[论文阅读] AI + 软件测试 | DL框架测试新神器:MirrorFuzz凭三大模块搞定跨框架漏洞,262个新漏洞获官方认可
针对深度学习(DL)框架API漏洞检测中,现有工具未利用“共享漏洞”特性的问题,提出MirrorFuzz——一款LLM驱动的自动化模糊测试工具。该工具通过三大模块实现共享漏洞检测:漏洞API识别器从GitHub Issue提取漏洞信息(准确率95.23%),相似API匹配器结合文本与语义相似度匹配相似API(覆盖率86%+),测试用例生成器生成并修复有效用例(有效性100%)。在TensorFlo
DL框架测试新神器:MirrorFuzz凭三大模块搞定跨框架漏洞,262个新漏洞获官方认可
论文信息
- 论文原标题:MirrorFuzz: Leveraging LLM and Shared Bugs for Deep Learning Framework APIs Fuzzing
- 主要作者及研究机构 Shiwen Ou, Yuwei Li, Lu Yu, Chengkun Wei, Tingke Wen, Qiangpu Chen, Yu Chen, Haizhi Tang, and Zulie Pan
- 来源: https://arxiv.org/pdf/2510.15690.
- 收录情况:Accepted for publication in IEEE Transactions on Software Engineering (TSE), 2025
一段话总结
MirrorFuzz是一款基于大语言模型(LLM)的自动化模糊测试工具,专门针对深度学习(DL)框架API中被忽视的“共享漏洞”问题——即功能或参数相似的API可能存在相同缺陷。它通过“漏洞API识别→相似API匹配→测试用例生成”三大核心模块,解决了现有工具API覆盖有限、无法利用跨框架相似性的痛点,最终在TensorFlow、PyTorch等4个主流DL框架中检测出315个漏洞(含262个新漏洞),代码覆盖率较最优基线提升最高达98.2%,且80个漏洞已被开发者修复,为DL框架安全性提供了高效、通用的解决方案。
思维导图

研究背景:DL框架的“漏洞盲区”与未被满足的需求
要理解MirrorFuzz的价值,得先搞懂DL框架的“特殊地位”——它是所有AI应用的“地基”。比如ChatGPT的训练依赖PyTorch,手机拍照的AI修图依赖TensorFlow Lite,一旦框架出现漏洞,上层应用可能直接崩溃、数据丢失,甚至被攻击者利用。
但长期以来,DL框架的漏洞检测存在一个“盲区”:共享漏洞。简单说,不同DL框架的API会因为“功能相似”(比如PyTorch的AdaptiveMaxPool2d和OneFlow的AdaptiveAvgPool1d都是池化操作)或“参数相似”(比如PyTorch的Conv2d和avg_pool2d都需要“卷积核大小”参数),导致相同的缺陷出现在多个API中——这就像不同品牌的手机,只要用了同款摄像头算法,可能都会有“夜间拍照模糊”的问题。
而现有测试工具根本没抓住这个点,主要分为两类:
- 模型级测试(如MoCo):必须依赖完整的DL模型(比如ResNet)才能测试,只能覆盖模型用到的少数API,像“管中窥豹”;
- API级测试(如TitanFuzz):虽然能直接生成API调用序列,覆盖范围更广,但只会“单打独斗”——测试PyTorch时不会参考TensorFlow的漏洞,测试一个API时不会关联相似API,导致大量共享漏洞被漏检。
这就催生了一个迫切需求:需要一款能“举一反三”的测试工具,利用DL框架API的相似性,从已知漏洞推导未知漏洞,提升检测效率和覆盖率。MirrorFuzz正是为解决这个需求而生。
创新点:MirrorFuzz的3个“打破常规”之处
-
首次系统定义并验证“共享漏洞”
之前行业内虽隐约发现相似API有相同bug,但从未明确分类和验证。MirrorFuzz首次将共享漏洞分为“操作相似(OS)”和“参数相似(PS)”两类,并通过4个框架的实验证明:跨框架/框架内均存在大量共享漏洞,且主要来自功能或参数设计的共性缺陷。 -
用LLM打通测试全流程,替代“脆弱”的传统方法
现有工具靠关键词过滤(比如搜“crash”找漏洞)、正则表达式提取API,准确率低且容易漏信息。MirrorFuzz全程用LLM(优先Qwen2.5-Coder)解决三大核心难题:从混乱的GitHub Issue中精准提漏洞API(准确率95.23%)、计算API语义相似度(避免“名字不同但功能相同”的误判)、生成符合API约束的测试用例(有效性100%)。 -
跨框架通用性,打破“一工具一框架”的局限
多数基线工具(如TENSORSCOPE)只支持TensorFlow或PyTorch中的一个,而MirrorFuzz同时支持TensorFlow、PyTorch、OneFlow、Jittor 4个主流框架,能跨框架推导漏洞——比如从TensorFlow的Conv2d漏洞,推导出PyTorch同类API的隐患,通用性远超同类工具。
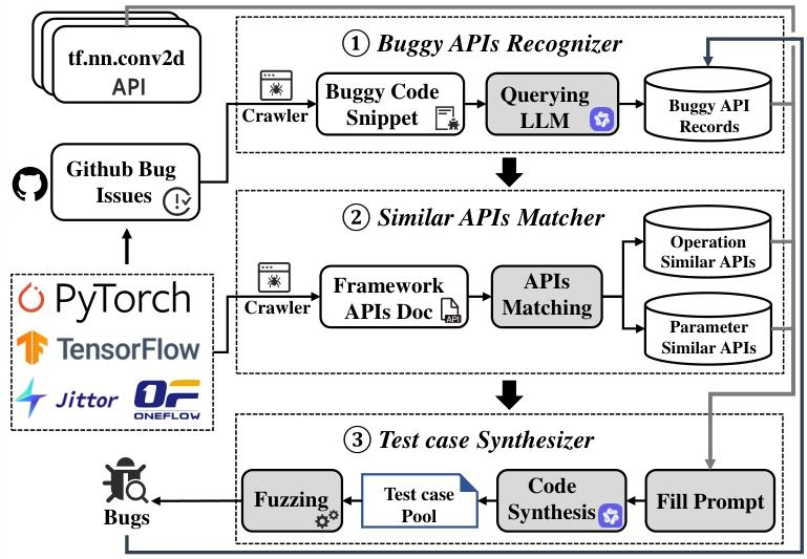
研究方法:三大模块拆解,看懂MirrorFuzz的“工作流”
MirrorFuzz的逻辑很清晰:先找到“有漏洞的API”,再找到“和它相似的API”,最后生成“能检测漏洞的测试用例”。整个过程分三大模块,每一步都有明确的技术细节:
模块1:漏洞API识别器——从GitHub Issue里“淘金”
要检测共享漏洞,首先得知道“哪些API有漏洞”。这个模块的核心是从海量GitHub Issue中提取有效信息,步骤如下:
- 数据采集:用爬虫爬取4个框架的88160条GitHub Issue,再用“crash”“segmentation fault”(段错误)等关键词,筛选出4336条漏洞相关Issue;
- LLM提取信息:给Qwen2.5-Coder喂少量示例(Few-shot),让它按“Chain-of-Thought”逻辑,从Issue的标题、描述、代码片段中提取3类关键信息——漏洞API名称、触发漏洞的参数、漏洞原因;
- 优化补全:用Levenshtein距离(字符串相似度算法)补全不完整的API名(比如把“nn.conv2d”补成“torch.nn.conv2d”),再让LLM二次验证提取结果,最终准确率达95.23%。
模块2:相似API匹配器——找到“漏洞API的兄弟”
知道了漏洞API,下一步是找“和它相似的API”。这个模块要解决“名字不同但功能/参数相似”的匹配难题,关键步骤,如下:
- 双相似度计算:同时计算两种相似度,再按权重(α=0.35)合并——
- 文本相似度:用TF-IDF算法,对比API名、参数名、官方文档的文本相似度;
- 语义相似度:用M3-embedding模型把API的元数据(功能描述、参数说明)转成向量,计算向量余弦相似度;
- 分类匹配:
- 操作相似API(OS):用“API名+参数+文档”全量元数据算相似度,匹配功能相似的API;
- 参数相似API(PS):只看参数元数据(比如是否需要“输入张量形状”“步长”参数),且排除已匹配的OS API,避免重复;
- 筛选优化:按“Top-k选择(默认选前6个最相似的API)+相似度阈值过滤”,既不遗漏高价值API,也不引入太多冗余,最终匹配覆盖率达86%以上(框架内86.29%、跨框架86.05%)。
模块3:测试用例生成器——造出“能戳漏洞的探针”
找到相似API后,需要生成测试用例来验证这些API是否真的有漏洞。这个模块的核心是“生成有效、高优先级的用例”,步骤如下:
- 用例生成:基于漏洞API的信息(比如“输入负数参数会崩溃”),让LLM生成符合目标API约束的测试用例(比如给PyTorch的
Conv2d传负数卷积核大小); - 错误修复:如果生成的用例有语法错误(比如少括号)或运行时错误(比如参数类型不匹配),让LLM结合错误提示自动修复;
- 优先级排序:按“是否包含目标API(G)+覆盖API唯一性(U)-执行时间(C)”的公式给用例排序,选前10个用例做“变异”(比如把参数改成边界值、换张量形状),最终用于模糊测试——这样能在有限时间内优先检测高风险API。
主要成果:用数据说话,MirrorFuzz到底有多强?
论文用4组核心实验验证了MirrorFuzz的性能,结果直接碾压基线工具。下面用表格和关键数据,清晰展示它的“实力”:
核心实验结果汇总表
| 研究问题(RQ) | 实验内容 | 关键结论 |
|---|---|---|
| RQ1:漏洞API识别准确率如何? | 对比Qwen2.5-Coder与CodeLLama等LLM的识别效果 | Qwen2.5-Coder准确率95.23%,比CodeLLama高12.7%,能精准提取漏洞信息 |
| RQ2:相似API匹配效果如何? | 测试框架内/跨框架API的匹配覆盖率 | 框架内匹配覆盖率86.29%,跨框架86.05%,漏检率远低于传统文本匹配方法 |
| RQ3:漏洞检测能力比基线强多少? | 相同时间内,对比MirrorFuzz与TitanFuzz、Orion的漏洞数 | TensorFlow中检测27个漏洞,是TitanFuzz(2个)的13.5倍,Orion(14个)的1.9倍 |
| RQ4:代码覆盖率提升多少? | 对比MirrorFuzz与最优基线的代码覆盖率 | TensorFlow覆盖率提升39.92%,PyTorch提升98.20%,覆盖API数量接近框架总量 |
更直观的“厉害之处”
- 漏洞数量多且质量高:总共检测出315个漏洞,其中262个是未被发现的新漏洞;52个漏洞获得CNVD(国家信息安全漏洞库)ID,80个被开发者修复,180个被框架官方确认——这意味着这些漏洞不是“假阳性”,而是真的能影响实际应用。
- 效率极高:5小时内就能测试400个API——在TensorFlow中测试了385个(发现27个漏洞),在PyTorch中测试完所有400个(发现11个漏洞),比基线工具节省至少一半时间。
- 开源资源可复用:作者开源了工具代码和漏洞数据集,方便其他研究者继续优化:
- 工具代码地址:https://github.com/MirrorFuzz/MirrorFuzz
- 漏洞数据集地址:https://github.com/MirrorFuzz/DL-Framework-Bug-Dataset
关键问题:5个核心疑问的直白解答
-
Q:MirrorFuzz解决的最核心问题是什么?
A:解决DL框架测试中“不会举一反三”的问题——利用API的相似性,从已知漏洞推导未知的共享漏洞,避免重复测试和漏检。 -
Q:“共享漏洞”为什么会存在?分哪两类?
A:因为DL框架要实现相同功能(如池化、卷积)或兼容标准(如ONNX),会设计相似的API逻辑或参数;分两类:操作相似API(OS)因功能逻辑缺陷产生,参数相似API(PS)因参数校验缺陷产生。 -
Q:如果不用LLM,MirrorFuzz能实现吗?
A:很难。现有工具靠关键词、正则提取信息,准确率低(比如把“nn.conv2d”误判成“nn.conv3d”);而LLM能理解Issue的语义,精准提漏洞信息,还能生成符合API约束的测试用例,是核心技术支撑。 -
Q:MirrorFuzz检测出的漏洞,对普通开发者有影响吗?
A:有。比如它发现的PyTorch“整数溢出”漏洞,会导致模型训练时数据异常;这些漏洞被修复后,普通开发者用框架时会更少遇到崩溃、数据丢失等问题。 -
Q:未来MirrorFuzz会怎么优化?
A:作者提到三个方向:优化相似API匹配的“自适应阈值”(现在是经验值α=0.35,未来会动态调整)、针对“释放后使用”等特定漏洞类型优化、用多智能体替代现有组件提升鲁棒性。
总结
MirrorFuzz的最大价值,在于它“换了个思路”做DL框架测试——不再孤立地测试单个API或单个框架,而是利用“共享漏洞”这个特性,用LLM实现“举一反三”的检测。从实验结果看,它不仅检测出了315个漏洞(含262个新漏洞),还大幅提升了代码覆盖率和测试效率,且开源资源能推动整个领域的安全测试发展。
对于AI开发者来说,这意味着未来DL框架的漏洞会更少,应用更稳定;对于研究者来说,它提供了“LLM+模糊测试”在DL领域的新范式,值得进一步探索优化。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)