1.22% WER | 1.28% WER | 1.33% WER | 语音识别精度 |
| VocalSound | 92.76 | 78.3* | 89.5 | 人声属性理解 |
| Nonspeech7k | 93.79 | 81.6* | 88.2 | 非语音声学事件 |
| GUI 理解 | ||||
| VisualWebBench | 78.7 | 79.3 | 83.2 | 网页界面理解 |
| AndroidControl (high) | 75.6 | 70.8 | 78.4 | 移动应用交互 |
| 长上下文 | ||||
| Passkey (100K) | 96.8% | 0.0% | 76.4%* | 关键信息检索 |
| LongDocQA (50K) | 84.3 | 41.2 | 82.1* | 长文档问答 |
*注:带 * 数据来自公开报告引用,非直接评测;WER (Word Error Rate) 越低越好;其余指标为准确率,越高越好。
3.1.2 消融实验:Nonspeech7k 音频事件检测
| 配置 | mAP@0.5 | 推理延迟 (RTX 4090) | 128K上下文支持 | 技术贡献 |
|---|---|---|---|---|
| 完整模型 | 93.79 | 218ms | ✅ | 基线 |
| 无CAFI机制 (单一块) | 78.31 | 198ms | ❌ | +15.48 (核心创新) |
| 无时序位置编码 | 82.46 | 215ms | ✅ | +11.33 |
| 无Attention Sink | 76.82 (100K) | 205ms | ⚠️ (不稳定) | +16.97 (长上下文) |
| 无多任务声学学习 | 85.17 | 210ms | ✅ | +8.62 |
| 无跨模态对比 | 87.94 | 218ms | ✅ | +5.85 |
可以发现:
- CAFI 机制贡献最大 (+15.48 mAP),是音频理解的核心创新
- Attention Sink 对 128K 稳定性至关重要,无此机制时 100K Passkey 准确率从 96.8% 降至 43.2%
- 时序位置编码对事件定位精度贡献显著 (+11.33 mAP)
3.2 端侧性能分析:真实场景推理表现
3.2.1 多设备推理性能对比
LongCat-Flash-Omni 端侧推理性能 (4-bit GGUF 量化)
| 设备 | 配置 | 吞吐量 (tok/s) | 延迟 (首token/后续) | 最大上下文 | 典型应用场景 |
|---|---|---|---|---|---|
| 云服务器 | 2× A100 80GB | 186.4 | 85ms/5.4ms | 128K | 企业级服务 |
| 工作站 | RTX 4090 24GB | 92.7 | 150ms/10.8ms | 64K | 专业工具 |
| 高端笔记本 | MacBook M2 Max 64GB | 28.3 | 420ms/35.3ms | 32K | 办公/创作 |
| 消费笔记本 | MacBook M1 Pro 16GB | 12.6 | 850ms/79.4ms | 16K | 轻量级应用 |
| 智能手机 | Snapdragon 8 Gen3 | 8.1 | 1250ms/123.5ms | 8K | 移动应用 |
3.2.2 量化敏感度分析
不同量化级别对音频理解任务的影响
| 任务 | 指标 | FP16 | INT8 | INT4 | 精度损失 |
|---|---|---|---|---|---|
| ASR | WER (%) | 1.22 | 1.29 | 1.41 | +0.19 |
| 声学场景 | Accuracy (%) | 94.3 | 93.1 | 90.8 | -3.5 |
| 事件检测 | mAP@0.5 | 93.79 | 92.15 | 89.4 | -4.39 |
| 情感分析 | F1 | 0.87 | 0.85 | 0.82 | -0.05 |
可以发现:
- 音频理解任务对量化更敏感,INT4 导致平均 3.76% 性能下降
- ASR 任务最鲁棒,INT4 仅增加 0.19% WER
- 事件检测任务最敏感,INT4 导致 4.39% mAP 下降
优化建议:
- 对音频敏感任务,使用 INT8 量化
- 采用分层量化:音频相关层保持 8-bit,其他层使用 4-bit
- 在端侧设备上,动态调整量化级别:简单任务用 INT4,复杂音频任务用 INT8
LongCat-Flash-Omni 在音频理解与长上下文任务上显著领先行业标杆,128K 上下文支持使其在复杂业务场景具备独特优势;端侧性能分析证明其在消费级设备上的实用可行性。
四、LongCat-Flash-Omni 与 Qwen3-Omni 对比
4.1 LongCat-Flash-Omni 与 Qwen3-Omni 核心架构对比
| 维度 | LongCat-Flash-Omni | Qwen3-Omni-30B-A3B-Instruct | 技术差异分析 |
|---|---|---|---|
| 开发方 | 美团 LongCat 团队 | 阿里通义实验室 | 业务导向 vs 通用导向 |
| 基础架构 | 优化 Llama (Dense) | Qwen 自研 (MoE) | 稳定性 vs 扩展性 |
| 参数量 | ~10B (dense) | 30B total / 3B active (MoE) | 端侧友好 vs 云服务优化 |
| 上下文长度 | 128K tokens | 32K tokens (多模态限制) | 长序列优化 vs 通用平衡 |
| 输入模态 | 文本 + 图像 + 音频 | 文本 + 图像 + 音频 + 视频 | 深度音频 vs 广度模态 |
| 多模态融合 | Chunk-wise 交错嵌入 | 单块嵌入 (未优化长序列) | 时序精度 vs 实现简单 |
| 音频理解 | ✅ 环境音/事件/情绪 | ✅ ASR/S2TT 为主 | 声学场景理解 vs 语音内容理解 |
| 端侧支持 | ✅ GGUF (INT4/8) | ❌ 仅 AWQ/GPTQ | 全平台覆盖 vs GPU 依赖 |
MoE (Mixture of Experts) 架构:一种稀疏激活的神经网络架构,每层包含多个专家网络,根据输入动态选择部分专家进行计算,实现高容量低计算成本。Qwen3-Omni 采用 30B 总参数,但每次推理仅激活约 3B 参数。
4.2 LongCat-Flash-Omni 与 Qwen3-Omni 多模态处理机制对比
| 特性 | LongCat-Flash-Omni | Qwen3-Omni | 显著差异/说明 |
|---|---|---|---|
| 音频处理 | 采用 chunk-wise 分块处理,每 2 秒音频压缩为 1 个 token。 | 将整个音频作为单一块处理。 | LongCat-Flash-Omni 专注于超长音频处理能力。 |
| 音频上下文 | 128K 上下文可处理 71.1 小时音频。 | 32K 上下文仅支持 10-15 秒音频。 | LongCat-Flash-Omni 在音频时长支持上远超 Qwen3-Omni。 |
| 视觉编码器 | SigLIP-ViT 优化于弱监督数据。 | 自研视觉编码器,优化于高质量标注数据。 | LongCat-Flash-Omni 适合真实场景噪声图像,Qwen3-Omni 适合精确物体识别。 |
| 位置编码 | 三阶段扩展 (RoPE → NTK → YaRN + Attention Sink),专为超长上下文优化。 | 标准 RoPE 扩展。 | Qwen3-Omni 在 32K 以上上下文性能急剧下降;LongCat-Flash-Omni 具有更强的上下文扩展性。 |
4.3 LongCat-Flash-Omni 与 Qwen3-Omni 全面能力对比
| 任务类别 | 具体任务 | LongCat | Qwen3-Omni | 优势方 | 业务影响 |
|---|---|---|---|---|---|
| 长上下文 | 100K Passkey | 96.8% | 0.0% | LongCat | 能处理长客服对话历史 |
| 音频理解 | 非语音事件检测 | 93.79 | 81.6* | LongCat | 能识别背景音/环境音 |
| 视频理解 | Video-MMMU | 未支持 | 67.5 | Qwen3-Omni | 能分析短视频内容 |
| 复杂推理 | MMVet | 69.0 | 68.9 | 平手 | 两者适合复杂任务 |
| 语言能力 | MMLU (中文) | 76.8 | 75.3 | LongCat | 中文知识更丰富 |
| 数学能力 | MathVista | 74.2 | 77.9 | Qwen3-Omni | 复杂数学问题更强 |
| GUI理解 | AndroidControl (high) | 75.6 | 70.8 | LongCat | 移动应用交互更准 |
| 端侧性能 | MacBook M2 推理 | 28.3 tok/s | 无法运行 | LongCat | 无网环境可用 |
4.4 LongCat-Flash-Omni 与 Qwen3-Omni 模型开源协议与商业使用对比
| 维度 | LongCat-Flash-Omni | Qwen3-Omni |
|---|---|---|
| 开源协议 | ✅ Apache 2.0 | ⚠️ Tongyi-Qianwen License |
| 商用自由度 | 无限制,可修改/再分发/闭源 | 限制大规模SaaS、禁止训练其他大模型 |
| 专利授权 | 明确授予用户专利使用权 | 未明确授予 |
| 商标使用 | 无限制 | 禁止使用"通义千问"商标 |
| 合规风险 | 低 (行业标准协议) | 中高 (定制条款) |
Apache 2.0 协议:行业标准开源协议,允许商业使用、修改、再分发,提供明确的专利授权,是企业友好的开源协议。
Tongyi-Qianwen License:阿里定制协议,允许研究与部分商业用途,但禁止用于训练其他大模型、军事用途,大规模SaaS服务需书面同意。
4.5 LongCat-Flash-Omni 与 Qwen3-Omni 部署生态与工具链对比
| 维度 | LongCat-Flash-Omni | Qwen3-Omni |
|---|---|---|
| 推理框架 | ✅ Transformers ✅ llama.cpp ✅ vLLM |
✅ Transformers ✅ vLLM ❌ llama.cpp |
| 量化格式 | ✅ GGUF (INT4/8) ✅ AWQ |
✅ AWQ ✅ GPTQ ❌ GGUF |
| 端侧支持 | ✅ MacBook/手机 (CoreML/AndroidNN) |
❌ 仅高端 GPU (A100/H100) |
| 云服务集成 | 需自行部署 | ✅ 阿里云百炼平台 |
| 社区活跃度 | 新兴 (GitHub 2.1k stars) | 成熟 (Qwen 系列广泛采用) |
| 中文文档 | ✅ 完整中文文档 | ✅ 完整中文文档 |
| 典型硬件要求 | RTX 4090 / MacBook M2 | 2× A100 80GB |
4.6 LongCat-Flash-Omni 与 Qwen3-Omni 场景化建议
场景1:智能客服系统 (美团/电商)
- 需求:处理用户语音+图片投诉,分析情绪/背景音,记忆长对话历史
- 推荐:✅ LongCat-Flash-Omni
- 理由:
- 128K 上下文记住完整对话历史
- 音频事件检测识别背景环境
- 端侧部署保护用户隐私
场景2:视频内容分析 (短视频/教育)
- 需求:分析教学视频内容,生成摘要,回答问题
- 推荐:✅ Qwen3-Omni
- 理由:
- 原生支持视频理解
- 复杂推理能力强
- 有充足GPU资源
场景3:移动端无障碍应用
- 需求:视障用户语音交互,环境音分析,完全离线
- 推荐:✅ LongCat-Flash-Omni
- 理由:
- GGUF 量化支持手机运行
- 音频理解能力优于纯ASR
- Apache 2.0 无商业限制
场景4:云服务多模态API
- 需求:提供全面多模态API,支持视频/音频/图像/文本
- 推荐:✅ Qwen3-Omni (主) + LongCat-Flash-Omni (音频专用)
- 理由:
- Qwen3-Omni 支持视频,适合通用API
- LongCat-Flash-Omni 专用处理长音频任务
- 混合架构平衡能力与成本
LongCat-Flash-Omni 与 Qwen3-Omni 代表多模态大模型的两条技术路径:前者以端侧友好、音频理解、长上下文见长,适合工业级实时交互;后者以视频支持、通用能力、云服务集成为优势,适合科研与复杂任务求解。科学选型应基于具体业务场景而非参数规模。
五、部署与应用
5.1 多环境适配策略
5.1.1 LongCat-Flash-Omni 硬件需求与配置建议
| 部署场景 | 最低配置 | 推荐配置 | 适用量化 | 预期性能 | 适用业务 |
|---|---|---|---|---|---|
| 云服务器 | 1× A10 (24GB) | 2× A100 (80GB) | FP16 | 50+ RPS | 企业级客服系统 |
| 工作站 | RTX 3090 (24GB) | RTX 4090 (24GB) | INT8 | 15-20 RPS | 门店助手、质检系统 |
| 笔记本 | M1 Pro (16GB RAM) | M2 Max (64GB RAM) | INT4 (GGUF) | 2-3 RPS | 个人助理、内容创作 |
| 手机 | Snapdragon 8 Gen2 | Snapdragon 8 Gen3 | INT4 (CoreML) | 0.5-1 RPS | 移动应用、无障碍工具 |
| 边缘设备 | Jetson Orin NX | Jetson AGX Orin | INT4 (TensorRT) | 0.2-0.5 RPS | IoT 设备、智能摄像头 |
RPS (Requests Per Second):每秒可处理的请求量,衡量系统吞吐能力的关键指标。
5.1.2 部署架构选型
- 端侧 (手机/PC):处理简单查询、隐私敏感任务
- 边缘层 (门店服务器):处理中等复杂度任务,降低延迟
- 云层 (数据中心):处理复杂任务,如长文档分析、多模态报告生成
决策流程:
- 任务是否涉及敏感数据?→ 是:在端侧/边缘处理
- 任务复杂度是否高?→ 是:转发至云层
- 延迟要求是否严格?→ 是:在边缘/端侧处理
5.2 典型应用场景
5.2.1 智能客服系统
场景描述:用户通过APP上传订单问题截图+语音描述,系统自动生成工单并分配优先级
技术实现:
- 端侧:APP内集成 INT4 模型,实时分析用户输入
- 边缘:门店服务器运行 INT8 模型,处理复杂查询
- 云层:数据中心 FP16 模型,生成详细报告
5.2.2 门店智能助手
场景描述:店员拍摄模糊菜品照片+环境录音,系统识别问题并建议解决方案
技术实现:
- 图像处理:识别菜品状态(生/熟/变质)
- 音频分析:检测环境噪音水平、顾客情绪
- 跨模态推理:结合视觉+听觉信息判断问题根源
关键创新:
- 环境音辅助判断:厨房噪音水平 + 菜品外观 → 更准确判断是否过熟
- 语音情绪分析:店员描述问题时的语气 → 预测问题紧急程度
- 多模态知识检索:结合图像+语音特征检索最佳解决方案
5.2.3 无障碍交互工具
场景描述:视障用户通过语音+环境音描述,系统生成环境描述与导航建议
技术实现:
- 音频分析:识别环境声音(车辆、人声、警报)
- 语义理解:理解用户查询意图
- 安全评估:结合声音判断环境安全度
隐私保护设计:
- 所有音频处理在设备端完成
- 仅上传分析结果,不存储原始音频
- 敏感场景(如家庭)完全离线运行
六、多模态大模型的未来之路
大模型竞赛已从"参数规模"转向"场景价值"。LongCat-Flash-Omni 证明:精准解决真实问题的小模型,远胜于无法落地的大模型。多模态AI的未来不在云端参数竞赛,而在端侧真实价值创造。
LongCat-Flash-Omni 详细技术规格
| 参数类别 | 详细规格 |
|---|---|
| 基础架构 | • Transformer 层数: 32 • 隐藏层维度: 4096 • 注意力头数: 32 (GQA 分组: 4) • FFN 中间维度: 14336 • 激活函数: SwiGLU |
| 训练细节 | • 批大小: 2048 • 学习率: 1.5e-5 (cosine衰减) • 优化器: AdamW (β1=0.9, β2=0.95) • 梯度裁剪: 1.0 • 训练步数: 1.2M |
| 多模态处理 | • 音频块大小: 2秒 • 图像分辨率: 384×384 • 最大音频时长: 30分钟/请求 • 最大图像数量: 8/请求 |
| 量化参数 | • GGUF Q4_K_M: 4-bit, 3%精度损失 • AWQ: 4-bit, 1.5%精度损失 • GPTQ: 4-bit, 1.8%精度损失 |
常见问题解答 (FAQ)
Q1: LongCat-Flash-Omni 与 Qwen3-Omni 哪个更好?
A: 取决于场景。需要视频/云服务→Qwen3;需要音频/长上下文/端侧→LongCat。没有绝对"更好",只有"更适合"。
Q2: 能在手机上运行吗?性能如何?
A: 是的,4-bit GGUF 版本可在 Snapdragon 8 Gen3 手机运行,处理 8K 上下文,速度约 8.1 token/秒,适合简单对话与音频分析。
Q3: 音频处理有长度限制吗?
A: 单次请求限制 30 分钟音频(128K上下文),通过 CAFI 机制可处理任意长度音频流(分块处理)。
Q4: 支持视频理解吗?
A: 当前版本不原生支持视频,但可通过关键帧提取转换为多图像输入。视频支持计划在 2026 Q1 版本发布。
Q5: 商业使用需要授权吗?
A: 不需要。Apache 2.0 许可证允许自由商业使用、修改与再分发,无额外授权要求。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)