斯坦福和Google双论文揭秘:如何让AI系统真正学会学习?从“上下文”和“策略记忆”出发,高效完成学术科研任务!
斯坦福和Google近期发表的两篇论文探索了如何让AI系统具备持续学习能力。斯坦福提出的ACE框架通过动态优化上下文实现AI自我改进,采用Generator-Reflector-Curator三角色机制和增量更新策略避免"上下文崩塌"。Google的ReasoningBank+MaTTS则构建"策略记忆库",将AI经验提炼为可复用策略,在测试阶段通过记忆引导
斯坦福和Google双论文揭秘:如何让AI系统真正学会学习?从“上下文”和“策略记忆”出发,高效完成学术科研任务!
在学术科研当中,不少同仁已经开始学会使用AI工具来辅助写作、润色、代码调试以及实验设计等任务。但我相信各位同仁都会有这种体验:一开始用AI辅助的时候,AI出来的效果确实很惊艳,回答的很快;但多次迭代真正让它对内容进行深入时,就会发现它经常记不住事,没办法持续进步,也很难在一次次提问中越用越聪明。
这背后,其实触及了一个非常核心的问题:如何让AI系统真正具备持续学习和自我进化的能力。
最近看到两篇非常有意思的论文,恰好都在试图解决这个难题。第一篇是来自MarkTechPost 的文章,介绍了斯坦福的Agentic Context Engineering,它提出了一种通过动态演化上下文,而不是传统微调方式,让大模型能够在使用过程中实现自我改进;第二篇则是介绍了Google AI 的 ReasoningBank 框架,它让AI系统在测试阶段就能主动总结、提炼和进化自己的策略,相当于让大模型在实操中 来持续成长。
两项研究看起来出发点确实不同,一个关注上下文优化,一个聚焦策略记忆,但本质上都在回答同一个问题,那就是怎么让AI真正学会学习。接下来我就把这两篇论文的核心要点进行梳理,希望各位同仁看完后能有所收获。
虽然这两篇论文的目标一样,但它们的路径不同,一个偏“上下文”,一个偏“记忆”,我们先来看第一篇论文的核心要点。
第一篇论文:ACE(Agentic Context Engineering)
关键词:上下文工程(context engineering)
文章强调与其反复的训练AI,不如靠修改和积累上下文来让AI变聪明。
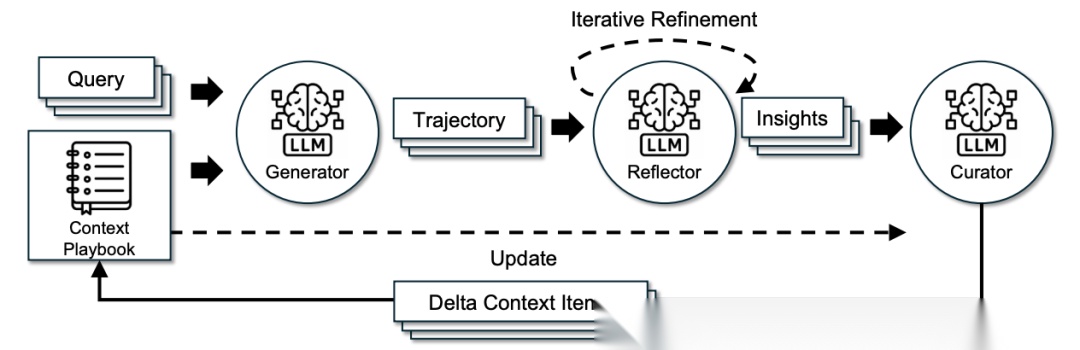
ACE把模型分成了三个角色:
1)Generator(执行者):执行任务、输出包括成功与失败动作的轨迹;
AI提示词指令:
请你现在扮演 Generator(执行者)角色,任务是【在此填写科研任务或具体目标】。请完整执行任务,并逐步记录你的推理过程。对于每一步,请说明:1) 采取的行动是什么;2)为什么选择该行动;3)该步骤是否成功;4)遇到的任何问题。最后把整个过程整理成结构化轨迹,记录成功与失败的动作。
2)Reflector(反思者):从轨迹中进行分析,提取成功原因或失败教训;
AI提示词指令:
你现在扮演 Reflector(反思者)角色。 输入是 Generator 为任务【在此填写科研任务】生成的轨迹。请逐步分析轨迹,指出: 1)哪些行为或决策促成了成功;2)哪些导致了失败或低效;3)可以从中提炼的经验教训或改进方法。最后清晰总结这些发现,区分可执行策略和需要避免的错误。
3)Curator(整理者):将分散的见解整理并转化为结构化的上下文更新。
AI提示词指令:
你现在扮演 Curator(整理者)角色。 输入是 Reflector 从 Generator 轨迹中提炼出的经验和教训,任务为:【在此填写科研任务】。 请将这些见解整理成结构化、简明的上下文更新,便于后续任务复用。包括: 1)上下文标题;2)关键可执行要点;3)对应用这些见解的建议;4)需要注意的潜在问题。请输出易于整合到提示词或记忆系统中的格式。
其实关键的创新"增量更新"机制,传统的方法一更新提示词,就会把原来的内容几乎全删掉重写,结果直接导致上下文越来越短、细节也越来越少。而 ACE 的聪明做法是:采用增量更新(delta updates),不进行整体重写,只改动需要改的部分,一步步‘加’或‘修’,这样就能 防止 “上下文崩塌” 或历史遗忘。
在实验中,ACE 不仅在智能体基准测试(比如 AppWorld),也在金融推理任务(如 XBRL 和 FiNER)上,都明显优于多种现有的上下文适配方法,还大幅降低了延迟和成本。
第二篇论文:ReasoningBank + MaTTS
关键词:策略级记忆(strategy-level memory)
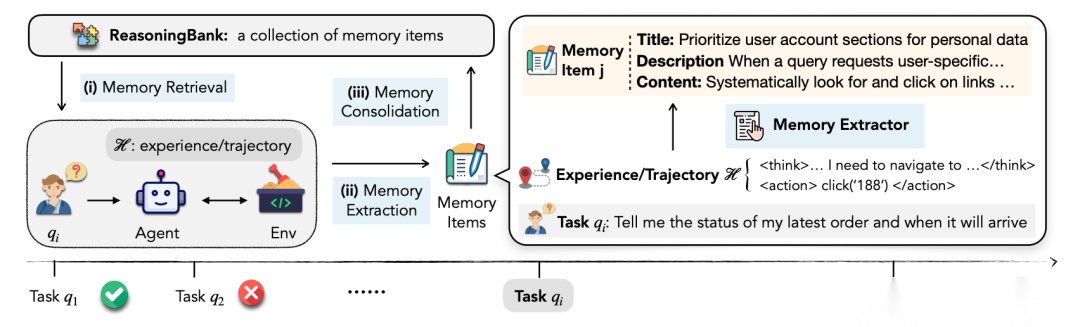
Google 这篇研究关注的是 “代理记忆(agent memory)”的设计,也就是在 AI 与外界交互过程中,如何把它的行为轨迹、成功经验和失败经验整理起来,用于指导未来决策。文章提出了一个叫 ReasoningBank 的机制:
- 不保存冗长的操作日志,而是将 AI 在任务中积累的经验抽象为策略级别的记忆条目,便于管理和复用。
- 每条记忆条目都包含标题、一行描述以及具体内容、原则、约束或启发,让经验信息既精炼又可操作。
- 在执行新任务时,系统通过 embedding 检索找到与当前任务相关的策略条目,把它们注入系统提示或引导语,形成检索 → 注入 → 执行 → 评估 → 提炼 → 追加(retrieve → inject → execute → judge → distill → append)
那么AI提示词可以这样设计(仅供参考):
提示词(检索):你现在作为 ReasoningBank 代理执行任务。 针对当前任务:【填写科研任务】,请从记忆库中检索相关的策略级记忆条目。 挑选最符合任务背景并能指导有效决策的条目。
提示词(注入):将检索到的策略记忆条目注入为系统提示或引导语,保证条目清晰融合,为 AI 的推理提供可执行指导。
提示词(执行):执行任务:【填写科研任务】,使用注入的策略记忆作为指导,记录每一步、每个决策及中间结果。
提示词(评估):请评估任务执行结果,识别成功、失败、低效环节,以及可改进的地方。
提示词(提炼):根据评估结果提炼关键经验、洞见和可泛化策略,将其整理为策略级记忆条目,包括标题、一行描述和可执行原则。
提示词(追加):将新提炼的记忆条目追加到记忆库中,供未来检索使用,保证条目结构化存储,便于高效调用。
有了这个流程,那么AI就会不断从已有经验中学习,并把新的经验加入记忆库。
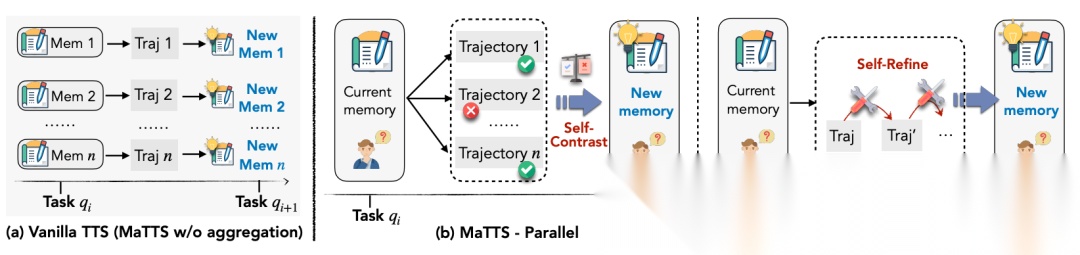
为了更高效地探索和利用记忆,他们还提出了 MaTTS(Memory-aware Test-Time Scaling),即在测试/推理阶段,通过增加搜索或推理次数(rollouts / refinements),结合记忆引导,产生更优轨迹或策略;
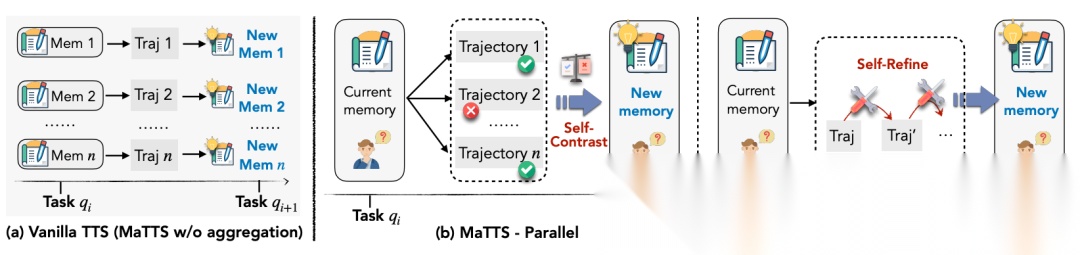
MaTTS 有两种实现方式:
- 并行版本:同时生成多个候选方案,然后比较筛选最佳;
- 顺序版本:逐步优化单条轨迹(refinement)。
换句话说,实际上ReasoningBank + MaTTS 就像给 AI 装了一个“策略记忆库”,让它在实际任务中能回顾经验、优化行为来实现不断进步。
总的来说,这两篇文章虽从不同切入点出发,但其实都没有去直接改模型或重新训练,而是在模型外部寻找办法,探索如何让AI持续学习、不断自我改进。ReasoningBank会让AI记住具体经验和教训(外部记忆),而ACE则让AI通过不断优化上下文来改进工作流程(内部优化)。如果把两者进行结合,那么我们就能得到一个既能 积累经验(ReasoningBank),又能不断优化方法(ACE)的系统。换句话说,AI 不只是要变得更聪明,更重要的是学会怎么去学习。

最近这几年,经济下行,IT行业面临经济周期波动与AI产业结构调整的双重压力,很多人都迫于无奈,要么被裁,要么被降薪,苦不堪言。
但我想说的是一个行业下行那必然会有上行行业,目前AI大模型的趋势就很不错,大家应该也经常听说大模型,也知道这是趋势,但苦于没有入门的契机,现在他来了,我在本平台找到了一个非常适合新手学习大模型的资源。
[大家想学习和了解大模型的,可以点击这里前往查看]

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)