基于LLM的自动文化基因算法求解可变子批次批量流混合流水车间调度问题
清华大学王凌教授团队在《IEEE Transactions on Evolutionary Computation》发表创新研究,提出LLM驱动的协同进化模因算法框架(LLMMA),解决航空制造中可变子批次混合流水车间调度(LHJSV)难题。该研究将复杂调度问题分解为工序排序、批次分割与机器选择两个子问题,通过协同进化机制优化决策。实验表明,LLMMA框架显著优于传统方法,在解空间复杂度高达阶乘级
之前就分享过大模型(LLM)结合进化算法的文章,今天要解析的这篇文章,我认为是直接用于求解车间调度问题的开创性文章。
获取更多资讯,赶快关注公众号《智能制造与智能调度》吧!
摘要
清华大学王凌教授团队《IEEE Transactions on Evolutionary Computation》发表突破性研究,提出一种LLM驱动的协同进化模因算法框架(LLMMA),解决航空制造中可变子批次混合流水车间调度(LHJSV) 难题。
问题定义:LHJSV调度挑战
-
三大子问题耦合
- 工序排序(Operation Sequencing)
- 批次分割(Lot-Splitting)
- 并行机选择(Machine Selection)
-
数学模型

-
问题示例
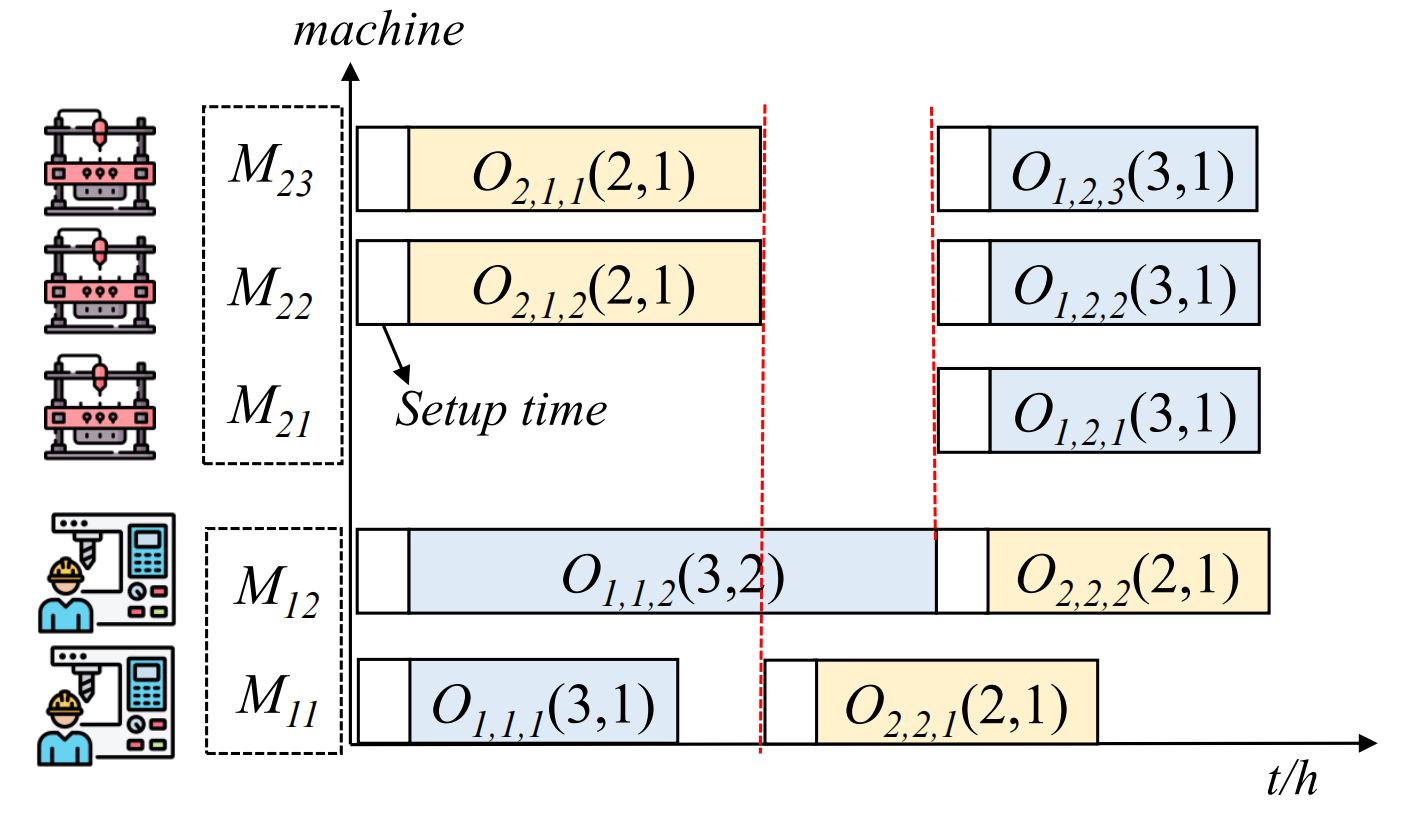
传统方法局限性
六类方法对比:
| 方法类型 | 代表算法 | 缺陷 |
|---|---|---|
| 精确方法 | 线性规划 | 仅适用于小规模问题 |
| 启发式方法 | 迭代贪婪搜索 | 不稳定且易早熟收敛 |
| 邻域搜索 | 专家设计 | 人工工作量大 |
| 元启发式方法 | 遗传算法 | 缺乏问题特定搜索策略 |
| 强化学习 | 深度Q网络 | 训练成本高、泛化性差 |
| 混合算法 | 文化基因算法 | 设计过程复杂且依赖人工 |
| LLM方法 | EoH | 无法处理复杂约束 |
解空间复杂度:
解空间总量=(∑i=1NNi)!∏i=1NNi!⏟工序排序×∏i=1N∏j=1NiC(Bi+NtM−1,NtM−1)⏟批次分割与机器选择\text{解空间总量} = \underbrace{\frac{(\sum_{i=1}^{N}N_i)!}{\prod_{i=1}^{N}N_i!}}_{\text{工序排序}} \times \underbrace{\prod_{i=1}^{N}\prod_{j=1}^{N_{i}} C(B_{i} + N_{t}^{M} -1, N_{t}^{M} -1)}_{\text{批次分割与机器选择}}解空间总量=工序排序
∏i=1NNi!(∑i=1NNi)!×批次分割与机器选择
i=1∏Nj=1∏NiC(Bi+NtM−1,NtM−1)
LLMMA框架设计
动机
先前研究[28]提出的框架仅适用于在线装箱、置换流水车间调度等简单组合优化问题,这些任务的逻辑约束较易通过提示描述。然而,面对LHJSV等复杂车间调度问题时,其约束条件和问题结构显著复杂化。直接应用[28]的框架会导致提示过长且复杂,可能引发LLM理解偏差,进而生成错误算法。受“分而治之”思想启发,本文提出启发式协同进化框架,以自动化设计针对复杂调度问题的启发式规则。
框架设计
-
问题分解
- 将LHJSV拆解为两个子问题:
(1) 工序排序(Operation Sequencing)
(2) 批次分割与机器选择(Lot-Splitting & Machine Selection) - 为每个子问题设计独立的提示模板(Prompts)
- 将LHJSV拆解为两个子问题:
-
协同优化机制
- 通过简化任务复杂度、缩短LLM输入长度,提升算法生成可行性
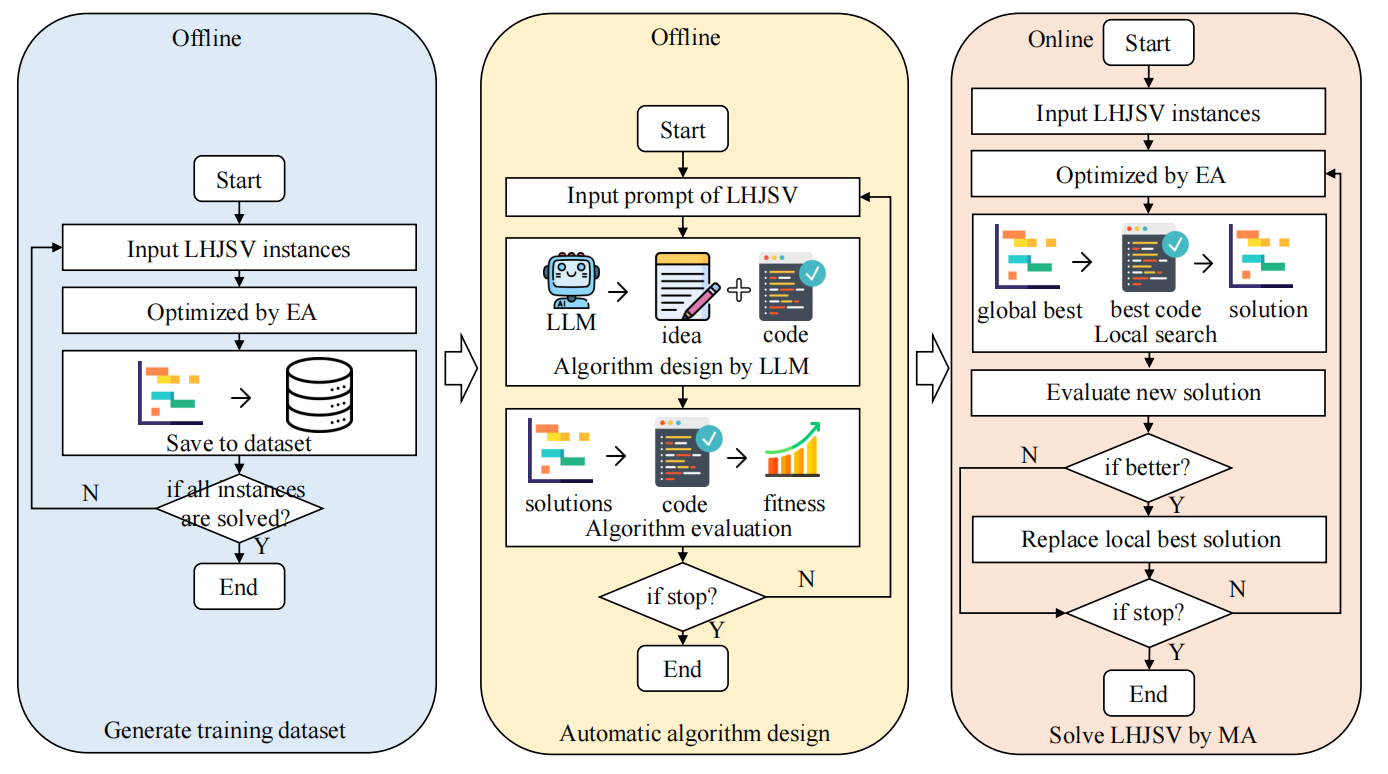
提示工程
-
核心算子
基于[28]的框架,采用四类操作算子:
[E1,E2,M1,M2]\left[E_1, E_2, M_1, M_2\right][E1,E2,M1,M2]- E1E_1E1:生成与父代算法完全不同的新算法
- E2E_2E2:基于父代算法概念设计新算法
- M1M_1M1:改进现有算法的结构或性能
- M2M_2M2:优化现有算法的参数
-
提示结构创新
- 传统提示组件:
- 任务描述(Task Description)
- 函数名(Function Name)
- 输入/输出定义(Input/Output)
- 输入输出信息说明(Information of Input and Output)
- 其他相关信息(Other Relevant Information)
- 本文新增组件:
- 手动代码(Manual Code):添加在任务描述后,通过Chain-of-Thought推理增强LLM对代码结构和问题理解的能力
- 传统提示组件:
初始化流程
-
提示构建
- 使用i1i_1i1提示模板初始化算法种群
- 提示结构:
任务描述 + 手动代码 - 标准化指令:
“首先用一句话描述新算法及其主要步骤(描述需用花括号括起)。
其次,用Python实现名为[函数名]的函数,该函数接受[输入]并返回[输出]。
同时提供[输入输出信息]和[其他相关信息]。”
-
种群生成
- 将上述组件嵌入i1i_1i1提示,与LLM交互两次
- 每个解包含:算法描述、对应代码、适应度评估值
算法评估
-
基准解生成
- 对每个LHJSV实例执行进化算法(EA),生成基准解Si(i=1,...,NC)S_i (i=1,...,N_C)Si(i=1,...,NC)
- 参数设置:
- 最大评估次数 MaxNFEs=2×104MaxNFEs=2×10^4MaxNFEs=2×104
- 种群大小 ps=100ps=100ps=100
- 交叉率 Pc=1.0P_c=1.0Pc=1.0,变异率 Pm=0.2P_m=0.2Pm=0.2
-
协同优化
- 将SiS_iSi的工序排序向量(OSOSOS)输入其对应算法种群
- 将批次分割(LSLSLS)和机器选择(MSMSMS)向量输入另一任务的种群
- 每个算法独立优化SiS_iSi,迭代nlsn_{ls}nls次
-
适应度计算
- 采用类似于SPEA2中使用的多目标指标:
Fj=∑i=1NCϕi−1RNC∑t=1R∑i=1NCCmax(Aj)−Cmax(Si)Cmax(Si),∀j(9)F_j=\sum_{i=1}^{N_C}\phi_i - \frac{1}{RN_C}\sum_{t=1}^{R}\sum_{i=1}^{N_C}\frac{C_{\max}(A_j)-C_{\max}(S_i)}{C_{\max}(S_i)}, \forall j \quad (9)Fj=i=1∑NCϕi−RNC1t=1∑Ri=1∑NCCmax(Si)Cmax(Aj)−Cmax(Si),∀j(9)- 当RPDi<0RPD_i<0RPDi<0时 ϕi=1\phi_i=1ϕi=1,否则 ϕi=0\phi_i=0ϕi=0
- RPDiRPD_iRPDi:算法AjA_jAj在实例iii的相对百分比偏差
- FjF_jFj值越大表示算法性能越优
- 采用类似于SPEA2中使用的多目标指标:
-
异常处理
- 若LLM生成的算法无法运行:适应度设为
None,环境选择阶段优先淘汰 - 若算法存在语法/逻辑错误导致不可行解:
(1) 定位解中不可行部分
(2) 对未调度工序随机重排并插入解中空闲位置
(3) 从候选集重新分配无效机器选择
- 若LLM生成的算法无法运行:适应度设为
算法协同进化
-
协同机制
- 每个任务独立评估并选出最优算法
- 向LLM提交操作算子[E1,E2,M1,M2][E_1, E_2, M_1, M_2][E1,E2,M1,M2]生成新算法
- 使用另一任务的最优解协同优化SiS_iSi
-
终止条件
- 算法协同进化执行AgA_gAg代后终止
算法种群更新
- 保留每个种群中适应度最高的前ApA_pAp个算法
- ApA_pAp:算法种群大小
以下是对论文**实验结果部分(Section IV)**的严格提炼,完全依据原文内容组织,未添加任何外部信息或主观推测:
实验结果
数据集与评估指标
-
数据集:
- 基础:JSP标准基准TA01-80
- 扩展:20个均匀选取的实例
- 参数设置:
- 批次大小 Bi∈{5,10}B_i \in \{5,10\}Bi∈{5,10}(随机)
- 每类机器并行数 ∈{2,3}\in \{2,3\}∈{2,3}(随机)
- 工序准备时间 Ti,jS∈[5,10]T^S_{i,j} \in [5,10]Ti,jS∈[5,10](均匀采样)
-
评估指标:
- LLM训练指标:
Fj=∑i=1NCϕi−1RNC∑t=1R∑i=1NCCmax(Aj)−Cmax(Si)Cmax(Si)(9)F_j = \sum_{i=1}^{N_C}\phi_i - \frac{1}{RN_C}\sum_{t=1}^{R}\sum_{i=1}^{N_C}\frac{C_{\max}(A_j)-C_{\max}(S_i)}{C_{\max}(S_i)} \quad (9)Fj=i=1∑NCϕi−RNC1t=1∑Ri=1∑NCCmax(Si)Cmax(Aj)−Cmax(Si)(9) - 调度性能指标:
RPD=Cmax(Aj)−LBLB,LB=min(Cmax(Aj))RPD = \frac{C_{\max}(A_j) - LB}{LB}, \quad LB = \min(C_{\max}(A_j))RPD=LBCmax(Aj)−LB,LB=min(Cmax(Aj))
- LLM训练指标:
超参数分析
实验1:启发式协同进化(CEoH)参数
- 因素:
- 算法种群大小 Ap∈{4,7,10}A_p \in \{4,7,10\}Ap∈{4,7,10}
- 进化代数 Ag∈{5,10,15}A_g \in \{5,10,15\}Ag∈{5,10,15}
- 关键结果
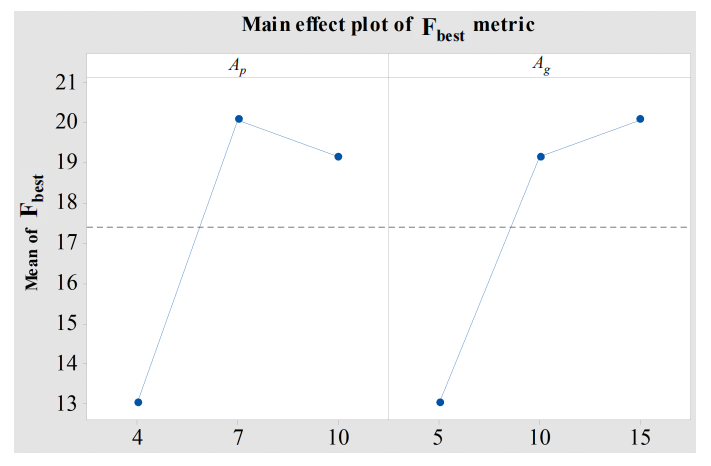
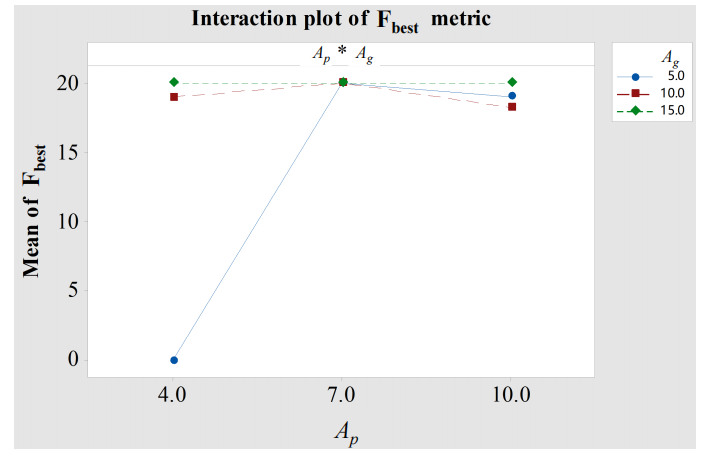
结论:Ap=7A_p=7Ap=7 为最优,AgA_gAg 无显著偏好(故设 Ag=15A_g=15Ag=15)
实验2:文化基因算法参数
- 因素:
- 种群大小 ps∈{20,50,100}ps \in \{20,50,100\}ps∈{20,50,100}
- 局部搜索次数 nls∈{1,5,10}n_{ls} \in \{1,5,10\}nls∈{1,5,10}
- 变异率 Pm∈{0.1,0.2,0.3}P_m \in \{0.1,0.2,0.3\}Pm∈{0.1,0.2,0.3}
- 关键结果
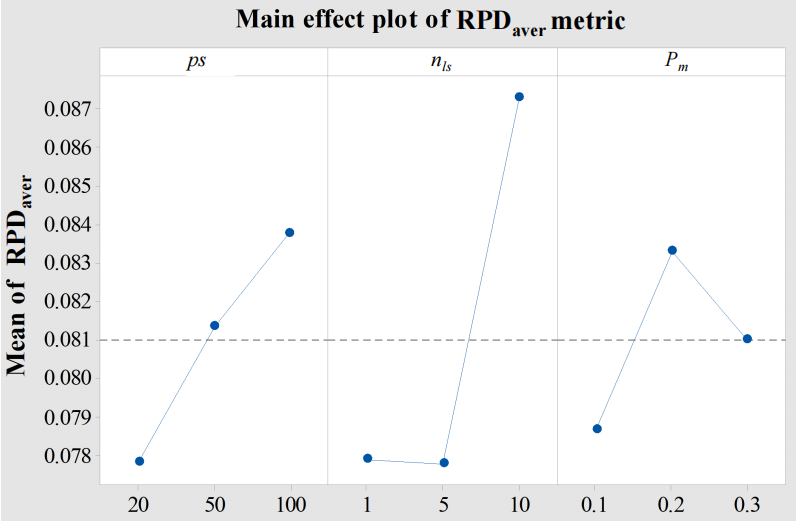
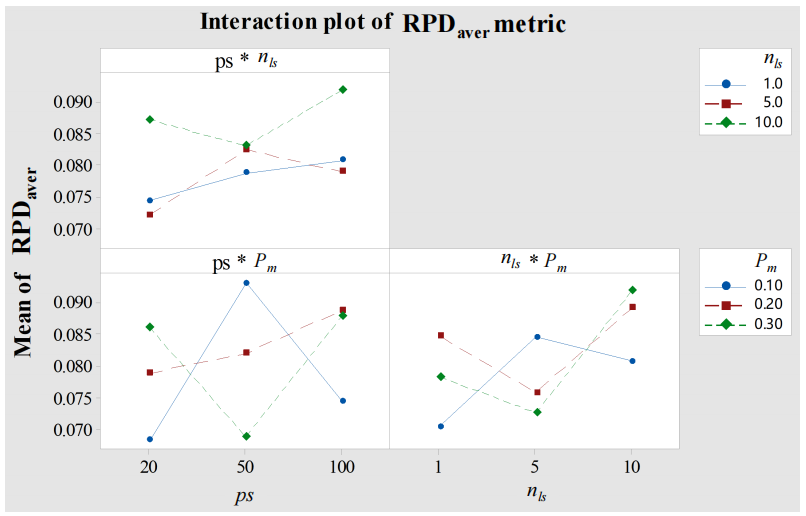
结论:nlsn_{ls}nls 存在拐点(nls=5n_{ls}=5nls=5 时 RPDaverRPD_{aver}RPDaver 最优)
消融实验
实验设计
| 消融方案 | 缩写 |
|---|---|
| 合并提示为单一复杂提示 | CEoH1 |
| 移除Chain-of-Thought机制 | CEoH2 |
| 移除LLM设计的局部搜索 | EA |
训练性能结果
| 算法 | FbestF_{best}Fbest | 改进实例数/20 | 平均RPDRPDRPD提升 |
|---|---|---|---|
| CEoH1 | 15.01831 | 15 | 1.831% |
| CEoH2 | 15.03009 | 15 | 3.009% |
| CEoH | 19.05527 | 19 | 5.527% |
测试性能结果
| 嵌入算法 | RPDaverRPD_{aver}RPDaver | 最佳解数量/20 |
|---|---|---|
| MA-CEoH1 | +1.75% | 8 |
| MA-CEoH2 | +1.35% | 9 |
| MA-CEoH | 基准 | 12 |
对比实验
- 迭代搜索算法:HHIGA, RLABC
- 生成式调度算法:HGNN
- LLM基础算法:EoH
标准测试集结果
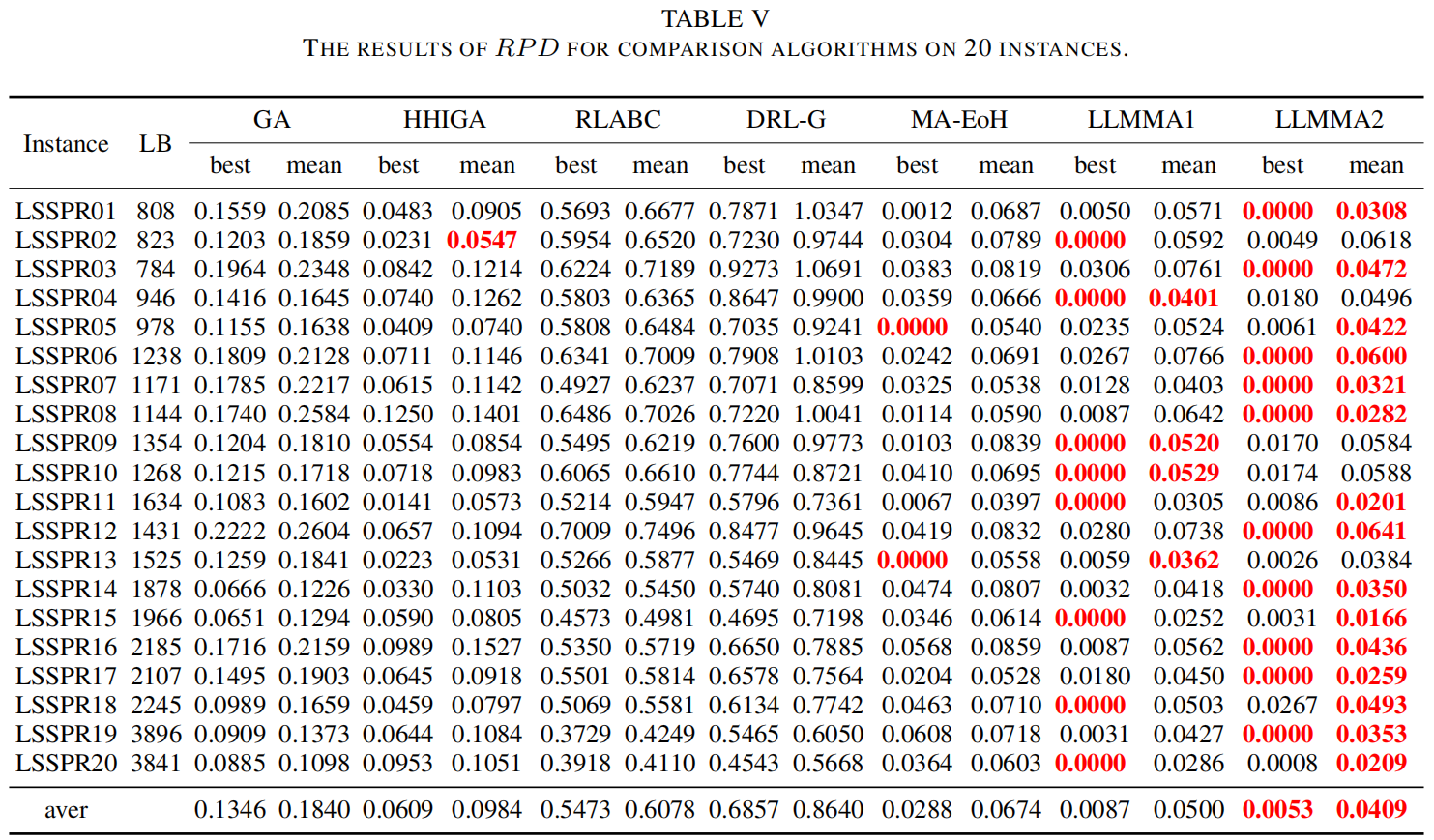
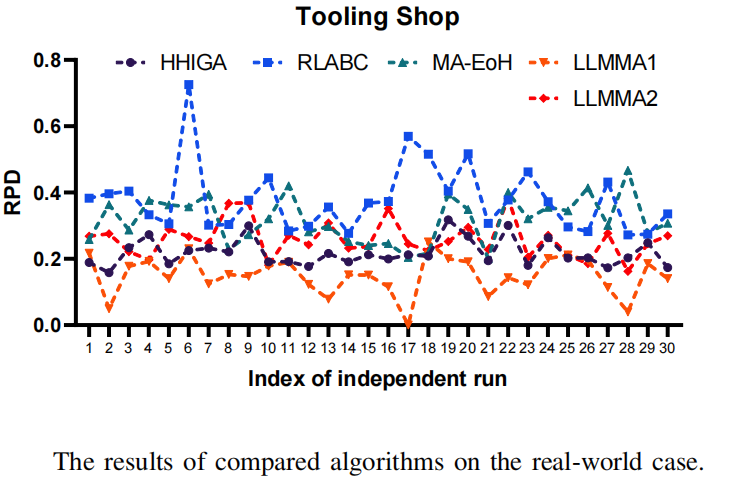
现实案例结果
- 场景:飞机工装车间(23个工件/575道工序)
- 关键发现:
- LLMMA1获得最优RPDRPDRPD
- 性能排序:LLMMA1 > LLMMA2 > HHIGA > MA-EoH > RLABC
参考文献
[1] R. Li, L. Wang, H. Sang, L. Yao, and L. Pan, “LLM-Assisted Automatic Memetic Algorithm for Lot-Streaming Hybrid Job Shop Scheduling With Variable Sublots,” IEEE Transactions on Evolutionary Computation, pp. 1-1, 2025, doi: 10.1109/TEVC.2025.3556186.
[28]F. Liu, T. Xialiang, M. Yuan, X. Lin, F. Luo, Z. Wang, Z. Lu, and
Q. Zhang, “Evolution of heuristics: Towards efficient automatic algolrithm design using large language model,” in Forty-first International
Conference on Machine Learning, 2024.

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)