stabilityai开源音频扩散生成小模型:stable-audio-open-small
Stable Audio Open Small 是一种基于潜在扩散模型的音频生成工具,能够根据文本提示生成最长11秒、44.1kHz的立体声音频。该模型结合了自编码器、T5文本嵌入和基于变换器的扩散模型(DiT),主要用于音乐和音频生成的研究与实验。训练数据集包含来自Freesound和Free Music Archive的音频记录,经过严格的版权审核。模型在Stability AI Commun
Stable Audio Open Small 模型概述
一、模型介绍
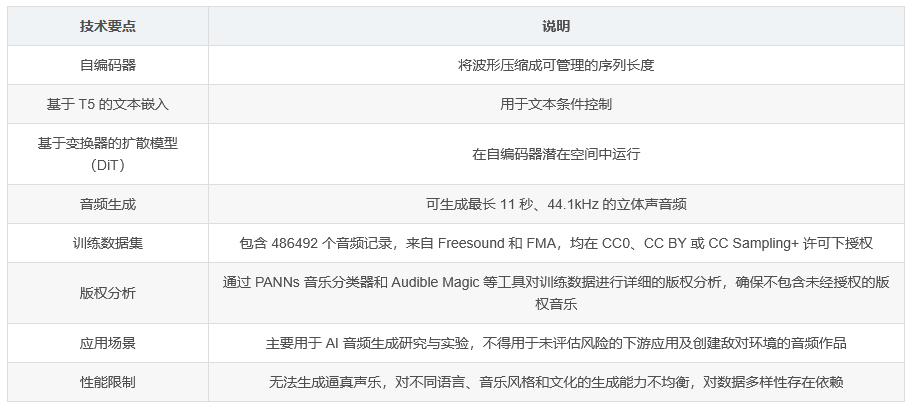
Stable Audio Open Small 是一种基于潜在扩散模型(latent diffusion model)的音频生成模型,主要由三个组件构成:用于将波形压缩成可管理序列长度的自编码器、基于 T5 的文本嵌入用于文本条件控制,以及在自编码器潜在空间中运行的基于变换器的扩散模型(DiT)。它能够根据文本提示生成时长可变(最长 11 秒)、44.1kHz 的立体声音频。该模型主要使用 English 语言进行训练,并在 Stability AI Community License 下授权,用于商业用途时需遵循特定许可要求。
二、模型运用
Stable Audio Open Small 模型通常结合 stable-audio-tools 库进行推理。使用时,需先下载模型,设置文本和时间条件,然后通过 generate_diffusion_cond 函数生成音频输出。在生成过程中,可指定步数、采样类型等参数。生成的音频输出需要进行重新排列、峰值归一化、裁剪、转换为 int16 格式,最后保存为音频文件。在实现过程中,主要运用了 PyTorch 等库进行模型操作和音频处理。
三、模型训练数据集
该模型的训练数据集包含 486492 个音频记录,其中 472618 个来自 Freesound,13874 个来自 Free Music Archive(FMA)。所有音频文件均在 CC0、CC BY 或 CC Sampling+ 许可下授权。在训练前,对数据集进行了详细的版权分析,以确保不包含未经授权的版权音乐。对于 Freesound 中的音乐样本,使用 PANNs 音乐分类器进行识别,将至少 30 秒且预测属于音乐相关类的概率超过 0.15 的样本发送给 Audible Magic 进行进一步的版权检测,最终移除了疑似版权音乐,剩下 266324 个 CC0、194840 个 CC BY 和 11454 个 CC Sampling+ 音频记录用于自编码器训练。对于 FMA 子集,主要通过元数据搜索和人工审核的方式,确保不包含版权内容,最终保留 8967 个 CC BY 和 4907 个 CC0 轨道用于训练。
四、模型用途与限制
使用范围
Stable Audio Open Small 主要用于基于 AI 的音乐和音频生成研究与实验,包括:
-
研究工作:探索生成模型的局限性,推动科学进步。
-
音频生成实验:机器学习从业者和艺术家通过文本引导生成音乐和音频,探索生成式 AI 模型的能力。
禁止用途
该模型不得在未进行进一步风险评估和缓解措施的情况下用于下游应用。同时,不得故意用于创建或传播会导致人们处于敌对或疏远环境的音频或音乐作品。
限制与偏见
-
生成能力限制:无法生成逼真的声乐。
-
语言限制:主要基于英语描述进行训练,在其他语言中的表现不佳。
-
音乐风格不均衡:对所有音乐风格和文化的生成能力不均衡,更擅长生成音效和现场录音而非音乐。
-
文本提示要求:有时难以评估何种文本描述能提供最佳的生成效果,可能需要进行提示工程以获得满意结果。
-
数据多样性问题:训练数据的来源可能存在多样性不足,所有文化在数据集中并非平等代表,导致模型在生成各类音乐类型和音效方面的表现不均衡,生成的样本会反映训练数据中的偏见。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献145条内容
已为社区贡献145条内容

所有评论(0)